CronusVLA:通过多帧 VLA 建模实现高效且稳健的操控 | AAAI 26 Oral
框架创新:提出 “单帧预训练 + 多帧后训练” 的两阶段范式,首次实现 “高效多帧 VLA 建模”,兼顾性能与速度;技术: 特征块+跨帧解码器+多帧正则化的三合一设计基准创新:提出 SimplerEnv-OR,填补 VLA 模型鲁棒性评估的空白,支持 24 种时空干扰的定量测试;可兼容现有VLA模型(OpenVLA等),即插即用CronusVLA 的核心突破在于“用特征级多帧建模替代图像级多帧输入
CronusVLA:通过多帧 VLA 建模实现高效且稳健的操控
关键词:#具身智能 #VLA
- 论文题目:CronusVLA: Towards Efficient and Robust Manipulation via Multi-Frame Vision-Language-Action Modeling
- arXiv:2506.19816
- Accepted: AAAI 2026 Oral
- 单位:USTC & 上海 AI Lab
- https://lihaohn.github.io/CronusVLA.github.io/
- 更多论文每日解读关注 v 公众号:https://mp.weixin.qq.com/s/UKvbOX1z3KcTtY5mzhobYA

::: block-1
- 仿真环境:SimplerEnv、LIBERO、SimplerEnv-OR
- 真机:Franka
:::
本文聚焦于机器人操纵领域的一个痛点:如何高效利用时序信息提升 VLA 模型性能。
🧠 一句话总结:CronusVLA 通过 “单帧预训练 + 多帧后训练” 的两阶段框架,解决了多帧输入的计算开销与延迟问题,同时实现了更快推理、更高性能和更强鲁棒性,还配套了 SimplerEnv-OR 鲁棒性基准。

研究背景
现有 VLA 模型(如 OpenVLA)依赖单帧输入,无法充分利用多帧时序信息(运动线索、历史上下文)。直接输入多帧会带来两个关键问题:
- VLM 骨干网的自注意力计算量随 token 数平方增长,训练和推理成本极高;
- 冗余视觉 token 导致推理速度下降,难以部署到真实机器人。
CronusVLA 的两阶段训练
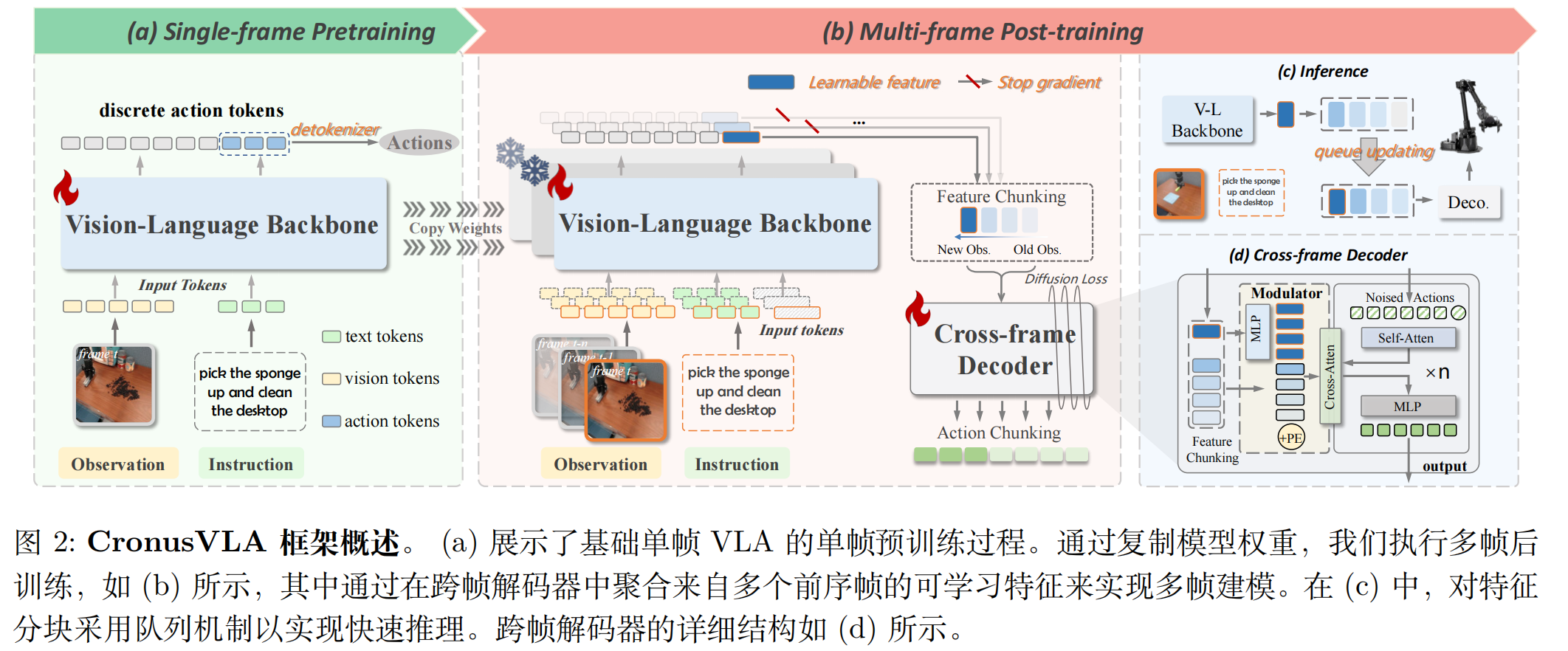
阶段 1:单帧预训练 —— 建立 VLA 基础
我们首先使用标准的自回归预测在离散动作 token 上训练一个基础的单帧 VLA 模型,从而更方便地利用大规模异构具身数据集,并建立有效的视觉-语言基础模型。
- 数据与任务:在 Open X-Embodiment 等大规模 embodied 数据集(含 27 个子数据集,如 Bridge-v2、Fractal)上训练,输入为 “单帧 RGB 图像 + 语言指令”,输出为离散动作 token;
- 动作 token 化:参考 OpenVLA,将机器人的连续动作(如 7 维末端执行器位姿)离散化为 256 个 bin,每个 bin 对应一个 “动作 token”,模型通过自回归预测下一个动作 token,再通过 detokenizer 还原为连续动作;
- 优势:
- 兼容现有 VLM 范式:保留 SigLip/Dinov2 的视觉感知能力,避免从头训练;
- 低成本预训练:单帧数据处理速度快,比直接多帧预训练节省 40% 以上计算资源。
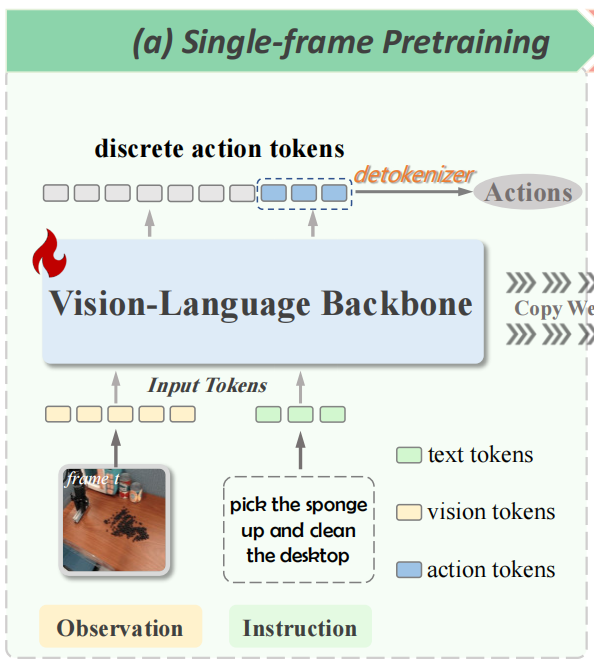
阶段 2:多帧后训练 —— 高效引入时序信息
我们在基础单帧 VLA 模型中引入可学习特征,并在高质量的跨具身数据集上进行后训练。这种多帧后训练将多个离散动作 token 替换为连续的可学习特征,并将视觉-语言主干网络的预测能力从单帧感知扩展到多帧感知。
通过将多帧历史信息中的运动线索提取为特征分块,实现有效的时序信
息聚合,从而提升效率。我们进一步引入特征调制器和多帧正则化,通过重构模型中过去帧的影响,缓解时序不平衡问题,并增强收敛能力。
模块 1:可学习特征和特征分块(Feature Chunking)
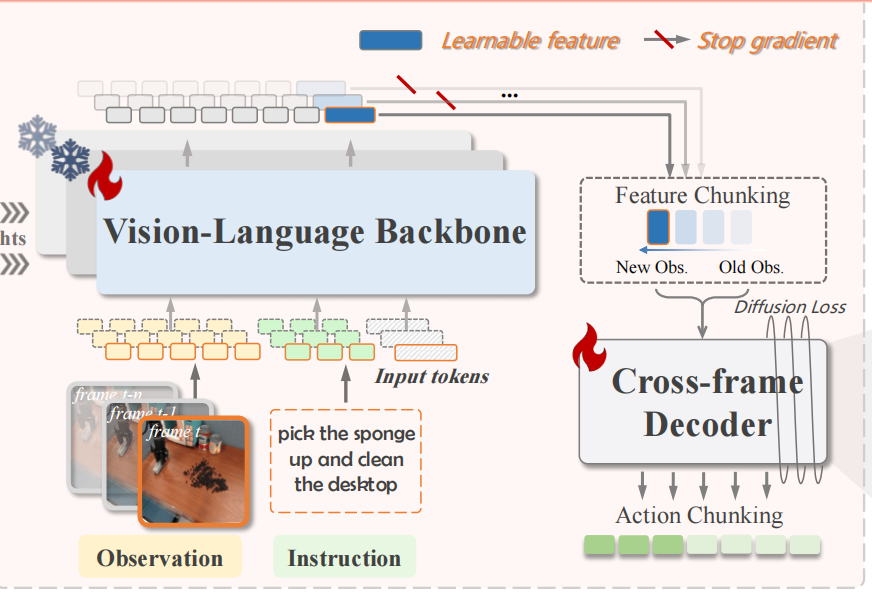
- 用连续特征替代离散 token:在单帧 VLA 的隐藏层中引入可学习特征 ft∈Rdf_t \in \mathbb{R}^dft∈Rd(d 为特征维度,如 7B 模型 d=4096),ftf_tft 整合了 “当前帧视觉信息 + 语言指令信息”,替代原有的离散动作 token 作为中间表示;
- 特征分块聚合历史:将过去 M 帧的可学习特征 (ft−m+1,⋯ ,ft−1,ft)(f_{t-m+1}, \cdots, f_{t-1}, f_t)(ft−m+1,⋯,ft−1,ft) 组成 “特征分块 FtMF_t^MFtM”,在特征级别建模多帧关系 —— 这一步的关键优势是:
- 单帧 VLA 仍独立处理每帧图像(生成 ftf_tft),复杂度仅随帧数线性增长(O(M×TVLM)\mathcal{O}(M \times T_{VLM})O(M×TVLM)),TVLMT_{VLM}TVLM 为单帧 VLA 推理时间),而非平方增长;
推理优化:用 “先进先出(FIFO)队列” 缓存历史特征分块,新帧输入时仅需计算当前 ftf_tft,再更新队列 —— 相比重新计算所有 M 帧,推理速度提升 3 倍以上(如 CronusVLA 7B 推理达 8.7Hz,远超 OpenVLA 7B 的 4.3Hz)。
模块 2:Cross-frame Decoder —— 从多帧特征到动作预测
目标:从特征分块 FtMF_t^MFtM 中解码出多步连续动作,解决“时序信息到动作”的映射。
- 架构设计:基于 DiT 构建解码器,包含 “自注意力层 + 交叉注意力层 + MLP 层”,输入为 “特征分块 FtMF_t^MFtM + 带噪声的动作序列”,输出为去噪后的连续动作;
- 特征调制器(Modulator):平衡 “当前帧特征” 与 “历史帧特征” 的权重 —— 将当前帧特征 ftf_tft 通过通道拆分(DIV)扩展为 (M-1) 个特征(与历史帧数量匹配),再通过 MLP 动态调整历史特征的贡献度,避免 “过时历史帧干扰当前决策”(如物体已移动,仍依赖旧位置信息)
- 扩散损失(Diffusion Loss):通过迭代去噪训练解码器,使模型能生成平滑的多步动作(如 “打开抽屉→放入物体” 的连续控制),如下所示:
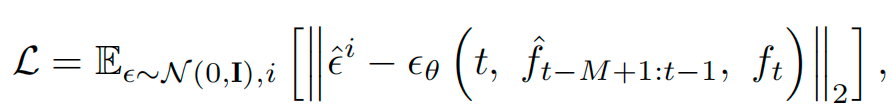
其中,ϵ^i\hat{\epsilon}^iϵ^i 是预测噪声,ϵθ\epsilon_\thetaϵθ 是模型输出的去噪噪声,fff 表示历史特征的 stop gradient(避免更新单帧 VLA 骨干网)。
模块 3:多帧正则化 —— 兼顾单帧感知与多帧鲁棒性
核心创新:通过 “梯度隔离” 确保单帧 VLA 的感知能力不被多帧训练破坏。
将特征分块 FtMF_t^MFtM 中的“历史帧特征”视为“辅助输入”,用 stop gradient 操作阻断其对单帧 VLA 骨干网的梯度更新 —— 仅让解码器学习历史特征的使用方式,而单帧 VLA 仍保持原有的视觉-语言对齐能力。
优势:
- 降低训练开销:无需重新训练庞大的 VLA 骨干网;
- 加速收敛:单帧感知能力稳定,多帧训练仅需优化解码器(参数仅 135M,远小于 VLA 骨干网的 6.7B)
CronusVLA 的推理流程
推理时,CronusVLA 通过 “队列缓存 + 单次 forward” 实现高效决策:
- 初始化 FIFO 队列,存储最近 M 帧的可学习特征(若帧数不足,用首帧特征填充);
- 新帧输入时,单帧 VLA 生成当前特征 ftf_tft,更新队列得到新的特征分块 FtMF_t^MFtM;
- 跨帧解码器仅需一次 forward,从 FtMF_t^MFtM 中解码出 K 步连续动作(如 K=16),无需自回归迭代。
最终,CronusVLA 7B 推理速度达 8.7Hz,0.5B 小模型甚至达 11.1Hz,远超同类多帧模型(如 TraceVLA 7B 仅 4.3Hz)。
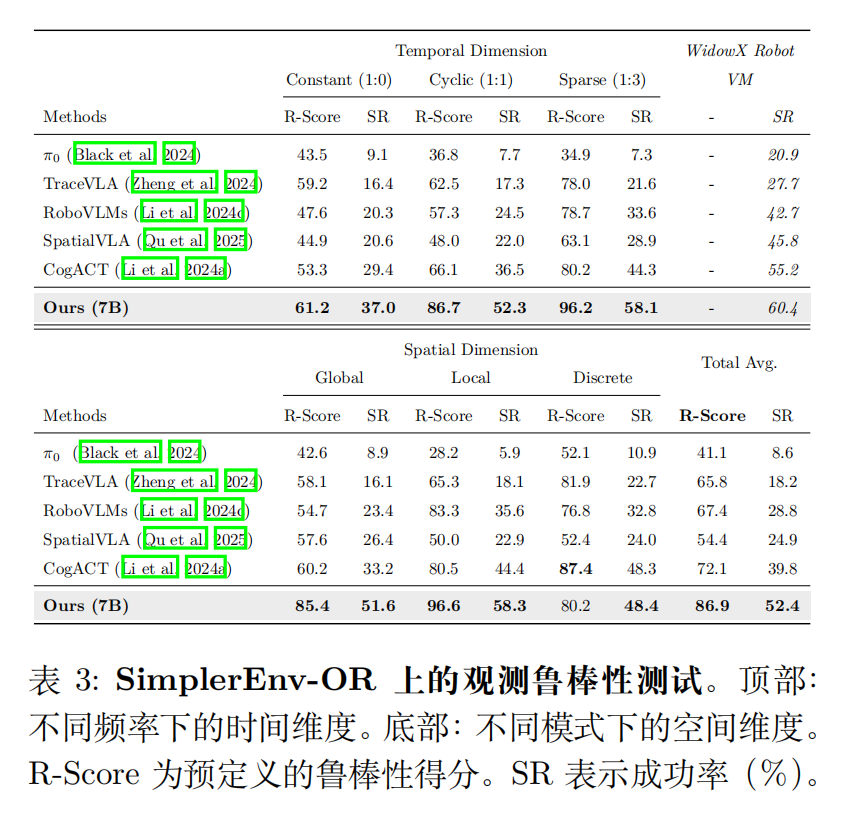
配套基准:SimplerEnv-OR 鲁棒性基准
现有基准(如 SimplerEnv、LIBERO)仅评估 “无干扰场景下的任务性能”,无法衡量真实环境中 “观测干扰” 对模型的影响。为此,作者提出 SimplerEnv-OR(Observational Robustness) 基准,专门测试 VLA 模型在时空干扰下的鲁棒性。
SimplerEnv-OR 扩展了 WidowX Robot 视觉匹配(WR-VM)设置在 SimplerEnv 中的仿真环境,并评估在 Bridge-v2 上训练的模型。并考虑如下干扰:
干扰维度:覆盖 “空间 + 时间” 两大维度,共 24 种干扰类型、120 个严重级别:
- 空间干扰:模拟相机硬件或环境干扰,分三类:
- 全局干扰:影响整帧(如高斯模糊、全帧遮挡、帧丢失);
- 局部干扰:仅影响部分区域(如局部过曝、部分遮挡);
- 离散干扰:随机像素噪声(如高斯噪声、椒盐噪声);
- 时间干扰:模拟干扰的频率变化,分三类:
- 恒定干扰(1:0):所有帧均受干扰;
- 周期性干扰(1:1):干扰帧与干净帧交替;
- 稀疏干扰(1:3/1:5):每 3/5 帧出现 1 次干扰
评估指标:定义 “鲁棒性得分(R-Score)”,量化干扰下的性能保持率。
令 SR 表示原始 WR-VM 任务的平均成功率,SRiSR^iSRi 表示在扰动情景 i 下的成功率。鲁棒性得分计算如下:
R-Scorei=100×SRiSR \text{R-Score}^i = 100 \times \frac{SR^i}{SR} R-Scorei=100×SRSRi
需要注意的是,每种情景包含 200 至 400 次试验,确保了评估的稳定性和可靠性。
实验
作者在 “模拟环境(SimplerEnv、LIBERO)” 和 “真实环境(Franka 机器人)” 中验证,CronusVLA 在性能、速度、鲁棒性上全面超越现有方法。
模拟环境实验
实验 1:SimplerEnv 基准(跨机器人任务)
SimplerEnv 包含 Google Robot(GR)和 WidowX Robot 两类机器人,覆盖 “视觉匹配(VM)” 和 “变体聚合(VA)” 两种设置(VA 引入背景、光照变化,更贴近真实)。核心结果:
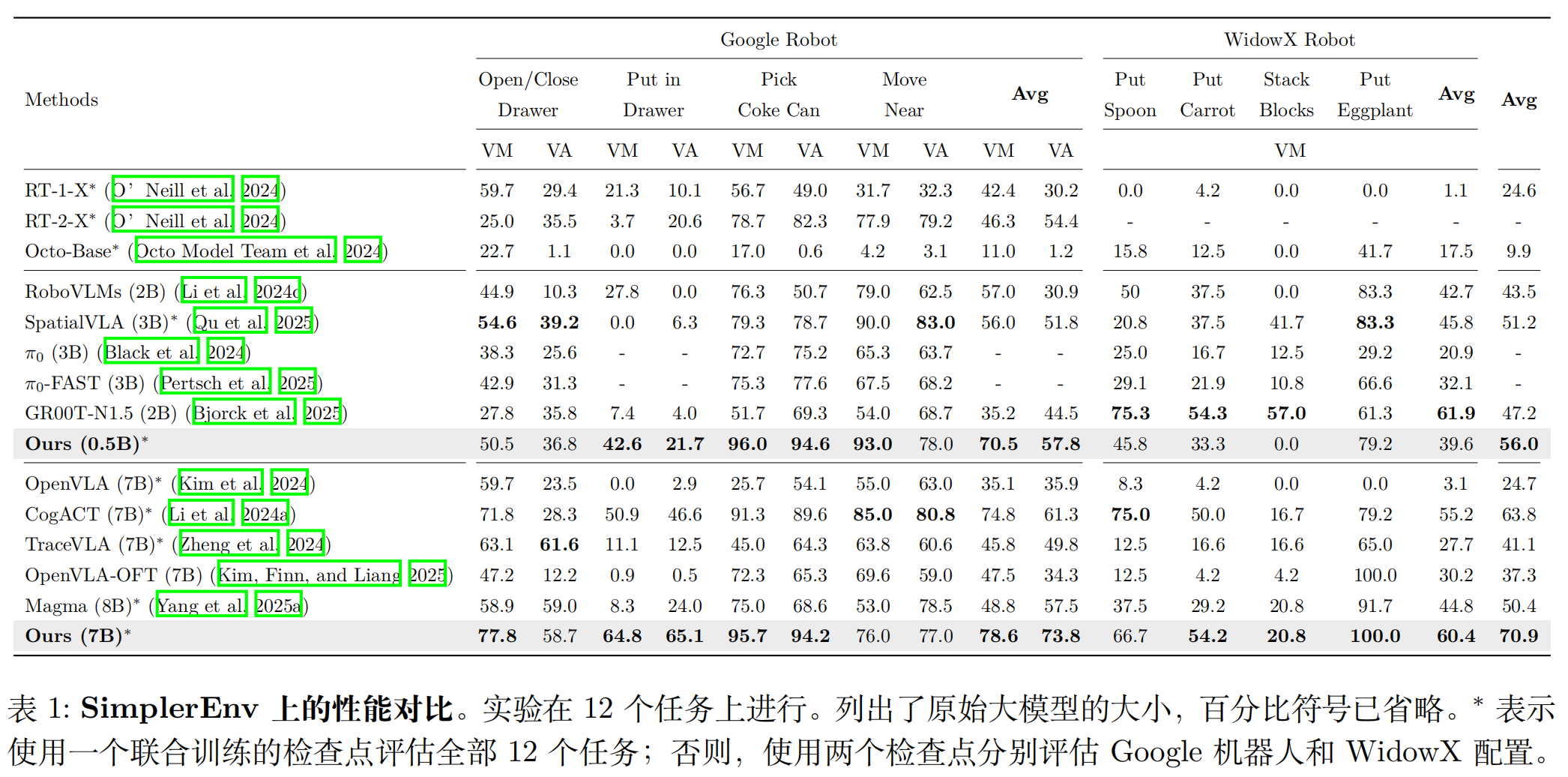
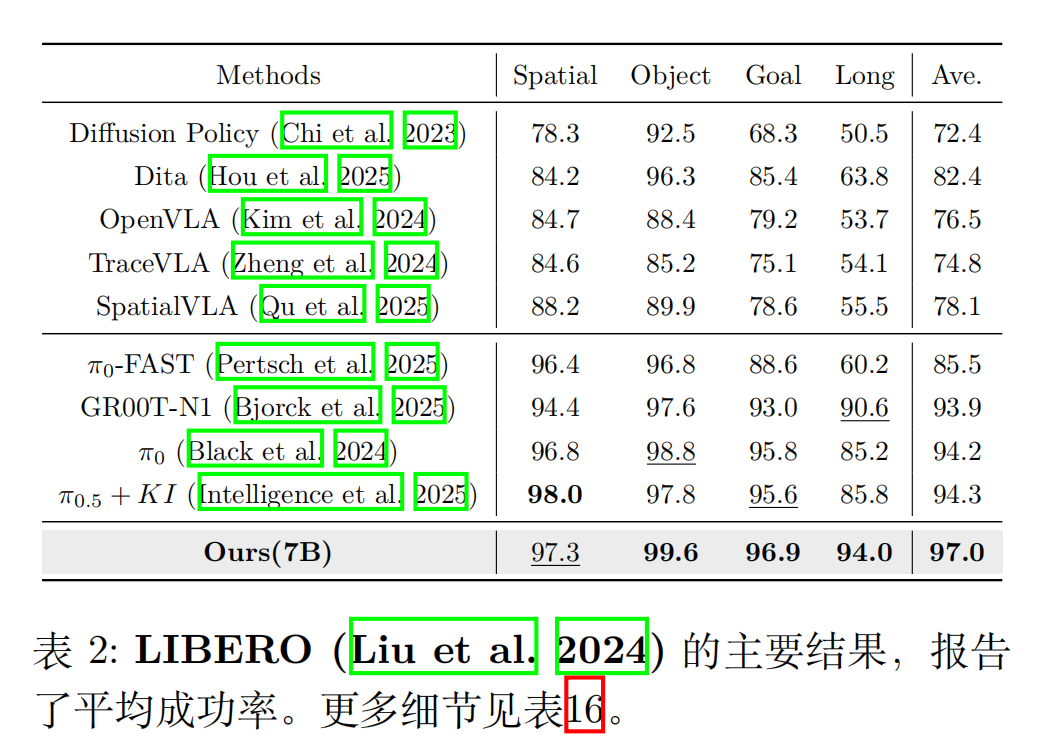
实验 2:LIBERO 基准(长 horizon 任务)
LIBERO 包含 4 类任务(Spatial/Object/Goal/Long),其中 “Long 任务” 需多步连续操作(如 “开抽屉→放物体→关抽屉”),最考验时序建模能力。
鲁棒性实验:SimplerEnv-OR 基准
真实环境实验
在 Franka 机械臂上测试三类任务,验证落地能力:
- 简单任务(拾取、堆叠):CronusVLA 在 “堆叠杯子” 任务中成功率 48%,远超 DP3(12%)和 OpenVLA(28%);
- 长 horizon 任务(按顺序按按钮、开抽屉放物体):OpenVLA 因无多帧信息,常重复按同一按钮(如 “先按红→再按红”),而 CronusVLA 按序成功率 88%;
- 干扰任务(遮挡、光照变化、人为干扰):CronusVLA 在 “相机遮挡” 下成功率 64%,比 OpenVLA(20%)高 3 倍,证明多帧时序的鲁棒性增益。
结论: 多帧建模让机器人能记住"刚才按了哪个按钮",避免重复操作,长程任务成功率显著高于单帧模型。
消融实验
- 无多帧正则化:平均成功率从 70.9% 降至 67.2%,收敛速度变慢(需多训练 10k 步);
- 无特征调制器:当前帧与历史帧权重失衡,成功率降至 63.5%;
- 用 MLP 替代 DiT 解码器:因表征能力不足,成功率骤降 20%。
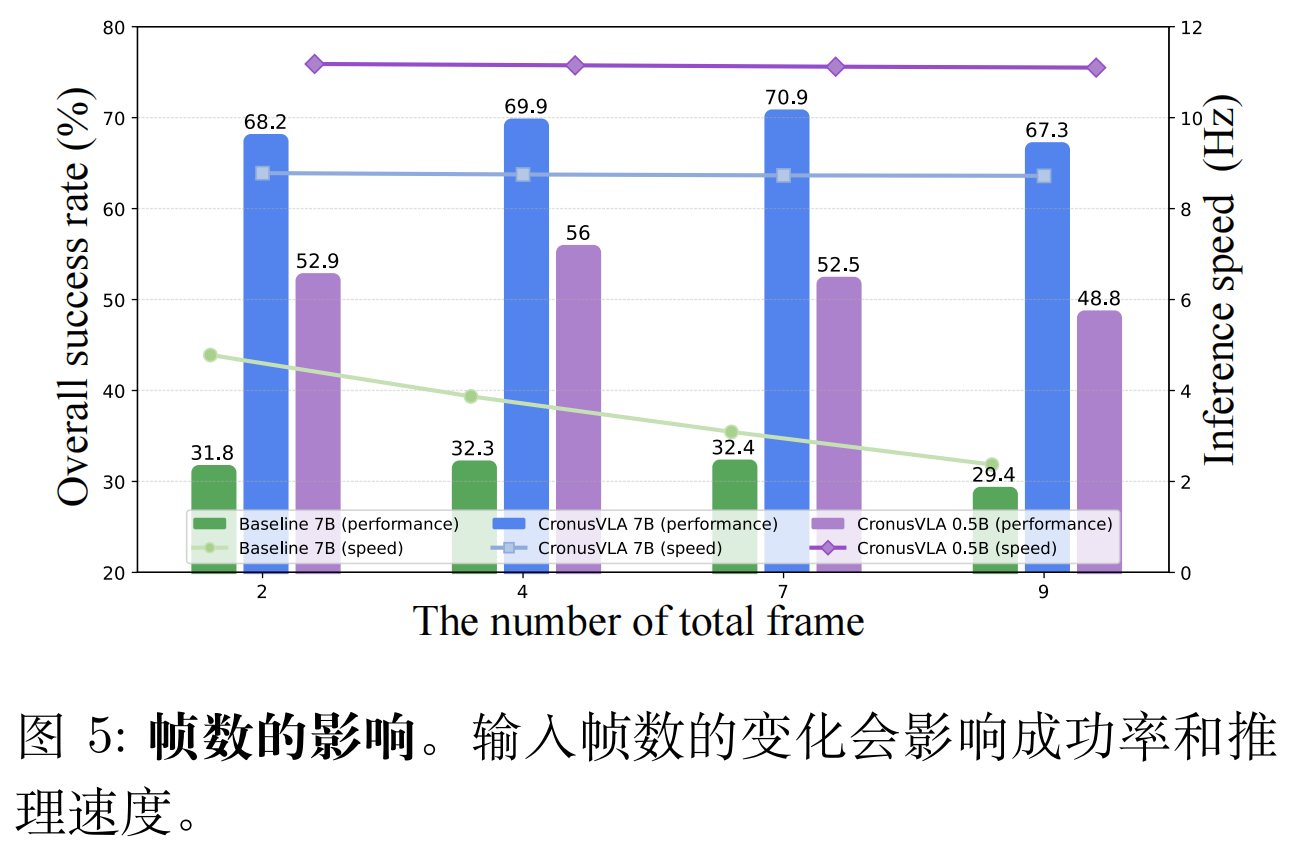
总结
主要贡献总结
- 框架创新:提出 “单帧预训练 + 多帧后训练” 的两阶段范式,首次实现 “高效多帧 VLA 建模”,兼顾性能与速度;
- 技术: 特征块+跨帧解码器+多帧正则化的三合一设计
- 基准创新:提出 SimplerEnv-OR,填补 VLA 模型鲁棒性评估的空白,支持 24 种时空干扰的定量测试;
- 可兼容现有VLA模型(OpenVLA等),即插即用
局限性与未来方向
作者诚实指出了不足:
- 深度感知: 在需要精确定位的任务上仍有提升空间
- 多模态融合: 目前只用第三视角,未来会加入腕部相机、力反馈等
- 语言推理: 未充分利用大模型的显式语言推理能力
- 效率: 帧间冗余信息处理仍可优化
一句话总结
CronusVLA 的核心突破在于 “用特征级多帧建模替代图像级多帧输入”,通过"特征级时序建模"让机器人拥有了短期记忆,既保留了单帧 VLA 的预训练优势,又避免了计算与延迟问题,为多帧 VLA 的落地提供了可行路径。
而 SimplerEnv-OR 基准的提出,也为后续 VLA 鲁棒性研究提供了统一的评估标准。对于机器人操纵领域而言,这一工作不仅提升了模型性能,更推动了 VLA 从 “实验室场景” 向 “真实复杂环境” 的落地。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)