MaskVLM:跨模态表示学习的联合掩码建模新范式
本文是对论文《MASKED VISION AND LANGUAGE MODELING FOR MULTI-MODAL REPRESENTATION LEARNING》的深度解读。在视觉 - 语言跨模态表示学习领域,传统方法独立处理掩码语言 / 图像建模,存在模态偏置与额外依赖问题。AWS AI Labs 团队发表的这项研究,创新性提出 MaskVLM 联合掩码建模方法,端到端利用跨模态信息互补重建
在视觉 - 语言(V+L)跨模态表示学习领域,掩码信号建模已成为核心预训练策略,但传统方法多独立处理视觉掩码(MIM)和语言掩码(MLM)任务,未能充分利用跨模态数据的内在关联性。AWS AI Labs 于 2023 年发表在 ICLR 的论文《MASKED VISION AND LANGUAGE MODELING FOR MULTI-MODAL REPRESENTATION LEARNING》提出了一种创新的联合掩码视觉 - 语言建模(MaskVLM)方法,通过跨模态信息互补实现掩码信号重建,在大规模数据和有限数据场景下均取得了 SOTA 性能。
原文链接:https://arxiv.org/pdf/2208.02131
一、研究背景与核心问题
1.1 跨模态表示学习的发展现状
视觉 - 语言表示学习因能迁移至零样本视觉识别、目标检测、跨模态检索等多种下游任务,已成为 AI 领域的研究热点。其成功主要依赖于大规模图文配对数据的预训练,而预训练技术大多借鉴了单模态自监督学习的思路,尤其是掩码信号建模。
在单模态领域:
- 自然语言处理(NLP)中,BERT 及其变体通过掩码语言建模(MLM),利用未掩码 tokens 预测掩码 tokens,实现了强大的语言表示学习;
- 计算机视觉(CV)中,BeiT、MAE 等模型通过掩码图像建模(MIM),恢复被掩码的图像块或像素,有效学习视觉特征。
在跨模态领域,现有方法存在明显局限:
- 部分方法仅基于未掩码图像进行 MLM,只能学习文本依赖图像的条件分布
,无法建模图像依赖文本的分布
,导致跨模态检索任务性能偏置;
- 少数尝试双模态掩码的方法,要么依赖冻结的目标检测器提取视觉特征,要么基于预训练图像分词器处理图像 tokens,不仅增加了额外的数据和模型依赖,还阻碍了端到端的跨模态交互学习。
1.2 核心研究问题
如何设计一种端到端的联合掩码建模方案,充分利用图文配对数据的语义一致性,同时学习 和
两种条件分布,实现更优的跨模态对齐和表示学习?该方案能否在有限训练数据场景下依然保持高效性能?
二、核心创新与方法设计
2.1 核心思想
MaskVLM 的核心创新在于联合掩码视觉 - 语言建模:通过随机掩码一种模态的信号,利用另一种未掩码模态的信息进行重建。这种设计基于图文配对数据的本质 —— 图像和文本虽形式不同,但传递的语义信息高度一致。通过跨模态互补重建,模型能隐式学习语言 tokens 与图像块之间的对齐关系,同时避免了传统方法的模态偏置和额外依赖。
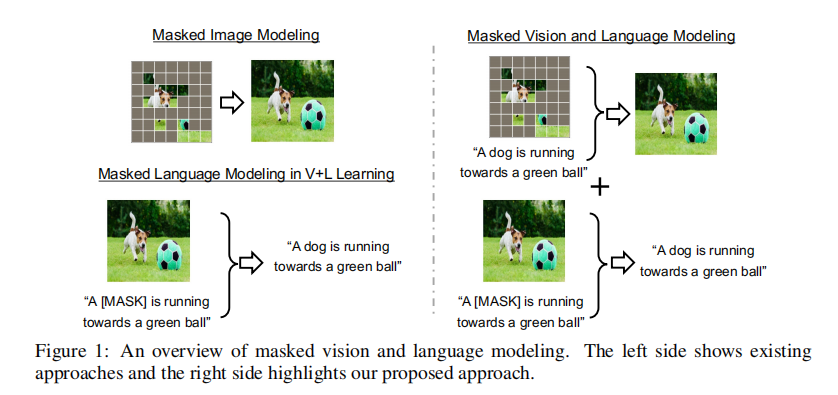
2.2 整体框架
MaskVLM 的整体框架包含两大预训练目标:联合掩码视觉 - 语言建模(核心任务)和多模态对齐(辅助任务),模型架构如图 2 所示。
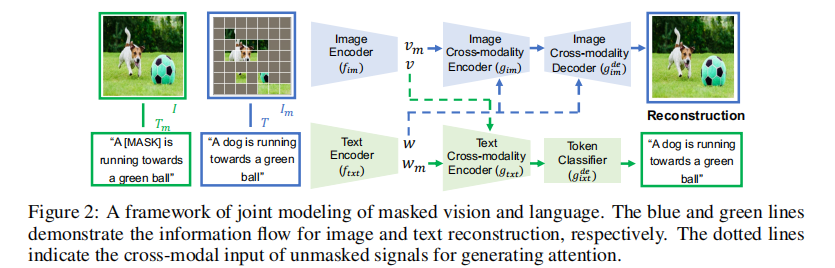
注:蓝色线表示图像重建的信息流,绿色线表示文本重建的信息流,虚线表示用于生成注意力的跨模态未掩码输入。
2.2.1 编码器结构设计
模型采用 Transformer-based 编码器,分为基础编码器和跨模态编码器:
- 图像编码器(
):基于 ViT 架构,将 224×224 图像分割为 16×16 个图像块,包含 12 个自注意力块,输出包含 [CLS] 令牌的图像特征
;
- 文本编码器(
):基于 RoBERTa 架构,包含 12 个自注意力块,输出包含 [START] 令牌的文本特征
;
- 跨模态编码器:分为图像跨模态编码器(
)和文本跨模态编码器(
),各包含 3 个跨注意力块(如图 3 所示),通过跨注意力机制融合另一模态的特征,增强当前模态的表示。
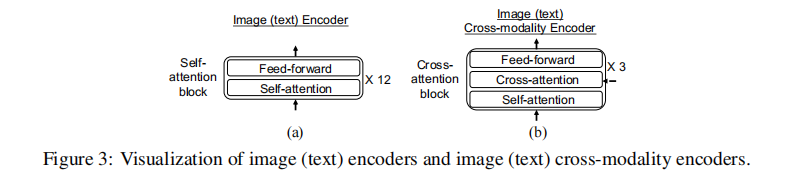
注:(a) 为图像 / 文本基础编码器结构,(b) 为跨模态编码器结构。
2.2.2 掩码策略
- 文本掩码:借鉴 BERT 的掩码方式,仅使用 [MASK] 令牌替换 30% 的文本 tokens(高于传统 15% 的比例,因图像可提供额外语义补充);
- 图像掩码:采用随机掩码策略,掩码块大小为 32×32,掩码比例为 60%。大尺寸掩码块避免模型通过复制相邻像素完成重建,迫使模型依赖跨模态信息。
2.2.3 联合重建机制
联合重建的核心是 “掩码模态 + 未掩码跨模态” 的条件重建,具体流程如下:
- 文本重建:输入原始图像 I 和掩码文本
,通过图像编码器得到未掩码图像特征
,通过文本编码器得到掩码文本特征
;将两者输入文本跨模态编码器
- 图像重建:输入掩码图像
和原始文本
,通过图像编码器得到掩码图像特征
,通过文本编码器得到未掩码文本特征
;将两者输入图像跨模态编码器
联合掩码建模损失 定义为文本重建的交叉熵损失与图像重建的 L1 损失之和:
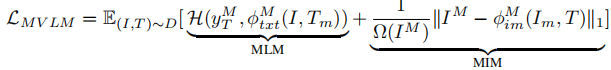
其中, 和
分别表示文本和图像的重建函数,
为掩码像素数量,仅对掩码部分计算损失。
2.2.4 多模态对齐辅助任务
为进一步增强跨模态对齐效果,模型引入两个辅助任务:
- 图像 - 文本对比学习(ITC):将图像 [CLS] 特征和文本 [START] 特征投影到同一单位范数空间,通过对比损失最大化正负样本对的区分度:
其中,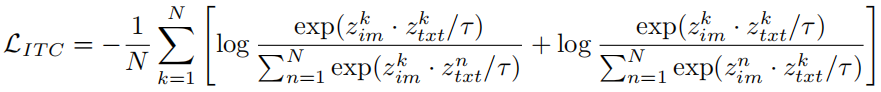
为温度系数,N 为批次大小。
- 图像 - 文本匹配(ITM):预测图文对是否匹配,将跨模态编码器输出的图像和文本特征进行元素 - wise 乘积融合,通过分类器输出匹配概率,损失函数为交叉熵损失:
其中,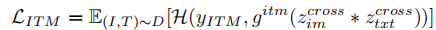
表示匹配,
表示不匹配。
模型总预训练损失为三部分之和:。
2.3 概率解释
从概率角度看,跨模态表示学习的目标是估计图文联合分布 。由于跨模态数据分布的异质性,直接最大化联合似然难度较大,而最小化信息变异量(
)可有效近似联合分布估计。
MaskVLM 通过联合建模 和
两种条件分布,直接最小化信息变异量,相比仅建模单一条件分布或依赖冻结特征提取器的方法,更能捕捉跨模态数据的内在关联,这也是其性能优异的核心原因之一。
三、实验设置与结果分析
3.1 实验配置
3.1.1 预训练数据
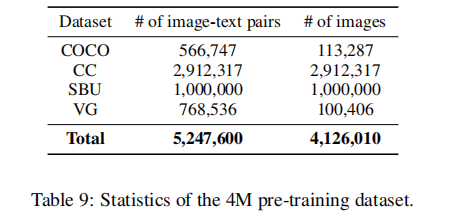
采用 4 个数据集的联合数据集(4M 数据集),包含 410 万张独特图像和 520 万对图文数据,具体统计如下:
3.1.2 下游任务
验证模型在四类跨模态任务上的性能:
- 图像 - 文本检索:COCO(5K 测试集)和 Flickr30k(1K 测试集),评估 Recall@1/5/10;
- 视觉问答(VQA):VQA v2 数据集,评估 test-dev 和 test-std 集准确率;
- 自然语言视觉推理(NLVR):NLVR2 数据集,评估 dev 和 test-P 集准确率;
- 视觉蕴含(VE):SNLI-VE 数据集,评估 val 和 test 集准确率。
3.1.3 实现细节
- 图像编码器初始化:使用 ImageNet 预训练的 ViT-Base;
- 文本编码器初始化:使用预训练的 RoBERTa-Base;
- 训练参数:批次大小 512,预训练 50 个 epoch,优化器为 AdamW(权重衰减 0.05),学习率采用余弦调度器(预热 5 个 epoch 至 3e-4,最终衰减至 3e-5);
- 微调设置:图像尺寸调整为 384×384,插值调整位置编码,不同任务采用不同的微调 epoch 和学习率。
3.2 主要实验结果
3.2.1 图像 - 文本检索性能
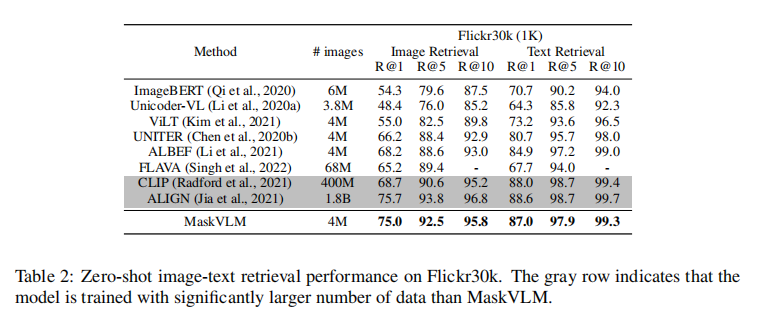
表 1 展示了微调后的检索性能对比,MaskVLM 在 4M 数据量下,除 Flickr30k 的部分指标外,在 COCO 和 Flickr30k 的所有 Recall@k 指标上均取得 SOTA 性能。即使与使用 18 亿数据的 ALIGN 相比,MaskVLM 在 COCO 图像检索 R@1 和 Flickr30k 文本检索 R@1 上仍实现反超。
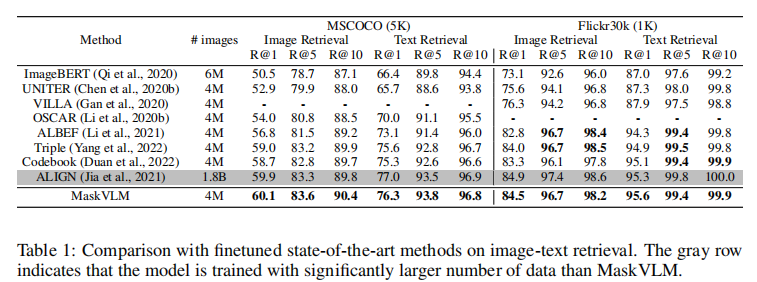
表 2 展示了零 - shot 检索性能,MaskVLM 在 Flickr30k 上的表现尤为突出:图像检索 R@1 达到 75.0,比第二名 ALBEF 高出 6.8 个百分点;即使与使用 4 亿数据的 CLIP 相比,图像检索 R@1 仍高出 6.3 个百分点,充分证明了其跨模态迁移能力。
3.2.2 VQA、NLVR2 和 VE 性能
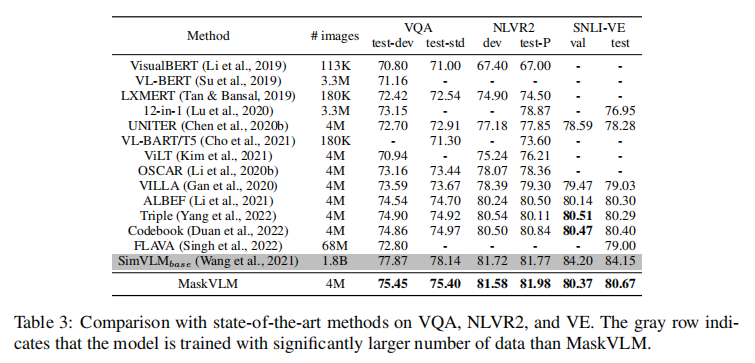
表 3 显示,除了使用 18 亿数据的 SimVLM 外,MaskVLM 在 VQA、NLVR2 和 VE 的所有测试集上均取得最佳性能。其中,VQA test-std 准确率达到 75.40,NLVR2 test-P 准确率达到 81.98,SNLI-VE test 准确率达到 80.67,分别比第二名高出 0.43、1.14 和 0.27 个百分点,验证了模型在复杂跨模态理解任务上的有效性。
3.2.3 有限数据场景性能
这是 MaskVLM 的核心优势之一。实验通过采样 CC 数据集的 50%、25% 和 10%,与 COCO 组合形成不同规模的有限数据集(分别包含约 2M、1.3M 和 0.9M 图文对),对比 MaskVLM 与 ALBEF 的性能。
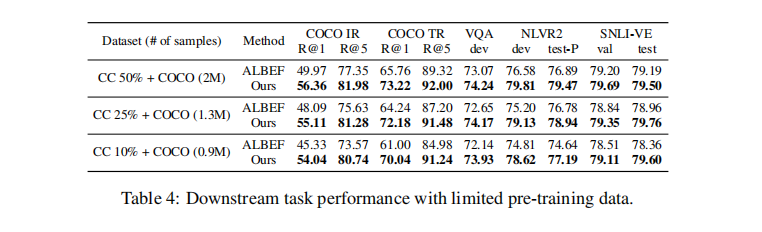
结果显示,随着数据量减少,MaskVLM 与 ALBEF 的性能差距逐渐扩大:
- COCO 图像检索 R@1 的差距从 6.39 个百分点扩大到 8.71 个百分点;
- COCO 文本检索 R@1 的差距从 7.46 个百分点扩大到 9.04 个百分点;
- 即使使用仅 0.9M 图文对的数据集,MaskVLM 的 VQA 和 NLVR2 性能仍超过使用 2M 数据的 ALBEF。
这一结果验证了联合掩码建模能更高效地利用有限数据中的跨模态信息,降低对大规模数据的依赖。
3.3 消融实验
3.3.1 损失函数组件的影响
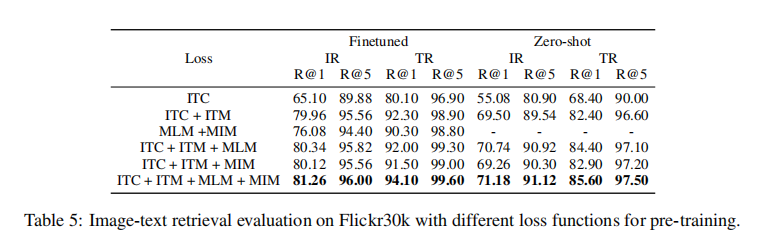
表 5 展示了不同损失组件组合的性能对比,关键结论如下:
- 仅 MLM+MIM 就能实现比单独 ITC 更优的检索性能,证明联合掩码建模本身就能学习有效的跨模态表示;
- 加入 ITC+ITM 后性能显著提升,验证了辅助对齐任务的价值;
- 完整损失(ITC+ITM+MLM+MIM)取得最佳性能,微调后图像检索 R@1 达到 81.26,文本检索 R@1 达到 94.10,零 - shot 性能也最优,证明各组件的互补性。
3.3.2 掩码策略的影响
表 6 对比了 “单模态掩码”(一次仅掩码一种模态)和 “双模态掩码”(同时掩码两种模态)的性能,结果显示单模态掩码策略略优,但两种策略均优于 ALBEF,证明联合掩码建模的有效性不依赖特定掩码方式。
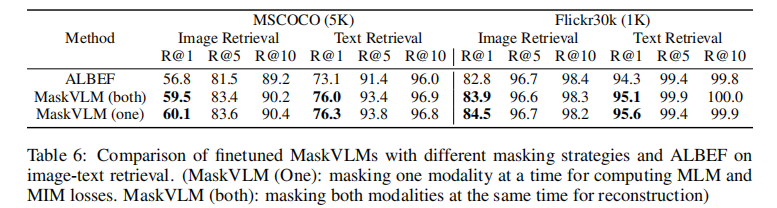
3.3.3 掩码比例的影响
表 7 显示,图像掩码比例在 50%-70% 之间时,模型性能保持稳定;文本掩码比例从 15% 提升至 30% 时,检索性能显著提升,验证了 30% 文本掩码比例的合理性(图像信息可补充文本语义)。
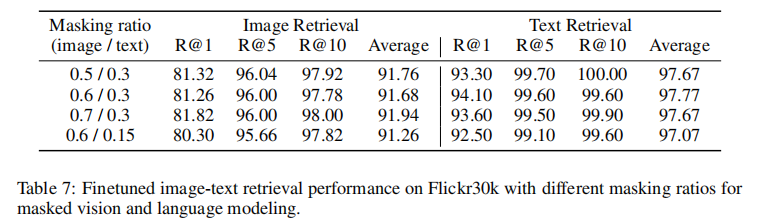
3.4 定性分析
图 5 展示了文本重建的定性结果,对比了使用掩码图像和原始图像进行重建的差异:
- 当输入掩码图像(缺失关键视觉信息)时,模型只能基于有限信息进行推测(如将 “dog” 重建为 “brown of motion”);
- 当输入原始图像(完整视觉信息)时,模型能准确重建掩码 tokens(如 “a brown and white dog”“white fence”),证明模型确实学会了利用跨模态信息进行掩码重建。

注:“Recon (mask)” 表示基于掩码图像的重建结果,“Recon (org)” 表示基于原始图像的重建结果。
四、创新价值与未来方向
4.1 核心创新点
- 提出联合掩码视觉 - 语言建模范式,首次实现端到端的跨模态掩码重建,同时学习
和
) 两种条件分布,解决了传统方法的模态偏置问题;
- 去除了对冻结目标检测器或预训练图像分词器的依赖,直接基于原始 RGB 像素和文本 tokens 进行训练,简化了模型架构并降低了数据依赖;
- 在有限数据场景下表现卓越,仅使用 40% 的 SOTA 模型数据量就能达到相当性能,为数据稀缺场景的跨模态学习提供了新方案;
- 提供了清晰的概率解释,从信息变异量最小化角度验证了方法的合理性,为跨模态建模提供了理论支撑。
4.2 局限性与未来方向
- 模型复杂度较高,跨模态编码器的计算成本相对显著,未来可探索更高效的跨注意力机制;
- 掩码策略仍可优化,当前采用固定比例的随机掩码,未来可结合语义重要性进行自适应掩码;
- 下游任务适配范围可进一步扩展,如多模态生成、视频 - 语言理解等更复杂的跨模态任务;
- 可探索与 Prompt Tuning 等技术的结合,进一步提升模型的零 - shot 和少 - shot 迁移能力。
五、总结
MaskVLM 通过创新的联合掩码视觉 - 语言建模,充分挖掘了图文配对数据的跨模态互补性,实现了更优的跨模态对齐和表示学习。其端到端的训练方式、对有限数据的高效利用以及在多种下游任务上的 SOTA 性能,为跨模态表示学习领域提供了新的研究思路和实践范式。无论是大规模数据场景下的性能突破,还是有限数据场景下的高效学习,MaskVLM 都展现出强大的竞争力,对后续跨模态 AI 模型的研究和应用具有重要的参考价值。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 9
9 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)