【硬核干货】从ReAct到IterResearch:让大模型学会“边做边重构思维“,小白也能玩转长程推理!
在正式介绍我们的工作之前,我想先通过自问自答的形式分享一下自己关于long-horizon agent浅陋的思考过程,希望对读者在某些方面有所启发。IterResearch 让 agent 学会“边做边重构思维”,在有限的上下文中实现无限的推理深度。
论文信息

论文题目: 《IterResearch: Rethinking Long-Horizon Agents via Markovian State Reconstruction》
论文链接: https://huggingface.co/papers/2511.07327
📝 写在前面
在正式介绍我们的工作之前,我想先通过自问自答的形式分享一下自己关于long-horizon agent浅陋的思考过程,希望对读者在某些方面有所启发。
1. 为什么要让 agent 进行长期的工具调用?
(1) 因为信息是稀疏的,路径是曲折的。
互联网上的关键信息往往密度低、分布散、质量参差;代码问题也常常是"定位难、修起来快"的典型长尾。这意味着 agent 需要反复检索、比对、验证、回溯,不断用工具来缩小不确定性。在这类场景中,更长的交互预算 往往= 更大的探索 or 更多的试错空间,从而带来更高的解题上限。
(2) 因为单纯的ReAct的“单上下文堆叠”模式在长程场景会快速“自我窒息”
近期大量工作在探索长期工具调用,令人印象深刻的是字节的Context Folding[1](当然还有类似的工作,在此不一一列举,欢迎大家补充)。原因很直接:在 deep research 中,上下文长度已成为 long-horizon 任务的硬约束。传统 ReAct 范式[2] 将每轮的思考(reasoning)与工具返回(tool response)持续追加至同一上下文,这种‘线性堆叠式记忆’在长程任务中会不可避免地触发两种结构性病灶:
- 上下文窒息(context suffocation):总上下文长度是有限的,历史信息不断堆积会挤占接下来的推理预算,导致生成被迫“短平快”,最终走向早结论/浅结论。
- 噪声污染(noise contamination):大量网页摘要、早期错误探索与无关线索(即便经过关键信息抽取[3])会被永久写入上下文,产生级联干扰,信噪比持续走低。
为了缓解这些问题,社区逐渐提出了 folding、summary 等策略[1, 4],尝试“补救”岌岌可危,濒临崩溃的上下文,希望给后续的推理维持一个干净的工作空间。
(3) 为未来的agent做好准备
在可以预见的未来,面向真实使用的agent不会只工作几分钟或几十步,而是跨天、跨会话、跨任务地持续运行:既要保持状态,又要不断进化。在目前的技术下,即便给到256K甚至更长的上下文,以ReAct“堆上下文换能力”的模式,在周、月、甚至更久周期的工作面前仍显脆弱。总之,个人浅薄的认为:真正的长程智能,离不开“长期的、可扩展的工具调用”。这不是在炫技,故意拉长轨迹,而是在逼近现实世界问题的复杂度。
因此,在目前long-horizon agent场景下,传统的ReAct模式似乎值得被重新审视。我们是不是能有一种“边做边重置工作空间”的范式,让推理能力不随交互步数衰减。
🎯 IterResearch
在长程推理(long-horizon reasoning)中,上下文窒息与噪声污染几乎是目前开源方案的deep research agents 难以逃避的结构性问题。传统 ReAct 范式将每一轮的思考(reasoning)与工具调用结果(tool response)不断追加到同一上下文中,导致上下文迅速膨胀,推理空间被压缩、关键信号被噪声淹没,最终引发性能退化。
🚀 我们的重新思考:从「堆叠上下文」到「重构状态」
在这篇工作中,我们重新审视了这种“单上下文堆叠”模式,提出了新的 IterResearch 范式,对 long-horizon agent 的推理过程进行了重构。我们将长程研究过程形式化为一个 马尔可夫决策过程(Markov Decision Process, MDP):
与传统 ReAct 不同,IterResearch 不再简单堆叠历史,而是通过一个持续进化的 演进式报告(evolving report) 来:
- 综合已有成果
- 压缩无关信息
- 更新推理状态
从而让模型始终在一个**恒定复杂度(O(1) 级别)**的、干净且稳定的工作区间中进行推理。
这并不意味着Report长度固定,而是模型的“核心记忆or核心工作空间”不会随着交互步数线性增长,从而在理论上具备「无限深度的探索能力」。
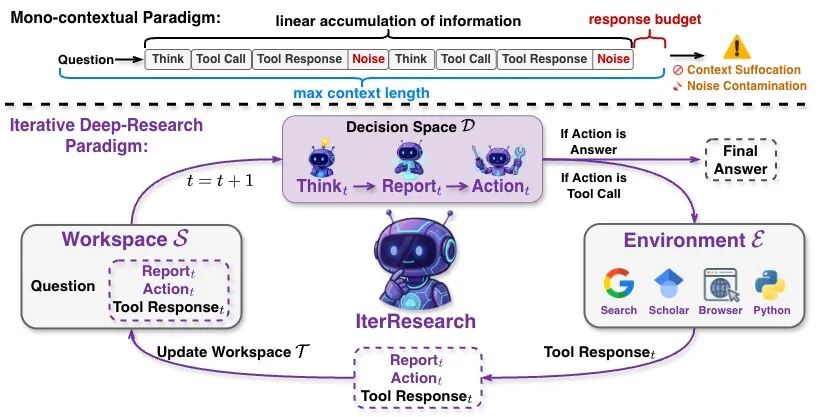
从上下文堆叠到马尔可夫式状态重构
⚙️ IterResearch 的核心机制
在 IterResearch 中,智能体的推理过程可以被抽象为两个核心动作(详细原理可见论文):
- 在决策函数(Decision)中,在每一轮推理中,agent 会基于当前状态 ,输出三部分:思考内容 、更新后的演进报告 ,以及本轮工具请求 。
- 在状态转移函数(Transition)中,在进入下一轮时,agent 仅保留前一轮的核心摘要:、工具调用 及其返回 ,以此构成新的状态 。 这意味着每一轮的推理都基于一个被压缩后的知识状态,而非完整的历史上下文。
在与社区的讨论中,我们发现这一机制的结构形式与 RNN / LSTM 的思想有着些许的相似之处。 它们都通过一个隐状态(hidden state)来承载记忆,只保留必要的信息,并在每一步进行更新。不同的是,IterResearch 的“隐状态”是一个显式、可解释的研究报告 ,它既能浓缩历史,又能为下一步提供清晰的推理起点。 换句话说,IterResearch 让 agent 在每一步都拥有自己的“工作记忆”,不需要每次都重新阅读整个过去。 这使得模型能在极深的交互链(例如 2048+ 次工具调用)中保持思路清晰,而不会被自身的历史拖垮。
🔍 从上下文管理的角度看差异
在上下文结构上,ReAct 与 IterResearch 的本质区别可以形式化为:
在传统 ReAct 中,随着交互次数 增加,上下文线性膨胀; 而在 IterResearch 中,模型通过不断**“折叠”过去、重构现在**,使得推理成本保持恒定。
💡 一句话总结
IterResearch 让 agent 学会“边做边重构思维”,在有限的上下文中实现无限的推理深度。
☀️ Takeaways:
接下来,我们总结论文的一些insight:
🧩 Insight 1: Interaction Scaling — IterResearch 让 Agent 在 2048+ 次工具调用中仍然保持清醒
据我们所知,IterResearch 是首个在仅 40K 上下文长度下,实现 2048 次工具交互仍保持稳定推理性能 的开源范式。 在 BrowseComp (BC) 基准上,性能从 3.5% → 42.5% 显著提升,展示了长程 agent 的潜在可扩展性。
这说明“长程任务困难”的来源可能并非一定是模型推理能力不足,也有可能是探索深度受限。 通过 马尔可夫式状态重构(Markovian Workspace Reconstruction),IterResearch 能够在每一轮“清空噪声、保留核心”,维持一个干净而恒定复杂度的推理空间,从而在理论上具备「无限深度的探索能力」。
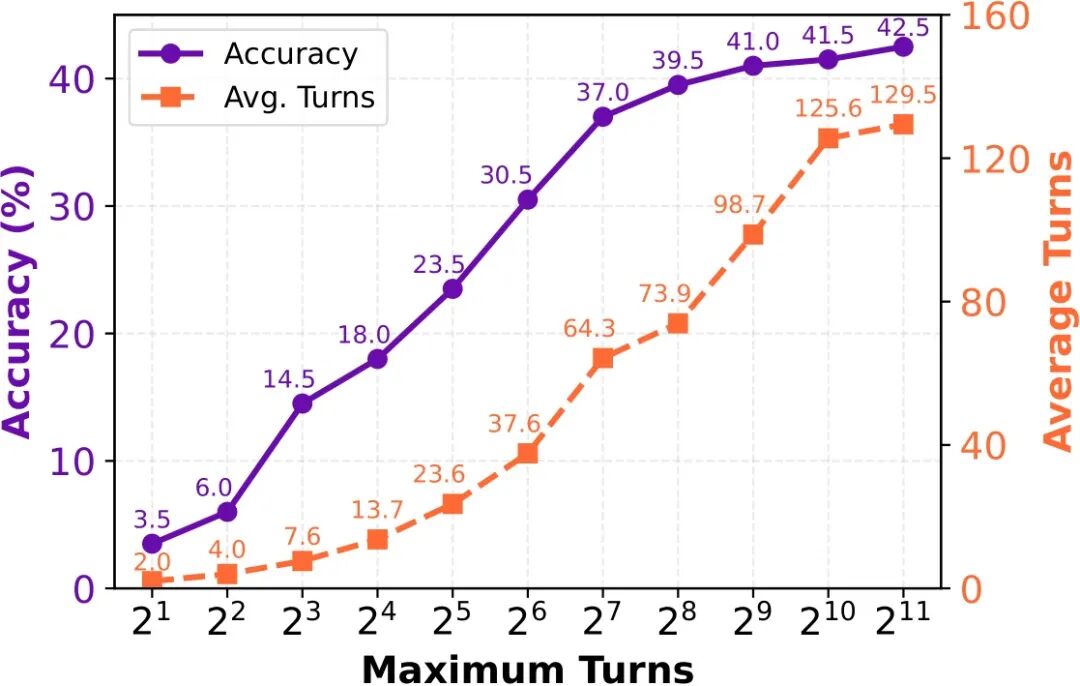
Iteraction Scaling: IterResearch在仅 40K context 下实现 2048 轮推理的稳定性能.
💡 换句话说:IterResearch 证明了,只要给模型一个干净的“思维工作空间”,它完全有潜力在超长任务中持续进步。
💡 值得强调的是,2048 并非 IterResearch 的交互上限,而是实验评测范围的终点。 模型在 2048 轮时依然保持稳定性能,没有出现明显退化,表明该范式在理论上具备进一步扩展潜力。
💡 另外,在HLE, BC, BC-zh, GAIA几个benchmark中,我们发现BC是最考验long-horizon能力的benchmark,其他几个benchmark往往并不需要这么多的交互次数。
🏗️ Insight 2: Cross-paradigm Knowledge Transfer — IterResearch提供了高质量的探索信号
我们发现:IterResearch 范式下生成的推理轨迹,还能显著增强传统 ReAct (mono-contextual) agents 的表现。
这意味着 IterResearch 学到的可能不仅是一个新的上下文结构,还有可能是一种更优的探索行为模式 (exploration behavior) ——这种模式能够迁移到不同范式的代理系统中,成为高质量的训练信号。
| Paradigm Setting | HLE | BC | BC-zh | GAIA | Xbench-DS | SEAL-0 | Avg |
|---|---|---|---|---|---|---|---|
| Mono-Agent | 18.7 | 25.4 | 34.6 | 62.1 | 55.0 | 23.4 | 36.5 |
| Mono-Agent + Iter | 25.4 | 30.1 | 40.4 | 63.1 | 62.0 | 30.6 | 41.9 |
| ↑ Improvement | +6.7 | +4.7 | +5.8 | +1.0 | +7.0 | +7.2 | +5.4 |
Table: Cross-Paradigm Knowledge Transfer — trajectories generated by IterResearch significantly enhance mono-contextual agents under identical training and environment settings.
🐝 IterResearch as an Effective Prompting Strategy for Long-Horizon Tasks
在验证了 IterResearch 作为训练范式的表现之后,我们进一步提出一个问题:
如果不进行任何训练,仅把 IterResearch 的推理逻辑用作提示(prompting strategy),它还会有效吗?
答案是肯定的。
我们将 IterResearch 的迭代范式直接应用于两款前沿的闭源模型——o3 和 DeepSeek-V3.1, 在完全相同的任务设定下,与传统的 ReAct (mono-contextual) 提示范式进行对比。 结果表明:即便在零训练的前提下,IterResearch 依然显著优于 ReAct, 特别是在最具挑战性的长程任务 BrowseComp 上,性能提升达到了 o3 (+12.7pp) , DeepSeek-V3.1 (+19.2pp)
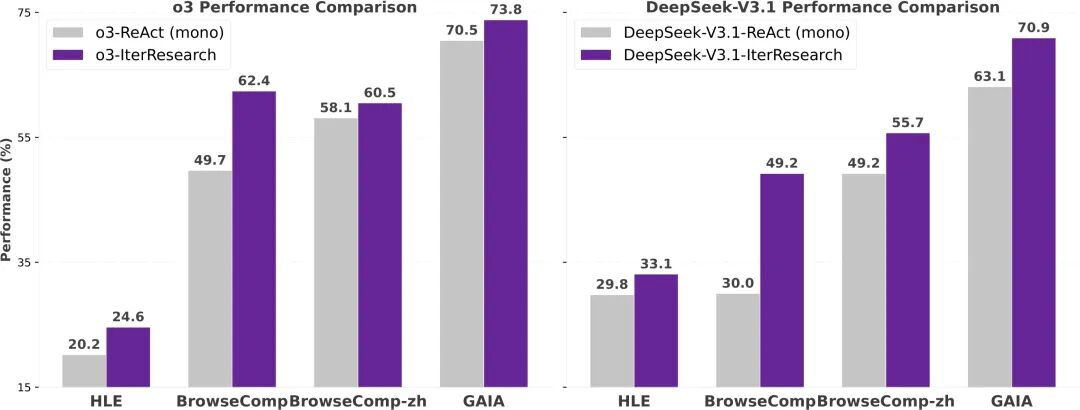
Performance comparison between IterResearch and ReAct as prompting strategies.
这一结果带来了两个重要启示:
-
结构性胜于技巧性。
IterResearch 的核心优势不在于微调或数据,而在于其结构性认知机制: 它通过“周期性综合 + 有限工作空间”保持推理聚焦,而非陷入累积噪声。 这使得模型在长程任务中能“持续清醒”,避免被自身历史淹没。
-
模型无关的普适性。
无论是 o3 还是 DeepSeek,二者架构完全不同,却都在使用 IterResearch 提示后显著提升。 这说明该范式触及的是长程推理中的共性瓶颈,而非特定模型的技巧性缺陷。
那么,如何系统的去学习大模型LLM?
作为一名深耕行业的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~
👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。

👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。
👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。
👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。
👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 24
24 0
0- 0



 已为社区贡献486条内容
已为社区贡献486条内容

所有评论(0)