告别Chain设计,LangChain 1.0结合Milvus打造生产级Agent实战指南!
LangChain 1.0重大改版,放弃Chain设计,引入标准化ReAct循环和Middleware机制,简化agent开发并提供生产级能力。通过create_agent函数快速构建agent,结合Milvus向量数据库实现长期记忆系统,解决知识检索、记忆持久化和多模态管理问题。LangChain与LangGraph形成渐进式技术栈,满足不同复杂度的agent开发需求,为生产级agent开发提供
不再搞Chain 设计的LangChain 1.0 ,如何结合Milvus打造生产级agent
最近,被广大开发者又爱又恨的LangChain ,迎来了重大改版:
专门为agent落地打造的LangChain 1.0版本终于来了!!!
简单来说,其改动主要在于:通过放弃早期的Chain 设计,引入标准化 ReAct 循环(推理→工具调用→观察→判断)和Middleware 机制,简化agent开发流程、统一标准。
那么改版的LangChain 怎么用,如何结合Milvus落地生产,本文将重点解读。
一、LangChain 为何改版?
Chain 设计不适用agent时代
过去,LangChain 0.x 版本的优点是能让开发者快速构建Agent 原型。但同时也存在三个核心问题:
1、僵化的 Chain 设计
预构建的 Chain(如SimpleSequentialChain、LLMChain)在标准场景下很方便,但一旦业务逻辑偏离模板,开发者就会陷入两难——要么被迫接受框架的全部设计,要么放弃框架直接操作原始 LLM 调用。
2、缺少生产级控制
- 上下文溢出:长对话导致 Token 超限,系统崩溃
- 敏感信息泄露:PII 数据(邮箱、身份证)直接发送给第三方模型
- 高风险操作:Agent 在无人工确认的情况下删除数据、发送邮件
这些问题在 Demo 阶段难以暴露,但上线后每一个都可能致命。
3、模型切换的重复工作
OpenAI、Anthropic、国产模型的接口差异(Reasoning 格式、Tool Calling 协议)迫使开发者在每次切换时重写适配代码。
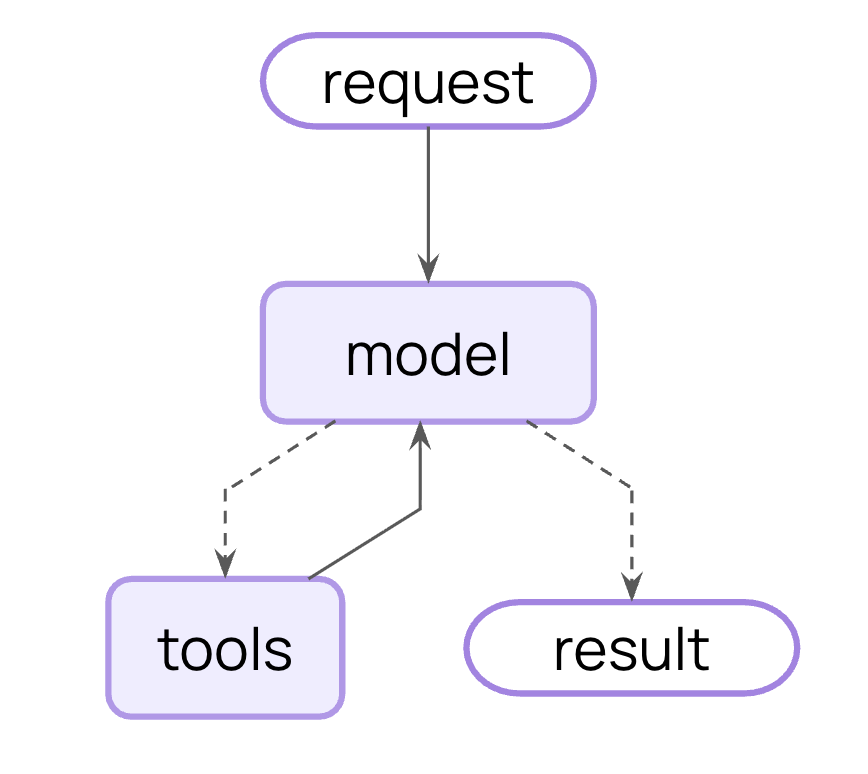
而针对以上问题,LangChain 1.0选择放弃早期的Chain 设计,引入标准化 ReAct 循环(推理→工具调用→观察→判断,create_agent函数 10 行代码就能构建生产级 Agent)和Middleware 机制(注入 PII 检测、人工审批、自动重试)**,**简化agent开发流程、统一模型接入等标准。
二、LangChain 1.0 的核心设计 All-in ReAct Agent
LangChain 团队在分析大量生产环境的 Agent 后发现:绝大多数成功案例都收敛到了 ReAct 模式。
无论是多 Agent 协作的 Supervisor 架构,还是需要深度推理的复杂场景,核心循环都是:
推理 → 工具调用 → 观察结果 → 判断是否完成
既然绝大多数问题都能用 ReAct 解决,为什么不把这个模式做到极致?因此1.0的第一个核心改版就是引入标准化 ReAct 循环。
LangChain 1.0 的分层策略:
- 标准场景:用
create_agent一个函数搞定(标准 ReAct 循环) - 扩展场景:通过 Middleware 机制扩展(PII 检测、人工审批、自动重试)
- 复杂场景:用 LangGraph 精确控制(复杂状态机、多 Agent 编排)
这种渐进式设计让开发者可以从最简单的方案开始,按需增加复杂度。
1. create_agent 函数:简化的 Agent 构建接口
LangChain 1.0 的核心突破在于将 Agent 构建的复杂性压缩到一个函数中。create_agent不再要求开发者手动编排状态管理、错误处理和流式输出 —— 这些生产级能力现在由底层 LangGraph 运行时自动提供。
三个参数,一个运行时:
- 模型(
m``odel):支持字符串标识符或实例化对象 - 工具(
tools):赋予 Agent 执行能力的函数列表 - 系统提示(
system_prompt):定义 Agent 的角色和行为准则
底层自动继承 LangGraph 的持久化状态、中断恢复和流式处理能力,将过去需要数百行代码实现的 Agent 循环浓缩为声明式 API。
from langchain.agents import create_agent
agent = create_agent(
model="openai:gpt-4o",
tools=[get_weather, query_database],
system_prompt="你是一个专业的客服助手,帮助用户查询天气和订单信息。"
)
result = agent.invoke({
"messages": [{"role": "user", "content": "上海今天天气怎么样?"}]
})
在此基础上,通过内置中间件(Middleware)机制,开发者可以在不破坏核心循环的前提下注入人机协作审批、对话摘要压缩、PII 数据脱敏等生产级能力
2. Middleware 机制:可组合的生产级能力层
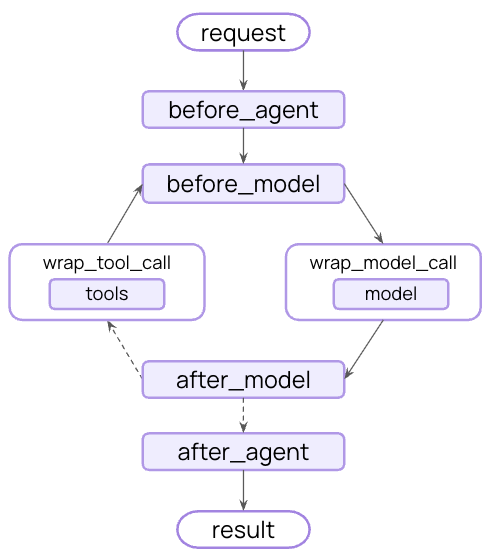
Middleware 是 LangChain 1.0 从原型到生产的核心桥梁。它在 Agent 执行循环的战略节点暴露钩子函数,让开发者无需重写核心循环即可注入自定义逻辑 —— 这种设计类似于 Web 服务器中间件的对称处理模式。
中间件的执行流程:
Agent 的核心循环遵循“模型→工具→终止”的三步决策模式
以下是几个典型的生产级中间件示例:
(1)PII Detection:敏感信息检测与处理
from langchain.agents import create_agent
from langchain.agents.middleware import PIIMiddleware
agent = create_agent(
model="openai:gpt-4o",
tools=[...],
middleware=[
# 脱敏邮箱地址
PIIMiddleware("email", strategy="redact", apply_to_input=True),
# 掩码信用卡号(显示后4位)
PIIMiddleware("credit_card", strategy="mask", apply_to_input=True),
# 自定义正则检测API密钥,发现后阻断
PIIMiddleware(
"api_key",
detector=r"sk-[a-zA-Z0-9]{32}",
strategy="block", # 检测到后抛出错误
),
],
)
(2)Summarization:自动管理上下文长度
from langchain.agents import create_agent
from langchain.agents.middleware import SummarizationMiddleware
agent = create_agent(
model="openai:gpt-4o",
tools=[...],
middleware=[
SummarizationMiddleware(
model="openai:gpt-4o-mini", # 使用更便宜的模型总结
max_tokens_before_summary=4000, # 触发阈值
messages_to_keep=20 # 保留最近20条消息不总结
)
],
)
(3)Tool Retry:工具调用失败自动重试
from langchain.agents import create_agent
from langchain.agents.middleware import ToolRetryMiddleware
agent = create_agent(
model="openai:gpt-4o",
tools=[search_tool, database_tool],
middleware=[
ToolRetryMiddleware(
max_retries=3, # 最多重试3次
backoff_factor=2.0, # 指数退避倍数
initial_delay=1.0, # 初始延迟1秒
max_delay=60.0, # 最大延迟60秒
jitter=True, # 添加随机抖动(±25%)
),
],
)
(4)自定义中间件:
除了官方提供的预构建中间件,开发者可以通过装饰器或类继承的方式创建自定义中间件。例如,记录模型调用日志:
from langchain.agents.middleware import before_model
from langchain.agents.middleware import AgentState
from langgraph.runtime import Runtime
@before_model
def log_before_model(state: AgentState, runtime: Runtime) -> dict | None:
print(f"即将调用模型,当前消息数: {len(state['messages'])}")
return None # 返回None表示继续正常流程
agent = create_agent(
model="openai:gpt-4o",
tools=[...],
middleware=[log_before_model],
)
中间件机制将生产级能力(安全合规、错误处理、性能优化)从业务逻辑中解耦,让开发者可以像搭积木一样组合这些能力。
3. Structured Output:标准化的结构化输出机制
LangChain 1.0 引入了统一的结构化输出机制,解决了模型供应商之间输出格式不一致的问题。
核心问题:传统 Agent 开发中,不同模型供应商对结构化数据的支持方式各不相同。OpenAI 有 Native Structured Output API,而其他模型只能通过 Tool Calling 模拟,开发者需要针对不同供应商编写适配代码。
LangChain 的解决方案:通过create_agent的response_format参数,开发者只需定义一次数据 Schema,框架自动选择最优策略:
from langchain.agents import create_agent
from pydantic import BaseModel, Field
class WeatherReport(BaseModel):
location: str = Field(description="城市名称")
temperature: float = Field(description="温度(摄氏度)")
condition: str = Field(description="天气状况")
agent = create_agent(
model="openai:gpt-4o",
tools=[get_weather],
response_format=WeatherReport # 直接传入Pydantic模型
)
result = agent.invoke({"role": "user", "content": "上海今天天气怎么样?"})
weather_data = result['structured_response'] # 获取结构化数据
print(f"{weather_data.location}: {weather_data.temperature}°C, {weather_data.condition}")
两种实现策略:
(1)Provider Strategy:当模型原生支持结构化输出(如 OpenAI、Grok)时,LangChain 自动使用 API 级别的 schema enforcement,可靠性最高
(2)Tool Strategy:对于不支持原生结构化输出的模型,LangChain 将 Schema 转换为 Tool Calling,通过工具调用机制实现相同效果
开发者无需关心底层策略选择,框架根据模型能力自动适配。这种抽象让你可以在不同供应商之间自由切换,而业务代码保持不变。
4.向量数据库与 Agent 记忆系统的集成
生产级 Agent 的能力上限,往往不在推理引擎,而在记忆系统。LangChain 1.0 将向量数据库作为 Agent 的外部海马体,通过语义检索赋予 Agent 长期记忆能力,Milvus是其最重要的生态组成之一。
为什么选择 Milvus?
Milvus 是目前最成熟的开源向量数据库之一,专为 AI 应用的大规模向量检索而设计。它在 LangChain 生态中拥有原生集成,无需手动实现向量化、索引管理和相似度计算——langchain_milvus包已将其封装为标准的VectorStore接口。
Milvus 解决 Agent 的三个关键记忆问题
问题一:海量知识的快速检索
假设 Agent 需要处理成千上万份文档、历史对话、产品手册时,关键词搜索已经不够用。Milvus 通过向量相似度搜索,在毫秒级找到语义最相关的内容——即使用户换了说法。
from langchain.agents import create_agent
from langchain_milvus import Milvus
from langchain_openai import OpenAIEmbeddings
# 初始化向量数据库作为知识库
vectorstore = Milvus(
embedding=OpenAIEmbeddings(),
collection_name="company_knowledge",
connection_args={"uri": "http://localhost:19530"} #
)
# 将检索器转为Tool供Agent使用
agent = create_agent(
model="openai:gpt-4o",
tools=[vectorstore.as_retriever().as_tool(
name="knowledge_search",
description="搜索公司知识库以回答专业问题"
)],
system_prompt="你可以从知识库中检索信息来回答问题。"
)
问题二:长期记忆的持久化
Middleware 的SummarizationMiddleware可以压缩对话历史,但那些被总结掉的细节去哪了? Milvus 将每一轮对话、每一次工具调用的结果向量化存储,构建 Agent 的长期记忆。需要时,通过语义检索快速唤醒相关记忆。
记忆持久化模式:
from langchain_milvus import Milvus
from langchain.agents import create_agent
from langchain.agents.middleware import SummarizationMiddleware
from langgraph.checkpoint.memory import InMemorySaver
# 长期记忆存储(Milvus)
long_term_memory = Milvus.from_documents(
documents=[], # 初始为空,运行时动态写入
embedding=OpenAIEmbeddings(),
connection_args={"uri": "./agent_memory.db"}
)
# 短期记忆管理(LangGraph Checkpointer + Summarization)
agent = create_agent(
model="openai:gpt-4o",
tools=[long_term_memory.as_retriever().as_tool(
name="recall_memory",
description="检索Agent的历史记忆和过往经验"
)],
checkpointer=InMemorySaver(), # 短期记忆
middleware=[
SummarizationMiddleware(
model="openai:gpt-4o-mini",
max_tokens_before_summary=4000 # 超过阈值时总结并存入Milvus
)
]
)
问题三:多模态内容的统一管理
现代 Agent 要处理文本、图片、音频、视频。Milvus 的多向量支持和动态 Schema23,让你在同一个系统中管理不同模态的向量,为多模态 Agent 提供统一的记忆底座。
元数据过滤检索:
# 按来源过滤检索(例如:只检索医疗报告)
vectorstore.similarity_search(
query="患者的血压指标是多少?",
k=3,
expr="source == 'medical_reports' AND modality == 'text'" # Milvus标量过滤
)
有了 Milvus 提供的记忆底座,Agent 才能从健忘的执行器进化为具备经验积累的智能体。
三、LangChain 与 LangGraph 的技术定位与选型策略
LangChain 1.0以上升级,只是其构建生产级 Agent 的一环,但并不意味着LangChain 1.0永远是构建agent的最优解。
选择合适的开发框架,决定了你能多快将这些能力组合成可用的系统。
在实际开发中,LangChain 1.0 和 LangGraph 1.0 的关系经常被误解为二选一的竞争关系。实际上,它们是渐进式的技术栈:LangChain 专注于快速构建标准 Agent,LangGraph 提供底层编排能力用于复杂工作流。
以下是一个小的技术定位对比
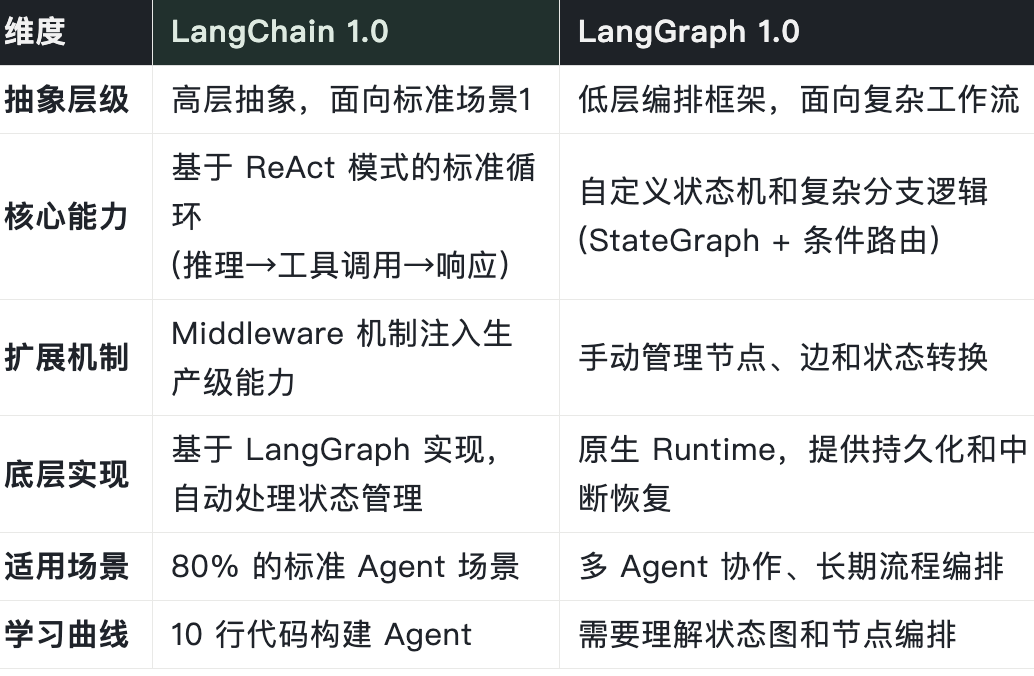
如果你是 Agent 新手或希望快速启动项目,从 LangChain 开始;如果你已经明确需要复杂编排、多 Agent 协作或长期流程,直接使用 LangGraph。两者可以在同一个项目中共存,根据具体场景选择合适的工具。
四、AI大模型从0到精通全套学习大礼包
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
只要你是真心想学AI大模型,我这份资料就可以无偿共享给你学习。大模型行业确实也需要更多的有志之士加入进来,我也真心希望帮助大家学好这门技术,如果日后有什么学习上的问题,欢迎找我交流,有技术上面的问题,我是很愿意去帮助大家的!
如果你也想通过学大模型技术去帮助就业和转行,可以扫描下方链接👇👇
大模型重磅福利:入门进阶全套104G学习资源包免费分享!

01.从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点
02.AI大模型学习路线图(还有视频解说)
全过程AI大模型学习路线


03.学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的


04.大模型面试题目详解


05.这些资料真的有用吗?
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
所有的视频由智泊AI老师录制,且资料与智泊AI共享,相互补充。这份学习大礼包应该算是现在最全面的大模型学习资料了。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


智泊AI始终秉持着“让每个人平等享受到优质教育资源”的育人理念,通过动态追踪大模型开发、数据标注伦理等前沿技术趋势,构建起"前沿课程+智能实训+精准就业"的高效培养体系。
课堂上不光教理论,还带着学员做了十多个真实项目。学员要亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!

如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 15
15 0
0- 0



 已为社区贡献511条内容
已为社区贡献511条内容

所有评论(0)