AAAI 2025 | 川大提出Mesorch:CNN与Transformer并行架构,革新图像篡改检测!
如今,图像篡改技术越来越逼真,如何准确识别和定位图像中被篡改的区域成为一个重要课题。现有的方法大多只关注图像的微观痕迹(如噪声、边缘)或宏观语义(如物体内容),难以同时捕捉篡改留下的细微痕迹和整体语义变化,导致定位效果不佳。实验表明,该模型在多个公开数据集上取得了最先进的定位精度,并且在抗干扰能力和计算效率方面也表现优异。作者姓名与单位:朱雪康、马晓晨、苏磊等,分别来自四川大学、MBZUAI、香港
一、导读
如今,图像篡改技术越来越逼真,如何准确识别和定位图像中被篡改的区域成为一个重要课题。现有的方法大多只关注图像的微观痕迹(如噪声、边缘)或宏观语义(如物体内容),难以同时捕捉篡改留下的细微痕迹和整体语义变化,导致定位效果不佳。
为了解决这一问题,本文提出了一种名为 Mesorch 的模型,它同时结合了 CNN 和 Transformer 两种网络结构,并引入频率域增强技术,自适应地融合多尺度特征。实验表明,该模型在多个公开数据集上取得了最先进的定位精度,并且在抗干扰能力和计算效率方面也表现优异。
二、论文基本信息

-
论文标题:Mesoscopic Insights: Orchestrating Multi-scale & Hybrid Architecture for Image Manipulation Localization
-
作者姓名与单位:朱雪康、马晓晨、苏磊等,分别来自四川大学、MBZUAI、香港理工大学、澳门大学等单位
-
发表日期与会议/期刊来源:AAAI 2025
-
代码链接:https://github.com/scu-zjz/Mesorch
三、主要贡献与创新
-
提出中观层面(mesoscopic level) 的图像篡改定位新视角,融合微观痕迹与宏观语义
-
设计并行混合编码器,CNN 提取局部特征,Transformer 提取全局语义
-
引入DCT频率增强模块,分别增强高频与低频信息以辅助定位
-
提出自适应加权模块(AdaptiveWeightingModule),动态融合多尺度预测
-
采用模型剪枝策略,在保持性能的同时降低计算开销
四、研究方法与原理
Mesorch 的核心思路是:通过频率增强与并行编码,同时捕捉图像的局部篡改痕迹和全局语义变化,再通过自适应加权融合多尺度预测结果。
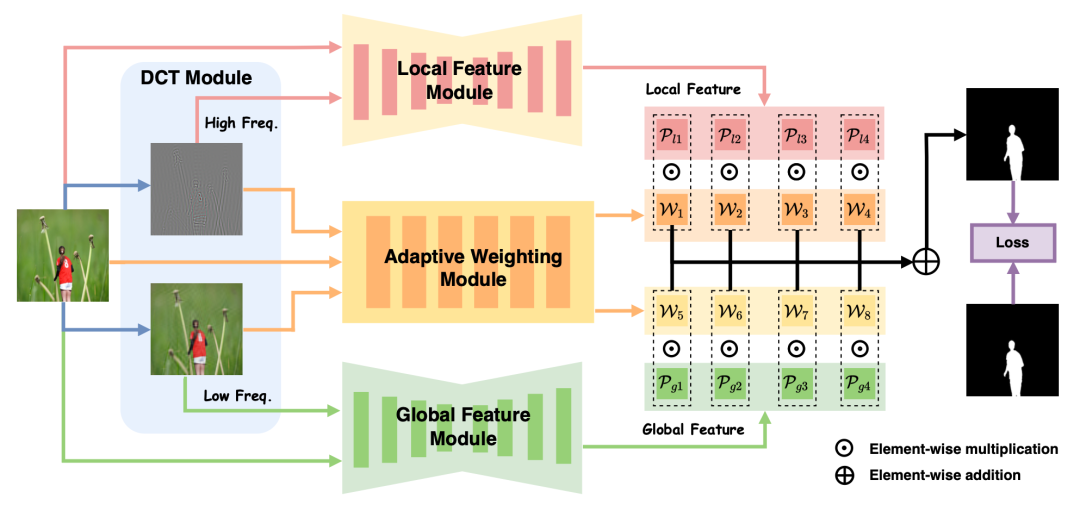
-
频率增强模块:
输入 RGB 图像 ,通过离散余弦变换(DCT)分离出高频 和低频 成分,分别与原始图像拼接,得到增强后的输入: -
并行编码与解码:
输入 LocalFeatureEncoder(CNN), 输入 GlobalFeatureEncoder(Transformer),各自输出四个尺度的特征图:每个尺度的特征分别通过解码器生成预测掩码:
-
自适应加权与融合:
加权模块输入 ,输出每个尺度的权重 ,最终预测为: -
模型剪枝:
计算每个尺度的平均权重 ,若低于阈值 ,则剪枝该尺度,以提升效率。
五、实验设计与结果分析
实验设置
-
数据集:CASIA v1、Coverage、NIST16、Columbia
-
图像尺寸:512×512
-
训练策略:150 epochs,batch size=12,AdamW 优化器,余弦学习率调度
-
评估指标:F1 分数、AUC、IOU、FLOPs、参数量
对比实验
【表1】显示 Mesorch 在四个数据集上的 F1 分数均优于现有方法(如 MVSS-Net、CAT-Net、TruFor等),平均 F1 达到 0.6771,剪枝后仍保持领先。
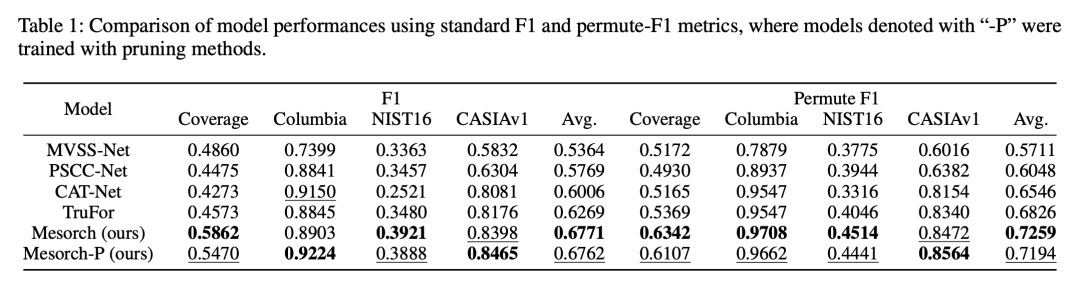
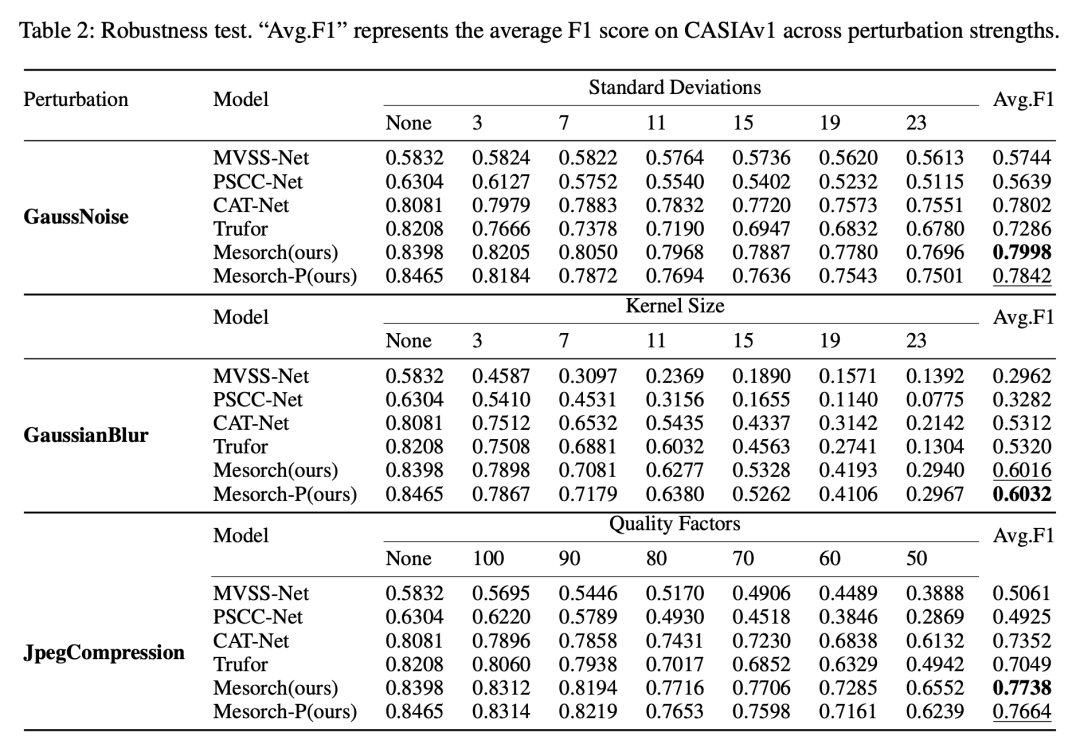
【表2】展示了在高斯噪声、高斯模糊、JPEG压缩三种干扰下的鲁棒性测试,Mesorch 在几乎所有干扰强度下均表现最优。
可视化对比
【图4】展示了 Mesorch 在语义与非语义篡改图像上的定位效果,能同时捕捉物体布局与细节痕迹。

消融实验
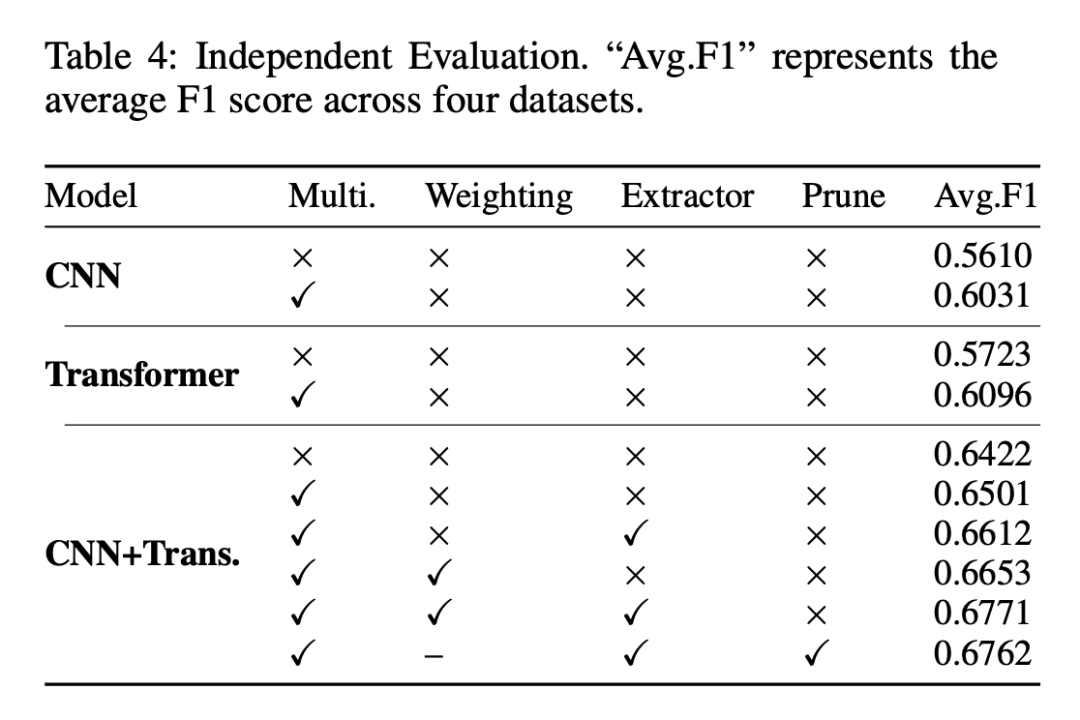
【表4】验证了各模块的贡献:多尺度、加权模块、DCT 提取、剪枝均能提升性能。
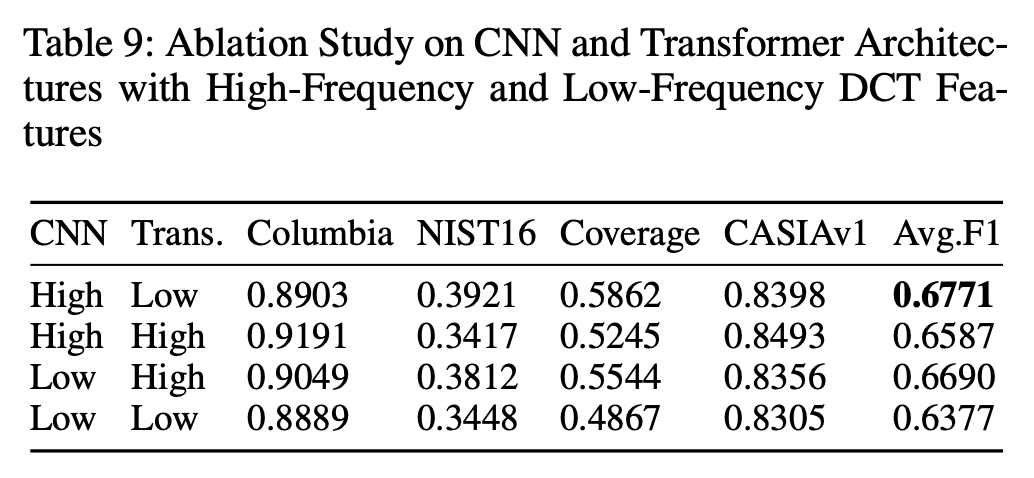
【表9】进一步显示:高频特征更适合 CNN,低频特征更适合 Transformer,二者结合效果最佳。
六、论文结论与评价
总结
本文提出了一种中观层面融合微观与宏观信息的图像篡改定位框架 Mesorch,通过并行 CNN-Transformer 编码、DCT 频率增强、自适应加权与剪枝,在多个数据集上实现了最先进的定位精度与鲁棒性。
评价
该方法首次将频率增强与混合架构系统性地引入篡改定位任务,具有较强的实用性与推广价值。其优点在于兼顾局部细节与全局语义,且计算效率高;缺点在于对训练数据质量依赖较强,且在极端低分辨率或强压缩图像上性能可能下降。未来可进一步探索更轻量化的网络结构与跨域泛化能力,以适用于更广泛的真实场景。
【往期内容推荐】
NeurIPS 2025|北交大等提出Jasmine:自监督+Stable Diffusion先验,实现高质量单目深度感知
北大、阿里通义提出UniLIP: 自蒸馏训练助力CLIP大一统重建!1B参数性能超越7B模型!
CVPR 2025 | 交叉注意力机制还能这么玩?WPFormer利用双域Transformer刷新缺陷检测SOTA(含代码)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 21
21 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)