RGBT Tracking via All-layer Multimodal Interactions with Progressive Fusion Mamba
本文提出了一种新颖的全层多模态交互网络,名为AINet,它在渐进式融合Mamba中执行所有模态和层的高效特征交互,以实现鲁棒的RGBT跟踪。利用RGB和热模态之间的特征差异在一定程度上反映了它们的互补信息,设计了一种基于差异的融合Mamba(DFM)。为了解决计算量大,设计了一种顺序动态融合Mamba(OFM)。
基于渐进式融合Mamba的全层多模态交互的RGBT跟踪
一、AUTHOR AND DERIVE
Andong Lu∗, Wanyu Wang†, Chenglong Li†, Jin Tang∗ and Bin Luo∗ ∗School of Computer Science and Technology, Anhui University †School of Artificial Intelligence, Anhui University adlu ah@foxmail.com
二、INTRODUCATION
2.1 RGBT track的用途(RGBT track`s mean)RGBT tracking aims to leverage the complementary information of visible light (RGB) and thermal infrared (TIR) images to predict the location and size of an object.
2.2 目前RGBT track 缺陷(now existing drawback): Existing RGBT tracking methods often design various interaction models to perform cross-modal fusion of each layer, but can not execute the feature interactions among all layers。Most RGBT tracking studies can be broadly classified into two categories
2.2.1 One category involves building complex interaction modules [1], [6], [7] with powerful representation to achieve inter-modal interactions,as Fig1(a). Another category involves designing lightweight interaction modules and adopting the strategy of interacting between all corresponding layers to achieve intermodal interactions,as Fig1(b).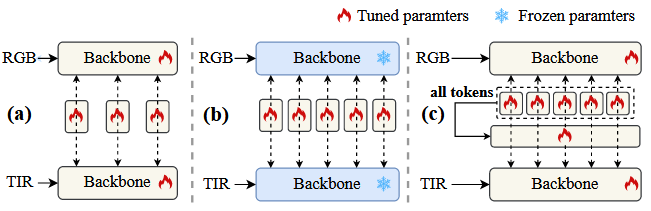
Fig. 1. Comparison with existing RGBT tracking methods. (a) Interactions between specific layers, with joint fine-tuning of the entire backbone. (b) Interactions between all corresponding layers, with the pre-trained backbone being frozen. (c) Interactions between all corresponding layers, and interactions among all layers, with joint fine-tuning with the backbone.
2.3 困难,待解决的问题(need to resolve problems):the first ,to build multimodal interactions in each layer due to struggling in balancing interaction capabilities and efficiency. Additionly,when interacting with features from all layers, a huge number of token sequences (3840 tokens in this work) are involved and the computational burden is thus large.
2.4 启发(inspary):First,features from different layers show significant complementarity: low-level features provide detailed texture information, while high-level features capture abstract and semantic content,Another,modality feature interaction aims to leverage the mutual enhancement and complementarity of two modalities, while complementary information reflected in their differences.
2.5 本文的创新点(This article innovation point):this paper presents a novel All-layer multimodal Interaction Network, named AINet,as shown in Fig. 1 (c),which performs efficient and effective feature interactions of all modalities and layers in a progressive fusion Mamba.
2.6 本文的主要工作(This article mian work): design a Difference-based Fusion Mamba (DFM) to achieve enhanced fusion of different modalities with linear complexity and an Order-dynamic Fusion Mamba (OFM) to execute efficient and effective feature interactions of all layers by dynamically adjusting the scan order of different layers in Mamba.
2.7本文的主要贡献(main contributions):
2.7.1: This article proposes a novel all-layer multimodal interaction network for RGBT tracking. It conducts multimodal interaction of each layer and all layer interaction in a progressive fusion Mamba.
2.7.2: This article design a difference-based fusion Mamba, which achieves inter-modal enhanced fusion by modelling intermodal differences to capture complementary information, and efficiently applies it to each layer.
2.7.3: This article design an order-dynamic fusion Mamba, which implements all-layer feature interaction with an input-aware dynamic scanning scheme to mitigate information forgetting of early input tokens.
三、RELATE WORK
3.1 RGBT tracking: The field of RGBT tracking has made significant progress.Most RGBT tracking studies can be broadly classified into two categories.One category involves late fusion, which takes place after the main feature extraction backbone.The second category involves modality interaction during the feature extraction phase. However existing methods are limited by computational costs and cannot utilize information from all layers
3.2 Vision State Space Model:State space models (SSMs) derived from classical control theory connects the input and output sequences through hidden states.Mamba has been widely applied in various fields due to its selective mechanism and efficient hardware acceleration design.
In this work, the article leverage Mamba for modality enhancement and all-layer fusion, exploring the potential of Mamba in RGBT tracking.
四、METHODOLOGY
4.1 AINet achieves multimodal interactions at each layer by the designing difference-based fusion Mamba, and it employs an order-dynamic fusion Mamba to establish all-layer interactions.Next, we first review the mamba, then introduce the overall architecture of AINet, and finally, we describe in detail the two fusion Mamba architectures.
4.2The state-space sequence model (状态空间序列模型-SSM) and Mamba are inspired by continuous linear systems. where a one-dimensional function or sequence, denoted as x(t) ∈ R, 通过隐藏状态 h(t) ∈ RN 映射到 x(t) ∈ R。这些模型可以用线性常微分方程 (ODE) 表示如下: 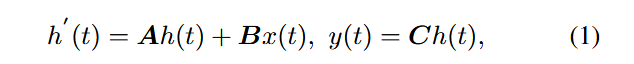
![]()

In this work, it extend the Mamba module to support all-layer multimodal interactions.
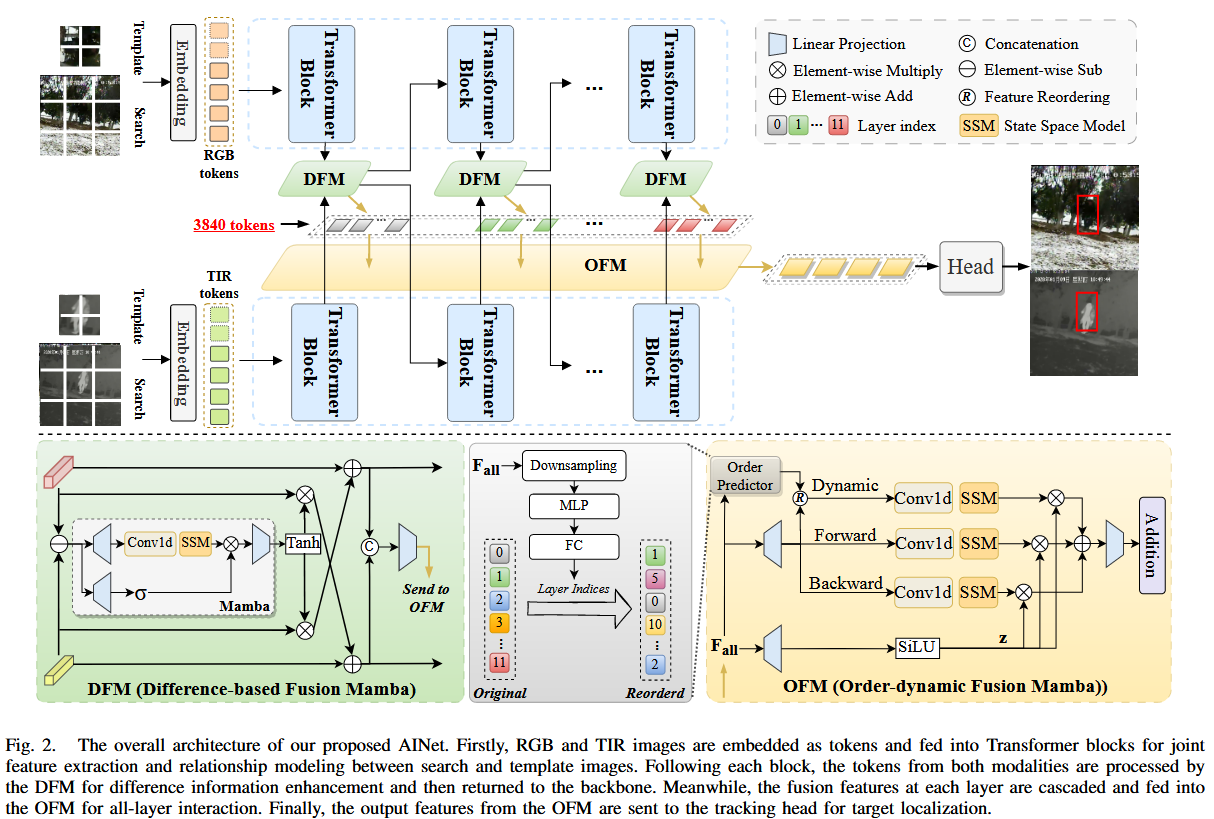
4.3 Overall Architecture: AINet incorporates a two-stream encoder structure, sharing the same parameters for both the RGB and TIR modalities.As shown in Fig. 2, AINet first processes the search and template frames of the given RGB and TIR modalities through the patch and position embedding layers, obtaining the initial token pairs for each modality. The search and template tokens from each modality are then concatenated along the token dimension to form RGB tokens xr 0gb and TIR tokens xtir 0 , which are fed into the ViT blocks for feature extraction and joint relationship modeling. Since the DFM is embedded in each layer to facilitate modality interactions, for the i-th layer block, it learns to integrate enhanced modality features from the output of the previous DFM, as described below.
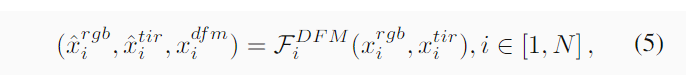

4.4 Difference-based Fusion Mamba (基于差异的融合Manba-DFM):Visible and thermal infrared modalities capture complementary object properties due to different imaging principles, which implies that the differences between modalities often contain complementary information. Thus, we design a difference-based fusion Mamba (DFM) with linear complexity, as depicted in Fig. 2 (b), which can be employed to model modality differences at each layer to enhance modal representation. To capture inter-modal differences and enrich feature learning, DFM employs the principles of differential amplifier circuits, which suppresses common-mode signals and amplifies differential ones.
将相同层的不同模态的特征相差,获得模态差异特征xdi,差异特征中有噪声也有有用的信息,因此xd i被馈送到Mamba以抑制噪声,同时增强有用的信息。接下来,经过激活函数处理的xd i与xr i gb和xtir i进行逐元素相乘,以获得每个模态的差异补偿特征。最后,这些补偿后的特征被加回到xr i gb和xtir i,以获得增强的特征xˆr i gb和xˆtir i。以下等式总结了这个过程:

4.5 Order-Dynamic Fusion Manba(顺序动态融合Mamba-OFM): No current method applies all feature layers to RGBT tracking,the article design an Order-dynamic Fusion Mamba (OFM) to efficiently and effectively interact with features from all layers by dynamically adjusting the scan order of different layers in Mamba.We first concatenate the output features xd ifm of each DFM layer along the token dimension to form a long token sequence Fall containing features from all layers. We then input Fall to the OFM and perform the following forward and backward scanning modeling process: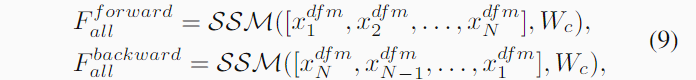
其中 Wc 代表一维卷积层,SSM 表示选择性扫描模型。然而,仅执行前向和后向扫描可能会忽略第一层和最后一层 token。因此,我们提出了一种顺序动态扫描方案,该方案允许扫描过程在任何层开始和结束。这种创新设计使 OFM 能够根据输入数据对不同层特征的重要性进行排序。
在顺序动态扫描建模中,Fall 首先被下采样 (D) 到指定的维度,然后被送入多层感知器 (MLP) 和全连接层 (FC),以预测覆盖所有层的扫描顺序的索引。该过程表达如10。然后,OFM按索引重新排列长token序列。因此,动态排序扫描建模可以表述如11。
![]()
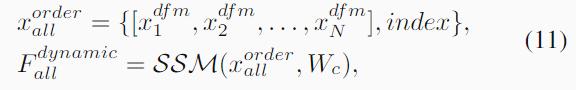
其中 {·, index} 表示根据给定索引排序的输入序列,而 xor allder 表示排序后的结果。接下来,Mamba 中一个简单的门控策略融合了三次扫描建模的结果。最后,所有层特征通过逐元素相加进行聚合,并输入到跟踪头中。
五、ECPERIMENT
5.1 Implenment Detail: We implement our AINet based on the PyTorch and use the AdamW [40] optimizer with a weight decay of 10−4, and set the batch size and learning rate to 16 and 10−4, respectively. The entire network is trained end-to-end over 15 epochs, with each epoch providing 6 × 104 pairs of samples. We use the LasHeR training set to train our network.
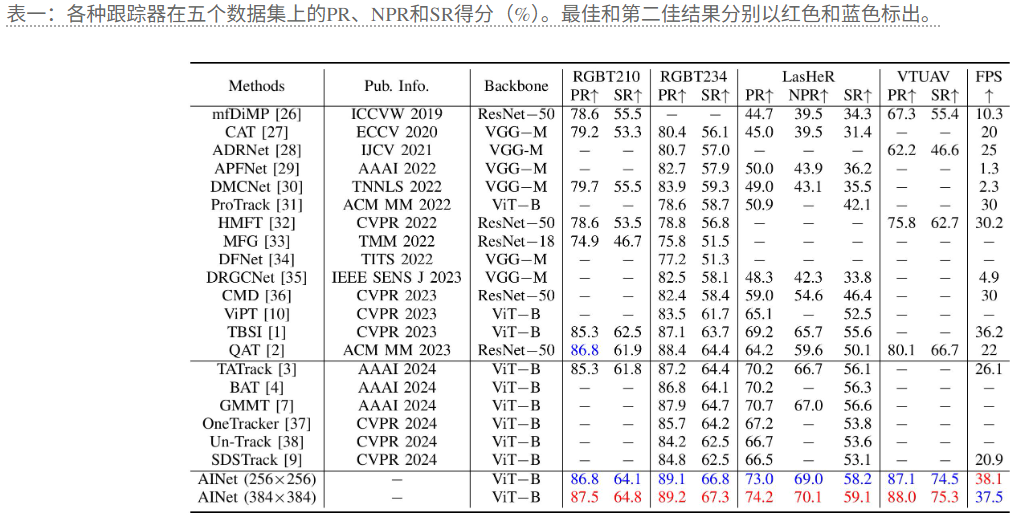
5.2 Adopt the Precision Rate (PR), Success Rate (SR), and Normalized Precision Rate (NPR) from OnePass Evaluation (OPE) as metrics for quantitative performance measurement and comparaion whis 20 state-of-theart RGBT trackers.
5.3 Comparasion:与最强大的跟踪器GMMT相比,本文方法在PR/NPR/SR方面分别提高了3.5%/3.1%/2.5%。与统一框架OneTracker、Un-Track和SDSTrack相比,本文在PR/SR方面分别实现了7.0%/5.3%、7.5%/5.5%和7.7%/6.0%的性能提升。
5.4 Ablation Study:Baseline denotes the removal of DFM and OFM modules from our method, while maintaining consistent training data and losses.w/ DFM indicates that each layer in the Baseline backbone network is equipped with a DFM module, achieving improvements of 1%/0.8%/0.5% in PR/NPR/SR, respectively. This experiment shows that difference-based fusion Mamba is effective.w/ OFM denotes that each layer in the Baseline backbone network uses simple feature addition to obtain fused features and is equipped with our proposed OFM module, achieving improvements of 1.1%/0.5%/0.4% in PR/NPR/SR, respectively.This experiment shows that order-dynamic fusion Mamba is effective.
liu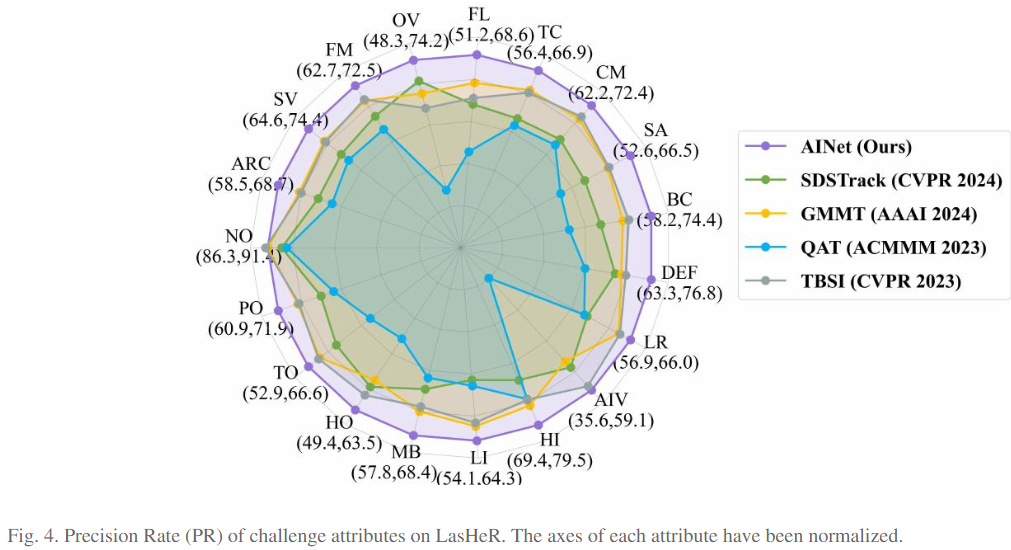
六、CONDUCTION
本文首次探索了 Mamba 在 RGBT 跟踪中的潜力,设计了一种新颖的全层交互网络 (AINet),该网络有效地整合了所有层的信息,实现了稳健的跟踪性能。AINet 的核心概念是引入 Mamba 的渐进式融合,以实现高效且有效的全层模态交互。具体来说,AINet 设计了一种基于差异的融合 Mamba,通过对模态差异进行建模,增强了骨干网络每一层的模态交互。此外,还设计了一种有序动态融合 Mamba,用于执行跨所有层特征的交互,从而降低了早期令牌信息丢失的风险。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)