当大模型遇见大数据:重新定义数据湖的智能引擎
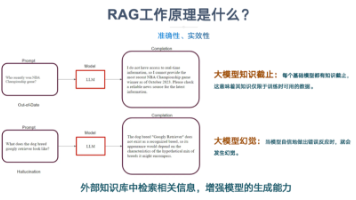
摘要:大模型技术正驱动数据湖架构向智能化演进。面对PB级多模态数据的处理挑战,本文系统分析了大模型如何重构数据湖的三大核心能力:基于自然语言交互的智能查询范式、自动化数据治理体系以及深度知识发现机制。重点探讨了向量化存储与混合检索的技术演进路径,结合华为云等实践案例,验证了智能数据湖在提升查询效率(毫秒级响应)、降低使用门槛(非技术人员可用)和增强价值挖掘(多模态关联分析)等方面的显著优势。研究为
摘要:随着大数据规模迈入PB级且多模态化趋势凸显,传统数据湖在查询效率、治理能力与价值挖掘深度上的瓶颈日益凸显。大模型凭借其强大的语义理解、多模态处理与知识推理能力,正成为重构数据湖智能引擎的核心驱动力。本文系统探讨大模型如何重塑数据湖的查询交互、数据治理与价值挖掘三大核心范式,深入分析向量化存储与混合检索系统的技术演进路径,并结合工业界实践案例阐述工程落地要点,为构建高效、智能的数据湖体系提供技术参考。
关键词:大模型;数据湖;智能引擎;向量化存储;混合检索;数据治理;查询范式
一、引言:传统数据湖的困境与大模型的破局契机
在数字经济时代,数据湖作为承载企业全量数据(结构化、半结构化、非结构化)的核心载体,已成为企业数字化转型的基础支撑。然而,随着数据规模激增(单企业数据量年均增长50%+)、数据类型多元化(文本、图像、音频等多模态数据占比超60%),传统数据湖逐渐暴露出三大核心困境:
-
查询效率低下且门槛高:依赖SQL的查询方式对非结构化数据适配性差,需专业人员编写复杂脚本,且海量数据下全表扫描延迟常达小时级,无法满足实时决策需求;
-
数据治理能力薄弱:缺乏自动化的数据质量检测、元数据标注与异常识别机制,导致“数据沼泽”问题凸显,据Gartner统计,企业约30%的数据因治理缺失无法被有效利用;
-
价值挖掘深度不足:传统分析工具仅能实现浅层次的统计分析,难以挖掘多模态数据间的隐性关联,无法支撑精准预测、智能决策等高阶需求。
大模型的出现为突破上述困境提供了关键契机。其具备的自然语言理解、多模态语义对齐、知识图谱构建等核心能力,能够从查询交互、数据治理、价值挖掘三个维度重构数据湖的运行逻辑,推动数据湖从“数据存储池”向“智能价值引擎”升级。同时,向量化存储与混合检索技术的演进,为大模型与数据湖的深度融合提供了底层技术支撑,实现了数据存储与检索效率的协同优化。
二、核心技术底座:向量化存储与混合检索的演进逻辑
大模型对数据湖的赋能,首先依赖于数据存储与检索层的技术革新。向量化存储解决了非结构化数据的高效表示问题,混合检索系统则实现了结构化与非结构化数据的统一高效查询,两者共同构成了智能数据湖的技术底座。
2.1 向量化存储:从“文本/像素”到“语义向量”的跨越
传统数据湖采用文件式或结构化存储,无法直接表征非结构化数据的语义信息。向量化存储的核心逻辑是通过大模型将各类数据(文本、图像、音频等)转化为高维语义向量(Embedding),实现数据的语义级统一表示。其技术演进经历了三个阶段:
-
第一阶段:独立向量库阶段。采用专门的向量数据库(如Milvus、FAISS)存储向量,数据湖与向量库独立部署,需通过数据同步工具实现数据互通。该阶段解决了向量存储的基础需求,但存在数据一致性差、查询时需跨系统关联的问题;
-
第二阶段:湖仓一体融合阶段。将向量存储能力集成至湖仓一体架构中,如Delta Lake通过Delta Tensor方案实现张量(向量是张量的特殊形式)与结构化数据的统一存储,支持ACID事务,解决了数据一致性问题。该阶段通过稀疏编码、多维数组存储优化,实现了向量存储的空间效率提升30%以上;
-
第三阶段:智能优化阶段。引入自适应向量压缩与索引优化技术,根据数据语义相似度动态调整向量维度,结合分层索引(如IVF-HNSW)平衡检索精度与速度。例如,华为云LakeSearch通过向量索引优化,将亿级数据检索延迟从秒级降至毫秒级。
2.2 混合检索系统:从“单一查询”到“多模态协同检索”的升级
混合检索系统的核心是融合传统结构化查询(SQL)与向量检索能力,实现对全类型数据的统一检索。其技术演进围绕“检索效率提升”与“检索场景扩展”展开:
-
初级阶段:查询拼接模式。通过中间层将用户查询拆分为结构化查询语句与向量检索请求,分别在结构化数据库与向量库中执行,最后合并结果。该模式实现了基础的混合检索,但存在查询计划优化不足、跨模态关联能力弱的问题;
-
进阶阶段:统一查询引擎。构建支持结构化与向量数据的统一查询解析与优化引擎,如基于Spark Photon优化器扩展向量检索算子,实现查询计划的全局优化。该阶段可减少跨系统数据传输,检索效率提升50%以上;
-
高级阶段:多模态协同检索。结合大模型的跨模态语义对齐能力,支持“文本查询图像”“语音查询文档”等跨模态检索场景。例如,贵州省基于华为云AI可信数据空间,通过多模态混合检索,实现了100个文旅政策文档生成1100+QA对,问答响应时间优化至毫秒级。
三、大模型重构数据湖核心范式:查询、治理与价值挖掘
基于向量化存储与混合检索的技术底座,大模型从交互方式、治理模式、价值挖掘三个核心维度重构数据湖的运行范式,推动数据湖的智能化升级。
3.1 查询范式重构:从“SQL依赖”到“自然语言交互”
传统数据湖查询依赖专业SQL编写,门槛高、效率低。大模型驱动的查询范式实现了两大突破:
-
自然语言到查询计划的自动转换:通过大模型的语义理解能力,将用户自然语言查询(如“查询2025年Q3华东地区经销商库存异常的关联因素”)转化为高效的混合查询计划(结构化查询+向量检索),无需用户掌握SQL。华为云Data Agent通过该技术,将数据使用门槛降低80%,非技术人员也可直接查询数据湖;
-
上下文感知的智能交互:支持多轮对话式查询,大模型可记忆用户历史查询意图,实现查询的递进式深化。例如,在“库存异常”查询基础上,用户进一步询问“可能的市场影响”,系统可自动关联销售数据、舆情数据进行多维度分析,输出结构化结论。
3.2 治理范式重构:从“人工主导”到“智能自动化”
传统数据治理依赖人工进行数据标注、质量检测、异常处理,效率低、成本高。大模型将治理能力嵌入数据湖全生命周期,实现治理自动化:
-
智能元数据管理:大模型自动解析数据湖中的文档、表格、图像等数据,生成结构化元数据(包括数据来源、字段含义、数据关联关系),并构建动态知识图谱,解决元数据缺失、更新不及时的问题。华为云DataArts Studio通过大模型赋能,元数据标注效率提升10倍;
-
自动化数据质量管控:大模型通过学习历史数据质量规则,自动检测数据缺失、异常值、数据不一致等问题,并给出修复建议。例如,在金融数据湖场景中,大模型可自动识别交易数据中的异常流水,准确率达95%以上;
-
敏感数据智能脱敏:通过大模型的实体识别能力,自动识别身份证号、银行卡号、个人隐私信息等敏感数据,实现动态脱敏,保障数据安全合规。
3.3 价值挖掘范式重构:从“浅层次统计”到“深度知识发现”
传统数据湖的价值挖掘多局限于统计分析、报表生成等浅层次应用。大模型凭借多模态处理与因果推理能力,实现数据价值的深度挖掘:
-
多模态数据关联分析:大模型可对齐文本、图像、音频等多模态数据的语义信息,挖掘隐性关联。例如,在零售数据湖场景中,关联分析客户评论文本、商品图像、销售数据,发现“商品包装设计缺陷”与“客户差评”的强关联,为产品优化提供依据;
-
动态预测与决策支持:结合时间序列预测与因果推理,大模型可基于数据湖中的历史数据,预测业务发展趋势,并模拟不同决策的潜在影响。某区域经销商通过大模型分析数据湖中的销售、客服、舆情数据,提前14天预警渠道危机,决策准确率提升至93%;
-
知识沉淀与复用:将业务专家经验与数据湖中的数据知识融合,构建领域知识图谱,支持智能问答、自动化报告生成等应用。海亮集团基于华为云数智融合数据湖,构建钢铁生产知识图谱,成材率从91%提升至93%,单位产品能耗下降300kWh。
四、工程实践要点与案例解析
4.1 工程实践核心要点
大模型赋能数据湖的工程落地需关注三个核心问题:
-
性能优化:通过向量索引优化(如HNSW索引)、查询计划缓存、分布式计算框架(Spark/Flink)集成,降低检索与分析延迟;
-
成本控制:采用分层存储策略(热点数据存入内存、冷数据存入对象存储),结合模型量化(INT8/4-bit)降低大模型推理成本;
-
兼容性保障:确保新的智能引擎与现有数据湖架构(如Hadoop、Delta Lake)兼容,支持平滑迁移,避免数据重构风险。
4.2 典型案例:华为云AI可信数据空间
华为云构建的“一湖一链一中枢”AI可信数据空间解决方案,是大模型赋能数据湖的典型实践:
-
一湖(融合数据湖):实现全模态数据全域入湖,通过统一元数据管理与权限控制,保障数据高质量供数;
-
一链(智能数据工具链):集成LakeSearch混合检索系统、Data Agent智能用数工具,支持自然语言交互与多模态检索;
-
一中枢(数据空间中枢):基于大模型实现数据流通流程编排与安全管控。
该方案在贵州文旅场景中,通过多模态数据处理与混合检索,赋能“黄小西”旅游服务智能体,问答准确率提升30%,响应时间从秒级优化至毫秒级,充分验证了大模型驱动数据湖智能升级的可行性。
五、总结与未来展望
大模型与数据湖的融合,本质上是通过语义理解、多模态处理等智能能力,解决传统数据湖“查得慢、管得难、用不深”的核心痛点,推动数据湖从“数据存储中心”向“智能价值引擎”转型。向量化存储与混合检索系统的持续演进,为这种融合提供了坚实的技术底座,而查询、治理、价值挖掘三大范式的重构,则实现了数据价值的高效释放。
未来,随着大模型技术的不断迭代,数据湖的智能引擎将向三个方向发展:一是实时化,通过边缘计算与大模型轻量化部署,实现数据入湖、检索、分析的端到端实时响应;二是自主化,构建自监督学习驱动的智能数据湖,实现数据治理、价值挖掘的全流程自主优化;三是生态化,打通上下游数据链路,构建跨企业、跨领域的协同数据湖生态,推动数据价值的最大化释放。对于企业而言,把握大模型与数据湖融合的技术趋势,构建适配自身业务的智能数据湖体系,将成为数字化转型的核心竞争力。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)