打造推理模型的4种方法——李宏毅2025大模型课程第7讲
本节课系统地介绍了如何让大语言模型(LLM)具备“推理”能力,介绍了打造推理模型的4种流派,并介绍了集4种技术流派大成的deepseek R1。最后提出了推理模型的挑战在于:推理过程冗长、效率低和成本高
本节课系统地介绍了如何让大语言模型(LLM)具备“推理”能力,介绍了打造推理模型的4种流派,并介绍了集4种技术流派大成的deepseek R1。最后提出了推理模型的挑战在于:推理过程冗长、效率低和成本高。

一、什么是“深度思考”的语言模型、什么是推理?
-
ChatGPT o 系列、DeepSeek-R1、Gemini 2 Flash Thinking、Claude 3.7 Sonnet 是普通用户可直接体验的“深度思考”模型。
-
什么是推理:模型在回答前会展示一个可折叠的思考过程(如
[thinking]...[/thinking]),这个过程叫做“推理”(reasoning),包含探索、验证、规划等步骤。 -
例子:面对“1+1=?”这样的问题,模型会思考“是不是陷阱?二进制里1+1=10”,但最终判断用户只是问基础数学,回答“2”。
-
本质:这是一种测试时间计算(Testing-Time Compute)行为,即在推理阶段投入更多算力,以换取更高质量答案。[1]
二、为什么“推理”有效?
-
核心理念:“深度不够,长度来凑” —— 模型通过生成更长的思考链,模拟更深层的计算。
-
类比 AlphaGo:不是直接落棋子,而是每次落子前,通过蒙特卡洛树搜索(MCTS)模拟不同位置的未来走法,选择最优解。
-
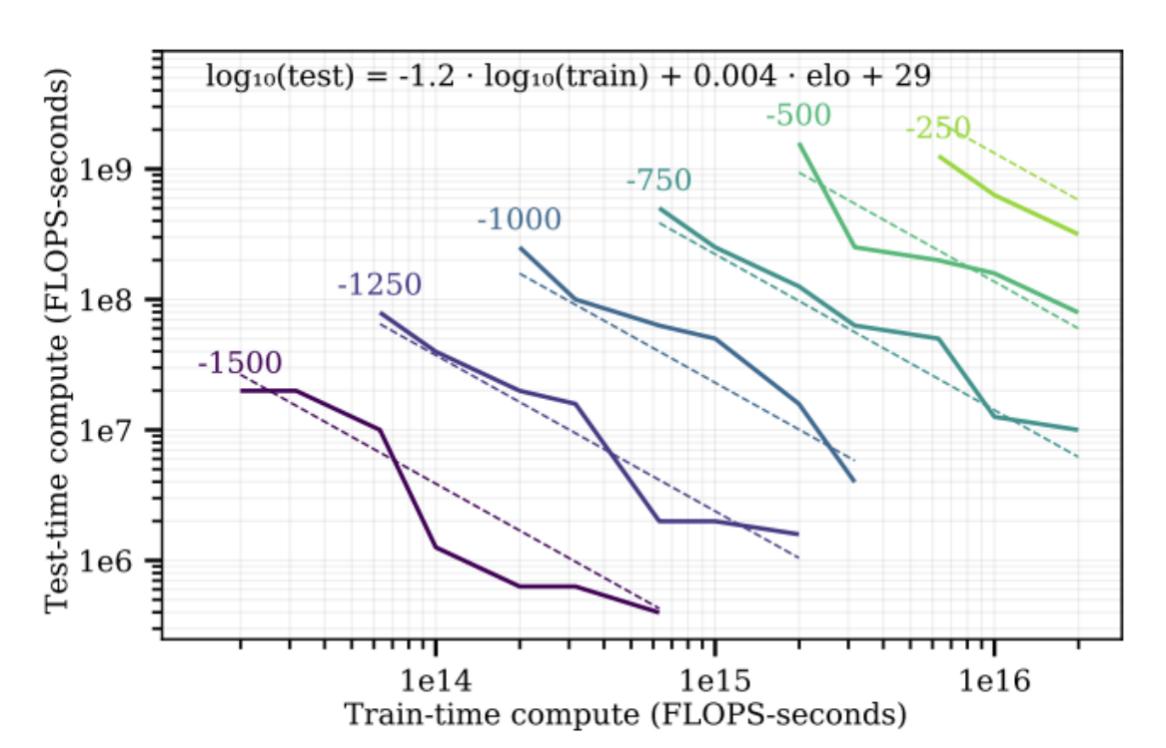
测试时间缩放(Test-Time Scaling):思考越多,答案通常越好。如下图,每跟线是一样的效果。横轴是增加训练的时间,纵轴是增加test-Time Scaling,可以看到,在小一点的train-time compute中,如果增加test-time compute,也能达到一样的效果[2]
三、打造「推理」語言模型的4种方法
| 流派 | 是否需微调 | 方法简介 | 举例/技术 |
|---|---|---|---|
| 1. 高级提示工程 | ❌ | 用复杂Prompt引导模型逐步思考 | 长链式思考(Long CoT)、Supervised CoT |
| 2. 构建推理工作流 | ❌ | 多次生成答案 + 筛选最优 | Self-consistency、Best-of-N、Beam Search、MCTS |
| 3. 模仿学习 | ✅ | 用高质量推理过程微调模型 | 教师模型生成推理数据 → 学生模型学习 |
| 4. 强化学习(RL) | ✅ | 只看答案对错,训练模型自己探索推理 | DeepSeek-R1、Aha Moment 自发涌现 |
四、关键技术详解
1. 高级提示工程 之 链式思考(Chain-of-Thought, CoT)
-
Short CoT:简单提示“Let’s think step by step”
-
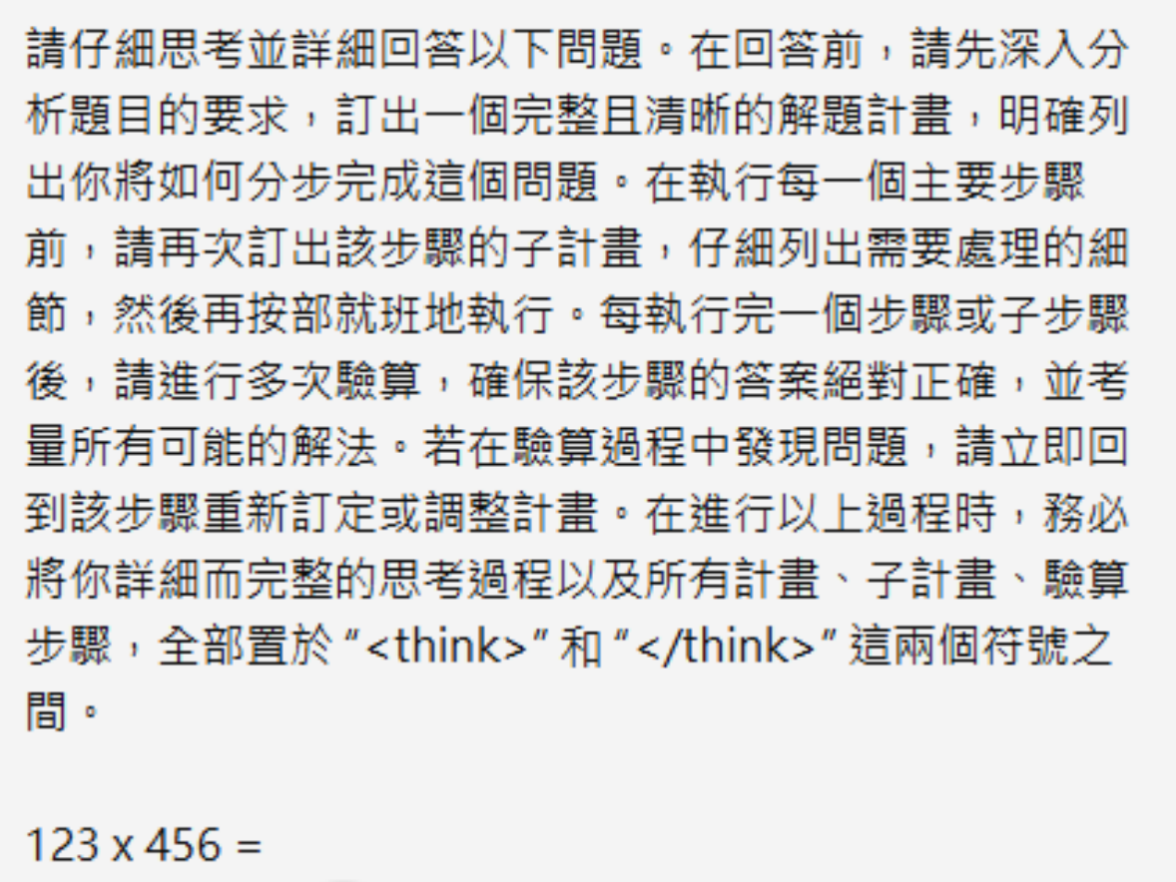
Long CoT:模型生成详细、结构化的思考过程(如规划、验算、反思),例子见下方截图[3]
-
不是所有模型都有能力根据复杂指令做 Long CoT
2. 构建推理工作流——多次采样与筛选(Generate + Select)
生成多个答案 → 用以下方法选最佳:
-
多数投票(Self-consistency)
-
验证器打分(Verifier / Best-of-N)
-
过程级验证 + Beam Search:每步都验证,保留最优路径
3.模仿学习(imitation learning),
- 人类教模型学习推理过程,那推理过程哪里来呢?
- 监督式思维链:使用标注的推理过程训练模型。这是一种非常昂贵的方式,标注高质量的推理过程很耗费人力,可以让模型自己多次生成推理过程,从正确答案往回找,确认哪些推理步骤是正确的,再用这些推理过程拿来训练。
- Math-Shepherd:无需人工标注,自动验证与强化推理步骤。
- rStar-Math:生成并验证每一步推理过程。
- 知识蒸馏:从大模型压缩知识到小模型。
4.强化学习:结果导向
-
只奖励最终答案正确与否,过程不重要
-
模型自发学会自我纠错、反思、验证(Aha Moment)
-
缺点:推理过程可读性差、语言混杂 → 需后续模仿学习优化
五、典型案例:DeepSeek-R1 系列
deepseek-R1则是以上4种技术的集大成
| 阶段 | 方法 | 说明 |
|---|---|---|
| R1-Zero | 纯RL | 只以答案正确为奖励,推理过程自发涌现 |
| R1 | RL + 模仿学习 | 用R1-Zero生成数据 → 人工筛选 → 微调 → 再RL优化 |
| 蒸馏版 | 模仿学习 | 用R1生成的数据教小模型(如Qwen-32B),效果优于直接RL |
六、挑战与未来方向
1.当前问题
-
推理过程冗长:模型会反复验算已正确的答案,浪费算力
-
成本高:长推理链消耗大量Token与计算资源
-
效率低:模型不会判断“是否需要深度思考”
2.未来方向
-
自适应推理:简单题快速答,难题才深度思考
-
高效搜索算法:更快找到最优推理路径
-
推理剪枝:减少无意义的重复验证
七、总结一句话
推理模型的核心不是“变聪明”,而是“愿意多想几步”
通过测试时间计算,我们让模型模拟更深层的思考过程,
而RL + 模仿学习 + 工作流的融合,正是打造下一代“会思考”的AI的关键路径。
参考文章
[1] Alphago https://www.nature.com/articles/nature16961
[2]Scaling Scaling Laws with Board Games https://arxiv.org/abs/2104.03113
[3]Long CoT https://arxiv.org/abs/2503.09567

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)