【Python大数据+AI毕设实战】豆瓣电影用户行为与市场趋势分析系统、计算机毕业设计、包括数据爬取、Spark、数据分析、数据可视化、Hadoop、实战教学
【Python大数据+AI毕设实战】豆瓣电影用户行为与市场趋势分析系统、计算机毕业设计、包括数据爬取、Spark、数据分析、数据可视化、Hadoop、实战教学
🎓 作者:计算机毕设小月哥 | 软件开发专家
🖥️ 简介:8年计算机软件程序开发经验。精通Java、Python、微信小程序、安卓、大数据、PHP、.NET|C#、Golang等技术栈。
🛠️ 专业服务 🛠️
- 需求定制化开发
- 源码提供与讲解
- 技术文档撰写(指导计算机毕设选题【新颖+创新】、任务书、开题报告、文献综述、外文翻译等)
- 项目答辩演示PPT制作
🌟 欢迎:点赞 👍 收藏 ⭐ 评论 📝
👇🏻 精选专栏推荐 👇🏻 欢迎订阅关注!
大数据实战项目
PHP|C#.NET|Golang实战项目
微信小程序|安卓实战项目
Python实战项目
Java实战项目
🍅 ↓↓主页获取源码联系↓↓🍅
这里写目录标题
基于大数据的豆瓣电影用户行为与市场趋势分析系统-功能介绍
本系统是一个基于Python大数据技术栈的豆瓣电影用户行为与市场趋势分析系统,旨在深度挖掘海量电影数据背后的潜在价值。系统后端以强大的Hadoop生态为基石,利用Spark分布式计算框架对大规模豆瓣电影数据集进行高效处理与复杂分析,核心处理逻辑通过Python语言实现,并借助Django框架构建稳健的API服务。前端则采用现代化的Vue.js与ElementUI构建交互界面,结合Echarts可视化库,将枯燥的数据转化为直观生动的图表。系统功能全面,覆盖了从电影基础特征统计(如类型、国家、时长分布)到深度的用户行为模式探究(如评分习惯、评论情感分析),再到高级的市场趋势洞察(如导演影响力、演员号召力分析)等多个维度。通过对用户评论的文本挖掘与情感倾向判断,系统能够量化电影的口碑效应;而基于电影多维度特征的聚类分析,则能发现相似作品群组,为个性化推荐提供数据支持。整个系统构建了一个从数据采集、清洗、存储、计算分析到最终可视化展示的完整大数据处理流水线,为理解电影市场动态和用户偏好提供了一个全面而深入的解决方案。
基于大数据的豆瓣电影用户行为与市场趋势分析系统-选题背景意义
选题背景
随着互联网的普及和在线影评平台的兴起,观众的表达欲和参与感被空前激发,像豆瓣这样的社区汇聚了海量的电影评分、评论和相关元数据,形成了一座蕴藏着巨大价值的金矿。这些数据不再是孤立的信息点,而是共同描绘出了一幅生动的电影市场全景图和复杂的用户行为图谱。传统的分析方法,如抽样调查或简单的统计,在面对如此规模和复杂度的数据时显得力不从心,难以捕捉到深层次的关联和隐藏的模式。如何有效地处理和分析这些非结构化与半结构化的海量数据,从中提炼出对电影创作、市场发行和用户观影有指导意义的洞察,成为了一个极具挑战且价值非凡的课题。在这样的背景下,运用大数据技术,特别是以Spark为核心的分布式计算框架,来对豆瓣电影数据进行系统性的深度分析,不仅技术上可行,也顺应了数据驱动决策的时代潮流,为理解和预测电影市场提供了全新的视角和工具。
选题意义
这个课题的意义在于,它不仅仅是一个技术演练,更是一次将大数据分析方法应用于具体文化领域的实践探索。对于电影行业的从业者来说,本系统的分析结果能提供一个相对客观的数据参考,比如哪种类型的电影更受观众青睐,哪些导演的作品具有稳定的市场号召力,或者上映时间的选择是否会影响电影的热度,这些都能为他们的投资、制作和宣发策略提供一些启发。从技术学习者的角度看,这个项目完整地走了一遍大数据处理的流程,从使用Hadoop进行分布式存储,到运用Spark进行高效的数据清洗、转换和复杂计算,再到将结果通过Web框架进行可视化呈现,这无疑是对全栈大数据开发能力的一次综合锻炼。可以说,这个系统为理解用户行为和市场趋势提供了一个数据驱动的视角,虽然它得出的结论可能还比较初步,但它所展示的分析方法和思路,对于未来更深入的研究或者类似的商业分析项目,都具有一定的借鉴价值。它证明了即使是学生级别的毕业设计,也能够利用开源的大数据工具,对真实世界的复杂问题做出有意义的分析尝试。
基于大数据的豆瓣电影用户行为与市场趋势分析系统-技术选型
大数据框架:Hadoop+Spark(本次没用Hive,支持定制)
开发语言:Python+Java(两个版本都支持)
后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持)
前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery
详细技术点:Hadoop、HDFS、Spark、Spark SQL、Pandas、NumPy
数据库:MySQL
基于大数据的豆瓣电影用户行为与市场趋势分析系统-图片展示

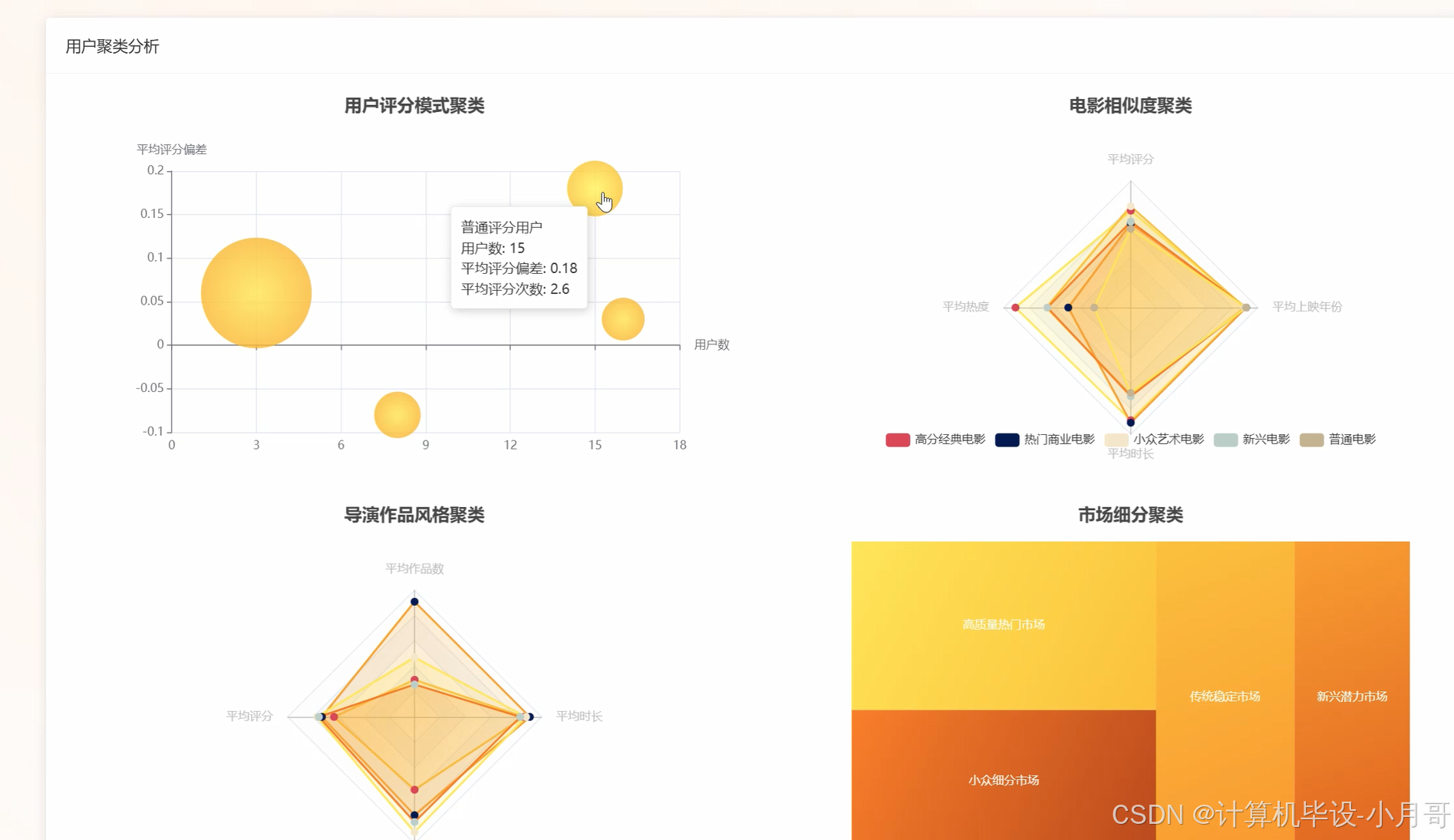





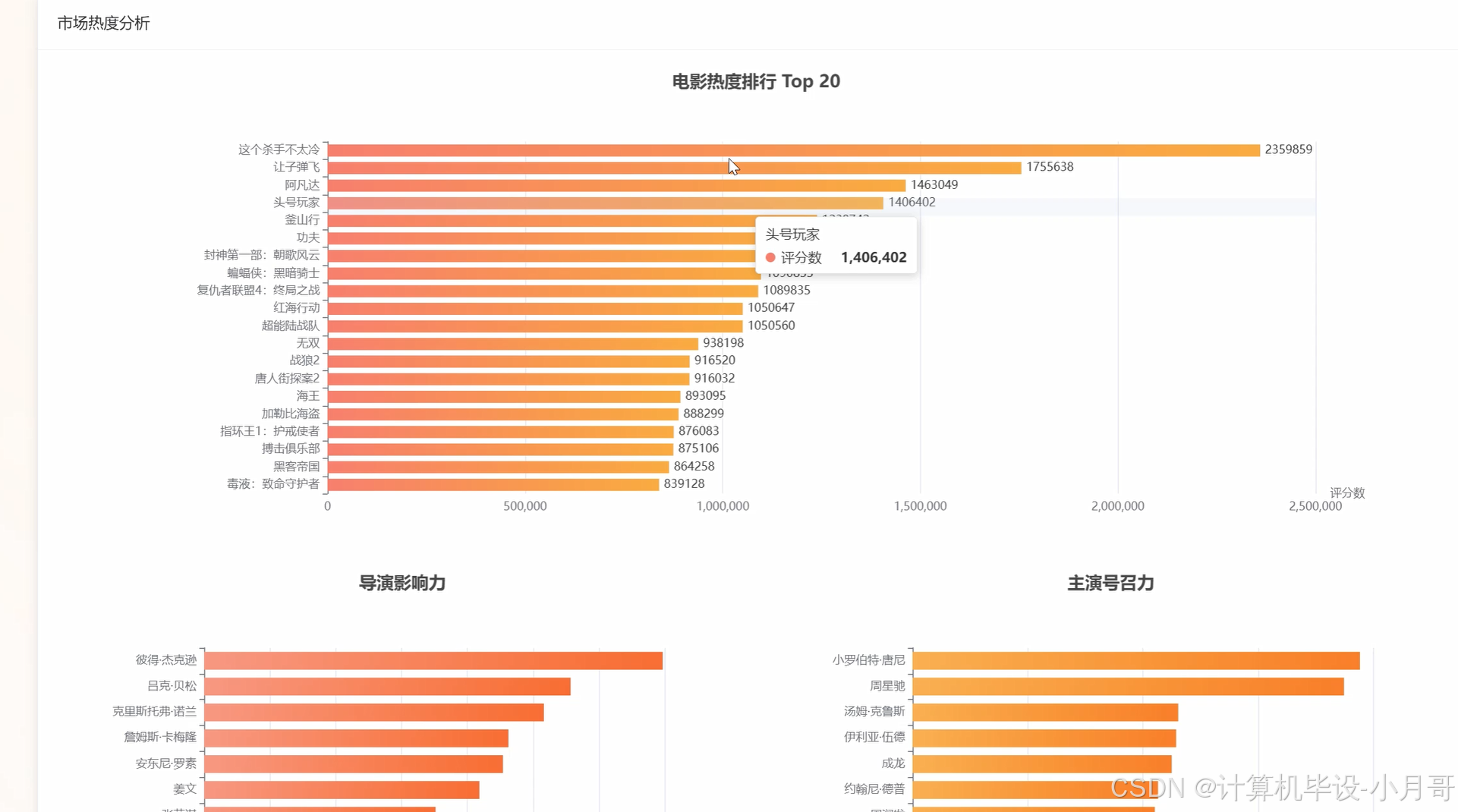
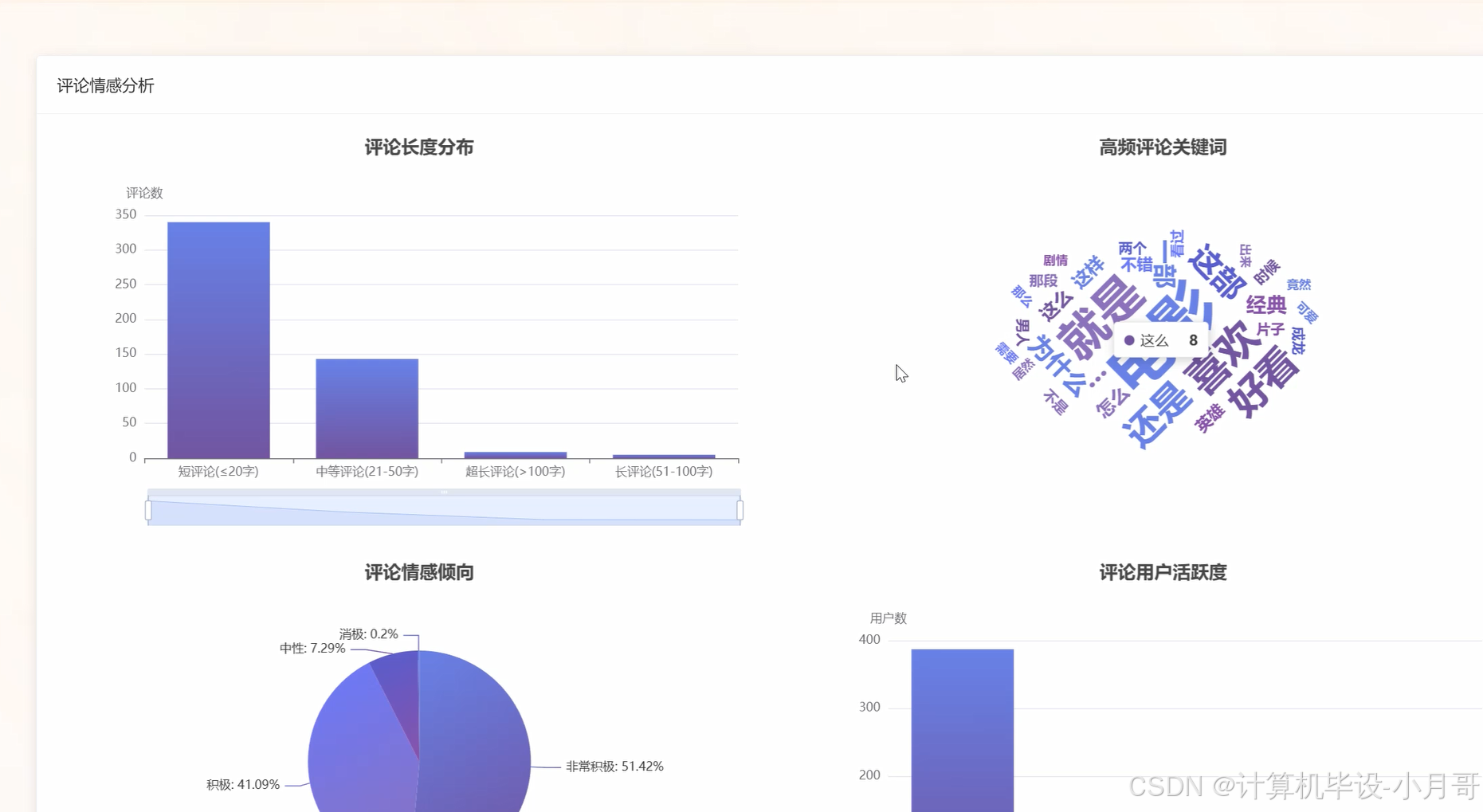
基于大数据的豆瓣电影用户行为与市场趋势分析系统-代码展示
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, explode, split, avg, count, regexp_replace, when, lit, udf
from pyspark.sql.types import IntegerType, StringType
from pyspark.ml.feature import VectorAssembler, StringIndexer
from pyspark.ml.clustering import KMeans
# 核心功能1: 电影类型与评分关系分析 (处理多值字段并聚合)
def analyze_genre_rating_relation(df):
# 处理多值类型字段,将" / "分隔的类型拆分为多行
df_exploded = df.withColumn("single_genre", explode(split(col("genre"), " / ")))
# 过滤掉空或未知的类型
df_filtered = df_exploded.filter(col("single_genre").isNotNull() & (col("single_genre") != ""))
# 按类型分组,计算平均评分和电影数量
genre_analysis = df_filtered.groupBy("single_genre") \
.agg(
avg(col("douban_rating")).alias("avg_rating"),
count(col("id")).alias("movie_count")
)
# 按平均评分降序排列,并格式化输出
result_df = genre_analysis.withColumn("avg_rating", col("avg_rating").cast("decimal(3,2)")) \
.orderBy(col("avg_rating").desc())
result_df.show()
return result_df
# 核心功能2: 用户评论情感倾向分析 (使用UDF进行简单情感判断)
def analyze_comment_sentiment(df):
# 定义简单的情感词典
positive_words = ["好", "棒", "喜欢", "优秀", "经典", "完美", "震撼", "感动", "推荐", "不错"]
negative_words = ["差", "烂", "糟糕", "失望", "无聊", "垃圾", "难看", "浪费时间", "不喜欢", "不好"]
# 定义用户自定义函数(UDF)进行情感打分
def calculate_sentiment(comment):
if not comment or comment == "未知":
return 0
score = 0
for word in positive_words:
if word in comment:
score += 1
for word in negative_words:
if word in comment:
score -= 1
return score
# 注册UDF
sentiment_udf = udf(calculate_sentiment, IntegerType())
# 应用UDF并创建情感标签列
df_with_score = df.withColumn("sentiment_score", sentiment_udf(col("comment")))
df_with_label = df_with_score.withColumn("sentiment_label",
when(col("sentiment_score") > 0, "正面")
.when(col("sentiment_score") < 0, "负面")
.otherwise("中性")
)
# 统计各情感倾向的数量
sentiment_analysis = df_with_label.groupBy("sentiment_label") \
.agg(count(col("id")).alias("comment_count")) \
.orderBy(col("comment_count").desc())
sentiment_analysis.show()
return sentiment_analysis
# 核心功能3: 基于多维度特征的电影聚类分析 (使用Spark ML)
def perform_movie_clustering(df):
# 数据预处理:选择特征并处理空值
clustering_df = df.select("douban_rating", "duration", "rating_count", "genre") \
.filter(col("douban_rating") > 0) \
.fillna({"duration": 90, "rating_count": 0})
# 将类型字符串转换为数值索引
indexer = StringIndexer(inputCol="genre", outputCol="genre_index", handleInvalid="keep")
indexed_df = indexer.fit(clustering_df).transform(clustering_df)
# 使用VectorAssembler将特征合并为一个特征向量
assembler = VectorAssembler(
inputCols=["douban_rating", "duration", "rating_count", "genre_index"],
outputCol="features"
)
assembled_df = assembler.transform(indexed_df)
# 训练K-Means模型,这里设置k=3,即将电影聚为3类
kmeans = KMeans(featuresCol="features", predictionCol="cluster", k=3, seed=1)
model = kmeans.fit(assembled_df)
# 使用模型进行预测
clustered_df = model.transform(assembled_df)
# 展示聚类结果,查看每个簇的平均特征
cluster_analysis = clustered_df.groupBy("cluster") \
.agg(
avg(col("douban_rating")).alias("avg_rating"),
avg(col("duration")).alias("avg_duration"),
avg(col("rating_count")).alias("avg_rating_count")
).orderBy("cluster")
cluster_analysis.show()
return cluster_analysis
基于大数据的豆瓣电影用户行为与市场趋势分析系统-结语
🌟 欢迎:点赞 👍 收藏 ⭐ 评论 📝
👇🏻 精选专栏推荐 👇🏻 欢迎订阅关注!
大数据实战项目
PHP|C#.NET|Golang实战项目
微信小程序|安卓实战项目
Python实战项目
Java实战项目
🍅 ↓↓主页获取源码联系↓↓🍅

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 20
20 0
0- 0



 已为社区贡献42条内容
已为社区贡献42条内容

所有评论(0)