Milvus:嵌入函数(Embeddings)功能详解(二十二)
摘要:Milvus的嵌入函数模块简化了文本向量化与语义搜索流程,支持OpenAI、AWS Bedrock等主流嵌入服务。通过自动化处理文本转向量、存储和搜索全流程,开发者无需编写底层API代码。该模块支持多服务商配置、批量操作优化和维度定制,适用于文档检索、产品推荐等场景。核心优势包括:开发简化(避免手动处理向量)、统一管理(集中配置多服务商)、灵活适配(支持不同模型和场景)。最佳实践建议采用配置
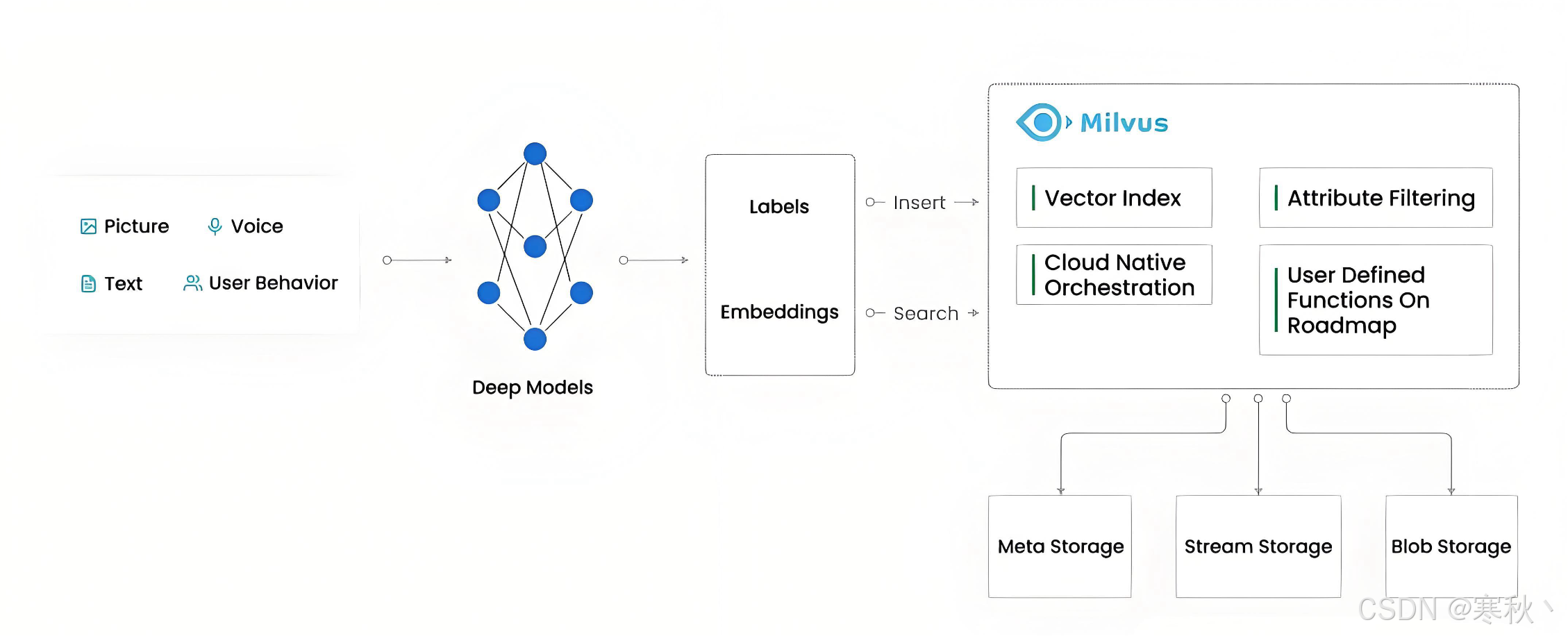
一、嵌入函数概述
1.1 基本概念
- 自动化处理:从调用嵌入服务到向量存储,全程无需人工干预,减少重复工作
- 简化开发:规避 API 调用、错误处理、向量格式转换等底层细节,专注业务逻辑
- 统一管理:在 Milvus 中集中配置多个嵌入服务,支持按需切换,无需修改核心代码
- 语义搜索:直接使用自然语言查询,系统自动将查询文本转换为向量,降低使用门槛
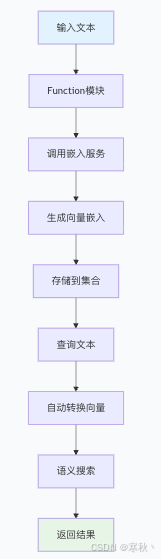
1.2 工作原理
- 数据写入阶段:输入文本 → 触发 Function 模块 → 调用配置好的嵌入服务 → 生成向量嵌入 → 存储到指定集合的向量字段
- 查询搜索阶段:输入查询文本 → Function 模块自动转换为向量 → 基于向量相似度匹配 → 返回关联结果
1.3 限制说明
- 输入字段限制:必须为非空的 VARCHAR 类型,若字段可能存在空值,需在插入前做数据清洗
- 字段处理规则:仅处理 Schema 中明确定义的字段,不会自动识别动态新增字段,需提前规划字段结构
- 向量类型支持:仅支持 FLOAT_VECTOR(浮点向量)和 INT8_VECTOR(8 位整型向量),不支持二进制向量(BINARY_VECTOR)、半精度浮点向量(FLOAT16_VECTOR)等类型
- 维度匹配要求:向量字段的 dim(维度)必须与嵌入模型的输出维度一致,否则会导致向量存储失败
二、支持的嵌入服务提供商
|
提供商 |
典型模型 |
嵌入类型 |
验证方法 |
补充说明 |
|
OpenAI |
text-embedding-3-*(small/large) |
FLOAT_VECTOR |
API 密钥 |
主流选择,支持维度自定义(1536-3072),适合大多数语义搜索场景 |
|
Azure OpenAI |
基于部署 |
FLOAT_VECTOR |
API 密钥 |
需提前在 Azure 平台部署模型,适合企业级合规场景 |
|
DashScope |
text-embedding-v3 |
FLOAT_VECTOR |
API 密钥 |
阿里云推出的嵌入服务,对中文文本支持较好 |
|
基岩(AWS Bedrock) |
Amazon.titan-embed-text-v2 |
FLOAT_VECTOR |
AK/SK 对 |
需配置 AWS 区域(如 us-east-2),适合 AWS 生态用户 |
|
顶点人工智能(Google Vertex AI) |
text-embedding-005 |
FLOAT_VECTOR |
GCP 服务帐户 JSON 凭证 |
凭证需转换为 BASE64 格式,适合 GCP 生态用户 |
|
Voyage AI |
Voyage-3, Voyage-lite-02 |
FLOAT_VECTOR / INT8_VECTOR |
API 密钥 |
支持低精度 INT8 向量,可降低存储成本 |
|
嵌入(Cohere) |
embed-english-v3.0 |
FLOAT_VECTOR / INT8_VECTOR |
API 密钥 |
英文文本嵌入效果优秀,适合英文场景为主的应用 |
|
SiliconFlow |
BAAI/bge-large-zh-v1.5 |
FLOAT_VECTOR |
API 密钥 |
开源中文嵌入模型,适合对成本敏感且需中文优化的场景 |
|
Hugging Face |
任何 TEI 服务的模型 |
FLOAT_VECTOR |
可选的 API 密钥 |
支持自定义开源模型,需部署 TEI(Text Embedding Inference)服务 |
三、配置凭证
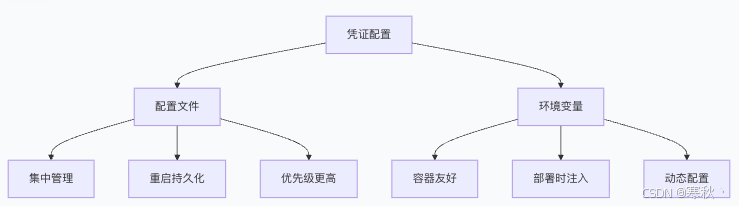
3.1 凭证配置方式
Milvus 支持两种凭证配置方式,适用于不同部署场景:
|
配置方式 |
核心特点 |
适用场景 |
优势 |
|
配置文件(milvus.yaml) |
集中管理、重启后持久化 |
物理机部署、稳定生产环境 |
安全性高,便于批量管理多个提供商凭证 |
|
环境变量 |
容器友好、部署时注入、动态配置 |
Docker/K8s 容器化部署 |
无需修改配置文件,适合动态调整的场景 |
优先级规则:若同一提供商的凭证同时存在于配置文件和环境变量中,Milvus 优先使用配置文件中的值,建议生产环境统一使用配置文件管理。
3.2 配置文件方式(推荐)
3.2.1 步骤 1:在 milvus.yaml 中添加凭证
# milvus.yaml 凭证配置段
# 说明:所有外部嵌入服务的认证信息集中配置在此,每个凭证需定义唯一名称(如 aksk1、apikey1)
credential:
# 适用于 AWS Bedrock 等需要 AK/SK 认证的服务
# 名称:aksk1(可自定义,建议体现服务类型+环境,如 bedrock_aksk)
aksk1:
access_key_id: <YOUR_AK> # 替换为实际的 Access Key ID
secret_access_key: <YOUR_SK> # 替换为实际的 Secret Access Key
# 适用于 OpenAI、Voyage AI 等基于 API 密钥的服务
# 名称:apikey1(可自定义,如 openai_prod_key)
apikey1:
apikey: <YOUR_API_KEY> # 替换为实际的 API 密钥
# 适用于 Google Vertex AI 服务
# 名称:gcp1(可自定义,如 vertexai_proj1)
gcp1:
# 说明:将 GCP 服务帐户 JSON 文件内容转换为 BASE64 编码后填入
credential_json: <BASE64_OF_JSON>3.2.2 步骤 2:配置提供商设置
function:
textEmbedding:
providers:
# OpenAI 配置
openai:
credential: apikey1 # 引用上方定义的凭证名称(必须一致)
# url: # 可选,默认使用 OpenAI 官方 API 地址,如需代理可配置代理地址
model_name: text-embedding-3-small # 指定使用的模型
# AWS Bedrock 配置
bedrock:
credential: aksk1 # 引用 AK/SK 类型凭证
region: us-east-2 # 必须配置,指定 AWS 区域
model_name: amazon.titan-embed-text-v2 # Bedrock 支持的模型
# Google Vertex AI 配置
vertexai:
credential: gcp1 # 引用 GCP 凭证
# url: # 可选,自定义 Vertex AI API 地址
# TEI 服务(Hugging Face)配置
tei:
enable: true # 是否启用内置 TEI 模型服务
# url: # 可选,指定 TEI 服务部署地址3.3 环境变量方式
适用于 Docker 或 K8s 部署场景,以 docker-compose.yaml 为例:
# docker-compose.yaml 中 standalone 服务的环境变量配置
standalone:
# 其他配置(如镜像、端口映射等)省略
environment:
# 其他环境变量省略
# OpenAI API 密钥配置
MILVUSAI_OPENAI_API_KEY: <YOUR_OPENAI_API_KEY>
# AWS Bedrock 凭证配置
MILVUSAI_AWS_ACCESS_KEY_ID: <YOUR_AWS_ACCESS_KEY>
MILVUSAI_AWS_SECRET_ACCESS_KEY: <YOUR_AWS_SECRET_KEY>
# 其他提供商环境变量格式:MILVUSAI_<提供商名称>_<凭证字段>四、使用嵌入函数
4.1 完整工作流程
以下代码实现了 “创建集合 → 配置嵌入函数 → 建立索引” 的完整流程,每一步都添加了详细注释:
from pymilvus import MilvusClient, DataType, Function, FunctionType
def setup_embedding_collection():
"""设置包含嵌入函数的集合完整示例(带详细注释)"""
# 1. 初始化 Milvus 客户端
# 说明:uri 为 Milvus 服务地址,默认本地部署为 http://localhost:19530
# 若为集群部署,需填写集群访问地址(如 http://milvus-cluster:19530)
client = MilvusClient(uri="http://localhost:19530")
# 2. 创建 Schema(数据结构定义)
# 说明:Schema 定义了集合的字段类型、主键、向量字段等核心信息
schema = client.create_schema()
# 3. 添加主键字段
# 类型:INT64(支持大范围数值),is_primary=True 表示为主键
# auto_id=False 表示手动指定 ID,若需自动生成可设为 True
schema.add_field("id", DataType.INT64, is_primary=True, auto_id=False)
# 4. 添加标量字段用于存储文本数据
# 类型:VARCHAR(字符串类型),max_length=9000 表示最大支持 9000 字符
# 注意:该字段为嵌入函数的输入字段,需与后续 function 配置的 input_field_names 一致
schema.add_field("document", DataType.VARCHAR, max_length=9000)
# 5. 添加向量字段用于存储嵌入结果
# 类型:FLOAT_VECTOR(浮点向量),dim=1536 表示向量维度
# 关键:dim 必须与嵌入模型的输出维度匹配(text-embedding-3-small 默认 1536)
schema.add_field("dense", DataType.FLOAT_VECTOR, dim=1536)
# 6. 定义嵌入函数
# 说明:Function 类用于配置嵌入服务的核心参数
text_embedding_function = Function(
name="openai_embedding", # 函数名称(自定义,需唯一)
function_type=FunctionType.TEXTEMBEDDING, # 函数类型(固定为文本嵌入)
input_field_names=["document"], # 输入字段(即存储文本的标量字段)
output_field_names=["dense"], # 输出字段(即存储向量的向量字段)
params={
"provider": "openai", # 嵌入服务提供商(需与配置文件中一致)
"model_name": "text-embedding-3-small", # 使用的模型名称
# "credential": "apikey1", # 可选:引用配置文件中的凭证名称(若未指定则使用默认凭证)
# "dim": "1536", # 可选:缩短向量维度(需小于模型默认维度,如 1536→768)
# "user": "user123" # 可选:用于嵌入服务的用户追踪(如 OpenAI 的用户标识)
}
)
# 7. 将嵌入函数添加到 Schema
# 说明:只有添加到 Schema 的函数才会生效,支持添加多个函数
schema.add_function(text_embedding_function)
# 8. 配置索引参数
# 说明:索引用于加速向量相似度搜索,AUTOINDEX 为 Milvus 自动选择最优索引类型
index_params = client.prepare_index_params()
index_params.add_index(
field_name="dense", # 索引字段(即向量字段)
index_type="AUTOINDEX", # 索引类型(推荐默认 AUTOINDEX,无需手动优化)
metric_type="COSINE" # 相似度计算方式(COSINE 适用于文本嵌入,支持 IP、L2 等)
)
# 9. 创建集合
# 说明:集合名称需唯一,创建后 Schema 不可修改
client.create_collection(
collection_name='demo_embeddings', # 集合名称(自定义)
schema=schema, # 传入配置好的 Schema
index_params=index_params # 传入索引配置
)
print("嵌入集合设置完成")
return client
# 执行设置(实际使用时需确保 Milvus 服务已启动)
client = setup_embedding_collection()4.2 插入数据示例
def insert_sample_data(client):
"""插入示例数据并自动生成嵌入(带详细注释)"""
# 示例文档数据
# 说明:数据格式为列表字典,每个字典对应一条记录,key 需与 Schema 中的字段一致
documents = [
{'id': 1, 'document': 'Milvus simplifies semantic search through numeric data.'},
{'id': 2, 'document': 'Vector embeddings convert text into searchable information quickly.'},
{'id': 3, 'document': 'Semantic search helps users find relevant to vector conversion.'},
{'id': 4, 'document': 'Embedding functions automate the process of text from textual input.'},
{'id': 5, 'document': 'Machine learning models generate dense vectors'}
]
# 插入数据 - 嵌入函数会自动处理向量生成
# 关键:无需手动调用嵌入 API,Milvus 会自动触发嵌入函数,生成向量并存储
insert_result = client.insert(
collection_name='demo_embeddings', # 目标集合名称(需已创建)
data=documents # 待插入的数据(需匹配 Schema 字段)
)
print(f"成功插入 {len(documents)} 个文档")
print(f"插入结果: {insert_result}") # 输出插入状态(如成功条数、ID 列表)
# 验证嵌入生成(通过查询确认数据已插入)
verify_result = client.query(
collection_name='demo_embeddings',
filter='id in [1, 2, 3]', # 筛选条件(查询 ID 为 1、2、3 的记录)
output_fields=['id', 'document'] # 需返回的字段(向量字段无法直接查询输出)
)
print("\n插入的文档:")
for entity in verify_result:
print(f" ID: {entity['id']}, 文档: {entity['document']}")
# 插入数据(需先执行 setup_embedding_collection 创建集合)
insert_sample_data(client)- 数据格式必须与 Schema 字段完全匹配,缺失字段或字段类型错误会导致插入失败
- 文本字段长度不能超过 VARCHAR 类型的 max_length 限制,否则会被截断
- 插入时若触发嵌入服务调用失败(如 API 密钥无效、网络异常),数据会插入失败,需检查凭证配置和网络连接
4.3 语义搜索示例
def semantic_search_demo(client):
"""演示语义搜索功能(带详细注释)"""
# 搜索查询列表(自然语言文本,无需手动转换为向量)
search_queries = [
'How does Milvus handle text search?', # 英文查询:Milvus 如何处理文本搜索?
'What are vector embeddings?', # 英文查询:什么是向量嵌入?
'Tell me about automated text processing' # 英文查询:介绍自动文本处理
]
for i, query in enumerate(search_queries, 1):
print(f"\n=== 搜索查询 {i}: '{query}' ===")
# 执行语义搜索 - 直接使用文本查询
results = client.search(
collection_name='demo_embeddings', # 目标集合名称
data=[query], # 搜索文本(列表格式,支持批量查询)
anns_field='dense', # 用于搜索的向量字段(即存储嵌入的字段)
limit=2, # 返回前 2 个最相关的结果
output_fields=['document'], # 返回的字段(需包含文本字段以便查看)
search_params={"metric_type": "COSINE", "params": {"nprobe": 10}} # 搜索参数
)
# 处理搜索结果
if results and len(results) > 0:
for j, hits in enumerate(results):
print(f"查询 {i} 的结果:")
for k, hit in enumerate(hits):
entity = hit.get('entity', {}) # 获取结果中的实体数据
# distance:相似度分数(COSINE 算法取值 0-1,越接近 1 相似度越高)
print(f" 排名 {k+1}: ID={hit['id']}, 相似度={hit['distance']:.4f}")
print(f" 文档: {entity.get('document', 'N/A')}")
else:
print("未找到相关结果")
# 执行语义搜索演示(需先插入数据)
semantic_search_demo(client)- 相似度分数:COSINE 算法下,分数越接近 1 表示查询与文档语义越相关
- 批量查询:data 参数支持传入多个查询文本(如 [query1, query2]),返回对应多个结果列表
- 搜索参数优化:nprobe 为查询参数,数值越大查询精度越高但速度越慢,默认 10 即可满足大部分场景
4.4 使用预计算向量搜索
def precomputed_vector_search(client):
"""演示使用预计算向量的搜索(带详细注释)"""
# 假设我们有一个预计算的查询向量(维度必须与集合的向量字段维度一致)
# 应用场景:若已提前生成向量(如离线批量计算),可直接使用向量搜索,避免重复调用嵌入服务
# 注意:预计算向量必须由与集合配置相同的嵌入模型生成,否则相似度无意义
precomputed_vector = [0.1] * 1536 # 示例向量(实际使用时需替换为真实嵌入结果)
print("=== 使用预计算向量搜索 ===")
results = client.search(
collection_name='demo_embeddings',
data=[precomputed_vector], # 传入预计算向量(列表格式)
anns_field='dense', # 向量字段名称
limit=3, # 返回前 3 个结果
output_fields=['document'], # 返回文本字段
search_params={"metric_type": "COSINE", "params": {"nprobe": 10}}
)
if results and len(results) > 0:
for hits in results:
for hit in hits:
entity = hit.get('entity', {})
print(f" ID: {hit['id']}, 相似度: {hit['distance']:.4f}")
print(f" 文档: {entity.get('document', 'N/A')}")
# 执行预计算向量搜索
precomputed_vector_search(client)五、多提供商配置示例
5.1 配置多个嵌入服务
# milvus.yaml - 多提供商配置示例(带详细注释)
credential:
# OpenAI 生产环境凭证(用于正式业务)
openai_prod:
apikey: "sk-prod-xxxxxxxxxxxxxxxx" # 生产环境 API 密钥
# OpenAI 开发环境凭证(用于测试)
openai_dev:
apikey: "sk-dev-xxxxxxxxxxxxxxxx" # 开发环境 API 密钥
# AWS Bedrock 凭证(美国东部区域)
bedrock_us_east:
access_key_id: "AKIAxxxxxxxxxxxxxxxx" # AWS Access Key ID
secret_access_key: "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" # AWS Secret Access Key
# Google Vertex AI 凭证
vertexai_proj1:
# GCP 服务帐户 JSON 文件的 BASE64 编码(需完整转换,不含换行)
credential_json: "ewogICJ0eXBlIjogInNlcnZpY2VfYWNjb3VudCIsCiAgInByb2plY3RfaWQiOiAi...(省略完整编码)"
function:
textEmbedding:
providers:
# 多个 OpenAI 配置(区分生产/开发环境)
openai_prod:
credential: openai_prod # 引用生产环境凭证
model_name: "text-embedding-3-large" # 大型模型,高精度场景使用
openai_dev:
credential: openai_dev # 引用开发环境凭证
model_name: "text-embedding-3-small" # 小型模型,测试场景使用
# AWS Bedrock 配置
bedrock:
credential: bedrock_us_east # 引用 Bedrock 凭证
region: "us-east-1" # 指定 AWS 区域
model_name: "amazon.titan-embed-text-v2" # Bedrock 支持的模型
# Google Vertex AI 配置
vertexai:
credential: vertexai_proj1 # 引用 Vertex AI 凭证
model_name: "text-embedding-005" # Vertex AI 模型5.2 多函数集合示例
def setup_multi_function_collection():
"""设置包含多个嵌入函数的集合(带详细注释)"""
# 初始化客户端
client = MilvusClient(uri="http://localhost:19530")
# 创建 Schema
schema = client.create_schema()
# 添加字段
schema.add_field("id", DataType.INT64, is_primary=True, auto_id=False) # 主键
schema.add_field("title", DataType.VARCHAR, max_length=500) # 标题字段(短文本)
schema.add_field("content", DataType.VARCHAR, max_length=9000) # 内容字段(长文本)
# 标题向量字段(使用 OpenAI small 模型,维度 1536)
schema.add_field("title_embedding", DataType.FLOAT_VECTOR, dim=1536)
# 内容向量字段(使用 OpenAI large 模型,维度 3072)
schema.add_field("content_embedding", DataType.FLOAT_VECTOR, dim=3072)
# 为标题添加嵌入函数(小型模型,适合短文本)
title_embedding_function = Function(
name="title_embedding_fn", # 函数名称(唯一)
function_type=FunctionType.TEXTEMBEDDING,
input_field_names=["title"], # 输入:标题字段
output_field_names=["title_embedding"], # 输出:标题向量字段
params={
"provider": "openai",
"model_name": "text-embedding-3-small", # 小型模型,速度快、成本低
"dim": 1536 # 匹配向量字段维度
}
)
# 为内容添加嵌入函数(大型模型,适合长文本高精度场景)
content_embedding_function = Function(
name="content_embedding_fn", # 函数名称(唯一)
function_type=FunctionType.TEXTEMBEDDING,
input_field_names=["content"], # 输入:内容字段
output_field_names=["content_embedding"], # 输出:内容向量字段
params={
"provider": "openai",
"model_name": "text-embedding-3-large", # 大型模型,精度高
"dim": 3072 # 匹配向量字段维度
}
)
# 将两个函数添加到 Schema
schema.add_function(title_embedding_function)
schema.add_function(content_embedding_function)
# 配置索引(为两个向量字段分别建立索引)
index_params = client.prepare_index_params()
# 标题向量索引
index_params.add_index(
field_name="title_embedding",
index_type="AUTOINDEX",
metric_type="COSINE"
)
# 内容向量索引
index_params.add_index(
field_name="content_embedding",
index_type="AUTOINDEX",
metric_type="COSINE"
)
# 创建集合
client.create_collection(
collection_name='multi_embedding_demo',
schema=schema,
index_params=index_params
)
print("多函数嵌入集合设置完成")
return client
# 设置多函数集合
multi_client = setup_multi_function_collection()5.3 多字段数据插入和搜索
def multi_field_operations(client):
"""多字段数据操作演示(带详细注释)"""
# 插入多字段数据(包含 id、title、content 三个字段)
multi_field_data = [
{
'id': 1,
'title': 'Introduction to Machine Learning', # 标题(短文本)
'content': 'Machine learning is a subset of artificial intelligence that focuses on algorithms...' # 内容(长文本)
},
{
'id': 2,
'title': 'Deep Learning Fundamentals',
'content': 'Deep learning utilizes neural networks with multiple layers to model complex patterns...'
},
{
'id': 3,
'title': 'Natural Language Processing',
'content': 'NLP enables computers to understand, interpret, and generate human language...'
}
]
# 插入数据 - 两个嵌入函数会自动处理各自的字段
# 说明:标题嵌入函数处理 title 字段,内容嵌入函数处理 content 字段,并行生成向量
insert_result = client.insert(
collection_name='multi_embedding_demo',
data=multi_field_data
)
print(f"插入多字段数据: {len(multi_field_data)} 条记录")
# 基于标题搜索(适合快速匹配短文本关键词)
print("\n=== 基于标题搜索 ===")
title_results = client.search(
collection_name='multi_embedding_demo',
data=['AI and machine learning basics'], # 搜索文本(与标题语义相关)
anns_field='title_embedding', # 使用标题向量字段搜索
limit=2, # 返回前 2 个结果
output_fields=['title', 'content'], # 返回标题和内容字段
search_params={"metric_type": "COSINE", "params": {"nprobe": 10}}
)
for hits in title_results:
for hit in hits:
entity = hit.get('entity', {})
print(f" 标题匹配: {entity.get('title')} (相似度: {hit['distance']:.4f})")
# 基于内容搜索(适合高精度语义匹配长文本)
print("\n=== 基于内容搜索 ===")
content_results = client.search(
collection_name='multi_embedding_demo',
data=['neural networks and deep learning models'], # 搜索文本(与内容语义相关)
anns_field='content_embedding', # 使用内容向量字段搜索
limit=2,
output_fields=['title', 'content'],
search_params={"metric_type": "COSINE", "params": {"nprobe": 10}}
)
for hits in content_results:
for hit in hits:
entity = hit.get('entity', {})
print(f" 内容匹配: {entity.get('title')} (相似度: {hit['distance']:.4f})")
# 执行多字段操作
multi_field_operations(multi_client)六、错误处理和验证
6.1 嵌入生成验证
def verify_embedding_generation(client, collection_name):
"""验证嵌入生成是否正确(带详细注释)"""
try:
# 步骤1:查询集合检查数据是否插入成功
# 说明:通过主键筛选查询,确认文本数据已存储
sample_results = client.query(
collection_name=collection_name,
filter='id == 1', # 查询 ID 为 1 的记录
output_fields=['id', 'document'] # 向量字段无法直接查询,仅返回标量字段
)
if sample_results:
print("✓ 数据插入成功")
# 步骤2:通过搜索验证嵌入功能是否正常
# 说明:使用测试查询文本,若能返回结果则说明嵌入生成成功
test_results = client.search(
collection_name=collection_name,
data=['test query'], # 测试查询文本(无实际意义,仅用于验证)
anns_field='dense', # 向量字段
limit=1,
output_fields=['document']
)
if test_results and len(test_results[0]) > 0:
print("✓ 嵌入生成和搜索功能正常")
return True
else:
print("✗ 搜索功能异常(未返回结果,可能嵌入生成失败)")
return False
else:
print("✗ 数据插入失败(未查询到指定 ID 的记录)")
return False
except Exception as e:
# 捕获所有异常(如集合不存在、网络异常、凭证错误等)
print(f"✗ 验证过程中出错: {e}")
return False
# 验证嵌入生成(传入客户端和集合名称)
verification_result = verify_embedding_generation(client, 'demo_embeddings')
print(f"嵌入功能验证: {'成功' if verification_result else '失败'}")6.2 错误处理示例
def robust_embedding_operations(client):
"""健壮的嵌入操作示例(带详细注释)"""
try:
# 测试1:空值处理(嵌入函数要求输入字段非空)
print("=== 测试空值处理 ===")
try:
invalid_data = [{'id': 100, 'document': ''}] # document 字段为空字符串
client.insert(collection_name='demo_embeddings', data=invalid_data)
print("✓ 空字符串处理正常")
except Exception as e:
# 预期错误:空值会导致嵌入服务调用失败,抛出异常
print(f"✗ 空字符串处理异常: {e}")
# 常见错误类型:InvalidArgumentError(参数无效)
# 测试2:无效凭证处理
print("\n=== 测试无效凭证处理 ===")
try:
# 定义使用不存在的凭证的嵌入函数
invalid_function = Function(
name="invalid_embedding",
function_type=FunctionType.TEXTEMBEDDING,
input_field_names=["document"],
output_field_names=["dense"],
params={
"provider": "openai",
"model_name": "text-embedding-3-small",
"credential": "nonexistent_credential" # 不存在的凭证名称
}
)
# 尝试添加函数到临时 Schema(仅用于测试)
temp_schema = client.create_schema()
temp_schema.add_field("id", DataType.INT64, is_primary=True)
temp_schema.add_field("document", DataType.VARCHAR, max_length=100)
temp_schema.add_field("dense", DataType.FLOAT_VECTOR, dim=1536)
temp_schema.add_function(invalid_function)
print("✗ 应检测到无效凭证")
except Exception as e:
# 预期错误:凭证不存在,抛出异常
print(f"✓ 正确检测到无效凭证: {e}")
# 常见错误类型:CredentialNotFoundError(凭证未找到)
except Exception as e:
# 捕获其他未预期的异常
print(f"操作异常: {e}")
# 执行错误处理测试
robust_embedding_operations(client)- 凭证错误:API 密钥无效、凭证名称不存在 → 检查凭证配置是否正确
- 字段错误:输入字段为空、字段类型不匹配 → 清洗数据,确保字段符合 Schema 定义
- 维度错误:向量维度与模型不匹配 → 调整 Schema 中向量字段的 dim 或模型参数
- 网络错误:无法连接嵌入服务 → 检查网络连接,确认嵌入服务可访问
七、性能优化建议
7.1 维度优化策略
def dimension_optimization_demo():
"""演示维度优化策略(带详细注释)"""
# 不同模型的维度优化建议(结合成本和性能)
optimization_strategies = {
"小型模型 (text-embedding-3-small)": {
"默认维度": 1536,
"优化建议": "适合大多数用例,平衡性能和质量,无需调整维度",
"适用场景": "通用语义搜索、文档检索、中小型数据集",
"成本说明": 每 1000 个 tokens 约 0.0001 美元,维度不变则成本固定
},
"大型模型 (text-embedding-3-large)": {
"默认维度": 3072,
"优化建议": "可缩短至 1024-2560 维度以优化成本(如 3072→1536,成本降低 50%)",
"适用场景": "高精度检索、复杂语义匹配、大型数据集",
"成本说明": 每 1000 个 tokens 约 0.0004 美元,维度越低成本越低,精度略有下降
},
"Ada 模型 (text-embedding-ada-002)": {
"默认维度": 1536,
"优化建议": "固定维度,无法调整,适合传统管道",
"适用场景": "向后兼容、稳定要求高、成本敏感的场景",
"成本说明": 每 1000 个 tokens 约 0.0001 美元,性价比高
}
}
print("嵌入模型维度优化策略:")
for model, info in optimization_strategies.items():
print(f"\n{model}:")
for key, value in info.items():
print(f" {key}: {value}")
# 显示优化策略
dimension_optimization_demo()- 无需高精度场景:使用小型模型,保持默认维度,兼顾速度和成本
- 高精度场景:使用大型模型,根据需求适当降低维度(如 3072→2048),平衡精度和成本
- 大规模数据集:降低维度可减少存储成本和搜索时间(向量存储量与维度成正比)
7.2 批量操作优化
def batch_operations_demo(client):
"""批量操作优化演示(带详细注释)"""
# 生成批量数据(10 条记录,实际可根据需求调整批量大小)
batch_data = []
for i in range(100, 110): # ID 从 100 到 109,共 10 条数据
batch_data.append({
'id': i,
'document': f'This is sample document number {i} discussing various topics in machine learning and artificial intelligence.'
})
print(f"准备插入 {len(batch_data)} 条记录...")
# 批量插入(测量耗时)
import time
start_time = time.time()
insert_result = client.insert(
collection_name='demo_embeddings',
data=batch_data
)
end_time = time.time()
duration = end_time - start_time
print(f"批量插入完成,耗时: {duration:.2f} 秒")
print(f"平均每条记录: {duration/len(batch_data):.3f} 秒")
# 验证批量插入结果(查询 ID ≥100 的记录)
verify_count = client.query(
collection_name='demo_embeddings',
filter='id >= 100',
output_fields=['id'],
limit=5 # 仅返回前 5 条验证
)
print(f"验证插入记录数: {len(verify_count)} 条")
# 执行批量操作演示
batch_operations_demo(client)- 批量大小:建议每次插入 100-1000 条记录,过小会增加 API 调用次数,过大可能导致超时
- 超时处理:批量插入时可设置 timeout 参数(如 timeout=30),避免网络波动导致失败
- 异步插入:对于超大规模数据,可使用异步插入接口(client.insert_async),提高处理效率
- 错误重试:批量操作失败时,建议拆分数据分批重试,避免重复插入已成功的数据
八、实际应用场景
8.1 文档检索系统
def document_retrieval_system(client):
"""文档检索系统示例(支持中文,带业务逻辑注释)"""
# 模拟文档库(中文文档,适用于中文语义搜索场景)
documents = [
{'id': 1001, 'document': '机器学习是人工智能的一个分支,专注于算法和统计模型的开发,使计算机能够自主学习。'},
{'id': 1002, 'document': '深度学习使用多层神经网络来学习数据的层次化表示,适用于图像识别、自然语言处理等领域。'},
{'id': 1003, 'document': '自然语言处理(NLP)使计算机能够理解、解释和生成人类语言,常见应用包括机器翻译、情感分析。'},
{'id': 1004, 'document': '计算机视觉涉及让计算机从数字图像或视频中获取高级理解,应用于人脸识别、自动驾驶等场景。'},
{'id': 1005, 'document': '强化学习是机器学习的一个领域,关注智能体如何在环境中采取行动以获得最大奖励,适用于机器人控制。'}
]
# 插入文档到 Milvus(自动生成向量)
client.insert('demo_embeddings', documents)
print("文档库初始化完成(共 5 篇中文文档)")
# 用户查询处理(中文自然语言查询)
user_queries = [
'什么是人工智能?',
'如何让计算机理解语言?',
'神经网络有哪些类型?'
]
print("\n=== 文档检索系统 ===")
for query in user_queries:
print(f"\n用户查询: '{query}'")
print("相关文档(按相似度排序):")
# 执行语义搜索
results = client.search(
collection_name='demo_embeddings',
data=[query], # 中文查询文本
anns_field='dense',
limit=2, # 返回前 2 个最相关文档
output_fields=['document'],
search_params={"metric_type": "COSINE", "params": {"nprobe": 10}}
)
# 处理并排序结果(按相似度降序)
for hits in results:
# 按相似度分数降序排序(默认已排序,此处确保稳定性)
sorted_hits = sorted(hits, key=lambda x: x['distance'], reverse=True)
for i, hit in enumerate(sorted_hits, 1):
entity = hit.get('entity', {})
document = entity.get('document', 'N/A')
# 相似度分数 ≥0.5 视为有效结果(可根据业务调整阈值)
if hit['distance'] >= 0.5:
print(f" {i}. {document} (相似度: {hit['distance']:.4f})")
else:
print(f" {i}. 无相关文档(相似度: {hit['distance']:.4f})")
# 运行文档检索系统
document_retrieval_system(client)8.2 产品推荐系统
def product_recommendation_system(client):
"""产品推荐系统示例(基于用户需求匹配,带业务逻辑注释)"""
# 模拟产品数据(包含产品关键属性,用于匹配用户需求)
products = [
{'id': 2001, 'document': '无线蓝牙降噪耳机,高保真音质,30小时续航,支持快充,适合通勤和运动'},
{'id': 2002, 'document': '智能手机,6.7英寸OLED屏幕,5G网络,256GB存储,5000mAh电池,拍照出色'},
{'id': 2003, 'document': '笔记本电脑,英特尔i7处理器,16GB内存,512GB SSD,轻薄设计,适合办公和编程'},
{'id': 2004, 'document': '智能手表,健康监测(心率、睡眠),GPS定位,防水设计,支持蓝牙通话'},
{'id': 2005, 'document': '平板电脑,10.9英寸视网膜屏幕,支持触控笔,续航10小时,适合学习和娱乐'}
]
# 插入产品数据到 Milvus
client.insert('demo_embeddings', products)
print("产品库初始化完成(共 5 款产品)")
# 用户需求匹配(自然语言描述需求)
user_needs = [
'想买一个音质好的无线耳机',
'需要一个大屏幕的移动设备',
'寻找性能强大的便携电脑'
]
print("\n=== 产品推荐系统 ===")
for need in user_needs:
print(f"\n用户需求: '{need}'")
print("推荐产品(按匹配度排序):")
# 执行需求匹配搜索
results = client.search(
collection_name='demo_embeddings',
data=[need], # 用户需求文本
anns_field='dense',
limit=2, # 推荐前 2 款产品
output_fields=['document'],
search_params={"metric_type": "COSINE", "params": {"nprobe": 10}}
)
# 处理推荐结果
for hits in results:
sorted_hits = sorted(hits, key=lambda x: x['distance'], reverse=True)
for i, hit in enumerate(sorted_hits, 1):
entity = hit.get('entity', {})
product = entity.get('document', 'N/A')
# 匹配度 ≥0.6 视为高相关(可根据业务调整)
match_level = "高" if hit['distance'] >= 0.6 else "中" if hit['distance'] >= 0.4 else "低"
print(f" {i}. {product} (匹配度: {hit['distance']:.4f} - {match_level}相关)")
# 运行产品推荐系统
product_recommendation_system(client)九、总结
9.1 核心优势总结
- 自动化处理:全程无需手动干预向量生成与存储,减少重复开发
- 简化开发:直接使用文本进行搜索,无需关注底层 API 调用和向量处理
- 统一管理:集中配置多个嵌入服务,支持按需切换,适配不同场景
- 灵活配置:支持凭证管理、维度优化、多字段嵌入等高级功能
- 性能优化:内置批量处理、自动索引等机制,提升数据处理和搜索效率
- 多场景支持:适用于文档检索、产品推荐、智能问答等多种业务场景
9.2 最佳实践
- 凭证管理:使用配置文件集中管理凭证,避免硬编码,定期轮换密钥确保安全
- 模型选型:根据场景选择模型(短文本用小型模型,长文本 / 高精度用大型模型)
- 字段设计:为不同类型的文本字段(如标题、内容)配置独立的嵌入函数,提升匹配精度
- 错误处理:实施空值检查、凭证验证、重试机制,确保系统稳定性
- 成本控制:通过维度优化、批量操作、选择高性价比模型(如 Ada)降低使用成本
- 质量监控:定期测试嵌入质量和搜索效果,根据业务反馈调整模型和参数
- 部署策略:容器化部署时使用环境变量注入凭证,生产环境配置重试和降级策略

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 17
17 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)