如何使用Jupyter在LangChain环境下调用本地开源大模型进行问答
首先,我需要在Anaconda下安装配置LangChain环境,还不会搭建LangChain环境的小伙伴可以参考我之前写的文章:LangChain的环境准备及快速实战。
在Anaconda的终端下搭建好LangChain环境后,在终端输入命令:jupyter notebook打开jupyter网页编辑界面。
运行后自动跳转到如图界面:
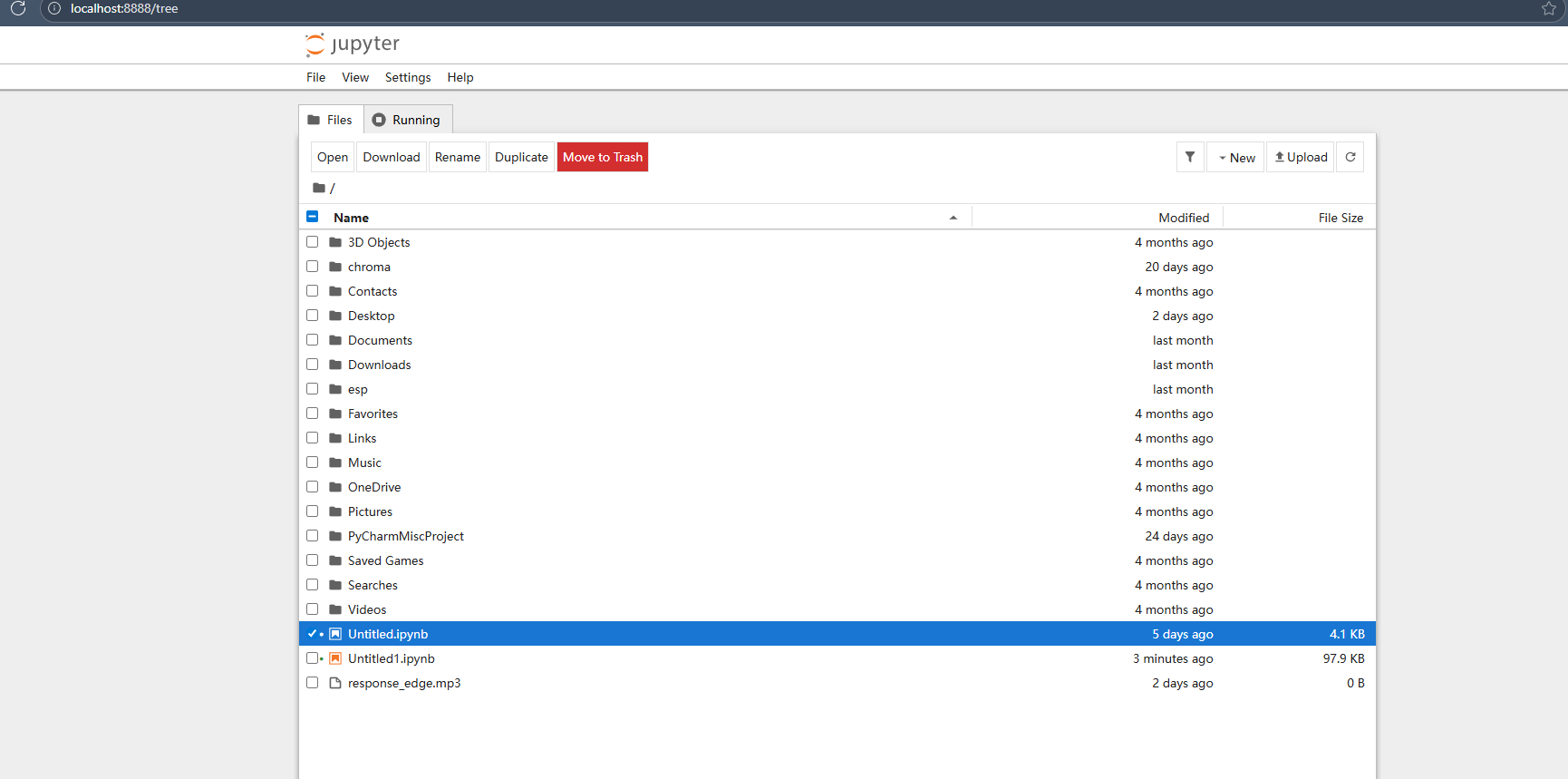
进入界面后,点击右上角New,新建文件并选择自己在conda中创建的内核。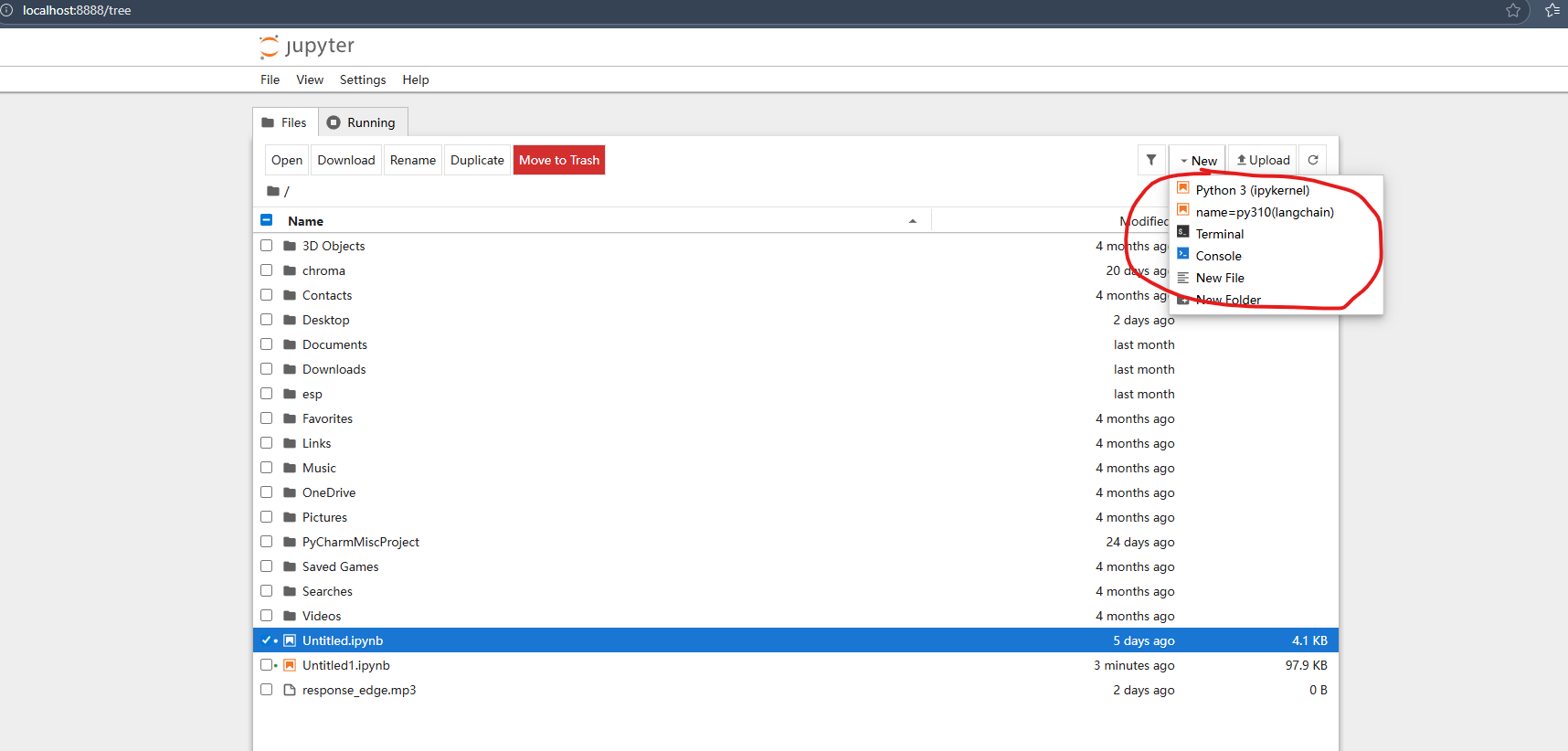
然后,我们需要下载大模型部署到本地。这里我使用LM Studio,LM Studio直接在官网里下就行了,接着在LM Studio中直接下载大模型,load就OK了!
点击顶端的紫色框,搜索大模型即可。

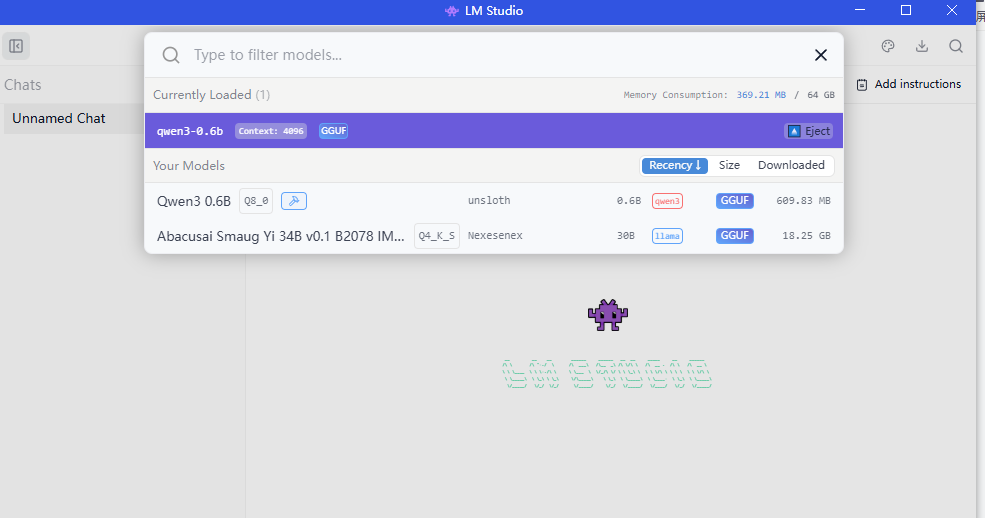
这里我下了一个Qwen3-0.6b的模型和一个Smaug Yi 34B的模型。然后点击最下方的Power User,再点击最上方的"Select a model to load",选择一个模型load。
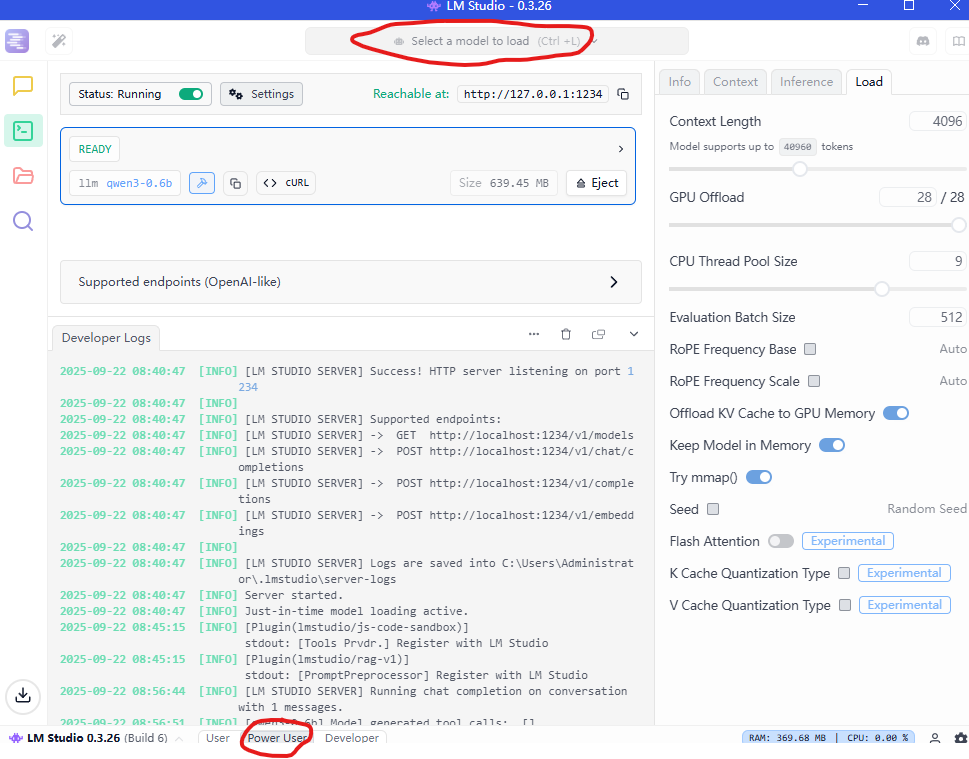
接着我们打开jupyter编辑界面,看看怎么调用本地模型进行问答!
好的,我先做个实践,通过 LangChain 框架调用本地部署的接口模型来回答 "请问 2 只兔子有多少条腿?" 这个问题。
我们顺着"导入依赖->配置API密钥->初始化聊天模型->调用模型并获取回答"这条路线来进行吧!
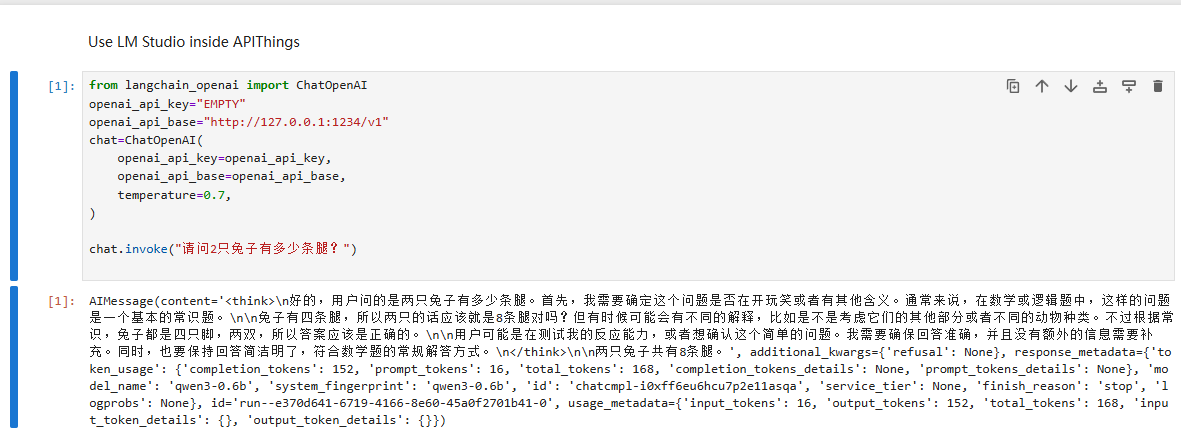 调用本地模型获取回答,运行后会输出类似内容,我们可以看到大模型回答的答案是2只兔子共有8条腿,完全正确!
调用本地模型获取回答,运行后会输出类似内容,我们可以看到大模型回答的答案是2只兔子共有8条腿,完全正确!
接着,我们试着使用提示词模板来让大模型生成一条营销短文。
我们利用 LangChain 的 "链条(Chain)"功能,将 "提示模板→模型调用→结果解析" 三个步骤串联起来,实现了可复用的文本生成流程。通过更换提示模板和主题参数,可以灵活生成不同类型的内容;而invoke和stream两种调用方式,则满足了不同场景下的输出需求(一次性获取 vs 实时展示)。
这里我构建了两条链条:
1.生成娃哈哈酸奶的营销短文
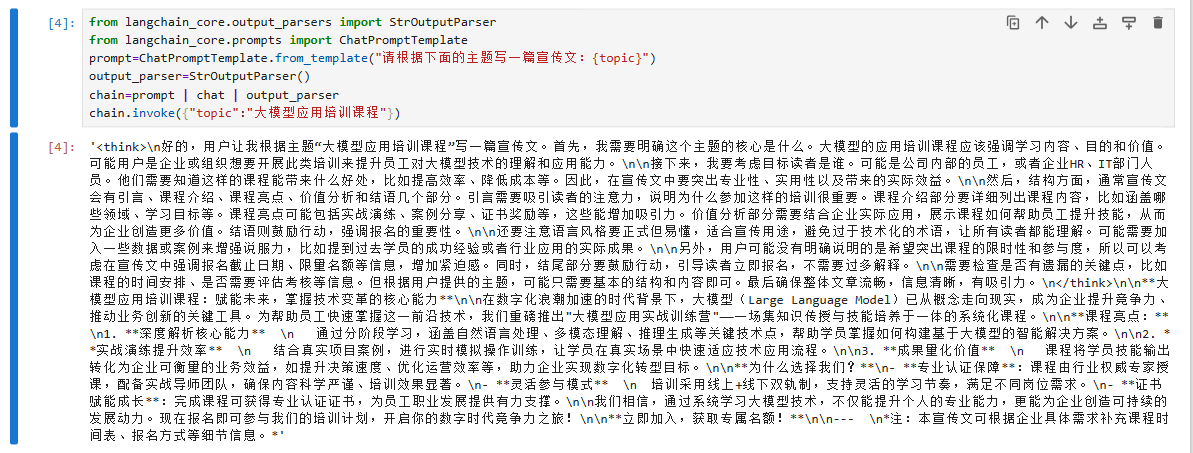
2.生成大模型培训课程的宣传文
在第一条链条中首先进行核心组件导入,然后定义提示词模板,初始化输出解释器,接着构建链条(prompt | chat | output_parser),# "|"是LangChain中链条拼接的语法,代表数据的流转方向,最后调用链条:传入主题"娃哈哈酸奶",生成结果。
我想说明一下为什么要初始化输出解释器?
输出解释器的核心目的是解决"模型原始输出"与"开发者实际需求"之间的格式不匹配问题,简单来说,就是把模型返回的"原始数据"处理成我们能直接使用的"干净结果"。
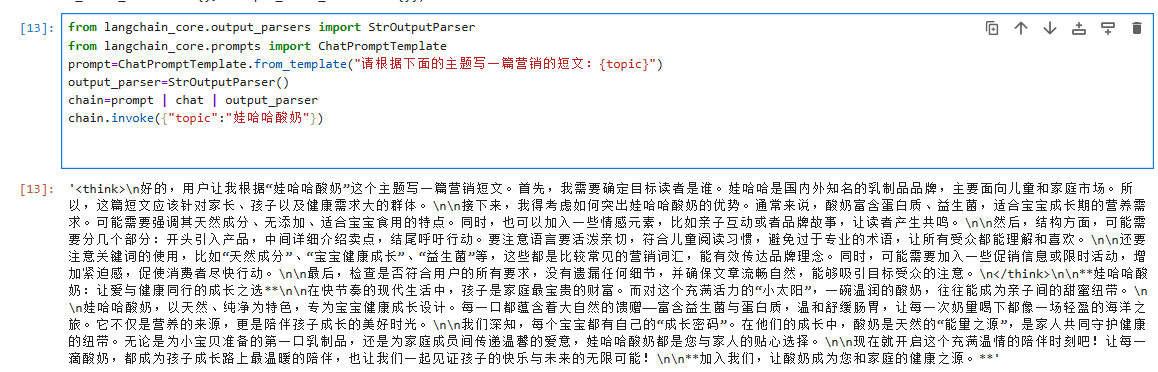
当我们使用chain调用invoke时,首先将{"topic":"娃哈哈酸奶"}传入prompt,生成完整提示(如"请根据下面的主题写一篇营销的短文:娃哈哈酸奶"),然后将提示发送给chat模型(之前定义的本地大模型),最后用output_parser将模型返回的结果转为字符串并返回。
当然,我们也可以使用stream来对输出结果进行处理。

如上图所示,模型在生成内容时,会以"流式"方式逐段返回结果(而非等待全部生成完成),每一段称为一个chunk,通过循环遍历chunk并实时打印,可模拟类似"打字机"的动态输出效果。而且end=""可以确保打印时不自动换行,让内容连续输出。
以上过程我使用文字流程图简单展示一下:
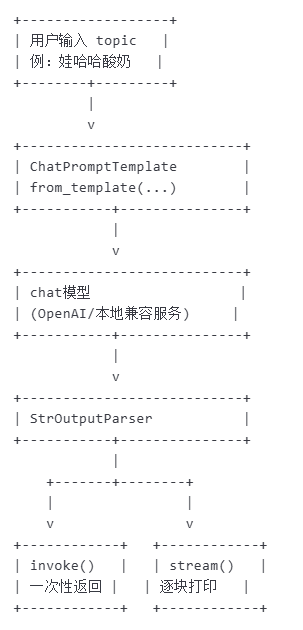
在第二条链条中还是首先进行核心组件导入,然后定义提示词模板,初始化输出解释器,接着构建链条(prompt | chat | output_parser),最后调用链条:传入主题"大模型应用培训课程",生成结果。
我们试着再使用流式输出查看输出结果。

如上图,和我们预期的效果完全一致!
而且,我们在jupyter中运行的过程和结果都能够在LM Studio上显示出来。如下图所示。
综上,我们实现了使用Jupyter在LangChain环境下调用本地开源大模型进行问答!
后续我会继续更新相关内容,请大家持续关注呀!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 23
23 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)