解锁 LLM 智力潜能,使用RAG + 多工具,打造你的智能工作流!
RAG 通常涉及定义诸如网络搜索或数据库查找之类的函数调用工具,并通过 API(例如 Responses API 或 OpenAI API)的方式进行编排。
多工具编排结合检索增强生成 (RAG) 的核心在于构建智能工作流程。这些流程让大型语言模型 (LLM) 能够与各种工具(如网络搜索引擎或向量数据库)协同工作,从而高效响应用户查询。通过这种动态协作,LLM 能根据每个查询请求智能地选择最合适的工具。例如,使用网络搜索工具可以提供最新的实时信息,而像 Pinecone 这样的向量数据库则能针对特定上下文提供详细资料。
在实践中,RAG 通常涉及定义诸如网络搜索或数据库查找之类的函数调用工具,并通过 API(例如 Responses API 或 OpenAI API)的方式进行编排。通过这种方法为每个用户查询启动了一系列检索和生成步骤,从而将模型的强大能力与最新、相关的外部信息紧密结合。
什么是 RAG?
RAG(检索增强生成) 是一种让语言模型能够检索并整合外部相关信息到其输出中的过程。与仅依赖内部训练数据的“闭卷”模型不同,RAG 模型会执行一个明确的检索步骤。它会搜索一系列文档,比如向量数据库或搜索索引,并利用这些检索到的文档来增强 LLM 的提示。
这样做的目的是为了 LLM 能够从外部知识中获取信息,从而提供对查询的准确响应。因此,我们可以将此过程视为一种实时“增强”生成。LLM 在提问时,通过结合自身的生成能力和经检索增强的信息,能够提供具有上下文相关性、准确性的答案。这使得 LLM 能够回答那些在训练时无法获得的最新、特定领域或专有知识问题。
RAG 的核心优势:
- 最新且特定领域的知识: RAG 允许模型访问动态更新的数据,例如实时新闻或企业内部文档,以回答用户查询。
- 降低“幻觉”率: RAG 能有效减少模型产生不准确或虚构信息的现象,因为它基于实际检索到的事实来生成答案。
- 可验证性: 答案可以引用或显示其信息来源,这大大增加了答案的透明度和可信赖性。
简而言之,RAG 使得 LLM 能够将生成能力与知识检索能力相结合。在这种方法中,模型在给出答案之前,会从外部语料库中检索相关的片段信息,然后利用这些上下文生成更精确、更全面的响应。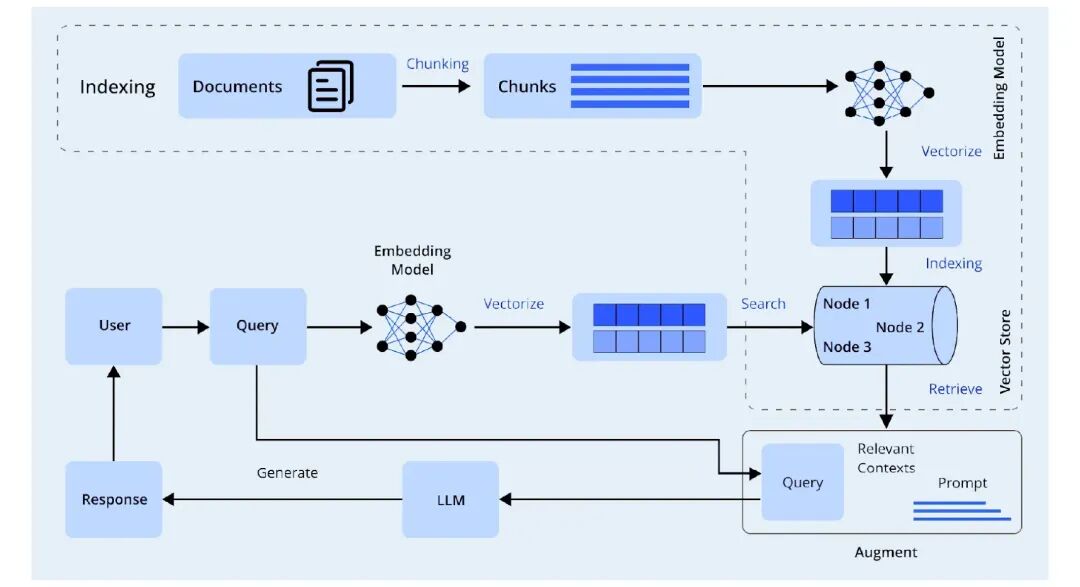
为何 RAG 需要工具?
网络搜索和向量索引查询等工具对 RAG 至关重要,因为它们提供了 LLM 自身无法提供的检索组件。当这些工具被整合进来后,RAG 可以有效解决仅依赖 LLM 服务所面临的问题。例如,LLM 往往存在知识截止期,可能会自信地给出不正确或过时的信息。而搜索工具允许系统自动获取按需更新的事实信息。同样,像 Pinecone 这样的向量数据库则能存储 LLM 本身无法得知的特定领域和专有数据,例如医疗记录或公司政策。
每个工具都有其独特的优势,而将多个工具协同使用便构成了多工具编排。例如,通用网络搜索工具适合回答高层次的概括性问题。而像 PineconeSearchDocuments 这样的工具,则能在包含专有信息集的内部向量存储中,找到高度相关的特定数据。它们共同确保了模型所给出的答案能够追溯到其最佳质量的来源。通用性问题可以通过功能齐全的内置工具(如网络搜索)处理。而“非常具体”或需要利用系统内部知识的医疗问题,则通过从向量数据库检索上下文来解决。总体而言,在 RAG 管道中使用多工具,显著提升了数据的有效性、正确性、准确性以及实时上下文。
构建基于 RAG 的多工具编排系统
现在,我们将通过一个实际案例,演示如何使用医疗问答数据集构建一个多工具 RAG 系统。该过程将包括将问答数据集嵌入到 Pinecone 中,并构建一个拥有网络搜索工具和基于 Pinecone 的搜索工具的系统。以下是该过程的关键步骤和代码示例。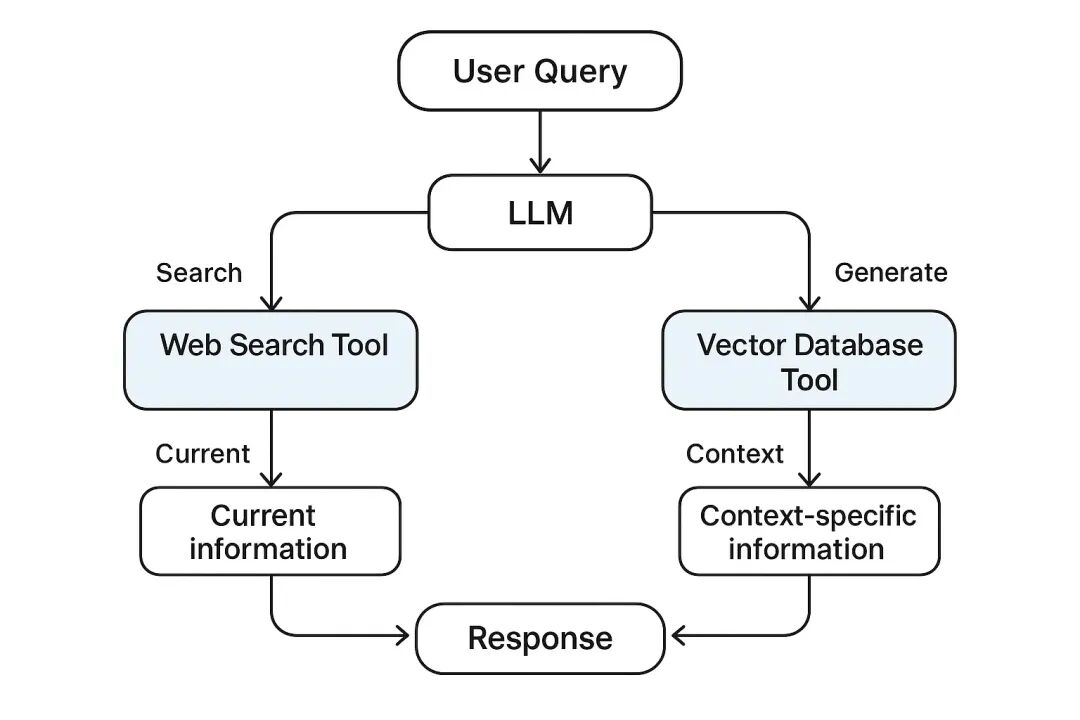
加载依赖项与数据集
首先,我们将安装并导入必要的库,最后下载所需的数据集。这要求您对数据处理、嵌入和 Pinecone SDK 有基本的了解。例如:
import os, time, random, stringimport pandas as pdfrom tqdm.auto import tqdmfrom sentence_transformers import SentenceTransformerfrom pinecone import Pinecone, ServerlessSpecimport openaifrom openai import OpenAIimport kagglehub
接下来,我们将下载并加载一个包含医疗问答关系的数据集。在示例代码中,我们使用 kagglehub 工具来访问一个专注于医疗领域的问答数据集:
path = kagglehub.dataset_download("thedevastator/comprehensive-medical-q-a-dataset")DATASET_PATH = path # 本地下载文件的路径df = pd.read_csv(f"{DATASET_PATH}/train.csv")
为方便本示例演示,我们将数据集截取前 2500 行。随后,我们会在“Question”和“Answer”列前分别添加“Question:”和“Answer:”前缀,并将这两列内容合并为一个文本字符串。这个合并后的字符串将是我们用于生成嵌入的上下文。
df = df[:2500]df['Question'] = 'Question: ' + df['Question']df['Answer'] = ' Answer: ' + df['Answer']df['merged_text'] = df['Question'] + df['Answer']
合并后的文本行示例如下: “Question: [医疗问题] Answer: [答案]”
例如:
Question: Who is at risk for Lymphocytic Choriomeningitis (LCM)?Answer: LCMV infections can occur after exposure to fresh urine, droppings, saliva, or nesting materials from infected rodents. Transmission may also occur when these materials are directly introduced into broken skin, the nose, the eyes, or the mouth, or presumably, via the bite of an infected rodent. Person-to-person transmission has not been reported, except vertical transmission from infected mother to fetus, and rarely, through organ transplantation.
基于数据集创建 Pinecone 索引
数据集加载完毕后,我们将为每个合并后的问答字符串生成向量嵌入。我们将使用句子-转换器模型 “BAAI/bge-small-en” 来编码这些文本:
MODEL = SentenceTransformer("BAAI/bge-small-en")embeddings = MODEL.encode(df['merged_text'].tolist(), show_progress_bar=True)df['embedding'] = list(embeddings)
我们将从单个样本 len(embeddings[0]) 中获取嵌入维度,本例中为 384。随后,我们将使用 Pinecone Python 客户端创建一个新的 Pinecone 索引并指定其维度:
def upsert_to_pinecone(df, embed_dim, model, api_key, region="us-east-1", batch_size=32): # 初始化 Pinecone 并创建索引(如果不存在) pinecone = Pinecone(api_key=api_key) spec = ServerlessSpec(cloud="aws", region=region) index_name = 'pinecone-index-' + ''.join(random.choices(string.ascii_lowercase + string.digits, k=10)) if index_name notin pinecone.list_indexes().names(): pinecone.create_index( index_name=index_name, dimension=embed_dim, metric='dotproduct', spec=spec ) # 连接到索引 index = pinecone.Index(index_name) time.sleep(2) # 等待索引初始化完成 print("Index stats:", index.describe_index_stats()) # 批量上传数据 for i in tqdm(range(0, len(df), batch_size), desc="Upserting to Pinecone"): i_end = min(i + batch_size, len(df)) # 准备输入和元数据 lines_batch = df['merged_text'].iloc[i:i_end].tolist() ids_batch = [str(n) for n in range(i, i_end)] embeds = model.encode(lines_batch, show_progress_bar=False, convert_to_numpy=True) meta = [ { "Question": record.get("Question", ""), "Answer": record.get("Response", "") } for record in df.iloc[i:i_end].to_dict("records") ] # 上传到索引 vectors = list(zip(ids_batch, embeds, meta)) index.upsert(vectors=vectors) print(f"Upsert complete. Index name: {index_name}") return index_name
这段代码实现了将我们的数据摄取到 Pinecone 的过程;在 RAG 术语中,这相当于将外部的权威知识加载到向量存储中。一旦索引创建完成,我们会将所有生成的嵌入与它们的元数据(即原始问题和答案文本,用于后续检索)批量上传:
index_name = upsert_to_pinecone( df=df, embed_dim=384, model=MODEL, api_key="your-pinecone-api-key")
至此,每个向量都已与其对应的文本和元数据一同存储,Pinecone 索引也已成功填充了我们的特定领域数据集。
查询 Pinecone 索引
为了能够使用这个索引,我们定义了一个函数,通过传入一个新的问题来查询索引。这个函数会嵌入查询文本,然后调用 index.query 来返回最相似的前 k 个文档:
def query_pinecone_index(index, model, query_text): query_embedding = model.encode(query_text, convert_to_numpy=True).tolist() res = index.query(vector=query_embedding, top_k=5, include_metadata=True) print("--- 查询结果 ---") for match in res['matches']: question = match['metadata'].get("Question", 'N/A') answer = match['metadata'].get("Answer", "N/A") print(f"{match['score']:.2f}: {question} - {answer}") return res
例如,如果我们调用 query_pinecone_index(index, MODEL, "What is the most common treatment for diabetes?"),我们将看到数据集中最匹配的问答对被打印出来。这便是检索过程:用户查询被嵌入,然后通过索引查找,并返回最相关的文档(及其元数据)。一旦这些上下文被检索到,我们就可以利用它们来帮助构建最终的答案。
编排多工具调用
接下来,我们将定义模型可以使用的工具。在这个管道中,我们定义了两个核心工具:
- 网络搜索预览工具: 用于从开放互联网进行通用事实的网络搜索。
- PineconeSearchDocuments 工具: 用于对我们的 Pinecone 索引执行语义搜索。
每个工具都以 JSON 对象的形式定义,包含其名称、描述和预期参数。例如:
步骤 1:定义网络搜索工具这个工具赋予代理执行网络搜索的能力,只需输入自然语言请求即可。它包含可选的位置元数据,这有助于提高搜索结果与用户所在地区的具体相关性(例如,特定地区的新闻或服务)。
web_search_tool = { "type": "function", "name": "web_search_preview", "function": { "name": "web_search_preview", "description": "Perform a web search for general queries.", "parameters": { "type": "object", "properties": { "query": { "type": "string", "description": "The search query string" }, "user_location": { "type": "object", "properties": { "country": {"type": "string", "default": "IN"}, "region": {"type": "string", "default": "Delhi"}, "city": {"type": "string", "default": "New Delhi"} } } }, "required": ["query"] } }}
因此,当代理需要获取最新信息或其训练数据中未包含的信息时,就会调用此工具。
步骤 2:定义 Pinecone 搜索工具这个工具使代理能够对向量数据库(如 Pinecone)执行语义搜索,RAG 系统因此可以利用向量之间的点积和角度语义来查找相关文档。该工具接受一个查询,并根据向量嵌入返回最相似的文档。
pinecone_tool = { "type": "function", "name": "PineconeSearchDocuments", "function": { "name": "PineconeSearchDocuments", "description": "Search for relevant documents based on the user’s question in the vector database.", "parameters": { "type": "object", "properties": { "query": { "type": "string", "description": "The question to search in the vector database." }, "top_k": { "type": "integer", "description": "Number of top results to return.", "default": 3 } }, "required": ["query"], "additionalProperties": False } }}
当代理需要从包含嵌入上下文的文档中检索特定信息时,此工具便会派上用场。
步骤 3:组合工具现在,我们将这两个工具组合成一个列表,并将其传递给代理:
tools = [web_search_tool, pinecone_tool]
每个工具都包含了其调用时所需参数的定义。例如,Pinecone 搜索工具需要一个自然语言查询字符串,该工具将在内部从我们的索引中返回前 K 个匹配文档。
除了工具之外,我们还将包含一组待处理的用户查询。对于每个查询,模型将自行决定是调用工具还是直接给出响应。例如:
queries = [ {"query": "Who won the cricket world cup in 1983?"}, {"query": "What is the most common cause of death in India?"}, {"query": "A 7-year-old boy with sickle cell disease has knee and hip pain... What is the next step in management according to our internal knowledge base?"}]
多工具编排流程详解
最后,我们执行对话流,其中模型将主动控制工具的使用。我们为模型提供一个**系统提示 (system prompt)**,指示它按特定顺序使用工具。在此示例中,我们的提示告诉模型:“当收到问题时,首先调用网络搜索工具获取结果,然后调用 PineconeSearchDocuments 在内部知识库中查找相关示例。”
system_prompt = ( "Every time it's prompted with a question, first call the web search tool for results, " "then call `PineconeSearchDocuments` to find relevant examples in the internal knowledge base.")
我们收集消息,并为每个用户查询启用工具后调用 Responses API:
for item in queries: input_messages = [ {"role": "system", "content": system_prompt}, {"role": "user", "content": item["query"]} ] response = openai.responses.create( model="gpt-4o-mini", input=input_messages, tools=tools, parallel_tool_calls=True )
输出:
API 会返回一个助手消息,其中可能包含或不包含工具调用。我们检查 response.output 以查看模型是否调用了任何工具;如果调用了,我们就执行这些调用,并将结果包含在对话中。例如,如果模型调用了 PineconeSearchDocuments,我们的代码会在内部运行 query_pinecone_index(index, MODEL, query),获取文档答案,并返回一个包含此信息的工具响应消息。最后,我们将更新后的对话发送回模型以获取最终响应。
上述流程清晰地展示了多工具编排的工作原理:模型根据查询动态选择并调用工具。正如示例所示,对于像“什么是哮喘?”这样的通用问题,它可能会使用网络搜索工具;而对于与“哮喘”更具体相关的、需要深层上下文的问题,它则会利用 Pinecone 中的知识来构建答案。
我们会从代码循环中进行多次工具调用,并在所有调用完成后,再次调用 API,让模型根据其收到的提示来构建“最终”答案。总体而言,我们期望接收到一个既结合了来自网络知识的外部事实,又考虑了内部知识文档上下文的综合性答案,这一切都基于我们预设的指令。
您可以点击下面的链接查看完整的代码示例:https://drive.google.com/file/d/1oAWjf1TmP3ZE5LpF6_DZUp4ouhV5q2ip/view
总结
多工具编排结合 RAG 能够构建一个功能强大且极具灵活性的问答系统。通过将模型的生成能力与检索工具相结合,我们能够同时利用模型的自然语言理解能力和外部数据集的事实准确性。在我们的用例中,我们建立了一个以 Pinecone 向量索引为基础的医疗问答系统,并赋予模型调用网络搜索或该索引的能力。通过使用这种方式,我们的模型能够更牢固地基于实际数据提供事实依据,并回答此前无法解决的问题。
在实践中,这种 RAG 管道能够显著提高答案的准确性和相关性,因为它能引用最新来源、覆盖小众知识并最大限度地减少“幻觉”。未来的迭代可能会包含更高级的检索方案或生态系统内的其他工具,例如与知识图谱或 API 的协作,但其核心功能无需改变。
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:
- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献378条内容
已为社区贡献378条内容

所有评论(0)