详解Github_35K+项目:打通200+数据源,构建企业级AI数据融合应用!
文章介绍了MindsDB这款开源AI数据统一访问引擎,展示了如何实现跨多数据源的统一查询和AI模型赋能数据查询。MindsDB作为"智能数据层",通过连接器对接各种异构数据源,提供统一API,并集成机器学习引擎为数据查询注入AI能力。文章详细演示了如何使用MindsDB连接RDBMS、文件、向量数据库等数据源,以及如何通过SQL调用传统ML模型、LLM和嵌入模型,实现数据与AI的无缝融合,简化AI
文章介绍了MindsDB这款开源AI数据统一访问引擎,展示了如何实现跨多数据源的统一查询和AI模型赋能数据查询。MindsDB作为"智能数据层",通过连接器对接各种异构数据源,提供统一API,并集成机器学习引擎为数据查询注入AI能力。文章详细演示了如何使用MindsDB连接RDBMS、文件、向量数据库等数据源,以及如何通过SQL调用传统ML模型、LLM和嵌入模型,实现数据与AI的无缝融合,简化AI应用开发流程。
前几天我们提到企业AI数据环境的复杂性,远非单一的向量库能胜任。大型企业的数据"散落”在大量的RDBMS、文档、SaaS甚至邮件中。未来企业AI应用的数据访问一定会体现两大最重要的特征:融合与智能。

本篇为大家实测MindsDB这款开源的AI数据统一访问引擎,以了解它是如何在数据不离开源头的前提下,给上层应用提供一种融合与智能的数据访问方式。:
- MindsDB初探、安装与启动
- 一:跨多数据源的统一查询
- 二:AI模型赋能数据查询
- 三:知识库与混合检索的应用
- 四:构建智能的Data Agent
- 结束语:MindsDB的应用总结
01
MindsDB初探、安装与启动
MindsDB不是一个随着大模型(LLM)才出现的项目,最开始它为跨源的机器学习而设计,但随着LLM的出现而发生进化。简单的说,目前的MindsDB是:
一个跨多数据源(数据库、文件、应用等)、支持多AI模型(传统ML/LLM模型、嵌入模型)的统一数据连接、查询与智能应用的"中间件”。
【平台架构】
我们将MindsDB的架构表示如下:
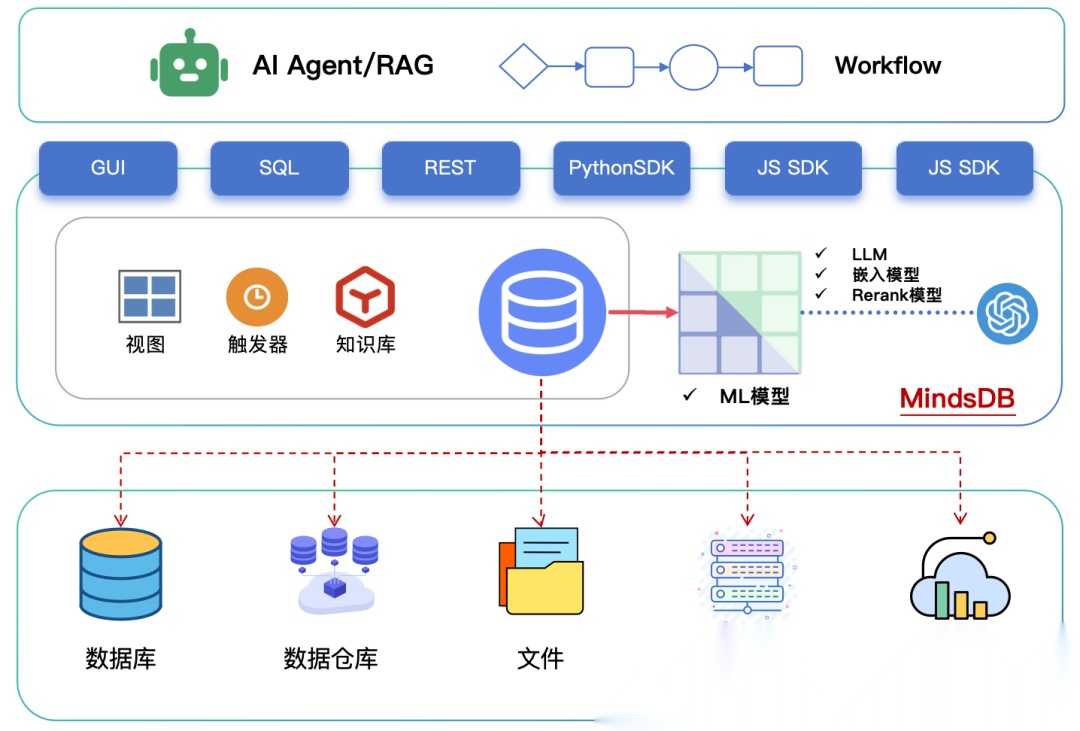
可以把MindsDB比作一个在数据源与AI应用之间的“智能数据层”:
-
对下层(数据源):通过可插拔的大量连接器对接各种异构数据源,可以是各种数据库/仓库、文件、向量库、SaaS应用等。
-
对上层(AI应用):提供统一的SQL、SDK、REST、MCP多种API,以实现统一查询、混合检索、智能分析、Data Agent等。
而MindsDB本身除了协调各个数据源的查询并汇总结果外,更重要的是:集成大量机器学习引擎(包括LLM),通过AI模型给数据查询注入AI能力。
什么意思呢?比如下面这些需要一点”AI“的查询:
-
在查询客户信息时,同步检索出这个客户的“流失概率”
-
在查询文章内容时,实时总结出这篇文章的“摘要信息”
-
在插入某段文本时,同时抽取其“结构化信息”插入到某个表
此外,MindsDB还支持一些在中间层进行数据联合(Unify)、同步、智能响应的有趣特性。
下面通过实例来探究MindsDB的用法与强大,首先进行安装并启动MindsDB Server。
【安装与启动】
最快速启动MindsDB的方式是Docker(具体请参考Github)。本着探索的精神,我们则用源码启动:
#创建虚拟环境(macos)python -m venv mindsdb-venvsource mindsdb-venv/bin/activate#安装依赖pip install -e .python -m mindsdb --config ./config.json
这里使用了config.json进行启动(建议你也这么做),其中的一些重点:
-
path:root字段为MindsDB自身的存储目录,可自行设置;
-
api:对MindsDB需要启动的API接口做配置。MindsDB会在不同端口启动不同的API接口,比如HTTP接口在47334(REST访问与GUI);MySQL接口在47335(MySQL客户端访问);MCP Server在47337(MCP协议访问)等;
-
default_llm:**默认LLM模型,支持Ollama。注意国内模型用OpenAI兼容接口,需要设置baseurl。举例:
"default_llm": { "provider": "openai", "model_name" : "gpt-4o-mini", "base_url":"<官方url或第三方平台url>", "api_key": "<你的API Key>"},
踩坑:为了让MindsDB能够成功通过OpenAI SDK访问其他模型,注意在代码中搜索CHATMODELSPREFIXES设置,把对应模型的前缀加进去。
-
default_*embedding_*model:默认的嵌入模型,与default_llm类似
-
default_*reranking_*model:默认的rerank模型,与default_llm类似
启动成功后,访问http://127.0.0.1:47334/,看到GUI后代表成功:
02
跨多数据源的统一查询
MindsDB最核心的两类集成能力是数据源与AI模型(通过对应的handler/引擎来连接)。本节先看前一类:数据源集成。
MindsDB中连接并访问外部数据源的方式为:
通过SQL声明式的连接外部数据源,将其注册成MindsDB的“虚拟数据库”。
我们看几种最主要的数据源。
【关系型数据库(RDBMS)】
最常见的数据源是企业中的各种RDBMS。我们在本地启动一个Postgres测试数据库来模拟,并生成一些数据。
现在进入MindsDB的GUI,执行如下”MindsDB风格“的SQL:
CREATE DATABASE my_postgres WITH ENGINE = 'postgres',PARAMETERS = { "host": "127.0.0.1", "port": 5432, "database": "mindsdb", "user": "postgres", "schema": "public", "password": "yourpassword"};
非常直观。Parameters是连接源库的参数,with engine则指定连接引擎是postgres。这就把一个Postgres库”映射“成了名字叫做my_postgres的虚拟库。
对RDBMS来说,这里遵循的映射规则是:
- 虚拟数据库中的表名、字段与源数据库一一对应
注意,虚拟库并不真实存在。所以你无需考虑数据同步等问题。现在你可以通过SHOW TABLES FROM查看库中的表清单,并对其查询。比如:
select * from my_postgres(select * from products limit5)--或者select * from my_postgres.products limit5
对于使用者来说,好像是在查询本地表,但其实数据仍然在Postgres里,由MindsDB将SQL转译并下推给Postgres执行,整个过程对用户透明。
你也可以通过这个映射的”虚拟库”直接创建表和数据:
create table my_postgres.demo ( id integer primary key, content varchar(50))insert into my_postgres.demo values(1,'demo')
一切都和你直接操作源库类似(注:MindsDB风格的SQL语法基本遵循MySQL与PostgreSQL),但这里创建的表和数据实际上都会被“推”到源数据库。
【文件】
另一种常见的数据源是文件,MindsDB直接支持的文件类型为TXT/PDF/Excel/CSV/JSON等。对于文件的映射规则是:
-
虚拟数据库的名字固定为“files”
-
表名则是你上传文件的时候设置的名称
对不同的文件类型,MindsDB会用不同的方式将其映射成“表”:
-
对于CSV/Excel:直接将电子表格映射成Table,字段与表头对应
-
对于TXT/PDF:会进行内容分割后映射成content与metadata两列
-
JSON文件:如果可以,将被转化为Table;否则与TXT处理方式一致
现在通过MindsDB的GUI上传几个测试文件:

然后你就可以向查询表一样查询这个“文件”。比如:
SELECT * FROM files.test_questions;
如果源文件是TXT或PDF的非结构化文件,查询结果可能像这样:

正如上文所说,文件会被拆成多行放在content字段中。
【向量数据库】
AI时代自然不能缺少向量库,MindsDB支持常见的向量库。向量库到虚拟数据库中的映射规则根据不同的向量库有所不同。
以ChromDB为例:
-
映射的表名为对应的Chroma中的collection名称
-
字段则统一为id、embeddings、metadata、content、distance
让我们找一个RAG应用中的Chroma向量库映射过来:
--创建chroma虚拟数据库映射CREATE DATABASE my_chromadbWITH ENGINE = 'chromadb'PARAMETERS = { "persist_directory": "./chromadata", "distance": "cosine"}
然后就可以直接查询这个向量库的某个collection,就像查一个普通表:
select embeddings,content,metadata from my_chromadb.vectorindex
你将会直接看到向量、对应的内容和元数据的输出。
向量库的插入与有条件检索需要用到嵌入模型,将在下一节讲解。
【跨源联合查询】
连接多个数据源后,MindsDB的强大之处在于可以直接用SQL对不同来源的数据进行JOIN和联合查询。
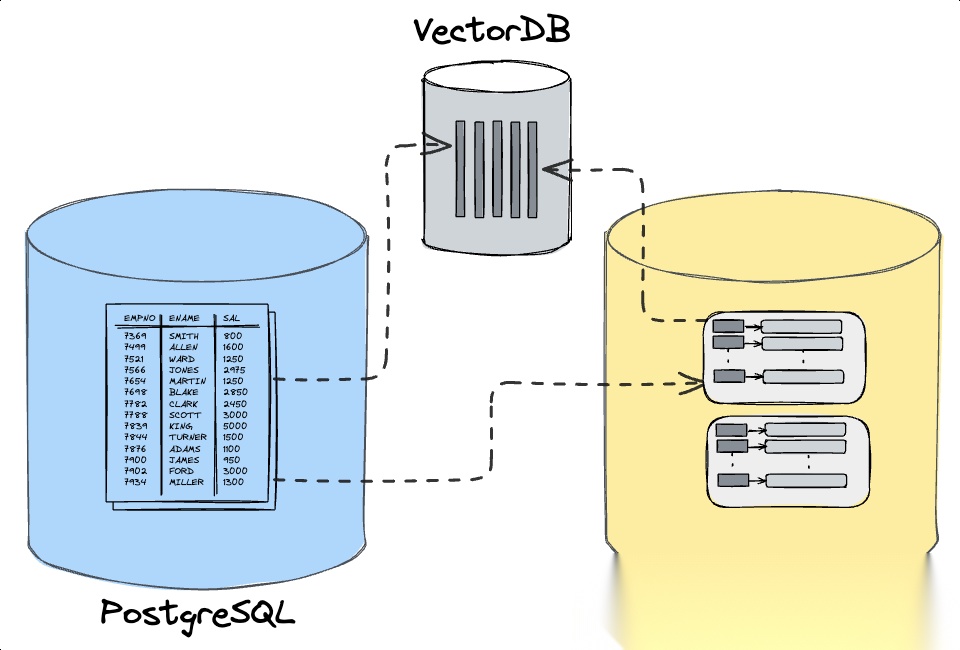
比如你的orders表在Postgres,客户行为日志存储在MongoDB中,你可以在MindsDB中写一个跨库JOIN,将两者关联分析而无需要任何ETL流程!MindsDB会将查询拆分给Postgres和Mongo分别执行,然后在内部完成结果拼接,最终把融合后的结果集返回。


需要注意的是,MindsDB尽量将过滤、聚合等操作下推到各自的数据源,但最终的跨库结合部分会在MindsDB层完成,因此对于超大数据集的跨源操作需要谨慎设计过滤条件。

03
AI模型赋能数据查询
接着来看MindsDB的第二大核心集成能力:AI模型。
如果说MindsDB的数据源集成解决的是”找齐数据并统一访问”的问题,那么模型集成的目的是让数据更聪明。
MindsDB通过一种“AI Table”的模式将AI模型融入数据库查询,使AI预测和分析如同查询一个表一样方便 。
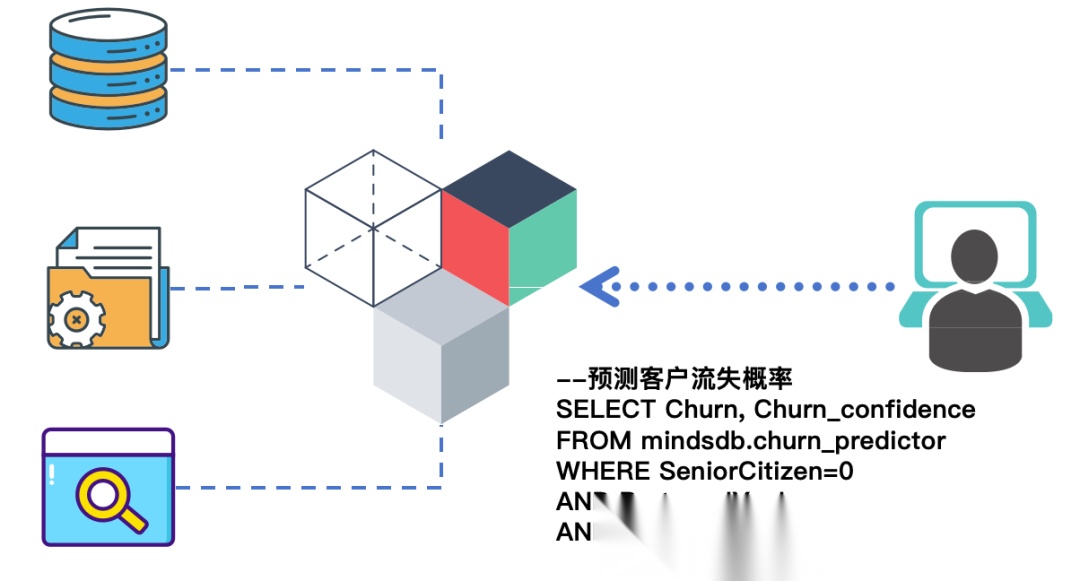
现在来看如何利用MindsDB的模型能力,创建、训练与调用模型,让查询注入AI能力。注意,大模型(LLM)也只是AI模型的一种,它的区别在于不需要基于MindsDB的数据源做训练。
【传统机器学习模型】
先看传统的机器学习(ML)模型,通常包括各种回归、分类、时间序列等模型。以一个简单的预测客户流失概率的分类模型举例。
比如,有一张客户流失历史数据表customers_churn在Postgres里,包含客户诸多属性和是否已经流失的标签。我们希望训练一个模型预测新的客户是否可能流失,首先来训练这个预测模型:
CREATE MODEL mindsdb.customers_churn_predictorFROM my_postgres( SELECT * FROM customers_churn)PREDICT churn;
上述SQL会让MindsDB读取my*postgres.customers_*churn数据,并自动训练一个预测churn(流失)字段的模型。训练完成后,一个名为customers_*churn_*predictor的模型就出现在MindsDB的名为mindsdb的内部库中。
现在,你可以像查询表一样查询它,传入新的客户属性,获取预测结果:
SELECT churn, churn_confidence, churn_explainFROM mindsdb.customers_churn_predictorWHERE SeniorCitizen=0 AND Partner='Yes' AND Dependents='No' AND tenure=1 AND PhoneService='No' ... -- 省略若干客户条件;
返回结果中包含模型预测的churn(是否流失),以及churn_*confidence置信度和churn_*explain解释信息等。MindsDB自动提供了预测的可信度和特征重要性等解释性输出,方便我们理解模型判断依据。
可以看到,这里既不需要模型开发与调用代码,也不需要把数据导出到外部工具,一切用SQL完成。
这种“AI Table”的方式还有个好处是:你甚至可以把模型“表”和数据表做JOIN,实现批量调用,比如批量预测一批客户的流失概率。你将在下面的大模型部分看到这一点。
【大语言模型(LLM)】
MindsDB将LLM视作特殊的AI引擎(无需训练),可以通过配置API密钥等参数,也将其包装为MindsDB中的模型“表”。
我们创建一个用来回答问题的模型:
CREATE MODEL my_llm_openai_answerPREDICT answerUSING engine = 'openai', model_name = 'gpt-4o-mini', api_base = 'https://api.openai.com/v1', openai_api_key = '<你的OpenAI密钥>', prompt_template = '回答问题:{{question}}',max_tokens=8000;
你可以替换成任意兼容OpenAI API接口的模型,如果配置正常,现在就得到了一个模型“表”,查询它:
SELECT answer FROM my_llm_openai_answer WHERE question = '你好,能简单介绍一下MindsDB吗?'
MindsDB会把question字段的内容插入到提示模板中调用模型,并将返回的回答作为answer字段输出(字段在创建时定义)。这种方式让我们用SQL就调用了LLM,而无需单独编写API代码。
巧妙的是,你可以把LLM模型”表“与数据表JOIN,实现更智能的查询。
我们现在创建一个生成摘要的模型:
CREATE MODEL my_llm_openai_summaryPREDICT summaryUSING engine = 'openai', model_name = 'gpt-4o-mini', openai_api_key = '<API密钥>', prompt_template = '请将以下内容概括为简短摘要:{{text}}';
现在将前面创建的Postgres数据库中的产品描述数据批量”喂“给它,让AI生成每个产品的描述摘要:
SELECT p.product_id, s.summaryFROM my_postgres( SELECT product_id, description AS text FROM products WHERE product_id BETWEEN 1 AND 3 ) AS pJOIN my_llm_openai_summary AS s;
这里通过JOIN操作将Postgres库中表的描述字段description发送给摘要模型(注意要as text,因为模型定义的条件字段是text),模型输出的summary再与原产品ID一起返回,从而实现了批量生成,真正实现了“让SQL更智能”。
再创建一个用来情感检测的LLM模型:
CREATE MODEL my_llm_qwen_sentimentPREDICT sentimentUSING engine = 'openai', model_name = 'qwen-plus', api_base = 'https://dashscope.aliyuncs.com/compatible-mode/v1', openai_api_key = '<API-Key>', prompt_template = '请将下面客服评论内容判断为 好评、中性 或 差评:{{review}}';
把上面Postgres库中的订单评价信息批量“送入”这个模型:
SELECT o.order_id, o.product_id, o.review, s.sentimentFROM my_postgres( SELECT order_id, product_id, review FROM order_items LIMIT 5 ) AS oJOIN my_llm_qwen_sentiment AS s;
你就可以轻松的得到所有评价的情感分类结果:

【嵌入模型】
嵌入模型在生成式AI中用于将输入转化为向量表示,从而实现语义检索。同其他模型一样,你也可以得到一个嵌入模型”表“,并对其进行查询。
首先创建一个嵌入模型”表“:
CREATE MODEL my_emb_openaiPREDICT embedding USING engine = 'openai', model_name='text-embedding-3-small', mode = 'embedding', question_column = 'content' ...
这里仍然使用openai引擎,但是mode为embedding;输入为content,输出为embedding。
现在我们基于上一节创建的文件与向量数据库,用SQL快速生成向量索引:
create table my_chromadb.sales_questions (select m.embedding as embeddings,f.content,f.metadatafrom files.sales_questions f join my_emb_openai m )
这里把“files”这个数据库中的sales_*questions文件“表”与my_*emb_*openai这个模型”表“进行JOIN,Mindsdb会自动发现两者匹配的”字段“content,并生成向量,然后直接在“my_*chromadb"这个库中创建向量”表“(注意字段名称是强制的),这样就完成了一个向量索引的过程!
基于这个新生成的向量”表“,借助向量模型就可以做语义检索:
select contentfrom my_chromadb.sales_questions where embeddings = (select embedding from my_emb_openai where content = '...')
注意这里的”=“并非绝对相等,仅仅代表语义相似。
你会看到类似如下的结果,而且会输出distance(代表相似度):

综合以上例子,我们通过几个简单的SQL就把文件进行了拆分、向量化、插入向量库,并可以语义检索。这实际上就是RAG在Index阶段的基本原理。但不同的是,这里全部是用SQL完成的。
可以看到,不管底层使用的是自训练ML模型还是外部的LLM,MindsDB都将其统一为SQL可查询的表接口,实现了模型与数据的无缝融合。通过这种方式,许多复杂的AI数据任务会变得更轻松,大大缩短了从数据到AI应用的路径。

本篇就到这里。
下篇我们继续介绍与演示MindsDB的两个高级特性:
-
用于更智能的组织多源信息的知识库(Knowledge Base)
-
用于实现自然语言访问统一数据的智能体(Data Agent)
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)
👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。

👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型实战项目&项目源码👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战项目来学习。(全套教程文末领取哈)
👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)
👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)
为什么分享这些资料?
只要你是真心想学AI大模型,我这份资料就可以无偿分享给你学习,我国在这方面的相关人才比较紧缺,大模型行业确实也需要更多的有志之士加入进来,我也真心希望帮助大家学好这门技术,如果日后有什么学习上的问题,欢迎找我交流,有技术上面的问题,我是很愿意去帮助大家的!
这些资料真的有用吗?
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 8
8 0
0- 0



 已为社区贡献205条内容
已为社区贡献205条内容

所有评论(0)