ZooKeeper Watcher机制深度解析:从原理到实践,构建高响应的分布式系统
在分布式系统的世界里,如何及时感知状态变化并作出响应,是一个核心且富有挑战性的问题。Apache ZooKeeper,作为分布式服务的协调大师,其强大的状态同步能力,很大程度上归功于其精心设计的 Watcher(观察者)机制。本文将深入剖析Watcher机制的工作原理、特性、使用方式以及最佳实践,并结合Mermaid流程图和序列图,帮助您彻底掌握这一关键技术。
在分布式系统的世界里,如何及时感知状态变化并作出响应,是一个核心且富有挑战性的问题。Apache ZooKeeper,作为分布式服务的协调大师,其强大的状态同步能力,很大程度上归功于其精心设计的 Watcher(观察者)机制。本文将深入剖析Watcher机制的工作原理、特性、使用方式以及最佳实践,并结合Mermaid流程图和序列图,帮助您彻底掌握这一关键技术。
一、 Watcher机制概述:分布式系统的“神经末梢”
1.1 什么是Watcher机制?
Watcher机制本质上是一种异步回调机制,允许客户端在ZooKeeper服务器上的特定数据节点(ZNode)上注册一个监听。当该ZNode或其子节点发生变化(如数据更新、节点删除、子节点列表变更)时,ZooKeeper服务端会主动向注册监听的客户端发送一个事件通知。客户端在接收到通知后,可以执行预先设定的回调逻辑,从而实现基于事件驱动的编程模型。
简单来说,你可以将Watcher理解为分布式系统的“神经末梢”或“警报系统”。客户端不需要不断地轮询ZooKeeper服务器(“你变了吗?”),而是设置一个监听点(“变了就告诉我”),从而实现了高效、实时的状态感知。
1.2 Watcher的核心特性
理解Watcher,必须掌握它的几个核心特性,这些特性决定了它的行为和用法:
-
一次性触发(One-time trigger): 这是Watcher最重要的特性。当Watcher被触发后,即客户端收到事件通知后,该Watcher就会被移除。如果客户端需要继续监听后续的变化,必须在回调函数中重新注册Watcher。
-
优点:避免了在节点频繁变化时产生大量的通知,减轻网络和客户端的压力。
-
缺点:可能存在事件丢失的风险。如果在客户端收到通知并重新注册Watcher的间隙,ZNode再次发生了变化,客户端将感知不到这次变化。
-
-
轻量级(Lightweight): Watcher通知本身只包含事件类型(如NodeDeleted)、连接状态(KeeperState)和被监视的ZNode路径,不包含变化的具体内容。客户端收到通知后,如果需要知道变化后的新数据或新的子节点列表,必须主动去ZooKeeper服务器上重新查询。
-
异步通知(Asynchronous Notification): 通知是由ZooKeeper服务器端异步发起的,客户端会在另一个线程中处理该事件。
-
先注册后监听(Watch before Listen): Watcher的设置是在读操作(如
exists,getData,getChildren)中完成的。这意味着,客户端必须先发起一个读取请求,并在该请求中附带Watcher,才能建立起监听。
二、 Watcher的工作原理与工作流程
为了直观地理解Watcher的完整生命周期,我们首先通过一个流程图来展示从注册到触发的全过程。
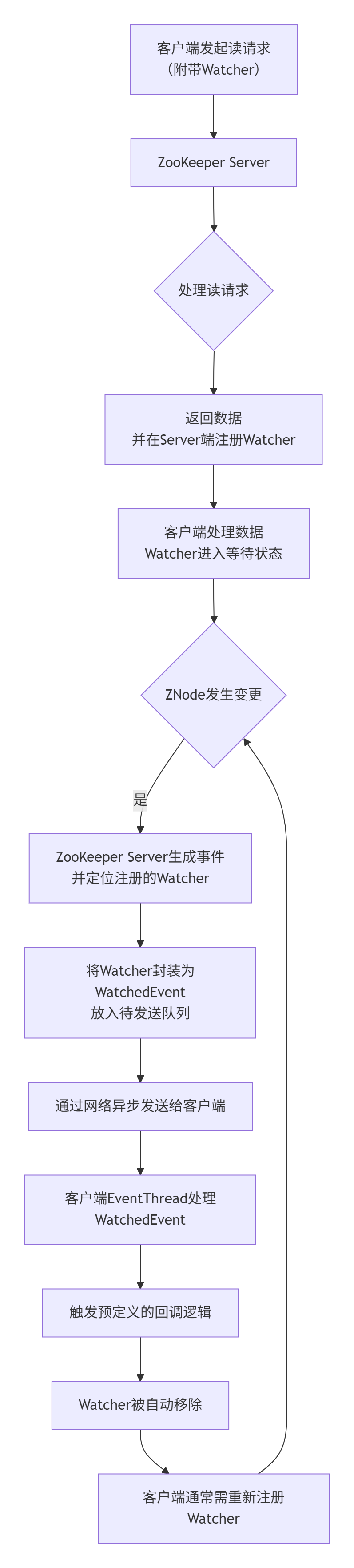
流程解读:
-
注册阶段:客户端通过调用
getData,getChildren或exists方法,并在参数中传入一个Watcher对象(或实现Watcher接口的回调函数)。这个请求到达ZooKeeper服务器后,服务器在返回数据的同时,会在内存中记录一个映射关系:“这个客户端正在监视这个ZNode路径的某种事件”。 -
等待阶段:客户端继续执行其他逻辑,Watcher在后台等待。
-
触发与通知阶段:当另一个客户端(或同一个客户端)对被监听的ZNode进行了修改(如
setData,delete,create),ZooKeeper服务器会检测到这一变更。 -
事件处理阶段:服务器根据变更类型(删除、数据更新等)生成一个
WatchedEvent对象,然后查找所有监听了该路径的Watcher,并将其放入一个专门的发送队列,异步地发送给对应的客户端。客户端的EventThread会接收到这个事件,并调用相应的process方法。 -
后续行动:Watcher被触发后自动失效。在客户端的回调逻辑中,通常需要重新注册Watcher以继续监听后续变化,并重新读取ZNode的数据以获取最新状态。
三、 Watcher的事件类型与API使用
3.1 核心事件类型
Watcher事件主要分为两类:通知状态(KeeperState) 和 事件类型(EventType)。
-
KeeperState:表示客户端与服务器之间的连接状态变化。
-
SyncConnected: 客户端与服务器成功建立连接或恢复连接。这是进行正常操作的前提。 -
Disconnected: 客户端与服务器断开连接。此时会话(Session)仍有效,但无法进行操作。 -
Expired: 会话过期。这是最严重的状态,此时在该会话下创建的临时节点和所有Watcher都会丢失。 -
AuthFailed: 认证失败。
-
-
EventType:表示ZNode上发生的具体数据变化。
-
None: 通常与KeeperState变化一起使用,表示连接状态发生了变化。 -
NodeCreated: 被监听的节点被创建。通过exists方法设置Watcher可监听此事件。 -
NodeDeleted: 被监听的节点被删除。通过exists或getData方法设置Watcher可监听此事件。 -
NodeDataChanged: 节点的数据内容发生变化。通过exists或getData方法设置Watcher可监听此事件。 -
NodeChildrenChanged: 节点的子节点列表发生变化(子节点被创建或删除)。通过getChildren方法设置Watcher可监听此事件。注意:此事件不告知是哪个子节点发生了变化,仅通知列表有变。
-
3.2 交互序列图
以下序列图展示了一个典型的“客户端A监听节点数据变化,客户端B修改节点数据”的交互场景。
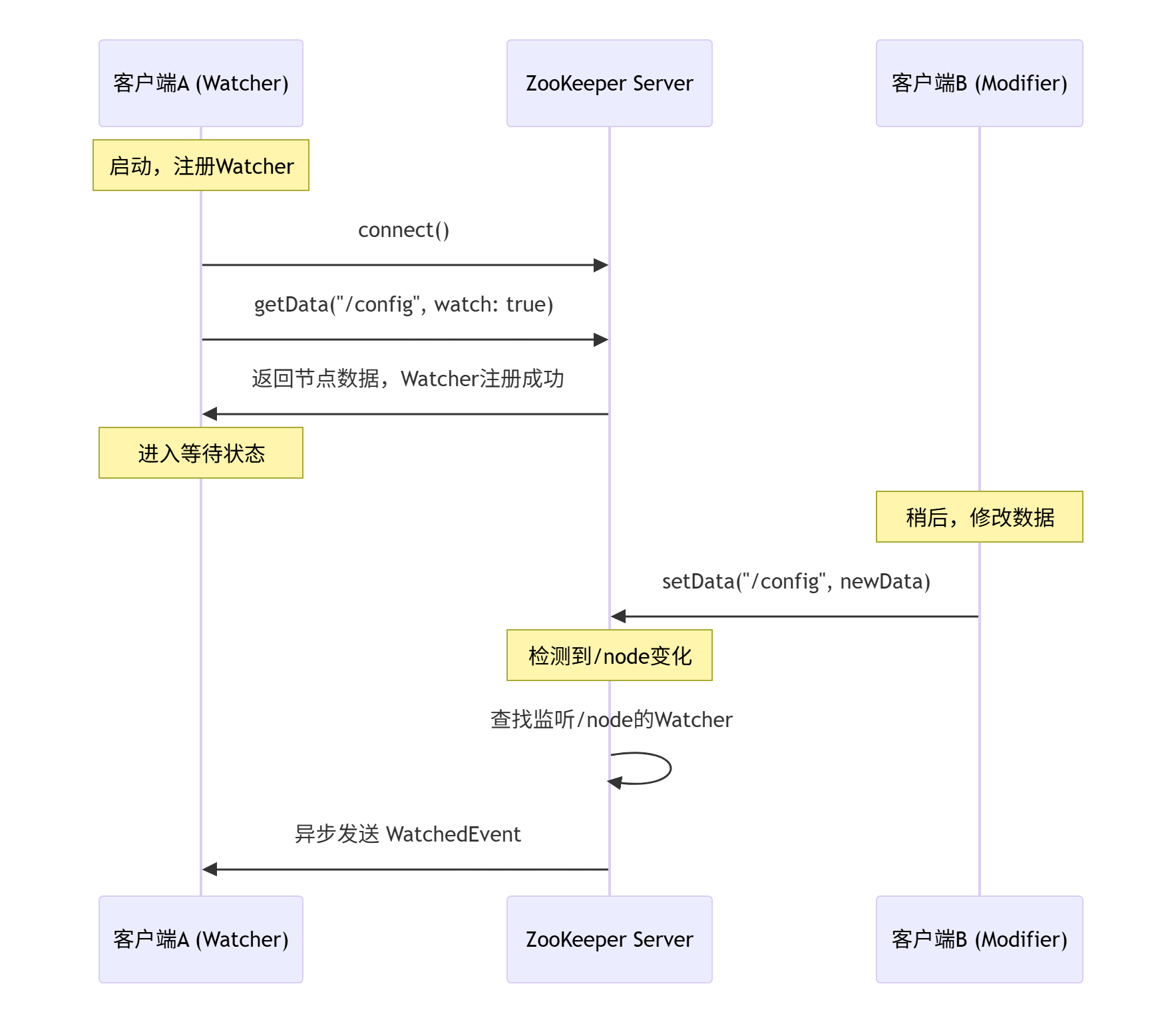
3.3 代码示例(Java)
// 实现Watcher接口
public class MyWatcher implements Watcher {
private ZooKeeper zk;
public MyWatcher(String connectString) throws IOException {
this.zk = new ZooKeeper(connectString, 3000, this); // this作为默认Watcher
}
@Override
public void process(WatchedEvent event) {
String path = event.getPath();
Event.EventType type = event.getType();
Event.KeeperState state = event.getState();
// 1. 处理连接状态事件
if (state == Event.KeeperState.Expired) {
System.out.println("Session expired, reconnecting...");
// ... 重连逻辑
return;
}
// 2. 处理节点事件
if (type == Event.EventType.NodeDataChanged) {
System.out.println("Node " + path + " data changed!");
try {
// 重新注册Watcher并获取新数据
byte[] newData = zk.getData(path, this, null);
System.out.println("New data: " + new String(newData));
} catch (Exception e) {
e.printStackTrace();
}
} else if (type == Event.EventType.NodeDeleted) {
System.out.println("Node " + path + " deleted!");
}
// ... 处理其他事件类型
}
public void watchNode(String path) throws KeeperException, InterruptedException {
// 初始注册Watcher
zk.getData(path, this, null);
}
}四、 Watcher的最佳实践与常见陷阱
4.1 最佳实践
-
始终处理连接状态:在
process方法中,首先要判断KeeperState,特别是Expired状态。会话过期后,所有临时节点和Watcher都会丢失,需要完整的重建逻辑。 -
收到通知后重新注册并获取数据:由于Watcher是一次性的,且通知不包含数据,因此回调函数中必须包含重新注册Watcher和重新读取数据的逻辑。
-
使用
getChildren实现集群管理:监听一个临时节点(如/members)的getChildrenWatcher,可以非常高效地实现服务上下线的动态感知,是服务发现和集群管理的经典模式。 -
处理好敏感时期(Session失效到重建期间)的变化:在客户端重连期间,ZNode可能已经发生了变化,而客户端可能错过了Watcher通知。因此,在连接恢复后,除了重新注册Watcher,还应该主动进行一次全量状态同步。
4.2 常见陷阱
-
消息丢失:由于Watcher的一次性特性,在连续快速变更的场景下,可能会丢失中间状态的变化。如果业务要求强一致性,不能完全依赖Watcher,可能需要结合其他机制(如版本号校验)。
-
“羊群效应”:如果成百上千的客户端都监听同一个ZNode(如一个全局配置节点
/config),当这个节点发生变化时,ZooKeeper服务器会同时向所有客户端发送通知,可能造成网络风暴。可以考虑将配置分散到各个客户端自己的节点下,或使用领导选举模式,只有一个主节点负责监听和更新。 -
未及时重新注册:在回调函数中忘记重新注册Watcher,会导致后续变化无法被感知。
五、 总结
ZooKeeper的Watcher机制以其简洁、高效的设计,为分布式系统提供了可靠的事件驱动模型。它通过一次性触发、轻量级通知等特性,在保证实时性的同时,避免了系统被海量通知压垮。深入理解其工作原理、事件类型和“先注册后监听”的模式,是正确、高效使用ZooKeeper的基石。
尽管它存在“消息可能丢失”的弱点,但在大多数协调场景(如配置管理、服务发现、领导选举、分布式锁)中,它已经足够强大。通过遵循最佳实践,并清晰地认识到其边界,开发者可以充分利用Watcher机制,构建出高响应、可扩展的分布式应用。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)