快手统一特征抽取框架KaiFG,用Python的优雅,唤醒C++般的性能狂潮!
当算法工程师困于异构特征框架的碎片化泥潭,当创新灵感被30分钟编译枷锁牢牢禁锢 —— 快手算法引擎团队自研的「特征工程超导体」KaiFG,破局而来!这套框架将赋能更多业务团队,让创新不再受技术枷锁所困,让每一行代码都能释放极致效能。
当算法工程师困于异构特征框架的碎片化泥潭,当创新灵感被30分钟编译枷锁牢牢禁锢 —— 快手算法引擎团队自研的「特征工程超导体」KaiFG,破局而来!它让 Python 代码跑出 C++ 级速度,让创意落地与性能极致在此刻完美同频!本文将为你详细解析这一框架的特性。
一、项目背景
在快手推荐、商业化、搜索等核心业务中,曾长期并存多套异构特征抽取框架(如 Mio/Kuiba/Dark)。这些框架功能相近却接口各异、编程范式不同,迫使算法工程师为每套框架开发专用算子,重复劳动激增;更因基于 C++ 开发,陷入「开发难、调试久、迭代慢」的困境。
以一段简单的特征抽取算法为例:
class ExtractSignReason : public SignFeature {
public:
explicit ExtractSignReason()
: SignFeature("ExtractSignReason", Type::kNormal, 136, 0, 0, 48) {}
virtual void Extract(const SampleInfo& sample_info, std::vector<uint64> *result) {
if (sample_info.reason != "" && sample_info.reason.length() > 0) {
int reason = 0;
if (sample_info.reason != "hx") {
std::string subStr = sample_info.reason.substr(1, sample_info.reason.length() - 1);
reason = std::atoi(subStr.c_str());
}
result->push_back(GenFeature(0, 0, reason));
}
}
private:
DISALLOW_COPY_AND_ASSIGN(ExtractSignReason);
};
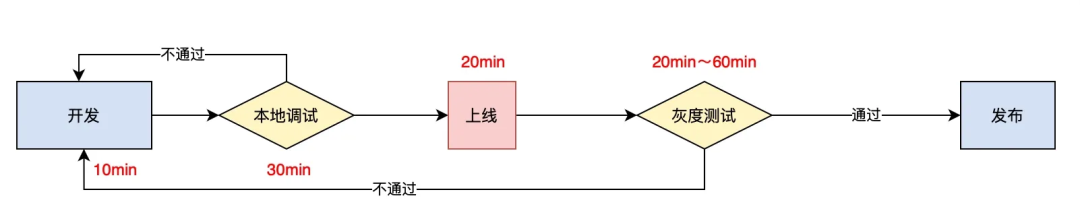
用 C++ 开发需面对复杂的类继承、接口适配,即便熟悉语法也需查阅手册。写好后,每次测试要经历 30分钟编译和20分钟上线流程,一旦出现逻辑错误,全流程重来,整体迭代周期长达 1-2 天,这种开发模式严重桎梏算法创新效率。

而用KaiFG,只需用最熟悉的 Python 编写,逻辑直观简洁,且本地即可调试运行,无需编译,性能与 C++ 版本几乎无差。
def ExtractSignReason(reason: str = "") -> List[int]:
ret: List[int] = []
if reason != "" and len(reason) > 0:
_reason = 0
if reason != "hx":
subStr = reason[1:]
reason = int(subStr)
ret.append(_reason)
return ret
整体迭代周期被大大缩短。
二、KaiFG是什么?
KaiFG(Kuaishou AI Feature Generator)是由快手算法引擎团队自主研发的统一特征抽取框架,致力于构建算法与工程之间的标准化接口,并通过底层技术实现极致的执行性能与开发效率。其核心设计目标为:
-
建立算法与工程的统一接口规范
-
通过 Python 编译器 Codon 及 LLVM 后端优化实现 C++ 级性能
-
支持复杂特征逻辑的简洁表达与高效执行
对于算法团队,KaiFG 的核心价值在于:
-
学习成本趋零:可使用非常熟悉的 Python 编写业务逻辑,甚至可以使用 NumPy
-
调试效率跃升:支持本地调试,修改验证周期缩短至分钟级
-
部署革命性变革:支持 Python 代码直接部署,线上可以直接修改源码,无需提前编译
对于工程团队同样来带收益:
-
性能收益:线上运行性能与原生 C++ 相当,远超脚本语言
-
开发成本:编译速度提升 10 倍(111min→12min),错误日志透明定位
-
稳定性:代码出错时抛出异常,不会崩溃
对于业务系统,KaiFG 解决了技术复用的痛点:
-
跨业务统一:多业务线之间共享特征抽取算法库
-
跨平台统一:同一份代码跨平台适配(在线/离线)
KaiFG 让我们告别“碎片化开发 + 性能妥协”的旧时代,用统一、灵活、高性能的框架,支撑 AI 业务的快速迭代,迎接更加高效的未来!
三、KaiFG的技术特性
KaiFG 引入开源的 Python 编译器 Codon 作为后端。Codon 提供了高度抽象的类型系统和可定制的优化能力。通过在 Codon IR 和 LLVM IR 层级进行定制化开发,KaiFG 实现了从前端到后端的端到端优化。
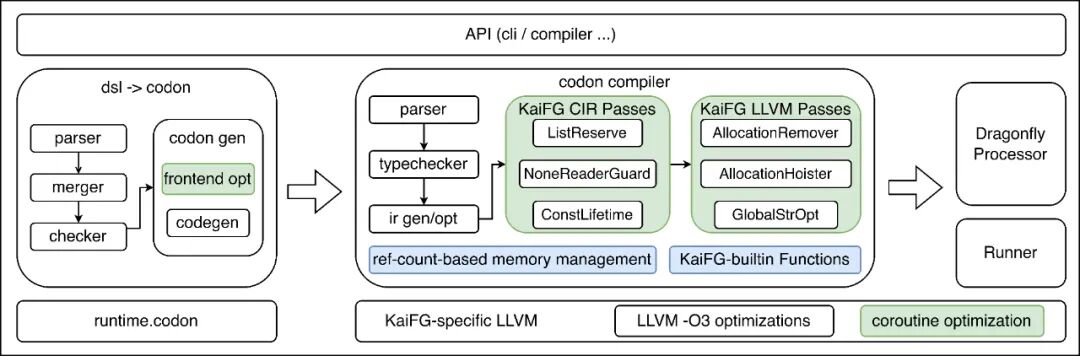
事实上,Python 并不适合编写高性能代码(例如,你会在写 Python 时主动为 List 调用 reserve 吗?)。基于 Codon 的架构,我们为 Python 开发了大量性能优化手段,在不改变用户编程习惯的前提下,自动实施相应优化。
接下来,我们将聚焦 KaiFG 中的几个技术亮点与工程突破:
3.1 IR层级的引用计数
原生 Codon 采用开源的 bdwgc 垃圾回收库(GC)进行内存管理,但该实现在多个方面均难以满足线上服务对性能与稳定性的严苛要求。
-
并发性能瓶颈显著:在 KaiFG 的多线程并发执行场景中,Codon 的垃圾回收机制依赖一个全局锁,在内存分配、释放以及垃圾回收触发等关键路径上均需独占。导致高并发时线程竞争激烈,吞吐受限,原生 Codon 无法满足线上服务需求。
-
运行时性能波动大:在内存不足时,函数执行可能因突发的 GC 而导致显著延迟上升(可达 1 秒级别),造成整体服务 P99 飙升。
相比 GC,引用计数(RefCount)的管理模式对于线上服务友善得多。事实上,RefCount 在编程中很常见,例如 C++ 中的 shared_ptr 就是一种引用计数的实现。然而,通常意义上的 RefCount 是在源代码或编译层实现的。Codon 编译器并未考虑 RefCount 的需求,如果在源码层实现会严重影响用户使用习惯。
为此,KaiFG 设计并实现了一套 IR 级别的引用计数内存管理机制,在用户无感知的情况下,自动通过引用计数完成内存管理,相比 GC 性能提升 294%。同时,
-
所有内存操作均在各自线程上下文中完成;
-
回收触发具有确定性和可预测性,从根本上消除了非预期的性能抖动;
-
实时释放不再使用的内存,提升了用户态已分配内存的复用效率,提升访存局部性。
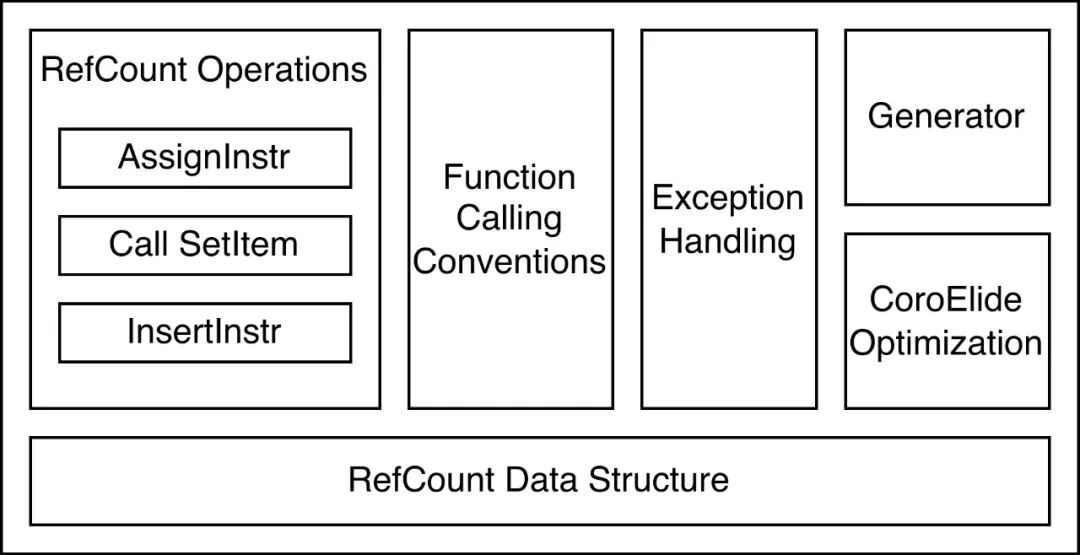
该机制在 Codon IR(CIR)层面实现,由于 CIR 未采用静态单赋值(SSA)形式,变量可被多次赋值,在处理引用计数时需同时追踪变量旧值与新值的状态变化。实现挑战和解决方案主要如下三点。
3.1.1 隐式内存追踪
自动为任意内存对象添加引用计数所需的数据结构,无需用户指定。
-
堆对象:通过重写 __alloc__ 隐式分配 ref_count 空间
-
栈对象:采用"影子指针"策略(如 str 的 _ptr 指向含 ref_count 的堆内存)
# 对象内存结构示意(64位系统)
+---------------------+
| ref_count (8 bytes) | # 位于对象指针-8位置
+---------------------+
| Object Data | # 实际数据区
+---------------------+
3.1.2 指令级插桩逻辑
基于 CIR 分析变量传递关系,并在变量不再被后续代码引用时添加临时保留及引用计数相关操作。同时,通过优化 Pass 削减冗余引用计数操作对(Pair)。
; a = b 对应的的 LLVM IR 改变
; tmp = a
%load_a = load { i64, ptr }, ptr %a
store { i64, ptr } %load_a, ptr %tmp
; a = b
%load_b = load { i64, ptr }, ptr %b
store { i64, ptr } %load_b, ptr %a
; inc_ref(a)
%load1_a = load { i64, ptr }, ptr %a
%unused = call {} @inc_ref({ i64, ptr } %load1_a)
; dec_ref(tmp)
%load_tmp = load { i64, ptr }, ptr %tmp
%unused1 = call {} @dec_ref({ i64, ptr } %load_tmp)同时,为了支持完整的异常处理模型,KaiFG 还需要确保在异常展开(unwind)过程中正确释放所有局部变量所持有的对象引用。为此,我们进行了如下改造:
-
所有可能抛异常的函数调用强制转为 LLVM 的 invoke 指令;
-
分析每个函数的 unwind 需求,并自动生成对应代码块统一释放局部变量。
3.1.3 协程内存安全方案
Generator 是 Python 的常用结构,Codon 借助 LLVM 协程实现,其协程栈通常在堆上分配。当 Generator 未被完全消费即被丢弃时,无法依赖正常结束的 cleanup 流程释放协程栈,因此需对 Generator 对象采用特别的引用计数管理。
为此,我们定制修改了 LLVM 的 CoroElide 优化 pass,确保在进行协程栈优化(将其优化至调用者栈帧)时,仍保留足够的附加空间以支持引用计数,避免引发运行时错误。
3.2 万用数据接口
为了扩大适用范围,KaiFG 并不约束调用方传入数据的格式,而是需要调用方提供 IDataAccessor 接口的实现,来指引 KaiFG 如何获取数据。同时,在编译期间根据对应的 Accessor 提供的能力列表(如是否支持顺序访问)决定如何优化代码生成,从而实现‘零拷贝’。
比如在 Dragonfly(快手内部通用图引擎框架及其周边工具所构建的开发生态)中使用,需要由 Dragonfly 提供存储的 DragonDataAccessor。至于 Dragonfly 底层适用何种存储格式均可。
基于以上方案,KaiFG 可以保证同一份代码在不同数据格式下通用,适合嵌入各种流水线中。例如离线业务也可以定义自己的 DataAccessor,而无需与线上业务捆绑。定义适当的存储约束后,KaiFG 的优化将基于这些约束假设,避免因兼容多种系统而带来的优化复杂性。
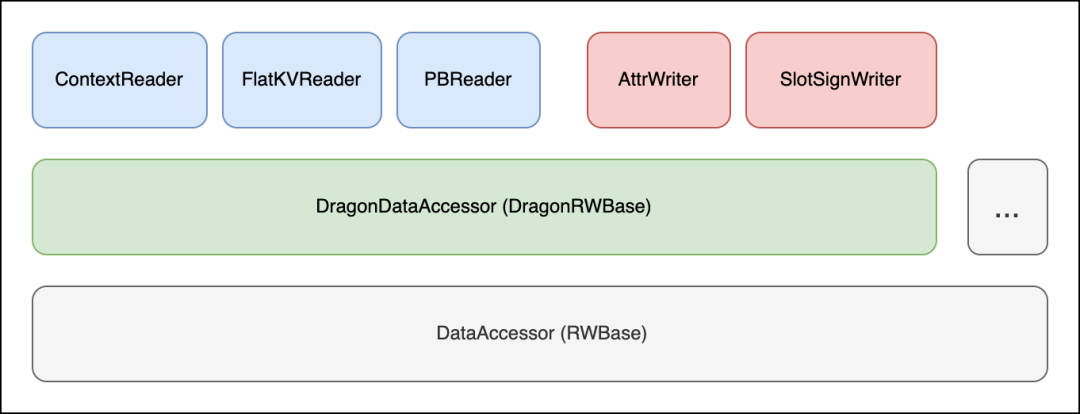
同时,针对 Protobuf 格式,我们推出了 ProtoKV 读取方式,无需依赖反序列化或反射,即可像访问 KV 一样读取 Protobuf 数据,实现了灵活性与性能的统一。
3.3 强化向量化推导
现代 CPU 普遍提供了向量指令集,允许以 SIMD 的形式用一条指令同时处理多个数据。LLVM 对向量化有非常好的支持,但是由于 Python 语法过于灵活,且用户既有书写习惯并不重视性能,其生成的代码往往不具备自动向量化的条件。
KaiFG 针对 CIR 进行模式分析,通过增加 TBAA、Assumption 等方式来指引 LLVM 进行相应优化。举例如下:
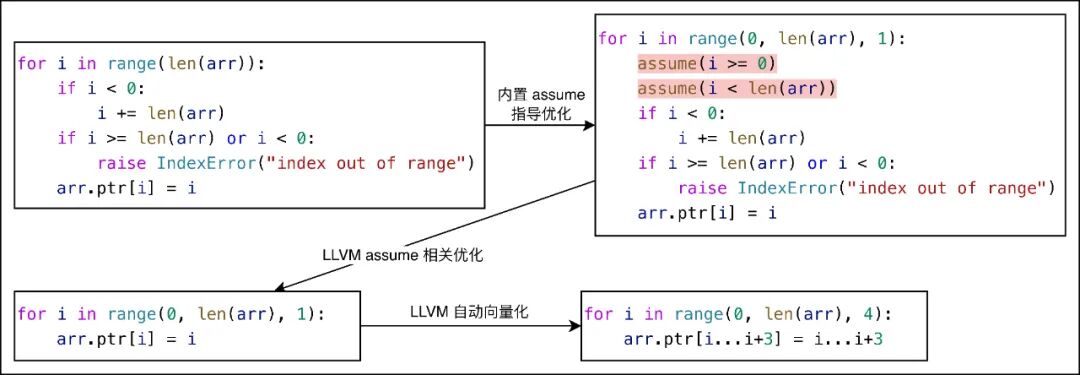
3.3.1 循环边界推导引擎
对于 `for ... in ...` 和 `for ... in range(...)` 这两种遍历 List 的写法,可以确定索引为正且不会越界,因此无需边界检查,List 访问可简化为一次直接的访存操作。
然而,以上推断 LLVM 无法自动完成,这使得所有 List 访问都不得不执行复杂的判断分支逻辑。导致过高的额外开销,也使得向量化无法实现。
为此,我们针对循环体的边界判断自动添加 assume 约束,指导 LLVM 优化。示意图如下:
3.3.2 增强的数据别名分析
LLVM 自动向量化要求循环内部不存在可能冲突的内存读写操作,例如 load 和 store 指令对同一段内存进行访问的情况。由于 load/store 的地址可能来自内存读取,静态分析难以直接判断两条指令是否访问同一地址,因此访存冲突需依赖类型信息来判定,在 C++ 中主要通过 TBAA(Type-Based Alias Analysis)实现。
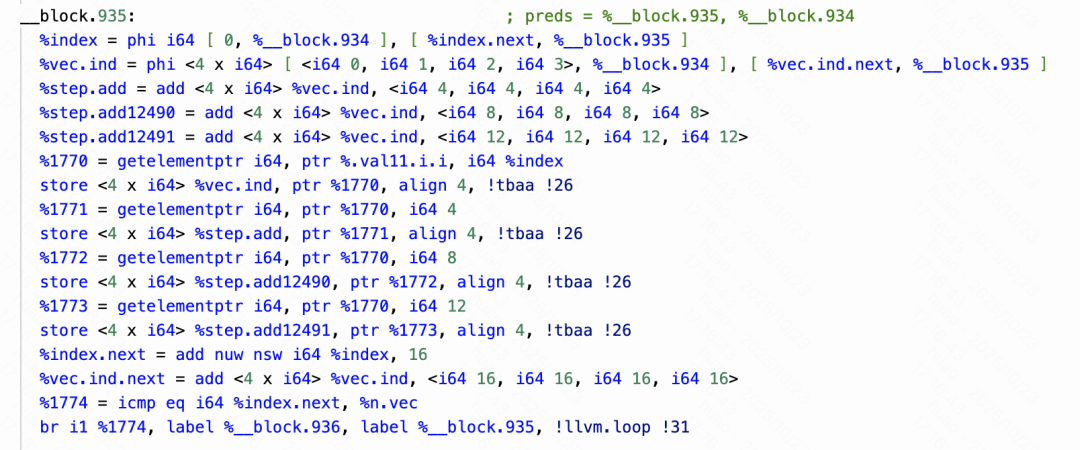
Python 不像 C++ 那样具有复杂的指针引用关系,实际上可以排除大量变量之间的别名可能(即指向同一内存地址的情况)。例如,List 中的 size 和 data 即使数据类型相同,也不可能存在指向关系。基于以上理念,我们在 Codon 上添加了全套 TBAA 推导机制,并针对 Python 特性进行了更细粒度的数据类型划分,为 LLVM 优化阶段提供更详尽的类型信息。
在为 Codon 生成的 LLVM IR 添加上述内容后,LLVM 的自动向量化 pass 能够识别并实现部分场景的向量化。通过与 Clang 优化效果的对比显示,KaiFG 可以达到并在部分场景下超过 C++ 的自动向量化效果。
四、性能收益
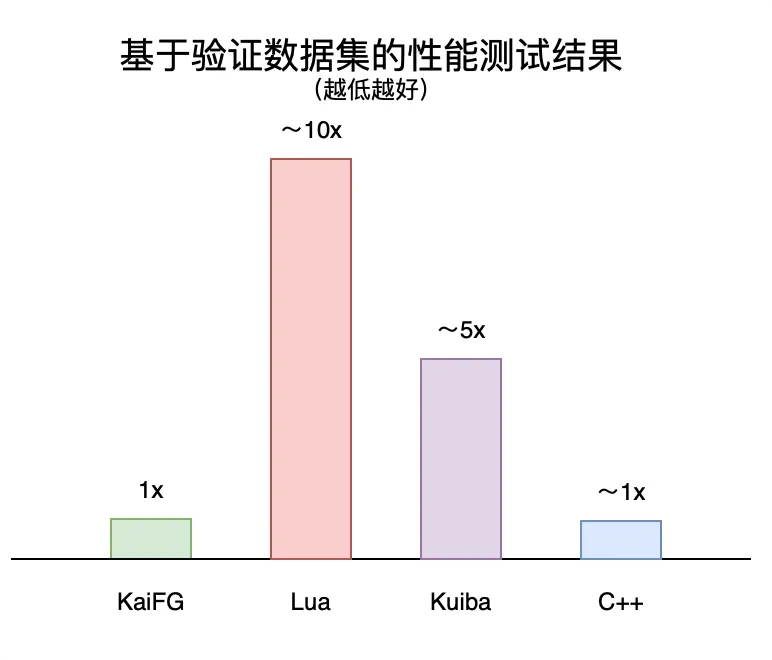
经过一系列优化,KaiFG 的运行效率与原生 C++ 程序(正常书写,没有极致优化)差距在 ±10% 内,均值相当。相比传统的脚本语言和低代码方案有显著提升,同时保证了易用性和高性能。
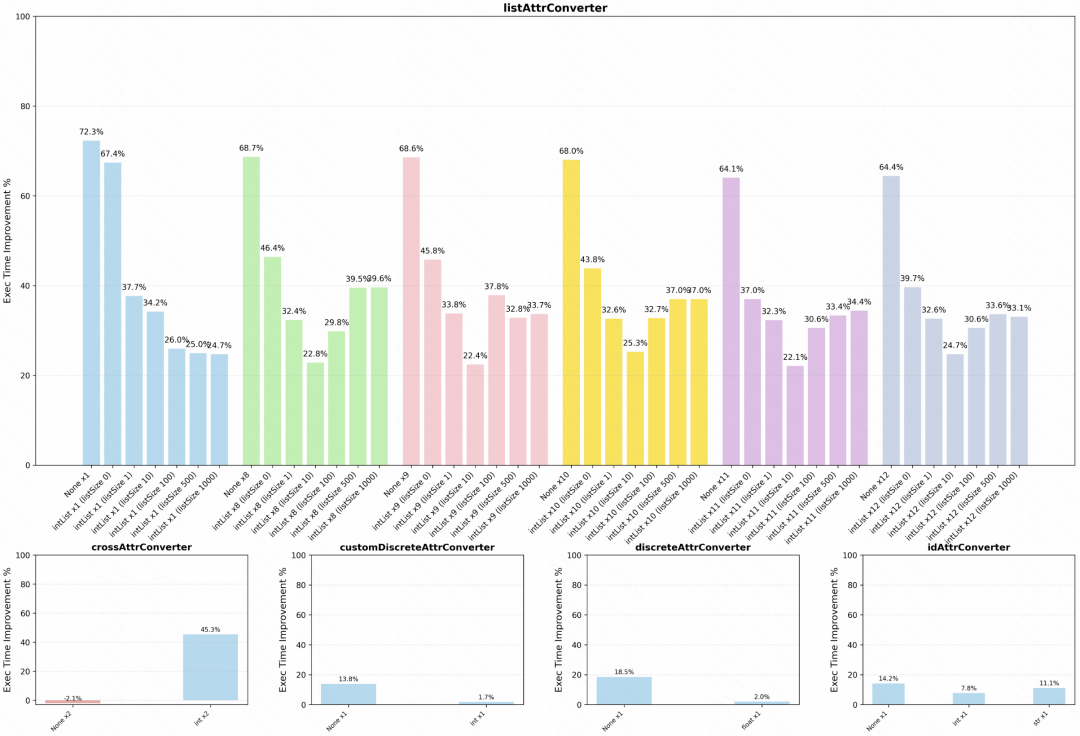
其中,相比原生 Codon,自研优化在各场景下的性能提升为 40%~80%。
在近半年上线的业务上,也取得了端到端的收益。
五、总结和展望
KaiFG 不仅是一次技术架构的革新,更是算法与工程协作模式的进化。它以 Python 的灵活语法为舟,以 C++ 级的性能为桨,让开发者在高效与性能之间无需妥协。无论是本地调试的分钟级验证、跨平台的无缝适配,还是对复杂业务场景的深度支持,KaiFG 正重新定义特征工程的开发范式。
我们相信,这套框架将赋能更多业务团队,让创新不再受技术枷锁所困,让每一行代码都能释放极致效能。未来,我们将持续深耕编译优化与生态建设,与开发者共同开启高效、敏捷的 AI 工程新时代!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)