人形机器人守门员:从位置为条件的任务-运动约束中学习
25年10月来自香港大学和上海AI实验室的论文“Humanoid Goalkeeper: Learning from Position Conditioned Task-Motion Constraints”。本文提出一种用于人形机器人在真实场景中自主守门的强化学习框架。虽然之前的研究已在四足机器人平台上展示类似的能力,但人形机器人守门面临着两个关键挑战:(1) 生成自然、类人的全身运动;(2)
25年10月来自香港大学和上海AI实验室的论文“Humanoid Goalkeeper: Learning from Position Conditioned Task-Motion Constraints”。
本文提出一种用于人形机器人在真实场景中自主守门的强化学习框架。虽然之前的研究已在四足机器人平台上展示类似的能力,但人形机器人守门面临着两个关键挑战:(1) 生成自然、类人的全身运动;(2) 在相同的响应时间内覆盖更广的防守范围。与现有依赖于独立远程操作或固定运动跟踪来实现全身控制的方法不同,该方法学习单一的端到端强化学习策略,从而实现全自主、高度动态且类人的机器人与物体交互。为了实现这一目标,通过对抗机制将基于感知输入的人类运动先验信息整合到强化学习训练中。通过真实场景实验验证方法的有效性,实验中人形机器人成功地完成对快速移动球的敏捷、自主且自然的拦截。除了守门之外,还通过诸如躲避球和抓取球等任务验证方法的泛化能力。
如图所示:

开发机器人足球能力本质上需要感知、决策和敏捷运动控制的紧密整合,这使其成为评估运动智能的理想基准[1-5]。在这一领域,守门员作为一项独特的子任务脱颖而出,面临着诸多尚未充分探索的挑战。与主要涉及下肢并与缓慢或静态物体交互的运球[6, 7]或射门[8, 9]不同,守门员需要对高度动态的刺激做出快速的全身反应。因此,推进机器人守门员技术的发展是迈向完全自主、实时物理智能(PI)的关键一步。
尽管人们对机器人守门员的兴趣日益浓厚,包括四足机器人动态技能的最新进展,但现有系统在几个关键方面仍然存在局限性:仅限于儿童尺寸的平台[10]、依赖于固定的运动基元[11]以及在狭窄的拦截范围内运行。与此同时,强化学习(RL)[12, 13]、模仿-驱动的运动先验[14, 15]和人体运动恢复流程[16-18]等领域的新兴进展,为克服这些局限性开辟新的途径。随着高性能人形机器人硬件和可扩展学习框架的出现,现在可以探索以下守门员行为:(1)展现出类似人类的全身交互运动;(2)在极端时间限制下有效响应;以及(3)执行高度动态的动作以覆盖广泛且多样的拦截区域。
本文开发一种人形守门员机器人,它能够自主地成功完成守门动作,并自适应地适应人类的运动先验。该方法(如图所示)的核心是一个端到端的强化学习(RL)策略,该策略能够生成高度动态且完全自主的守门行为。该策略直接基于实时球的位置观测数据运行,这些数据同时也作为整合人类运动先验的条件变量。这些先验信息通过对抗训练方案融入到强化学习过程中,从而在不依赖预定义轨迹或严格运动跟踪的情况下,促进鲁棒且自然的运动生成。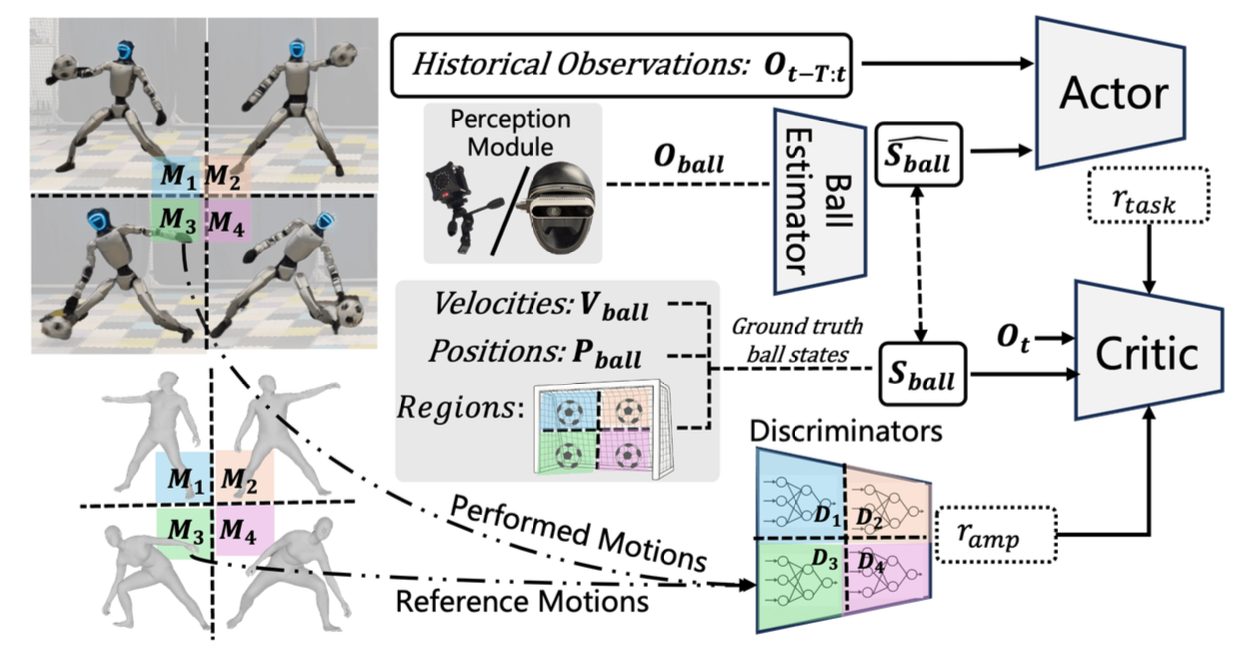
本方法通过解决两个关键挑战,推进以往的工作:(1)提出一个统一的框架,通过基于观测条件的对抗训练,同时确保任务成功和运动的真实性,从而无需单独的优化阶段;(2)在真实世界的人形机器人上展示硬件可行的、高动态的性能。
基于强化学习的守门员训练
这个学习系统旨在优化两个主要目标:(1) 任务成功率和 (2) 动作与人类示范动作的相似度。
- 训练环境:用标准的 PPO 算法 [12] 训练策略,该算法在 IsaacGym 模拟器 [13] 中实现。该策略训练机器人阻止飞行中的球在击中球门线之前落地。
观测空间包括观测的球位置 O_ball 以及本体感觉观测值 O_p。这些被用作执行器输入 O_t,并具有长度为 T 的历史数据,以捕获预测球的运动轨迹所需的时间信息。
每个episode 开始时,一个球被发射向机器人。训练环境被划分为 k 个区域,记为 R = 0, 1, 2, …, k,其中每个区域对应于球可能到达的球门线上的特定区域。区域在每个episode 开始时确定,然后在该区域内随机采样一个落点位置 p_land,并据此赋予球的速度,使其到达目标。下表概述训练期间使用的观测空间。所有与球相关的观测均在机器人的局部坐标系中计算,便于直接使用机载感知进行部署。
- 位置条件任务奖励:引入位置条件任务奖励 r_t,引导机器人通过跟踪动态目标使球远离球门线。最终目标 p_target 旨在提示机器人预测接近的球的落点,在球接近时触碰并将其击开,然后在球停止后保持静止位置(如图所示)。
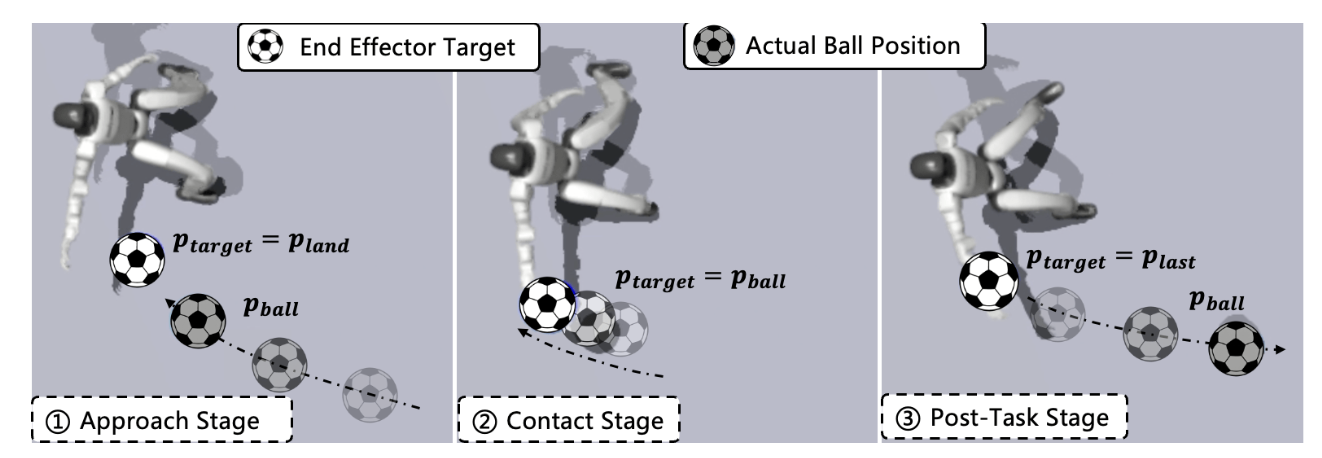
当球飞向机器人时,计算
p_target = p_land · 1_dx>d_th + p_ball · 1_dx≤dth,
其中 1_condition 根据球与机器人之间距离选择相应的目标,d_x 表示球与球门线之间的距离,d_th 表示接近的阈值。用一个 sigmoid 函数定义平滑的、基于距离的奖励,以鼓励末端执行器(手)到达目标位置,其中 σ_keep 为尺度因子,d_keep 为接球距离阈值,指示末端执行器何时足够接近球。奖励 r_t 取决于落球区域 R,通过计算所选手与最终目标之间的距离 ||p_target − p®_hand|| 来确定。例如,如果球飞向左侧区域,机器人应使用左手拦截,右侧区域的情况类似。
引入位置相关的动力学调制项 ν®,以鼓励全身运动,例如横向移动或跳跃,具体取决于区域 R:
ν® = ν_y ·1_right +(−ν_y)·1_left +ν_z ·1_up,
ν® 促进一致的全身运动,从而支持拦截过程中末端执行器的协调运动。
除了位置相关的奖励 r_t 之外,还加入额外的奖励项,以强制执行运动约束并促进硬件可行的行为。
- 任务后稳定性:将回合长度设置为 3 秒,这远长于球的飞行时间(通常为 0.4 秒),以便进行任务后稳定性训练。为了鼓励机器人在球飞过后保持标准化的姿态,引入任务后奖励项,以促进机器人从高动态的保持运动中恢复平衡。这些奖励通常定义为:
r_post = exp (−σ_stable · ||Err_stable||) · 1_ballstopped,
其中 Err_stable 表示关键稳定性相关量(例如底座高度、角速度和方向)与其标称值的偏差。指示函数 1_ballstopped 仅在球被机器人保持住或飞到机器人身后时才激活奖励。此外,将一部分环境的关节位置重置为从其他正在进行环境中采样得到的关节位置,而不是默认关节位置。这迫使机器人从先前保持运动的中间状态开始新的试验,而不是从标称重置状态开始。除了提高稳定性之外,我这种策略对于学习连续保持行为也很有效,因为机器人可以在不返回默认姿态的情况下开始新的试验。
基于运动约束的优化
引入位置条件对抗运动先验(AMP)奖励,在训练过程中施加运动约束,鼓励机器人根据球的落点区域展现合适的运动风格。受文献 [29](其探讨四足机器人的区域-特定守门行为)的启发,将模仿学习融入强化学习,以促进区域一致性行为。这些运动约束源自一个基于人类演示构建的任务特定运动库。
-
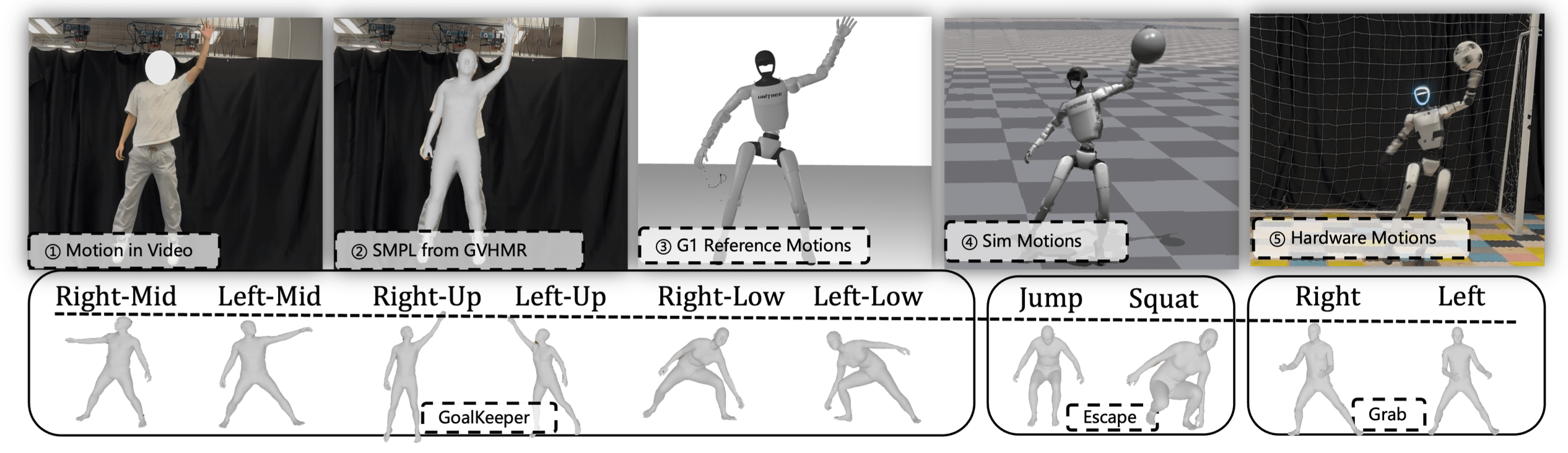
参考运动整理:首先利用现有的流程(GVHMR [16])从自录制的 RGB 视频中提取人形机器人的运动(如图所示)。接下来,将提取的运动重新应用于 Unitree G1 机器人,并将生成的关节位置序列 q_t 存储在区域特定运动参考缓冲区中。
-
基于运动约束的优化:运动约束通过对抗运动先验(AMP)奖励[14]实现,该奖励鼓励机器人在拦截过程中展现区域一致的运动风格。为此,定义位置条件AMP奖励,将每个区域R与一个专用的参考运动槽(slot)和相应的一个判别器D®关联起来。每个判别器都经过训练,以区分来自参考运动的状态转换和由策略生成的状态转换。在D®的训练目标函数,d®_M 和 d®_π 分别表示在区域 R 条件下,从专家参考运动和策略出发的关节位置转移 (q_t, q_t+1) 的分布。
鉴于任务对精度要求很高,采用更为柔和的运动约束方式,以避免与任务特定目标发生冲突。与原始的AMP公式(直接对执行的运动进行评分并奖励那些与参考分布高度匹配的运动)不同,围绕每个执行的运动生成高斯样本,并仅奖励判别器得分最高的那个。这鼓励与参考运动分布平滑对齐,使得策略能够对邻近的运动获得相似的奖励,同时让任务目标决定精确的执行方式。计算AMP的奖励函数,其中每个 (q̃(j)_t, q̃(j+1)^_t+1) 从执行的转换 (q_t, q_t+1) 为中心的高斯分布中采样得到。
模拟与现实感知的融合
获取硬件可部署的球感知,并弥合模拟与现实之间的差距,是动态目标交互任务中的关键挑战。本文机器人接收球相对于其躯干坐标系的位置,该位置由观测向量 O_ball 表示。本文实现两种基于硬件的感知系统来获取球位置 O_ball:1) 一个运动捕捉 (MoCap) 系统,该系统使用放置在机器人头部和球上的标记点,O_ball 由 MoCap 系统报告的两者之间相对位置计算得出;2) 一个安装在机器人头部并带有红外 (IR) 滤光片 [4] 的深度摄像头(Intel RealSense D435i),该摄像头可以检测高反射率的球,并直接从摄像头的感知流程中估计 O_ball。虽然这两个系统都能提供相当精确的球位置估计,但由于校准误差和感知限制(例如 MoCap 系统中的遮挡和基于摄像头的系统中的视场限制),仍然存在性能差距。为了缓解这些问题,在策略中加入球的位置估计器,并引入训练时噪声以提高两种感知模态的鲁棒性。
-
球的位置估计器:将球的位置估计器集成到训练循环中,该估计器能够有效地识别区域(针对任务和运动条件),并准确预测球的位置和运动轨迹,充分利用历史观测数据。位置估计器使用均方误差 (MSE) 损失进行训练,以最小化球位置的预测误差;而区域估计器则使用交叉熵损失进行训练,对球可能落点的正确区域进行分类。
-
训练噪声:为了模拟真实世界的感知不确定性,在训练过程中向球的观测值 O_ball 引入噪声。具体来说,应用:1) 位置噪声——最大 5 厘米的随机扰动,即球 10 厘米半径的一半——以模拟典型的感知误差; 2)随机丢包——O_ball 偶尔会在飞行 0.4 秒后被设置为零,以模拟硬件感知中球接近时遇到的遮挡或超出视场角的情况。此外,一旦球停止飞行(例如被拦截或着陆后),将 O_ball 设置为 0,以反映不再进行跟踪。然后,机器人会保持其最终姿态。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 11
11 0
0- 0



 已为社区贡献135条内容
已为社区贡献135条内容

所有评论(0)