CANN在昇腾NPU上的落地实践与图像分类加速应用
通过本次落地实践可以看出,CANN 不仅解决了异构硬件适配和性能调优的行业痛点,还显著提升了端云一体的 AI 开发效率。开发者无需过多关注底层硬件细节,即可专注于模型创新和业务逻辑的优化,实现“高性能算力即开即用”的目标。
前言
随着大模型应用的普及和多样化推理场景的兴起,AI 算力的供给与利用效率正成为产业发展的关键问题。为应对这一挑战,华为推出了 CANN(Compute Architecture for Neural Networks) —— 一套面向 AI 领域的端云统一异构计算架构。CANN 以性能优化为核心设计目标,通过统一算子抽象、图级优化、混合精度计算以及端云一体化的开发工具链,有效提升模型在昇腾硬件上的运行效率,并显著降低开发与迁移成本。
本报告以图像分类任务为示例,完整展示了从 PyTorch GPU 训练脚本迁移到昇腾 NPU 的实践过程,涵盖训练、推理、性能监控与精度验证等环节。实验结果表明,CANN 能够在保持模型精度的同时,充分挖掘底层硬件潜能,并将复杂的算子优化与资源调度过程对开发者透明化。这不仅简化了 AI 应用的开发流程,也为模型高效部署与算力最大化利用提供了可行方案。
一.AI算力的基石
1.1 什么是CANN?

CANN 是面向昇腾(Ascend)系列硬件的统一计算架构与软件栈集合,核心能力包括:
-
异构计算统一抽象:对算子、内存、并行、调度进行统一建模,屏蔽硬件差异。
-
高性能算子库:覆盖主流深度学习与传统数值计算算子,针对昇腾架构深度优化。
-
工具链与编译器:提供图级优化、算子融合、量化与静态/动态编译能力,适配训练与推理。
-
生态适配:面向 PyTorch/TensorFlow/MindSpore 等主流框架提供迁移与部署通道。
简言之,CANN 以“架构 + 算子 + 编译 + 工具”的组合拳,将模型计算映射到昇腾硬件的峰值效率。
1.2 为什么需要CANN?—— 解决的行业痛点
在 AI 模型落地过程中,开发者往往会面临多重现实痛点:通用深度学习框架在异构硬件上难以充分发挥算力潜能,性能优化常常卡在“天花板”;模型从训练到部署的迁移需要大量手动适配,工程成本高且容易出现性能断层;调优经验又分散在脚本和实验笔记中,无法沉淀形成可复用的方法体系;

同时,端侧设备、单机服务器到大规模集群之间缺乏一致的开发与部署体系,导致业务难以统一演进。CANN 的价值,正是在于通过统一算子抽象、系统级编译优化与端云一体的工具链,将高性能变成默认结果,使开发者不再为“如何跑快”焦虑,而能把精力更多投入模型创新和业务设计本身。
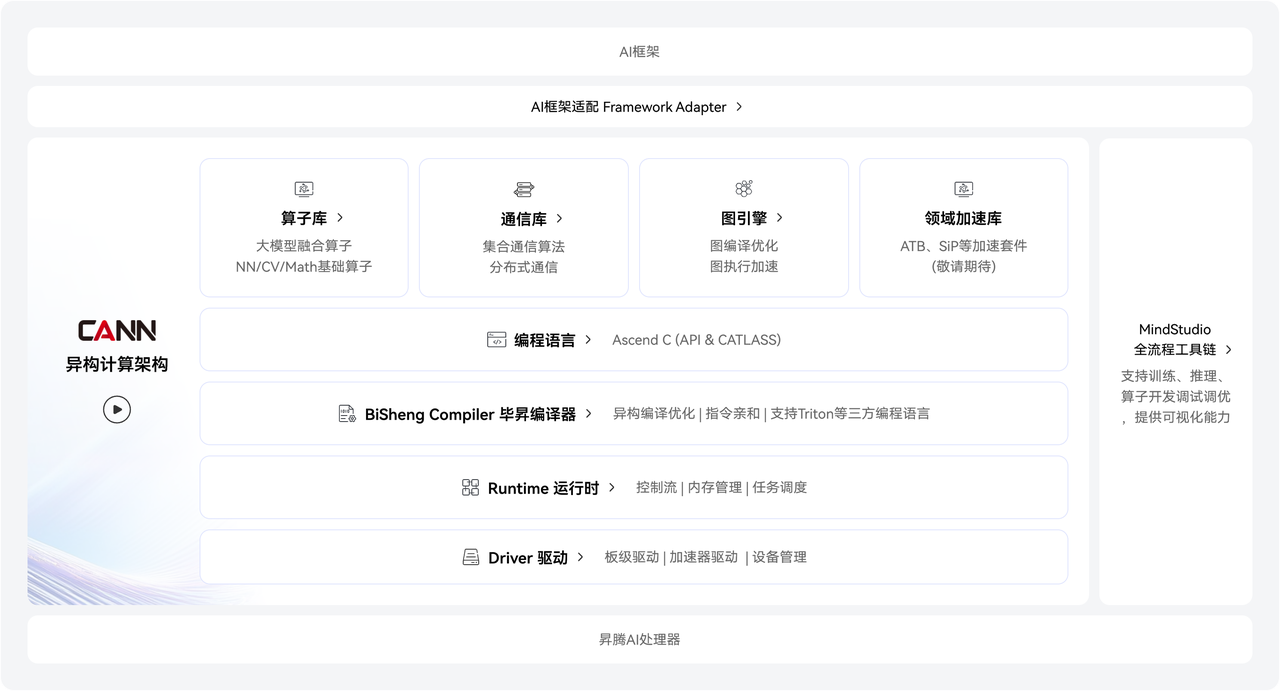
1.3 CANN在AI全栈中的位置
昇腾推理与训练软件栈整体位于深度学习“框架”与“硬件”之间,向上承接 PyTorch、TensorFlow、MindSpore 等模型表达,并通过模型转换(OM)与框架适配完成算法到硬件执行的映射;向下则对接昇腾 NPU/Atlas 等硬件。在运行时层面,依托 Ascend Driver、Runtime 和 ACL 提供基础算子与任务调度能力;

在编译优化层进行图优化、算子融合、内存复用以及并行策略调度,实现计算与数据通路的高效组织;同时配套 ATC 模型编译工具、Profiling/调试工具、MindStudio 与可视化性能分析工具,构成完整的开发、调试和优化生态体系,从而使模型能以高效方式在昇腾硬件上运行。
二.深度剖析CANN的核心技术
在算子层面,通过对卷积、GEMM、归一化与激活等核心算子进行指令级和数据通路级调优,包括向量化、流水线并行、访存对齐和片上缓存复用,最大化硬件执行效率;在图级优化方面,通过跨算子融合(如 Conv+BN+ReLU、MatMul+Bias+Activation)减少中间张量落地与全局内存访问,从而显著降低带宽压力;
在内存与调度侧,采用静态内存规划和生命周期分析,以流水化与并行调度策略充分提升片上与片外带宽利用率及算力并发;同时,在可控精度损失的前提下,引入混合精度和量化策略进一步压缩延迟与功耗。整体遵循“编译期为主、运行期为辅”的优化路径,使通用模型在默认执行链路下即可获得可观加速效果。

三.图像分类任务实战落地——CANN的性能提升
本节以经典图像分类模型 ResNet-50 为例,完整演示从 PyTorch GPU 训练脚本 到 昇腾 NPU 环境可运行脚本 的迁移流程。通过 PyTorch GPU2Ascend 工具,可以在不大幅度修改原代码的情况下,实现训练脚本快速迁移,并在昇腾 NPU 环境中运行,从而显著提升开发效率。
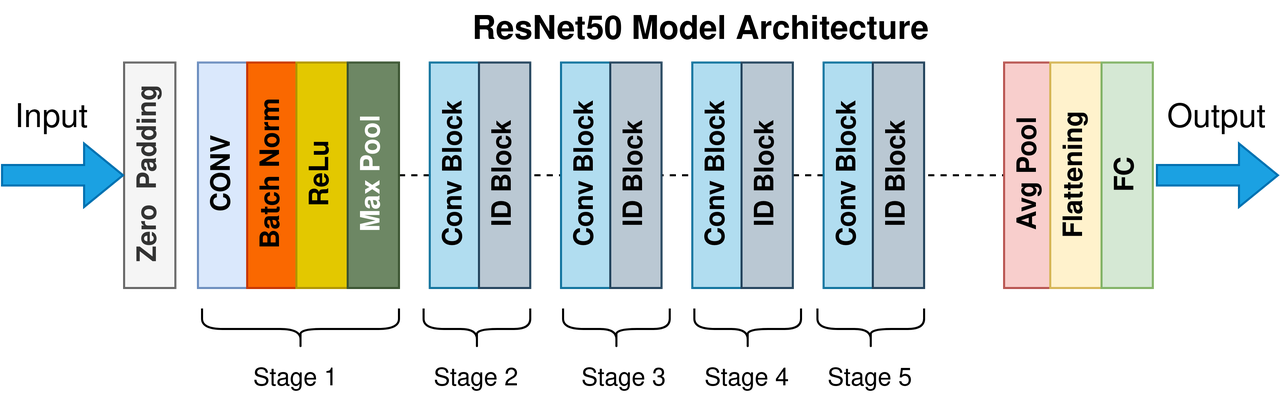
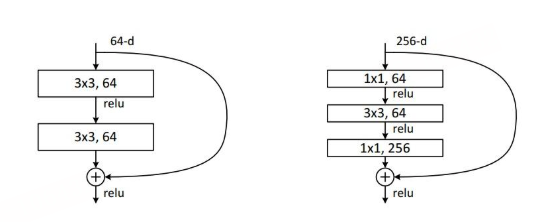
ResNet 的设计理念与 Highway Network 十分相似,都允许原始输入信息直接传递到后续的网络层,这一机制被称为残差模块。在 ResNet 中,残差模块主要有两种结构形式,以 50 层作为一个划分标准,具体结构在原论文中进行了详细定义。
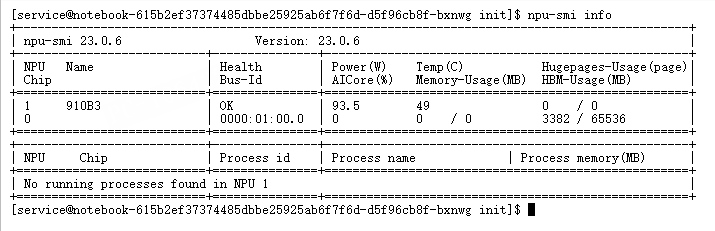
3.1 环境准备与搭建
1.原始 PyTorch GPU 训练脚本
先创建一个 pytorch_main.py 的训练文件,内容为标准 PyTorch GPU 环境下的 ResNet-50 训练脚本。可直接从已有 GPU 工程中复制或下载样例训练文件。
import argparse
import os
import random
import shutil
import time
import warnings
from enum import Enum
import torch
import torch.backends.cudnn as cudnn
import torch.distributed as dist
import torch.multiprocessing as mp
import torch.nn as nn
import torch.nn.parallel
import torch.optim
import torch.utils.data
import torch.utils.data.distributed
import torchvision.datasets as datasets
import torchvision.models as models
import torchvision.transforms as transforms
from torch.optim.lr_scheduler import StepLR
from torch.utils.data import Subset
model_names = sorted(name for name in models.__dict__
if name.islower() and not name.startswith("__")
and callable(models.__dict__[name]))
parser = argparse.ArgumentParser(description='PyTorch ImageNet Training')
parser.add_argument('data', metavar='DIR', nargs='?', default='imagenet',
help='path to dataset (default: imagenet)')
parser.add_argument('-a', '--arch', metavar='ARCH', default='resnet18',
choices=model_names,
help='model architecture: ' +
' | '.join(model_names) +
' (default: resnet18)')
parser.add_argument('-j', '--workers', default=4, type=int, metavar='N',
help='number of data loading workers (default: 4)')
parser.add_argument('--epochs', default=90, type=int, metavar='N',
help='number of total epochs to run')
parser.add_argument('--start-epoch', default=0, type=int, metavar='N',
help='manual epoch number (useful on restarts)')
parser.add_argument('-b', '--batch-size', default=256, type=int,
metavar='N',
help='mini-batch size (default: 256), this is the total '
'batch size of all GPUs on the current node when '
'using Data Parallel or Distributed Data Parallel')
parser.add_argument('--lr', '--learning-rate', default=0.1, type=float,
metavar='LR', help='initial learning rate', dest='lr')
parser.add_argument('--momentum', default=0.9, type=float, metavar='M',
help='momentum')
parser.add_argument('--wd', '--weight-decay', default=1e-4, type=float,
metavar='W', help='weight decay (default: 1e-4)',
dest='weight_decay')
parser.add_argument('-p', '--print-freq', default=10, type=int,
metavar='N', help='print frequency (default: 10)')
parser.add_argument('--resume', default='', type=str, metavar='PATH',
help='path to latest checkpoint (default: none)')
parser.add_argument('-e', '--evaluate', dest='evaluate', action='store_true',
help='evaluate model on validation set')
parser.add_argument('--pretrained', dest='pretrained', action='store_true',
help='use pre-trained model')
parser.add_argument('--world-size', default=-1, type=int,
help='number of nodes for distributed training')
parser.add_argument('--rank', default=-1, type=int,
help='node rank for distributed training')
parser.add_argument('--dist-url', default='tcp://224.66.41.62:23456', type=str,
help='url used to set up distributed training')
parser.add_argument('--dist-backend', default='nccl', type=str,
help='distributed backend')
parser.add_argument('--seed', default=None, type=int,
help='seed for initializing training. ')
parser.add_argument('--gpu', default=None, type=int,
help='GPU id to use.')
parser.add_argument('--multiprocessing-distributed', action='store_true',
help='Use multi-processing distributed training to launch '
'N processes per node, which has N GPUs. This is the '
'fastest way to use PyTorch for either single node or '
'multi node data parallel training')
parser.add_argument('--dummy', action='store_true', help="use fake data to benchmark")
best_acc1 = 0
def main():
args = parser.parse_args()
if args.seed is not None:
random.seed(args.seed)
torch.manual_seed(args.seed)
cudnn.deterministic = True
cudnn.benchmark = False
warnings.warn('You have chosen to seed training. '
'This will turn on the CUDNN deterministic setting, '
'which can slow down your training considerably! '
'You may see unexpected behavior when restarting '
'from checkpoints.')
if args.gpu is not None:
warnings.warn('You have chosen a specific GPU. This will completely '
'disable data parallelism.')
if args.dist_url == "env://" and args.world_size == -1:
args.world_size = int(os.environ["WORLD_SIZE"])
args.distributed = args.world_size > 1 or args.multiprocessing_distributed
if torch.cuda.is_available():
ngpus_per_node = torch.cuda.device_count()
if ngpus_per_node == 1 and args.dist_backend == "nccl":
warnings.warn("nccl backend >=2.5 requires GPU count>1, see https://github.com/NVIDIA/nccl/issues/103 perhaps use 'gloo'")
else:
ngpus_per_node = 1
if args.multiprocessing_distributed:
# Since we have ngpus_per_node processes per node, the total world_size
# needs to be adjusted accordingly
args.world_size = ngpus_per_node * args.world_size
# Use torch.multiprocessing.spawn to launch distributed processes: the
# main_worker process function
mp.spawn(main_worker, nprocs=ngpus_per_node, args=(ngpus_per_node, args))
else:
# Simply call main_worker function
main_worker(args.gpu, ngpus_per_node, args)
def main_worker(gpu, ngpus_per_node, args):
global best_acc1
args.gpu = gpu
if args.gpu is not None:
print("Use GPU: {} for training".format(args.gpu))
if args.distributed:
if args.dist_url == "env://" and args.rank == -1:
args.rank = int(os.environ["RANK"])
if args.multiprocessing_distributed:
# For multiprocessing distributed training, rank needs to be the
# global rank among all the processes
args.rank = args.rank * ngpus_per_node + gpu
dist.init_process_group(backend=args.dist_backend, init_method=args.dist_url,
world_size=args.world_size, rank=args.rank)
# create model
if args.pretrained:
print("=> using pre-trained model '{}'".format(args.arch))
model = models.__dict__[args.arch](pretrained=True)
else:
print("=> creating model '{}'".format(args.arch))
model = models.__dict__[args.arch]()
if not torch.cuda.is_available() and not torch.backends.mps.is_available():
print('using CPU, this will be slow')
elif args.distributed:
# For multiprocessing distributed, DistributedDataParallel constructor
# should always set the single device scope, otherwise,
# DistributedDataParallel will use all available devices.
if torch.cuda.is_available():
if args.gpu is not None:
torch.cuda.set_device(args.gpu)
model.cuda(args.gpu)
# When using a single GPU per process and per
# DistributedDataParallel, we need to divide the batch size
# ourselves based on the total number of GPUs of the current node.
args.batch_size = int(args.batch_size / ngpus_per_node)
args.workers = int((args.workers + ngpus_per_node - 1) / ngpus_per_node)
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.gpu])
else:
model.cuda()
# DistributedDataParallel will divide and allocate batch_size to all
# available GPUs if device_ids are not set
model = torch.nn.parallel.DistributedDataParallel(model)
elif args.gpu is not None and torch.cuda.is_available():
torch.cuda.set_device(args.gpu)
model = model.cuda(args.gpu)
elif torch.backends.mps.is_available():
device = torch.device("mps")
model = model.to(device)
else:
# DataParallel will divide and allocate batch_size to all available GPUs
if args.arch.startswith('alexnet') or args.arch.startswith('vgg'):
model.features = torch.nn.DataParallel(model.features)
model.cuda()
else:
model = torch.nn.DataParallel(model).cuda()
if torch.cuda.is_available():
if args.gpu:
device = torch.device('cuda:{}'.format(args.gpu))
else:
device = torch.device("cuda")
elif torch.backends.mps.is_available():
device = torch.device("mps")
else:
device = torch.device("cpu")
# define loss function (criterion), optimizer, and learning rate scheduler
criterion = nn.CrossEntropyLoss().to(device)
optimizer = torch.optim.SGD(model.parameters(), args.lr,
momentum=args.momentum,
weight_decay=args.weight_decay)
"""Sets the learning rate to the initial LR decayed by 10 every 30 epochs"""
scheduler = StepLR(optimizer, step_size=30, gamma=0.1)
# optionally resume from a checkpoint
if args.resume:
if os.path.isfile(args.resume):
print("=> loading checkpoint '{}'".format(args.resume))
if args.gpu is None:
checkpoint = torch.load(args.resume)
elif torch.cuda.is_available():
# Map model to be loaded to specified single gpu.
loc = 'cuda:{}'.format(args.gpu)
checkpoint = torch.load(args.resume, map_location=loc)
args.start_epoch = checkpoint['epoch']
best_acc1 = checkpoint['best_acc1']
if args.gpu is not None:
# best_acc1 may be from a checkpoint from a different GPU
best_acc1 = best_acc1.to(args.gpu)
model.load_state_dict(checkpoint['state_dict'])
optimizer.load_state_dict(checkpoint['optimizer'])
scheduler.load_state_dict(checkpoint['scheduler'])
print("=> loaded checkpoint '{}' (epoch {})"
.format(args.resume, checkpoint['epoch']))
else:
print("=> no checkpoint found at '{}'".format(args.resume))
# Data loading code
if args.dummy:
print("=> Dummy data is used!")
train_dataset = datasets.FakeData(1281167, (3, 224, 224), 1000, transforms.ToTensor())
val_dataset = datasets.FakeData(50000, (3, 224, 224), 1000, transforms.ToTensor())
else:
traindir = os.path.join(args.data, 'train')
valdir = os.path.join(args.data, 'val')
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
train_dataset = datasets.ImageFolder(
traindir,
transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize,
]))
val_dataset = datasets.ImageFolder(
valdir,
transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize,
]))
if args.distributed:
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
val_sampler = torch.utils.data.distributed.DistributedSampler(val_dataset, shuffle=False, drop_last=True)
else:
train_sampler = None
val_sampler = None
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=args.batch_size, shuffle=(train_sampler is None),
num_workers=args.workers, pin_memory=True, sampler=train_sampler)
val_loader = torch.utils.data.DataLoader(
val_dataset, batch_size=args.batch_size, shuffle=False,
num_workers=args.workers, pin_memory=True, sampler=val_sampler)
if args.evaluate:
validate(val_loader, model, criterion, args)
return
for epoch in range(args.start_epoch, args.epochs):
if args.distributed:
train_sampler.set_epoch(epoch)
# train for one epoch
train(train_loader, model, criterion, optimizer, epoch, device, args)
# evaluate on validation set
acc1 = validate(val_loader, model, criterion, args)
scheduler.step()
# remember best acc@1 and save checkpoint
is_best = acc1 > best_acc1
best_acc1 = max(acc1, best_acc1)
if not args.multiprocessing_distributed or (args.multiprocessing_distributed
and args.rank % ngpus_per_node == 0):
save_checkpoint({
'epoch': epoch + 1,
'arch': args.arch,
'state_dict': model.state_dict(),
'best_acc1': best_acc1,
'optimizer' : optimizer.state_dict(),
'scheduler' : scheduler.state_dict()
}, is_best)
def train(train_loader, model, criterion, optimizer, epoch, device, args):
batch_time = AverageMeter('Time', ':6.3f')
data_time = AverageMeter('Data', ':6.3f')
losses = AverageMeter('Loss', ':.4e')
top1 = AverageMeter('Acc@1', ':6.2f')
top5 = AverageMeter('Acc@5', ':6.2f')
progress = ProgressMeter(
len(train_loader),
[batch_time, data_time, losses, top1, top5],
prefix="Epoch: [{}]".format(epoch))
# switch to train mode
model.train()
end = time.time()
for i, (images, target) in enumerate(train_loader):
# measure data loading time
data_time.update(time.time() - end)
# move data to the same device as model
images = images.to(device, non_blocking=True)
target = target.to(device, non_blocking=True)
# compute output
output = model(images)
loss = criterion(output, target)
# measure accuracy and record loss
acc1, acc5 = accuracy(output, target, topk=(1, 5))
losses.update(loss.item(), images.size(0))
top1.update(acc1[0], images.size(0))
top5.update(acc5[0], images.size(0))
# compute gradient and do SGD step
optimizer.zero_grad()
loss.backward()
optimizer.step()
# measure elapsed time
batch_time.update(time.time() - end)
end = time.time()
if i % args.print_freq == 0:
progress.display(i + 1)
def validate(val_loader, model, criterion, args):
def run_validate(loader, base_progress=0):
with torch.no_grad():
end = time.time()
for i, (images, target) in enumerate(loader):
i = base_progress + i
if args.gpu is not None and torch.cuda.is_available():
images = images.cuda(args.gpu, non_blocking=True)
if torch.backends.mps.is_available():
images = images.to('mps')
target = target.to('mps')
if torch.cuda.is_available():
target = target.cuda(args.gpu, non_blocking=True)
# compute output
output = model(images)
loss = criterion(output, target)
# measure accuracy and record loss
acc1, acc5 = accuracy(output, target, topk=(1, 5))
losses.update(loss.item(), images.size(0))
top1.update(acc1[0], images.size(0))
top5.update(acc5[0], images.size(0))
# measure elapsed time
batch_time.update(time.time() - end)
end = time.time()
if i % args.print_freq == 0:
progress.display(i + 1)
batch_time = AverageMeter('Time', ':6.3f', Summary.NONE)
losses = AverageMeter('Loss', ':.4e', Summary.NONE)
top1 = AverageMeter('Acc@1', ':6.2f', Summary.AVERAGE)
top5 = AverageMeter('Acc@5', ':6.2f', Summary.AVERAGE)
progress = ProgressMeter(
len(val_loader) + (args.distributed and (len(val_loader.sampler) * args.world_size < len(val_loader.dataset))),
[batch_time, losses, top1, top5],
prefix='Test: ')
# switch to evaluate mode
model.eval()
run_validate(val_loader)
if args.distributed:
top1.all_reduce()
top5.all_reduce()
if args.distributed and (len(val_loader.sampler) * args.world_size < len(val_loader.dataset)):
aux_val_dataset = Subset(val_loader.dataset,
range(len(val_loader.sampler) * args.world_size, len(val_loader.dataset)))
aux_val_loader = torch.utils.data.DataLoader(
aux_val_dataset, batch_size=args.batch_size, shuffle=False,
num_workers=args.workers, pin_memory=True)
run_validate(aux_val_loader, len(val_loader))
progress.display_summary()
return top1.avg
def save_checkpoint(state, is_best, filename='checkpoint.pth.tar'):
torch.save(state, filename)
if is_best:
shutil.copyfile(filename, 'model_best.pth.tar')
class Summary(Enum):
NONE = 0
AVERAGE = 1
SUM = 2
COUNT = 3
class AverageMeter(object):
"""Computes and stores the average and current value"""
def __init__(self, name, fmt=':f', summary_type=Summary.AVERAGE):
self.name = name
self.fmt = fmt
self.summary_type = summary_type
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
def all_reduce(self):
if torch.cuda.is_available():
device = torch.device("cuda")
elif torch.backends.mps.is_available():
device = torch.device("mps")
else:
device = torch.device("cpu")
total = torch.tensor([self.sum, self.count], dtype=torch.float32, device=device)
dist.all_reduce(total, dist.ReduceOp.SUM, async_op=False)
self.sum, self.count = total.tolist()
self.avg = self.sum / self.count
def __str__(self):
fmtstr = '{name} {val' + self.fmt + '} ({avg' + self.fmt + '})'
return fmtstr.format(**self.__dict__)
def summary(self):
fmtstr = ''
if self.summary_type is Summary.NONE:
fmtstr = ''
elif self.summary_type is Summary.AVERAGE:
fmtstr = '{name} {avg:.3f}'
elif self.summary_type is Summary.SUM:
fmtstr = '{name} {sum:.3f}'
elif self.summary_type is Summary.COUNT:
fmtstr = '{name} {count:.3f}'
else:
raise ValueError('invalid summary type %r' % self.summary_type)
return fmtstr.format(**self.__dict__)
class ProgressMeter(object):
def __init__(self, num_batches, meters, prefix=""):
self.batch_fmtstr = self._get_batch_fmtstr(num_batches)
self.meters = meters
self.prefix = prefix
def display(self, batch):
entries = [self.prefix + self.batch_fmtstr.format(batch)]
entries += [str(meter) for meter in self.meters]
print('\t'.join(entries))
def display_summary(self):
entries = [" *"]
entries += [meter.summary() for meter in self.meters]
print(' '.join(entries))
def _get_batch_fmtstr(self, num_batches):
num_digits = len(str(num_batches // 1))
fmt = '{:' + str(num_digits) + 'd}'
return '[' + fmt + '/' + fmt.format(num_batches) + ']'
def accuracy(output, target, topk=(1,)):
"""Computes the accuracy over the k top predictions for the specified values of k"""
with torch.no_grad():
maxk = max(topk)
batch_size = target.size(0)
_, pred = output.topk(maxk, 1, True, True)
pred = pred.t()
correct = pred.eq(target.view(1, -1).expand_as(pred))
res = []
for k in topk:
correct_k = correct[:k].reshape(-1).float().sum(0, keepdim=True)
res.append(correct_k.mul_(100.0 / batch_size))
return res
if __name__ == '__main__':
main()2.将训练脚本上传至昇腾服务器 将 pytorch_main.py 上传到具有读写权限的任意工作目录下,例如:
/home/ascend/workspace/resnet50/
3.执行脚本迁移(PyTorch GPU → Ascend NPU) 在训练脚本中插入自动迁移库,使其能够在昇腾 NPU 环境上运行:
import torch_npu
from torch_npu.contrib import transfer_to_npu上述两行代码即为 GPU2Ascend 工具生成的迁移关键语句,插入后脚本支持在 NPU 上加速执行,无需其他结构化改动。

3.执行训练验证迁移效果 在昇腾 NPU 环境下运行训练命令:
python pytorch_main.py -a resnet50 -b 32 --gpu 1 --dummy如果迁移成功,将看到训练过程日志正常输出,例如:

启动训练
net.train()
for epoch in range(10):
for batch_idx, data in enumerate(train_loader, start=0):
inputs, labels = data
optimizer.clear_grad()
# 6. 前向传播并计算损失
outputs = net(inputs)
loss = net_loss(outputs, labels)
# 7. 反向传播
loss.backward()
# 8. 更新参数
optimizer.step()
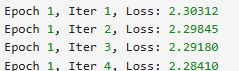
print('Epoch %d, Iter %d, Loss: %.5f' % (epoch + 1, batch_idx + 1, loss))
print('Finished Training')训练过程中会打印 loss 的变化情况,可以观察到 loss 在初步下降,这意味着模型参数逐渐适应了该数据集。
# 测试 5 张图片效果
for i in range(5):
test_image, gt = test_dataset[i] # 注意索引 i
# CHW -> NCHW
test_image = test_image.unsqueeze(0) # shape: [1, C, H, W]
# 推理
with torch.no_grad():
outputs = net(test_image) # net 为你的 PyTorch 模型
res = outputs.argmax(dim=1).cpu().numpy()[0]
print(f"图像{i} 标签:{gt}")
print(f"模型预测结果:{res}")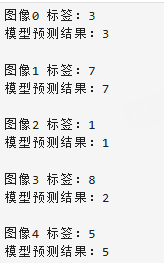
3.2 图像分类模型(ResNet-50)性能评测
为了监控训练过程中模型权重的梯度分布,可以使用 TrainerMon 工具。
1.创建配置文件
在训练脚本所在目录创建 monitor_config.json 文件,示例如下:
{
"targets": {},
"wg_distribution": true,
"format": "csv",
"ops": ["norm", "min", "max", "nans"]
}-
wg_distribution: true表示开启权重梯度分布监控 -
format: "csv"指定输出文件格式为 CSV -
ops指定监控操作,包括范数、最小值、最大值及 NaN 检测
2.在训练脚本中挂载监控工具
在训练脚本中引入并初始化监控对象:
import torch_npu
from torch_npu.contrib import transfer_to_npu
from torch_npu.contrib.monitor import TrainerMon
monitor = TrainerMon(
config_file_path="./monitor_config.json",
params_have_main_grad=False # 权重是否使用 main_grad
)在模型进入训练模式后挂载监控对象:
model.train()
monitor.set_monitor(
model,
grad_acc_steps=1,
optimizer=optimizer,
dp_group=None,
tp_group=None,
start_iteration=0 # 若断点续训可设置当前 iteration
)3.执行训练并查看结果
通过如下命令执行训练脚本:
python pytorch_main.py -a resnet50 -b 32 --gpu 1 --dummy训练完成后,当前目录下会生成 monitor_output 文件夹,按照时间戳存储多份监控结果。打开最新目录,即可查看模型权重梯度的统计数据文件。
结果如下

在 NPU 场景下,为了全面评估 API 的计算精度,需要从三个层面进行比对:真实数据模式、统计数据模式和 MD5 模式。不同模式下比对的表头和落盘数据类型有所区别,但均用于分析 NPU 与 Bench 的一致性。
三种精度比对模式
| 模式 | 描述 | 配置示例 |
| 真实数据模式 | 数据采集时记录全量 tensor 和统计量 | config.json 中 task: "tensor" |
| 统计数据模式 | 数据采集时仅记录统计量 | task: "statistics",summary_mode: "statistics" |
| MD5 模式 | 数据采集时仅记录统计量和 MD5 值 | task: "statistics",summary_mode: "md5" |
注意:不同模式下采集的数据类型不同,可根据需求选择对应模式进行精度验证。
统计量包括:最大值(max)、最小值(min)、平均值(mean)以及 L2-范数(L2 norm)。
使用流程概述
-
根据需要选择比对模式,并修改
config.json中task和summary_mode字段。 -
执行数据采集,生成对应模式下的落盘文件。
-
通过导出的表格分析 NPU 与 Bench 的数据差异、梯度一致性以及精度达标情况。
-
对于需要堆栈信息的场景,记得在采集命令中加
-s参数生成NPU_Stack_Info字段。
执行精度比对后,compare 工具会在 ./compare_result/accuracy_compare 目录下生成两类文件:advisor_{timestamp}.txt 和 compare_result_{timestamp}.xlsx。其中,advisor_{timestamp}.txt 文件中给出了可能存在精度问题的 API 及对应的专家建议;
而 compare_result_{timestamp}.xlsx 文件列出了所有参与精度比对的 API 的详细信息和比对结果,用户可以通过颜色标记、比对结果(Result)、计算精度达标情况(Accuracy Reached or Not)以及错误信息提示(Err_Message)快速定位可疑算子。不过由于每种指标都有对应的判定标准,最终分析仍需结合实际业务场景进行综合判断。

四.总结与展望
在本次评测中,我们通过图像分类任务的实战演示,完整呈现了 CANN 在 AI 开发流程中的落地应用。从 PyTorch GPU 训练脚本到昇腾 NPU 环境的迁移,CANN 提供了高效、可复用的工具链,使开发者能够在最小改动的前提下,实现训练脚本的快速迁移和加速执行。通过 GPU2Ascend 自动迁移库,原本需要手动适配的模型和算子,现在可以直接在 NPU 上运行,同时保持计算精度和性能一致性。
在训练和推理过程中,CANN 的核心功能充分发挥了作用:
-
异构算子优化与图级融合 显著降低了内存访问压力,提高了算力利用率;
-
静态内存规划与并行调度 保证了计算资源的高效利用,减少了瓶颈;
-
混合精度与量化策略 在保证精度的前提下进一步压缩了延迟与功耗;
-
权重梯度监控和精度比对工具 为训练调优提供了可视化、可量化的数据支撑,帮助开发者快速定位问题并优化模型性能。
通过本次落地实践可以看出,CANN 不仅解决了异构硬件适配和性能调优的行业痛点,还显著提升了端云一体的 AI 开发效率。开发者无需过多关注底层硬件细节,即可专注于模型创新和业务逻辑的优化,实现“高性能算力即开即用”的目标。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献45条内容
已为社区贡献45条内容

所有评论(0)