现阶段Agent落地效果不佳的五大问题
看到知乎的一个问题,如何评价当前的 AI Agent 落地效果普遍不佳的?结合近段时间的实践和调研,整理了目前agent落地效果不佳的五大问题。
看到知乎的一个问题,如何评价当前的 AI Agent 落地效果普遍不佳的?结合近段时间的实践和调研,整理了目前agent落地效果不佳的五大问题。
五大问题归因为:
1.现阶段agent在工业实践上和学术研究存在比较大的gap;
2现阶段agent依赖的底座大模型推理泛化不足;
3.现阶段agent记忆能力不足;
4.现阶段agent技术范式同质化且工程保障薄弱;
5.现阶段很多场景不具备agent落地实现条件。
下面就依次展开谈一谈。
agent在工业实践上和学术研究存在比较大的gap
谈这个问题,需要先介绍下技术背景。最近半年,大模型(尤其是Reasoning model)技术发展很明显的趋势就是越来越agentic[1],几乎新发布的模型都会提到这个agentic特性,就是评估模型在agent相关的任务上表现如何,这是LLM缺乏action,而agent补上了action这一环,解决了LLM"只能想不能做"的问题。在现实场景任务自动化的过程中,很多任务只靠推理不行,还需要行动和反馈,这也暗合了大模型的另外一个技术范式的变化,从training scaling 到test time scaling,虽然这个趋势出现的更早(从o1,deepseek开始),但现在仍在延续。
技术范式变化的两点标志是long cot和parrallel inference,但是核心推动是RL后训练,sft是让模型学习特定能力来做到场景适配,偏向于特定模式学习缺少泛化性,而RL可以基于奖励函数(现在主要是可验证的强化学习RLVR)来进行探索式的学习,能稳定推理路径并保持一定的泛化性(是否能学习探索出超越基础模型的推理能力暂时存疑,大部分研究认为RL基于基模型的推理空间探索到稳固的推理路径[2],但是可以结合使用,比如long cot可以先进行sft冷启动打下基础,让模型具备生成long cot这种格式数据的能力,接着再上RL进行后训练。
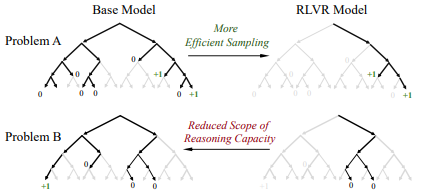
从最近的各项基于RL的agent模型训练,构造agent多轮迭代过程环境依赖的环境(包括工具和执行环境),并设计对应的奖励函数,就能让模型学习到如何在复杂的长程任务上如何调用工具,如何进行多轮迭代,最终完成任务。相比直接使用基础模型,RL训练后的模型在agent各项任务的整体性能上提升非常大,这说明了rl在agent基础模型训练的有效性,模型agent化已逐渐成为模型发展的一种趋势[3]。
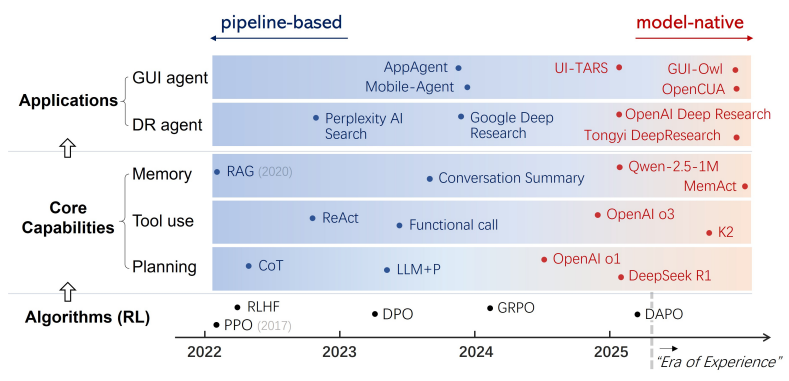
那为什么说工业实践和学术研究存在比较大的gap呢,一方面是因为现在agent rl是一个热门研究方向,技术更新很快,不断有新工作出现,而工业实践需要消化,实践,测试,上线流程,迭代速度很难跟上学术进展,这本身是合理的;另一方面是大部分研究还是集中在相对"狭窄"的领域,包括DeepResearch,coding等方便直接验证结果的场景,另外很多试验性能的提升也是基于agent的公开数据集,在业务场景上并不能随插即用;第三个原因是环境问题,rl的训练环境内置了工具链和执行器让模型在这个环境中实现工具调用和结果返回,在真实业务场景中使用需要保持环境与训练环境的一致性才能确保模型有可靠稳定的发挥,但目前环境迁移问题还没有标准解决方案,虽然mcp从一定程度上实现了工具使用的标准化,但是要统一推理和训练环境的标准,还需要考虑执行环境,执行条件,上下文记忆管理等问题。
现阶段agent依赖的底座大模型推理泛化不足
其实上一条已经提到很多agent的研究集中相对狭窄的领域,这个原因除了和大模型预训练的自回归范式相关:虽然LLM可以理解为是一个文本"世界模型",但还不具备稳健的世界模型理解和长程规划能力,导致以它为核心构建的 agent 在跨任务、跨环境的推理泛化上存在明显瓶颈。
另外还和现阶段的后训练范式相关,近期我们看到的大部分agent后训练工作取得有效的成果都是基于RLVR,但是RLVR存在的一个局限点在于奖励需要能够被verify,在可自动化验证奖励的场景,比如数学、代码、检索等领域,可以通过奖励信号学习到更可靠的长程推理能力,但很多现实任务缺少可验证奖励或验证器不可靠,因此 RLVR 的直接适用面受限,这会在一定程度上限制泛化。
但是针对这两个问题也有一些解决思路,针对预训练,现在有一些研究开始尝试RLP[4](Reinforcement as a Pretraining Objective),RL 前移到预训练阶段,把“下一个 token/片段是否正确”当作可验证奖励,进行规模化强化学习训练,但是算力要求和环境要求都还存在很多工程化挑战。而对于RLVR的可验证局限性,有研究提出rubrics奖励的方法[5],从严格二元奖励扩展到多维度奖励,扩展到更多场景。但有效应还没得到广泛验证,落地更需时间。
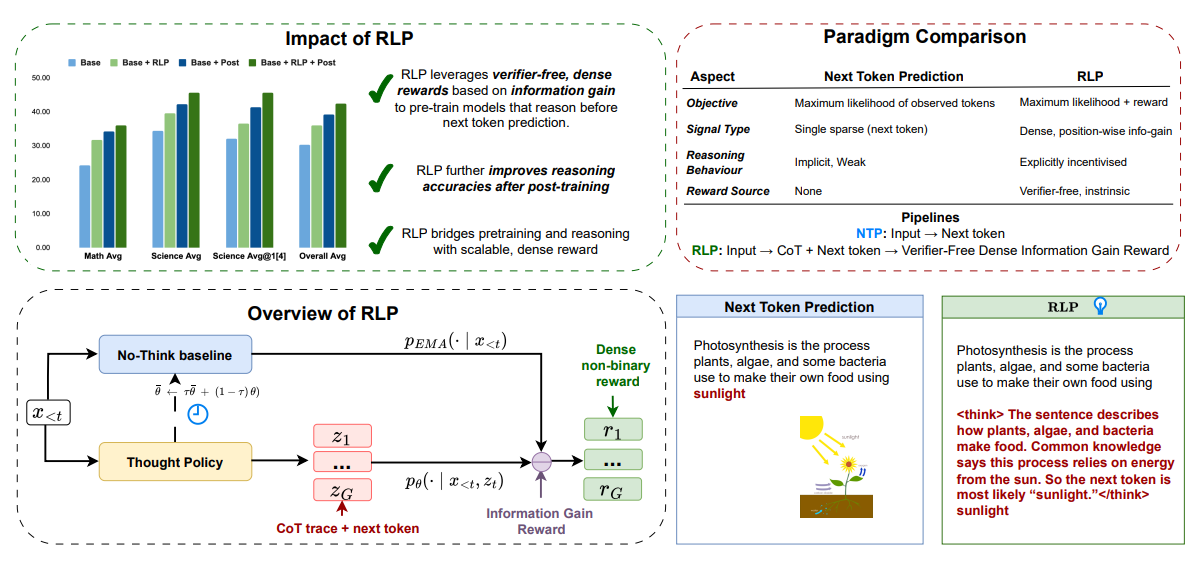
现阶段agent记忆能力不足
最近我们能看到不少文章和技术分享谈到agent落地的关键在于context engineering,从agent记忆分类来看,context engineering属于短期记忆,而agent的记忆模块的划分理念完全来自人类记忆,长期记忆包括经历(情景记忆),知识(语义记忆)和技能(程序化记忆),短期记忆一般就指工作记忆,就是记录当前有限的时间窗口内发生了什么,引申到agent的使用上,用于记录最近agent与人/外界发生了什么交互,产生了什么结果。以react为例,agent运多个think-act-obs的循环,短期记忆包括了这个agent每个迭代循环调用了什么工具(act),产生了什么结果(obs),plan一般不记录,那短期记忆可以用一个集合wm={a0,o0,a1,o1...an,on}来表示,也可以理解为一个执行了多个步骤的trajectory。
那问题是什么呢?agent需要去执行更复杂的任务,更复杂的任务需要执行的次数就会越来越多,那这个短期记忆也会随之膨胀,一方面agent进行plan依赖的LLM存在天然的上下文限制,这个短期记忆的扩展可能会导致上下文放不下完整的trajectory。另一重要原因,之所以需要记忆模块,不只是简单的把记录的过程直接进行使用,而是需要区分哪些有用,哪些没用,这也恰好是记忆中最难的点-识别出哪些信息是对当前决策有用的。
agent对应的上下文和一般的chabot上下文是有所不同的,虽然都是基于LLM为技术底座,但是chatbot上下文的构成是循环qa对的格式,而agent的大量上下文是被上面提到的wm集合包含的动作-结果(工具调用)所占据,相比之下agent上下文的管理难度就会大很多,因为agent需要完成复杂任务不仅步骤多,关联跨度长,与外界交互复杂,而且还需要处理多种中间结果,结果的类型也不只是字符串,还包括各种文件。
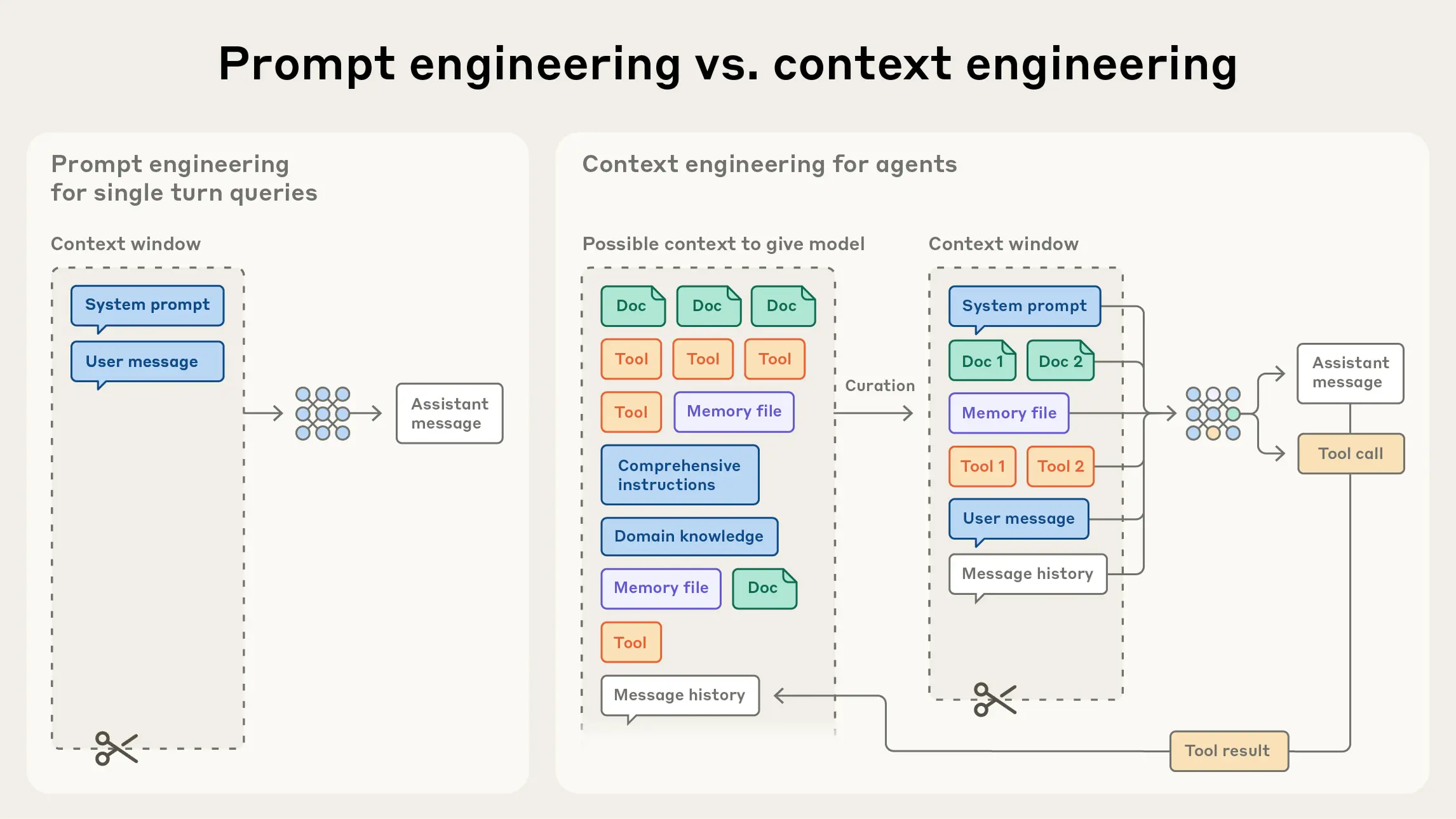
我们当前看到一些短期记忆的技术分享,包括manus[6],anthropic[7],chagpt[8]的实践分享,都是集中在如何管理上下文(context engineering),处理上面提到的这问题。实际上对上下文的处理主要包括四种方式:检索(retrival),裁剪(trimming),压缩(compact/summaration),缓存(cache)。四种方式这里只做简要说明,检索是把短期记忆持久化实现按需提取,裁剪是对当前积累轨迹中时间较久的上下文进行裁剪,压缩是抽取总结对当前决策有用的上下文,缓存是将上下文进行cache复用降低成本。四种方式目前主要依赖工程化实现,没有统一的解决方案,目前的技术发展趋势是通过RL实现自主记忆管理,但这个落地难度仍然还很大。
agent技术范式同质化且工程保障薄弱
目前agent的基本运行模式大都为react,react的思路理解起来比较简单,就是对"plan-act-obs"链路进行持续迭代循环,直到完成任务退出。但是react确实也比较有效,这个模式兼顾了迭代相对可控和自主发挥,"先规划后执行"符合人类完成复杂任务的行动方式,"think-act-obs的抽象过程"将问题动态的交给agent进行决策,例如迭代中某一轮报错了,这个错误信息会记录到obs,自动进入下一轮的上下文,agent会据此进行对应的修复和调整,并再次重试(但一般也会加护栏防止一直重试)。也有一些和Reflection结合的工作,比如ReflAct[9],还有将plan和act拆开(plan and act[10])的方式,基本上也都是与react结合或部分优化,综合性能,成本,效果来看,目前react仍然是业界用的最多的范式。这种偏工程化的收敛并不是一种很好的迹象,可能需要其它范式来进行pk对比,才能带来更大的技术突破和落地推进。
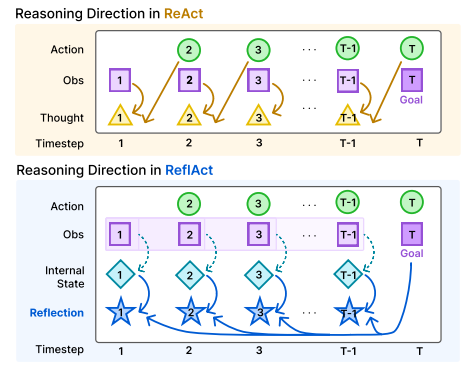
对于工程保障薄弱问题,首先与agent依赖的LLM强相关,目前基于大模型搭建的软件服务暂时没有形成一套公认规范的测评,测试体系方法,来对大模型存在的不确定性输出,大模型效果评估标准(准确率,幻觉率,稳定性)问题进行解决。然后在agent的技术开发链路上,可观测,可审计的技术协议和语义约定也还没有标准化手段,同样的在工具安全,动作授权,human in loop(人在环路)的工程设计也还处于早期实践标准建立阶段。
很多场景不具备agent落地实现条件
首先agent要能运行有一个前提是-"完成当前场景任务需要的工具可以通过API访问",这个前提的基础是因为agent要具备行动能力,工具是基础,而对于目前的大部分agent场景,工具都是以api来提供的,但是很多企业并不具备大部分工具实现了API集成的基础。
在agent实践的开发过程中,首先也得自己清楚当前任务需要用到哪些工具,自己没有想清楚这个问题,agent大概率也不会完成预期目标。另外现阶段的agent做demo很容易,但是要实现生产可用支持持续迭代,需要投入的算法,工程资源都不低。agent技术发展的很快,第一点也提到了agent在工业实践上和学术研究存在比较大的gap,但从另外一个角度上来说,企业构建的agent如果不考虑技术的迭代因素,那可能这个项目花几个月实践搭建的项目,在模型能力提升后,所做的优化就失去了原有的价值。
所以需要在启动agent项目时,就从算法层面判断agent的技术发展趋势,可以在工具链,安全验证,可审计/可测评,智能冗余,自主化空间改造上下功夫,而不应该在提示词优化,规则兜底,业务知识结构化注入等容易被模型能力替代优化的方面投入太多,同时应该对项目周期留出合理的技术探索空间,搭建好基础能力很重要,基于好的基础就能逐步提升性能指标。
在技术快速迭代当下,这种方式会比“先快速搭一个能跑的,后面再来补漏洞”更适合agent项目的研发和迭代。

参考文献:
[1] https://arxiv.org/pdf/2509.02547
[2] https://arxiv.org/pdf/2504.13837
[3] https://arxiv.org/pdf/2510.16720
[4] https://arxiv.org/pdf/2510.01265
[5] https://arxiv.org/pdf/2508.12790
[6] Context Engineering for AI Agents: Lessons from Building Manus
[7] Effective context engineering for AI agents
[8] Context Engineering - Short-Term Memory Management with Sessions from OpenAI Agents SDK | OpenAI Cookbook
[9] https://arxiv.org/pdf/2505.15182
[10] https://arxiv.org/pdf/2503.09572

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 24
24 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)