【跟我学YOLO】MOCHA:让YOLO实现少样本学习
MOCHA(Multi-modal Objects-aware Cross-arcHitecture Alignment)是一种面向少样本个性化目标检测的多模态跨架构知识蒸馏方法,核心是将大型视觉语言模型(VLM)的区域级多模态语义迁移到轻量级纯视觉目标检测器中。本文将大型 Transformer-based 视觉语言教师模型(如 LLaVa-1.5-7B)的语义知识,高效迁移到轻量级 CNN-b
欢迎关注『跟我学 YOLO』系列
【跟我学YOLO】MOCHA:让YOLO实现少样本学习]
0. MOCHA 论文概况
0.1 基本信息
2025年9月,三星英国研究院和 Padova 大学的研究者 Elena Camuffo 等发表论文《MOCHA:面向多模态对象的跨架构对齐方法(MOCHA: Multi-modal Objects-aware Cross-arcHitecture Alignment)》 。
本文提出一种多模态跨架构知识蒸馏方法,MOCHA(Multi-modal Objects-aware Cross-arcHitecture Alignment)是一种面向少样本个性化目标检测的多模态跨架构知识蒸馏方法,核心是将大型视觉语言模型(VLM)的区域级多模态语义迁移到轻量级纯视觉目标检测器中。
首次将大型 Transformer-based 视觉语言教师模型(如 LLaVa-1.5-7B)的语义知识,高效迁移到轻量级 CNN-based 目标检测器(如 YOLOv8n)中,无需修改教师模型结构,解决了 “大模型语义能力” 与 “小模型部署效率” 的矛盾。
论文下载:Arxiv
引用格式:
E. Camuffo et al., “MOCHA: Multi-modal Objects-aware Cross-arcHitecture Alignment”, arXiv preprint arXiv:2509.14001v2, 2025.

图1:MOCHA方法流程。(1) 学生模型预训练阶段;(2) 基于冻结教师模型提取的多模态视觉-文本联合特征进行知识蒸馏;(3) 在冻结学生模型基础上结合原型学习器进行小样本个性化适配
0.2 主要贡献
-
对象级跨架构多模态蒸馏
MOCHA 提出对象级别的跨架构蒸馏范式,实现了三大突破:架构异构性适配,推理高效性,少样本泛化增强。 -
核心组件与技术创新
MOCHA 在蒸馏流程、特征处理、损失函数设计上提出多项关键技术,确保多模态语义的有效迁移与对齐- 多模态监督提取:视觉 - 语言联合表示优化
- 特征翻译模块:学生 - 教师空间对齐桥梁
- 双目标损失函数:局部对齐与全局关系一致性
- 三阶段训练流程:从预训练到个性化
MOCHA 为 “多模态大模型知识迁移到轻量级检测器” 提供了可复用范式,其创新点可扩展至其他视觉任务(如语义分割、实例检索),同时为 “个性化计算机视觉” 提供了高效解决方案 —— 无需依赖用户端的大模型部署,仅通过服务器端蒸馏即可让轻量级设备具备 “用户专属对象识别” 能力。
0.3 论文摘要
MOCHA:面向多模态对象的跨架构对齐方法
我们提出MOCHA(多模态对象感知的跨架构对齐),这是一种知识蒸馏方法,能够将大型视觉-语言教师模型(如LLaVa)中的区域级多模态语义迁移至轻量化纯视觉目标检测学生模型(如YOLO)。该方法通过翻译模块将学生模型的特征映射至联合嵌入空间,并采用双重目标损失函数指导学生模型与翻译模块的训练,同时强化局部特征对齐与全局关系一致性。
相较于现有专注于密集匹配或全局对齐的方法,MOCHA在对象层级进行操作,无需修改教师模型架构或推理阶段的文本输入即可实现高效的语义迁移。我们在四个小样本个性化检测基准上验证了该方法,实验结果显示其性能始终优于基线模型,平均得分提升达+10.1。尽管采用紧凑型架构,MOCHA达到了与大型多模态模型相当的检测性能,证实了其在实际部署场景中的适用性。
1. 引言
最近,视觉语言模型(VLMs)如 CLIP(Radford et al. 2021)、Flamingo(Alayrac et al. 2022)和 LLaVa(Liu et al. 2023a)的进步展示出了显著的零样本和开放词汇能力,这得益于它们丰富的表示能力和规模。然而,这些模型通常庞大且计算密集,限制了它们在实时或资源受限场景(如移动设备,例如智能手机或机器人)中的应用。相比之下,轻量级架构如 YOLO(Jocher, Chaurasia, and Qiu 2023)提供了快速且内存高效的物体检测能力,但在数据量较少的情况下性能会下降,并且容易受到神经坍塌(Kothapalli 2022;Papyan, Han, and Donoho 2020)的影响,即特征变得难以区分,丧失了辨别力。
在这项工作中,我们旨在通过提出 MOCHA(多模态知识蒸馏方法)来弥合这一差距,该方法将视觉语言教师(例如LLaVa)的物体为中心的多模态嵌入转移到一个紧凑的仅视觉学生检测器中。MOCHA 利用了语义相关概念在良好泛化的骨干结构下不同模态的嵌入空间中表现出相似结构的性质(Huh et al. 2024;Girdhar et al. 2023;Camuffo, Michieli, and Milani 2023)。通过对学生的特征空间进行对齐和正则化,它在少量样本检测设置中展示了改进的泛化能力(图1)。
我们的方法基于三个阶段,包括:
- 学生模型的预训练;
- 从冻结的教师模型中丰富的联合视觉和文本特征的知识蒸馏;
- 基于冻结的学生模型和原型分类器的少量样本个性化。
我们的贡献主要集中在知识蒸馏阶段,其中我们引入了以下内容:
- 从冻结的教师模型中提取条件于图像区域和类别标签的丰富联合视觉-语言表示;
- 一个转换模块,将学生的特征映射到教师的多模态空间;
- 一个结合局部对齐与区域间关系嵌入正则化的蒸馏目标。
我们在个人物体检测数据集上验证了 MOCHA,目标是将通用检测器适应用户特定的个人类别(例如,区分通用狗和特定用户的狗)。MOCHA 在保持最小推理成本的同时显著优于现有方法,使其适用于资源受限的部署。
2. 相关的工作
1. 跨架构知识蒸馏。
传统知识蒸馏方法(Romero et al. 2015;Zhang et al. 2020;Passalis, Tzelepi, and Tefas 2020;Luo et al. 2019;Gou et al. 2024;Hao et al. 2022;Li et al. 2024;Tu et al. 2025)通常假设教师和学生网络具有相似的架构。采用大型基于变换器的模型(Vaswani et al. 2017;Dosovitskiy 2020;Devlin et al. 2019;Liu et al. 2021)为高效卷积神经网络(CNNs)的知识转移带来了新的挑战,这些模型在部署中提供了更好的权衡。最近的研究(Liu et al. 2022;Hao et al. 2023)通过将教师和学生网络的多尺度特征投影到共享空间进行监督,解决了这一问题,这类似于基于捷径的策略(Szegedy et al. 2014;Lee et al. 2014),以提高收敛稳定性。
这些方法主要旨在提高教师和学生共享的任务上的性能。相比之下,我们的方法更接近于AuXFT(Barbato et al. 2024b),它利用教师特征引导学生完成相关辅助任务,而不损害原始任务的性能。具体而言,AuXFT 通过将高级教师特征注入轻量级检测器来支持原型分类,解决了少量样本实例级个性化物体检测问题。
我们的方法在三个方面有所不同:(i)我们利用来自视觉和文本信号的多模态监督,而不是先前研究中仅使用的纯视觉线索;(ii)我们蒸馏紧凑的区域级嵌入而非密集的中间激活,提高了效率;(iii)我们显式正则化嵌入空间,以鼓励个体实例之间的几何和关系对齐。
2. 跨模态适应。
已经提出了多种跨模态学习策略,以利用不同模态之间的互补信息(Xia et al. 2023;Barbato et al. 2024a),或将不同模态预测之间的一致性强制执行(Jaritz et al. 2022, 2020)。
在我们的工作中,我们将视觉语言模型中的丰富多模态语义转移到一个紧凑的学生检测器中,以将多模态先验嵌入到轻量级架构中。
3. 个性化场景理解。
个性化最初是在自然语言处理(NLP)中探索的(Liu et al. 2023a;Vaswani et al. 2017;Devlin et al. 2019)。后来,它扩展到了计算机视觉领域,早期应用包括个性化语义分割(Zhang et al. 2021)和物体检测(Michieli et al. 2024)。基础模型如CLIP(Radford et al. 2021)和SAM(Kirillov et al. 2023)的出现促使个性化策略转向通用架构的提示控制(Meng, Xia, and Ma 2024)。例如,ViLD(Gu et al. 2022)对视觉和语言嵌入进行对齐,以实现开放词汇检测,为通过文本提示实现实例和用户感知预测铺平了道路。同样,SwissDINO(Paramonov et al. 2024)、PerSAM(Zhang et al. 2024)、Matcher(Liu et al. 2023b)和SegGPT(Wang et al. 2023)利用提示调优和强大的视觉表示来定制预测以满足用户偏好。
我们的工作则在服务器端训练期间将丰富的语义特征蒸馏到一个紧凑的检测器中,避免依赖提示或在线适应,从而实现资源受限部署的高效少量样本个性化。
3. 方法
MOCHA(多模态物体感知跨架构对齐)通过对齐区域级嵌入和正则化学生特征空间,将视觉语言基础模型中的多模态语义转移到一个轻量级的学生检测器中。MOCHA 提高了少量样本个性化检测中的特征可分性和泛化能力。我们的方法是架构无关的,并结合了多模态监督、特征转换和双重损失,强制执行局部和关系对齐。
3.1 问题设定
MOCHA 包含三个阶段,如下所述。
-
基础预训练。
我们从一个标准检测模型 mS(·) = lS ◦ gS 开始,其中 lS(·) 是检测头,gS(·) 是学生骨干,◦ 是复合操作符。我们使用标准检测目标 Ldet(Jocher, Chaurasia, and Qiu 2023)在预训练检测数据集上对其进行训练。这一阶段产生了一个强大的通用检测器,能够识别广泛的物体类别,但缺乏个性化的语义或细粒度的嵌入分离,作为学生权重的初始化。 -
特征蒸馏。
在初始化后,我们使用一个冻结的大型视觉语言模型作为教师,在一个物体检测数据集 Dc 上进行特征蒸馏(图2a)。数据集中每个图像 X ∈ Dc 由一个集合 {(bi, ci)}ni=1 ⊂ B × Cc 标记,其中 ci ∈ Cc 是类别标签,bi ∈ B ⊂ R4 是标识 n 个图像区域 Xi 的框坐标。假设教师包括视觉编码器 gT(·) 和大型语言模型 fT(·),能够联合处理图像和文本。请注意,通常学生和教师的特征可能不对齐。因此,我们使用一个特征转换模块 tS(·) : Rds → Rdt(其中 ds 和 dt 分别是学生和教师特征的维度),以允许从学生的空间转移到教师的空间的知识蒸馏。 -
少量样本个性化。
在特征蒸馏后,学生骨干被冻结并用于从个人检测数据集 Df 中提取多尺度区域级特征 {Fj}j = gS(X),该数据集带有边界框 B 和类别标签 Cf。这些特征通过冻结的转换模块(图2b)翻译成共享嵌入空间,并传递给基于原型的少量样本学习器 p(·),如最近类均值(Snell, Swersky, and Zemel 2017),并按照 (Barbato et al. 2024b) 中的方法进行训练和测试。具体而言,在个性化过程中,用户向系统提供少量个人物体实例的标记样本(例如,1-5 个样本)。在推理过程中,系统自动用个人标签覆盖粗略预测。这种策略使学生能够保留其紧凑的架构并适应新的视觉概念。由于在个性化过程中不需要教师推理或提示工程,该方法高效且适用于现实世界的低资源部署。
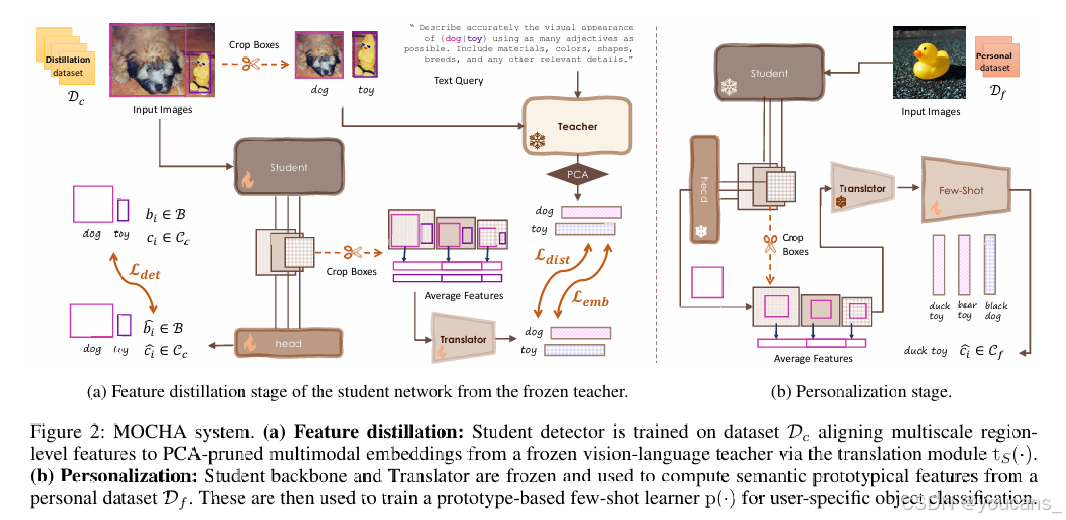
图2:MOCHA系统框架。
(a)特征蒸馏阶段:在数据集Dc上训练学生检测器,通过翻译模块 ts(·) 将多尺度区域层级特征与冻结视觉语言教师生成的PCA修剪多模态嵌入进行对齐。
(b)个性化阶段:冻结学生骨干网络及翻译模块,利用个人数据集 Df 计算语义原型特征,并据此训练基于原型的小样本学习器p(·),最终实现用户特定目标的分类任务。
3.2 多模态监督提取
不失一般性,在我们的实验中,我们将教师实例化为一个 LLaVa(Liu et al. 2023a)模型,该模型除了 gT(·) 和 fT(·) 之外,还包括一个共享投影矩阵 WT。每个裁剪的图像区域 Xi 由教师的视觉编码器处理以获得视觉嵌入 ZV,i,并投影到联合文本-视觉表示空间中,即 HV,i = WTZV,i。同时,类别标签 ci 被嵌入为文本查询 ZQ,i,并通过 HQ,i = WTZQ,i 投影。对 (HV,i, HQ,i) 对传递给冻结的语言模型 fT,该模型计算描述区域与类之间交互的一系列标记。我们沿时间维度对输出求平均,以获得表示区域 Xi 的融合视觉-语言描述的单个语义嵌入 hi ∈ Rdh。
维度降维。尽管教师的多模态特征 hi 捕获了丰富的语义信息,但它不一定保留外观级别的线索。为了结合语义和视觉信号,我们将多模态表示与对应视觉嵌入的 dz 维类标记 zV,i ∈ ZV,i ⊂ Rdz 进行连接: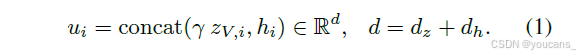
其中 γ = ||hi|| 作为缩放因子,将视觉特征归一化为文本特征。这个组合向量同时表示对象的原始视觉内容及其基于标签的语义解释。然而,结果表示仍然是高维度的,并且可能包含冗余信息。为了降低维度并提高效率,我们在与蒸馏使用的同一数据集上离线应用主成分分析(PCA),并取前 dt 个元素:
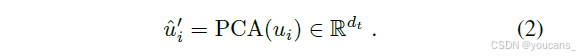
最后,为了使 PCA 表示中每个通道的贡献相等,我们估计蒸馏数据集中每个通道激活的标准差 σc,并使用它来缩放通道,公式为:
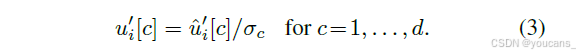
值得注意的是,偏差紧密遵循双曲线形状,使得我们仅根据通道索引即可估计其值(详细讨论见附录)。
3.3 学生检测器和特征聚合
为了进行对象级监督,我们应用与教师相同的裁剪策略:对于每个真实边界框 bi,我们首先将特征图调整到一个共同的大小,以考虑分辨率差异,确保空间对齐一致。然后,我们从每个分辨率级别 j 中提取相应的区域对齐特征 FA,j,i,并应用空间平均池化以获得固定大小的描述符 fA,j,i ∈ Rds。
区域 i 的最终聚合特征由每个级别的池化表示:
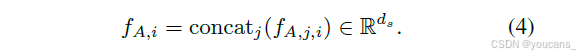
我们用 FA 表示这些特征的密集等价物,即在不进行区域池化的情况下将它们连接起来。
不损失泛化能力,我们采用 YOLOv8(Jocher, Chaurasia 和 Qiu 2023)作为在 COCO 数据集(Lin 等人 2014)上预训练的学生模型,并在 MOCHA 中进行微调。
特征翻译模块。
翻译模块 tS 模仿了变压器编码器块,并由通道内多头自注意力块和轻量级多层感知机(MLP)依次组成。注意力机制通过建模通道间依赖关系来增强表达能力,而 MLP 适应所需的维度:
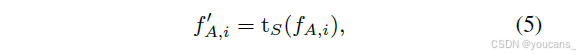
其中 f′A,i ∈ Rdt 是与 PCA 压缩后的教师目标 u′i 维度相同的翻译后学生特征。
在我们的实现中(图 2a),翻译模块与学生检测器一起训练,允许特征对齐在蒸馏过程中逐步进化。
3.4 训练目标与策略
为了使翻译后的学生特征与教师目标对齐,我们定义了两个互补的目标:点wise蒸馏损失和关系嵌入损失。
1. 蒸馏损失。
主要目标强制直接对齐翻译后的学生特征 f′A,i 与其相应的教师向量 u′i。我们将蒸馏损失定义为 ℓ1 和 ℓ2 距离的平均值,如 (Barbato 等人 2024b) 所示:
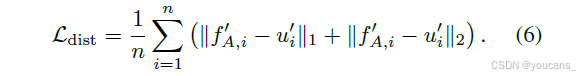
这种表述通过 ℓ1 项捕获了对离群值的鲁棒性,并通过 ℓ2 项促进了精细的幅度对齐,从而促进稳定且具有区分性的对齐。
2. 嵌入损失。
除了个体对齐外,我们鼓励学生保留教师嵌入空间的全局几何结构。为此,我们基于所有学生和教师特征之间的成对欧几里得距离定义了关系嵌入损失。
给定翻译后的学生特征 {f′A,i}i 和相应的教师目标 {u′i}i,我们计算两个成对距离矩阵 Dff 和 Duu。我们使用温度缩放的 softmax 将它们转换为归一化分布:
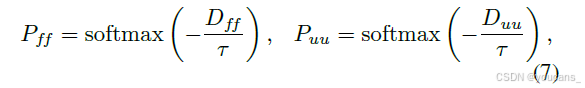
其中 τ 是控制分布锐度的超参数。嵌入损失随后定义为两个分布之间的交叉熵:
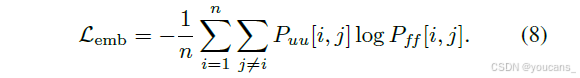
该项确保学生不仅保留语义内容,还保留嵌入空间的相对结构,反映了教师编码的类间和类内关系。
3. 最终目标。
最终目标将检测损失与蒸馏和嵌入项结合起来:
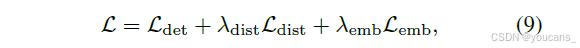
其中 λ 系数调节每个辅助项的贡献。通过结合多模态特征监督和结构正则化,MOCHA 能够在紧凑检测器中实现稳健的语义转移,提高在低资源和个性化场景中的性能。
4. 实验
在本节中,我们介绍了实验设置,以测试 MOCHA 有效将多模态教师的知识传递给轻量级学生模型的能力,目标是在四个个性化数据集中实现稳健的少量样本个性化对象检测性能。我们首先讨论一般分析,然后与最先进的方法进行比较,并最终呈现消融研究。
4.1 实验设置
数据集。
对于预训练,我们采用 COCO (Lin 等,2014) 和 OpenImagesV7 (Kuznetsova 等,2020)。此外,我们考虑从预训练的 AuXFT 权重开始(这些权重从 COCO 细化到 OpenImages)。蒸馏在 OpenImages 上进行。考虑的个性化数据集有:PerSeg (Zhang 等,2024),POD (Barbato 等,2024b),CORe50 (Lomonaco 和 Maltoni,2017),以及 iCubWorld (Fanello 等,2013)。
模型。
我们的方法使用 YOLOv8n 作为学生模型,LLaVa-1.5-7B 作为教师,其中包括 CLIP 作为视觉编码器(使用 ViT-B/32)和 LLaMA 7B 作为文本编码器。为了进行比较,我们还包括:(i) LLaVa 的文本编码器,即 LLaMA 7B;(ii) LLaVa 的视觉编码器,即 CLIP;(iii) DINOv2 (Oquab 等,2023)。此外,我们还与其他基于蒸馏的方法进行了比较:OFA (Hao 等,2023),通过 KL 散度在输出空间进行知识蒸馏 (KL) (Touvron 等,2021),以及与 MSE 融合的嵌入空间蒸馏 (MSE + KL) (Romero 等,2015),开放式词汇检测器 (VILD) (Gu 等,2022),以及迄今为止最相关的个性化方法 (AuXFT)。
度量标准。
为了保持一致性和公平比较,我们遵循 AuXFT 中相同的实现细节,除非是从 AuXFT 预训练模型进行蒸馏。在这种情况下,蒸馏的 epochs 数从 50 减少到 20,因为收敛时间缩短了。我们还采用相同的评估指标:PerSeg 和 POD 的 mAP50-95,以及 CORe50 和 iCubWorld 的检索精度。少量样本个性化检测在 1-和 5- shot 环境下进行。
4.2 分析
嵌入损失。
图 3 显示了我们的关系嵌入损失 Lemb 对保留教师特征的几何结构到学生特征的影响。我们考虑了一个玩具设置,其中我们优化一组 2D 点(代表学生嵌入 f′A,i)的坐标,使其匹配固定 3D 参考配置(代表教师嵌入 u′i)的成对距离分布。
图 3a 显示了均匀采样的 3D 参考点。图 3b 在 2D 空间中可视化了优化轨迹:每条路径从初始位置(标记为 ⋆)开始,并在 Lemb 的引导下逐渐适应,保持局部邻域关系,同时全局重新排列以逼近原始距离几何(颜色饱和度表示时间演化)。
图 3c 定量跟踪了邻域结构的对齐情况。我们报告了 2D 最近邻中与参考 3D 分布匹配的比例。我们观察到所有 k 的比例都稳步提高,并且收敛速度很快。这一分析证实了关系监督在点对点对齐之外正则化学生嵌入空间的作用,最终促进了特征多样性和语义可分性。
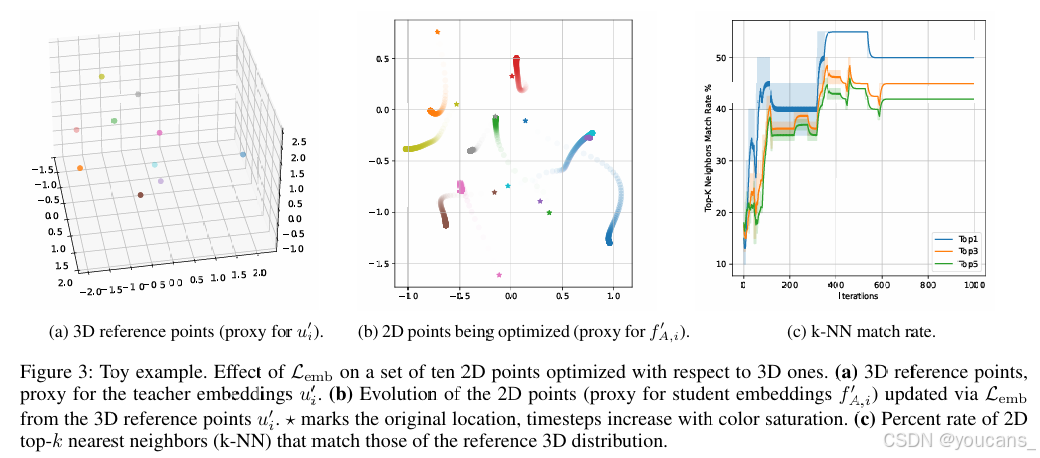
图3:示例说明。Lemb对10个2D点(相对于3D点进行优化)的影响效果。(a) 3D参考点(作为教师嵌入u′i的代理);(b) 通过Lemb从3D参考点u′i更新的2D点(作为学生嵌入f′A,i的代理)的演化过程。⋆标记初始位置,时间步长随色彩饱和度增加;© 2D点与参考3D分布在top-k近邻(k-NN)上的匹配百分比。
教师特征维度的影响。
图 4 通过比较特征:(i) 个性化数据集 Df(作为上限),(ii) 蒸馏数据集 Dc 未归一化,以及(iii) PCA 归一化(附加细节和验证见附录),评估了教师监督维度 (dt) 的作用。总体而言,性能稳步提高,直到 dt = 512,这在紧凑性和表达性之间达到了良好的平衡。之后,性能在最大维度 d = 4608 时趋于平稳或略有下降。这表明大部分相关语义在紧凑子空间中得到了保留,而进一步的维度可能会引入冗余或噪声。归一化特征 u′i 一致地优于其未归一化的对应物 ˆu′i(特别是在 1- shot 设置中),即使与个性化数据集的特征相比,也能获得更好的性能。
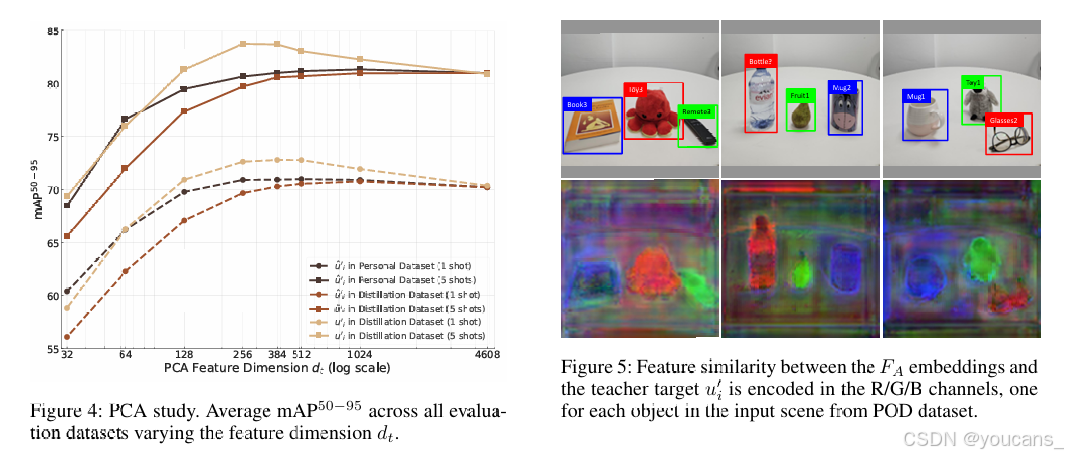
图4:PCA维度研究。显示不同特征维度dt下所有评估数据集的平均mAP50−95性能指标。
图5:FA嵌入与教师目标u′i之间的特征相似性以R/G/B通道编码,分别对应POD数据集中输入场景的各个对象。
特征相似性。
图 5 显示了每个场景中三个对象的教师视觉-语言描述符 u′i 与学生模型 FA 输出的特征之间的相似性。每个底部图像中的三个相似性矩阵分别在红/绿/蓝通道中可视化,显示 MOCHA 成功地将稀疏的 VLM 对象级特征(位于对象框内)映射到高效检测器的密集特征中。
4.3 主要结果
我们首先在 oracle 设置中进行评估,其中模型在少量样本个性化阶段使用真实边界框进行评估。
这种设置去除了检测头,专注于每种方法的分类能力,使我们能够比较不同的教师模型和监督嵌入类型(语言、视觉和多模态)。表 1 按两部分结构化。顶部部分报告了在个性化阶段直接使用教师嵌入的结果,而底部部分展示了使用相同监督信号蒸馏的 YOLO 模型。在第一部分中,视觉教师表现出色。值得注意的是,CLIP 的表现优于 AuXFT 中使用的 DINO。另一方面,LLaVa 的特征 (hi) 表现较差,但将它们与 CLIP 特征 (zV,i) 结合使用(即,使用 ui 进行监督)带来了显著的收益,且无额外成本(因为 CLIP 已包含在 LLaVa 中),这表明视觉和文本线索的互补性。归一化视觉特征也略微优于其未归一化的版本(γ = 1)。在第二部分中,我们使用视觉监督(CLIP,zV,i)、文本监督(LLaVa,hi)或它们的结合(LLaVa,ui)评估蒸馏。所有模型均通过 MOCHA 监督进行蒸馏,显示出与非蒸馏基线(仅 YOLO)相比,我们方法的一致性收益。然而,单独使用单一模态的效果不如利用完整多模态监督的效果。
表1:在个人数据集上使用真实标注边界框的Oracle实验结果。顶部区块:个性化阶段直接使用冻结教师嵌入时的性能表现。底部区块:采用教师信号蒸馏的YOLO模型的性能表现。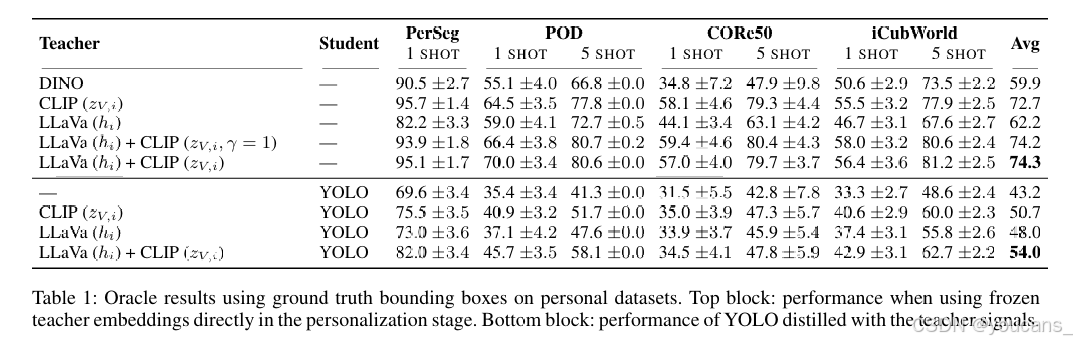
比较。
然后我们在标准少量样本个性化设置(不使用真实边界框)中评估完整的系统,包括主干网络和检测头。
表 2 显示了 MOCHA 与近期个性化检测方法的比较。在基于蒸馏的方法中,KL 散度和 OFA 只能提供微小的性能改进,而将 KL 与 MSE 结合使用则提供了稍微更好的性能。ViLD 在高度个性化的情景中表现不佳,尽管它具有开放词汇表的能力。AuXFT 在先前方法中取得了最强的平均性能,但在更具挑战性的领域(如 PerSeg 和 POD)中仍然表现不佳,这些领域需要精细的语义对齐。相比之下,MOCHA 在所有数据集和设置中表现出一致的强劲结果,相对于 YOLO 基线平均提高了 +10.1 分,并且相对于最佳竞争对手 AuXFT 提高了 +4.9 分。从 COCO 预训练权重蒸馏时,MOCHA 已经超过了最先进的方法的性能。从 AuXFT 预训练权重开始,进一步提高了性能,这证实了初始化的兼容性和有效性。总体而言,结果验证了 MOCHA 在将冻结的视觉-语言模型中的高层语义转移到紧凑检测器中的有效性,使其在少量样本约束下实现稳健的个性化。
表2:个人数据集上的小样本个性化检测结果。首行:未使用蒸馏的YOLO基线模型。首区块:MOCHA与现有最先进监督方法的对比结果。次区块:不同MOCHA变体的评估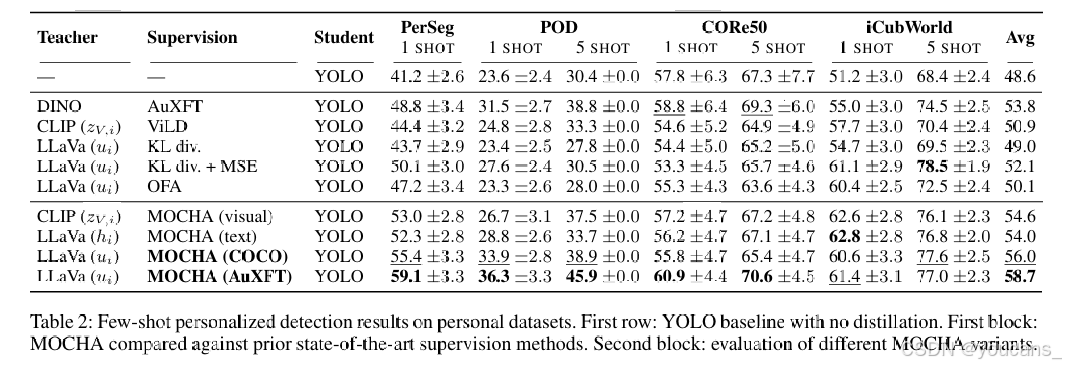
定性结果。
图 6 在 PerSeg 数据集上展示了定性比较,包含三个样本图像:一个罐子、一只猫和一只狗。绿色边界框表示真实注释,而红色边界框显示最高置信度的预测。MOCHA (AuXFT) 在所有样本中一致表现出优越的性能,正确分类并精确地框定了边界。相比之下,其他竞争方法偶尔会出现分类错误和不准确的检测。结果强调了 MOCHA 特征转换和关系对齐策略在提高空间精度和适应新类别方面的有效性。

*图6:PerSeg数据集上的定性结果展示。绿色标注表示真实值(ground truth),红色表示最高置信度的预测结果(所示类别名称对应PerSeg中的个人类别标签)。YOLO表示基线模型结果。标注表示MOCHA(AuXFT)变体。
4.4 消融实验
表 3 报告了广泛的削减实验,分离了 MOCHA 在 PerSeg 和 iCubWorld 数据集上关键设计和训练组件的贡献。我们首先评估了用于压缩教师嵌入的 PCA 维度 dt 的影响。如图 4 所示,压缩教师的嵌入相比使用全分辨率特征能提高性能。PCA 维度为 dt = 512 在紧凑性和表达能力之间取得良好的平衡。更激进的压缩(例如,256 或 384)会导致性能下降,表明丢失了相关语义内容。接下来,我们考察核心 MOCHA 组件的作用。移除嵌入对齐损失 (Lemb) 在两个数据集上都降低了准确性,强调了其在保持教师全局结构方面的重要性。禁用翻译器 (tS no attn.) 中的注意力机制也导致一致的性能下降,表明注意力层在适应多模态特征方面起着关键作用。同样,移除翻译器的最终层 (tS no ffn) 也会降低性能。启用数据增强(仅改变颜色的标准 YOLO 数据增强)降低了鲁棒性,而单独将学习率翻倍(分别对编码器或解码器)则略微损害了性能。最后,我们比较了不同的预训练策略。仅在 OpenImages 上进行预训练时,性能仍低于 MOCHA 配置。COCO 预训练权重提供了显著的性能提升,但 AuXFT 预训练权重总体上取得了最佳结果,得益于其强大的初始性能和与我们 MOCHA 的架构兼容性。
表3:MOCHA的消融实验结果。首块为PCA维度dt的消融分析。次块针对不同MOCHA组件进行变更测试。第三块比较不同预训练方式:OpenImages(OI)、COCO以及AuXFT。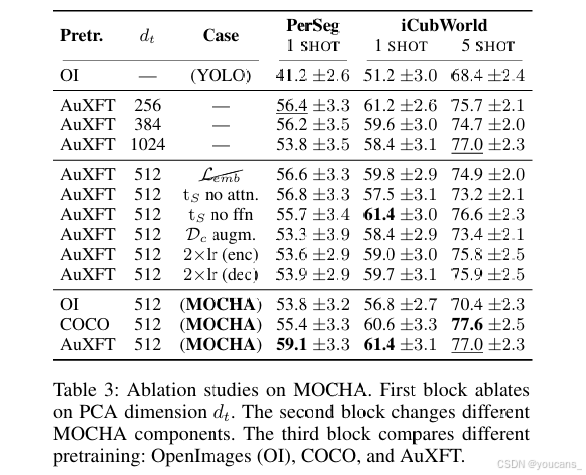
5. 结论
在本工作中,我们提出了 MOCHA,一种针对少量样本个性化对象检测的新型多模态跨架构蒸馏方法。
MOCHA 将紧凑的学生特征对齐到由大规模冻结的视觉-语言模型衍生的区域级嵌入,通过 PCA 去除冗余。
我们的方法通过蒸馏损失和嵌入损失分别实现类内和类间对齐,从而在最先进的方法上取得了显著的性能提升。MOCHA 要求的开销很小,并且在测试时不需要教师模型,使其与轻量级检测器兼容,并适用于资源受限的应用,如移动机器人。
附录
A.4 MOCHA 伪代码
所有实验均在运行内核版本为 6.12.9-1 的基于 RHEL8(RedHat)的 Unix 系统上进行,配备了 8 块 NVIDIA L40S GPU(每块 GPU 配备 48GB VRAM,CUDA 12.8,驱动程序 570.86.15)、2 块 AMD EPYC 9224 24 核处理器、1.5TB 内存以及 Python 版本 3.11.9。每个预训练实验使用 4 块 GPU、24 个 CPU 核心和 64GB 内存,而少量样本训练和推理仅需单块 GPU 和 6 个 CPU 核心即可。完整的 MOCHA 蒸馏(50 个 epoch)大约需要 48 小时,当从 AuXFT 检查点进行蒸馏时(20 个 epoch),时间会减少到大约 20 小时。
在本节中,我们报告了 MOCHA 特征蒸馏和少量样本学习过程的假代码实现。算法 A.1 报告了将视觉-语言知识蒸馏成高效视觉检测器所需的步骤,而算法 A.2 和 A.3 分别解释了如何训练 MOCHA 的少量样本模块并进行推理。请注意,# 表示注释。



A.5 MOCHA 的局限性
MOCHA 带来的改进是显著的,但我们希望强调一些我们认为未来研究潜在方向的局限性。首先,由于 MOCHA 架构的性质,最终任务被限制在对象检测上,这可能限制其在其他领域的应用。其次,虽然推理所需的开销很小,但在训练过程中依赖基础模型会带来显著的计算成本,这在某些情况下是不可取的。最后,我们方法中的原型网络在大规模应用中本质上是低效的,这意味着当涉及大量个性化对象实例时,性能可能会下降。
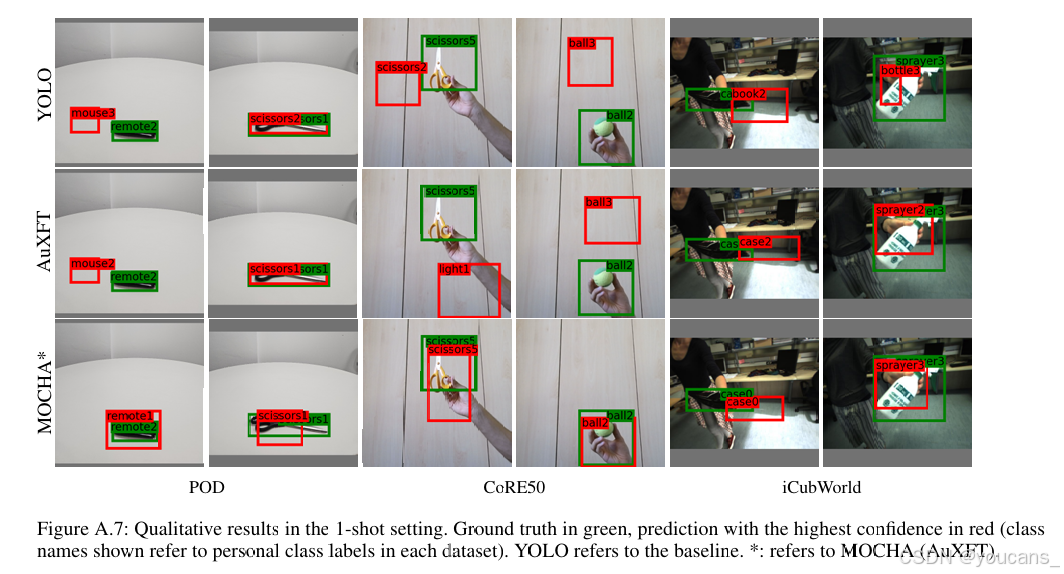
*图A.7:1样本设置下的定性结果。绿色标注为真实标签,红色表示最高置信度的预测结果(所示类别名称对应各数据集的个性化类别标签)。YOLO表示基线方法,表示MOCHA方法(AuXFT)。

*图A.8:5样本设置下的定性结果展示。绿色标注为真实标签,红色标注表示最高置信度的预测结果(所示类别名称对应各数据集的个性化类别标签)。YOLO表示基线模型结果,标注表示采用辅助特征迁移策略的MOCHA模型(AuXFT)输出。
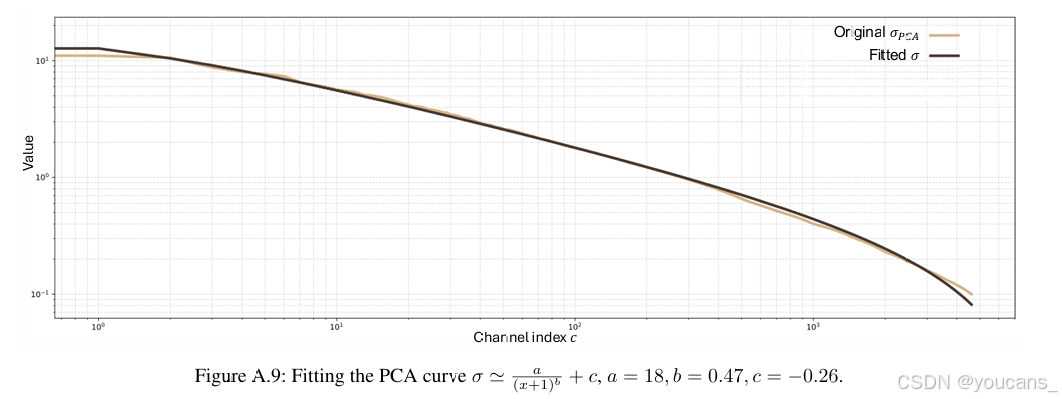
图A.9:PCA曲线拟合过程
参考文献
[1] ALAYRAC J B, DONAHUE J, LUC P, et al. Flamingo: a visual language model for few-shot learning[C]//International Conference on Neural Information Processing Systems. Red Hook, NY, USA: Curran Associates Inc., 2022.
[2] BARBATO F, CAMUFFO E, MILANI S, et al. Continual road-scene semantic segmentation via feature-aligned symmetric multi-modal network[C]//IEEE International Conference on Image Processing. Piscataway, NJ: IEEE, 2024: 722-728.
[3] BARBATO F, MICHIELI U, MOON J, et al. Cross-architecture auxiliary feature space translation for efficient few-shot personalized object detection[C]//IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway, NJ: IEEE, 2024.
[4] CAMUFFO E, MICHIELI U, MILANI S. Learning from mistakes: Self-regularizing hierarchical representations in point cloud semantic segmentation[J]. IEEE Transactions on Multimedia, 2023.
[5] DEVLIN J, CHANG M W, LEE K, et al. BERT: Pre-training of deep bidirectional transformers for language understanding[C]//North American Chapter of the Association for Computational Linguistics, 2019.
[6] DOSOVITSKIY A. An image is worth 16x16 words: Transformers for image recognition at scale[EB/OL]. arXiv, 2020. arXiv:2010.11929.
[7] FANELLO S R, CILIberto C, SANTORO M, et al. iCub World: Friendly robots help building good vision data-sets[C]//IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Piscataway, NJ: IEEE, 2013: 700-705.
[8] GIRDHAR R, EL-NOUBAY A, LIU Z, et al. Imagebind: One embedding space to bind them all[C]//IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2023: 15180-15190.
[9] GOU J, CHEN Y, YU B, et al. Reciprocal teacher-student learning via forward and feedback knowledge distillation[J]. IEEE Transactions on Multimedia, 2024, 26: 7901-7916.
[10] GU J, GHIASI G, CUI Y, et al. ViLD: Open-vocabulary object detection via vision and language knowledge distillation[C]//International Conference on Learning Representations, 2022.
[11] HAO Z, GUO J, HAN K, et al. One-for-All: Bridge the gap between heterogeneous architectures in knowledge distillation[C]//International Conference on Neural Information Processing Systems, 2023.
[12] HAO Z, LUO Y, WANG Z, et al. CDFKD-MFS: Collaborative data-free knowledge distillation via multi-level feature sharing[J]. IEEE Transactions on Multimedia, 2022, 24: 4262-4274.
[13] HUH M, CHEUNG B, WANG T, et al. The platonic representation hypothesis[J/OL]. Proceedings of Machine Learning Research, 2024.
[14] JARITZ M, VU T H, CHARETTE R D, et al. xmuda: Cross-modal unsupervised domain adaptation for 3d semantic segmentation[C]//IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2020: 12605-12614.
[15] JARITZ M, VU T H, DE CHARETTE R, et al. Cross-modal learning for domain adaptation in 3d semantic segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 45(2): 1533-1544.
[16] JOCHER G, CHAURASIA A, QIU J. Ultralytics YOLOv8[CP/DK]. (2023). https://github.com/ultralytics/ultralytics. (2024-07).
[17] KIRILLOV A, MINTUN E, RAVI N, et al. Segment anything[C]//IEEE/CVF International Conference on Computer Vision. Piscataway, NJ: IEEE, 2023: 4015-4026.
[18] KOTHAPALLI V. Neural collapse: A review on modelling principles and generalization[J/OL]. Transactions on Machine Learning Research, 2022.
[19] KUZNETSOVA A, ROM H, ALLDRIN N, et al. The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale[J]. International Journal of Computer Vision, 2020, 128(7): 1956-1981.
[20] LEE C Y, XIE S, GALLAGHER P, et al. Deeply-supervised nets[J/OL]. Proceedings of Machine Learning Research, 2014.
[21] LI M, ZHANG L, ZHU M, et al. Lightweight model pre-training via language guided knowledge distillation[J]. IEEE Transactions on Multimedia, 2024, 26: 10720-10730.
[22] LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft coco: Common objects in context[C]//European Conference on Computer Vision. Berlin: Springer, 2014: 740-755.
[23] LIU H, LI C, WU Q, et al. Visual instruction tuning[J]. Advances in Neural Information Processing Systems, 2023, 36: 34892-34916.
[24] LIU Y, CAO J, LI B, et al. Cross-architecture knowledge distillation[C]//Proceedings of the Asian Conference on Computer Vision. Berlin: Springer, 2022: 3396-3411.
[25] LIU Y, ZHU M, LI H, et al. Matcher: Segment anything with one shot using all-purpose feature matching[C]//International Conference on Learning Representations, 2023.
[26] LIU Z, LIN Y, CAO Y, et al. Swin transformer: Hierarchical vision transformer using shifted windows[C]//IEEE/CVF International Conference on Computer Vision. Piscataway, NJ: IEEE, 2021: 10012-10022.
[27] LOMONACO V, MALTONI D. CORe50: a new dataset and benchmark for continuous object recognition[EB/OL]. arXiv, 2017. arXiv:1705.03550.
[28] LUO S, WANG X, FANG G, et al. Knowledge amalgamation from heterogeneous networks by common feature learning[C]//International Joint Conference on Artificial Intelligence, 2019.
[29] MENG Z, XIA X, MA J. Toward foundation models for inclusive object detection: Geometry- and category-aware feature extraction across road user categories[J]. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2024, 54(11): 6570-6580.
[30] MICHIELI U, MOON J, KIM D, et al. Object-conditioned bag of instances for few-shot personalized instance recognition[C]//IEEE/SPS International Conference on Acoustics, Speech and Signal Processing. Piscataway, NJ: IEEE, 2024: 7885-7889.
[31] OQUAB M, DARCET T, MOUTAKANNI T, et al. DINOv2: Learning robust visual features without supervision[EB/OL]. arXiv, 2023. arXiv:2304.07193.
[32] PAPYAN V, HAN X Y, DONOHO D L. Prevalence of neural collapse during the terminal phase of deep learning training[J]. Proceedings of the National Academy of Sciences, 2020, 117(40): 24652-24663.
[33] PARAMONOV K, ZHONG J X, MICHIELI U, et al. Swiss dino: Efficient and versatile vision framework for on-device personal object search[C]//IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway, NJ: IEEE, 2024: 2564-2571.
[34] PASSALIS N, TZELEPI M, TEFAS A. Heterogeneous knowledge distillation using information flow modeling[C]//IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2020: 2339-2348.
[35] RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision[J/OL]. Proceedings of Machine Learning Research, 2021.
[36] ROMERO A, BALLAS N, KAHOU S E, et al. FitNets: Hints for thin deep nets[C]//International Conference on Learning Representations, 2015.
[37] SNELL J, SWERSKY K, ZEMEL R. Prototypical networks for few-shot learning[C]//Advances in Neural Information Processing Systems, 2017, 30.
[38] SZEGEDY C, LIU W, JIA Y, et al. Going deeper with convolutions[C]//IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2014.
[39] TOUVRON H, CORD M, DOUZE M, et al. Training data-efficient image transformers & distillation through attention[C]//International Conference on Machine Learning. Proceedings of Machine Learning Research, 2021, 139: 10347-10357.
[40] TU Z, ZHOU W, QIAN X, et al. Hybrid knowledge distillation network for RGB-D co-salient object detection[J]. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2025: 1-12.
[41] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[J]. Advances in Neural Information Processing Systems, 2017, 30.
[42] WANG X, ZHANG X, CAO Y, et al. Seggpt: Segmenting everything in context[C]//IEEE/CVF International Conference on Computer Vision. Piscataway, NJ: IEEE, 2023.
[43] XIA R, ZHAO C, ZHENG M, et al. Cmda: Cross-modality domain adaptation for nighttime semantic segmentation[C]//IEEE/CVF International Conference on Computer Vision. Piscataway, NJ: IEEE, 2023: 21572-21581.
[44] ZHANG L, SHI Y, SHI Z, et al. Task-oriented feature distillation[J]. Advances in Neural Information Processing Systems, 2020, 33: 14759-14771.
[45] ZHANG R, JIANG Z, GUO Z, et al. Personalize segment anything model with one shot[C]//International Conference on Learning Representations, 2024.
[46] ZHANG Y, ZHANG C B, JIANG P T, et al. Personalized image semantic segmentation[C]//IEEE/CVF International Conference on Computer Vision. Piscataway, NJ: IEEE, 2021: 10549-10559.
【本节完】
本文由 youcans@xidian 对论文 MOCHA: Multi-modal Objects-aware Cross-arcHitecture Alignment 进行摘编和翻译。该论文版权属于原文期刊和作者,译文只供研究学习使用。
版权声明:
欢迎关注『跟我学YOLO』系列
转发必须注明原文链接:
【跟我学YOLO】MOCHA:让YOLO实现少样本学习
Copyright 2025 by youcans@Xidian
Crated:2025-09

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献202条内容
已为社区贡献202条内容

所有评论(0)