【2025 NeurIPS】Thought Communication in Multiagent Collaboration
这一工作为机器间"脑对脑"式直接通信奠定了理论和实践基础。
·
1. 核心问题 (Core Problem)
现有的基于大语言模型(LLM)的多智能体系统(Multi-Agent Systems, MAS)主要依赖自然语言(文本或其嵌入)作为通信媒介。然而,作者指出自然语言存在根本性的局限性:
- 有损与模糊(Lossy & Ambiguous): 语言是思维的间接、碎片化反映,往往无法完全传递智能体内部复杂的推理过程和意图。
- 低效(Inefficient): 语言是序列化的,对于机器而言,这种人类生物学限制是不必要的。
- 导致协作失败: 实证分析表明,许多多智能体协作的失败源于信息的模糊表达和智能体之间的未对齐,这本质上是由语言通信的间接性造成的。
核心疑问: 既然机器不受人类生理限制,为什么它们必须像人类一样用语言交流?是否存在一种超越语言的通信形式?
2. 核心思想 (Core Idea)
论文提出了一种新的通信范式——思维通信(Thought Communication)。

- 类比“心灵感应”: 就像“心灵感应”一样,智能体不交换表层的文本 Token,而是直接交换底层的潜在思维(Latent Thoughts)。
- 潜在变量模型: 作者将这一过程形式化为一个通用的潜在变量模型。假设智能体在通信前的模型状态(Hidden States, H t H_t Ht)是由一组未知的潜在思维( Z t Z_t Zt)通过某种函数 f f f 生成的,即 H t = f ( Z t ) H_t = f(Z_t) Ht=f(Zt)。
- 可识别性理论(Identifiability): 论文的核心理论突破在于证明了:在非参数设置下,只要施加稀疏性正则化(Sparsity Regularization),我们就能够从观察到的智能体状态中,数学上可证明地恢复出真实的潜在思维(包括共享的思维和私有的思维),以及这些思维在智能体间的共享结构。
3. 方法 (Method: THOUGHTCOMM)
基于上述理论,作者提出了一个名为 THOUGHTCOMM 的实用框架,使 LLM 智能体能够进行思维层面的通信。该框架主要包含三个步骤: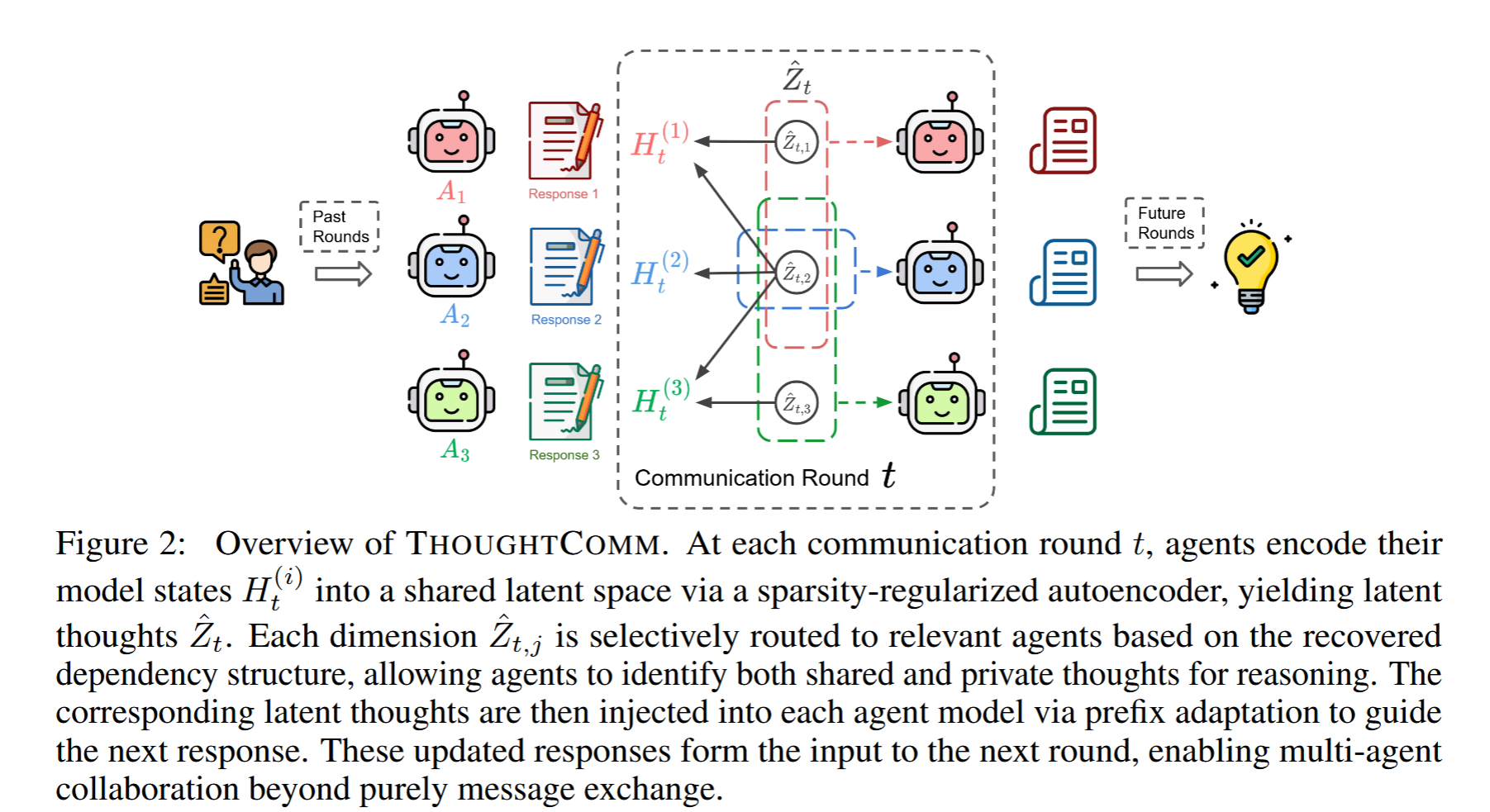
-
挖掘潜在思维 (Uncovering Latent Thoughts):
- 提取所有智能体在生成回复前的模型隐藏状态(Model States)。
- 训练一个带有 ℓ 1 \ell_1 ℓ1 稀疏正则化的自编码器(Autoencoder)。根据理论,这个自编码器的中间层就能捕捉到解耦的、真实的潜在思维 Z t Z_t Zt。
- 稀疏性约束确保了恢复出的思维结构是可解释的(区分哪些是共享的,哪些是私有的)。
-
利用思维结构 (Leveraging Structure):
- 通过分析自编码器的雅可比矩阵(Jacobian)的非零模式,确定哪些思维对哪些智能体是相关的。
- 根据思维在智能体间的共享程度(Agreement level)对潜在变量进行加权和分组,为每个智能体构建个性化的潜在表示。
-
通过前缀适配注入思维 (Latent Injection via Prefix Adaptation):
- 为了让 LLM 理解这些连续的潜在向量,作者训练了一个轻量级的适配器(Adapter)。
- 适配器将恢复出的潜在思维映射为连续的前缀(Prefix Embedding)。
- 在下一轮对话生成时,这些前缀被直接注入到智能体的上下文中,从而在不显式传递文本消息的情况下,引导智能体的推理和生成方向。
4. 贡献 (Contributions)
- 新范式的提出: 引入了“思维通信”这一新范式,突破了多智能体系统仅依赖自然语言通信的限制,允许机器进行更直接的“脑对脑”交互。
- 理论保证(可识别性证明):
- 证明了在一般非参数设置下,智能体间**共享的(Shared)和私有的(Private)**潜在思维是可以被唯一识别的。
- 证明了思维的全局结构(即谁拥有什么思维)也是可以被恢复的。这为从黑盒状态中提取有意义的认知结构提供了数学基础。
- 实用的 THOUGHTCOMM 框架: 开发了一个即插即用的框架,通过稀疏正则化自编码器和前缀微调,实现了理论到实践的转化。该框架不需要微调整个 LLM,计算开销小。
- 实验验证:
- 合成数据: 验证了理论,能够准确分离共享和私有变量。
- 真实基准(MATH & GSM8K): 在多个 LLM(Llama-3, Qwen-3, Phi-4 等)上进行了测试。结果显示,THOUGHTCOMM 在准确率(Accuracy)和共识度(Consensus)上均显著优于单智能体和现有的多智能体微调(Multiagent Finetuning)方法。例如,在 Qwen-3-1.7B 上,其在 MATH 数据集上的准确率比多智能体微调提高了 17.2%。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 2
2 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)