【Datawhale组队学习】吴恩达Agentic TASK03 Tool use
*重要性:**代码执行是使智能体式应用变得极其强大的关键工具。**行业趋势:**许多大型语言模型的训练者会专门优化模型,以确保其在应用中代码执行功能的良好表现。开发者需要手动为智能体系统创建并添加工具。一个新的标准——MCP (Model Context Protocol) 正在兴起,它旨在让开发者更容易地访问一套庞大的工具集,供大型语言模型使用,从而简化开发流程。
工具使用Tool Use
核心思想:工具即函数,模型自主决策 关键在于,模型拥有自主决策权。它不再是被动地根据内部知识库生成答案,而是能主动判断:在当前情境下,是否需要、以及应该调用哪个工具来完成任务。 就像人类借助锤子、扳手等工具能完成徒手无法做到的事情一样,语言模型通过调用“函数工具”,也能突破自身训练数据和能力的限制,变得无比强大。
简单工具执行流程(simple tool execution)
例子:工具使用的运作流程。以”现在几点?“为例,清晰展示了工具使用的完整闭环。
- 输入提示(Input Prompt):用户提问”What time is it “
- 模型决策 (Model Decision): LLM 意识到自己无法提供实时时间,于是决定调用名为 get_current_time() 的工具。
- 工具执行 (Tool Execution): 系统执行该函数,返回精确的时间值,例如 15:20:45。
- 结果反馈 (Result Feedback): 这个时间值被作为新的上下文(对话历史)回传给 LLM。
- 最终输出 (Final Output): LLM 结合这个新信息,生成自然语言回复:“It’s 3:20pm.”
整个过程的关键点:
- 工具是函数:get_current_time() 是一段 Python 代码,它负责与系统时钟交互并返回字符串。
- 模型自主选择:模型自行决定何时、何地调用哪个工具。
- 动态上下文:工具返回的结果会融入对话历史,供模型后续推理使用

何时调用,何时不调用?
工具使用的一个重要特性是条件性调用。 模型并非对所有问题都盲目调用工具,而是能智能判断。
- 调用工具的例子:当被问及“现在几点?”,模型知道需要实时数据,因此调用 get_current_time()。
- 不调用工具的例子:当被问及“绿茶含多少咖啡因?”,模型可以基于其内部知识库直接回答:“Green tea typically contains 25-50 mg of caffeine per cup.”,无需调用任何工具。 这体现了模型的“智能”——它能区分哪些信息是静态的(可内化),哪些是动态的(需外求)。
工具使用的实际应用示例
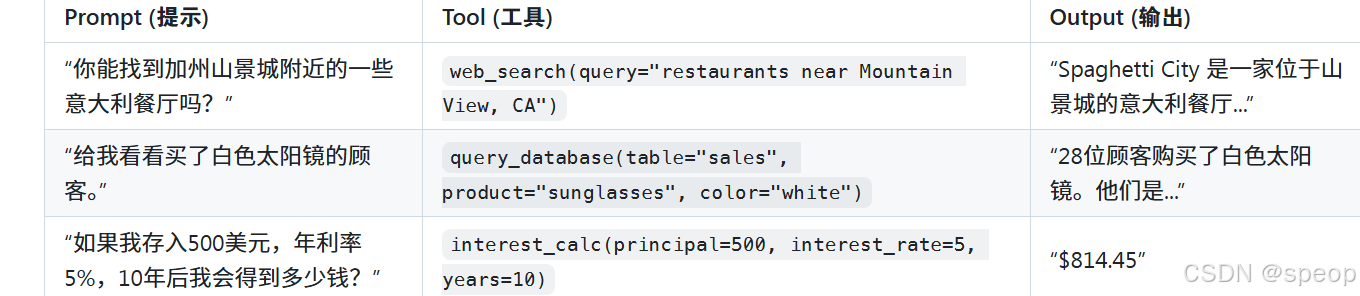
多工具协作
对于更复杂的请求,模型可以串联调用多个工具,形成工作流。 案例:日历助理
- 用户请求: “请在周四我的日历中找一个空闲时段,并与Alice预约。”
- 提供的工具集:
- check_calendar(): 查询日历,返回空闲时段。
- make_appointment(): 创建预约。
- delete_appointment(): 取消预约。
- 模型执行流程:
- 首先调用 check_calendar(),获得结果:“Thursday, 3pm; Thursday, 4pm; Thursday, 6pm”。
- 基于返回的信息,模型决定选择“3pm”这个时段。
- 接着调用 make_appointment(time=“3pm”, with=“Alice”)。
- 工具返回确认信息:“Meeting created successfully!”。
- 最终,模型整合信息,回复用户:“Your appointment is set up with Alice at 3 PM Thursday.”
总结 工具使用是构建下一代 AI 应用的关键技术。它让语言模型从“只会聊天”的伙伴,进化为能够“动手做事”的智能助手。 核心价值:
- 超越知识边界:通过调用工具,模型可以获取实时数据、访问数据库、执行计算。
- 实现复杂逻辑:支持多步推理和工具链协作,处理现实世界的复杂需求。
- 提升应用价值:无论是餐厅推荐、零售分析还是个人日程管理,都能因工具而变得更实用、更强大。
创建一个工具
LLM本身并不会直接执行代码或调用函数,它被训练的核心能力是生成文本。 如何让LLM学会调用函数的过程,核心思想是模型不直接调用,而是“请求”调用。工具其实就是一些代码/函数。如今的主流语言模型都经过直接训练去使用工具,没有训练就必须得写提示词来告诉模型如何使用工具。
早期方法(手动提示工程)
-
在 LLM 尚未被直接训练来使用工具时,开发者必须通过编写详细的系统提示词来“告诉” LLM 如何请求调用工具。
-
例如,指示 LLM 在需要调用 get_current_time 工具时,必须输出特定格式的文本:“FUNCTION: get_current_time()”。
-
这种方法虽然有效,但需要开发者手动处理 LLM 的输出,解析其意图,然后执行相应的函数。
现代方法:
当前主流的 LLM 都经过了直接训练,能够原生地理解何时以及如何请求调用工具。
开发者不再需要像过去那样在提示词中硬编码特定的触发语法(如全大写的 “FUNCTION”),而是只需向 LLM 提供工具的描述和可用性,模型会自行决定何时调用。
实际工具使用:
- 开发者编写工具函数:例如 get_current_time()。
- 开发者编写系统提示词 (System Prompt):告诉模型,如果它想使用某个工具,应该如何格式化它的输出。
- 模型根据提示词输出特定格式的文本:这个文本不是最终答案,而是一个“请求”,例如 FUNCTION: get_current_time()。
- 开发者编写解析代码:读取模型的输出,识别出这个“请求”,然后真正地调用对应的函数。
- 将函数结果回传给模型:把函数返回的结果作为新的上下文输入给模型,让它生成最终的自然语言回复。
手工提示工程方法详解
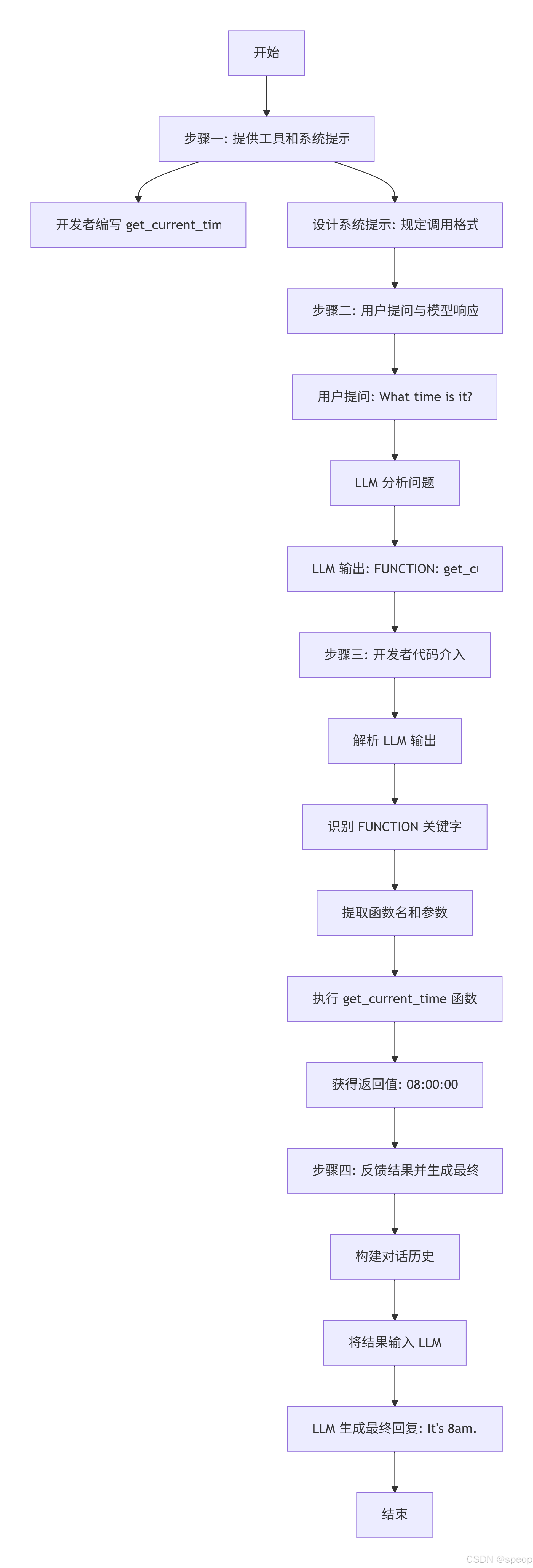
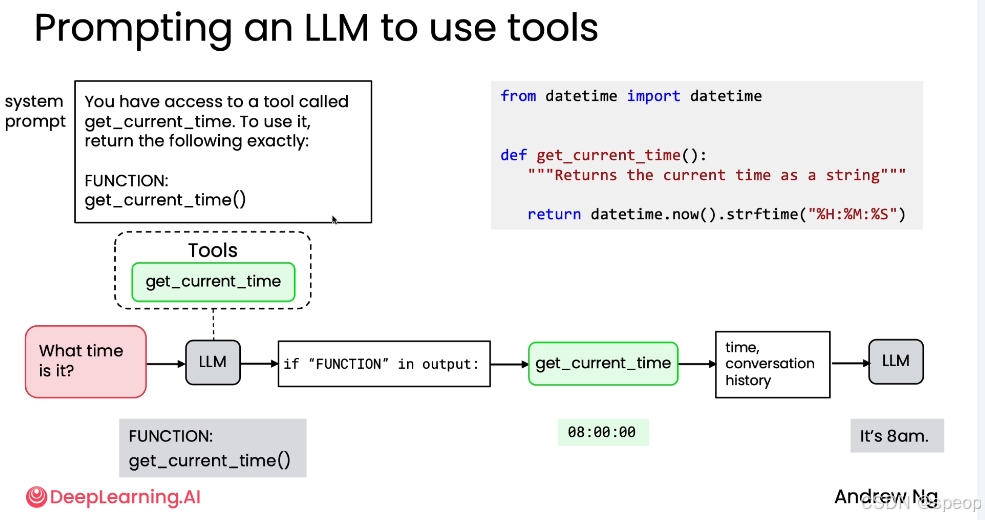
以 get_current_time 工具为例,展示完整的交互流程:
步骤一:提供工具和系统提示
实现工具:开发者编写好 get_current_time() 函数。
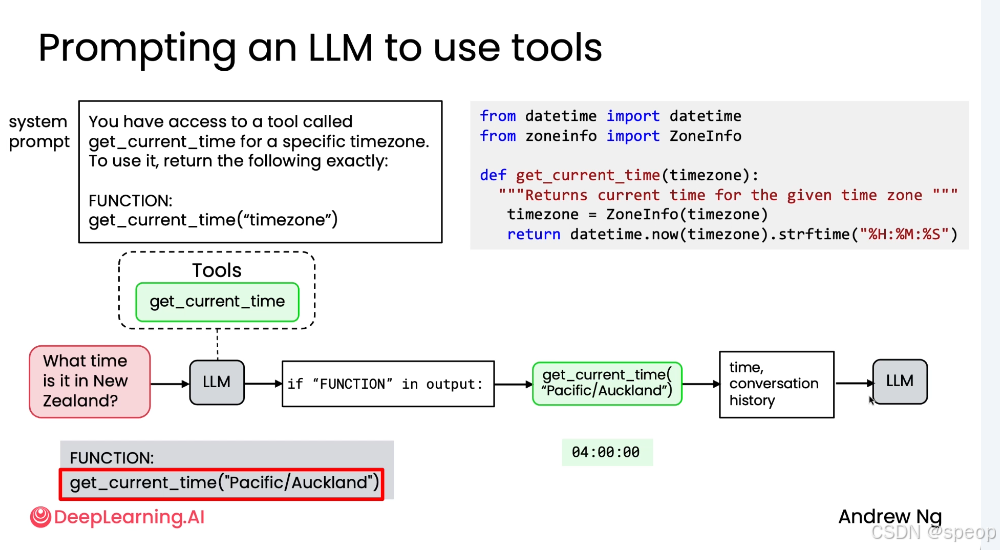
设计系统提示 (System Prompt):编写一个提示词,明确告知 LLM 它可以访问这个工具,并规定调用它的精确格式。
You have access to a tool called get_current_time. To use it, return the following exactly:
FUNCTION: get_current_time()
步骤二:用户提问与模型响应
用户提问:“What time is it?”
LLM 决策:LLM 分析问题后,意识到需要获取当前时间。
LLM 输出:根据系统提示的要求,LLM 不会直接回答,而是输出预设的触发文本:
FUNCTION: get_current_time()
步骤三:开发者代码介入
- 解析输出:开发者编写的程序读取 LLM 的输出。
- 识别意图:检查输出中是否包含 “FUNCTION” 关键字。
- 提取参数:如果包含,则提取出要调用的函数名 get_current_time 及其参数(此例中无参数)。
- 执行工具:程序实际调用 get_current_time() 函数,获得返回值(如 “08:00:00”)。
步骤四:反馈结果并生成最终答案
- 构建对话历史:将工具的执行结果(如 “08:00:00”)连同之前的对话历史(用户问题、LLM 的函数请求)一起,作为新的上下文输入给 LLM。
- LLM 生成最终回复:LLM 接收到包含工具执行结果的新上下文后,知道之前发生了什么(用户问时间 -> LLM 请求调用函数 -> 函数返回了“8点”),于是生成自然语言的最终回复:“It’s 8am.”
处理带参数的工具
当工具函数需要参数时,流程类似,但提示词和 LLM 的输出需要包含参数信息。
例:获取指定时区的时间
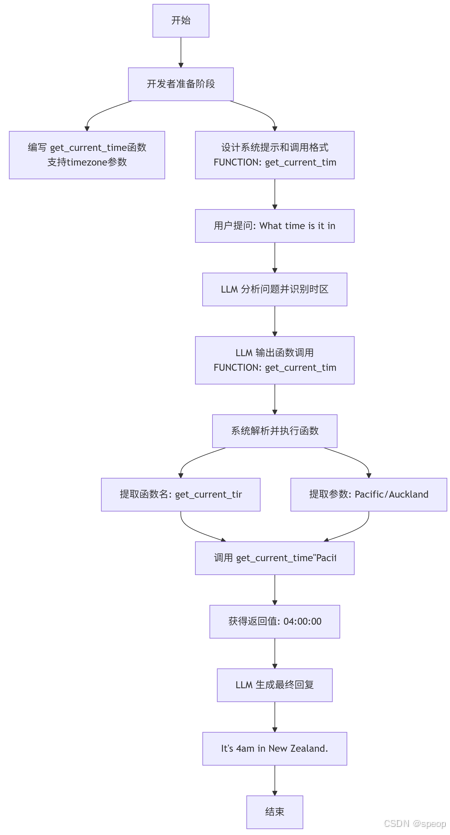
- 实现工具:编写一个带参数的函数 get_current_time(timezone)。
- 修改系统提示:
You have access to a tool called get_current_time for a specific timezone. To use it, return the following exactly:
FUNCTION: get_current_time("timezone")
- 用户提问:“What time is it in New Zealand?”
- LLM 输出:LLM 会根据提示格式,输出带有具体参数的文本
FUNCTION: get_current_time("Pacific/Auckland")
- 开发者代码
解析出函数名和参数 “Pacific/Auckland”,然后调用 get_current_time(“Pacific/Auckland”)。 - 反馈与回复
将执行结果(如 “04:00:00”)反馈给 LLM,最终 LLM 回复:“It’s 4am in New Zealand.”
总结:工具使用的核心流程 四步循环:
- 提供工具 (Provide the Tool):开发者编写好功能函数。
- 告知模型 (Tell the LLM):通过系统提示词,明确告诉模型有哪些工具可用,以及如何“请求”调用它们(即输出什么格式的文本)。
- 解析并执行 (Parse and Execute):开发者编写代码,监听模型的输出,识别其“请求”,并实际执行对应的函数。
- 反馈结果 (Feed Back Result):将函数执行的结果作为新的上下文,送回给模型,让它继续推理或生成最终答案。 这个流程的关键在于,开发者扮演了“翻译官”和“执行者”的角色,弥合了语言模型的“文本生成”能力与现实世界“函数执行”能力之间的鸿沟。
工具调用语法 Tool Use Syntax
工具调用的本质:
- LLM(大语言模型)本身不会直接调用工具。
- LLM 会“请求”开发者去调用某个工具,开发者负责执行该工具并将其结果返回给 LLM。
- 在开发社区中,人们常简化说“LLM 调用了工具”,但这在技术上并不准确,仅是一种便捷的说法。
AI Suite 库:
- 这是一个开源库,由 Andrew Ng 及其团队开发。
- 它提供了一种统一、简便的语法来调用多个不同的 LLM 提供商(如 OpenAI)。
- 该库的核心功能之一是自动处理工具描述,极大简化了开发流程。
以get_current_time函数为例
工具定义:
from datetime import datetime
def get_current_time():
"""Returns the current time as a string"""
return datetime.now().strftime("%H:%M:%S")
# 获取并格式化当前时间
# now 当前时间,
# strftime datetime对象的一个方法
# 将日期时间对象格式化为指定的字符串
# 定义了输出的时间格式:
# %H:24小时制的小时数(00-23)
# %M:分钟数(00-59)
# %S:秒数(00-59)
使用 AI Suite 库调用工具的基本代码框架:
import aisuite as ai
client = ai.Client()
response = client.chat.completions.create(
model="openai:gpt-4o", # 指定使用的模型
messages=messages, # 传递给 LLM 的消息数组
tools=[get_current_time], # 定义 LLM 可以访问的工具列表
max_turns=5 # 设置工具调用的最大轮次,防止无限循环
)
解析:
- model: 选择要使用的 LLM,此处为 OpenAI 的 gpt-4o。
- messages: 传递给模型的对话历史或提示信息。
- tools: 这是最核心的部分。只需将你希望模型能访问的函数对象(如 get_current_time)放入一个列表中即可。
- 【max_turns】: 设置一个上限,防止模型在工具调用上陷入无限循环。通常设为5即可,除非你的任务异常复杂。
AI Suite 的优势: 该库的语法与 OpenAI 原生 API 非常相似,但提供了更高的抽象层,使得开发者可以专注于业务逻辑,而非繁琐的 API 细节。它还支持轻松切换多个 LLM 提供商。

AI Suite如何自动化工具描述
AI Suite 的强大之处在于其自动化能力,它能将你的 Python 函数无缝转换为 LLM 可理解的格式。 当你将 get_current_time 函数传入 tools 参数后,AI Suite 会在后台自动为其生成一个 JSON Schema。【这个 Schema 是传递给 LLM 的真实数据结构】。
{
"type":"function",.
"function":{
"name":"get_current_time",
"description":"Returns the current time as a string",
"parameters":{}
}
}
- 自动生成过程:
- 函数名 (name): 直接提取 Python 函数的名称。
- 函数描述 (description): 自动从函数的 docstring 中提取。
- 参数 (parameters): 对于无参函数,此部分为空对象 {}。
AI Suite处理带参数的函数
工具定义
from datetime import datetime
from zoneinfo import ZoneInfo
def get_current_time(timezone):
"""Returns current time for the given time zone """
timezone = ZoneInfo(timezone)
return datatime.now(timezone).strftime("%H:%M:%S")
{
"type": "function",
"function": {
"name": "get_current_time",
"description": "Returns current time for the given time zone",
"parameters": {
"timezone": {
"type": "string",
"description": "The IANA time zone string, e.g., 'America/New_York' or 'Pacific/Auckland'."
}
}
}
}
这里的参数是由类型和描述的,需要注意一下
"timezone": {
"type": "string",
"description": "The IANA time zone string, e.g., 'America/New_York' or 'Pacific/Auckland'."
}
AI Suite 不仅能提取函数名和描述,还能识别出 timezone 参数,并将其类型(string)和详细说明(来自 docstring)也一并纳入 Schema。这样,当 LLM 决定调用此函数时,它就知道需要提供一个类似 ‘America/New_York’ 的字符串作为参数。

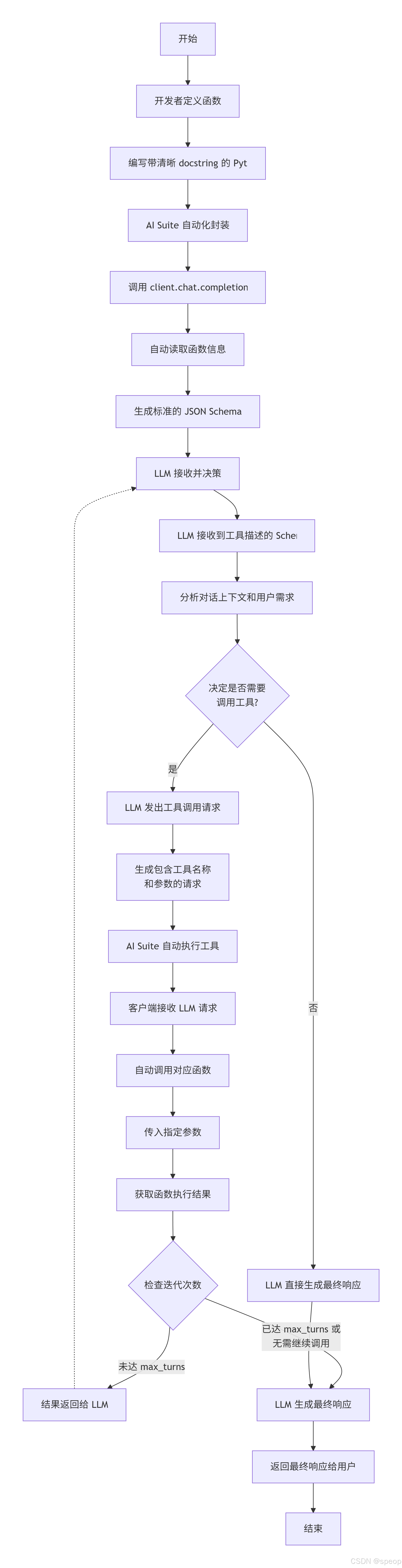
工作流程:
- 开发者定义函数: 编写一个带有清晰 docstring 的 Python 函数。
- AI Suite 自动化封装: 在调用 client.chat.completions.create 时,AI Suite 自动读取函数信息,生成标准的 JSON Schema。
- LLM 接收并决策: LLM 接收到包含所有可用工具描述的 Schema。它会根据当前的对话上下文和用户需求,决定是否需要调用某个工具。
- LLM 发出请求: 如果需要,LLM 会生成一个包含工具名称和所需参数的请求。
- 开发者执行工具: AI Suite 的客户端接收到 LLM 的请求后,会自动调用开发者定义的对应函数,并传入指定的参数。
- 结果返回与迭代: 函数执行的结果会被送回 LLM,LLM 可以基于此新信息继续思考,甚至发起下一次工具调用。整个过程最多可重复 max_turns 次。
- 最终响应: 当所有轮次结束或 LLM 决定不再调用工具时,它会生成最终的文本响应返回给用户。
代码执行工具:
- 终极灵活性: 与其他工具不同,代码执行工具赋予了 LLM 几乎无限的可能性。因为代码本身可以完成任何计算、数据处理或外部交互任务。
- 开发者赋能: 通过提供这个工具,开发者实际上是在告诉 LLM:“你可以让我为你执行任何你认为必要的代码。”这极大地扩展了 LLM 的能力和应用场景。
代码执行 Tool Use:Code Execution
代码执行(Code execution)是让大型语言模型(LLM)能够编写并运行代码,以解决用户提出的任务。
- 核心优势:
- 强大能力: LLM生成的代码方案常常出人意料地聪明和有效,能解决各种复杂任务。
- 灵活性: 相比于为每个功能手动创建独立工具,让模型自己写代码是一种更灵活、可扩展性更强的方法。例如,一个科学计算器有大量功能按钮,不可能为每个按钮都创建一个工具。
- 提升应用性能: 许多语言模型的训练者会专门优化模型,以确保其在应用中代码执行功能表现良好。
示例:简单计算器
传统方法:预定义工具集
- **场景:**构建一个能输入数学文字题并解答的应用。
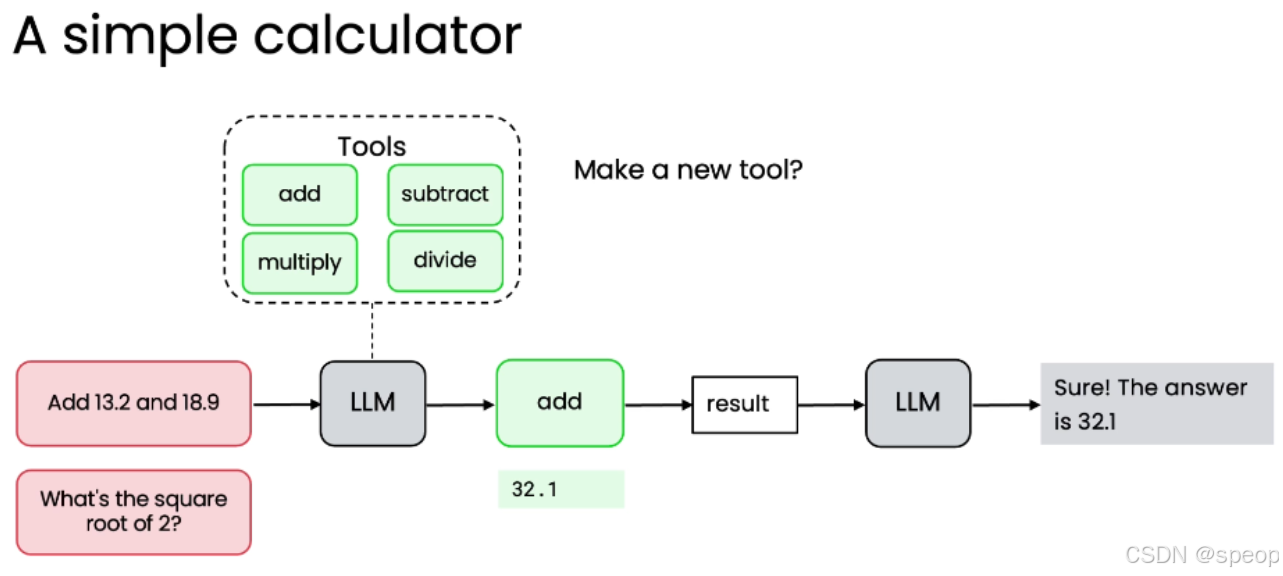
- **方法:**创建一系列预定义工具(如
add,subtract,multiply,divide)。 - 流程:
- 用户输入:“Add 13.2 and 18.9”。
- LLM 识别需求,调用 add 工具。
- 工具执行计算,返回结果 32.1。
- LLM 将结果格式化后返回给用户。
- 局限性:
- 面对新需求(如“2的平方根是多少?”),需要不断添加新工具(如 sqrt, exponentiation)。
- 现代科学计算器功能繁多,为每个按钮都创建独立工具不切实际。
替代方案: 让模型自己写代码
方法概述
核心理念:与其逐个实现功能,不如让系统自己编写并执行代码来解决问题。
优势:极大地扩展了模型的能力边界,使其能处理任何可以通过编程解决的问题
实现步骤
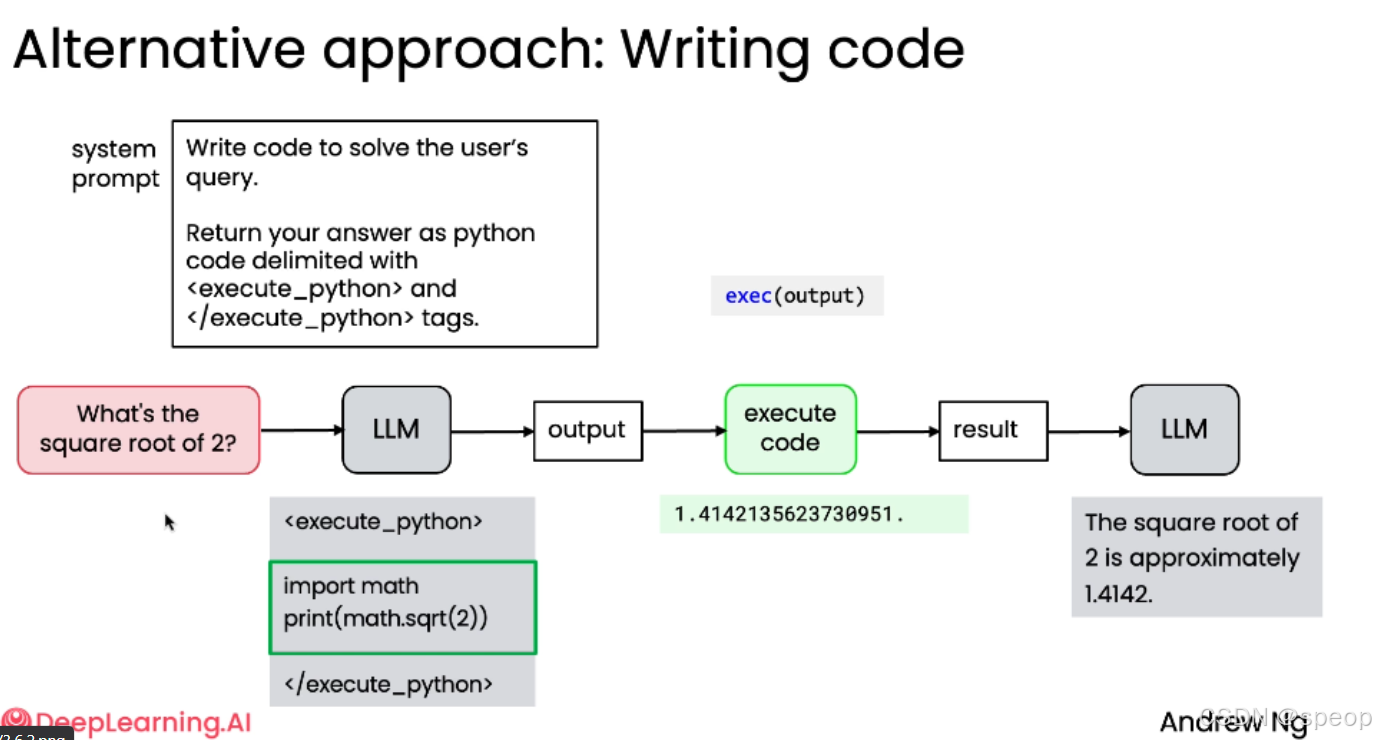
- 设计系统提示词 (System Prompt):
- 指令模型:“编写代码来解决用户的问题”。
- 要求模型将答案以 Python 代码形式返回,并用
<execute_python>和</execute_python>标签包裹。
- 模型输出:
对于查询 “What’s the square root of 2?”,模型可能输出:
<execute_python>
import math
print(math.sqrt(2))
</execute_python>
- 提取与执行:
- 使用正则表达式等模式匹配技术,从模型输出中提取被标签包裹的代码。
- 在安全的沙盒环境中执行提取出的代码。
- 获取执行结果(例如 1.4142135623730951)。
- 反馈与格式化:
- 将数值结果传回给 LLM。
- LLM 根据原始问题,生成一个格式良好的最终答案(例如:“The square root of 2 is approximately 1.4142.”)。
执行代码的方式
- Python 的 exec() 函数:这是一个内置函数,可以执行传入的任意字符串代码。虽然强大,但也带来了安全风险。
- 专用工具:存在一些专门用于安全执行代码的工具,可以在更安全的沙盒环境中运行。
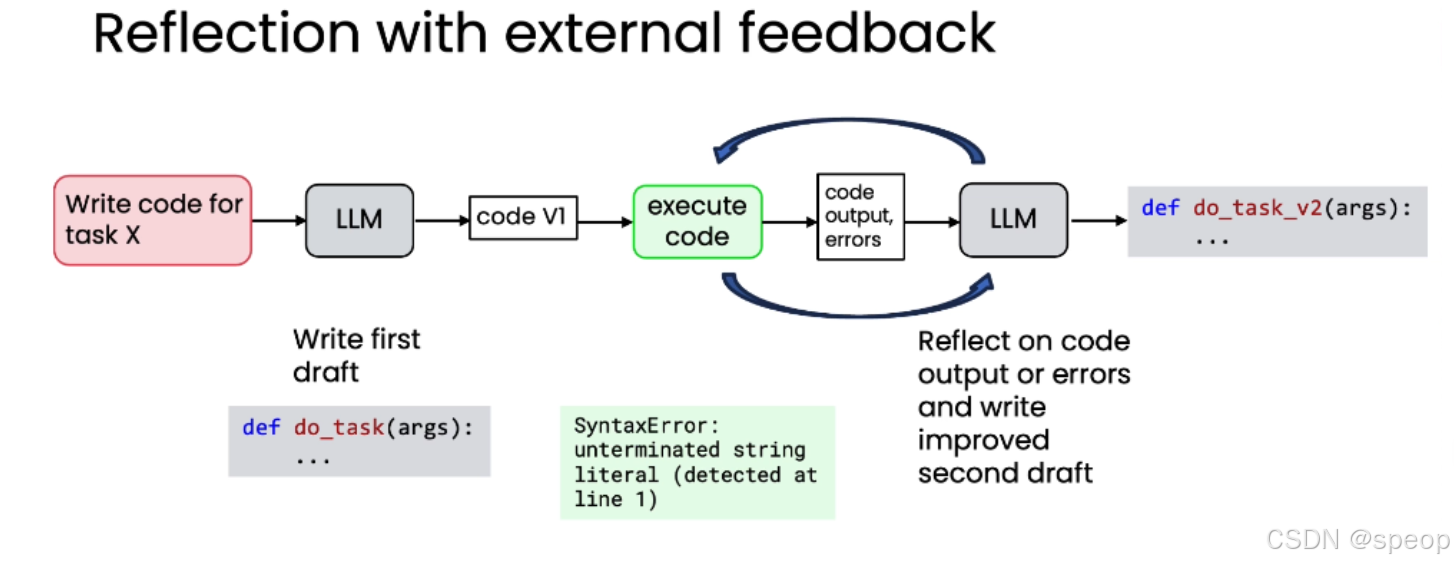
进阶:带外部反馈的反思(Reflection with External Feedback)
- **概念:**当代码执行失败时,将错误信息(如 SyntaxError)反馈给模型。
- 流程:
- 模型生成第一版代码草稿。
- 执行代码,捕获错误。
- 将错误信息连同原始任务一起发送给模型。
- 模型反思错误,生成改进后的第二版代码。
- **效果:**通过这种迭代过程,模型有时能修正错误,得到更精确的答案。
安全考量:安全的代码执行(Source Code Execution)
- **核心风险:**在沙盒环境外运行由模型生成的任意代码是有风险的。
- 真实案例:
- 一位团队成员使用的高度智能体化代码执行器,曾错误地执行了 rm *.py 命令,删 除了项目目录中的所有 Python 文件。
- 幸运的是,该成员有备份习惯,未造成实质损失。
- 最佳实践:
- 必须使用沙盒环境:这是保护系统、防止数据丢失或敏感数据泄露的最佳做法。
- 轻量级沙盒:推荐使用像 Docker 或 E2B 这样的轻量级沙盒环境,它们能有效隔离代码,降低损坏系统或环境的风险。
- **现实情况:**尽管有风险,许多开发者仍会直接执行模型生成的代码而不做过多检查。但为了安全,应坚持使用沙盒。

总结
**重要性:**代码执行是使智能体式应用变得极其强大的关键工具。
**行业趋势:**许多大型语言模型的训练者会专门优化模型,以确保其在应用中代码执行功能的良好表现。
未来方向:
- 开发者需要手动为智能体系统创建并添加工具。
- 一个新的标准——MCP (Model Context Protocol) 正在兴起,它旨在让开发者更容易地访问一套庞大的工具集,供大型语言模型使用,从而简化开发流程。
MCP Model Context Protocol
定义: MCP(Model Context Protocol,模型上下文协议)是由 Entropy 提出的一个标准,旨在为大型语言模型(LLM)提供一种标准化的方式来访问外部工具和数据源。
目的: 解决开发者在构建智能体式应用时,需要为每个应用重复编写代码来集成不同工具(如 Slack, GitHub, Google Drive 等)的痛点。
**现状:**该协议已被许多公司和开发者广泛采用,形成了一个活跃的生态系统。
问题与解决方案
传统开发模式的问题
重复造轮子:
- 开发者 A 构建 App 1,需要集成 Slack、Google Drive、GitHub 和 PostgreSQL。
- 开发者 B 构建 App 2,同样需要集成这些工具。
- 每个应用都必须独立编写封装代码来调用各个工具的 API。
- 如果有 m 个应用和 n 个工具,整个社区的工作量是 m × n,效率低下且浪费资源。
MCP的解决方案
引入共享服务器: MCP 提出了一种标准,允许应用程序通过一个共享的 MCP 服务器来访问工具和数据源。
工作量优化:
- 不再是每个应用都创建自己的工具封装。
- 只需要开发 n 个 MCP 服务器(每个对应一个工具),然后让 m 个应用去连接这些服务器。
- 整个社区的工作量从 m × n 降低到 m + n,实现了巨大的效率提升。
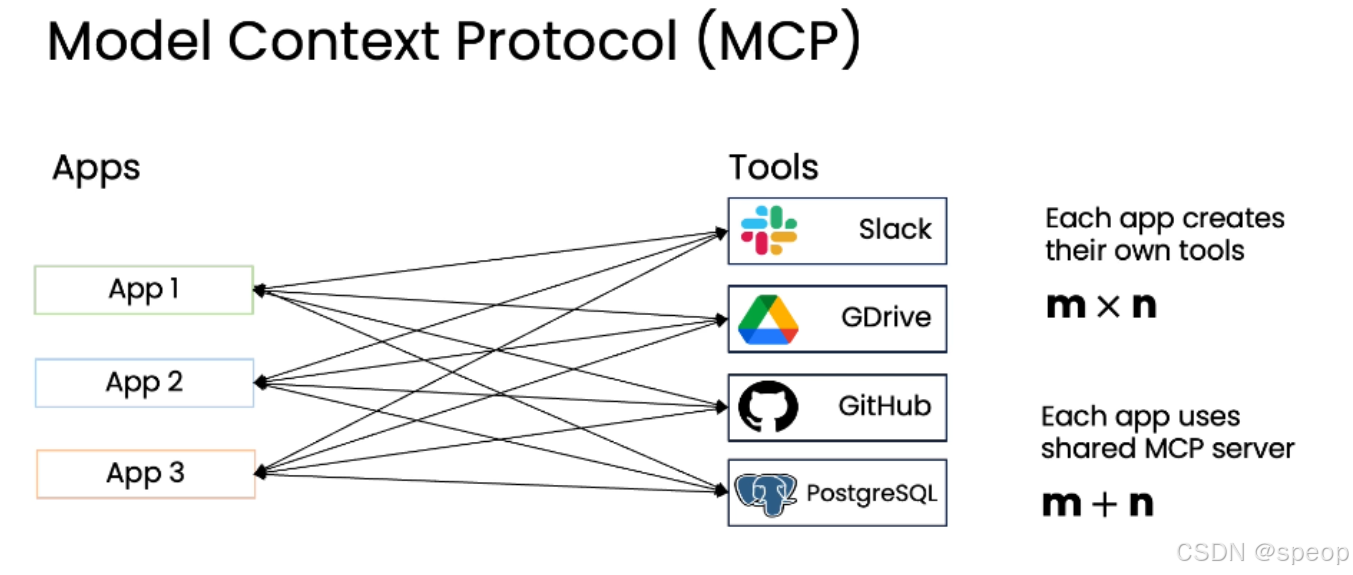
MCP的核心组件
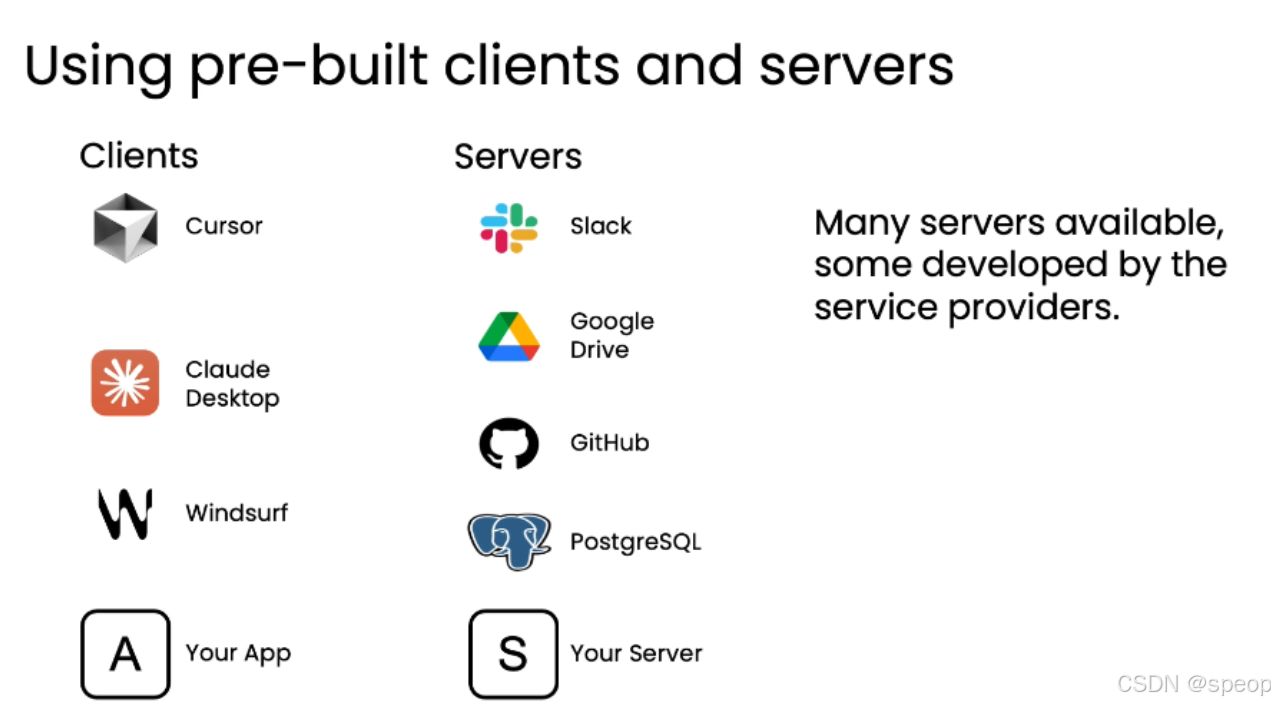
客户端(Clients)
- 角色:希望访问外部工具或数据的应用程序。
- 示例:Cursor, Claude Desktop, Windsurf。
- 功能:向 MCP 服务器发送请求,获取数据或执行操作。
服务器(Servers)
- 角色: 提供工具和数据源的软件服务。
- 示例: Slack, Google Drive, GitHub, PostgreSQL。
- 功能: 作为“包装器”,接收来自客户端的请求,并将其转换为对原始工具 API 的调用,然后将结果返回给客户端。
- 来源: 部分服务器由服务提供商开发,但也有大量第三方开发者贡献。
MCP 的能力范围
- 初始设计:侧重于为 LLM 提供更多上下文,最初的工具主要是用于**“获取数据”**(fetch data)。
- 当前发展:MCP 的能力已扩展,不仅能访问数据,还能调用更通用的功能和执行操作。在 MCP 文档中,这些统称为**“资源”**(resources)。
实际演示:Claude Desktop 使用 GitHub MCP 服务器
- 场景:用户在 Claude Desktop 中输入查询:“总结该 GitHub 仓库的 README 文件内容”,并附上 URL。
- 流程:
- Claude Desktop 作为 MCP 客户端,识别到这是一个需要访问 GitHub 的请求。
- 它向已连接的 GitHub MCP 服务器发送一个请求,参数包含文件路径 (README.md)、仓库名 (aisuite) 和所有者 (andrewng)。
- GitHub MCP 服务器执行请求,从仓库下载文件内容。
- 服务器将长文本响应返回给 Claude Desktop。
- Claude Desktop 将接收到的内容反馈给 LLM,LLM 生成一份简洁、格式良好的摘要。
- 第二次查询:用户询问“有哪些最新的 Pull Request?”。
- 同样,客户端向服务器发送“List pull requests”的请求。
- 服务器返回 JSON 格式的拉取请求列表。
- LLM 将其整理成清晰易读的列表,包括标题、状态、作者和描述等信息。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 10
10 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)