AI驱动的缺陷全自动修复
摘要:本文探讨了AI加速软件开发过程中产生的效率失衡问题,提出了端到端自动修复体系设计方案。核心矛盾在于AI提升了编码速度,但测试、评审等环节压力倍增,导致"造得快、修得慢"的瓶颈。解决方案采用5阶段闭环流程(上报、分析、修复、测试、评审),强调工程化体系(上下文分层、Hook检测、证据链)比算法更重要。关键创新点包括:分层上下文加载机制、分阶段质量门控、自进化知识库。实践表明
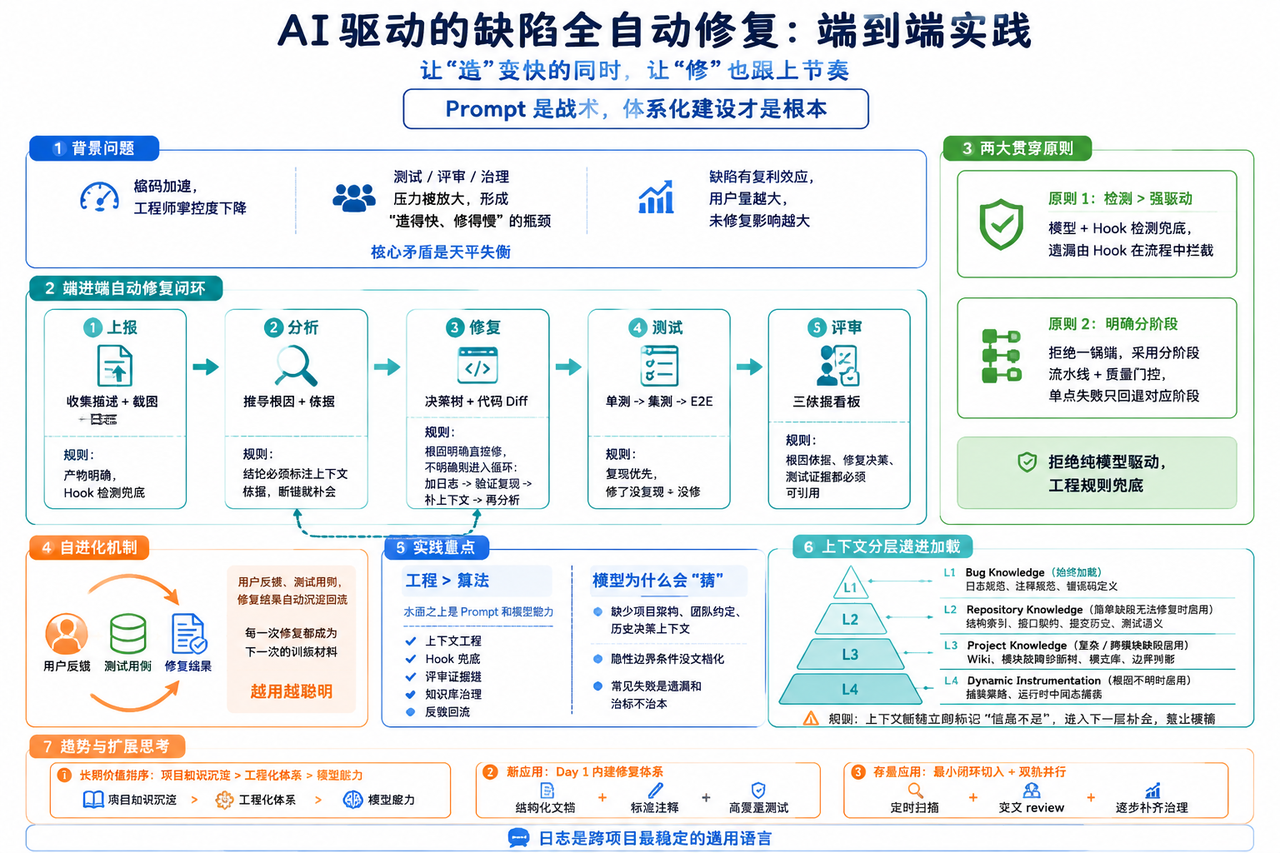
一、背景:AI提效带来的新问题
核心矛盾:天平失衡
| 环节 | AI带来的影响 |
| 编码 | 加速产出,工程师掌控度下降 |
| 测试/评审/治理 | 压力被反向放大,形成「造得快、修得慢」的瓶颈 |
| 本质 | 缺陷存在复利效应,用户量越大,未修复缺陷的影响呈指数级放大 |
核心命题
AI让「造」变快的同时,必须通过缺陷修复全链路自动化让「修」跟上节奏;Prompt是战术,体系化建设才是根本。
二、端到端自动修复体系设计
5阶段闭环流程
| 阶段 | 核心动作 | 关键规则 |
| 上报 | 收集描述+截图+日志 | 产物明确,Hook检测兜底 |
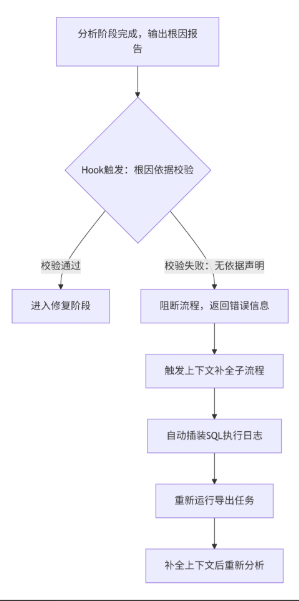
| 分析 | 推导根因+依据 | 结论必须标注「依据上下文」,断链则触发补全子流程 |
| 修复 | 决策树+代码Diff | 根因明确直接修复;不明确则进入「加日志→验证复现→补上下文→再分析」循环 |
| 测试 | 金字塔+E2E验证 | 单测(底层快速反馈)→集测(中层链路验证)→E2E(顶层含Computer-Use);复现优先,修了没复现=没修 |
| 评审 | 三依据看板 | 不依赖人脑记忆,依赖可引用证据链: • 根因依据:分析报告、推理链 • 修复决策:代码Diff、决策说明、规范引用 • 测试证据:截图、录屏、用例结果 |
两大贯穿原则
| 原则 | 具体做法 |
| 检测>强驱动 | 拒绝纯模型驱动,采用「模型+Hook检测」兜底:模型遗漏由Hook在阶段3拦截,避免缺陷流出 |
| 明确分阶段 | 拒绝「一锅端」,采用分阶段流水线+质量门控:单点出错仅回退对应阶段,不推翻整体流程 |
自进化机制
用户反馈、测试用例自动沉淀回流,每一次修复都成为下一次的训练材料,实现「越用越聪明」。
三、实践经验:难点与重点
核心认知:工程>算法
水面之上可见的是算法/Prompt技巧,水面之下决定持续价值的是上下文工程、Hook兜底、评审证据链、知识库治理、反馈回流等工程体系。
模型「猜」的问题根源
| 现象 | 原因 | 典型失败模式 |
| 模型倾向「给答案>承认不知」,用通用知识填补输入缺失 | 模型能力≠项目知识: • 缺少项目架构/团队约定/历史决策上下文 • 隐性边界条件无文档记录 |
• 遗漏:单点修复导致回归新问题 • 治标不治本:try-catch吞异常/硬编码偏移,根因未解决反而加深隐患 |
两大解决重点
(1)上下文分层递进加载
| 层级 | 适用场景 | 包含内容 |
| L1 Bug Knowledge | 始终加载 | 日志规范、注释规范、错误码定义 |
| L2 Repository Knowledge | 简单缺陷无法修复时启用 | 结构索引、接口契约、提交历史、测试语义 |
| L3 Project Knowledge | 复杂/跨模块缺陷启用 | Wiki、模块故障诊断树、模式库、判断边界 |
| L4 Dynamic Instrumentation | 根因不明时启用 | 插装策略、运行时中间态捕获 |
规则:上下文断链立即标记「信息不足」,进入下一层补全,禁止硬猜
(2)分阶段产物+Hook检测
通过工程规则兜底,不依赖模型自觉,每个阶段输出标准化产物,Hook校验不通过则阻断流程。
四、趋势与扩展思考
长期价值排序
项目知识沉淀>工程化体系>模型能力:前两者可长期沉淀进化,是抗模型迭代风险的「地基」。
两类应用场景策略
| 应用类型 | 策略 | 核心动作 |
| 新应用(无历史包袱) | AI友好化前置 | 从Day-1内建修复体系:结构化文档+标准注释+高覆盖测试,治理动作前置到设计开发阶段 |
| 存量应用 | 最小闭环切入→双轨并行 | • 轨道一:用例驱动开发,补齐review、日志规范、注释、知识库、测试覆盖 • 轨道二:定时扫描,7×24主动发现问题,多次交叉review避免遗漏 |
通用规律
日志是跨项目最稳定的「通用语言」:缺陷上下文提供方式、复现/验证方式因端/技术栈而异,但链路分析均可基于日志实现。
Hook规则写法详解
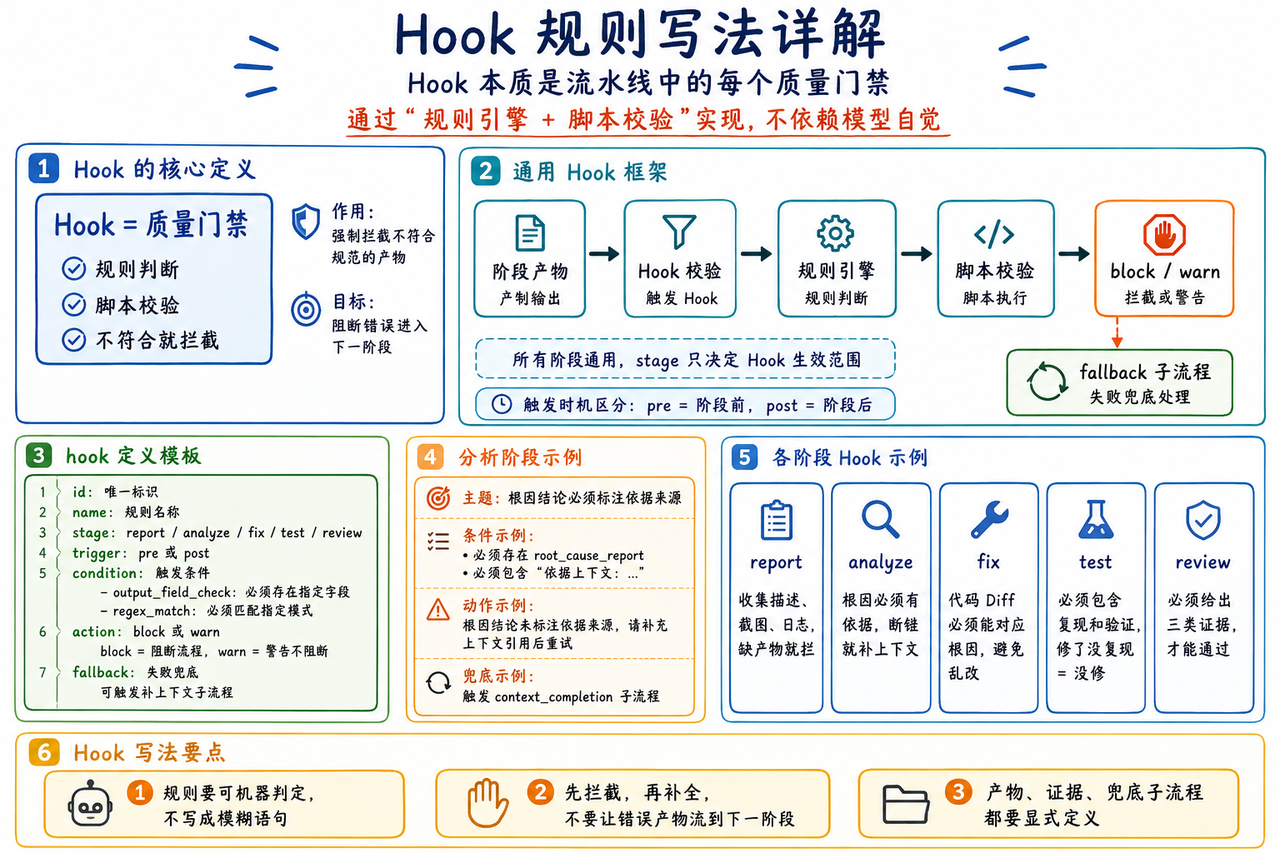
Hook本质是流水线中的每个质量门禁,通过「规则引擎+脚本校验」实现,不依赖模型自觉,强制拦截不符合规范的产物。
通用Hook框架(所有阶段通用)
# hook定义模板(以分析阶段为例) hook: id: analyze_root_cause_check name: 根因结论依据校验 stage: analyze # 生效阶段:report/analyze/fix/test/review trigger: post # 触发时机:pre(阶段前)/post(阶段后) condition: # 触发条件(逻辑表达式) - type: output_field_check field: root_cause_report operator: exists # 必须存在根因报告 - type: regex_match field: root_cause_report pattern: "依据上下文:.+" # 必须包含依据声明 action: # 拦截动作 type: block # block=阻断流程,warn=警告不阻断 message: "根因结论未标注依据来源,请补充上下文引用后重试" fallback: # 失败兜底 type: trigger_sub_flow sub_flow: context_completion # 触发上下文补全子流程
各阶段具体Hook规则示例
| 阶段 | Hook名称 | 核心校验逻辑 | 拦截场景示例 | 兜底动作 |
| 上报阶段 | 日志完整性校验 | trace_id != null && log.contains("export_task_start") && log.contains("export_task_end") | 上报日志缺失TraceID或任务起止标记 | 触发日志插装子流程 |
| 分析阶段 | 根因依据校验 | root_cause_report.matches("依据上下文:.+") && evidence_list.length >=1 | 模型输出"可能是索引问题"但无日志/提交记录支撑 | 触发调试增强子循环 |
| 修复阶段 | SQL变更规范校验 | code_diff.type == "sql" && sql.parse(diff).contains("INDEX") && rule_engine.check("index_naming_rule") | 模型添加的索引名不符合idx_表名_字段名规范 | 返回修复建议,阻断合并 |
| 测试阶段 | E2E用例强制校验 | test_result.e2e_pass == true && test_data.volume >= 1000000 | 仅通过单测,未复现百万数据超时场景 | 触发E2E用例生成子流程 |
| 评审阶段 | 三依据完整性校验 | evidence_board.root_cause_ref != null && evidence_board.fix_decision_ref != null && evidence_board.test_evidence_ref != null | 缺少测试证据或根因依据 |
上下文分层实现逻辑详解
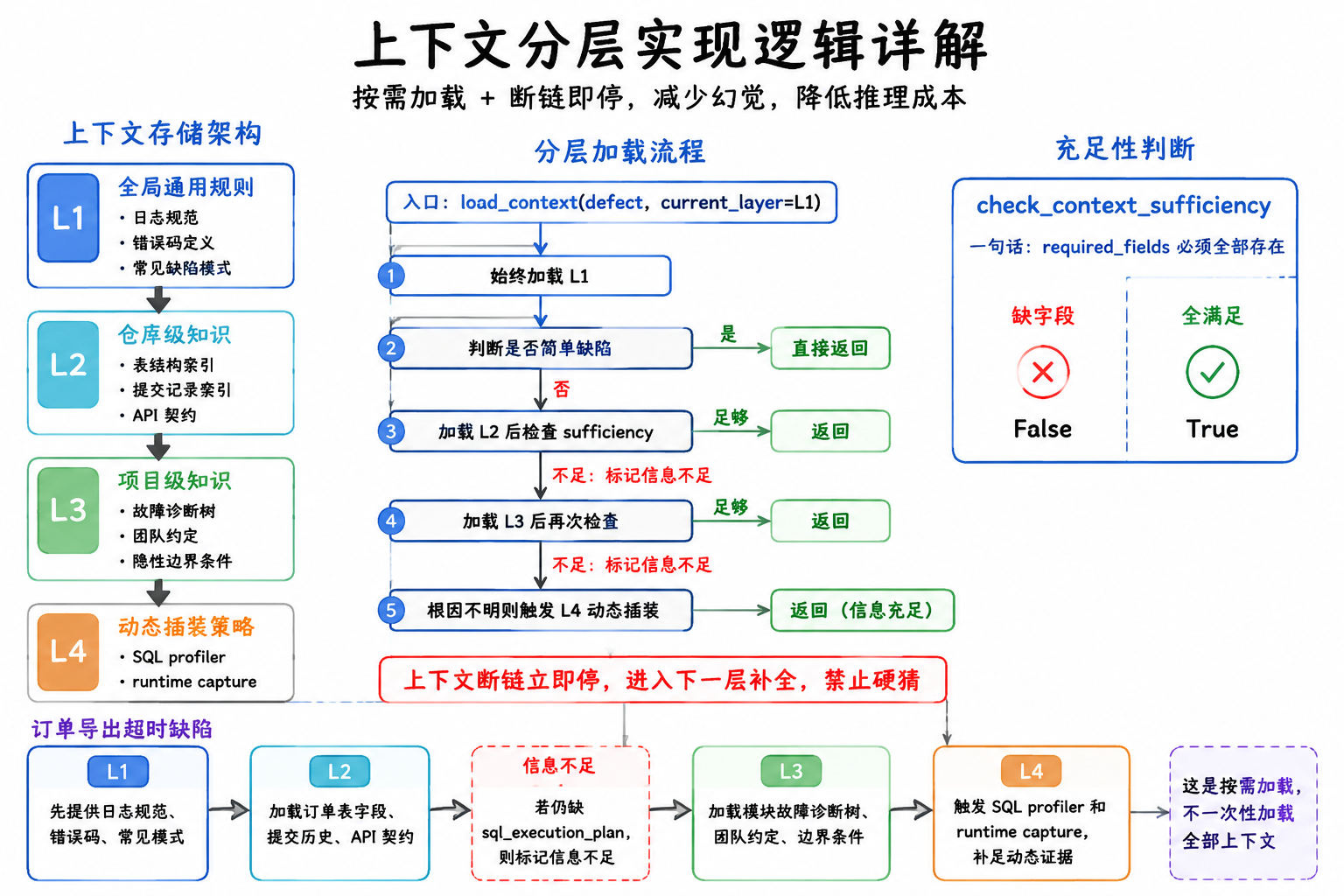
上下文分层的核心是按需加载+断链即停,避免一次性喂入过多无关信息导致模型幻觉,同时降低推理成本。
上下文存储架构
context-store/ ├── L1_bug_knowledge/ # 全局通用规则 │ ├── log_spec.yaml # 日志规范 │ ├── error_code.yaml # 错误码定义 │ └── common_patterns.json # 常见缺陷模式 ├── L2_repo_knowledge/ # 仓库级知识 │ ├── schema/ # 表结构索引 │ │ └── order_table.yaml # 订单表字段+索引定义 │ ├── commit_history/ # 提交记录索引 │ │ └── index.json # 按文件/功能索引的提交记录 │ └── api_contract/ # API契约 ├── L3_project_knowledge/ # 项目级知识 │ ├── module_diagnosis_tree/ # 模块故障诊断树 │ │ └── export_timeout.yaml │ ├── team_conventions/ # 团队约定 │ └── boundary_conditions/ # 隐性边界条件 └── L4_dynamic_instrumentation/ # 动态插装策略 ├── sql_profiler.yaml # SQL执行计划插装规则 └── runtime_capture.yaml # 运行时变量捕获规则
分层加载逻辑(伪代码)
def load_context(defect, current_layer=L1): # 1. 始终加载L1基础上下文 context = load_L1_context() # 2. 判断是否需要加载更高层级 if is_simple_defect(defect): # 简单缺陷(如空指针异常):L1足够 return context # 3. 尝试L2仓库知识 if current_layer >= L2: repo_context = load_L2_repo_context(defect.module) context.merge(repo_context) # 检查上下文是否充足 if check_context_sufficiency(context, defect): return context # 断链:标记信息不足,准备升级层级 mark_insufficient_context(defect, missing_fields=["sql_execution_plan"]) # 4. 尝试L3项目知识(复杂/跨模块缺陷) if current_layer >= L3: project_context = load_L3_project_context(defect.project) context.merge(project_context) if check_context_sufficiency(context, defect): return context # 5. 最后尝试L4动态插装(根因不明时) if current_layer >= L4: dynamic_context = trigger_dynamic_instrumentation(defect) context.merge(dynamic_context) return context def check_context_sufficiency(context, defect): # 校验上下文是否覆盖缺陷分析所需的最小字段集 required_fields = get_required_fields(defect.type) for field in required_fields: if field not in context: return False return True
场景落地示例(订单导出超时缺陷)
| 步骤 | 加载层级 | 加载内容 | 判断是否充足 | 下一步动作 |
| 1 | L1 | 日志规范(export_前缀)、错误码EXPORT_TIMEOUT=5001 | 不足(缺SQL相关信息) | 升级到L2 |
| 2 | L2 | 订单表结构(字段定义)、提交记录#1234(删除索引) | 不足(缺SQL执行计划) | 升级到L3 |
| 3 | L3 | 导出超时诊断树、团队约定「大数据查询必加索引」 | 不足(缺实际执行计划) | 升级到L4 |
| 4 | L4 | 动态插装的SQL执行计划日志 | 充足(找到全表扫描证据) | 开始根因分析 |

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 4
4 0
0- 0



 已为社区贡献37条内容
已为社区贡献37条内容

所有评论(0)