大模型平台搭建(五)本地模型Xinference平台部署
本文介绍了本地Xinference平台的部署流程,重点解决Rerank模型支持问题。
·
大模型平台搭建(五)本地模型Xinference平台部署
Xinference 部署指南
上次提到Ollama平台缺少对Rerank模型的支撑,本次文章中Xinference平台可满足Rerank模型的使用需求。以下是详细的 Xinference 部署流程。
环境准备
- Docker 20.10+ 版本
- 至少 8GB 内存(建议 16GB+ 以运行大模型)
- 支持 NVIDIA GPU 的机器(可选,需安装 NVIDIA Container Toolkit)
快速部署
创建持久化数据目录
# 创建xinference持久化数据目录
1. mkdir /data/xinference
# 进入xinference目录
2. cd /data/xinference
# 创建docker-compose.yml文件
3. vim docker-compose.yml
docker-compose.yml
version: '3.8'
services:
xinference:
image: xprobe/xinference:latest-cpu # 请替换为实际版本号
container_name: xinference
environment:
- XINFERENCE_MODEL_SRC=modelscope # 设置模型源环境变量
- XINFERENCE_HOME=/data/xinference # 环境变量设置
ports:
- "9997:9997" # 端口映射(宿主机:容器)
command: xinference-local -H 0.0.0.0 --log-level debug # 容器启动命令
restart: unless-stopped # 可选:设置重启策略
# 如需持久化数据,可添加数据卷挂载
volumes:
- /data/xinference:/data/xinference
GPU 加速(可选)
若需 GPU 支持,启动时添加 --gpus all 参数:
version: '3.8'
services:
xinference:
image: xprobe/xinference:latest # GPU版本镜像(无-cpu后缀)
container_name: xinference
restart: always # 对应--restart=always
volumes:
- /data/xinference:/data/xinference # 数据卷挂载
environment:
- XINFERENCE_HOME=/data/xinference # 工作目录环境变量
- XINFERENCE_MODEL_SRC=modelscope # 模型源环境变量
ports:
- "9998:9997" # 端口映射(宿主机:容器)
command: xinference-local -H 0.0.0.0 # 启动命令
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all # 使用所有GPU,对应--gpus all
capabilities: [gpu] # 声明GPU能力
启动Xinference平台
# 使用docker-compose启动
docker-compose up -d
# 查看目前的运行状态
docker-compose ps
# 运行状态
NAME IMAGE COMMAND SERVICE CREATED STATUS PORTS
xinference xprobe/xinference:latest-cpu "xinference-local -H…" xinference 6 minutes ago Up 6 minutes 0.0.0.0:9997->9997/tcp, :::9997->9997/tcp
模型部署
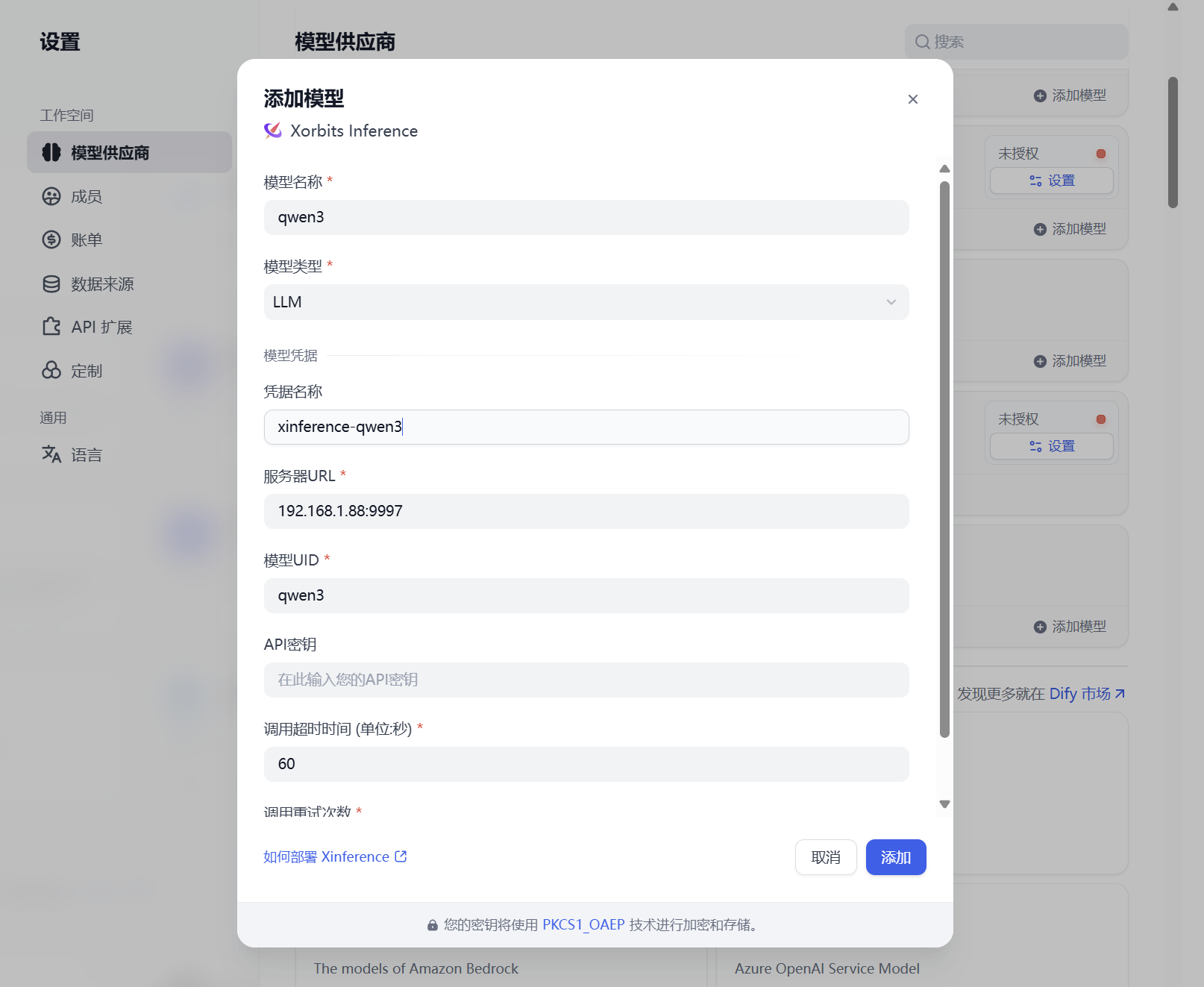
登录Xinference平台,例如:http://192.168.1.88:9997
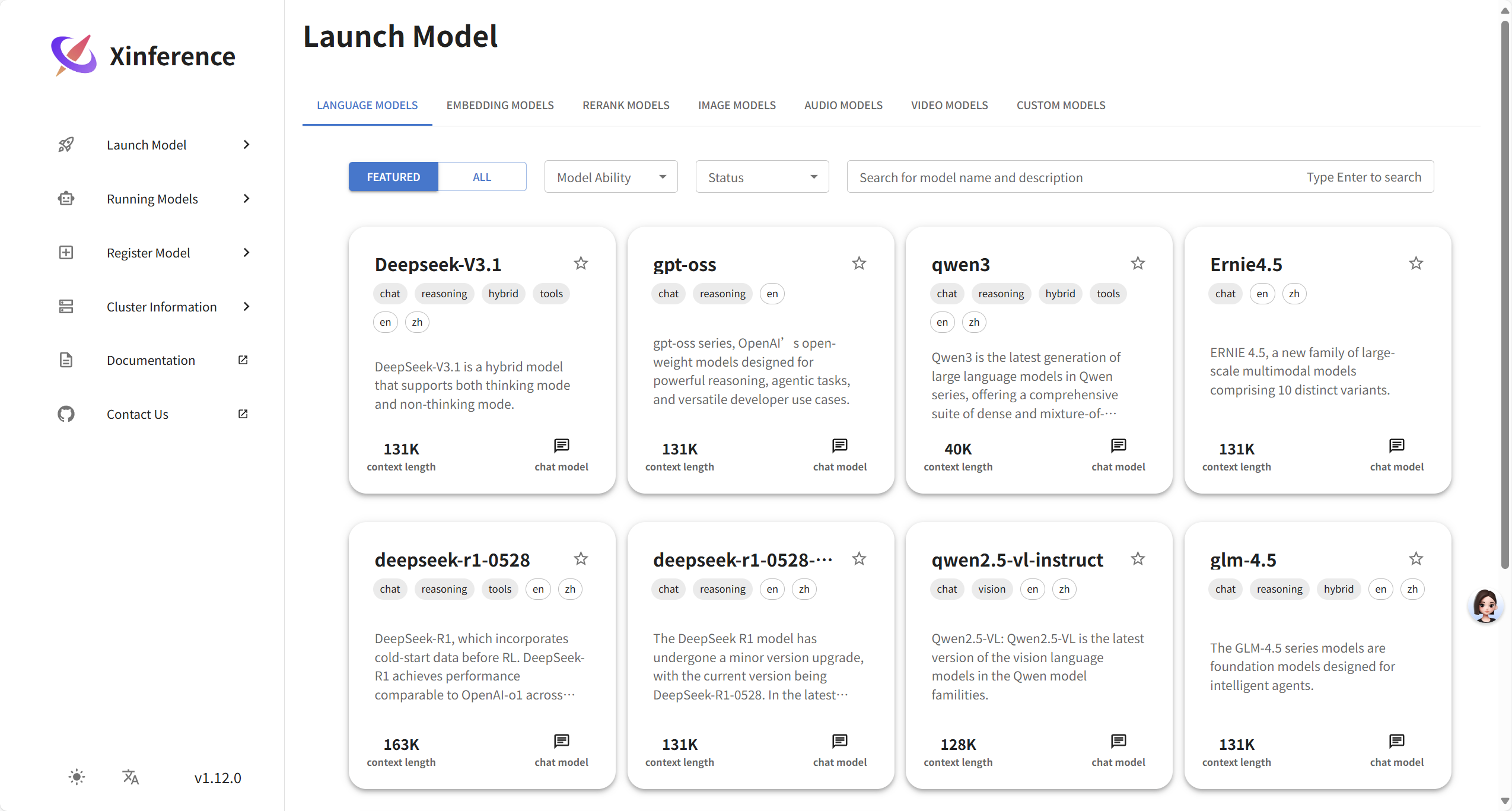
功能说明:
- launch Model:可以发现一些内置的模型,只是这些模型需要下载才可以使用,可以直接在页面上点击下载
- Running Models:正在运行的模型
- Register Model:注册模型,可以将自己微调后的模型在这里注册
- Cluster Information:集群信息,在这里可以看到当前xinference部署的宿主机的硬件信息
内置的模型类型:
- 大语言模型
- 嵌入模型
- 图像模型
- 音频模型
- 重排序模型
- 视频模型
选择自己想用的模型后就可以开始安装了,我这边以qwen3模型做演示
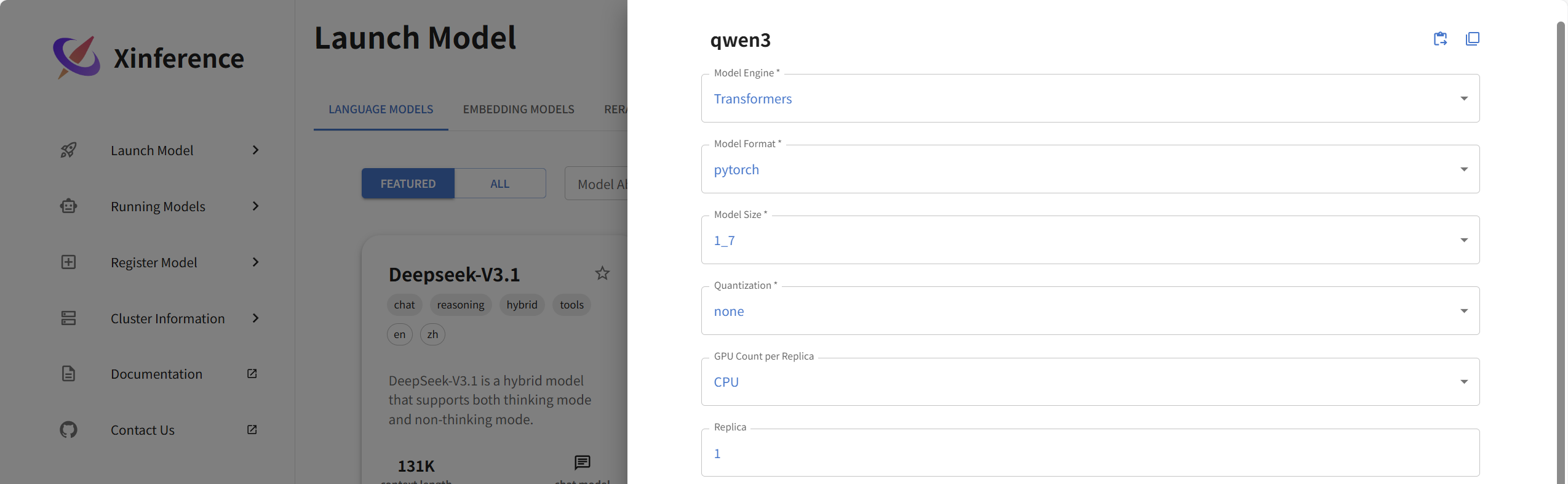
选中模型后,可以看到部署模型需要的参数
- Model Engine (模型引擎):运行模型的引擎或者框架
- Model Format (模型格式):模型训练或推理时使用的底层框架
- Model Size (模型大小):模型越大,所需的内存和计算资源也越多,单位是“十亿”
- Quantization (量化):量化通常用于减小模型大小并加速推理
- N-GPU (GPU数量):模型允许使用几个GPU
- Replica (副本数量):更多副本意味着可以处理更多并发请求。
同时在Optional Configuration中需要选择一下Dowload_hub。
点击部署后,通过日志 docker-compose logs -f查看模型安装进度,会在日志里显示进度条。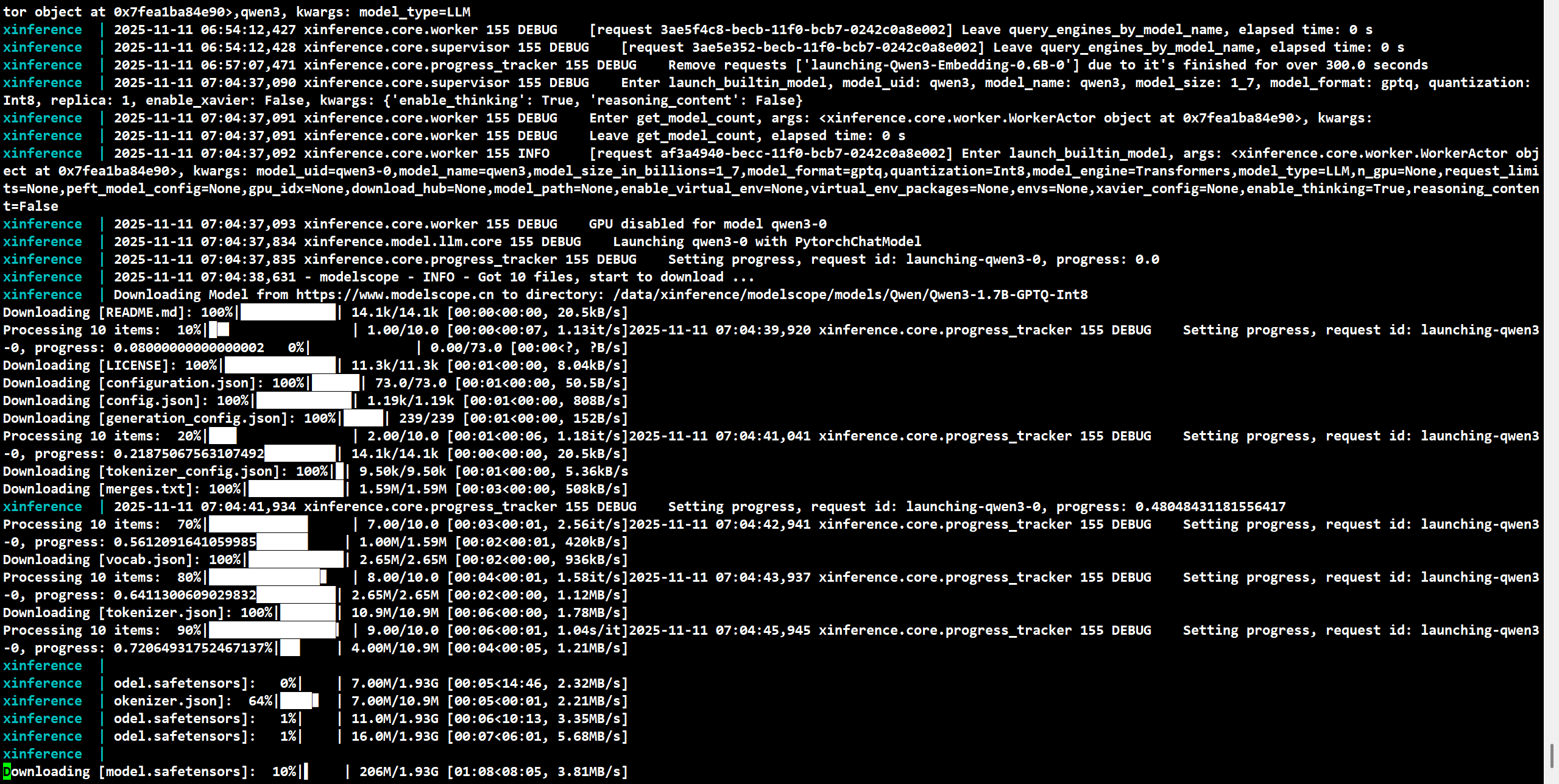
一般大语言模型都比较大,需要等待较长时间。
模型调用
模型部署完成后,可以在运行模型模块看到部署的模型。
然后点击操作中红框的图标,就可以对模型进行适用啦。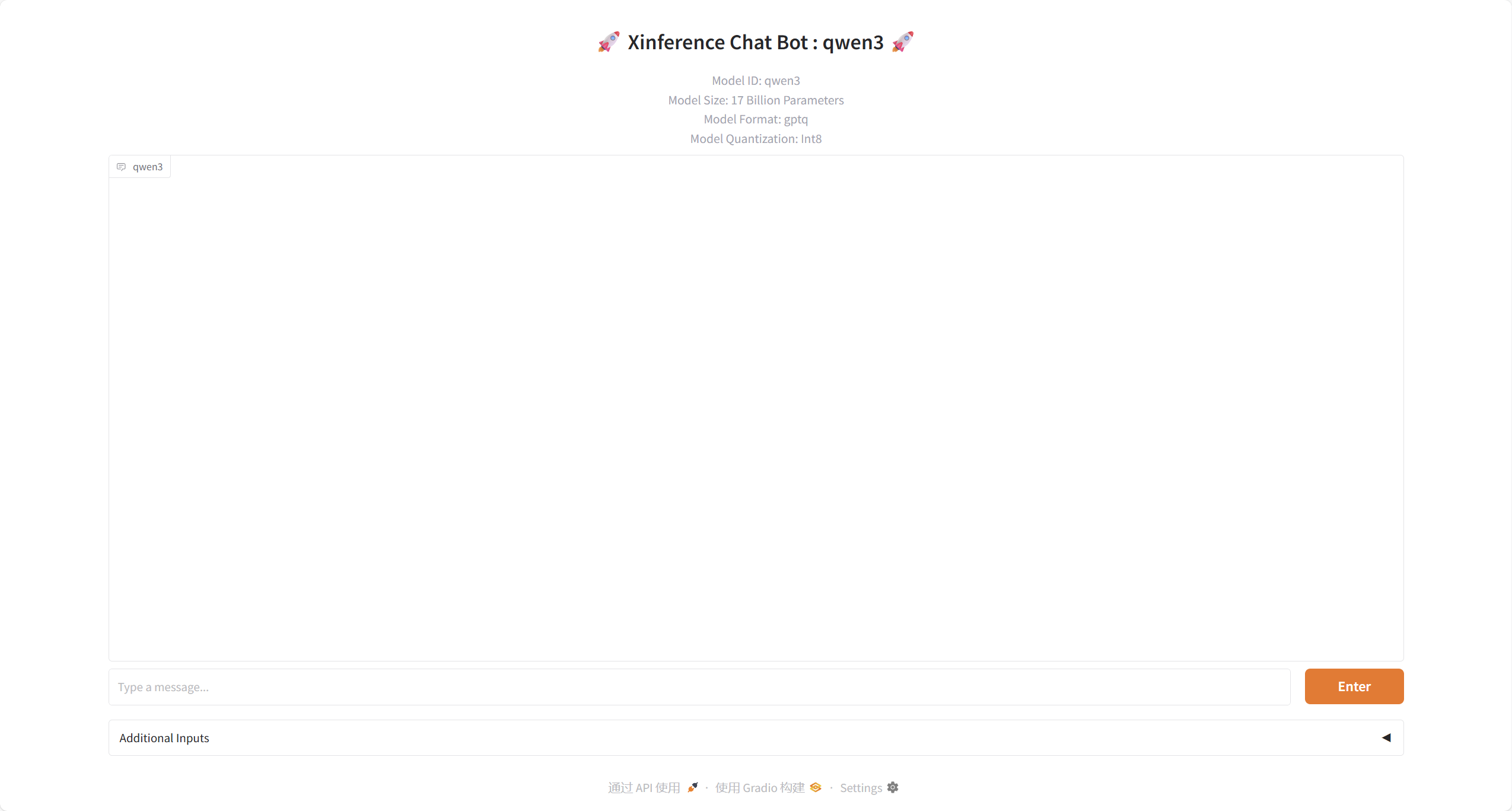
其它模型平台接入Xinference平台部署的模型
Dify接入

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)