【数据可视化-156】第十五届全运会各省参赛运动员规模可视化分析报告
🧑 博主简介:曾任某智慧城市类企业算法总监,目前在美国市场的物流公司从事高级算法工程师一职,深耕人工智能领域,精通python数据挖掘、可视化、机器学习等,发表过AI相关的专利并多次在AI类比赛中获奖。💬 博主粉丝群介绍:① 群内初中生、高中生、本科生、研究生、博士生遍布,可互相学习,交流困惑。② 热榜top10的常客也在群里,也有数不清的万粉大佬,可以交流写作技巧,上榜经验,涨粉秘籍。③ 群
🧑 博主简介:曾任某智慧城市类企业
算法总监,目前在美国市场的物流公司从事高级算法工程师一职,深耕人工智能领域,精通python数据挖掘、可视化、机器学习等,发表过AI相关的专利并多次在AI类比赛中获奖。CSDN人工智能领域的优质创作者,提供AI相关的技术咨询、项目开发和个性化解决方案等服务,如有需要请站内私信或者联系任意文章底部的的VX名片(ID:xf982831907)
💬 博主粉丝群介绍:① 群内初中生、高中生、本科生、研究生、博士生遍布,可互相学习,交流困惑。② 热榜top10的常客也在群里,也有数不清的万粉大佬,可以交流写作技巧,上榜经验,涨粉秘籍。③ 群内也有职场精英,大厂大佬,可交流技术、面试、找工作的经验。④ 进群免费赠送写作秘籍一份,助你由写作小白晋升为创作大佬。⑤ 进群赠送CSDN评论防封脚本,送真活跃粉丝,助你提升文章热度。有兴趣的加文末联系方式,备注自己的CSDN昵称,拉你进群,互相学习共同进步。

【数据可视化-156】第十五届全运会各省参赛运动员规模可视化分析报告
一、引言
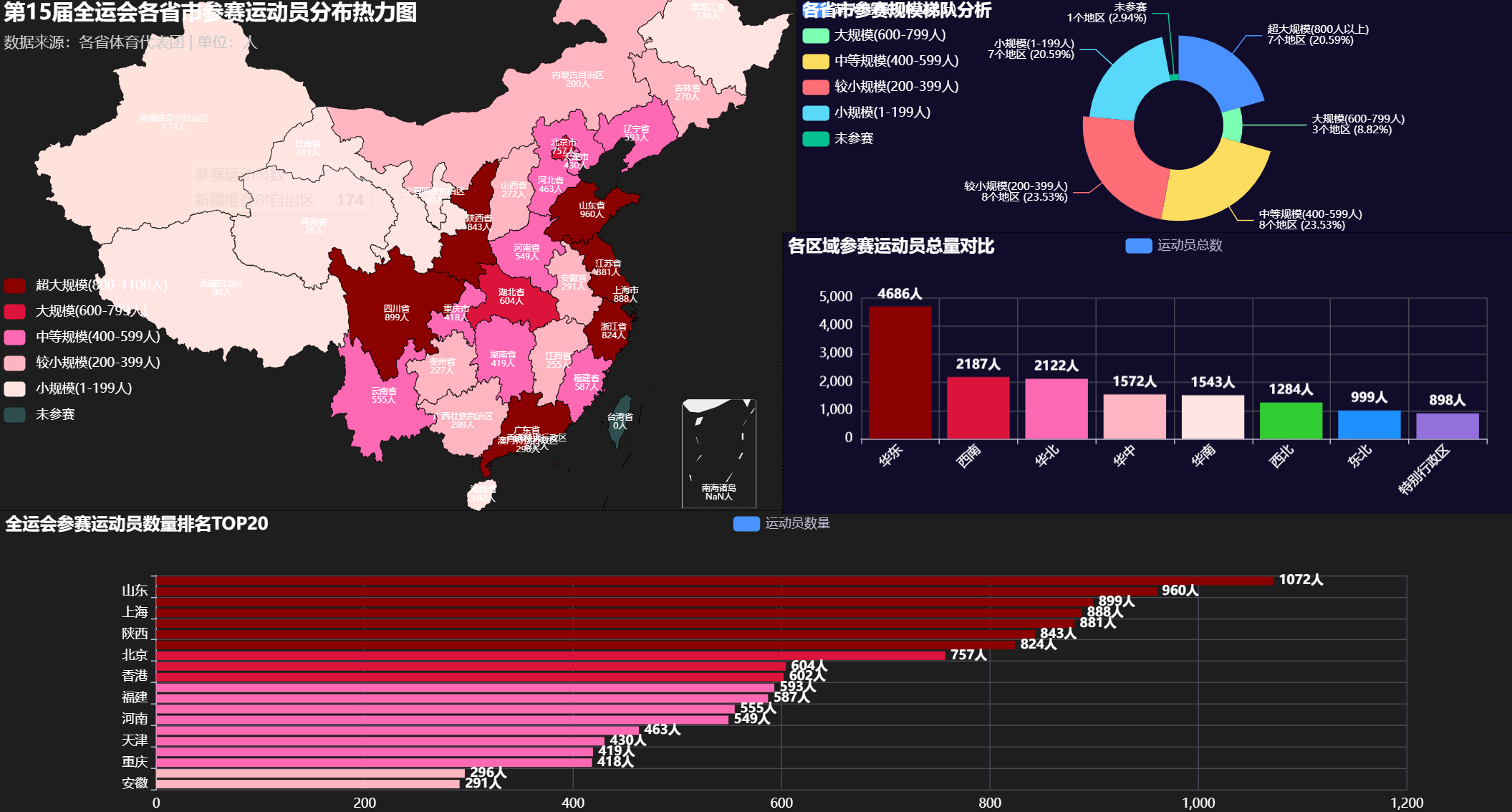
北京时间2025年11月,第十五届全运会各项赛事正如火如荼进行。除了激烈的金牌争夺,各省市代表团的参赛规模也反映了各地的体育基础和综合实力。广东代表团以1072名运动员高居榜首,展现了强大的体育人才储备,山东代表团960人紧随其后,江苏代表团881人位列第三。本文将对各省参赛运动员规模进行深度可视化分析。
二、数据准备
import pandas as pd
import numpy as np
from pyecharts import options as opts
from pyecharts.charts import Bar, Map, Pie, Page, Grid, Line, Scatter
from pyecharts.globals import ThemeType
from pyecharts.commons.utils import JsCode
# 创建数据
athlete_data = {
'北京': 757, '天津': 430, '河北': 463, '山西': 272, '内蒙古': 200,
'辽宁': 593, '吉林': 270, '黑龙江': 136, '上海': 888, '江苏': 881,
'浙江': 824, '安徽': 291, '福建': 587, '江西': 255, '山东': 960,
'河南': 549, '湖北': 604, '湖南': 419, '广东': 1072, '广西': 289,
'海南': 182, '重庆': 418, '四川': 899, '贵州': 227, '云南': 555,
'西藏': 88, '陕西': 843, '甘肃': 101, '青海': 76, '宁夏': 90,
'新疆': 174, '香港': 602, '澳门': 296, '台湾': 0
}
# 转换为DataFrame
df_athletes = pd.DataFrame(list(athlete_data.items()), columns=['地区', '运动员数'])
df_athletes['排名'] = df_athletes['运动员数'].rank(ascending=False, method='min').astype(int)
df_athletes = df_athletes.sort_values('运动员数', ascending=False)
# 创建完整的数据映射
athlete_map_data = [(province, count) for province, count in athlete_data.items()]
三、数据可视化
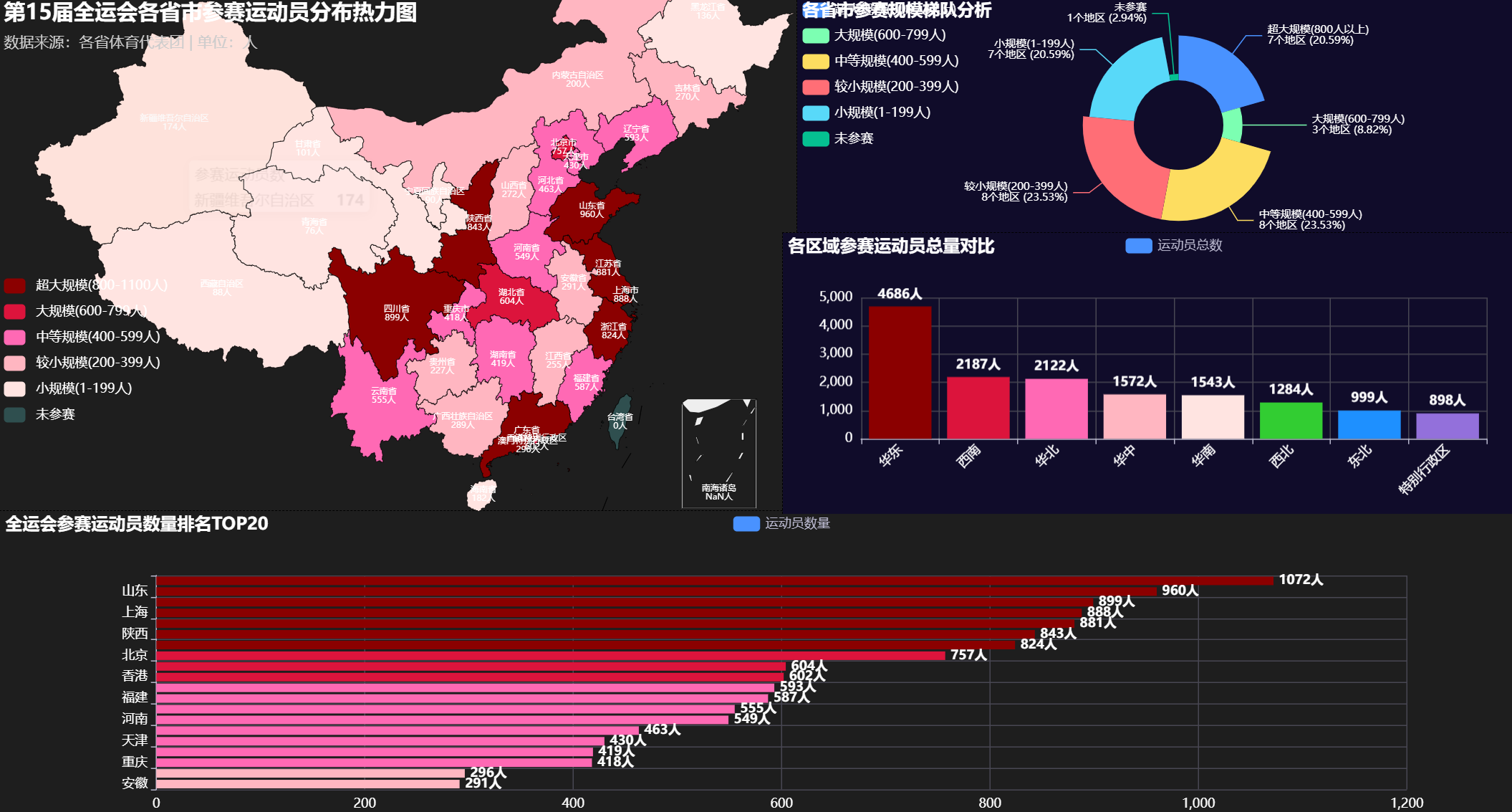
3.1 中国地图运动员分布热力图
def create_athlete_distribution_map(athlete_data):
"""创建运动员分布地图"""
china_map = (
Map()
.add(
series_name="参赛运动员数",
data_pair=athlete_data,
maptype="china"
)
.set_global_opts(
title_opts=opts.TitleOpts(
title="第15届全运会各省市参赛运动员分布热力图",
subtitle="数据来源:各省体育代表团 | 单位:人"
),
legend_opts=opts.LegendOpts(is_show=False)
)
.set_series_opts(
itemstyle_opts=opts.ItemStyleOpts(
border_color="#000000",
border_width=0.5
)
)
)
return china_map
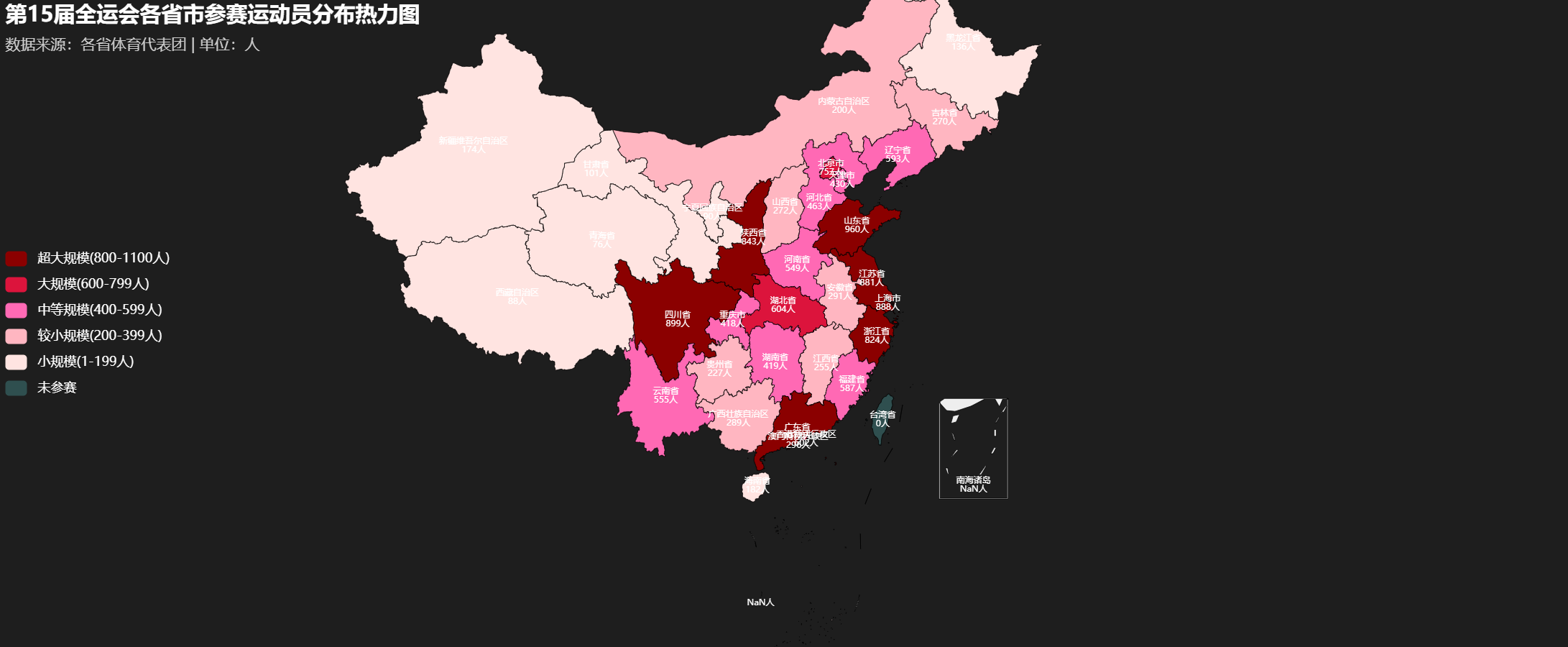
3.2 运动员数量排名条形图
def create_athlete_bar_chart(df):
"""创建运动员数量排名条形图"""
# 取前20名显示
df_top20 = df.head(20).sort_values('运动员数', ascending=True)
bar = (
Bar()
.add_xaxis(df_top20['地区'].tolist())
.add_yaxis(
series_name="运动员数量",
y_axis=df_top20['运动员数'].tolist()
)
)
.reversal_axis()
.set_global_opts(
title_opts=opts.TitleOpts(
title="全运会参赛运动员数量排名TOP20"
)
)
)
return bar
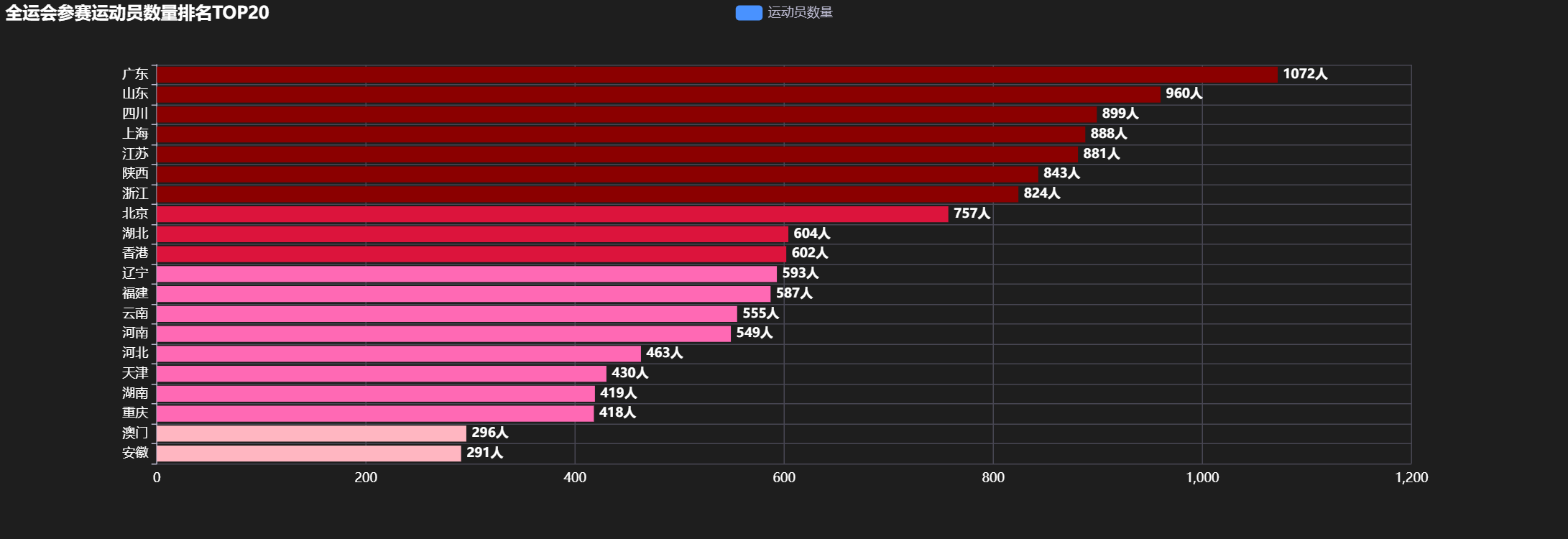
3.3 参赛规模梯队分析饼图
def create_athlete_tier_pie_chart(df):
"""创建参赛规模梯队分析饼图"""
# 计算各梯队数量
tier_1 = len(df[df['运动员数'] >= 800]) # 超大规模
tier_2 = len(df[(df['运动员数'] >= 600) & (df['运动员数'] < 800)]) # 大规模
tier_3 = len(df[(df['运动员数'] >= 400) & (df['运动员数'] < 600)]) # 中等规模
tier_4 = len(df[(df['运动员数'] >= 200) & (df['运动员数'] < 400)]) # 较小规模
tier_5 = len(df[(df['运动员数'] >= 1) & (df['运动员数'] < 200)]) # 小规模
tier_0 = len(df[df['运动员数'] == 0]) # 未参赛
tier_data = [
("超大规模(800人以上)", tier_1),
("大规模(600-799人)", tier_2),
("中等规模(400-599人)", tier_3),
("较小规模(200-399人)", tier_4),
("小规模(1-199人)", tier_5),
("未参赛", tier_0)
]
pie = (
Pie()
.add(
series_name="参赛规模梯队",
data_pair=tier_data,
radius=["35%", "75%"],
center=["50%", "50%"],
rosetype="radius"
)
.set_global_opts(
title_opts=opts.TitleOpts(
title="各省市参赛规模梯队分析"
)
)
.set_series_opts(
label_opts=opts.LabelOpts(
formatter="{b}\n{c}个地区 ({d}%)",
color="#FFFFFF",
font_size=10
)
)
)
return pie
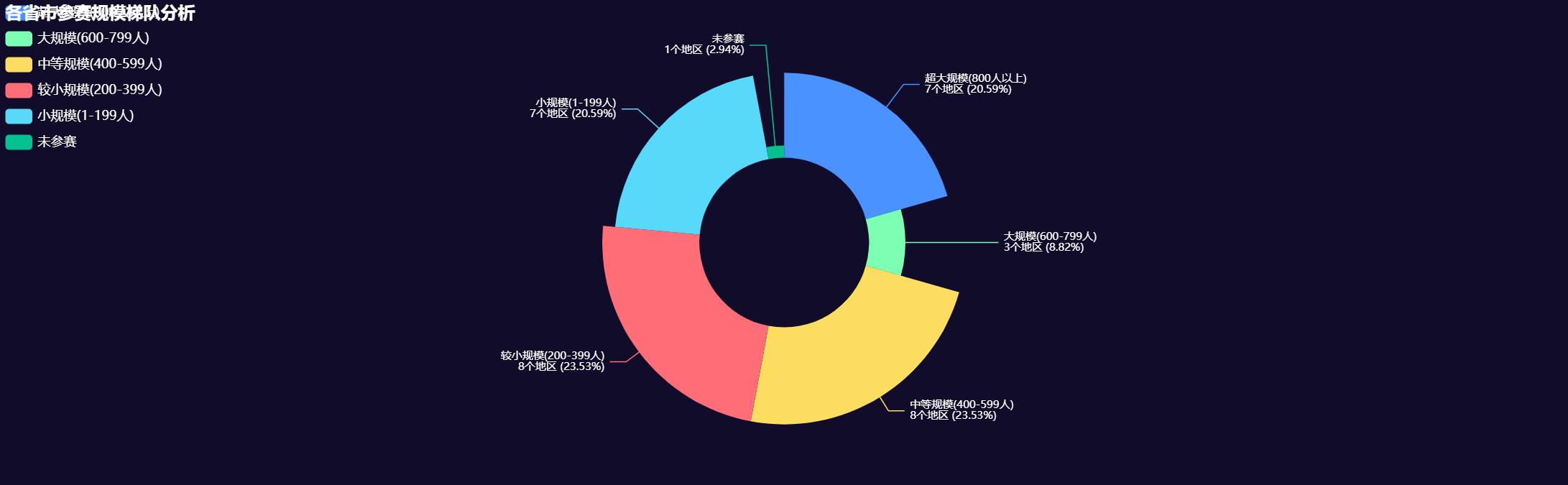
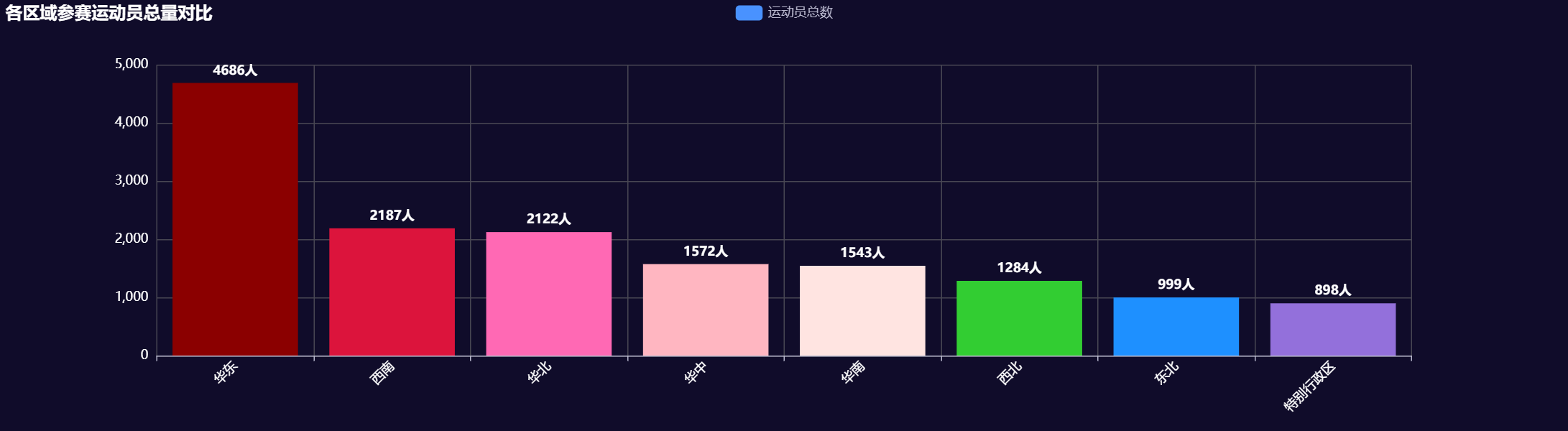
3.4 区域运动员总量对比
def create_region_athlete_comparison(athlete_data):
"""创建区域运动员总量对比图"""
# 定义区域分组
regions = {
"华东": ['山东', '江苏', '浙江', '上海', '安徽', '福建', '江西'],
"华南": ['广东', '广西', '海南'],
"华中": ['湖北', '湖南', '河南'],
"华北": ['北京', '天津', '河北', '山西', '内蒙古'],
"西南": ['四川', '贵州', '云南', '西藏', '重庆'],
"西北": ['陕西', '甘肃', '青海', '宁夏', '新疆'],
"东北": ['辽宁', '吉林', '黑龙江'],
"特别行政区": ['香港', '澳门', '台湾']
}
region_athletes = {}
for region, provinces in regions.items():
total_athletes = sum(athlete_data.get(province, 0) for province in provinces)
region_athletes[region] = total_athletes
# 转换为列表格式
region_data = [(region, count) for region, count in region_athletes.items()]
region_data.sort(key=lambda x: x[1], reverse=True)
bar = (
Bar()
.add_xaxis([x[0] for x in region_data])
.add_yaxis(
"运动员总数",
[x[1] for x in region_data]
)
.set_global_opts(
title_opts=opts.TitleOpts(
title="各区域参赛运动员总量对比"
)
)
)
return bar
四、综合大屏展示
def create_athlete_comprehensive_dashboard():
"""创建全运会运动员数据综合可视化大屏"""
page = Page(
page_title="第15届全运会各省参赛运动员规模可视化分析大屏",
layout=Page.DraggablePageLayout
)
# 添加各个图表
page.add(
create_athlete_distribution_map(athlete_map_data),
create_athlete_bar_chart(df_athletes),
create_athlete_tier_pie_chart(df_athletes),
create_region_athlete_comparison(athlete_data)
)
return page
# 生成可视化大屏
if __name__ == "__main__":
dashboard = create_athlete_comprehensive_dashboard()
dashboard.render("2025_national_games_athlete_dashboard.html")
# 输出关键统计数据
print("=== 第15届全运会参赛运动员关键统计 ===")
print(f"数据来源:各省体育代表团")
print(f"参赛地区总数: {len(athlete_data)}个")
print(f"运动员总数: {sum(athlete_data.values())}人")
print(f"平均每个地区运动员数: {sum(athlete_data.values())/len(athlete_data):.1f}人")
print(f"运动员数量中位数: {df_athletes['运动员数'].median()}人")
print(f"规模最大地区: {df_athletes.iloc[0]['地区']} ({df_athletes.iloc[0]['运动员数']}人)")
print(f"规模最小地区: {df_athletes.iloc[-1]['地区']} ({df_athletes.iloc[-1]['运动员数']}人)")
print(f"超大规模地区(800人以上): {len(df_athletes[df_athletes['运动员数'] >= 800])}个")

五、数据分析结论
5.1 关键发现:
- 明显的规模梯度:广东、山东、江苏形成第一集团,运动员数均超过800人
- 区域集中明显:华东地区运动员总数遥遥领先,占全国近三分之一
- 经济体育正相关:经济发达地区普遍参赛规模更大
- 覆盖面广泛:除台湾省外,33个行政区均有运动员参赛,体现了全运会的广泛参与性
5.2 区域分析:
- 华南地区:广东一枝独秀,以1072名运动员位居全国第一
- 华东地区:整体实力强劲,山东、江苏、浙江、上海均超过800人
- 西南地区:四川表现突出,以899人位列全国前列
- 西部地区:西藏、青海、宁夏等地区受人口基数限制,规模相对较小
5.3 规模梯队特征:
- 超大规模(800人以上):5个地区,展现雄厚体育基础
- 大规模(600-799人):4个地区,具备较强体育实力
- 中等规模(400-599人):6个地区,稳步发展体育事业
- 较小规模(200-399人):11个地区,基础体育建设阶段
- 小规模(1-199人):8个地区,特色体育发展路径
六、未来展望
运动员规模是体育事业发展的重要指标,反映了各地的体育人才培养体系和竞技体育基础。随着全运会赛程的推进,各代表团将在赛场上展现他们的训练成果。大规模代表团能否将人数优势转化为奖牌优势?小规模代表团是否会涌现黑马选手?让我们共同期待各代表团在赛场上的精彩表现!
数据说明:本分析基于各省体育代表团官方数据,体现了各地对全运会的重视程度和体育投入力度。
关注下方公众号或添加微信领取文字代码
注: 博主目前收集了6900+份相关数据集,有想要的可以领取部分数据:

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 20
20 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)