基于大模型的本地知识库问答系统部署文档
本篇文章主要介绍了如何在服务器中部署基于AI大模型的本地知识库问答系统,利用RAG技术解决大模型无法回答私有化知识内容的问题。
0. 视频教程
1. 服务器准备
点击这里,或者复制下面网址在浏览器中打开。
https://www.vultr.com/?ref=8685401
如果还没账号,需要注册一个账号。
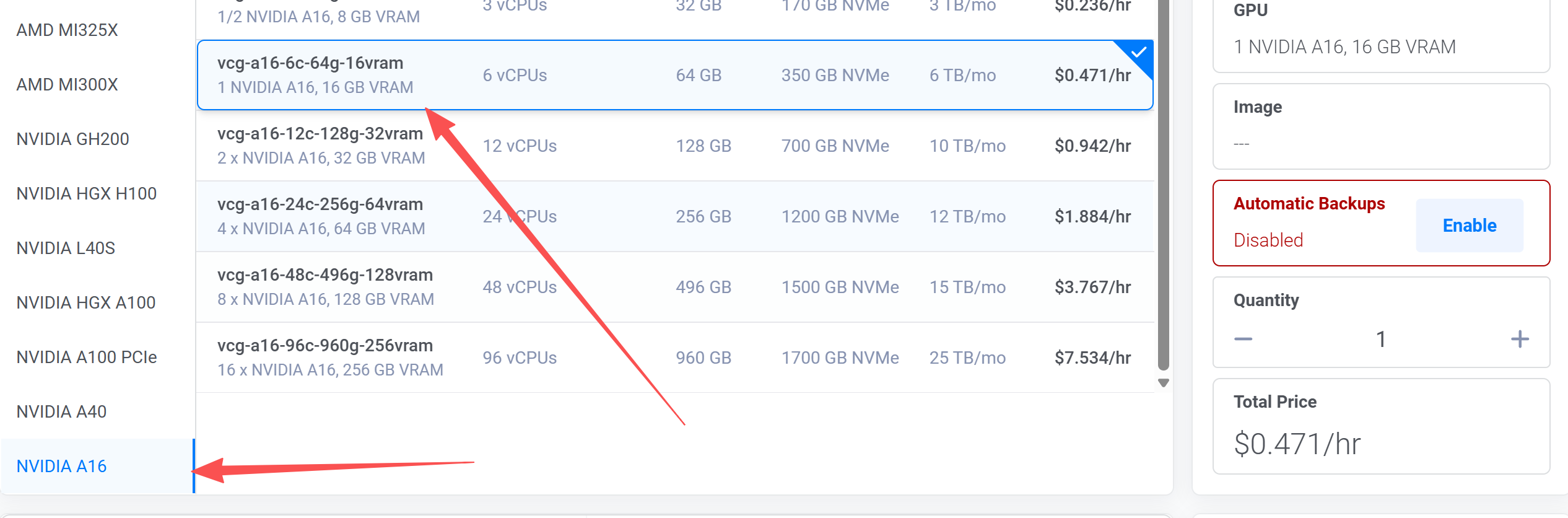
然后登录到账号内,点击面板右上角中的"Deploy +“,然后选择"Cloud GPU”,地理位置这里选择"New York",当然你也可以选择其它地区。然后把自动备份去掉,这个自动备份收费挺贵的,没有必要使用。即把"Automatic Backups"改为"Disabled"。然后选择GPU显卡型号,这里需要选择英伟达显卡,我这里选择英伟达的A16显卡,显存为16GB。
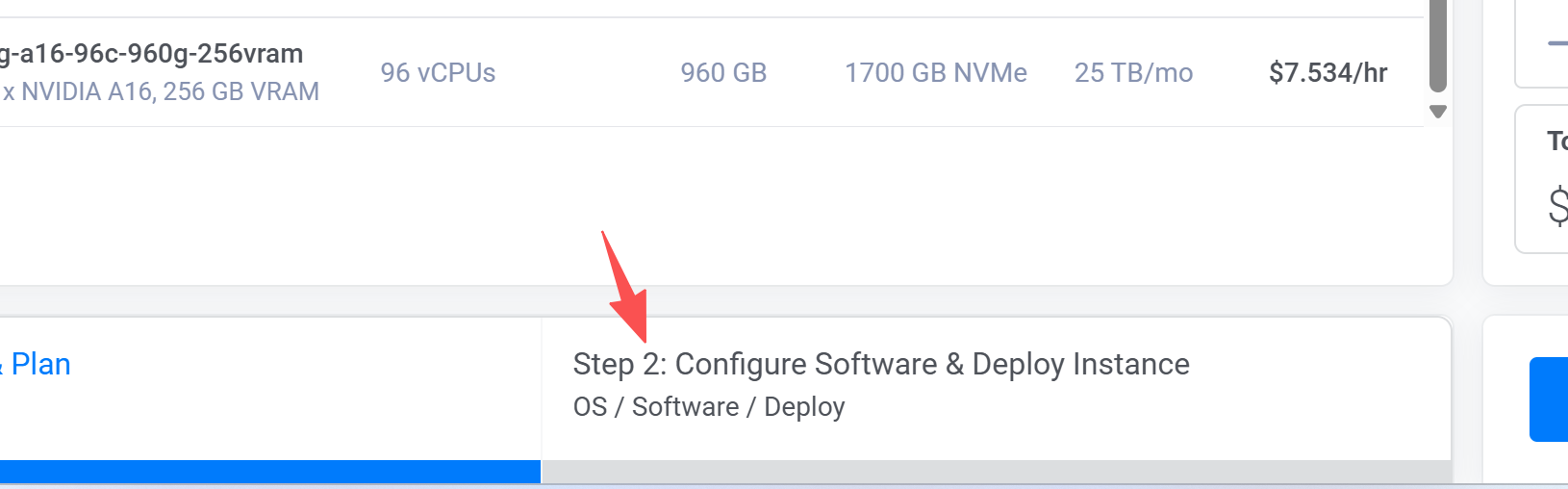
选择第二步,配置软件和部署实例。
选择操作系统,这里选择"ubuntu 22.04"。最后直接点击右下角中的“Deploy”来部署实例,这个时候会自动跳转到"Cloud Compute"管理页面中,在这个页面中可以看到你正在创建的实例,等待创建完成,然后进入实例,复制公网ipv4地址,在ssh中输入ip地址和密码,然后就可以访问到你租的服务器了。
我这里使用的是windterm工具,当然你使用你更熟悉的ssh工具也一样的,windterm是开源的,可以直接在github中搜索得到。
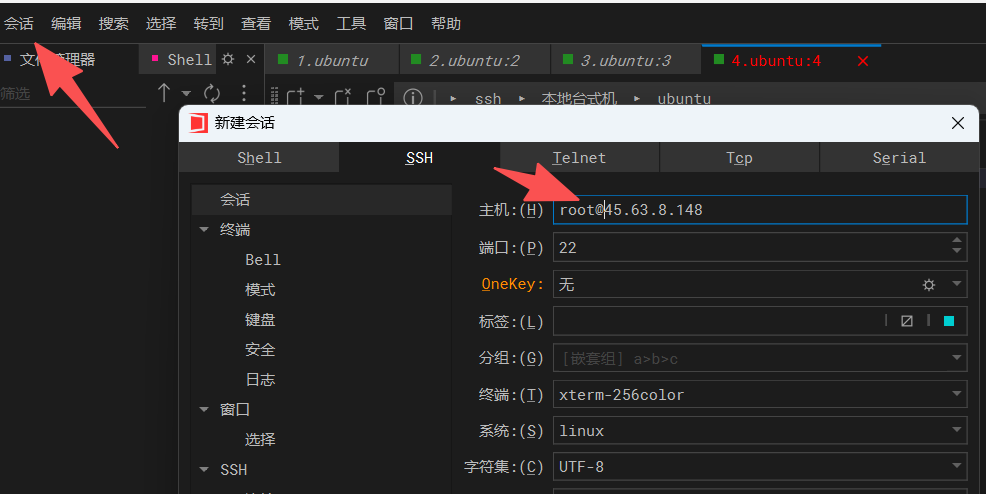
到此为止,我们就租好了服务器,下面正式开始部署AI大模型。
2. 安装环境
2.1 安装python依赖
经过上面的步骤,我们已经准备好了服务器,并且连接到了服务器中,现在我们需要在服务器中,先执行下面命令。
apt-get update -y && apt update -y
切换路径并且上传项目源码到这个路径中。
cd /usr/local/src/ && mkdir ai && cd ai
安装Anaconda或者Miniancoda,这里安装后者。如果没有Anaconda账号的人,还需要自行注册,否则不让下载。
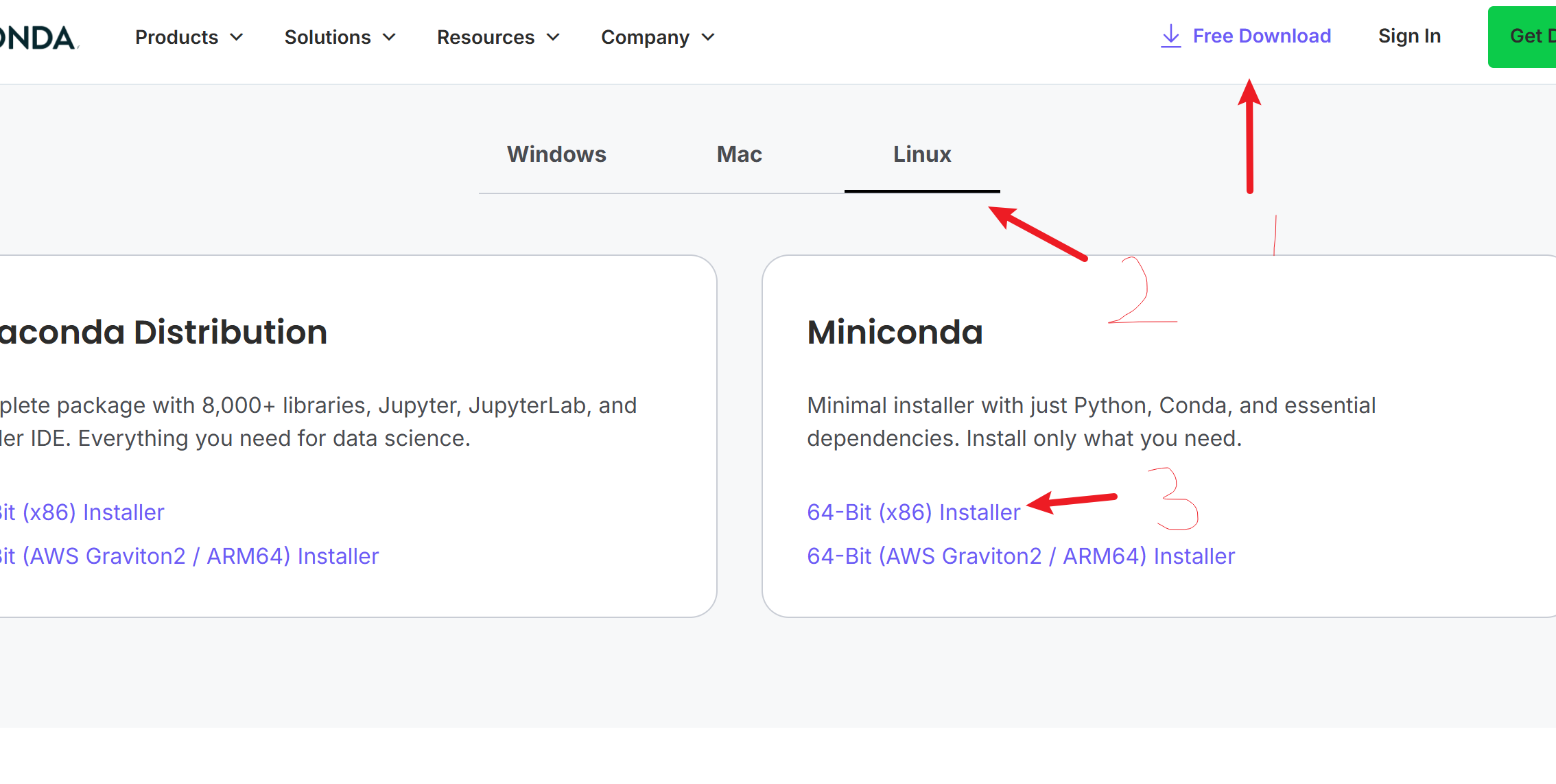
这里直接给一下下载安装脚本地址,方便你们直接复制使用。
https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
如果是ARM64的服务器,则使用下面这个下载地址。
https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-aarch64.sh
如果你是Windows用户,并且是x86架构的,那么使用下面地址。
https://repo.anaconda.com/miniconda/Miniconda3-latest-Windows-x86_64.exe
如果你是MacOS用户,则使用下面地址。
# 苹果芯片
https://repo.anaconda.com/miniconda/Miniconda3-latest-MacOSX-arm64.pkg
# 英特尔芯片
https://repo.anaconda.com/miniconda/Miniconda3-latest-MacOSX-x86_64.pkg
我上面选择的服务器是X86的,并且是Ubuntu系统,所以使用第一条命令下载这个安装脚本。
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
下载完成后记得给可执行权限。
chmod +x Miniconda3-latest-Linux-x86_64.sh
然后就可以执行安装了。
./Miniconda3-latest-Linux-x86_64.sh
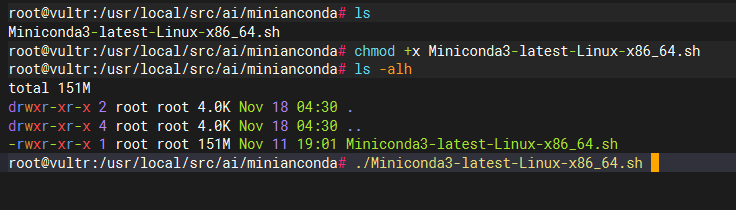
在执行上面命令的时候会提醒yes或者no,输入yes回车即可。
当全部安装完成之后,我们输入下面命令,或者重新连接到服务器也可以的,这里我执行下面命令即可。
source ~/.bashrc
然后就可以看到界面中最开始的位置上有(base)标识,说明安装成功。
然后创建名为ai的conda环境。
conda create -n ai python=3.12
安装python依赖。
pip install -r requirements.txt
2.2 安装Ollama
点击这里访问ollama下载地址,选择Linux,复制命令到ssh中执行。
curl -fsSL https://ollama.com/install.sh | sh
下载对应版本的cuda。
wget https://developer.download.nvidia.com/compute/cuda/12.4.0/local_installers/cuda_12.4.0_550.54.14_linux.run
安装cuda
chmod +x cuda_12.4.0_550.54.14_linux.run
./cuda_12.4.0_550.54.14_linux.run
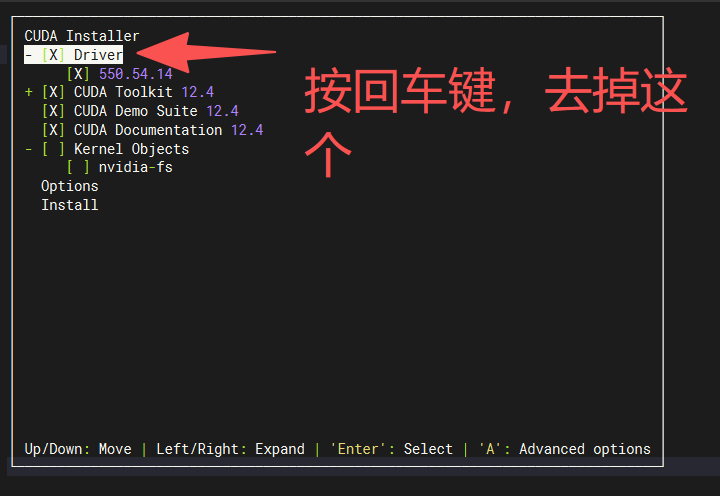
配置环境变量
vim ~/.bashrc
# 在最后面添加下面内容
export PATH=/usr/local/cuda/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
# 保存退出后,记得执行下面命令
source ~/.bashrc
验证是否配置好了环境变量,执行下面命令,当输出版本信息时,说明配置好了。
nvcc -V
通过ollama下载并且运行qwen3:8b大模型。
ollama pull qwen3:8b
下载嵌入式模型。
ollama pull bge-m3:latest
3. 运行项目
先进入到ai环境。
conda activate ai && cd /usr/local/src/ai/Qwen_Agentic_RAG
执行下面命令启动项目。
streamlit run app.py --server.port 8080
开放防火墙端口。
ufw allow 8080/tcp
然后再浏览器中访问下面地址。
http://your_ip:8080
把your_ip改为你自己服务器中的公网ip地址,如果你是内网搭建的,那么修改为你的内网ip地址。
4. 项目效果
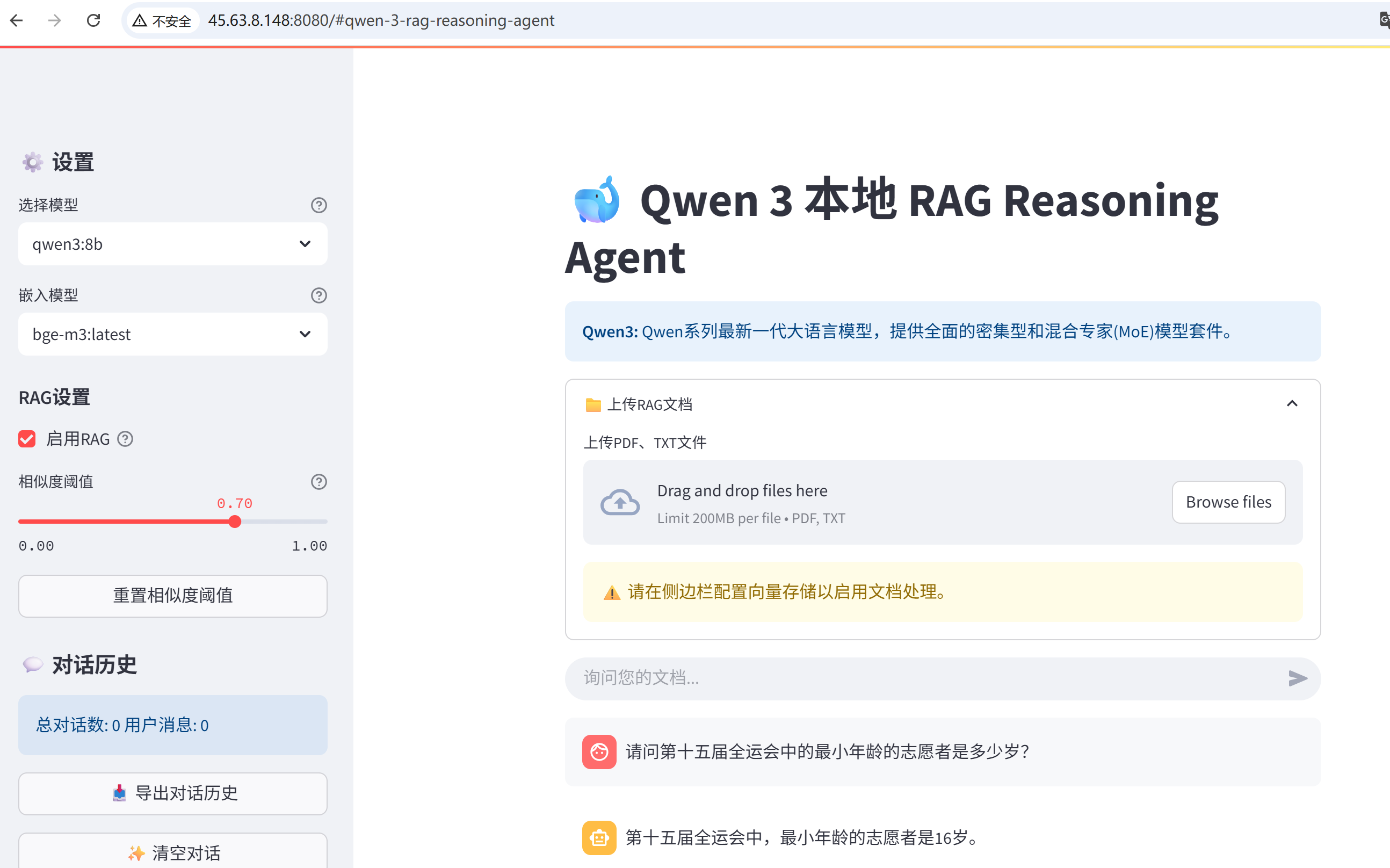
这里上传的知识库是下面内容。
广东赛区,来自全省17个承办地市的3万名志愿者为赛事护航。香港赛区共有1.6万名赛事志愿者服务赛场内外。65岁的陆海豪是一名退休警察,2008年,他曾服务保障北京奥运会香港分赛场。这次赛事来到家门口,他也再次忙碌了起来,每天早上七点到达场馆,一天至少走上2万多步、15公里。
本届全运会,香港志愿者报名创造了历史之最,最终入选的志愿者最小的16岁,最长的已经85岁,大家用行动呼应着全运会的志愿服务口号——“为你,更精彩”。
为了对比测试,这里把RAG去掉,看看是否可以正确回答。
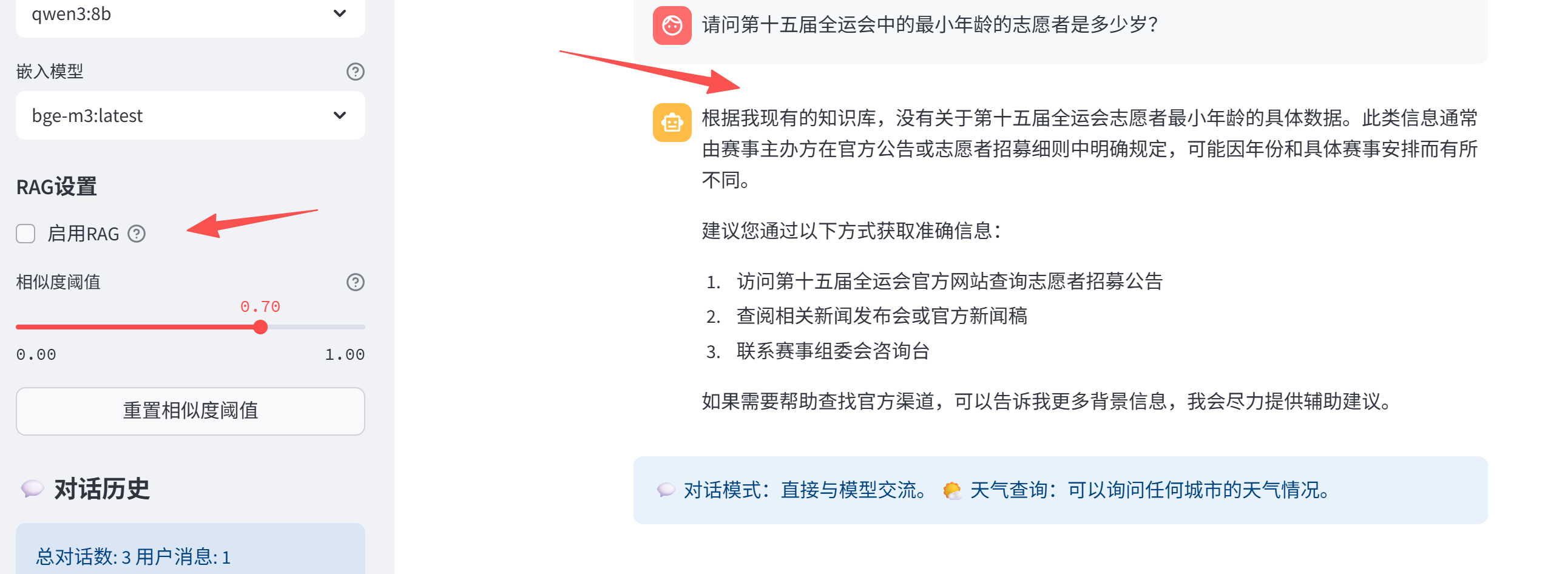
对比发现,我们是可以使用RAG方式回答私有化知识库中的内容。
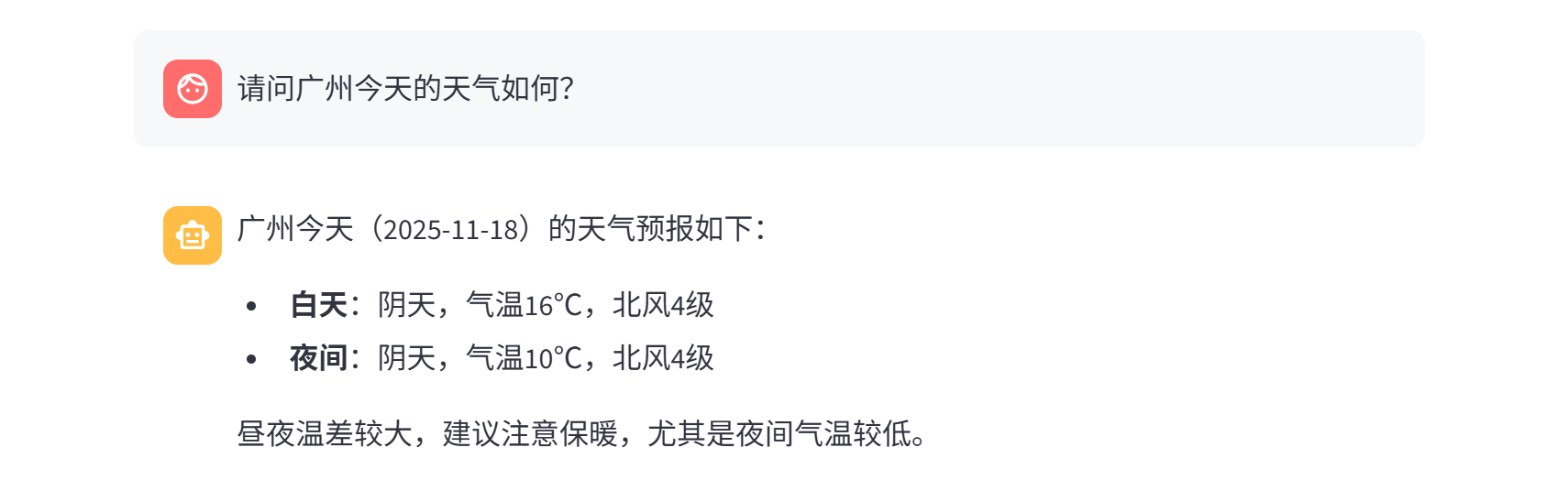
我们还可以询问天气情况,如下所示。
5. 解决报错问题
处理文档时,可能会报下面的错误。
INFO:faiss:Failed to load GPU Faiss: name 'GpuIndexIVFFlat' is not defined. Will not load constructor refs for GPU indexes. This is only an error if you're trying to use GPU Faiss.
解决方法。
pip list | grep faiss
删除faiss-cpu,安装gpu版本。
pip uninstall faiss-cpu
pip install faiss-gpu-cu12
6. 其它

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 23
23 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)