【AI大模型前沿】Mini-o3:字节跳动联合港大推出的开源视觉推理模型
Mini-o3是一个开源的视觉推理模型,专为解决复杂的视觉搜索问题而设计。它通过强化学习和基于图像的工具,能够执行深度多轮推理,推理轮次可扩展至数十轮。该模型在多个视觉搜索基准测试中取得了最先进的结果,并且所有代码、模型和数据集均开源,便于研究人员复现和进一步研究。
系列篇章💥
前言
在人工智能领域,视觉推理模型一直是研究的热点之一。随着技术的不断进步,如何让模型具备更强大的视觉推理能力和更自然的交互能力成为了研究的重点。Mini-o3正是在这样的背景下应运而生,它由字节跳动和香港大学联合推出,旨在解决复杂的视觉搜索问题,通过深度多轮推理和创新的技术手段,显著提升了模型的性能。
一、项目概述
Mini-o3是一个开源的视觉推理模型,专为解决复杂的视觉搜索问题而设计。它通过强化学习和基于图像的工具,能够执行深度多轮推理,推理轮次可扩展至数十轮。该模型在多个视觉搜索基准测试中取得了最先进的结果,并且所有代码、模型和数据集均开源,便于研究人员复现和进一步研究。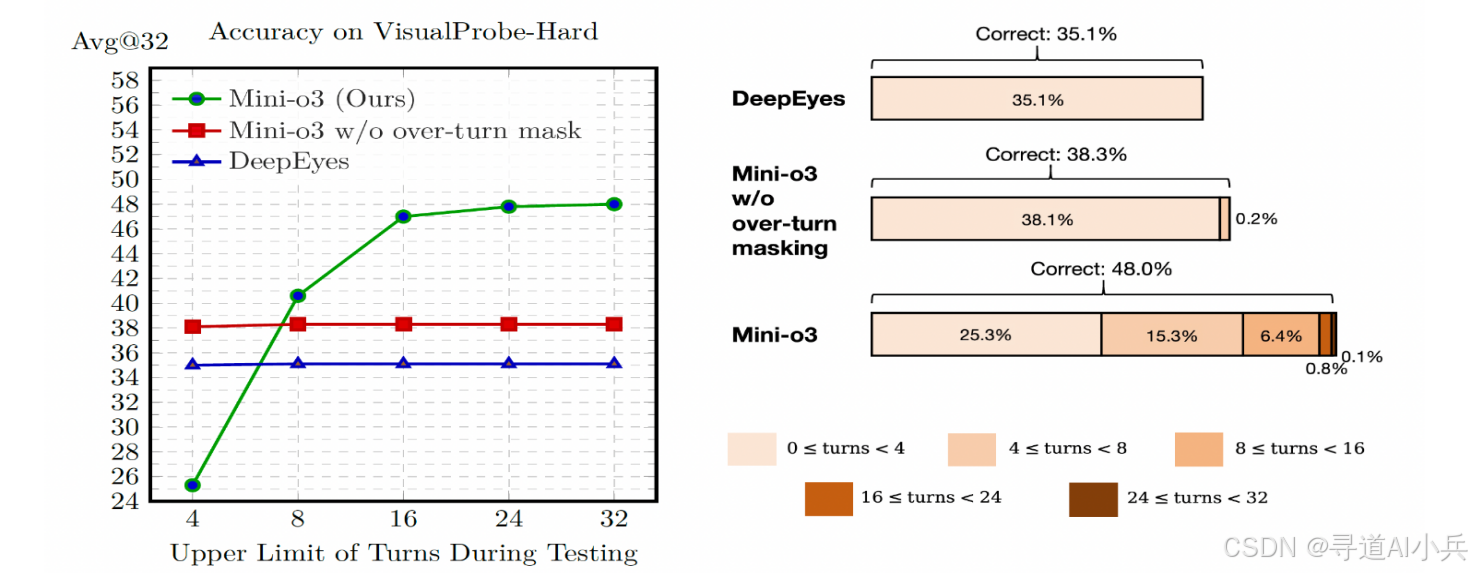
二、核心功能
(一)多轮交互推理
Mini-o3能够进行深度多轮交互推理,交互轮次可扩展至数十轮。在复杂的视觉搜索任务中,模型通过逐步探索和试错,逐步缩小搜索范围,最终精准定位目标。这种深度交互推理能力使其能够处理更为复杂的视觉问题,例如在高分辨率图像中,即使目标物体较小且存在大量干扰物体,Mini-o3也能通过多轮推理,逐步排除干扰,准确找到目标物体。
(二)多样化推理模式
Mini-o3支持多种推理模式,包括深度优先搜索、试错和目标维持等。深度优先搜索模式使其能够沿着一条线索深入探索,直至找到目标或确定该线索无效;试错模式则允许模型在探索过程中不断尝试不同的路径和方法,通过失败来学习和调整策略;目标维持模式则确保模型在多轮交互中始终保持对目标的关注,不会因干扰而偏离搜索方向。
(三)挑战性视觉搜索
Mini-o3专为解决挑战性的视觉搜索问题而设计。它能够在高分辨率图像中,面对小目标、大量干扰物体等复杂情况,依然准确地定位和识别目标。例如,在电商平台上,用户可能上传一张包含众多商品的图片,希望找到与其中某一特定商品相似的其他商品。Mini-o3能够在这张图片中准确识别出目标商品的特征,并在海量商品库中进行精准搜索,为用户提供满意的搜索结果。
三、技术揭秘
(一)冷启动监督微调(Cold-start Supervised Fine-tuning, SFT)
通过少量手工制作的示例,用上下文学习能力的视觉语言模型(VLM)生成高质量、多样化的多轮交互轨迹。
(二)强化学习(Reinforcement Learning, RL)
基于过轮遮蔽(over-turn masking)策略,避免因交互轮次超出限制而受到惩罚,在测试时能自然扩展到数十轮交互。
(三)降低图像像素预算(Lower Down Max Pixels)
通过减少每张图像的最大像素数,增加单次交互中允许的轮次数量,提高解决长周期问题的能力。
(四)挑战性数据集(Visual Probe Dataset)
构建一个包含数千个视觉搜索问题的数据集,问题设计用在鼓励探索性推理,帮助模型在训练过程中学习复杂的推理模式。
四、基准评测
Mini-o3在多个视觉搜索基准测试中取得了卓越的性能表现。例如,在VisualProbe数据集的hard级别上,Mini-o3的准确率达到了48.0%,远超其他同类模型,如GPT-4o的11.2%和LLaVA-OneVision的13.4%。此外,在V* Bench、HR-Bench和MME-Realworld等基准测试中,Mini-o3也展现出了强大的性能,分别取得了88.2%、77.5%和73.3%的准确率。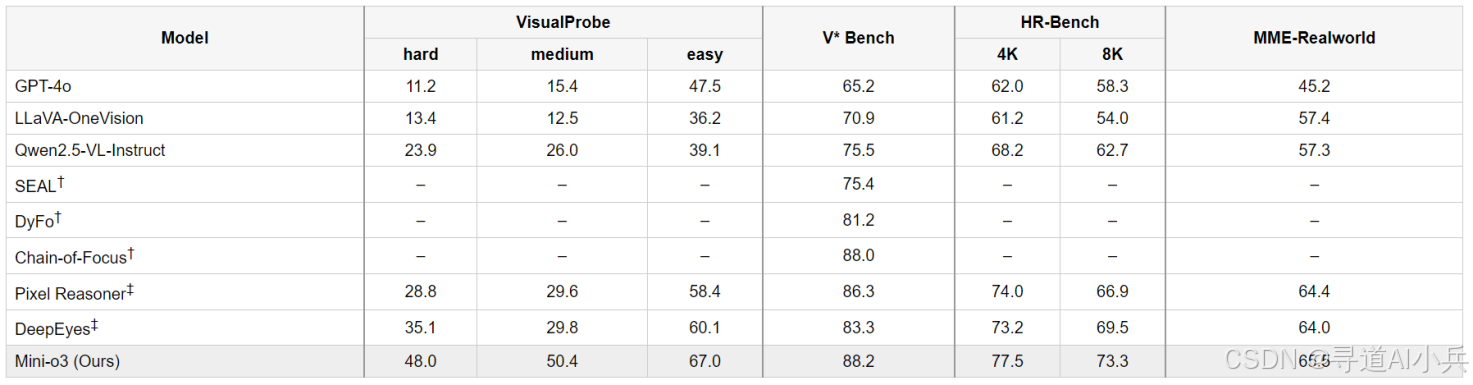
五、应用场景
(一)电商领域
在电商平台上,用户常常需要通过图片搜索来寻找心仪的商品。Mini-o3能够帮助用户在海量商品图片中快速找到目标商品。例如,用户可能上传一张包含众多服装的图片,希望找到与其中某一特定服装相似的款式。Mini-o3通过深度多轮推理,能够准确识别出目标服装的特征,并在商品库中进行精准搜索,为用户提供与之相似的商品推荐。
(二)智能家居领域
在智能家居环境中,Mini-o3可以通过摄像头捕捉图像,帮助用户快速找到丢失的物品。例如,用户可能在家中找不到钥匙或遥控器,通过与Mini-o3进行交互,模型可以在家庭环境中进行视觉搜索,逐步缩小搜索范围,最终帮助用户找到丢失的物品。
(三)监控视频分析领域
在监控视频中快速定位和识别特定目标是Mini-o3的另一个重要应用场景。例如,在人群密集的公共场所,如机场、车站等,监控系统需要快速准确地找到特定人员或物品。Mini-o3通过多轮推理分析监控视频,能够逐步排除干扰,锁定目标物体的位置。此外,Mini-o3还可以用于异常行为检测,通过分析监控视频中的人员行为模式,及时发现异常行为,如入侵、打斗等,并发出警报。
(四)自动驾驶领域
在自动驾驶系统中,Mini-o3的多轮视觉推理能力可以发挥重要作用。例如,在复杂路况中,自动驾驶系统需要准确理解和规划路径,尤其是在有遮挡物或复杂交通标志的情况下。Mini-o3可以通过多轮推理,逐步分析路况信息,识别交通标志和障碍物,并为自动驾驶系统提供准确的决策依据。
(五)医疗影像分析领域
在医疗影像分析中,Mini-o3可以帮助医生快速准确地定位病变区域。例如,在高分辨率的医学影像中,病变区域可能较小且存在大量干扰组织,Mini-o3通过深度多轮推理,能够逐步缩小搜索范围,最终准确找到病变区域的位置。

六、快速使用
(一)安装环境
首先克隆Mini-o3的GitHub仓库,然后创建Python环境并安装所需的包。
git clone https://github.com/Mini-o3/Mini-o3.git
conda create -n minio3 python=3.11 -y
conda activate minio3
cd Mini-o3
pip3 install -r requirements.txt
pip3 install -e .
pip3 install httpx==0.23.3
(二)模型训练
训练过程包括两个阶段。第一阶段是冷启动监督微调(SFT),第二阶段是强化学习(RL)。
- 冷启动监督微调(SFT):使用LLaMA-Factory对冷启动数据进行微调。
python3 scripts/preprocess_coldstart.py --dataset_path Mini-o3/Mini-o3-Coldstart-Dataset --output_dir [YOUR_DATASET_FOLDER]
llamafactory-cli train sft_configs/qwen2.5-vl.yaml
- 强化学习(RL):基于冷启动模型进行强化学习训练。
python3 -m verl.trainer.main_ppo [训练参数]
(三)模型评估
在训练完成后,可以通过添加相应的参数来评估模型的性能。
actor_rollout_ref.rollout.val_n=32 \
actor_rollout_ref.rollout.val_do_sample=True \
trainer.val_only=True
结语
Mini-o3作为一款开源的视觉推理模型,通过其深度多轮推理能力和创新的技术手段,在多个视觉搜索基准测试中取得了卓越的性能。它的开源性为研究人员提供了极大的便利,有助于推动相关技术的进一步发展。未来,随着技术的不断进步,Mini-o3有望在更多的应用场景中发挥更大的作用。
项目地址
- 项目官网:https://mini-o3.github.io/
- GitHub仓库:https://github.com/Mini-o3/Mini-o3
- HuggingFace模型库:https://huggingface.co/Mini-o3/models
- arXiv技术论文:https://arxiv.org/pdf/2509.07969

🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索(CSDN博客之星|AIGC领域优质创作者)
📖专属社群:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,回复‘入群’ 即刻上车,获取邀请链接。
💘领取三大专属福利:1️⃣免费赠送AI+编程📚500本,2️⃣AI技术教程副业资料1套,3️⃣DeepSeek资料教程1套🔥(限前500人)
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我们,一起携手同行AI的探索之旅,开启智能时代的大门!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 18
18 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)