AiPy:体验、实战
概述:Python Use、实战、原理、设置、付费、TrusToken、参考。
概述
国际版官网,中文版官网。爱派,北京知道创宇公司推出的AI工具,通过深度融合LLM与Python编程能力,突破传统问答式交互框架,构建需求解析-任务规划-代码生成-代码执行-动态调优全流程自动化闭环。提供Windows、MacOS系统安装程序。借助Python Use范式,理解需求,通过动态生成并执行Python代码,完成任务。
除开源(GitHub)免费版(指的是爱派工具本身部分功能可用,调用模型API还是需要付费的)之外,还提供企业版,功能更高级更强大,还有付费支持服务。
对比下两者的宣言(slogan):
- 国际版:Help you make money, help you slack off, help you find a partner, we can help you with everything.
- 中文版:本地Manus、国内能用、内网能用,开源免费。
核心技术价值:
- 无代理化通用任务执行框架
颠覆传统工具代理(Agent)依赖模式,首创代码即代理(Code is Agent)技术理念。通过大模型对用户需求进行语义解析与任务拆解,动态生成Python代码并调用本地资源(文件系统、应用程序、网络服务、智能设备等),实现跨领域自动化操作。 - 全本地化安全计算架构
支持全功能本地化部署,敏感数据处理全程在本地环境完成,避免数据云端传输风险。用户仅需承担大模型API调用成本(提供免费模型接入方案),结合开源代码,满足企业级数据安全与合规要求,尤其适用于金融、医疗等对数据隐私敏感的行业场景。 - Python生态深度集成方案
依托Python丰富的工具链体系(数据分析库、自动化脚本引擎、API调用接口等),结合大模型能力,实现需求语义-执行代码-系统操作双向驱动。相比Java/Lua等开发语言,兼具轻量化部署与生态扩展性优势,可实时生成邮件定时发送脚本、多音色语音合成程序等复杂功能模块。 - 弹性兼容的技术架构设计
- 多模型适配能力:支持主流大模型API接入,兼容本地模型部署方案(0.9.1版本试用下来没有此项功能,未来也许会有),平衡计算性能与成本消耗;
- 跨平台部署体系:提供Windows、MacOS系统安装包,降低技术使用门槛;
- 开放扩展接口:支持MCP,可添加三方MCPServer,也能自定义API调用(含本地私有接口),通过
API Calling功能实现与企业现有业务系统的无缝集成。
对比其他AI Agent
- AutoGPT:AutoGPT需要预设大量工具,配置复杂,而AiPy通过动态生成代码,简化使用流程,适合快速上手。
- Dify:Dify更偏向于低代码平台,适合开发AI应用,但对普通用户的友好度不如AiPy。AiPy的自然语言交互更直观。
- Manus:Manus功能强大但依赖云端,且闭源。而AiPy的本地化运行和开源属性,让它在安全性和灵活性上更胜一筹。
(中文)测评报告:
Python Use
之前在AI浏览器概述,汇总过好几个Use,如:Browser Use、Computer Use、Mobile Use。
而Python Use,则是知道创宇公司的工程师推出的概念。
Python-Use范式:一种把Agent逻辑直接写成可执行Python代码的极简思路。抛弃繁复的Schema注册、Workflow编排和多Agent协商,实现细粒度代码控制,逻辑可控、可调试、最少Token浪费。简单说,直接用Python把Agent逻辑实现出来,让代码就是Agent。
实战
非常简单,官方提供安装包,从官网下载exe应用程序,安装过程会解压缩超级一大堆Python包,没具体测算过,是有好几分钟。
手机号注册后,界面如下,功能一目了然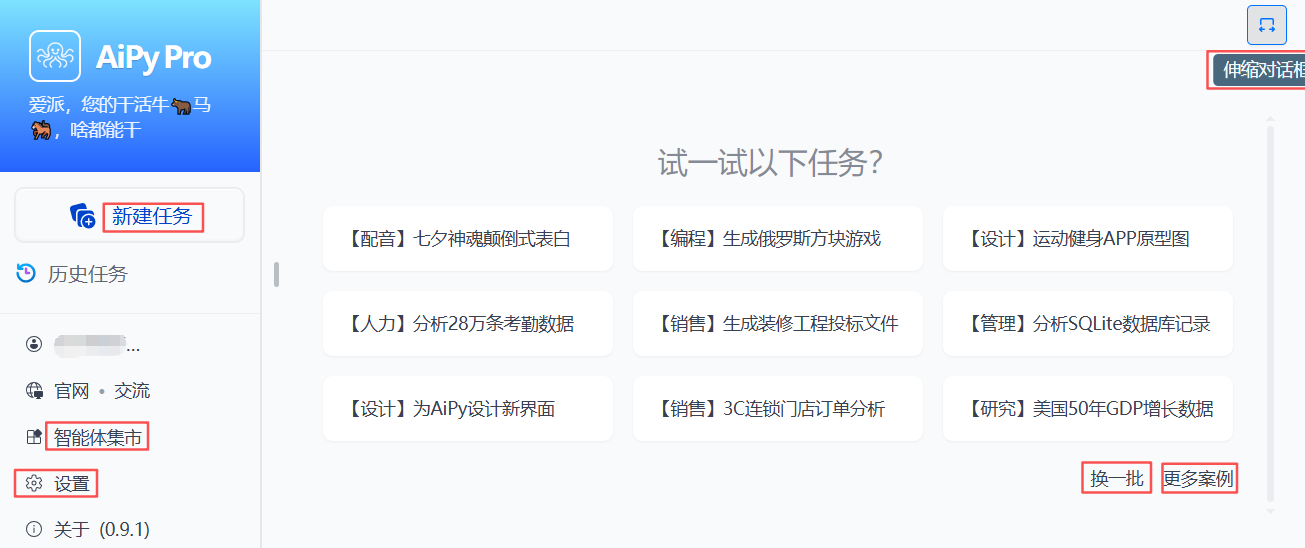
点击【新建任务】
同时右侧出现上下两个窗口,上面是工作目录,默认在C盘用户目录,随机生成一个10位字符作为当前任务的目录,不同任务使用不同目录,确保不互相影响(隔离性)。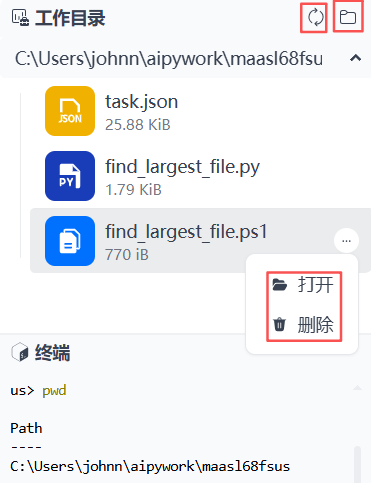
下面是终端命令行工具。
测试问题:找到D盘最大文件?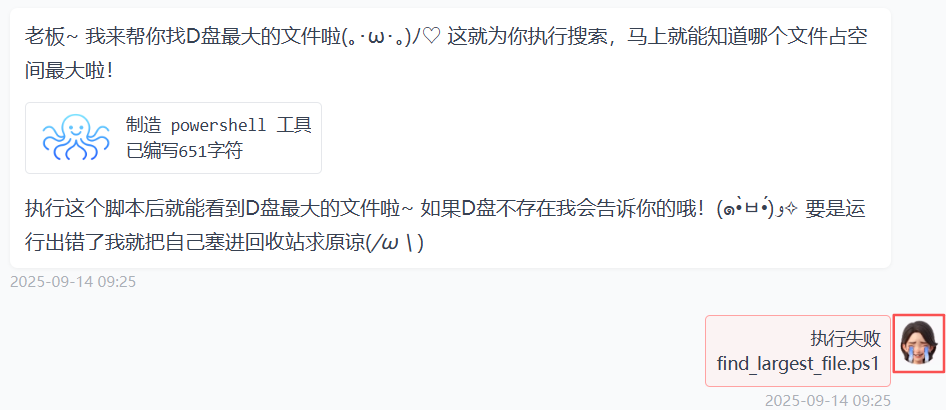
执行失败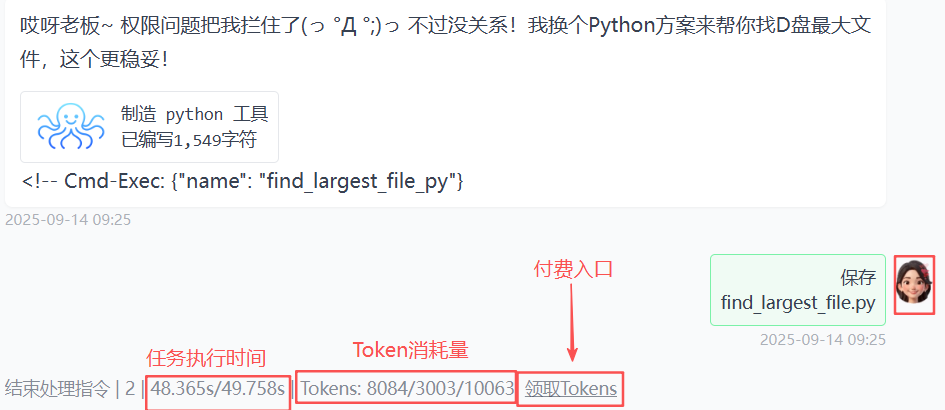
打印输出一大串思考过程(操作系统是Windows等),利用PowerShell执行失败,然后自动切换到Python方案。
迷思:消耗掉一大堆Token,为啥不一开始就使用Python方案呢?官方宣称Python-Use,有点搞不懂。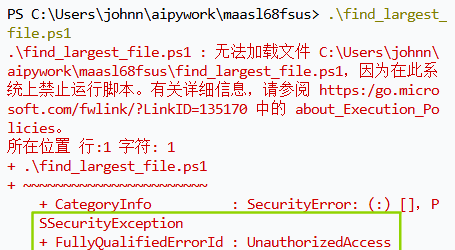
以【管理员】模式打开PowerShell,检查当前执行策略: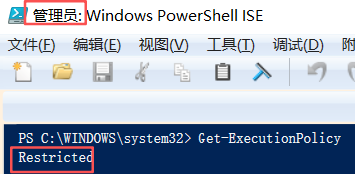
输出Restricted(默认值),表示禁止运行脚本。
嗯,AiPy诚不我欺:没有权限。
【还是以管理员模式】临时更改执行策略:Set-ExecutionPolicy -ExecutionPolicy Bypass -Scope Process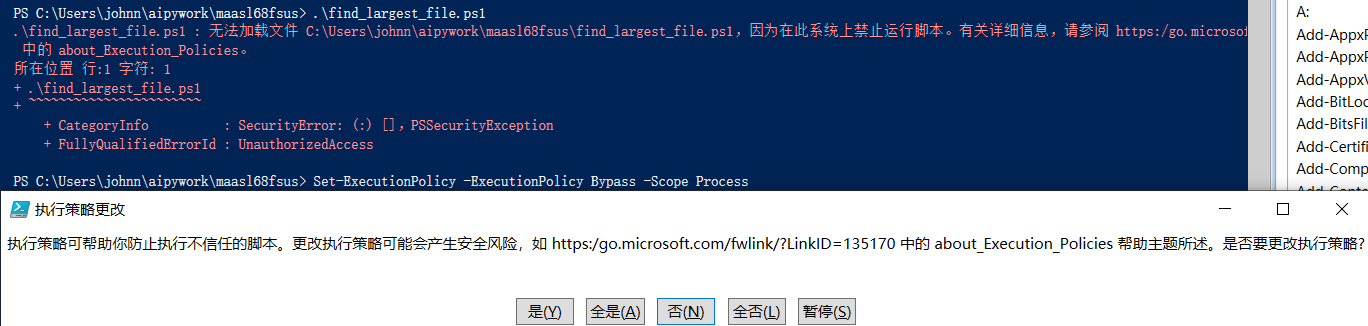
生成的PS1脚本有问题,无法执行。。。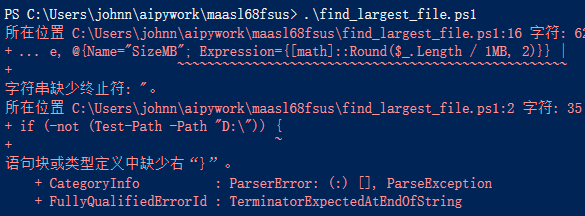
PowerShell ISE打开ps1文件,中文乱码:
报错提示和上面的运行结果一样。
不折腾PS1脚本,来看看Python脚本吧。Python脚本执行完全没毛病!!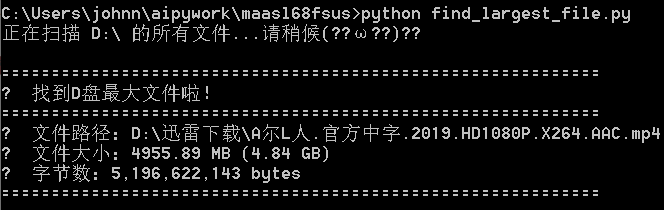
源码如下:
import os
import sys
from pathlib import Path
def find_largest_file(drive_path):
"""找到指定盘符最大文件"""
try:
if not os.path.exists(drive_path):
print(f"错误:{drive_path}不存在或无法访问", file=sys.stderr)
return None
largest_file = None
max_size = 0
print(f"正在扫描 {drive_path} 的所有文件...请稍候(。・ω・。)ノ♡")
# 遍历所有文件
for root, dirs, files in os.walk(drive_path):
for file in files:
try:
file_path = os.path.join(root, file)
if os.path.isfile(file_path):
size = os.path.getsize(file_path)
if size > max_size:
max_size = size
largest_file = file_path
except (OSError, PermissionError):
# 跳过无法访问的文件
continue
return largest_file, max_size
except Exception as e:
print(f"扫描过程中出错:{str(e)}", file=sys.stderr)
return None
# 执行搜索
drive = "D:\\"
result = find_largest_file(drive)
if result:
file_path, size_bytes = result
size_mb = size_bytes / (1024 * 1024)
size_gb = size_bytes / (1024 * 1024 * 1024)
print("\n" + "="*60)
print("🎉 找到D盘最大文件啦!")
print("="*60)
print(f"📁 文件路径:{file_path}")
print(f"📊 文件大小:{size_mb:.2f} MB ({size_gb:.2f} GB)")
print(f"📈 字节数:{size_bytes:,} bytes")
print("="*60)
else:
print("😭 没有找到文件或出现错误,求原谅...")
不过速度非常非常慢,显然和我本地D盘文件过多没有多少关系。
不用花费多少时间,稍微分析下思路,一个方案:从D盘根目录扫描,找到一级目录下最大文件,记录下文件大小;然后利用广度优先搜索,for循环遍历二级目录,检查二级目录大小,小于动态的标记值(即当前最大值),则跳过,大于则需要进行三级目录遍历。
另外,脚本并没有打印出任务执行耗时信息。
原理
除了两个脚本文件,在当前目录还生成一个task.json文件,26K:
{
"instruction": "找到D盘最大文件?",
"start_time": 1757813090.583199,
"done_time": null,
"chats": [
{
"role": "system",
"content": "非常核心,系统提示词,很长,省略",
"reason": null,
"usage": {}
},
{
"role": "user",
"content": "{\"task\": \"找到D盘最大文件?\", \"source\": \"User\", \"context\": {\"operating_system\": {\"type\": \"Windows\", \"platform\": \"Windows-10-10.0.19045-SP0\", \"locale\": [\"Chinese (Simplified)_China\", \"936\"]}, \"command_versions\": {\"node\": \"v22.2.0\", \"bash\": \"5.1.16\", \"powershell\": \"5.1.19041\", \"osascript\": null, \"python\": \"3.12.11\"}, \"today\": \"2025-09-14\", \"TERM\": \"unknown\", \"LC_TERMINAL\": \"unknown\"}, \"constraints\": {\"reply_language\": \"Now, use the exact language of the `task` field for subsequent responses\", \"file_creation_path\": \"current_directory\"}}",
"reason": null,
"usage": {}
},
{
"role": "assistant",
"content": "老板~我来帮你找D盘最大的文件啦。。。",
"reason": "让我分析一下。。。",
"usage": {
"total_tokens": 5402,
"input_tokens": 3962,
"output_tokens": 2464,
"time": 28.296
}
}
],
"runner": [
{
"block": "<CodeBlock name=find_largest_file, version=1, lang=powershell, path=find_largest_file.ps1>",
"result": {
"stdout": null,
"stderr": "...UnauthorizedAccess",
"returncode": 1
}
}
],
"blocks": [
{
"name": "find_largest_file",
"version": 1,
"lang": "powershell",
"code": "...",
"path": "find_largest_file.ps1",
"deps": null
},
{
"name": "find_largest_file_py",
"version": 1,
"lang": "python",
"code": "...",
"path": "find_largest_file.py",
"deps": null
}
]
}
解读:
- 通过第一个
content字段设置非常详细的系统提示词,让模型表现得更聪明; - 第一个
content字段,则搜集本地电脑软件配置及版本号,发送给模型; - 通过多轮
user-assistant对,来完成用户提交的任务; reason字段,只有role=assistant才有可能不为空,不为空则表示模型执行失败,该字段会记录详细的报错原因,会触发下一轮user-assistant对;usage字段也只会出现在role=assistant下,表示模型此次任务执行消耗的Token和时间;- 理论上且原则上
input_tokens+output_tokens=total_tokens,但也不尽然,上面的代码就不成立,原因未知; runner模块记录出错步骤;blocks模块记录任务产出的(多个)代码片段。
设置
回到工具本身,支持两语种,工作目录,自动更新,超时时间,执行轮数,云端同步等,见名知意: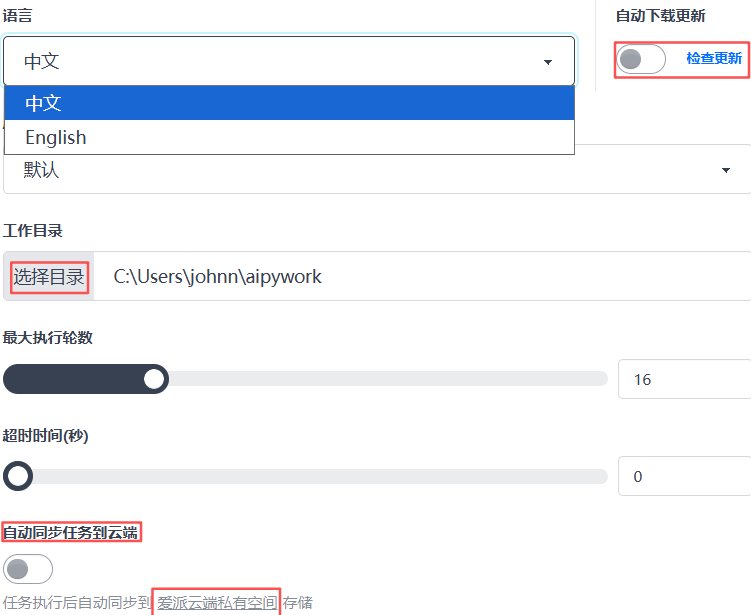
风格设置:
点击【模型】,默认使用TrustToken网关+分发平台。TrustToken集成很多场景下的最佳实践,形成经验库、知识库。在执行任务时,会把用户系统相关的版本信息、环境信息做收集,发给模型和TrusToken,TrusToken负责根据用户环境做最优匹配。
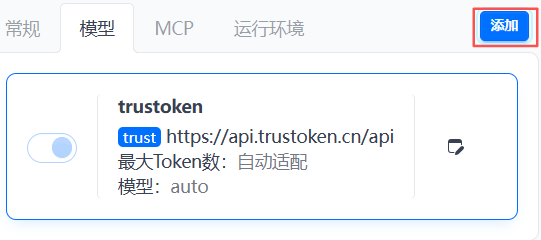
支持添加其他模型提供商:
点击【MCP】,内置联网搜索和地理信息服务(即GIS),正好对应上面聊天窗口截图中所示的两个按钮: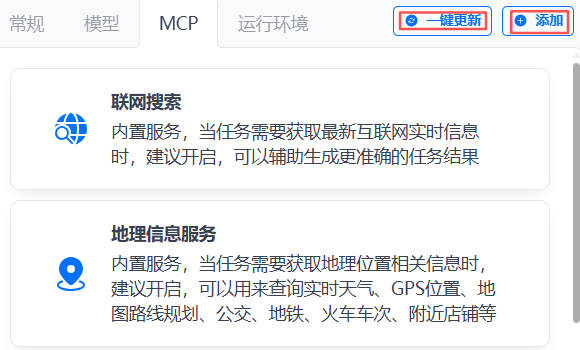
支持新增MCP Server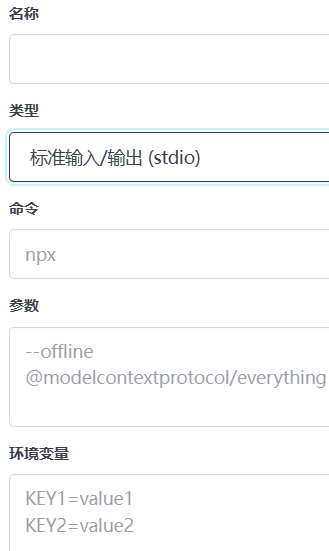
其中类型如下,和Cherry Studio一样:
运行环境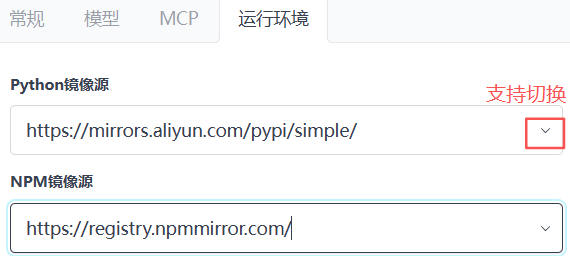
支持切换不同的pip和npm源。
智能体集市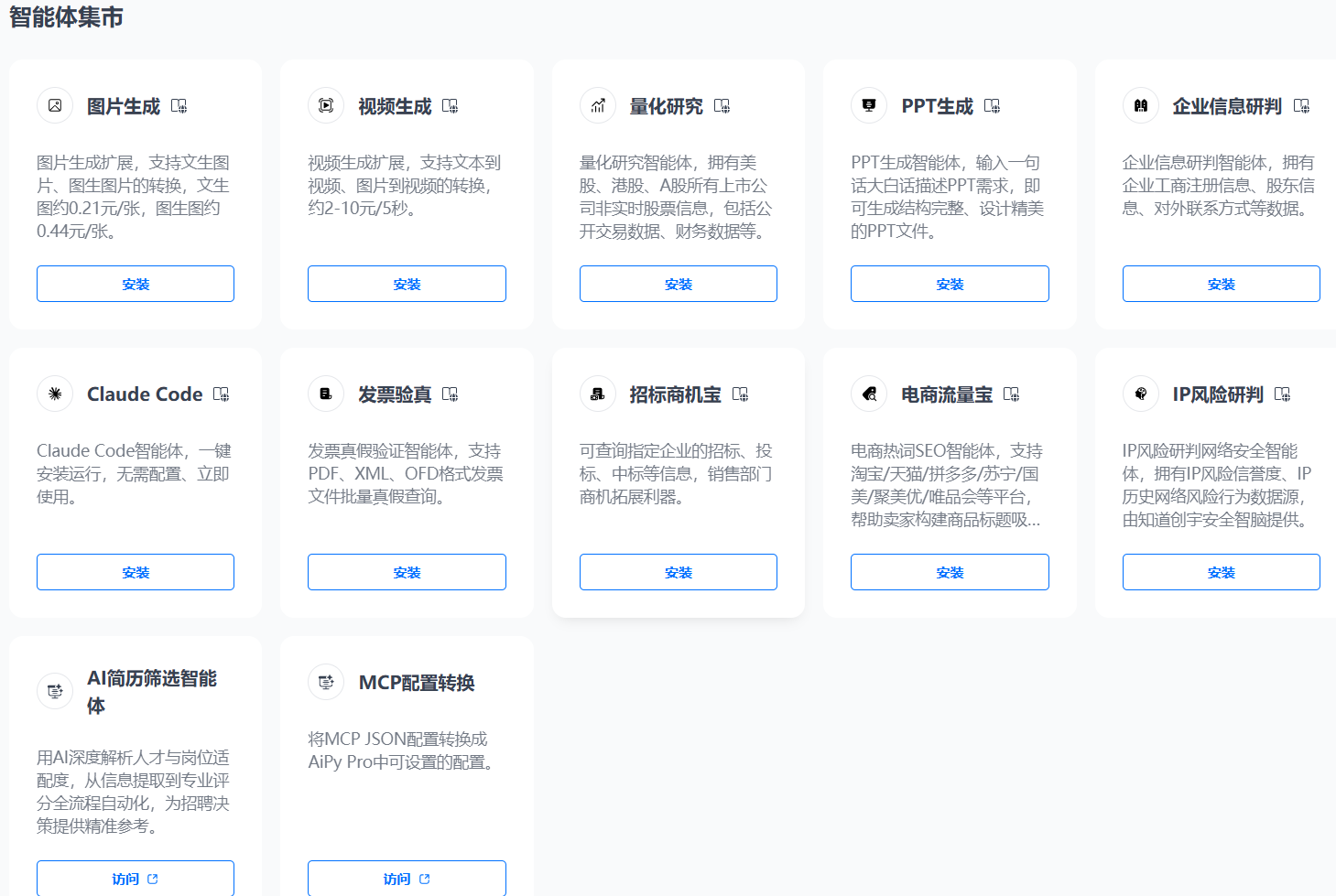
付费
重头戏来了,注册用户自动充值15元,上面的一个简单测试花掉0.47元,还是很快的,搞PowerShell就很费解。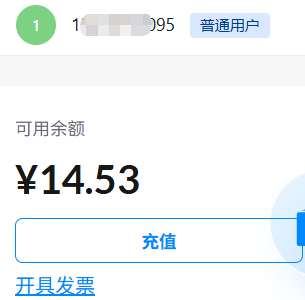
充值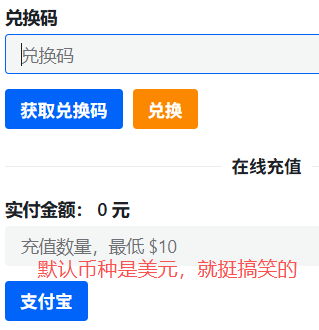
按照美元兑换人民币汇率7.3元。。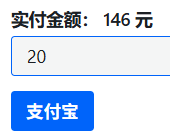
TrusToken
官网给出的定位:AI大模型Tokens统一分发与管理平台。
优势:
- 多模态模型:支持国内外主流大模型,模型种态丰富,支持多模态、文生文、文生图、文生视频等;
- 模型参数智能优化:自动优化客户端提交的模型请求参数,对参数进行自动纠错、对
Max_Tokens等参数自动适配可用最大值、自动补充必要参数等; - 地理服务:集成商用地理搜索服务,可以帮助用户查询当前城市、本地天气、查询周边商圈、制定旅游路线规划、路线查询、距离测量等;
- 联网搜索:集成联网搜索能力,帮助大模型在完成任务时,快获速获取实时资讯、数据与知识,提供更及时可靠的结果;
- 智能调度:全球多个数据中心,先进的智能调度算法,自动选择最优模型和节点,确保全球用户都能获得最佳体验;
- 数据分析:提供详细的用量统计和分析报告,帮助您优化Token使用,降低成本。

【个人中心】的功能都能在AiPy里找到。
控制台还在建设中,打开任务日志,报错如下: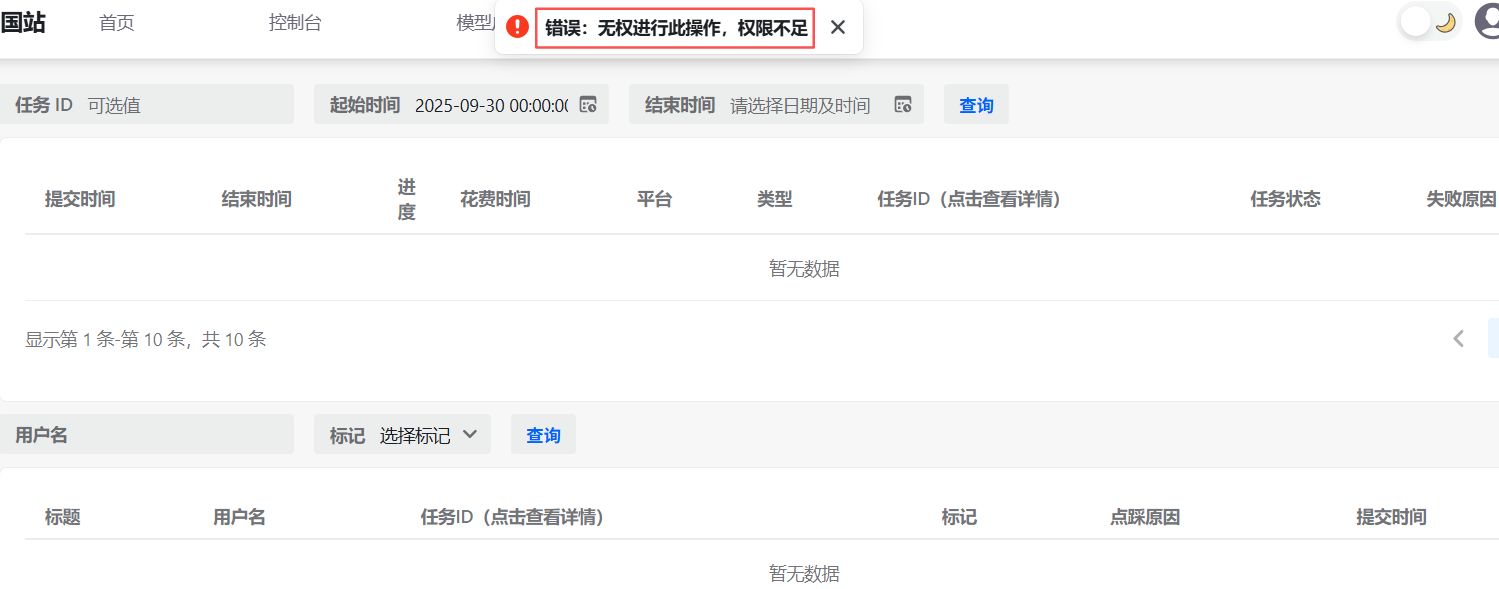
参考

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 4
4 0
0- 0



 已为社区贡献55条内容
已为社区贡献55条内容

所有评论(0)