Day50 | J.U.C集合-ConcurrentLinkedQueue详解
本文深入解析了ConcurrentLinkedQueue这一线程安全队列的实现原理和应用场景。文章详细分析了其核心结构(head/tail指针和Node内部类)、构造方法以及关键操作(offer/poll/peek),重点阐述了其独特的延迟更新tail指针策略和失效节点处理机制。通过与LinkedBlockingQueue的对比,清晰区分了有界/无界、阻塞/非阻塞、有锁/无锁等核心概念。文章还通过
本文将详细剖析ConcurrentLinkedQueue的原理、实现细节、API使用以及实际应用场景。
一起深入理解他在并发环境下的优势和适用性。
在讲解ConcurrentLinkedQueue的时候,我们会引入LinkedBlockingQueue进行对比。
让大家对有界/无界、阻塞/非阻塞、锁/无锁等这些基础的概念有更加直观的理解。
一、ConcurrentLinkedQueue简介
1.1队列
首先队列是一种数据结构,就类似于现实生活中食堂窗口、银行窗口、营业厅窗口前排的队伍。
一般情况下,这些队伍都有头有尾(head、tail),队伍里的人也是遵守先来后到的原则,排在前面的人就会先获得服务。
现实生活中的队伍是为了让我们的生活更加有序高效,不至于大家蜂拥而至,为了抢服务扭打在一起。
其实队列在计算机里也是为了让程序运行得井井有条。
有了队列,可以作为生产者和消费者缓冲区,两者可以解耦,各做各的事情,不相互影响。
如果遇到了类似中午这种用餐高峰期,有了队列,大家不至于把食堂大门冲爆,在计算机里就是把大量的请求放到队列里,后台服务器按照自己最大的处理能力,一个一个的处理,这样服务器就不会因为瞬时高峰瘫痪。
再有就是你在网购的时候,系统告诉你下单成功了。你就可以去干其他事情了。不用一直等着你买的东西出仓、运输等等。其实你下单成功,系统就相当于往队列里丢了条数据。然后队列的数据后续在慢慢的处理。这是最简介的异步的概念。
1.2有界/无界
队列的有界、无界是指队列的容量是不是有上限。
有界队列一般会预设一个最大容量。
当队列达到容量上限之后,要么就是等着,要么就是入队失败返回,或者直接被丢弃,看具体的实现。
无界队列理论上就是没有上限的,有多少收多少,来者不拒。
但是队列也不可能无限的膨胀下去,毕竟内存还是有限制的。
ConcurrentLinkedQueue就是无界的,他的构造函数中没有预设容量的属性。
offer方法也没有容量阈值的相关判断。
而LinkedBlockingQueue的默认构造可以理解为无界队列。因为他把Integer.MAX_VALUE作为了默认容量。
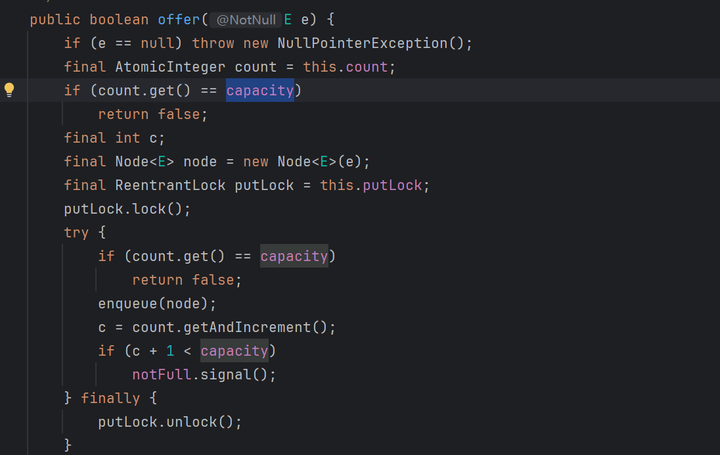
LinkedBlockingQueue的另一个代参构造,则接收一个int值作为队列的容量。这就是有界队列。

LinkedBlockingQueue的offer方法中也针对这个容量进行了分支判断处理。
1.3阻塞/非阻塞
阻塞就是假设条件不满足的时候,线程就会被挂起,这个时候不占用CPU了,直到出现空位、超时或者被中断。
非阻塞就是假设不满足条件的时候就马上返回,线程不会等,自己决定要不要重试或者放弃。
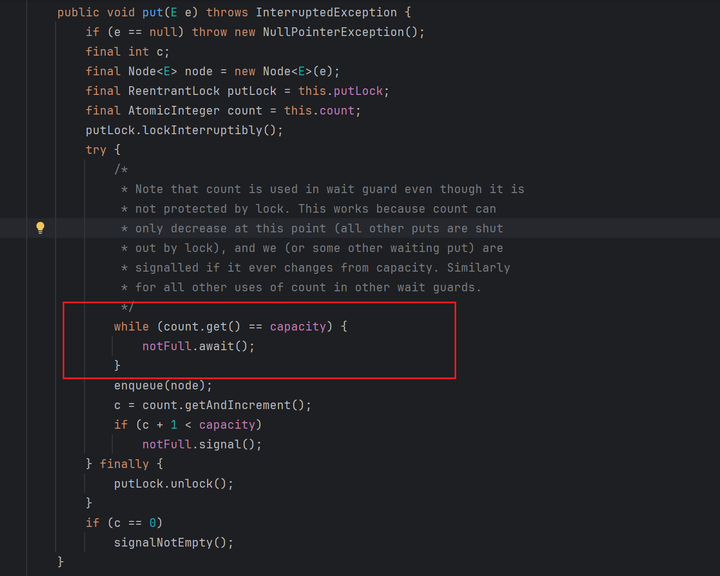
LinkedBlockingQueue中的put方法,假如队列满了,线程就会通过notFull.await()挂起,直到被唤醒或者中断、超时。
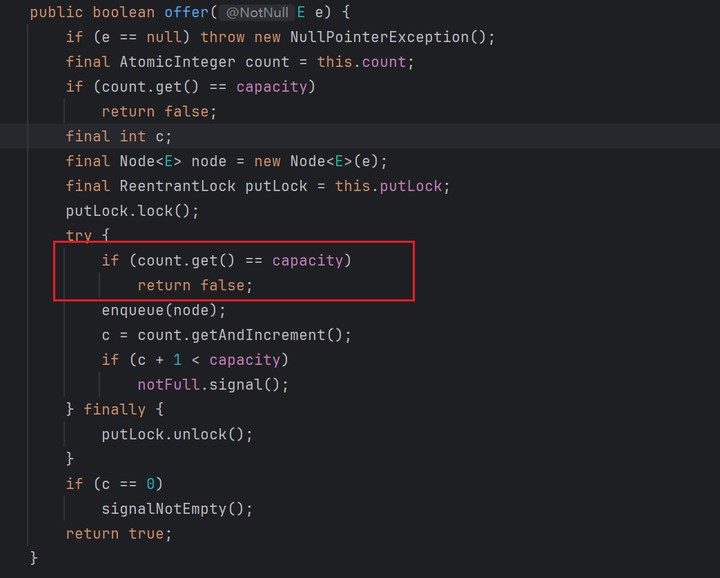
LinkedBlockingQueue中的offer方法是非阻塞的,如果碰到队列满了,直接就返回false了。
ConcurrentLinkedQueue的offer同样也是非阻塞的,整个方法中都没有锁、await、park这些东西。
主体就是一个无限for循环配合CAS。
在竞争激烈的情况下,其实生产者线程在时间维度上也是在等待,但是他属于忙等自旋,不属于阻塞式的挂起等待。相当于生产者线程一直是处于运行状态的。注意理解这两种等待。
1.4有锁/无锁
ConcurrentLinkedQueue就是无锁实现的,他的offer方法中只使用了CAS,没有锁痕迹。
LinkedBlockingQueue的offer方法通过ReentrantLock + Condition实现。
想象一个场景,如果有非常多的人想要加入队伍(很多线程在往队列加数据),又有很多人离开队伍(多个窗口在办理业务),怎么才能让他们不打起来呢(有序的进出)?
回到ConcurrentLinkedQueue,这是J.U.C包里一个线程安全的队列实现。
基于链表结构,支持FIFO(先进先出)顺序,是一个无界队列,不会因为元素太多了阻塞生产者线程。
ConcurrentLinkedQueue采用的是无锁算法,通过CAS操作实现并发访问。
二、ConcurrentLinkedQueue结构
2.1继承体系
先来看一下ConcurrentLinkedQueue的继承体系:
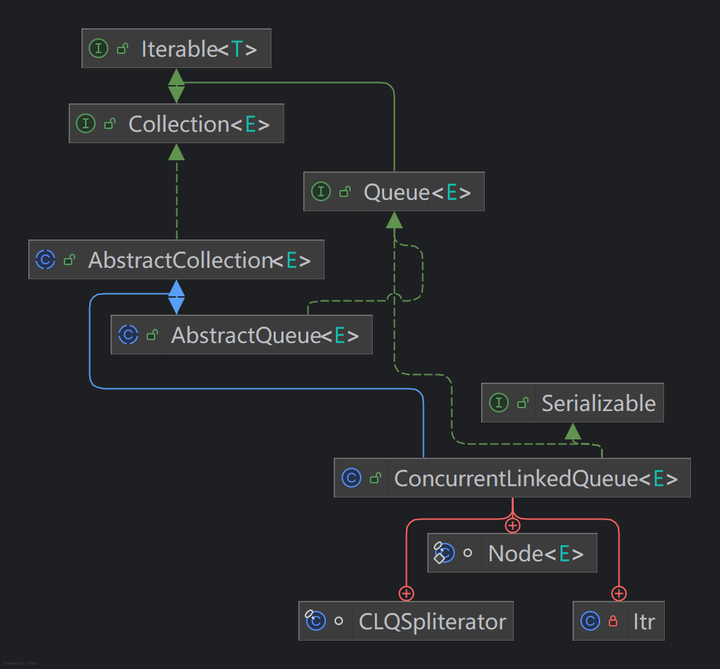
首先是接口层:
Iterable<T>说明这是一个可迭代的集合。
Collection<E>说明具有集合的基本操作。
Queue<E>说明这是一个FIFO的数据结构,有offer(), poll(), peek()这些队列操作方法。
Serializable说明这个类的对象可以被序列化。
抽象类层的AbstractCollection和AbstractQueue说明继承了集合和队列的一些骨架实现。
最后就是内部类中最重要的Node<E>,ConcurrentLinkedQueue就是连接这些存储数据的Node形成的。
2.2核心属性
transient volatile Node<E> head;
private transient volatile Node<E> tail;这两个属性是ConcurrentLinkedQueue整个数据结构的基础。
head定位队列的起点,poll()和peek()操作都是从head开始。
tail用来定位队列的终点,offer()操作从tail开始,把新节点添加到他后面。
2.3核心内部类
ConcurrentLinkedQueue的所有数据都存储在一个核心的内部类实例里,这个内部类是构成链表的基本单元。
这个内部类自然就是Node。
static final class Node<E> {
volatile E item;
volatile Node<E> next;
//...
}这是一个静态内部类,代表链表中的一个节点。
他作为数据的载体,由两个部分组成。
item用来存储元素;next指向像一个节点的引用。
offer和poll的核心就是通过CAS操作原子性地修改next引用或head/tail引用。
2.4构造方法
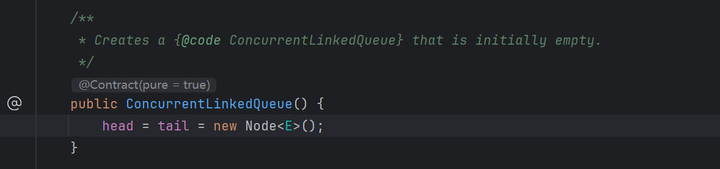
public ConcurrentLinkedQueue() {
head = tail = new Node<E>();
}
public ConcurrentLinkedQueue(Collection<? extends E> c) {
Node<E> h = null, t = null;
for (E e : c) {
Node<E> newNode = new Node<E>(Objects.requireNonNull(e));
if (h == null)
h = t = newNode;
else
t.appendRelaxed(t = newNode);
}
if (h == null)
h = t = new Node<E>();
head = h;
tail = t;
}ConcurrentLinkedQueue有两个构造方法。
无参构造方法直接创建了一个Node,然后把head和tail都指向了他。
第二个构造接收一个集合。遍历集合,然后通过appendRelaxed一个一个的把节点串起来。
如果是个空集合,就是无参构造的逻辑。
三、ConcurrentLinkedQueue核心方法
3.1offer方法
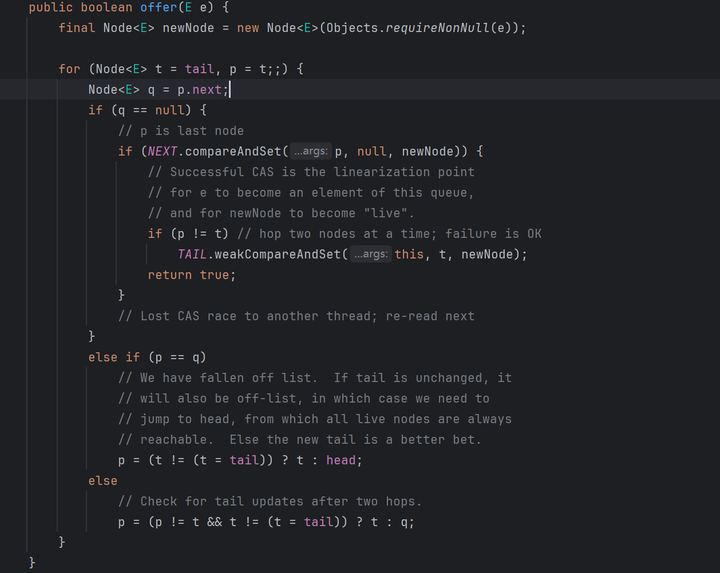
public boolean offer(E e) {
final Node<E> newNode = new Node<E>(Objects.requireNonNull(e));
for (Node<E> t = tail, p = t;;) {
Node<E> q = p.next;
if (q == null) {
if (NEXT.compareAndSet(p, null, newNode)) {
if (p != t) // hop two nodes at a time; failure is OK
TAIL.weakCompareAndSet(this, t, newNode);
return true;
}
}
else if (p == q)
p = (t != (t = tail)) ? t : head;
else
p = (p != t && t != (t = tail)) ? t : q;
}
}这个方法就是用来往队尾插入元素的。
第一步就是构建一个新的节点。
接着就进入一个无限循环for(Node<E> t = tail, p = t;;)。
循环初始时,先通过Node<E> t = tail获取到队列尾指针。p可以看成一个探针指针,用来遍历或者定位要添加上新节点的节点。一开始跟t是相同的。
这个无限循环是一个自旋循环,只有成功添加新节点后才返回。失败了就重试,不会阻塞。
循环的目的只有一个,就是找到一个合适的p(当前的尾节点),他的next是null,然后CAS添加上新节点。
循环内部分成三个主要的分支,根据q = p.next的状态来决定走哪条路。q就是p的下一个节点。
第一个分支:q ==null
如果这个条件满足,是不是就意味着p可能就是当前队列的实际尾部。
这就简单了,直接通过CAS尝试把新节点挂上去。
如果CAS失败了,说明有其他线程抢先一步在p后面添加了节点。只能进下一次循环了。
如果CAS成功了,新节点就已经成为了队列的一部分,offer方法的大部分工作就算完成了。
if(p != t)是为了优化。注意一开始的时候,p是等于t的。如果p!=t了,说明我们是从一个过时的tail出发,一路向后遍历才找到队尾的。
这时就要通过weakCompareAndSet把tail指针向前移动到我们新加的节点。
成功与否无所谓,反正新节点已经加上了,失败了其他线程也会继续帮助推进tail指针。
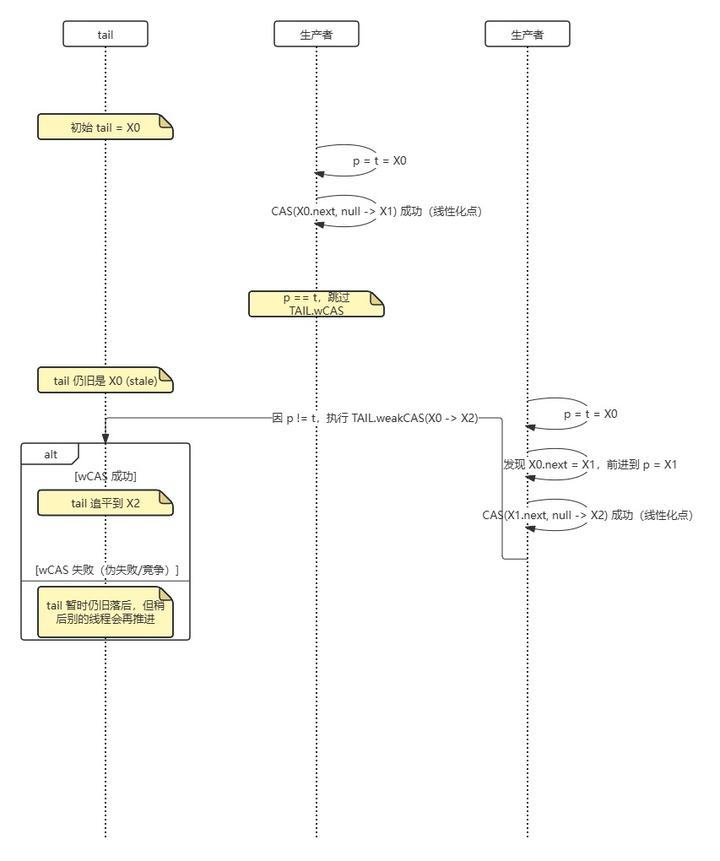
关于tail指针过时及tail指针的延迟更新我画了两张图便于理解:
第一张图展示tail怎么落后的,另一个线程又是怎么推进的。
第二张图展示并发情况下,弱CAS(weakCompareAndSet)失败,会不会对队列有什么影响。
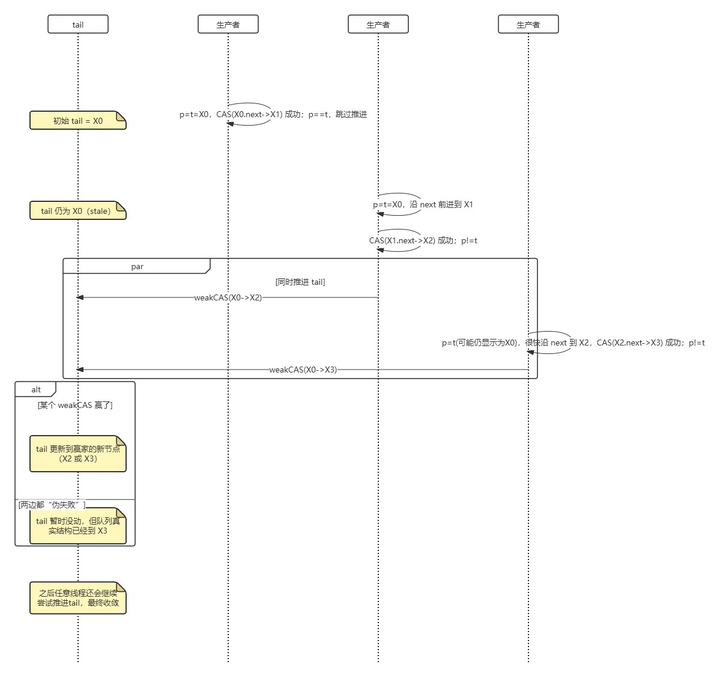
为什么要设计成这种延迟更新呢?因为之前已经有一次强制的CAS(添加节点),如果再来一次强制的CAS,在高并发情况下,必然有线程会不停的失败重试,竞争非常激烈。况且tail指针是不是精准完全不影响队列。减少对同一地址的竞争性CAS通常比偶尔多走几步链表(next到尾节点)更划算。
第二个分支:p == q
回想一下q是p的下一个节点。也就是p.next == p。这是一种特殊的状态。
如果一个节点被poll方法从队列头部移除之后,他的next指针会被置成指向自己。相当于给自己打了个标记,表示我已经被移除了。
如果探针p走到了这样的节点,说明我们的tail指针t已经严重过时了,指向了已经被消费掉的区域。
出现这种情况,我们只能重置探针p。
首先重新读取tail,如果tail已经被其他线程更新了,我们就跳到新的tail(t)位置重新开始
如果tail还是没变,说明他可能卡住了(一直没线程推进tail),我们就干脆从head(头指针,永远是稳定的起点)重新开始寻找队尾。
同样我们画一张图来看看怎么出现的这种情况:
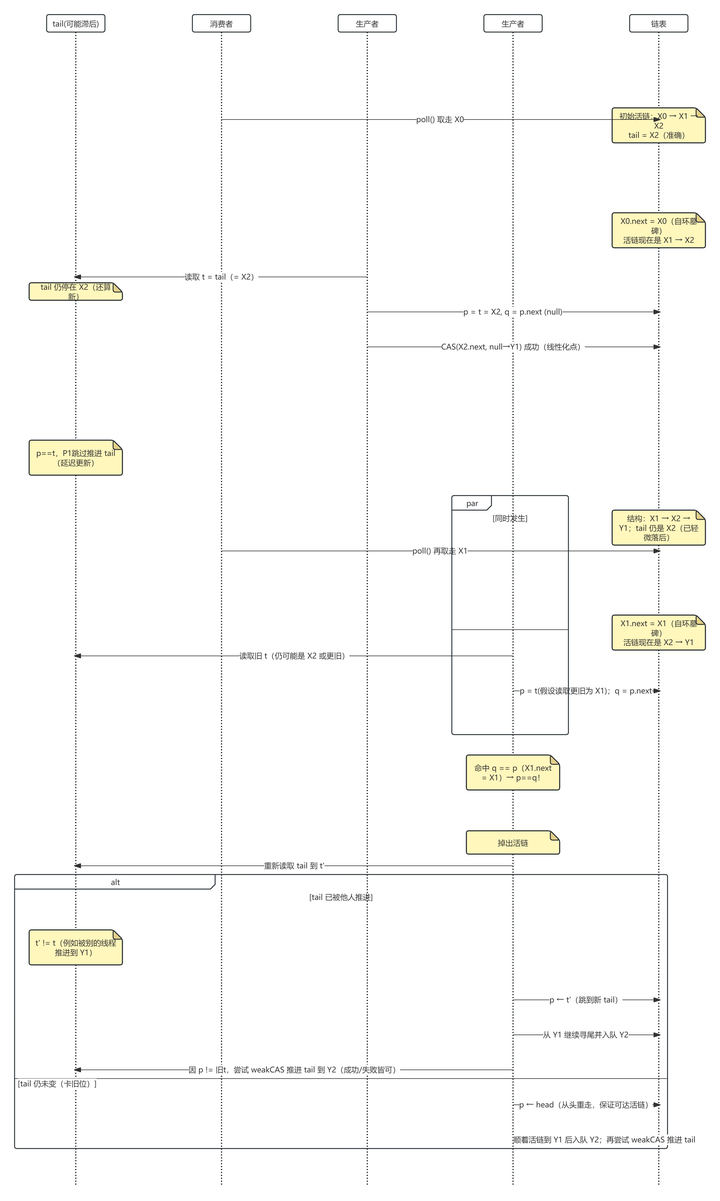
消费者把X1出队并自环,P2从过时位置(看到的t或更旧)出发,出现X1.next = X1,既p == q。
然后按分支,如果tail已经被推进就跳尾,不然就回头。
第三个分支
这个else里面处理的就是比较常见的情况。
q不是null,说明p不是队尾,p != q说明p不是失效的节点。
排除了上面两种情况,只能说明tail过时了,我们得用探针p往后再走一走。
t != (t = tail)重新读取了tail,然后跟循环开始的t进行比较。
不相等说明其他线程在我们遍历的时候更新了tail。
如果tail被更新了,说明我们之前遍历走的那几步白费了,最快的办法就是让p直接跳到新的tail。
如果没被更新,那就老老实实的用p往前走一步。
3.2poll方法
public E poll() {
restartFromHead: for (;;) {
for (Node<E> h = head, p = h, q;; p = q) {
final E item;
if ((item = p.item) != null && p.casItem(item, null)) {
if (p != h) // hop two nodes at a time
updateHead(h, ((q = p.next) != null) ? q : p);
return item;
}
else if ((q = p.next) == null) {
updateHead(h, p);
return null;
}
else if (p == q)
continue restartFromHead;
}
}
}poll方法用来从队列头部移除并返回元素。如果队列是空的,就返回null。
restartFromHead是个标签,主要是为了方便内层循环能够跳出来(continue restartFromHead)。
外层也是一个无限循环,我们主要看一下内层循环的条件分支。
内层循环初始化的时候,h = head获取队列头指针。p = h,这里的p同样是个探针指针,用来遍历和定位的,一开始跟h一样。
q还是在循环体里面被设置成p.next。
内层的无限循环通过p逐步向后推进(p = q),目的就是找到一个有item的节点,或者确认队列是空的。
内层循环体根据p.item和q = p.next的状态分三个分支处理:
第一个分支
(item = p.item) != null && p.casItem(item, null)p.item不是null,然后尝试CAS把p.item从当前值改成null。
如果满足这个条件,那这个节点就被"移除"了,但是节点还是在链中,item被清空了。
item被置空后还会经历一个p != h的判断,如果满足p != h,说明从过时head出发,遍历了节点才找到的item。
就通过updateHead尝试CAS推进一下head,失败了也无所谓。交给其他线程推进就是了。
updateHead的入参有个三目运算:((q = p.next) != null) ? q : p
如果p.next是null,就把head推进到p。
如果p.next不为null,就把head推进到q(q=p.next)。
p.item都被清空了,如果p.next不为空,就顺手把head推进到p.next。
第二个分支
else if ((q = p.next) == null)这个分支条件,叠加上第一个分支(p.item == null),说明p是实际尾部,没有元素。
然后尝试把head推进到p,返回null。
第三个分支
else if (p == q)在队列里面,如果节点被移除了,next可能设为自身。
这种情况下,就只能通过continue restartFromHead跳出内循环,重新获取新的head,再开始循环。
3.3peek方法
peek方法跟poll方法有点类似,不过peek方法可以看成只读方法。他只会获取对头节点,但是不会像poll一样把他删除了。
public E peek() {
restartFromHead: for (;;) {
for (Node<E> h = head, p = h, q;; p = q) {
final E item;
if ((item = p.item) != null
|| (q = p.next) == null) {
updateHead(h, p);
return item;
}
else if (p == q)
continue restartFromHead;
}
}
}(item = p.item)!=null说明探针找到了一个有效的节点。
(q = p.next)==null说明已经到达了链表的末尾,这个队列是空的。
在返回item之前,还做了一件事情,updateHead推进head。
不是说,peek只读,不会做任何其他操作吗?
其实peek也只是顺手帮个忙,如果他peek的过程中,一路上跳过了几个失效节点,那就说明head已经过时了,顺手就CAS一下,举手之劳,管他成不成功。成功了后续线程就稍微省点事情。
如果进入了第二个分支p == q,这种就是失效节点,说明在遍历的过程中,队列结构已经发生了变化,比如瞬间被poll了很多元素。这种情况下,那就通过continue restartFromHead;跳出去,搞个最新的head ,再来取。
隐藏的第三分支其实就是p.item是null且p.next不是null。这种情况就直接通过循环中的p = q,让探针p继续前进到下一个节点找就行了。
结语
希望阅读完本文,大家对队列这种数据结构有了基本的了解。
同时通过对ConcurrentLinkedQueue的介绍和分析,大家对有界、无界、阻塞、阻塞这些概念也有一定的认识。
了解ConcurrentLinkedQueue的一个基本的工作原理和结构。
下一篇预告
Day52 | J.U.C工具-CountDownLatch详解
如果你觉得这系列文章对你有帮助,欢迎关注专栏,我们一起坚持下去!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 10
10 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)