Agent记忆技术及落地实践
本文探讨了Agent记忆模块与Chatbot对话上下文的区别,分析了Agent记忆管理的关键技术方案和实践经验。研究发现,尽管两者都维护上下文,但Agent记忆模块更强调任务执行的连贯性和关键信息提取,而Chatbot侧重意图识别和切换。实践中,短期记忆和长期记忆的解耦设计尤为重要,可结合压缩、裁剪、结构化存储等技术优化上下文管理。当前研究进展包括系统化框架(如Mem0)和自动化学习(如Memor
做agent记忆模块搭建的相关研发工作,一开始认为agent的记忆就是维护上下文,应该和chatbot的对话管理差不多,但真的做一段时间之后,才发现和对话管理相比还是区别比较大的,而且记忆模块对agent的实现效果以及后期可扩展性有比较重要的影响。
agent记忆与chatbot上下文的区别
我们拿agent记忆与chatbot上下文来作下比较,暂且不考虑长期记忆,就拿短期记忆来作对比,短期记忆(工作记忆)主要就是维护上下文,更官方一点的说法就是上下文工程,那chabot的对话管理不是也是在维护上下文吗?那两者有什么区别呢?
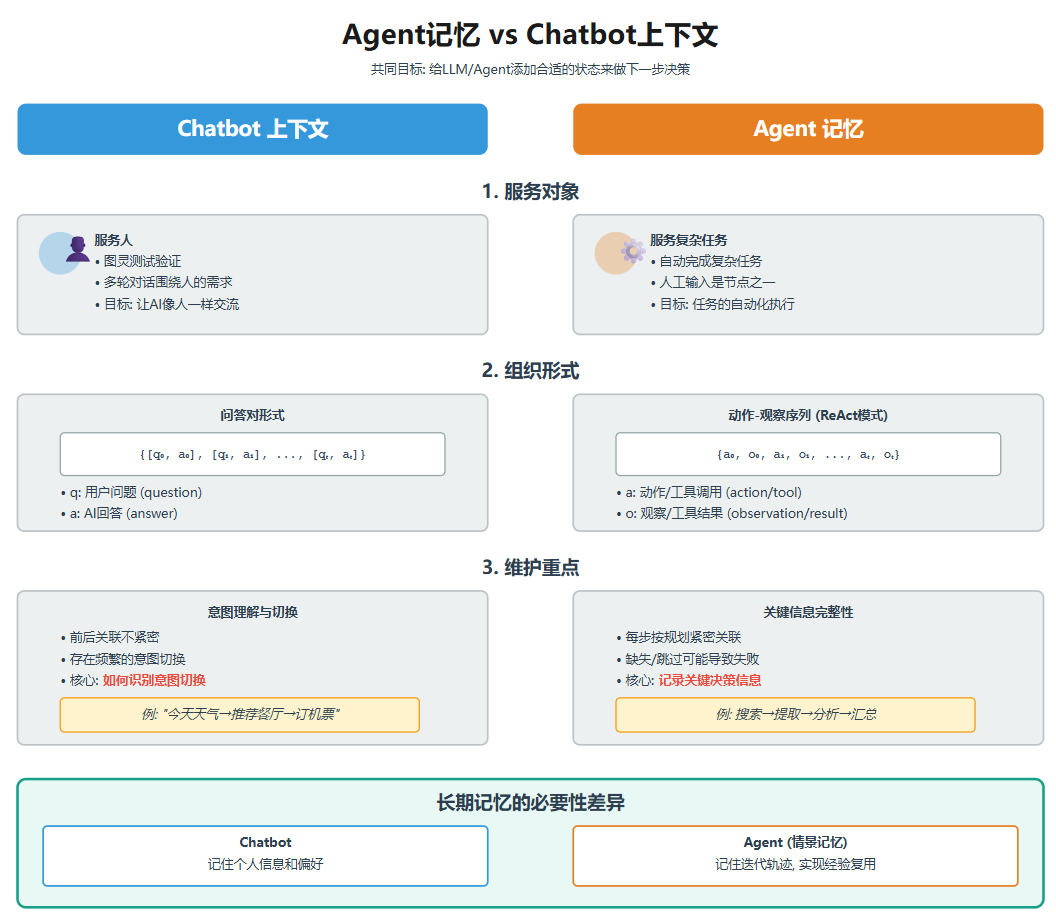
目标
agent记忆和chatbot上下文的目标看上去是一致的:给LLM/agent添加合适的状态来做下一步的决策。但是从服务对象,组织形式和维护重点的扩展来看有比较大的区别。
服务对象
虽然两者都算是人机交互,拿服务的对象都可以算作是人,但从现阶段的主要技术实现来看,服务对象还是存在差异的。
chatbot的服务对象是人这个毋庸置疑,做图灵测试也是为了验证对面和你说话的那个AI,有没有可能骗过你,而从让你以为它是个人,chatbot展开的多轮对话也是围绕人的实际需求展开。
agent虽然也存在与人的交互,agentic workflow中一般也会有人工输入的节点,但现阶段我们搭建agent的主要任务,更多时候是在自动完成一个复杂任务,因此服务对象可以认为是复杂任务。
组织形式
从组织形式上来看,由于agent具备了行动能力,所以和chabot产生了组织形式的不同。
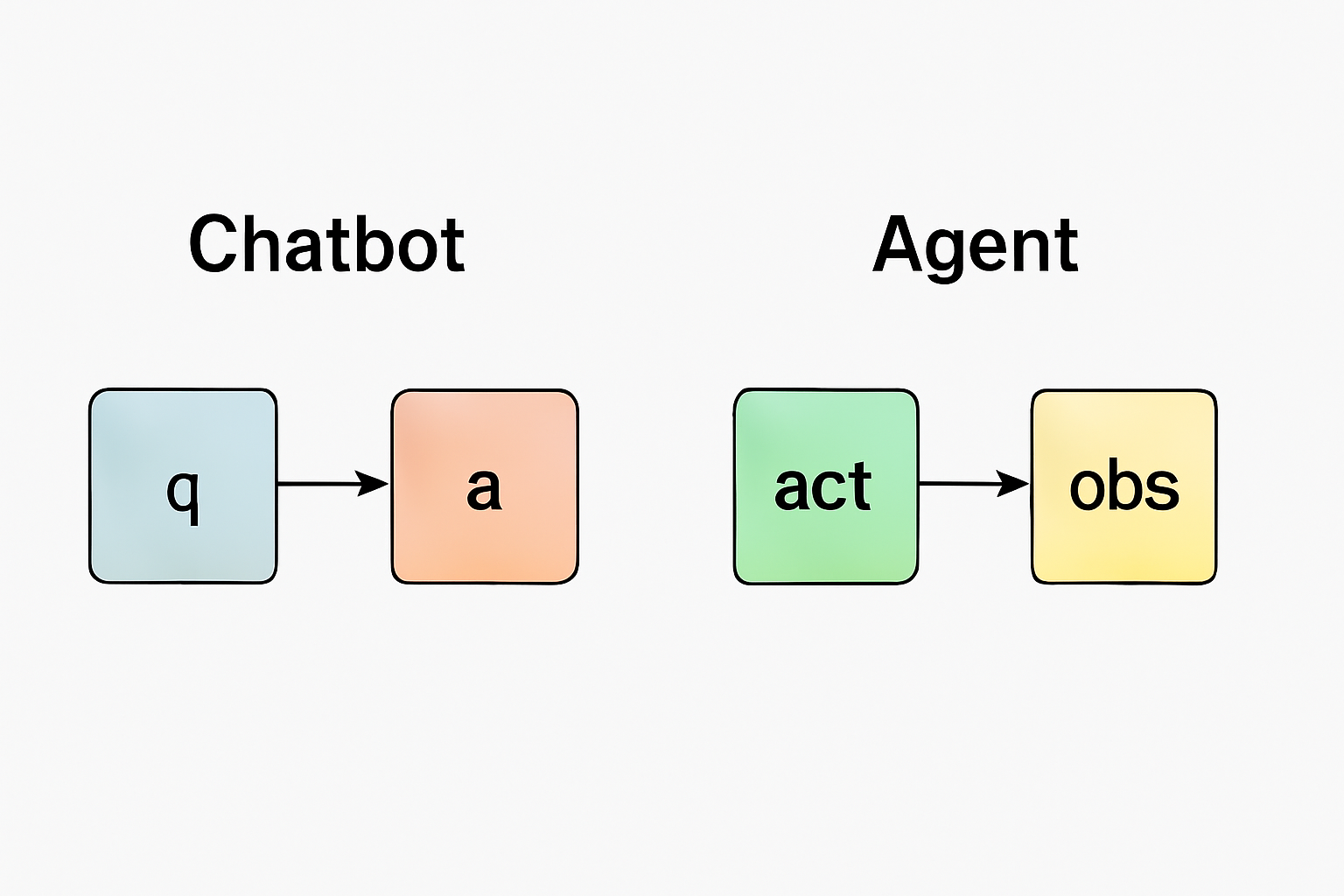
chatbot主要的构成是一问一答的形式,包括我们调用大模型api一般也遵循这个结构,可以表示为{[q0,a0],[q1,a1],...[qt,at]}。
agent记忆的构成以最常见的react模式为例,主要是动作(tool)和动作结果(tool_result)的时序集合,可以表示为{a0,o0,a1,01,...at,ot}。
维护重点
对于记忆和上下文,很重要的一个功能是维护,但维护的侧重点也是有所不同的。
chabot的上下文虽然也存在前后关联,不会每一轮都紧密联系,但会存在频繁的意图切换,如何理解意图并且实现有效的意图切换识别是上下文维护的重点。
而agent记忆的每一个步骤都是按迭代规划进行的,缺失某个步骤或跳过某个步骤都可能会导致任务失败,因此它的维护重点是如何在有限的窗口中记录对下一步决策产生影响的所需关键信息。
另外agent和chatbot还存在一个很大不同的点是长期记忆的必要性。对于chatbot,长期记忆主要是记住个人信息和偏好用于个性化服务。而对于agent,长期记忆需要通过情景记忆来记住之前的迭代轨迹,这样不仅能通过检索的方式来获取与当前决策相关的上下文信息,还可以实现经验复用,在下一次遇到类似任务时,可以将之前的经验作为参考,马普所今年2月份发这篇论文时候就指出情景记忆是当前agent所缺少的[1]。
agent短期记忆-业界技术分享
anthropic
anthropic提到agent在长程任务上的三种管理上下文方式[2]包括:压缩,结构化笔记和采用子agent架构。
压缩通过对上下文关键内容的提取,改写和无关内容删除实现上下文瘦身;
结构化笔记是把关键信息以结构化形式存入笔记,让agent可以阅读到关键信息;
子agent架构则是通过子agent维护自己的独立上下文再将关键结果返回主agent实现上下文解耦。
oepnai
openai的短期记忆管理[3]则是围绕agent sdk来谈到管理短期记忆的两个主要方式:裁剪(trimming)和压缩(summarizing)。
压缩和anthropic的compact是一样的,裁剪就是把旧的历史信息直接剪掉。
trimming的好处是实现比较简单,延时友好而且不会引入偏移信息(相比压缩),但缺点也显而易见,裁剪的内容可能包含当前决策需要的信息,所以一般适用于任务独立,上下文关联不大,低延迟要求场景。
langchain & manus
langchain与manus最近的一次交流[4]提到manus的三种上下文管理方式:reduce context,offload context和isolate context。
reduce context包括将工具执行结果进行压缩放在窗口内,而降完整结果保存在文件系统中,在上下文触发窗口限制时对整个轨迹进行整体压缩;
context isolate类似于anthropic的sub agent方法,但细分为两种方式:对于简单任务main agent通过function call的方式将指令传递给子agent,子agent在自己的窗口执行任务;而对于复杂任务,子agent会和主agent共享上下文。
context offloading和anthropic的结构化笔记虽然都是将内容存入文件,但处理思路不一样。manus的方式是将大多数操作卸载到沙盒层,在沙盒中通过bash工具就可以实现多样化的文件读写操作,这样就可以把工具执行结果保存到文件,在需要时通过bash的grep等查询命令进行访问。另外manus的这个设计相当于把大部分先验知识文件化,让agent按需通过读取文件内容获取先验来指导行动,anthropic的skill实现应该也是类似的思路。
agent记忆-项目实践
初版记忆实现
在实际搭建agent项目时,工具模块,记忆模块,提示词模块是三个重要的基础模块。工具模块和提示词模块相对简单或者说比较成熟的方案,而记忆模块的搭建则有不同的设计思路和实现方式,但核心思路一致 - "给agent提供恰当的上下文",但难就难在"恰当",首先受限于LLM的上下文窗口,所以累计上下文就不能过长。
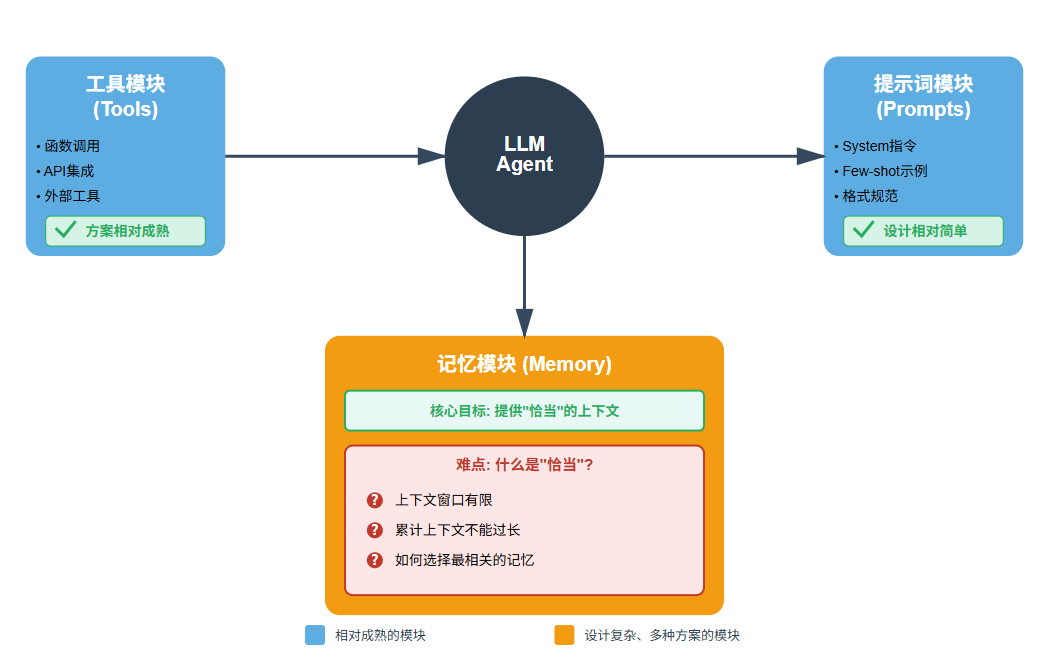
另外上下文中堆积无关或者重复的内容不但会影响推理规划,也是不经济的。还有一个重要原因是上下文中的内容对于agent来说不是等权重的,对于当前决策而言,有的内容相对其它内容就会更重要,类似于需要一个attention机制来选择关键信息,那以什么形式来管理上下文获取更相信的信息加入就尤为关键了。
在近期的一个agent项目实践中,实现记忆模块的初始版本,设定的原则是"状态是记忆的投影",以记忆作为事实的唯一来源,同时要求不在agent中维护状态,把记忆事实作为状态来源,放入agent的上下文中让agent自己进行决策。思路看上去是没有问题,但实际测试后就发现想简单了。
对于agent而言本身依赖的LLM是无状态的,所以agent也可以认为是无状态的,但是记忆的目的就是为了让agent具有状态。在初版的实现里,每一轮迭代都把obs写入工作记忆,同时读取当前轮之前的工作记忆中的结构化历史信息,把obs作为上下文唯一来源,直接注入到下一轮迭代的上下文,这样做是比较省事,但是一旦agent内部迭代出现问题,因为obs和工作记忆之间的这种耦合设计,很难追溯问题来源。
第二版记忆重构优化
在发现第一版的问题后,开始进行第二版改进。第二版的改进主要是基于看到的相关的技术博客和论文,重新设计了记忆方案。首先记忆模块的目录设计应该把短期记忆和长期记忆做清晰分划分,维护当前agent迭代执行任务所需上下文的就是短期记忆(工作记忆),而记录完整迭代过程的是长期记忆(情景记忆),产生对应产出的也是长期记忆(语义记忆)。其中比较容易混淆的是工作记忆和情景记忆,从持久化的角度来说,把工作记忆持久化存储就可以理解为情景记忆,但实际上是存在差别的。
对于一个agent的迭代轨迹{a0,o0,a1,o1,...at,ot},可以直接把这个迭代轨迹放入上下文,也可以对这个迭代轨迹的每一步进行摘要提取,仅保留关键信息和引用,比如某步生成了一个很大的结构化json,在进入下一轮时没有必要把整个json全部放入上下文,可以只放入一个引用,但是会把完整的json存入情景记忆,在下一轮迭代使用这个引用时再从情景记忆中取出这个对应的json,这样能避免大段内容直接进入到上下文中。
同时还需要考虑到上下文长度限制和成本问题,一般的工作记忆还会考虑使用最近k轮的策略,上下文只保留最近k轮的迭代记录,但是全局信息以结构化的信息记录,把这个结构化信息也注入到上下文中,这样也不至于让agent丢失掉全局信息。而第一版的问题就在这里,状态不应该只是记忆的投影,状态是对记忆的删减和加工,实际上的改进就是在短期记忆和长期记忆之间加一个桥接适配层,来实现短期记忆和长期记忆的搭配使用。
而为了agent项目的阶段性扩展和迭代,在前期工程化实现时就应该考虑长期记忆。在一个agent的迭代循环里,如果迭代轮数比较长,上下文窗口和LLM的上下文利用效率已经开始明显下降,就需要考虑结合长期记忆使用了。而为了缩减上下文,在删减掉比较早期的迭代信息后,需要识别出长期记忆中已保存的迭代记录中,哪些记忆内容会对当前轮决策有用,就选择加入到上下文。这个一般会使用retrival的方法,从长期记忆中进行检索。技术实现上会结合结构化和向量检索,而实际的实践需要根据场景需求去做设计和调整记忆存储和读写方式,可以使用slot,sql数据库,向量数据库,图数据库等等。
实践过程汇总有一个原则可以参考:记忆模块在开始实现之初,就应该把短期记忆和长期记忆进行解耦设计,这不但为上下文管理留有比较大的优化空间,在符合可审计性原则之外还为经验复用和未来可能的RL微调积累数据基础。
同时第二版的改进上,还有一个比较重要的改进点是还原了obs的单纯职责,obs只应该对当前轮的act和执行结果进行记录,不应该注入历史内容,obs保持职责单一只把当前轮的执行和执行结果(或摘要)放到工作记忆,工作记忆再去通过记忆模块补充历史上下文,这样修改之后,obs和工作记忆的职责也分的比较清晰了。
另外在agent的工层化实现过程中,造成可审计比较困难的一个点就是对工程化实现过程的不同组件的职责理解和划分不清晰,一旦出了bug,bug溯因就会因为这种不清晰的边界设计增加debug的难度,所以需要在设计之初就厘清不同模块的边界再动手进行实现。
agent记忆相关研究进展
上面提到RL微调,就再展开谈一下在agent在记忆管理方向的相关研究。agent记忆管理是一个很复杂的问题,从工程角度来看,agent的记忆管理可以分为两类技术方案,一种将复杂问题简化,另外一种是自动化。目前相关的记忆研究在这两个方向论文也比较多,找到了几篇比较有代表性的论文。前者是提供系统化/可插拔的记忆管理底座框架,如mem0[5],A-MEM[6],后者是将手动/规则维护记忆的方式转为自动化,如Memory‑R1[7],MEM1[8],Memp[9], MEMSearcher[10]等。
系统化框架方向
1. Mem0
Mem0的核心目标是提供一个生产级的记忆管理框架,能够动态地从对话中提取、整合和检索关键信息。
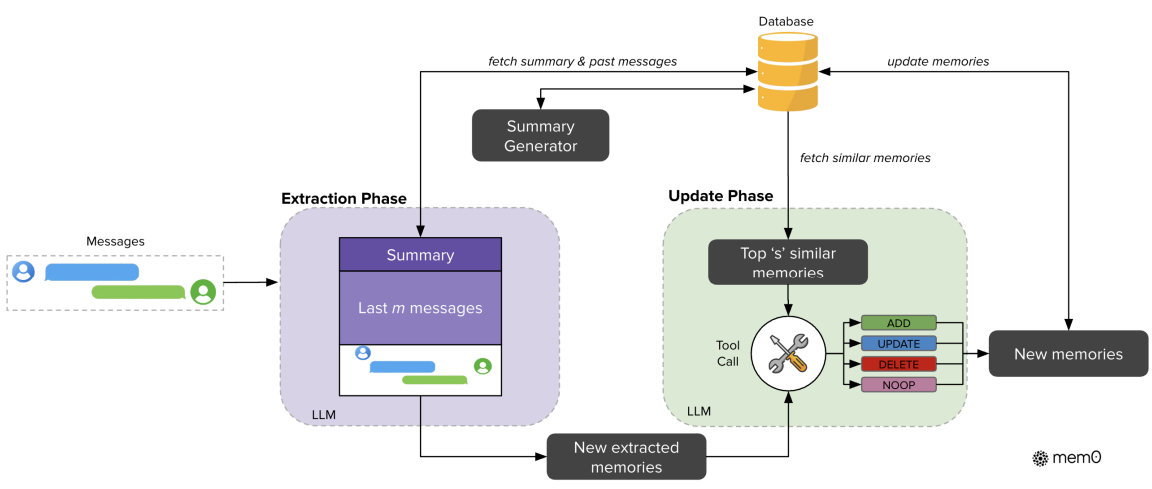
Mem0支持多层次的记忆管理,包括用户级、会话级和Agent级三个层面。系统会通过LLM自动从对话中提取记忆,并智能处理记忆冲突。特别是它基于grapg存储的图增强版本Mem0ᵍ,将记忆组织为知识图谱,以实体-关系三元组的形式存储,这让系统能够捕捉更复杂的多跳关系。从工程角度看,Mem0已经构建的比较成熟,提供了API服务,并集成了LangChain、CrewAI等主流agent框架。
在LOCOMO基准测试上,Mem0相比OpenAI Memory的准确率提升了26%,相比将全部上下文都送入模型的做法,P95延迟降低了91%,token使用量减少了90%。Mem0在保持高准确率的同时,显著提升了效率。Mem0目前在很多agent项目中也是使用比较多的。
2. A-MEM
A-MEM的设计灵感来自Zettelkasten[11]笔记法,是一种通过原子化笔记和灵活链接来构建知识网络的方法论。
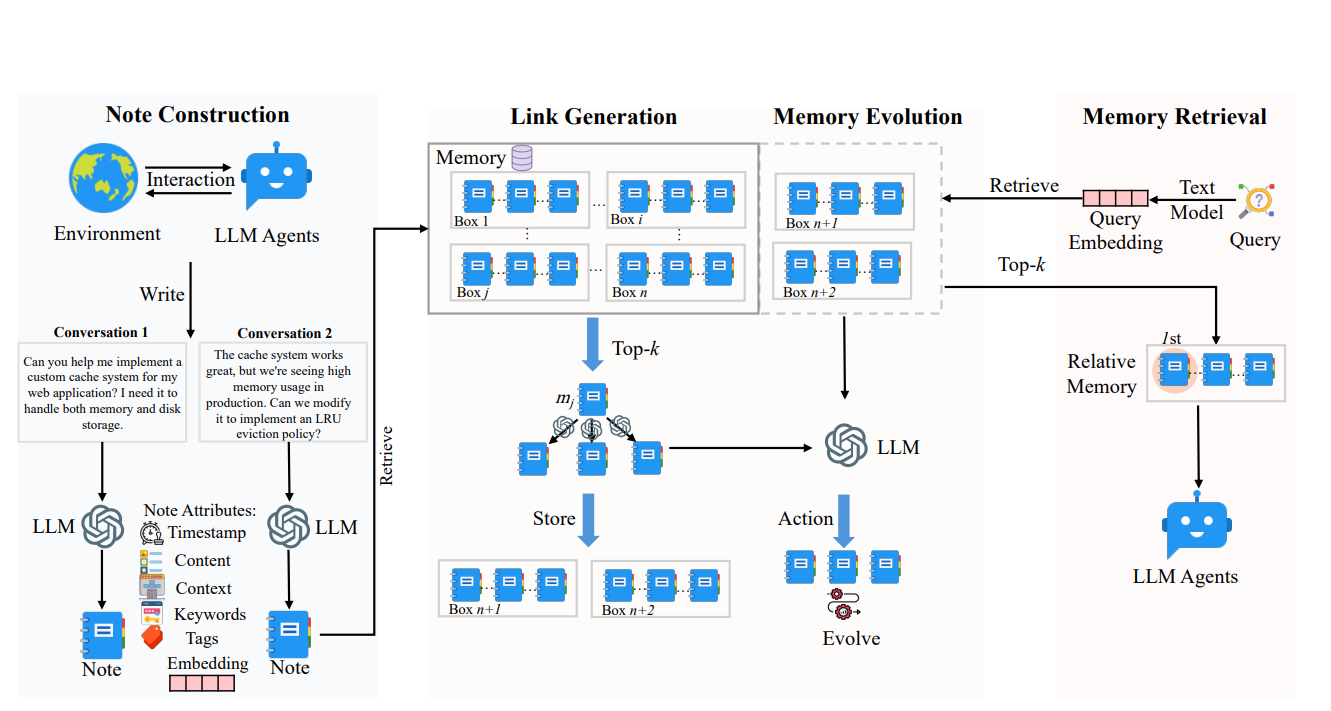
A-MEM将每条记忆组织成包含多个属性的"原子笔记",包括上下文描述、关键词、标签等结构化信息。当新记忆加入时,系统会自动分析它与历史记忆之间的关联,建立有意义的连接。比较有意思的是A-MEM的记忆演化机制:新记忆的加入可能触发对旧记忆的更新,让整个记忆网络持续精炼自己的理解。这种设计让记忆系统不依赖预定义的固定操作,而是能灵活适应不同类型的任务。
在性能上,A-MEM在多跳推理任务中表现突出,效果是基线方法的两倍以上。同时它的记忆使用效率很高,通常只需要1200到2500个tokens,低于作比较的MemGPT需要的16900 个tokens。
自动学习方向
3. Memory-R1
Memory-R1算是第一个真正用强化学习训练agent主动管理外部记忆的框架,论文发表于2025年。它的核心思路是把记忆管理归类为一个决策问题,应该通过任务最终结果的奖励信号来学习,而不是依赖人工设计的规则。
系统包含两个专门的agent。Memory Manager负责学习执行结构化的记忆操作,包括添加、更新、删除或保持不变。Answer Agent则实现了一个"记忆蒸馏"策略,从检索到的大量记忆中筛选出最相关的部分用于回答。这两个agent都通过PPO和GRPO算法进行outcome-driven的强化学习训练。
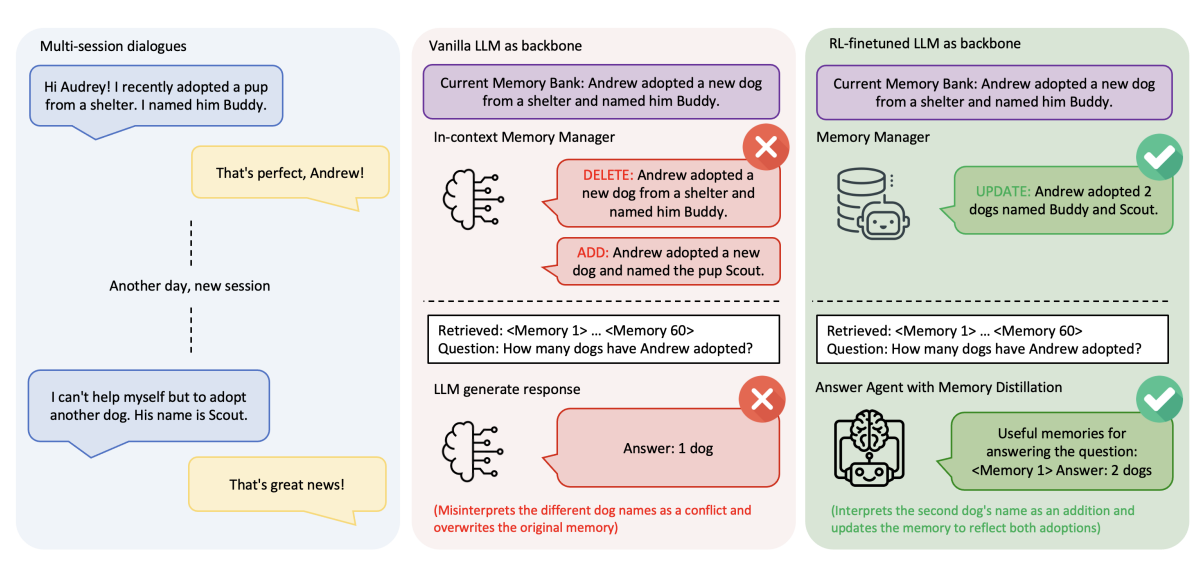
Memory-R1的数据效率很高,仅用152个问答对就能达到最优性能,因为它直接优化任务结果,不需要为每个记忆操作标注正确答案。论文中举了个生动的例子:用户先说"我养了只狗叫Buddy",后来又说"我又养了只狗叫Scout"。普通系统会误判这是矛盾,执行删除再添加,导致第一条记忆丢失。而训练过的Memory-R1会执行更新操作,将两条信息整合为"养了两只狗,Buddy和Scout"。在LOCOMO基准上,Memory-R1的F1分数达到24.91,并且在LLaMA-3.1和Qwen-2.5等不同模型上都展现出良好的泛化能力。
4.MEM1
这项工作提出了一个比较独特的视角:将记忆整合与推理统一起来,让agent在推理过程中自然地完成记忆管理。
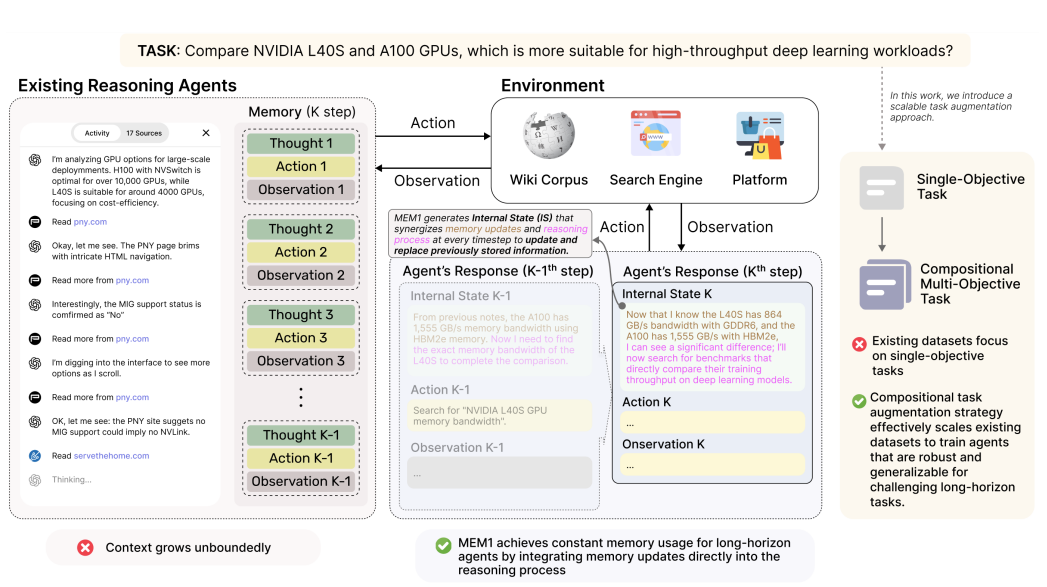
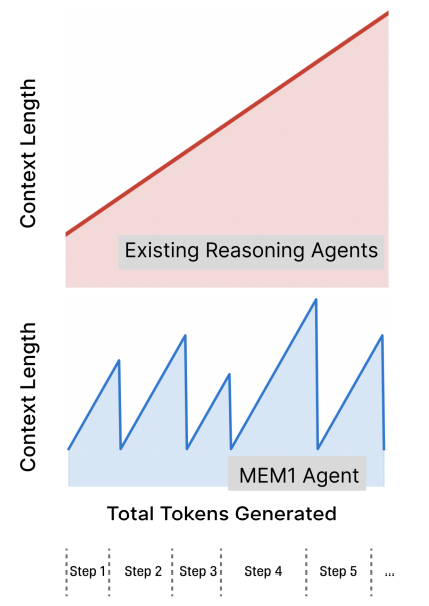
MEM1的一个创新点是把推理本身视为"工作记忆"。在与环境交互的过程中,agent的推理链会提取关键信息,构建对问题的演进理解。使用XML风格的标签来显式标注不同组件:用表示内部推理状态,表示向环境的查询,表示agent的回答,表示外部观察结果。通过迭代的状态更新,MEM1只保留最新的完整状态集合,旧的工具输出则可以丢弃(anthropic也有类似的上下文维护策略),有效减轻上下文增长压力。
在训练时,MEM1使用多目标任务,相比担任训练,多任务训练需要更多轮次的交互才能实现收敛,从而迫使模型学会高效的记忆管理。实验结果显示,MEM1的token消耗比较稳定,不会随着任务复杂度增长而快速增长,推理速度也更快。这让它特别适合长期web导航、多跳问答等需要持续环境交互的场景。
5. Memp
Memp探索的是程序性记忆(procedural memory)在agent中的作用。程序性记忆在人类认知中指的是"如何做"的知识,比如骑自行车、打字等通过练习变得自动化的技能。
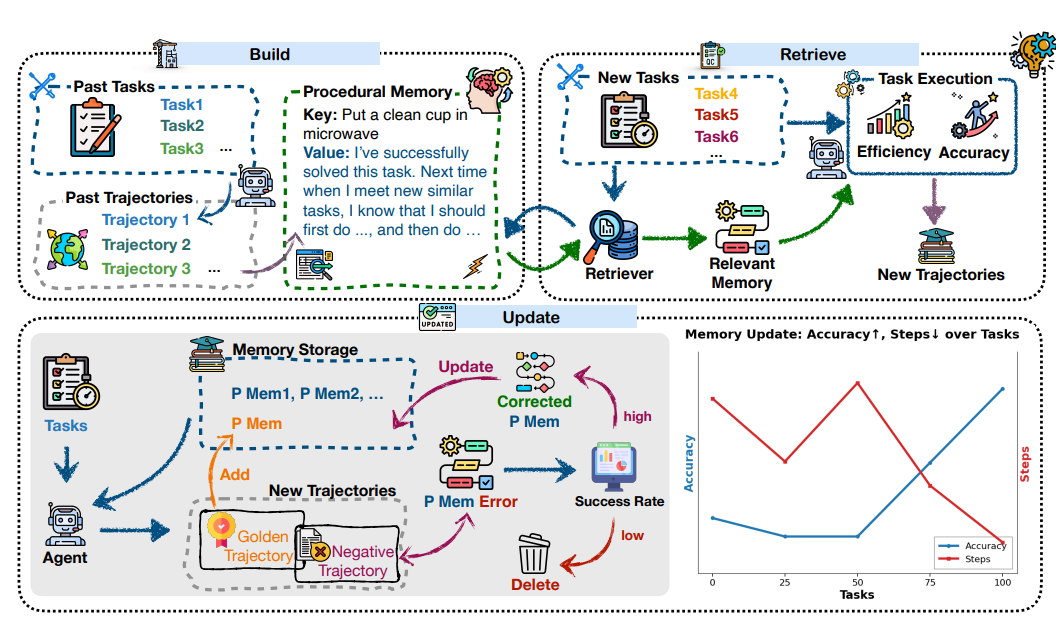
Memp设计了一个三阶段的循环机制。首先是构建阶段,系统从agent过去的行为轨迹中提炼记忆,既可以存储为细粒度的逐步操作指令,也可以抽象为高层次的脚本式表示。然后是检索阶段,当面对新任务时,agent会搜索记忆库找出最相关的过去经验作为起点,这比随机尝试要高效得多。最后再是更新阶段,agent可以反思失败案例,(www.tvmkv.com)修正和修订原始记忆。
Memp的更新策略很灵活,可以简单地添加新经验,也可以只保留成功案例,还可以反思失败进行修正。通过持续的更新、纠错和淘汰过时内容,记忆库会随着经验的积累而演化。另外Memp还发现记忆可以跨模型迁移:用GPT-4o生成的程序性记忆可以直接给Qwen2.5使用,显著提升小模型的性能,这对降低部署成本有一些启发意义。在TravelPlanner和ALFWorld任务上,随着记忆库的精炼,agent的成功率稳步提升,效率也明显优化。
6.MemSearcher
这是最近一周国科大联合小红书刚发表的新工作,专门针对搜索agent的记忆管理问题,实现了agent推理,工具调用和记忆管理的联合优化。
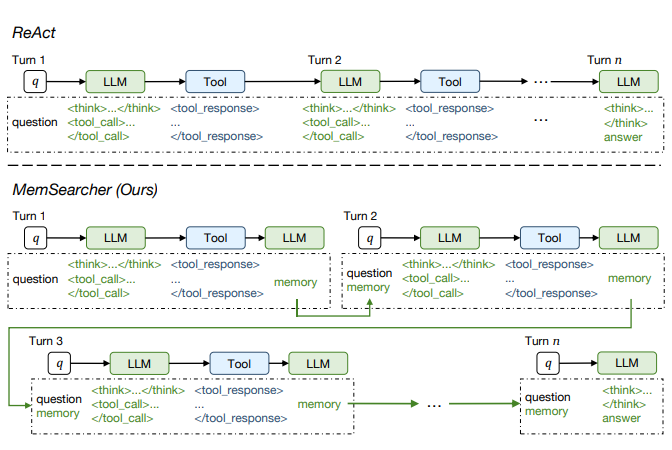
现阶段的搜索agent面临一个两难困境:如果把完整的交互历史都拼接到上下文中,虽然保持了信息完整性,但会产生又长又嘈杂的上下文,导致计算和内存成本飙升;如果只使用当前轮次的信息,虽然避免了开销,但丢失了关键的历史信息。这种权衡限制了搜索agent的可扩展性。这个问题前文也提到过,说明工业实践和学术研究都在研究解决这个问题。
MemSearcher提出了一个比较有意思的解决方案:在多轮交互过程中迭代维护一个紧凑的记忆,并在每轮将它与当前问题结合。具体工作流程是,每一轮MemSearcher首先将用户问题与记忆融合,生成推理轨迹并执行搜索动作,然后根据新的观察结果更新记忆,只保留对解决任务至关重要的信息。这种设计让上下文长度在多轮交互中保持稳定,在不牺牲准确性的前提下提升了效率。
为了优化这个工作流,研究者引入了multi-context GRPO,这是一个端到端的强化学习框架,能够联合优化MemSearcher的推理能力、搜索策略和记忆管理。Multi-context GRPO会在不同上下文下采样多组轨迹,并在所有对话中传播轨迹级别的优势信号。
在性能表现上,MemSearcher使用与Search-R1相同的训练数据,在7个公开基准测试上取得了显著提升:基于Qwen2.5-3B的版本平均相对增益11%,基于Qwen2.5-7B的版本增益12%。还有一点值得注意,3B参数的MemSearcher甚至超过了7B参数的基线模型,这说明在信息完整性和效率之间找到了一个合适的平衡点,能够同时带来更高的准确率和更低的计算开销。
结语
通过一段时间的项目实践和agent学术研究的学习,可以明显的感受agent已经成为构建数字生产力的重要技术路径,它的主要突破在于,本身贴合强化学习理念的"行动-反馈"机制与大模型的推理能力的配合使用,实现了“1+1>>2”的组合效应。在LLM持续推高推理能力,工具连接逐步完善的同时,agent还比较缺失的两个环节,一个是现实世界的应用,这需要依赖世界模型和具身智能的突破,另外一个就是记忆,人类的记忆是非常精妙的设计,回忆遗忘都是如此的自然,但是要实现这样高效、健壮的记忆,还有很长一段路要走,这不但是追求更高智能的基础需求,也是让agent在更广泛,更复杂任务场景发挥价值所必须的。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)