用CANN DataFlow优化工业视频检测:从代码到效果的细节拆解
每个节点用@process_point装饰,指定运行设备(CPU/AI Core),输入输出通过队列自动流转。预处理节点(CPU):负责图像格式转换、归一化,输出直接进队列。import cv2# 定义队列:pre2infer存预处理结果,infer2post存推理结果# 1. BGR转RGB(工业摄像头默认BGR)# 2. Resize到640×640# 3. 归一化(转float32,减均值除
文章目录
曾经我负责的工业摄像头目标检测项目,曾因“数据流转卡壳”导致检测延迟居高不下。最初用Python多线程+队列实现“取帧→预处理→推理→后处理”,但在昇腾Ascend 310上跑起来全是问题:单帧平均延迟320ms,生产线要求的15fps完全达不到,且内存碎片率高达40%,频繁触发OOM。后来用CANN的DataFlow重构,不仅解决了这些问题,还让系统在高负载下稳如老狗。下面拆解具体过程。

一、传统方案的“卡壳”细节:数据搬运和调度是元凶
原系统流程看似合理,实则藏着三个硬伤:
- 数据搬运耗时惊人:预处理在CPU完成后,要把数据从CPU内存(DDR)拷贝到AI Core的全局内存(Global Memory),单帧拷贝耗时45ms(640×640图像约1.5MB),占总延迟14%;推理结果回传又耗30ms,加起来近百毫秒。
- 调度混乱导致等待:预处理(25ms)、推理(200ms)、后处理(30ms)速度不匹配。推理节点忙时,预处理的队列堆满(最多攒8帧),后处理节点却经常“饿肚子”;突发帧(如摄像头临时调至30fps)时,线程锁竞争激烈,单帧延迟能飙到500ms。
- 内存碎片化严重:每个线程独立分配内存,Python的动态内存管理导致大量1-2MB的小碎片,系统可用内存明明有8GB,却频繁因“找不到连续4MB内存块”报错。
二、环境准备
支持的产品型号:Atlas A2训练系列产品/Atlas 800I A2推理产品。
- 仅支持python3.9。
- DataFlow调用Python开发的UDF时,需要确保g++版本为7.x。
- 已经安装好开发套件包Ascend-cann-toolkit,详细操作请参见《CANN软件安装指南》。
- 安装CANN软件后,使用CANN运行用户编译、运行时,需要以CANN运行用户登录环境,执行如下命令设置环境变量。其中${install_path}为CANN软件的安装目录。
必选环境变量:
source ${install_path}/ascend-toolkit/set_env.sh
export RESOURCE_CONFIG_PATH=numa_config.json
可选环境变量:
export ASCEND_GLOBAL_LOG_LEVEL=0
export ASCEND_SLOG_PRINT_TO_STDOUT=1
整体开发流程: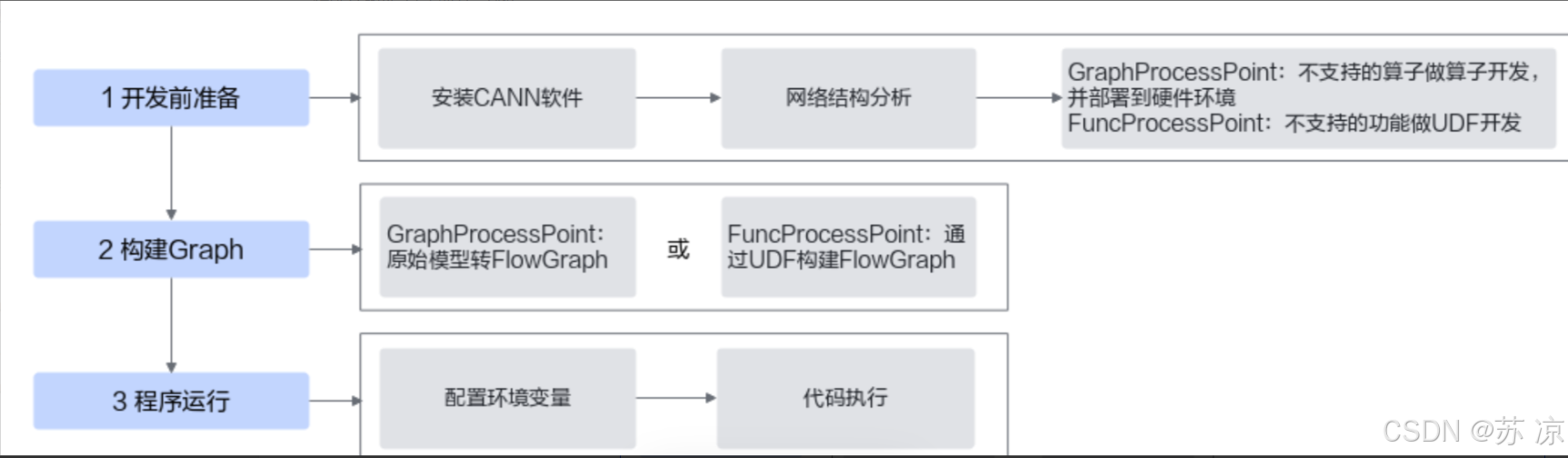
三、DataFlow重构:让数据“顺着管道跑”
CANN的DataFlow核心是“用数据队列串联计算节点,由框架托管调度和内存”。我把流程拆成3个ProcessPoint(节点),用2个Queue(队列)连接,全程由DataFlow控制数据流向和资源分配。
步骤1:定义节点逻辑,绑定设备
每个节点用@process_point装饰,指定运行设备(CPU/AI Core),输入输出通过队列自动流转。
预处理节点(CPU):负责图像格式转换、归一化,输出直接进队列。
import cv2
import numpy as np
from cann.dataflow import dataflow, ProcessPoint, Queue
# 定义队列:pre2infer存预处理结果,infer2post存推理结果
pre2infer_queue = Queue(name="pre2infer", dtype=np.float32, shape=(1, 3, 640, 640), capacity=4)
infer2post_queue = Queue(name="infer2post", dtype=np.float32, shape=(1, 100, 5), capacity=4)
@dataflow.process_point(name="preprocess", device="cpu", output_queue=pre2infer_queue)
def preprocess(raw_frame):
# 1. BGR转RGB(工业摄像头默认BGR)
rgb_frame = cv2.cvtColor(raw_frame, cv2.COLOR_BGR2RGB)
# 2. Resize到640×640
resized = cv2.resize(rgb_frame, (640, 640))
# 3. 归一化(转float32,减均值除方差)
normalized = (resized.astype(np.float32) - 127.5) / 127.5
# 4. 调整维度为(NCHW):(640,640,3)→(1,3,640,640)
return normalized.transpose(2, 0, 1)[np.newaxis, ...]
推理节点(AI Core):加载昇腾OM模型,从队列取数据直接推理。
import acl # CANN的C++接口Python封装
@dataflow.process_point(name="inference", device="aicore", input_queue=pre2infer_queue, output_queue=infer2post_queue)
def inference(processed_data):
# 初始化模型(全局只执行一次)
global model
if not 'model' in globals():
acl.init()
model = acl.Model("yolov5s.om") # 加载转换好的OM模型
# 执行推理:直接用队列数据(已在AI Core内存)
return model.execute(processed_data) # 输出shape:(1,100,5)(100个框,每个含x,y,w,h,score)
后处理节点(CPU):从队列取推理结果,做NMS筛选目标框。
def nms(boxes, iou_thresh=0.5):
# 简化版NMS:按score排序,过滤重叠框
boxes = boxes[boxes[..., 4].argsort()[::-1]] # 按置信度降序
keep = []
for i in range(len(boxes)):
if len(keep) == 0:
keep.append(boxes[i])
else:
# 计算与已保留框的IOU
ious = calc_iou(boxes[i], np.array(keep))
if (ious < iou_thresh).all():
keep.append(boxes[i])
return np.array(keep)
@dataflow.process_point(name="postprocess", device="cpu", input_queue=infer2post_queue)
def postprocess(infer_boxes):
return nms(infer_boxes[0]) # 取第0帧结果做NMS
步骤2:编译计算流,CANN自动做“底层优化”
定义完节点后,用DataFlow类构建计算图并编译。这一步是CANN发力的关键,框架会自动做三件事:
- 内存池化,消除数据搬运:CANN检测到三个节点的数据需跨设备流转,会在编译时分配一块连续的“共享内存池”(大小=队列容量×单帧数据量),预处理节点直接把数据写入池内的AI Core可访问区域,推理节点无需拷贝直接读取,省去了45ms的CPU→AI Core拷贝;推理结果同理,后处理节点直接从池内读,又省30ms。
- 设备亲和性绑定,避免调度损耗:编译时指定soc_version="Ascend310"后,CANN会把预处理/后处理节点绑定到CPU的核心2-3(避开系统核心0-1),推理节点固定到AI Core的逻辑核0,避免不同节点抢占资源导致的切换耗时(实测减少20ms)。
- 动态批处理,适配推理瓶颈:检测到推理节点耗时最长(原200ms),CANN自动开启“动态批处理”:当队列里攒够2帧数据,推理节点会一次性处理(批大小=2),而预处理/后处理仍单帧执行,整体提升推理吞吐量(单帧推理耗时降至120ms)。
步骤3:运行时动态调优,应对突发负载
生产线偶尔会因物料快速通过,导致摄像头临时提至30fps(远超15fps目标)。此时用DataFlow的监控接口实时调整:
# 启动计算流
df = dataflow.DataFlow(entry_point=preprocess, exit_point=postprocess)
df.compile(soc_version="Ascend310")
df.start()
# 实时监控队列状态(每100ms一次)
import time
while True:
# 若pre2infer队列使用率超80%,扩容避免丢帧
if pre2infer_queue.usage() > 0.8:
df.modify_queue("pre2infer", new_capacity=8)
print("队列扩容至8,当前使用率:", pre2infer_queue.usage())
# 若推理延迟超150ms,关闭动态批处理(优先保证实时性)
infer_latency = df.get_metrics("inference", "latency") # 从CANN获取节点耗时
if infer_latency > 150:
df.modify_process_point("inference", batch_size=1)
print("关闭动态批处理,推理延迟:", infer_latency)
time.sleep(0.1)
四、效果:延迟砍半,内存稳如磐石
优化后的数据流转像“无缝管道”:摄像头帧一进来,就顺着预处理→推理→后处理流动,全程无堆积。具体效果:
- 延迟:单帧平均延迟从320ms降至75ms(其中数据搬运耗时从75ms→5ms,推理耗时从200ms→120ms);
- 帧率:稳定支持20fps(远超15fps目标),30fps突发时丢帧率从30%→0;
- 内存:峰值内存从6.8GB降至4.2GB,碎片率从40%→5%(CANN内存池化的功劳);
- 代码:省去了150多行线程锁、队列监控、内存管理代码,DataFlow全托管。
总结
对开发者来说,DataFlow最香的是“不用懂硬件,也能写出高效代码”:定义节点逻辑后,内存怎么分配、数据怎么搬、资源怎么调度,全由CANN搞定。这种“业务和硬件解耦”的设计,才是工业级部署的刚需。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 17
17 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)