【即插即用模块】注意力篇 | AAAI 2026 Oral | LWGA:四种注意力并行,多尺度特征全捕捉!
本文介绍了一种轻量级分组注意力模块(LWGA),该模块针对遥感图像任务中的空间和通道冗余问题设计。LWGA创新性地采用四尺度注意力拆分机制,包含通道门控筛选(GPA)、3×3局部注意力(RLA)、定向中程注意力(SMA)和自适应全局注意力(SGA)四个子模块。实验表明,LWGA能有效处理多尺度特征,在保持轻量化的同时显著提升性能。该模块适用于各类视觉任务,特别是需要平衡精度与效率的场景,可作为即插
VX: shixiaodayyds,备注【即插即用】,添加即插即用模块交流群。
模块出处

Code:https://github.com/AeroVILab-AHU/LWGANet
模块介绍
LWGANet网络结构: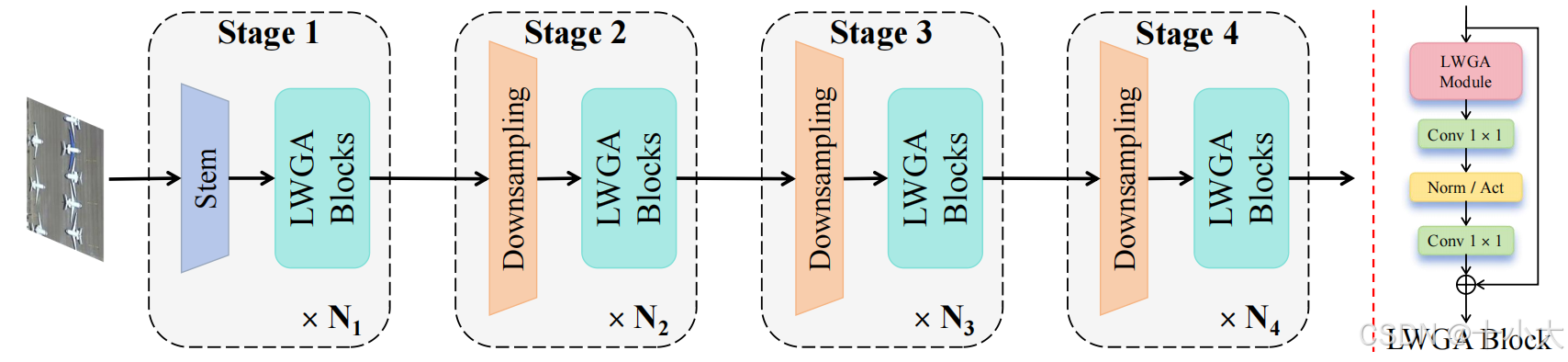
LightWeight Grouped Attention (LWGA)模块: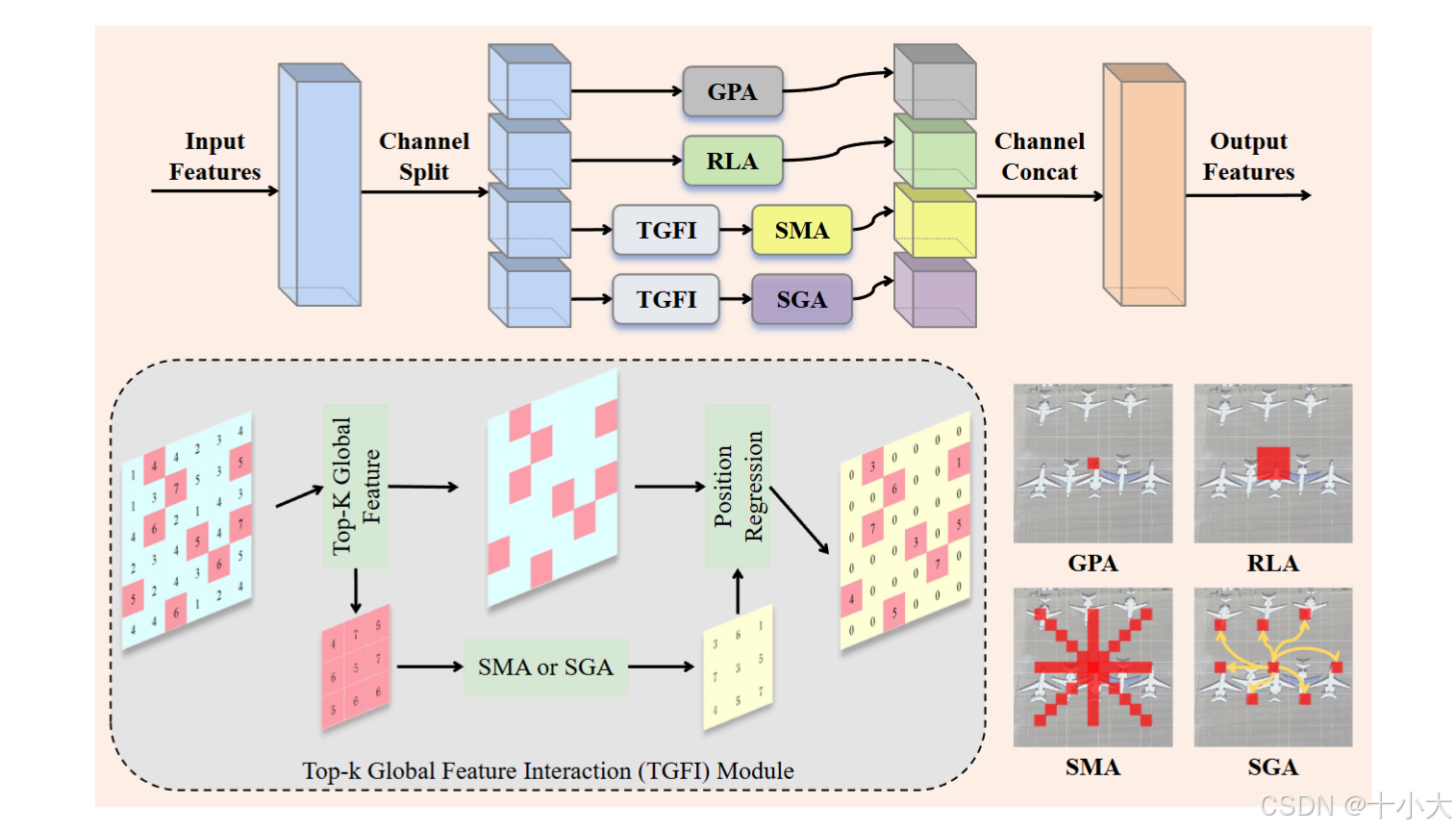
LWGA创新点:四尺度注意力拆分机制。
- Gate Point Attention (GPA):通道门控筛选关键通道,抑制冗余;
- Regular Local Attention (RLA):3×3 卷积捕捉细粒度细节;
- Sparse Medium-range Attention (SMA):定向卷积 + 变换操作,覆盖中距离关联;
- Sparse Global Attention (SGA):阶段自适应设计,平衡全局捕捉与效率;
模块提出的动机(Motivation)
用于遥感 (RS) 视觉分析的轻量级神经网络必须克服两个固有的冗余:来自庞大、同质背景和通道冗余的空间冗余,其中极端尺度变化使得单个特征空间效率低下。现有的模型通常设计用于自然图像的模型无法解决 RS 场景中的这种双重挑战。为了弥合这一差距,我们提出了 LWGANet,这是一种专为 RS 特定属性设计的轻量级主干。LWGANet 引入了两个核心创新:Top-K 全局特征交互 (TGFI) 模块,该模块通过将计算集中在显着区域来减轻空间冗余,以及一个轻量级分组注意力 (LWGA) 模块,该模块通过将通道划分为专门的、特定于尺度的路径来解决通道冗余。
LWGANet 通过联合建模局部细节和远程依赖实现了更好的效果:
适用范围与模块效果
适用范围:适用于通用视觉领域,特别是复杂视觉任务(多尺度、细粒度)与轻量级任务。
缝合位置:检测模型的Backbone/Neck,分割模型的 Encoder/Decoder,其他模型的基本块(残差块/注意力块)。
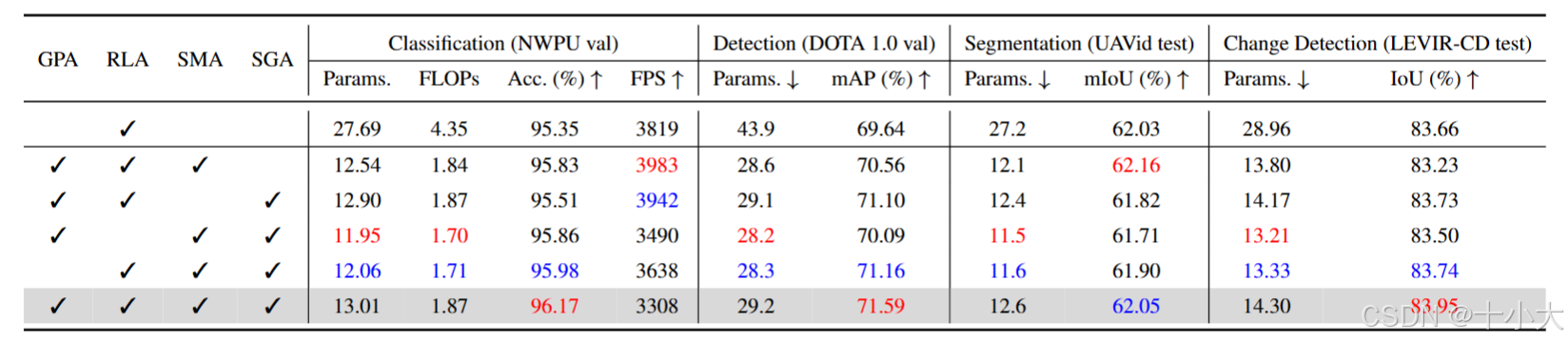
模块效果:LWGA消融研究,使用LWGA比不使用明显涨点。

LWGA各组件消融结果:

LWGA各组件的CAM可视化结果:
模块代码及使用方式
代码逻辑: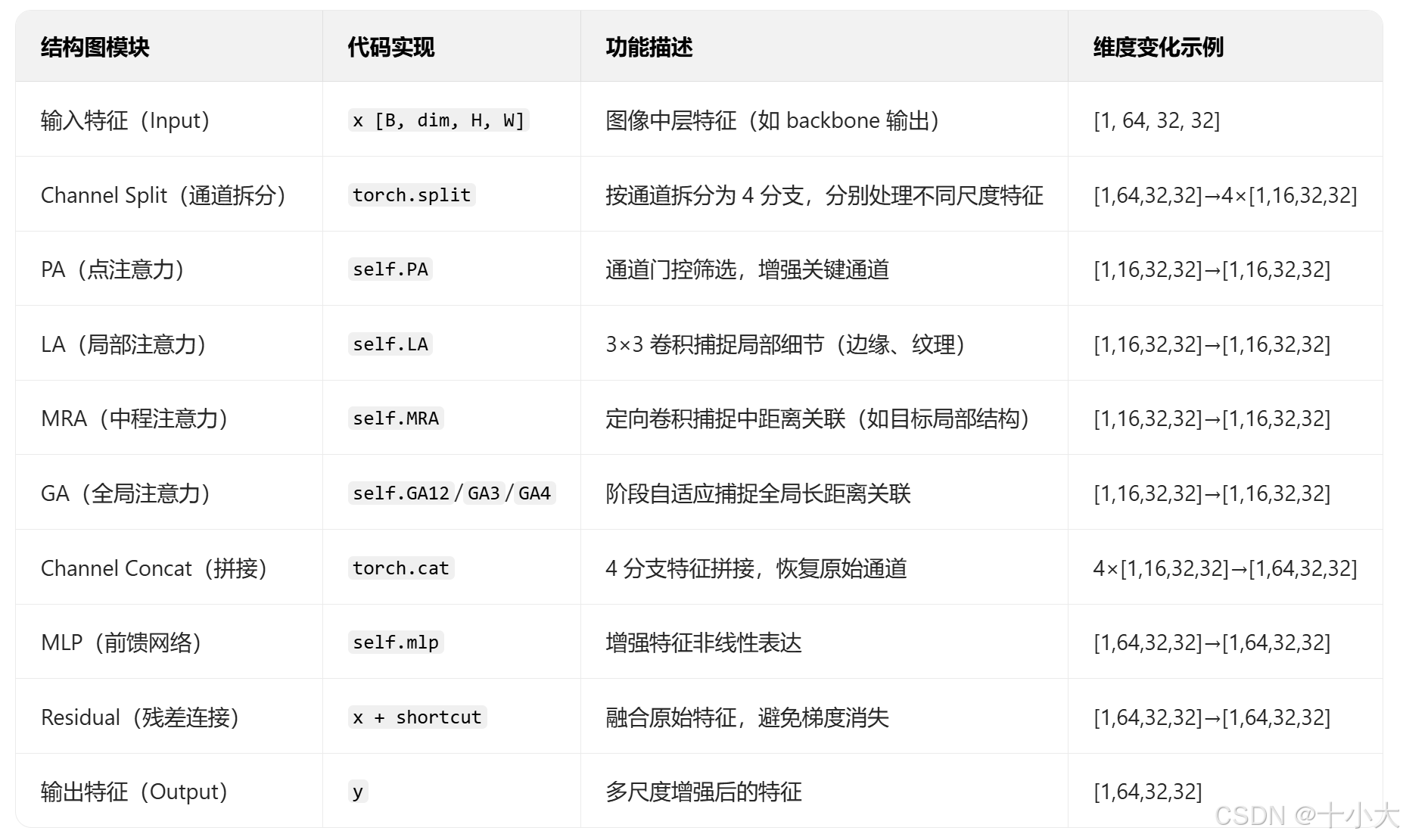
模块代码(详细注释与特征流前向传播过程中的维度变化):
import torch
import torch.nn as nn
from timm.models.layers import DropPath
from typing import List
from torch import Tensor
import antialiased_cnns
import torch.nn.functional as F
class PA(nn.Module):
"""
点注意力模块(PA):基于1×1卷积的通道门控注意力
核心作用:通过通道维度的门控筛选,增强关键通道特征,抑制冗余
输入:特征图 [B, dim, H, W]
输出:门控增强特征 [B, dim, H, W](与输入维度一致)
"""
def __init__(self, dim, norm_layer, act_layer):
super().__init__()
# 1×1卷积序列:通道扩展→归一化→激活→通道恢复,生成门控权重
self.p_conv = nn.Sequential(
nn.Conv2d(dim, dim*4, 1, bias=False), # 通道扩展4倍,增强表达
norm_layer(dim*4), # 归一化稳定训练
act_layer(), # 非线性激活
nn.Conv2d(dim*4, dim, 1, bias=False) # 通道恢复,生成门控权重
)
self.gate_fn = nn.Sigmoid() # 门控函数,权重映射至[0,1]
def forward(self, x):
att = self.p_conv(x) # 生成门控权重
x = x * self.gate_fn(att) # 逐元素加权,筛选有效特征
return x
class LA(nn.Module):
"""
局部注意力模块(LA):基于3×3卷积的局部特征增强
核心作用:捕捉局部邻域关联(如边缘、纹理),补充细粒度细节
输入:特征图 [B, dim, H, W]
输出:局部增强特征 [B, dim, H, W]
"""
def __init__(self, dim, norm_layer, act_layer):
super().__init__()
self.conv = nn.Sequential(
nn.Conv2d(dim, dim, 3, 1, 1, bias=False), # 3×3卷积捕捉局部关联
norm_layer(dim), # 归一化
act_layer() # 非线性激活
)
def forward(self, x):
x = self.conv(x) # 局部特征增强
return x
class MRA(nn.Module):
"""
中程注意力模块(MRA):基于定向卷积的中距离特征关联捕捉
核心作用:通过水平/垂直定向卷积+变换操作,覆盖中距离空间关联
输入:特征图 [B, channel, H, W]
输出:中程增强特征 [B, channel, H, W]
"""
def __init__(self, channel, att_kernel, norm_layer):
super().__init__()
att_padding = att_kernel // 2 # 定向卷积padding,确保尺寸不变
self.gate_fn = nn.Sigmoid()
self.channel = channel
# 池化操作:降低特征分辨率,减少计算量
self.max_m1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1) # 局部池化
self.max_m2 = antialiased_cnns.BlurPool(channel, stride=3) # 抗锯齿池化,平滑特征
# 水平/垂直定向卷积(分组卷积,轻量化)
self.H_att1 = nn.Conv2d(channel, channel, (att_kernel, 3), 1, (att_padding, 1), groups=channel, bias=False)
self.V_att1 = nn.Conv2d(channel, channel, (3, att_kernel), 1, (1, att_padding), groups=channel, bias=False)
self.H_att2 = nn.Conv2d(channel, channel, (att_kernel, 3), 1, (att_padding, 1), groups=channel, bias=False)
self.V_att2 = nn.Conv2d(channel, channel, (3, att_kernel), 1, (1, att_padding), groups=channel, bias=False)
self.norm = norm_layer(channel) # 归一化融合特征
def h_transform(self, x):
"""水平变换:扩展特征宽度,增强水平中程关联捕捉"""
shape = x.size()
x = torch.nn.functional.pad(x, (0, shape[-1])) # 右侧padding
x = x.reshape(shape[0], shape[1], -1)[..., :-shape[-1]] # 重塑裁剪
x = x.reshape(shape[0], shape[1], shape[2], 2*shape[3]-1)
return x
def inv_h_transform(self, x):
"""逆水平变换:恢复原始特征尺寸"""
shape = x.size()
x = x.reshape(shape[0], shape[1], -1).contiguous()
x = torch.nn.functional.pad(x, (0, shape[-2])) # 尾部padding
x = x.reshape(shape[0], shape[1], shape[-2], 2*shape[-2])
x = x[..., 0: shape[-2]] # 裁剪恢复
return x
def v_transform(self, x):
"""垂直变换:扩展特征高度,增强垂直中程关联捕捉"""
x = x.permute(0, 1, 3, 2) # 转置为H-W交换
shape = x.size()
x = torch.nn.functional.pad(x, (0, shape[-1]))
x = x.reshape(shape[0], shape[1], -1)[..., :-shape[-1]]
x = x.reshape(shape[0], shape[1], shape[2], 2*shape[3]-1)
return x.permute(0, 1, 3, 2) # 恢复原始维度顺序
def inv_v_transform(self, x):
"""逆垂直变换:恢复原始特征尺寸"""
x = x.permute(0, 1, 3, 2)
shape = x.size()
x = x.reshape(shape[0], shape[1], -1)
x = torch.nn.functional.pad(x, (0, shape[-2]))
x = x.reshape(shape[0], shape[1], shape[-2], 2*shape[-2])
x = x[..., 0: shape[-2]]
return x.permute(0, 1, 3, 2)
def forward(self, x):
# 特征降采样与平滑
x_tem = self.max_m1(x)
x_tem = self.max_m2(x_tem)
# 水平/垂直中程关联捕捉
x_h1 = self.H_att1(x_tem)
x_w1 = self.V_att1(x_tem)
x_h2 = self.inv_h_transform(self.H_att2(self.h_transform(x_tem)))
x_w2 = self.inv_v_transform(self.V_att2(self.v_transform(x_tem)))
# 特征融合与门控加权
att = self.norm(x_h1 + x_w1 + x_h2 + x_w2)
out = x[:, :self.channel, :, :] * F.interpolate(
self.gate_fn(att), size=(x.shape[-2], x.shape[-1]), mode='nearest'
)
return out
class GA12(nn.Module):
"""
全局注意力模块1/2(GA12):适用于阶段1/2的轻量化全局注意力
核心作用:通过下采样+扩张卷积捕捉全局关联,兼顾效率与覆盖范围
输入:特征图 [B, dim, H, W]
输出:全局增强特征 [B, dim, H, W]
"""
def __init__(self, dim, act_layer):
super().__init__()
self.downpool = nn.MaxPool2d(kernel_size=2, stride=2, return_indices=True) # 下采样
self.uppool = nn.MaxUnpool2d((2, 2), 2, padding=0) # 上采样恢复
self.proj_1 = nn.Conv2d(dim, dim, 1) # 特征投影
self.activation = act_layer() # 激活
self.conv0 = nn.Conv2d(dim, dim, 5, padding=2, groups=dim) # 分组卷积提取特征
self.conv_spatial = nn.Conv2d(dim, dim, 7, stride=1, padding=9, groups=dim, dilation=3) # 扩张卷积捕捉全局
self.conv1 = nn.Conv2d(dim, dim // 2, 1) # 通道拆分1
self.conv2 = nn.Conv2d(dim, dim // 2, 1) # 通道拆分2
self.conv_squeeze = nn.Conv2d(2, 2, 7, padding=3) # 挤压融合门控权重
self.conv = nn.Conv2d(dim // 2, dim, 1) # 通道恢复
self.proj_2 = nn.Conv2d(dim, dim, 1) # 输出投影
def forward(self, x):
x_, idx = self.downpool(x) # 下采样
x_ = self.proj_1(x_)
x_ = self.activation(x_)
# 双路径特征提取
attn1 = self.conv0(x_)
attn2 = self.conv_spatial(attn1)
# 通道拆分与门控融合
attn1 = self.conv1(attn1)
attn2 = self.conv2(attn2)
attn = torch.cat([attn1, attn2], dim=1)
avg_attn = torch.mean(attn, dim=1, keepdim=True)
max_attn, _ = torch.max(attn, dim=1, keepdim=True)
agg = torch.cat([avg_attn, max_attn], dim=1)
sig = self.conv_squeeze(agg).sigmoid() # 门控权重
attn = attn1 * sig[:, 0, :, :].unsqueeze(1) + attn2 * sig[:, 1, :, :].unsqueeze(1)
attn = self.conv(attn)
# 加权与恢复
x_ = x_ * attn
x_ = self.proj_2(x_)
x = self.uppool(x_, indices=idx) # 上采样恢复尺寸
return x
class D_GA(nn.Module):
"""
深度全局注意力模块(D_GA):适用于阶段2的全局注意力,含归一化
输入:特征图 [B, dim, H, W]
输出:全局增强特征 [B, dim, H, W]
"""
def __init__(self, dim, norm_layer):
super().__init__()
self.norm = norm_layer(dim) # 归一化
self.attn = GA(dim) # 全局注意力核心
self.downpool = nn.MaxPool2d(kernel_size=2, stride=2, return_indices=True) # 下采样
self.uppool = nn.MaxUnpool2d((2, 2), 2, padding=0) # 上采样
def forward(self, x):
x_, idx = self.downpool(x)
x = self.norm(self.attn(x_)) # 注意力+归一化
x = self.uppool(x, indices=idx) # 恢复尺寸
return x
class GA(nn.Module):
"""
基础全局注意力模块(GA):适用于阶段3的标准多头注意力
核心作用:通过多头注意力捕捉全局长距离关联
输入:特征图 [B, dim, H, W]
输出:全局增强特征 [B, dim, H, W]
"""
def __init__(self, dim, head_dim=4, num_heads=None, qkv_bias=False,
attn_drop=0., proj_drop=0., proj_bias=False, **kwargs):
super().__init__()
self.head_dim = head_dim # 单头通道数
self.scale = head_dim ** -0.5 # 缩放因子
self.num_heads = num_heads if num_heads else dim // head_dim # 注意力头数
if self.num_heads == 0:
self.num_heads = 1
self.attention_dim = self.num_heads * self.head_dim # 注意力总通道数
self.qkv = nn.Linear(dim, self.attention_dim * 3, bias=qkv_bias) # QKV投影
self.attn_drop = nn.Dropout(attn_drop) # 注意力Dropout
self.proj = nn.Linear(self.attention_dim, dim, bias=proj_bias) # 输出投影
self.proj_drop = nn.Dropout(proj_drop) # 输出Dropout
def forward(self, x):
B, C, H, W = x.shape
x = x.permute(0, 2, 3, 1) # BCHW→BHWC
N = H * W
# QKV生成与拆分
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, self.head_dim).permute(2, 0, 3, 1, 4)
q, k, v = qkv.unbind(0)
# 注意力计算
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
# 加权与恢复
x = (attn @ v).transpose(1, 2).reshape(B, H, W, self.attention_dim)
x = self.proj(x)
x = self.proj_drop(x)
x = x.permute(0, 3, 1, 2) # BHWC→BCHW
return x
class LWGA_Block(nn.Module):
"""
轻量化多尺度门控注意力块(LWGA_Block):LWGA核心模块,融合多尺度注意力
核心创新:
1. 四分支注意力拆分:按通道拆分,分别处理点、局部、中程、全局特征;
2. 阶段自适应全局注意力:不同网络阶段适配不同全局注意力,平衡效率与精度;
3. 轻量化设计:分组卷积、通道拆分、下采样等降低计算量;
4. 门控与残差融合:提升特征判别性,稳定深层训练。
输入:特征图 [B, dim, H, W]
输出:多尺度增强特征 [B, dim, H, W](与输入维度一致)
"""
def __init__(self,
dim,
stage,
att_kernel,
mlp_ratio,
drop_path,
act_layer=nn.GELU,
norm_layer=nn.BatchNorm2d
):
super().__init__()
self.stage = stage
self.dim_split = dim // 4
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
mlp_hidden_dim = int(dim * mlp_ratio)
mlp_layer: List[nn.Module] = [
nn.Conv2d(dim, mlp_hidden_dim, 1, bias=False),
norm_layer(mlp_hidden_dim),
act_layer(),
nn.Conv2d(mlp_hidden_dim, dim, 1, bias=False)
]
self.mlp = nn.Sequential(*mlp_layer)
self.PA = PA(self.dim_split, norm_layer, act_layer) # PA is point attention
self.LA = LA(self.dim_split, norm_layer, act_layer) # LA is local attention
self.MRA = MRA(self.dim_split, att_kernel, norm_layer) # MRA is medium-range attention
if stage == 2:
self.GA3 = D_GA(self.dim_split, norm_layer) # GA3 is global attention (stage of 3)
elif stage == 3:
self.GA4 = GA(self.dim_split) # GA4 is global attention (stage of 4)
self.norm = norm_layer(self.dim_split)
else:
self.GA12 = GA12(self.dim_split, act_layer) # GA12 is global attention (stages of 1 and 2)
self.norm = norm_layer(self.dim_split)
self.norm1 = norm_layer(dim)
self.drop_path = DropPath(drop_path)
def forward(self, x: Tensor) -> Tensor:
# for training/inference
shortcut = x.clone()
x1, x2, x3, x4 = torch.split(x, [self.dim_split, self.dim_split, self.dim_split, self.dim_split], dim=1)
x1 = x1 + self.PA(x1)
x2 = self.LA(x2)
x3 = self.MRA(x3)
if self.stage == 2:
x4 = x4 + self.GA3(x4)
elif self.stage == 3:
x4 = self.norm(x4 + self.GA4(x4))
else:
x4 = self.norm(x4 + self.GA12(x4))
x_att = torch.cat((x1, x2, x3, x4), 1)
x = shortcut + self.norm1(self.drop_path(self.mlp(x_att)))
return x
if __name__ == "__main__":
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
x = torch.randn(1, 64, 32, 32).to(device)
model = LWGA_Block(64, 1, 11, 2, 0.1)
model.to(device)
y = model(x)
print("微信公众号:十小大的底层视觉工坊")
print("VX: shixiaodayyds, 备注【即插即用】添加交流群")
print("知乎、CSDN:十小大")
print("输入特征维度:", x.shape)
print("输出特征维度:", y.shape)
运行结果:

至此本文结束。
如果本文对你有所帮助,请点赞收藏,创作不易,感谢您的支持!
点击下方👇公众号区域,扫码关注,可免费领取一份200+即插即用模块资料!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 35
35 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)