操作符详解
int age;int high;char id;}s4,s5,s6;//s4,s5,s6是结构变量(全局的)//全局的int main()struct Student s1 = { "张三",20,108,75.5f,"0000000001" };//初始化struct Student s2 = { .age = 30,.name = "李四",.weight = 80.5f,.high = 1
一、操作符的分类

二、二进制和进制转换
其实在学习中,我们经常能听到2进制、8进制、16进制这样的说法,那是什么意思呢?
其实,2进制、8进制、16进制是数值的不同表示形式而已。
比如,数值15的各种进制的表示形式:
15的2进制:1111
15的8进制:17
15的10进制:15
15的16进制:F
特别的:
16进制的数值之前写:0x
8进制的数值之前写:0我们重点讲解一下二进制:
首先我们还是得从十进制引入,在十进制中:
1.10进制中满10进1;
2.10进制的数字每一位都是0~9的数字组成。
其实,二进制也是一样的:
1. 2进制中满2进1;
2. 2进制的数字每一位都是0~1的数字组成。
(一)2进制转10进制
其实10进制的123表示的值是一百二十三,为什么是这个值呢?
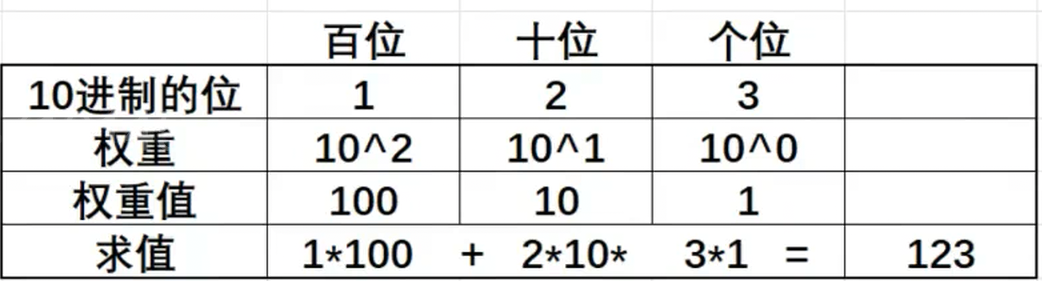
由上图我们可以清晰地知道,10进制中的每一位都是有权重的,这也就是123为什么代表一百二十三的原因。
那么2进制数字我们该怎么理解呢?

由上图我们可以清晰地看出,2进制的算数原理以及2进制如何转换为10进制。由这一原理,我们可以知道8进制、16进制是如何转为10进制的。
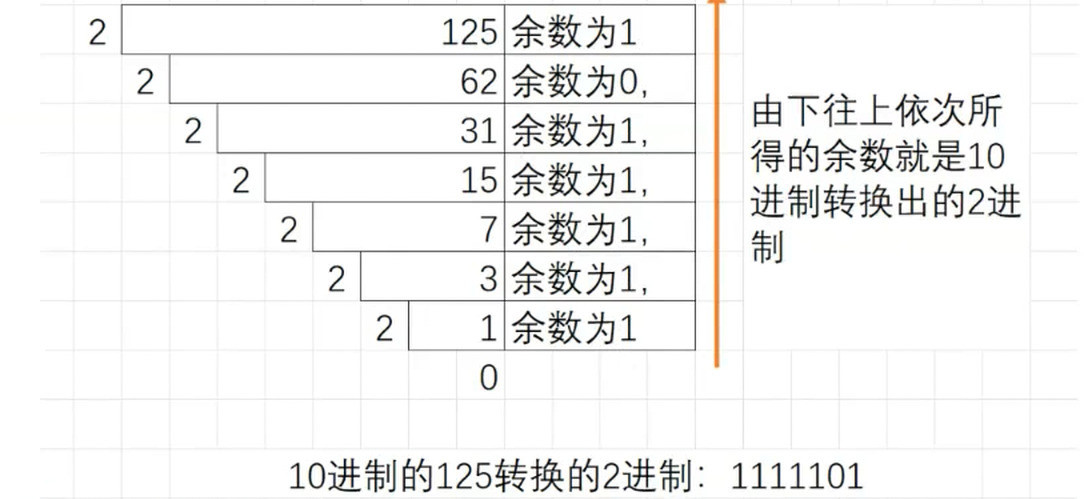
(二)10进制转2进制
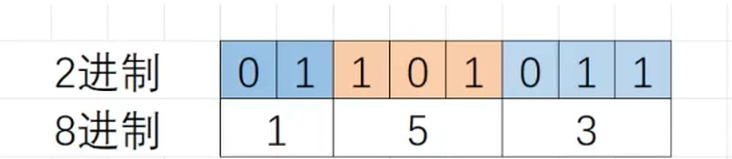
(三)2进制转8进制
8进制的数字每一位是0~7的,0~7的数字各自写成2进制,最多有3个2进制位就足够了,比如7的2进制位是111,。所以,在2进制转8进制的时候,从2进制序列最右边低位开始向左每3个2进制位会换算一个8进制位,剩余不够3个2进制位的直接换算。
(四)2进制转16进制
16进制的数字每一位是0~9,A~F(代表10~15)的,各自写成2进制,最多有4个2进制就足够了。比如F的2进制是1111,所以在2进制转16进制的时候,从2进制序列最右边低位开始向左每4个2进制位会换算一个16进制位,剩余不够4个2进制位的直接换算。

至于10进制如何转为16进制等问题,我们则可以通过上述的方法联合转换。
三、原码、反码、补码
整数的2进制表示方法有三种,即原码、反码和补码。
有符号的整数的三种表示方法均有符号位和数值位两部分,2进制序列中,最高位的1位是被当做符号位,剩余的都是数值位。
符号位都是用0表示“正”,用1表示“负”。
正整数的原码、反码、补码都相同。
负整数的三种表示方法各不相同:
原码:直接将数值按照正负数的形式翻译成二进制得到的就是原码;
反码:将原码的符号位不变,其他位依次按位取反(0变1,1变0)就可以得到反码;
补码:反码+1就能得到补码。
补码得到原码有两种操作方式(主要用第一种):
1.补码取反,然后+1;
2.补码-1,然后取反。
对于整形来说,数据存放内存中其实存放的是补码,为什么呢?
在计算机系统中,数值一律用补码来表示和存储。因为,使用补码,可以使符号位和数值域统一处理;同时,加法和减法也可以统一处理(CPU只有加法器)。此外,补码与原码相互转换,其运算方式过程是相通的,不需要额外的硬件电路。
我们来举一些例子:
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
int main()
{
int a = -10;
//-10是存放在a中,因为a是整型变量,是4个字节
//所以占据32个比特位
//10000000000000000000000000001010-原码
//11111111111111111111111111110101-反码
//11111111111111111111111111110110-补码
int b = 10;
//00000000000000000000000000001010-原码
//00000000000000000000000000001010-反码
//00000000000000000000000000001010-补码
return 0;
}四、移位操作符
<<左移操作符
>>右移操作符
注意:移位操作符的操作数只能是整数。
(一)左移操作符
移位规则:左边抛弃,右边补0。

int main()
{
int num = 10;
int n = num << 1;
//10的原码: 00000000000000000000000000001010
//10的反码: 00000000000000000000000000001010
//10的补码: 00000000000000000000000000001010
//对补码进行移位操作:
//移位完后: 00000000000000000000000000010100
//因为输出的是原码代表的值,所以要计算原码;
//移位完后的补码多对应的原码是:
// 00000000000000000000000000010100
printf("%d\n", n);
printf("%d\n", num);
return 0;
}
int main()
{
int num = -10;
int n = num << 1;
//-10的原码: 10000000000000000000000000001010
//-10的反码: 11111111111111111111111111110101
//-10的补码: 11111111 11111111 11111111 11110110
//对补码进行移位操作:
//移位完后: 11111111 11111111 11111111 11101100
//因为输出的是原码代表的值,所以要计算原码;
//移位完后的补码多对应的原码是:
// 10000000 00000000 00000000 00010100
printf("%d\n", n);
printf("%d\n", num);
return 0;
}
这里,我们可以看出,移位操作符对于变量本身的值并没有做出改变。
(二)右移操作符
移位规则:右移操作符的运算规则分为两种
1.逻辑右移:左边用0填充,右边丢弃;

2.算术右移:左边用原该值的符号填充,右边丢弃。

int main()
{
int num = -10;
int n = num >> 1;
printf("%d\n", n);
printf("%d\n", num);
return 0;
}
五、位操作符:&、|、^、~
(一)&(按位与)
&的运算规则:有0得0,全1为1。
int main()
{
int a = 3;
int b = -5;
int c = a & b;
//3的补码:00000000000000000000000000000011
// -5的原码:10000000000000000000000000000101
// -5的反码:11111111111111111111111111111010
// -5的补码:11111111111111111111111111111011
//&操作规则:有0得0,全1为1
//3的补码:00000000000000000000000000000011
// -5的补码:11111111111111111111111111111011
//c代表的数字的补码:
// 0000000000000000000000000000011
// 转换为原码:
// 0000000000000000000000000000011(注意正负数)
printf("%d", c);
return 0;
}![]()
(二)|(按位或)
| 运算规则:有1得1,全0为0。
int main()
{
int a = 3;
int b = -5;
int c = a | b;
// // 3的补码:00000000000000000000000000000011
// // -5的原码:10000000000000000000000000000101
// // -5的反码:11111111111111111111111111111010
// // -5的补码:11111111111111111111111111111011
/*| 操作规则:有1得1,全0为0*/
// //3的补码: 00000000000000000000000000000011
// // -5的补码:11111111111111111111111111111011
// //c代表的数字的补码:
// // 11111111111111111111111111111011
// // 转换为原码:
// // 10000000000000000000000000000101(注意正负数)
printf("%d", c);
return 0;
}![]()
(三)^(按位异或)
^ 运算规则:相同为0,相异位1
int main()
{
int a = 3;
int b = -5;
int c = a ^ b;
//3的补码:00000000000000000000000000000011
// - 5的原码:10000000000000000000000000000101
// - 5的反码:11111111111111111111111111111010
// - 5的补码:11111111111111111111111111111011
// ^ 操作规则:相同为0,相异位1
// 3的补码:00000000000000000000000000000011
// - 5的补码:11111111111111111111111111111011
// c代表的数字的补码:
// 11111111111111111111111111111000
// 转换为原码:
// 10000000000000000000000000001000(注意正负数)
printf("%d", c);
return 0;
}![]()
(四)~(按位取反)
~运算规则:0变1,1变0
//~ 按位取反
//~ 操作规则:0变1,1变0
int main()
{
int a = 0;
int b = ~a;
//a的补码:00000000000000000000000000000000
//b的补码:11111111111111111111111111111111
//b的原码:10000000000000000000000000000001
printf("%d", b);
return 0;
}![]()
(五)例题1
一道变态的面试题目:不能创建临时变量(即第三个变量),实现两个数的交换。
方法一(创建了第三个变量):
int main()
{
int a = 3;
int b = 5;
int c = 0;
c = a;
a = b;
b = c;
printf("%d\n%d",a,b);
return 0;
}
方法二:
int main()
{
int a = 3;
int b = 5;
a = a + b;
b = a - b;
a = a - b;
printf("%d\n%d", a, b);
return 0;
}
方法三:
我们要首先明白两点:
1.a^a=0;
2.0^a=a;
int main()
{
int a = 3;
int b = 5;
a = a ^ b;
b = a ^ b;
a = a ^ b;
printf("%d\n%d", a, b);
return 0;
}
(六)例题2
求一个整数存储在内存中的二进制中1的个数。
方法一:
int main()
{
int n = 0;
scanf("%d", &n);
int count = 0;
while (n)
{
if (n % 2 == 1)
{
count++;
}
n /= 2;
}
printf("%d", count);
}
但是,如果n是负数的话,上述代码就不能正常运行了。但我们还可以来改进它:
int main()
{
unsigned int n = 0;
scanf("%d", &n);
int count = 0;
while (n)
{
if (n % 2 == 1)
{
count++;
}
n /= 2;
}
printf("%d", count);
}方法二:
我们知道,1的补码为00000000000000000000000000000001
那我们随便举一个数字:15
15的补码为00000000000000000000000000001111
我们进行1&15的运算:
00000000000000000000000000000001
00000000000000000000000000001111
会得到:
00000000000000000000000000000001==1
我们会发现,15的补码最后一个数字是1,
运行完以上运算后得到的原码恰好是1的原码。
这里我们就成功判断了15的补码中最后一位是1。
那怎么判断前面的31位呢?我们只需要用“右移操作符”
将原数字的补码每次向右移动一位即可。
int main()
{
int n = 0;
scanf("%d", &n);
int count = 0;
for (int i = 0; i < 32; i++)
{
if ((n >> i) & 1 == 1)
{
count++;
}
}
printf("%d", count);
}
方法三(难以想到):
我们来进行这样一个运算:n &(n-1)
这里n我们取15:
n==15 1111
n-1==14 1110
n &(n-1) 1110
n==14 1110
n-1==13 1101
n &(n-1) 1100
n==12 1100
n-1==11 1011
n&(n-1) 1000
n==8 1000
n-1==7 0111
n&(n-1) 0000
我们可以发现,这样的运算是一个循环,一共循环了四次。
而这种运算,可以把二进制数最右边的1化为0。
int main()
{
int n = 0;
int count = 0;
scanf("%d",&n);
while (n)
{
n = n & (n - 1);
count++;
}
printf("%d", count);
}
(七)思考题
判断一个整数是否为2的次方数(次方数位正整数)。
我们可以很容易发现,2的次方数的二进制数中,不管有多少位,都只有一个1。
那么我们就可以利用例题2的方法三的运算方法:
int main()
{
int n = 0;
scanf("%d", &n);
if ((n & (n - 1))== 0)
{
printf("True.");
}
else
printf("False.");
return 0;
}
但是如果我们写成如下代码(if语句内有变化):
int main()
{
int n = 0;
scanf("%d", &n);
if (n & (n - 1)== 0)
{
printf("True.");
}
else
printf("False.");
return 0;
}代码运行结果会出错,原因是因为==的优先级高于&。
六、单目操作符
单目操作符有这些:
![]()
单目操作符的特点是只有一个操作数,在单目操作符中仅有&与*没有介绍,是因为&与*在指针学习中讲解会更加生动形象。
七、逗号表达式
exp1,exp2,exp3,...,expN上述就是一个逗号表达式的一般形式。
逗号表达式,从左到右依次执行。整个表达式的结果是最后一个表达式的结果(但这不意味着只需要运算最后一个表达式)。
代码1:
int main()
{
int a = 1;
int b = 2;
int c = (a > b, a = b + 10, b = a + 1);
printf("%d", c);
return 0;
}打印c的值为多少?
如果是3,那就是没有理解透逗号表达式。
正确的结果应该是13。
![]()
代码2(伪代码,只展示逻辑):
a = get_val();
count_val(a);
while (a > 0)
{
//
业务处理
//...
a = get_val();
count_val(a);
}
如果使⽤逗号表达式,改写:
while (a = get_val(), count_val(a), a > 0)
{
//业务处理
}
八、下表访问[]、函数调用()
(一)[] 下标引用操作符
int main()
{
int arr[10] = { 1,2,3,4,5,6,7 };
printf("%d", arr[6]);
return 0;
}![]()
这里arr[]的[]就是下标引用操作符,而[]的操作数则是arr与6。
也就是说[]的操作数是一个数组名和一个索引值(下标)。
(二)() 函数调用操作符
()接受一个或者多个操作数,第一个操作数是函数名,剩余的操作数就是传递给函数的参数。
int Add(int x, int y)
{
return x + y;
}
void test()
{
printf("hehe\n");
}
int main()
{
printf("hehe\n");//() 函数调用操作符
int ret = Add(2, 3);//() 函数调用操作符
test();
return 0;
}这里的printf函数,Add函数后面的()都是函数调用操作符。
而test()则告诉我们,函数调用操作符的操作数至少有1个,即函数名。
九、结构成员访问操作符
(一)结构体
C语言已经提供了内置类型,比如:char、short、int、long、float、double等,但是只有这些内置类型还是不够的。假设我想描述一个学生,描述一本书,这是单一的内置类型是无法做到完全描述的。
C语言为了解决这个问题,增加了结构体这种自定义的数据类型,让程序员可以自己创造适合的类型。
结构是一些值的集合,这些值为成员变量。结构的每个成员可以是不同类型的变量,如:标量、数组、指针,甚至是其他结构体。
1.结构的声明
struct tag
{
member - list;
}variable;描述一个学生:
struct Student
{
char name[20];
int age;
int high;
float weight;
char id;
};2.结构体变量的定义和初始化
struct Student
{
char name[20];
int age;
int high;
float weight;
char id;
}s4,s5,s6;
//s4,s5,s6是结构变量(全局的)
struct Student s7;//全局的
int main()
{
struct Student s1 = { "张三",20,108,75.5f,"0000000001" };//初始化
struct Student s2 = { .age = 30,.name = "李四",.weight = 80.5f,.high = 177,.id = "0000000002" };
return 0;
}结构体嵌套初始化:
struct S
{
char c;
int n;
};
struct B
{
struct S s;
int* p;
char arr[10];
float sc;
};
(二)结构成员访问操作符
1.结构体成员的直接访问
结构体成员的直接访问是通过点操作符(.)访问的。点操作符接受两个操作数。如下所示:
struct S
{
char c;
int n;
};
struct B
{
struct S s;
int* p;
char arr[10];
float sc;
};
int main()
{
struct B b = { {'C',7},NULL,"Ronaldo",85.0f };
printf("%c\n", b.s.c);
return 0;
}使用方式:结构体变量.成员名。
2.结构体成员的间接访问
等到学完指针再讲述。
十、操作符的属性:优先级、结合性
C语言的操作符有两个重要的属性:优先级、结合性,这两个属性决定了表达式求值的计算顺序。
(一)优先级
优先级是指,如果一个表达式包含多个运算符,哪个运算符应该优先执行。各种运算符的优先级是不一样的。
举一个最简单的例子:
int main()
{
printf("%d", 3 + 4 * 5);
return 0;
}![]()
这里就表明:*的优先级高于+。
(二)结合性
如果两个运算符优先级相同,优先级没办法确定先计算哪个,这时候就看结合性。
我们需要根据运算符是左结合,还是右结合,决定执行顺序。大部分运算符是左结合(从左到右执行),少数运算符是右结合(从右到左执行),比如赋值运算符(=)。

参考:https://zh.cppreference.com/w/c/language/operator_precedence
十一、表达式求值
(一)整形提升
C语言中整形算术运算总是至少以缺省(默认)整型类型的精度来进行的。
为了提升这个精度,表达式中的字符和短整型操作数在使用之前被转换为普通整型,这种转换成为整型提升。
整形提升的意义:

上述表述可能会有点抽象,我们来用代码举一个例子:
在举例子之前,我们先重温几个点:
int类型的长度是4个字节,即32个比特位;
而char类型的长度是1个字节,即8个比特位。
int main()
{
char a = 3;
//00000000000000000000000000000011:3的二进制序列
//但是char的长度为8个比特位,所以只能存8个数:
//00000011 - a(a中真实存的值)
char b = 127;
//00000000000000000000000001111111:127的二进制序列
// 但是char的长度为8个比特位,所以只能存8个数:
// 01111111 - b(b中真实存的值)
char c = a + b;
//00000000000000000000000010000010:c的二进制序列
// 但是char的长度为8个比特位,所以只能存8个数:
// 10000010 - c(c中真实存的值)
printf("%d\n", c);
//% d - 以10进制的形式打印有符号的整数
//我们要对c进行提升:
// 因为c是有符号整数
// 所以按照变量的数据类型的符号位来提升
//11111111111111111111111110000010 -- - C提升后的结果(补码)
//10000000000000000000000001111101(反码)
//10000000000000000000000001111110(原码)
// 然后,这个原码所代表的十进制的值就是打印出来的值。
return 0;
}![]()
(二)算数转换
如果某个操作符的各个操作数属于不同的类型,那么除非其中一个操作数转换为另一个操作数类型,否则操作就无法进行。下面的层次体系为寻常算数转换:

如果某个操作数的类型在上面这个表格中排名靠后,那么首先要转换为另一个操作数的类型后执行运算。
(三)问题表达式解析
1.表达式1
int main()
{
int a, b, c, d, e, f;
int n = a * b + c * d + e * f;
return 0;
}上述代码,在计算的时候,由于*的优先级比+高,只能保证*总是比+早,但是优先级不能决定第三个*比第一个+早执行。
所以计算机的计算顺序可能是:
1.先a*b、c*d、e*f,然后再从左向右求和;
2.先先a*b、c*d,再算(a*b)+(c*d),再算e*f,最后求和。
这就是计算机的运算过程产生了歧义。不小小看这种运算,假如这六个字母分别又是表达式,那后果将不堪设想。
2.表达式2
int main()
{
int c = 0;
int b = c + --c;
return 0;
}操作符的优先级只能保证自减(--)的运算在+的运算前面,但是我们没有办法得知+操作符的做操作数的获取是在又操作符运算之前还是之后,所以这种代码也是有歧义的。
3.表达式3
int main()
{
int i = 10;
i = i-- - --i * (i = -3) * i++ + ++i;
printf("i = %d\n", i);
return 0;
}上述代码,在不同的编译器中的测试结果如下:

试想,这段代码的可移植性是不是就很可笑了?
所以,这也是段不好的代码。
4.表达式4
int fun()
{
static int count = 1;
return ++count;
}
int main()
{
int answer;
answer = fun() - fun() * fun();
printf("%d\n", answer);//输出多少?
return 0;
}这个代码看起来没有问题,实际上也是有问题的。
我们只能知道*的优先级高于-,但函数调用先后顺序无法通过操作符的优先级确定(即fun函数与操作符的顺序)。
5.表达式5
int main()
{
int i = 1;
int ret = (++i) + (++i) + (++i);
printf("%d\n", ret);
printf("%d\n", i);
return 0;
}
同一段代码,在不同变异其中产生了两种不同的结果,这是为什么?
我们分析一下可以知道,之所以两段代码的运行结果不一样,就在于两次运行时第一个+和第三个前置++的先后顺序不一致。
(四)总结
根据以上五个表达式,我们可以知道即使有了操作符和结合性,我们写出的表达式仍然有可能不能通过操作符的属性确定唯一的计算路径,那这个表达式就是存在风险的,建议不要写出这种特别复杂的表达式。代码不是谁的代码越长越让别人难懂越好,而是要写出优质的代码。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 22
22 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)