MDocAgent 论文完整解析:多模态多智能体破解DocQA核心痛点
DocQA(Document-based Question Answering)即“基于文档的问答任务”,核心是从包含文本、图表、表格、图像的复杂文档中,精准回答用户自然语言问题。学术论文分析(提取实验数据、对比模型性能)自动化办公(解析报告、提取关键信息)信息检索(从长文档中定位核心答案)验证一致性:核对aG、aT、aI的核心事实(如三者是否均提到“0.600准确率”);补充互补细节:整合单一模
MDocAgent 论文完整解析:多模态多智能体破解DocQA核心痛点
摘要
本文提出 MDocAgent——一种面向文档理解(DocQA)的多模态多智能体框架,核心目标是解决复杂文档(文本+视觉混合)问答中的“模态割裂、信息过载、跨模态推理”三大痛点。框架创新性地融合“双RAG检索流水线”与“五阶段智能体协作”,在5个权威基准数据集上全面超越现有SOTA方法,Top-1检索平均准确率达0.407(较M3DocRAG提升12.1%),Top-4检索准确率达0.465(较最佳LVLM提升73.5%)。本文将从研究背景、核心创新、框架细节、实验验证、难理解点拆解等维度,完整讲解论文核心内容。
一、研究背景:DocQA的核心痛点与现有方法局限
1.1 DocQA任务定义与价值
DocQA(Document-based Question Answering)即“基于文档的问答任务”,核心是从包含文本、图表、表格、图像的复杂文档中,精准回答用户自然语言问题。其应用场景覆盖:
- 学术论文分析(提取实验数据、对比模型性能)
- 自动化办公(解析报告、提取关键信息)
- 信息检索(从长文档中定位核心答案)
1.2 DocQA的三大核心挑战(论文核心痛点)
| 挑战类型 | 具体含义 | 现实影响 |
|---|---|---|
| 模态割裂 | 现有方法优先处理单一模态(文本或图像),无法有效融合文本与视觉信息 | 跨模态问题(如“图表数据+文本结论”)无法解答 |
| 信息过载 | 长文档(如33000+页的报告)包含海量数据,模型难以快速定位关键信息 | 回答效率低、易遗漏核心线索 |
| 跨模态推理 | 需理解文本与图表/图像的关联(如文本“增长率”对应图表中的柱状图数据) | 传统方法缺乏针对性推理机制 |
1.3 现有方法的局限(论文创新的出发点)
现有研究主要分为三类,但均无法同时解决三大痛点:
- 大型视觉语言模型(LVLM)
- 优势:能处理视觉信息,具备基础跨模态能力(如Qwen2-VL、LLaVA-v1.6)
- 局限:长文档处理受限(上下文窗口不足)、细粒度细节关注不够、跨模态融合不深入
- 传统RAG方法
- 优势:缓解长文档信息过载,精准检索相关片段(如ColBERTv2文本RAG)
- 局限:文本RAG与图像RAG独立运作,缺乏跨模态协同
- 多智能体系统
- 优势:分工协作提升复杂任务处理能力
- 局限:未针对DocQA的多模态需求设计专用架构,模态融合薄弱
二、核心创新:MDocAgent的设计理念
MDocAgent的核心创新是 “双RAG检索+五智能体协同”,针对性解决“模态割裂+信息过载+跨模态推理”三大痛点:
- 双RAG检索:文本RAG(ColBERTv2)+ 图像RAG(ColPali)并行,同时获取文本/视觉上下文,解决“模态割裂”;
- 五智能体分工协作:从预处理到答案合成,逐步精简信息,解决“信息过载”;
- 跨模态融合贯穿全流程:从上下文检索到答案合成,均实现文本与视觉信息的联动,解决“跨模态推理”。
三、MDocAgent完整框架:五阶段流水线式协作
框架核心逻辑是“数据预处理→多模态检索→初始分析→专用处理→答案合成”,每个阶段输出作为下阶段输入,形成闭环。以下是各阶段的详细拆解(含输入、输出、核心动作):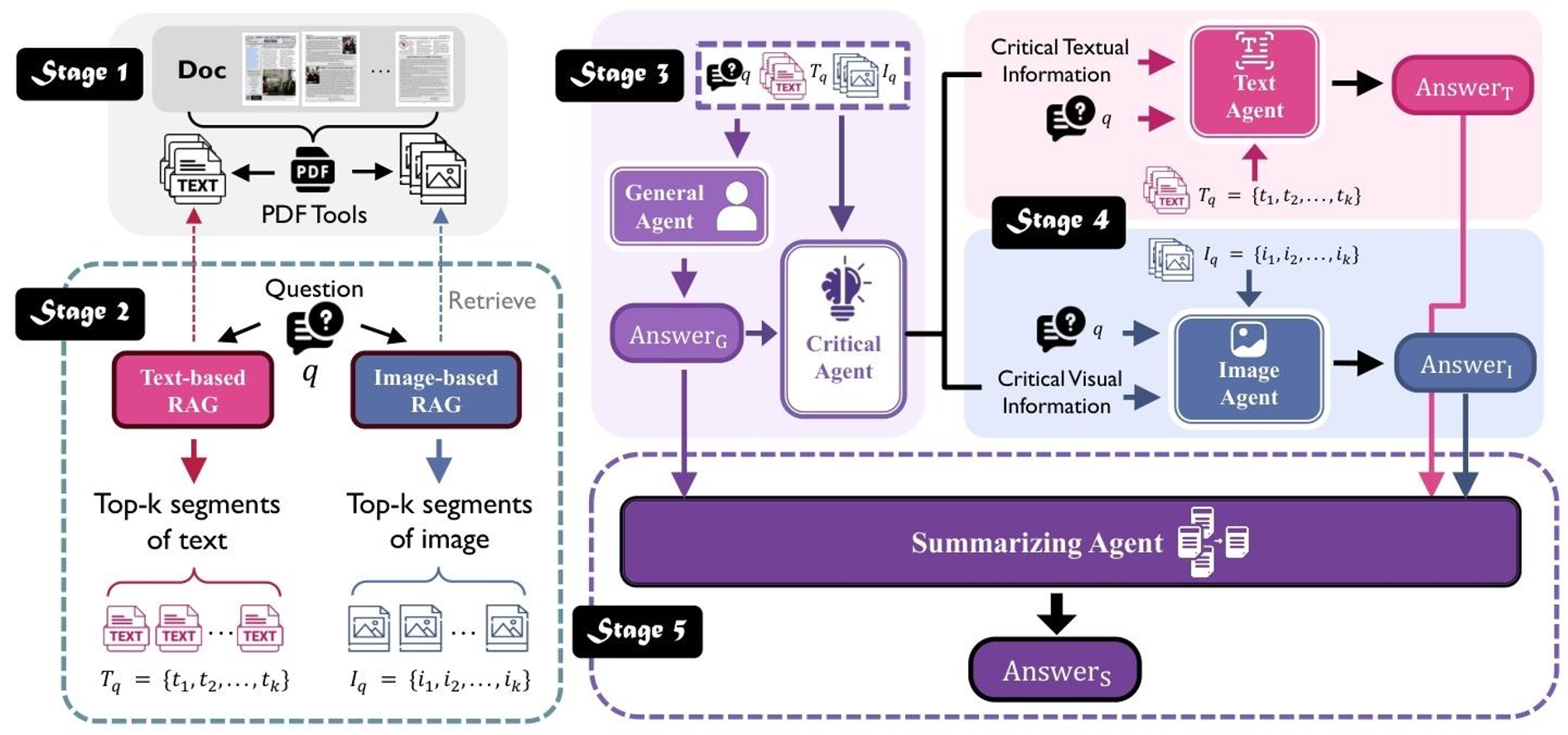
3.1 阶段一:文档预处理——生成双模态表征
核心目标
将原始PDF文档(文本+图像混合)转化为计算机可处理的“文本表征+视觉表征”,为后续检索打基础。
关键操作
| 处理对象 | 技术手段 | 输出结果 |
|---|---|---|
| 文本提取 | 双模式组合:PDF解析(处理数字编码PDF)+ OCR(处理图像类PDF/扫描件) | 文本表征(Ti):按页面拆分的文本片段序列,如 Ti = [页面1-片段1, 页面1-片段2, ...] |
| 视觉保留 | 将每页文档保存为图像,完整保留布局、图表、表格等视觉特征 | 视觉表征(Ii):原始页面图像集合,如 Ii = [页面1图像, 页面2图像, ...] |
难理解点拆解
- 数字编码PDF vs 图像类PDF:数字编码PDF是Word/LaTeX导出的可编辑PDF(文字以字符编码存储,可直接复制);图像类PDF是纸质文档扫描件(文字是像素点,需OCR识别)。
- 鲁棒性的体现:双模式组合覆盖所有PDF格式,避免单一方法(如仅用OCR)导致的文本提取失败。
3.2 阶段二:多模态上下文检索——双RAG并行找素材
核心目标
针对用户问题,从双模态表征中精准检索“最相关”的文本片段和图像页面,减少后续智能体的冗余信息处理。
关键操作
- 文本RAG(ColBERTv2):对文本表征(Ti)建立索引,根据用户问题检索Top-k相关文本片段,输出 文本上下文(Tq)(如Top-1/Top-4片段);
- 图像RAG(ColPali):对视觉表征(Ii)生成“密集视觉嵌入”(图像特征转成计算机可理解的代码),检索Top-k相关图像页面,输出 视觉上下文(Iq);
- 检索策略:文本RAG与图像RAG 并行执行,同时输出结果,避免串行导致的效率低下。
难理解点拆解
- 视觉嵌入与图像检索的关联:视觉嵌入是图像的“特征身份证”(按颜色、形状、图表结构生成),检索时先将用户问题转成同格式代码,通过“代码相似度比对”找到相关图像,最终输出的是图像页面(而非代码)。
- Top-1/Top-4检索的区别:Top-1是取最相关的1个素材(速度快,依赖检索精准度);Top-4是取前4个相关素材(信息更全,容错率高,对智能体整合能力要求更高)。
3.3 阶段三:初始分析与关键信息提取——智能体初筛重点
核心目标
生成初步答案框架,筛选核心线索,为后续专用智能体“减负”,避免信息过载。
参与智能体及功能
| 智能体类型 | 输入信息 | 核心动作 | 输出结果 |
|---|---|---|---|
| 通用智能体(AG) | Tq(文本上下文)、Iq(视觉上下文)、用户问题(q) | 整合双模态信息,进行初步跨模态理解,搭建答案基础框架 | 初步回答(aG):如“MDocAgent在FetaTab数据集的准确率高于现有方法” |
| 关键智能体(AC) | q、Tq、Iq、aG(初步回答) | 分析核心需求,筛选关键信息,剔除冗余内容 | 关键文本(Tc)+ 关键视觉描述(Ic):如“Tc=Top-1检索下MDocAgent在FetaTab准确率0.600” |
难理解点拆解
- 智能体的本质:不是“独立软件”,而是“大模型(如Llama-3.1-8B)+ 自定义代码”——自定义代码限定智能体的功能边界(如通用智能体仅做初步整合,不做细粒度分析)。
- 数据传递逻辑:不是“智能体调用智能体”,而是前一智能体的输出作为后一智能体的输入(如aG传递给AC),流程由代码预设。
3.4 阶段四:专用智能体处理——细粒度深度分析
核心目标
由文本/图像专用智能体,在关键信息(Tc/Ic)引导下,分别深挖单一模态的细节,生成精准的模态基回答。
参与智能体及功能
| 智能体类型 | 输入信息 | 核心动作 | 输出结果 |
|---|---|---|---|
| 文本智能体(AT) | q、Tq(文本上下文)、Tc(关键文本) | 聚焦Tc,深挖文本细节(如验证数据准确性、提取术语定义) | 文本基回答(aT):如“Top-1检索下,MDocAgent在FetaTab的准确率为0.600,较M3DocRAG提升21.0%” |
| 图像智能体(AI) | q、Iq(视觉上下文)、Ic(关键视觉描述) | 针对Ic标注的视觉区域(如“第3页表格”),解析图表数据、图像内涵 | 视觉基回答(aI):如“第3页表格显示,M3DocRAG在FetaTab的准确率为0.390” |
难理解点拆解
- 专用智能体的“专业性”:文本智能体仅处理文本信息,图像智能体仅处理视觉信息,避免“全能但不精”——比如文本智能体擅长提取学术术语,图像智能体擅长解析表格结构。
- 关键信息的引导作用:Tc/Ic相当于“导航员”,让专用智能体不用遍历所有素材,直接聚焦核心,提升分析效率。
3.5 阶段五:答案合成——跨模态融合的深度解读
核心目标
融合多源答案(aG、aT、aI),解决模态间冲突,输出全面、准确的最终答案(aS)。
参与智能体:总结智能体(AS)
核心动作(非简单拼接)
- 验证一致性:核对aG、aT、aI的核心事实(如三者是否均提到“0.600准确率”);
- 补充互补细节:整合单一模态的专属信息(如文本aT的“提升21.0%”+ 图像aI的“M3DocRAG准确率0.390”);
- 解决冲突:若模态间信息矛盾(如文本说“0.600”,图像说“0.590”),以更可信的模态为准(如表格图像的信息更精准);
- 结构化表达:按“结论+证据+对比”组织语言,形成逻辑闭环。
输出结果示例
最终答案(aS):Top-1检索设置下,MDocAgent在FetaTab数据集的平均准确率为0.600,较现有SOTA方法M3DocRAG(0.390)提升21.0%,显著优于最佳LVLM模型Qwen2.5-VL-7B(0.329)。该结论与文本描述和表格数据一致,可信度较高。
难理解点拆解
- 与“简单拼接”的区别:拼接是罗列信息(如“aG说A好,aT说0.600,aI说0.390”),融合解读是逻辑整合(验证+补充+修正),实现“1+1+1>3”。
- 跨模态推理的落地:通过“文本证据+视觉证据”的相互验证,解决单一模态无法解答的问题(如“文本提到增长率,图像表格提供具体数据支撑”)。
四、实验设计与核心结果
4.1 实验设置(保证评估公平性)
1. 评估基准(5个数据集,覆盖全场景)
| 数据集 | 核心场景 | 数据规模(问答对/文档) | 关键特点 |
|---|---|---|---|
| MMLongBench | 多模态长文档 | 13,331/135(平均47.5页) | 支持128K超长文本,跨模态任务 |
| LongDocURL | 超长文档 | 2,325/33,000+页 | 含跨元素定位任务(如“答案来自第12页表格”) |
| PaperTab | 学术表格理解 | 393/307 | 学术论文表格,结构复杂(合并单元格、多层表头) |
| PaperText | 学术纯文本理解 | 2,804/1,087 | 顶会论文纯文本,含大量学术术语 |
| FetaTab | 通用表格问答 | 1,023/878 | 维基百科表格,需自由文本回答 |
2. 基线方法
- LVLMs:Qwen2.5-VL-7B、LLaVA-v1.6、Phi-3.5-Vision等;
- RAG方法:ColBERTv2+LLaMA-3.1、M3DocRAG(当前SOTA多模态RAG)。
3. 评估指标与流程
- 指标:平均准确率(正确率) ——由GPT-4o作为第三方评估器,二分类判定(正确=1/错误=0),取5个数据集的平均值;
- 流程:模型输出答案 → GPT-4o对比数据集预设参考答案 → 统计正确率,避免人工评估的主观性。
4.2 核心实验结果(一):对比SOTA
关键数据(Top-1/Top-4检索)
| 方法类型 | 方法名称 | 平均准确率(Top-1) | 平均准确率(Top-4) | 相对提升(vs SOTA) |
|---|---|---|---|---|
| 最佳LVLM | Qwen2.5-VL-7B | 0.268 | - | - |
| 现有SOTA | M3DocRAG | 0.363 | 0.420 | - |
| 本文方法 | MDocAgent | 0.407 | 0.465 | Top-1提升12.1%,Top-4提升10.9% |
突出亮点
- FetaTab数据集表现最优:Top-1准确率0.600,较SOTA提升21.0%;
- 长文档任务优势明显:LongDocURL(33000+页)Top-1准确率0.517,超越M3DocRAG(0.506)。
4.3 核心实验结果(二):消融实验(验证组件必要性)
关键数据(Top-1检索,对比完整框架与变体)
| 框架变体 | 平均准确率 | 相对下降(vs 完整框架) | 关键结论 |
|---|---|---|---|
| MDocAgent(完整框架) | 0.407 | - | 所有组件协同效果最优 |
| 无文本Agent | 0.384 | -5.65% | 文本Agent对文本密集任务(如PaperText)至关重要 |
| 无图像Agent | 0.392 | -3.69% | 图像Agent对视觉密集任务(如LongDocURL)影响显著 |
| 无通用+关键Agent | 0.382 | -6.14% | 通用+关键Agent是协作基础,影响最大 |
难理解点拆解
- 消融实验的意义:通过“移除某个组件”观察性能变化,验证该组件的不可或缺性——比如移除通用+关键Agent后性能下降最明显,说明其“定方向、筛重点”的核心作用。
- 模态适配性体现:移除文本Agent对PaperText(文本密集)冲击最大,移除图像Agent对LongDocURL(视觉密集)影响更突出,印证了专用智能体的“专业分工价值”。
五、核心贡献与未来工作
5.1 核心贡献
- 提出“双RAG+五智能体”框架,首次将多智能体与多模态RAG深度融合,全面解决DocQA三大痛点;
- 设计流水线式协作逻辑,从预处理到答案合成,实现“信息逐步精简、能力逐步聚焦”,提升问答效率与准确率;
- 实验验证框架有效性:在5个基准数据集上全面超越SOTA,代码开源(https://github.com/aiming-lab/MDocAgent),可复用性强。
5.2 未来工作
- 优化智能体间通信机制,提升协作效率;
- 整合外部知识源,增强复杂推理能力(如学术术语库、领域知识库);
- 扩展至多文档问答场景,解决多文档间的跨模态关联问题。
六、新手避坑:难理解点汇总与解答
| 难理解点 | 核心解答 |
|---|---|
| 视觉嵌入为何能检索图像 | 视觉嵌入是图像的“特征代码”,通过“问题代码与图像代码的相似度比对”找到相关图像,最终输出图像页面 |
| 多智能体协同不是“聊天” | 是“数据传递+功能分工”,前一智能体的输出作为后一智能体的输入,流程由代码预设,无自主沟通 |
| 跨模态融合不是“拼接” | 是“验证+补充+修正”的逻辑整合,总结智能体需解决模态冲突、补充细节,形成逻辑闭环 |
| 平均准确率的来源 | 数据集预设参考答案 + GPT-4o第三方二分类判定,避免人工评估主观性 |
| 双RAG的并行优势 | 同时获取文本/视觉上下文,避免串行导致的“文本检索完再做图像检索”的效率低下 |
总结
MDocAgent的核心价值在于“针对性解决DocQA的核心痛点”——通过双RAG解决模态割裂与信息过载,通过多智能体协作解决跨模态推理。框架的每个组件都有明确分工,却又围绕“精准问答”的共同目标协同运作,最终实现了性能上的全面超越。对于新手而言,理解“模态融合的本质”“智能体的分工逻辑”“RAG与智能体的联动”是掌握该论文的关键,也是入门多模态文档理解领域的基础。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 19
19 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)