【论文阅读】BART: Denoising Sequence-to-Sequence Pre-training for NaturalLanguage Generation, Translation
Abstract
我们提出了BART,一种用于序列到序列模型预训练的去噪自编码器。BART的训练方法是:(1)用任意的噪声函数破坏文本,(2)学习一个模型来重建原始文本。它使用标准的基于transformer的神经机器翻译架构,尽管它很简单,但可以被看作是BERT(由于双向编码器),GPT(从左到右解码器)和许多其他最新的预训练方案的泛化。我们评估了许多降噪方法,通过随机打乱原始句子的顺序和使用新颖的填充方案(其中文本的跨度被单个掩码令牌替换)找到了最佳性能。BART在对文本生成进行微调时特别有效,但也适用于理解任务。它与RoBERTa在GLUE和SQuAD上的类似训练资源的表现相匹配,在一系列抽象对话、问题回答和总结任务上取得了新的最先进的结果,收益高达6 ROUGE。BART还提供了比机器翻译的反向翻译系统增加1.1 BLEU,只有目标语言预训练。我们还报道了在BART框架内复制其他预训练方案的消融实验,以更好地衡量哪些因素对任务结束表现影响最大。
1 Introduction
自监督方法在广泛的NLP任务中取得了显著的成功(Mikolov等人,2013;Peters等人,2018;Devlin等人,2019;Joshi等人,2019;Yang等人,2019;Liu等人,2019)。最成功的方法是掩码语言模型的变体,这是一种去噪的自动编码器,它被训练来重建文本,其中随机的单词子集已经被掩码掉了。最近的工作表明,通过改善掩面具令牌的分布(Joshi等人,2019)、预测掩面具token的顺序(Yang等人,2019)以及替换掩面具token的可用上下文(Dong等人,2019),可以获得收益。然而,这些方法通常侧重于特定类型的终端任务(例如跨度预测、生成等),限制了它们的适用性。
在本文中,作者提出了BART,它预训练了一个结合双向和自回归transformer的模型。BART是一个用序列到序列模型构建的去噪自动编码器,适用于非常广泛的终端任务。预训练有两个阶段(1)文本被任意的噪声函数破坏,(2)学习一个序列到序列的模型来重建原始文本。BART使用标准的基于transformer的神经机器翻译架构,尽管它很简单,但可以看作是BERT(由于双向编码器),GPT(从左到右解码器)和许多其他最新的预训练方案的推广(参见图1)。
这种设置的一个关键优势是噪声的灵活性;可以对原始文本应用任意转换,包括更改其长度。作者评估了许多降噪方法,通过随机打乱原始句子的顺序和使用新颖的填充方案找到最佳性能,其中任意长度的文本跨度(包括零长度)被单个掩码token替换。这种方法通过迫使模型对整个句子长度进行更多的推理,并对输入进行更大范围的转换,从而推广了BERT中的原始词屏蔽和下一个句子预测目标。BART在对文本生成进行微调时特别有效,但也适用于理解任务。它将RoBERTa (Liu et al., 2019)的性能与GLUE (Wang et al., 2018)和SQuAD (Rajpurkar et al., 2016)的训练资源相匹配,并在一系列抽象对话、问答和总结任务上取得了最新的结果。例如,它比以前在XSum上的工作提高了6个ROUGE的性能(Narayan et al., 2018)。
BART还开辟了对微调的新思路。我们提出了一种新的机器翻译方案,其中BART模型堆叠在几个额外的transformer层之上。这些层被训练成基本上将外语翻译成有噪声的英语。通过BART进行传播,从而使用BART作为预训练的目标端语言模型。这种方法在强大的反翻译MT基线上提高了1.1 BLEU的WMT罗马尼亚-英语基准的性能。

(a)BERT:随机标记被掩码取代,文档被双向编码。缺失的token是独立预测的,因此BERT不容易用于生成。
(b)GPT:token是自动回归预测的,这意味着GPT可以用于生成。然而,单词只能以左侧上下文为条件,因此它无法学习双向交互。
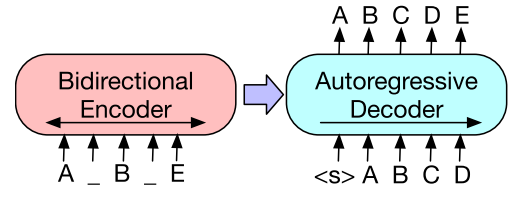
(c)BART:编码器的输入不需要与解码器的输出对齐,允许任意的噪声变换。这里,一个文档被用遮罩符号替换文本的跨度而损坏。使用双向模型对损坏的文档(左)进行编码,然后使用自回归解码器计算原始文档(右)的可能性。为了进行微调,将未损坏的文档同时输入到编码器和解码器中,我们使用解码器最终隐藏状态的表示。
图1:BART与BERT (Devlin等人,2019)和GPT (Radford等人,2018)的示意图比较。
为了更好地理解这些影响,我们还报告了一项消融分析,该分析复制了最近提出的其他训练目标。这项研究使我们能够仔细控制许多因素,包括数据和优化参数,这些因素已被证明对整体性能和训练目标的选择一样重要(Liu et al., 2019)。我们发现BART在我们考虑的所有任务中都表现出最稳定的强劲表现。
2 Model
BART是一个去噪的自动编码器,它将损坏的文档映射到它派生的原始文档。它是作为一个序列到序列模型实现的,具有损坏文本的双向编码器和从左到右的自回归解码器。对于预训练,我们优化原始文档的负对数似然。
2.1 Architecture
BART使用来自(Vaswani et al., 2017)的标准序列到序列转换器架构,除了在GPT之后,作者将ReLU激活函数修改为gelu (Hendrycks & Gimpel, 2016)并初始化N(0,0.02)的参数。
对于我们的基本模型,我们在编码器和解码器中使用6层,对于我们的大型模型,我们在每个模型中使用12层。该架构与BERT中使用的架构密切相关,但有以下区别:(1)解码器的每一层在编码器的最终隐藏层上额外执行交叉注意(如在变压器序列到序列模型中);(2) BERT在单词预测之前使用了一个额外的前馈网络,而BART没有。总的来说,BART比同等大小的BERT模型多包含大约10%的参数。
2.2 Pre-training BART
BART的训练方法是先破坏文档,然后优化重建损失——解码器输出和原始文档之间的交叉熵。现有的去噪自动编码器是针对特定的去噪方案量身定制的,BART允许我们应用任何类型的文档损坏。在极端情况下,关于源的所有信息都丢失了,BART相当于语言模型。
作者尝试了一些先前提出的和新颖的转换,但作者相信还有其他新替代方案的巨大发展潜力。我们使用的转换总结如下,示例如图2所示。
Token Masking 在BERT (Devlin et al., 2019)之后,随机Token被采样并替换为[MASK]元素。
Token Deletion 从输入中删除随机token。与token屏蔽相反,模型必须确定哪些位置缺少输入。
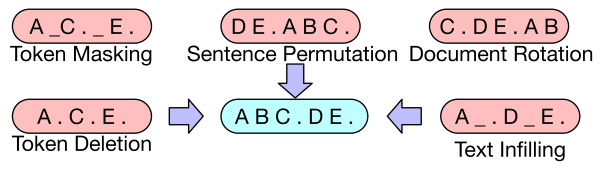
图2:对我们实验的输入进行噪声处理的转换。这些转换可以组合起来。
Text Infilling 对许多文本跨度进行采样,跨度长度取自泊松分布(λ = 3)。每个span被替换为单个[MASK]token。0长度的跨度对应于[MASK]token的插入。文本填充的灵感来自SpanBERT (Joshi等人,2019),但SpanBERT从不同的(固定的几何)分布中采样跨度长度,并用长度完全相同的[MASK]token序列替换每个跨度。
Sentence Permutation 文档根据句号被分成句子,这些句子以随机顺序进行洗牌。
Document Rotation 随机均匀地选择一个token,并旋转文档,使其以该token开始。这个任务训练模型识别文档的开头。
3 Fine-tuning BART
BART生成的表示可以以多种方式用于下游应用程序。
3.1 Sequence Classification Tasks
对于序列分类任务,将相同的输入馈送到编码器和解码器中,并将最终解码器token的最终隐藏状态馈送到新的多类线性分类器中。这种方法与BERT中的CLStoken有关;然而,作者在末尾添加了额外的token,以便解码器中令牌的表示可以关注来自完整输入的解码器状态(图3a)。
3.2 Token Classification Tasks
对于token分类任务,例如SQuAD的应答端点分类,我们将完整的文档提供给编码器和解码器,并使用解码器的顶部隐藏状态作为每个单词的表示。这种表示用于对token进行分类。
3.3 Sequence Generation Tasks
因为BART有一个自回归解码器,它可以直接微调序列生成任务,如抽象的问题回答和摘要。在这两种任务中,信息都是从输入中复制但经过处理,这与去噪预训练目标密切相关。这里,编码器输入是输入序列,解码器自回归生成输出。
3.4 Machine Translation
作者还探索了使用BART来改进机器翻译解码器以翻译成英语。之前的工作Edunov等人(2019)表明,可以通过合并预训练的编码器来改进模型,但在解码器中使用预训练的语言模型的收益有限。作者表明,通过添加一组从bittext学习到的新的编码器参数,可以将整个BART模型(编码器和解码器)用作机器翻译的单个预训练解码器(见图3b)。
更准确地说,作者用一个新的随机初始化编码器替换BART的编码器嵌入层。该模型是端到端训练的,它训练新的编码器将外来词映射到BART可以去噪的输入中。新的编码器可以使用与原始BART模型不同的词汇表。
作者分两步训练源编码器,在这两种情况下,从BART模型的输出反向传播交叉熵损失。在第一步中,我们冻结了BART的大部分参数,只更新了随机初始化的源编码器、BART的位置嵌入和BART编码器第一层的自关注输入投影矩阵。在第二步中,我们为少量迭代训练所有模型参数。
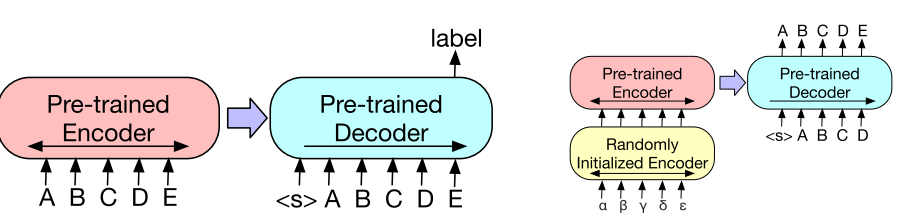
图3:对BART进行分类和翻译微调。
(a)为了将BART用于分类问题,将相同的输入馈送到编码器和解码器中,并使用最终输出的表示。
(b)对于机器翻译,我们学习了一个小的附加编码器,它取代了BART中的词嵌入,新的编码器可以使用不相交的词汇表。
4 Comparing Pre-training Objectives
BART在预训练期间支持的降噪方案比以前的工作范围大得多。我们使用基本大小模型(6个编码器和6个解码器层,隐藏大小为768)比较了一系列选项,并对我们的任务的代表性子集进行了评估。
4.1 Comparison Objectives
虽然已经提出了许多预训练目标,但很难对这些目标进行公平的比较,至少部分原因是由于训练数据、训练资源、模型之间的架构差异和微调过程的差异。作者重新实施最近提出了用于判别和生成任务的强预训练方法。作者的目标是尽可能地控制与预训练目标无关的差异。然而,为了提高性能,作者确实对学习率和层归一化的使用做了一些小的改变(针对每个目标分别调整这些)。作为参考,作者将作者的实现与BERT发布的数字进行了比较,BERT也在书籍和维基百科数据的组合上训练了1M步。作者比较了以下几种方法:
Language Model 与GPT类似(Radford et al., 2018),作者训练了一个从左到右的Transformer语言模型。这个模型相当于BART解码器,没有交叉注意。
Permuted Language Model 基于XLNet (Yang et al., 2019),作者对1/6的token进行采样,并以随机顺序自回归生成它们。为了与其他模型保持一致,作者没有实现XLNet分段之间的相对位置嵌入或注意。
Masked Language Model 根据BERT (Devlin等人,2019),作者用[MASK]符号替换了15%的token,并训练模型独立预测原始token。
Multitask Masked Language Model 与UniLM (Dong et al., 2019)一样,作者用额外的自注意掩码训练了一个掩码语言模型。自我注意掩码按以下比例随机选择:1/6从左到右,1/6从右到左,1/3未掩码,1/3前50%未掩码,剩余部分从左到右掩码。
Masked Seq-to-Seq 受MASS (Song et al., 2019)的启发,作者屏蔽了一个包含50% token的跨度,并训练了一个序列到序列模型来预测被屏蔽的token。
对于permed LM, mask LM和Multitask mask LM,我们使用两流注意力(Yang等人,2019)来有效地计算序列输出部分的可能性(在输出上使用对角自注意掩码来预测单词从左到右)。
我们尝试(1)将任务视为标准的序列到序列问题,其中编码器的源输入和目标是解码器的输出,或者(2)将源作为前缀添加到解码器的目标,仅在序列的目标部分上损失。我们发现前者对BART模型效果更好,后者对其他模型效果更好。
为了最直接地比较我们的模型对其微调目标(人类文本的对数似然)建模的能力,我们在表1中报告了困惑。
4.2 Tasks
SQuAD (Rajpurkar et al., 2016)对维基百科段落进行抽取式问答任务。答案是从给定文档上下文中提取的文本跨度。与BERT (Devlin等人,2019)类似,我们使用连接的问题和上下文作为BART编码器的输入,并将它们传递给解码器。该模型包括分类器来预测每个标记的开始和结束索引。
MNLI (Williams et al., 2017),用于预测一个句子是否包含另一个句子的文本分类任务。经过微调的模型将两个句子与附加的EOS令牌连接起来,并将它们传递给BART编码器和解码器。与BERT相反,EOS令牌的表示用于对句子关系进行分类。
ELI5 (Fan et al., 2019),一个长格式抽象问答数据集。模型根据问题和支持文档的连接来生成答案。
XSum (Narayan et al., 2018),一个具有高度抽象摘要的新闻摘要数据集。
ConvAI2 (Dinan et al., 2019),对话响应生成任务,以上下文和角色为条件。
CNN/DM (Hermann et al., 2015),新闻摘要数据集。这里的摘要通常与源句密切相关。
4.3 Results
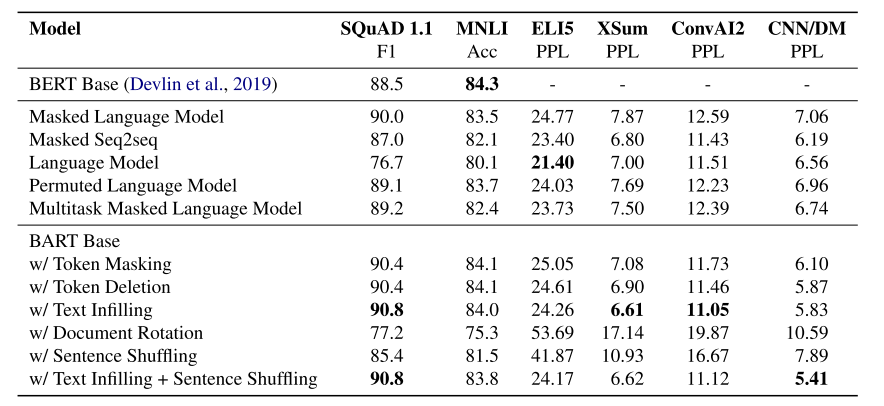
表1:预训练目标对比。所有模型的大小都相当,并且在书籍和维基百科数据的组合上进行了1M步的训练。底部两个块中的条目使用相同的代码库在相同的数据上进行训练,并使用相同的过程进行微调。第二个区块的条目受到先前工作中提出的预训练目标的启发,但已简化为专注于评估目标(参见§4.1)。不同任务的性能差异很大,但是具有文本填充的BART模型表现出最一致的强大性能。
预训练方法在不同任务中的表现差异很大 预训练方法的有效性高度依赖于任务。例如,一个简单的语言模型实现了最好的ELI5性能,但是最差的SQUAD结果。
token屏蔽至关重要 基于旋转文档或排列句子的预训练目标在孤立情况下表现不佳。成功的方法要么使用token删除或屏蔽,要么使用自关注屏蔽。删除在生成任务上的表现似乎优于屏蔽。
从左到右的预训练提高了生成 遮罩语言模型和排列语言模型在生成方面的表现不如其他模型好,并且是我们认为在预训练期间不包括从左到右自回归语言建模的唯一模型。
双向编码器对SQuAD至关重要 正如之前的工作(Devlin et al., 2019)所指出的那样,仅从左到右解码器在SQuAD上的表现很差,因为未来的上下文对分类决策至关重要。然而,BART仅用一半的双向层数就实现了类似的性能。
训练前的目标并不是唯一重要的因素 我们的排列语言模型的表现不如XLNet (Yang et al., 2019)。其中一些差异可能是由于没有包括其他架构改进,例如相对位置嵌入或段级递归。
纯语言模型在ELI5上表现最好 ELI5数据集是一个异常值,比其他任务具有更高的困惑,并且是唯一一个其他模型优于BART的生成任务。纯语言模型表现最好,这表明当输出仅受输入的松散约束时,BART的效率较低。
BART实现了最稳定的强劲性能。 除了ELI5,使用文本填充的BART模型在所有任务上都表现良好。
5 Large-scale Pre-training Experiments
最近的工作表明,当预训练扩展到大批量时,下游性能可以显着提高(Yang等人,2019;Liu等人,2019)和语料库。为了测试BART在这种情况下的表现,并为下游任务创建一个有用的模型,作者使用与RoBERTa模型相同的规模来训练BART。
5.1 Experimental Setup
作者预训练了一个大型模型,每个编码器和解码器都有12层,隐藏大小为1024。遵循RoBERTa (Liu et al., 2019),作者使用8000个批大小,并训练模型500,000步。文档使用与GPT-2相同的字节对编码进行标记(Radford et al., 2019)。基于第§4节的结果,作者使用了文本填充和句子排列的组合。作者屏蔽了每个文档中30%的标记,并排列了所有的句子。
虽然句子排列仅在CNN/DM摘要数据集上显示出显著的加性增益,但作者假设更大的预训练模型可能能够更好地从该任务中学习。
为了帮助模型更好地拟合数据,作者在最后10%的训练步骤中禁用了dropout。作者使用与Liu等人(2019)相同的预训练数据,包括160Gb的新闻、书籍、故事和网络文本。
5.2 Discriminative Tasks
表2比较了BART与最近几种方法在SQuAD和GLUE任务上的性能(Warstadt等人,2018;Socher等人,2013;Dolan和Brockett, 2005; Agirre等人,2007;Williams等人,2018;Dagan等人,2006;Levesque等人,2011)。最直接可比较的基线是RoBERTa,它是用相同的资源进行预训练的,但目标不同。总的来说,BART的表现相似,在大多数任务上,模型之间只有很小的差异。这表明BART在生成任务上的改进并不是以牺牲分类性能为代价的。
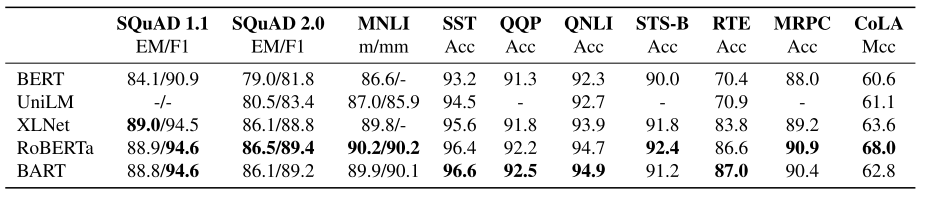
表2:在SQuAD和GLUE任务上的大型模型的结果。BART的性能与RoBERTa和XLNet相当,这表明BART的单向解码器层不会降低判别任务的性能。
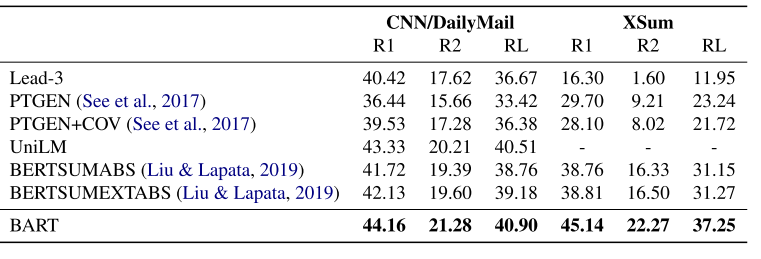
表3:两个标准汇总数据集的结果。BART在两个任务和所有指标的总结上优于以前的工作,在更抽象的数据集上获得了大约6分的收益。
5.3 Generation Tasks
作者还试验了几个文本生成任务。BART作为从输入到输出文本的标准序列到序列模型进行了微调。在微调过程中,我们使用标签平滑交叉熵损失(Pereyra等人,2017),平滑参数设置为0.1。在生成过程中,我们将光束大小设置为5,在光束搜索中删除重复的三元组,并在验证集上使用min-len, max-len,长度惩罚来调整模型(Fan et al., 2017)。
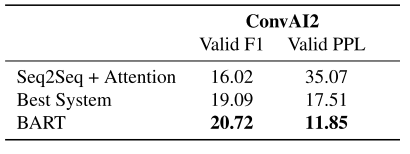
表4:BART在会话响应生成方面优于以前的工作。基于ConvAI2的官方标记器对困惑进行了重新规范化。
Summarization 为了与最先进的摘要进行比较,我们给出了CNN/DailyMail和XSum这两个具有不同属性的摘要数据集的结果。CNN/DailyMail的摘要往往与源句相似。提取模型在这里做得很好,甚至前三个源句子的基线也是高度竞争的。然而,BART比所有现有的工作都要好。
相反,XSum是高度抽象的,抽取模型的性能很差。BART在所有ROUGE指标上比以前最好的工作(利用BERT)高出大约6.0分,这代表了在这个问题上性能的显著进步。定性上,样品质量高(见§6)。
Dialogue 我们评估了CONVAI2上的对话响应生成(Dinan等人,2019),其中代理必须根据之前的上下文和文本指定的角色生成响应。BART在两个自动化指标上优于以前的工作。
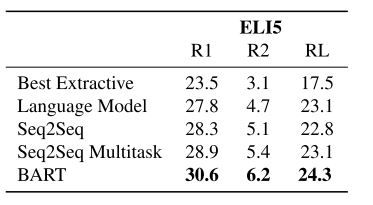
表5:BART在具有挑战性的ELI5抽象问答数据集上获得了最先进的结果。比较模型来自Fan等人(2019)。

表6:基线和BART在WMT ' 16 RO-EN上的性能(BLEU)与反向翻译数据的增强。BART通过使用单语英语预训练来改进强回译(BT)基线。
摘要式的质量保证 作者使用最近提出的ELI5数据集来测试模型生成长自由格式答案的能力。我们发现BART比以前最好的工作高出1.2 ROUGE-L,但数据集仍然具有挑战性,因为答案仅由问题弱指定。
5.4 Translation
作者还评估了WMT16罗马尼亚英语的性能,并使用了Sennrich等人(2016)的反向翻译数据。作者使用6层变压器源编码器将罗马尼亚语映射为BART能够降噪的英语表示,遵循§3.4中介绍的方法。实验结果见表6。作者将结果与Transformerlarge设置(基线行)的基线Transformer架构(Vaswani et al., 2017)进行比较。作者在固定BART和调优BART行中展示了模型的两个步骤的性能。对于每一行,作者都对原始的WMT16罗马尼亚语-英语进行了反翻译数据增强实验。作者使用5的光束宽度和α = 1的长度惩罚。初步结果表明,如果没有反向翻译数据,作者的方法效果较差,并且容易过度拟合——未来的工作应该探索额外的正则化技术。
6 Qualitative Analysis
BART在总结指标上有很大的改进,比之前的最先进的技术提高了6分。为了了解BART在自动化指标之外的性能,我们定性地分析了它的世代。
表7显示了BART生成的示例摘要。示例取自创建预训练语料库后发布的WikiNews文章,以消除模型训练数据中出现所描述事件的可能性。根据Narayan et al.(2018),我们在总结文章之前删除了文章的第一句话,因此没有简单的摘录摘要。
不出所料,模型输出是流利且符合语法的英语。然而,模型输出也是高度抽象的,很少有从输入复制的短语。输出通常也是事实准确的,并且集成了来自整个输入文档的支持证据和背景知识(例如,正确填写姓名,或推断PG&E在加利福尼亚运营)。在第一个例子中,推断鱼类保护珊瑚礁免受全球变暖的影响需要从文本中进行非平凡的推断。然而,声称这项工作发表在《科学》杂志上的说法并没有得到来源的支持。
这些样本表明BART预训练已经学习了自然语言理解和生成的强大组合。
7 Related Work
早期的预训练方法是基于语言模型的。GPT (Radford et al., 2018)只对左向上下文建模,这对于某些任务来说是有问题的。ELMo (Peters et al., 2018)将仅左和仅右表示连接起来,但不预训练这些特征之间的相互作用。Radford等人(2019)证明,非常大的语言模型可以作为无监督多任务模型。
BERT (Devlin et al., 2019)引入了掩模语言模型,它允许预训练来学习左右上下文词之间的交互。最近的研究表明,通过更长的训练时间(Liu et al., 2019)、跨层绑定参数(Lan et al., 2019)以及屏蔽跨度而不是单词(Joshi et al., 2019),可以实现非常强的性能。预测不是自动回归的,这降低了BERT对生成任务的有效性。
UniLM (Dong et al., 2019)用一组掩模对BERT进行微调,其中一些掩模只允许向左上下文。像BART一样,这使得UniLM既可以用于生成任务,也可以用于判别任务。不同的是,UniLM的预测是条件独立的,而BART的预测是自回归的。BART减少了预训练和生成任务之间的不匹配,因为解码器总是在未损坏的上下文上进行训练。MASS (Song et al., 2019)可能是与BART最相似的模型。一个连续的标记被屏蔽的输入序列被映射到一个由缺失标记组成的序列。MASS对于判别任务不太有效,因为不相交的标记集被馈送到编码器和解码器中。
xml - net (Yang et al., 2019)通过按排列顺序自动回归预测掩码令牌来扩展BERT。这个目标允许对左右上下文进行预测。相比之下,BART解码器在预训练期间从左到右工作,与生成时的设置相匹配。
有几篇论文探讨了使用预训练表征来改进机器翻译。最大的改进来自源语言和目标语言的预训练(Song et al., 2019; Lample & Conneau, 2019),但这需要对所有感兴趣的语言进行预训练。其他研究表明,编码器可以使用预训练的表示来改进(Edunov等人,2019),但解码器的收益更有限。我们展示了如何使用BART来改进机器翻译解码器。
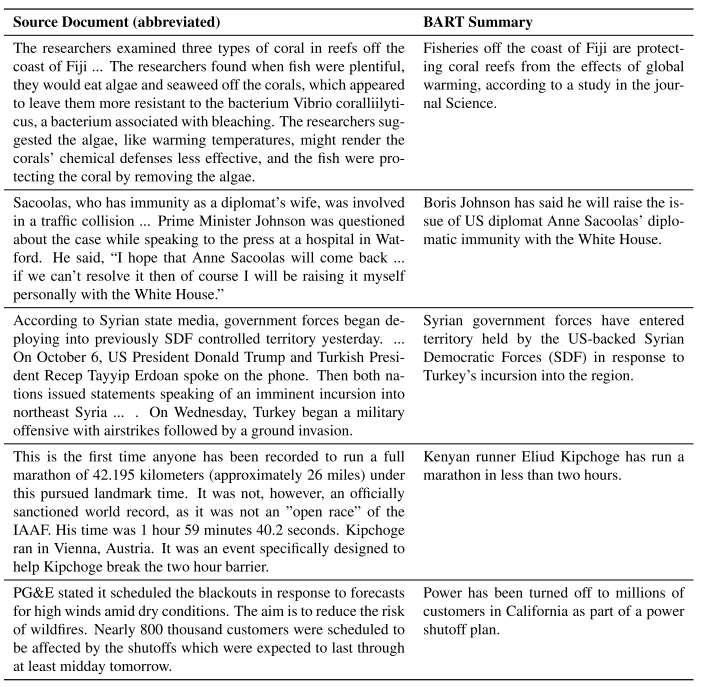
表7:WikiNews文章上经过xsum调优的BART模型的示例摘要。为清楚起见,只显示了来源的相关摘录。摘要结合了整个文章的信息和先前的知识。
8 Conclusions
作者引入了BART,这是一种预训练方法,可以学习将损坏的文档映射到原始文档。BART在判别性任务上实现了与RoBERTa相似的性能,同时在许多文本生成任务上实现了最新的结果。未来的工作应该探索用于预训练的损坏文档的新方法,也许可以将它们裁剪为特定的最终任务。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 18
18 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)