一文讲清:AI大模型8个关键词及其基本原理
你是不是脑海中立刻闪现出OpenAI、ChatGPT、DeepSeek?还有那些能跳机械舞、表演后空翻的智能机器人?稍微专业点的,还能脱口而出监督学习、强化学习这些术语?
什么是大模型?
你是不是脑海中立刻闪现出OpenAI、ChatGPT、DeepSeek?还有那些能跳机械舞、表演后空翻的智能机器人?稍微专业点的,还能脱口而出监督学习、强化学习这些术语?
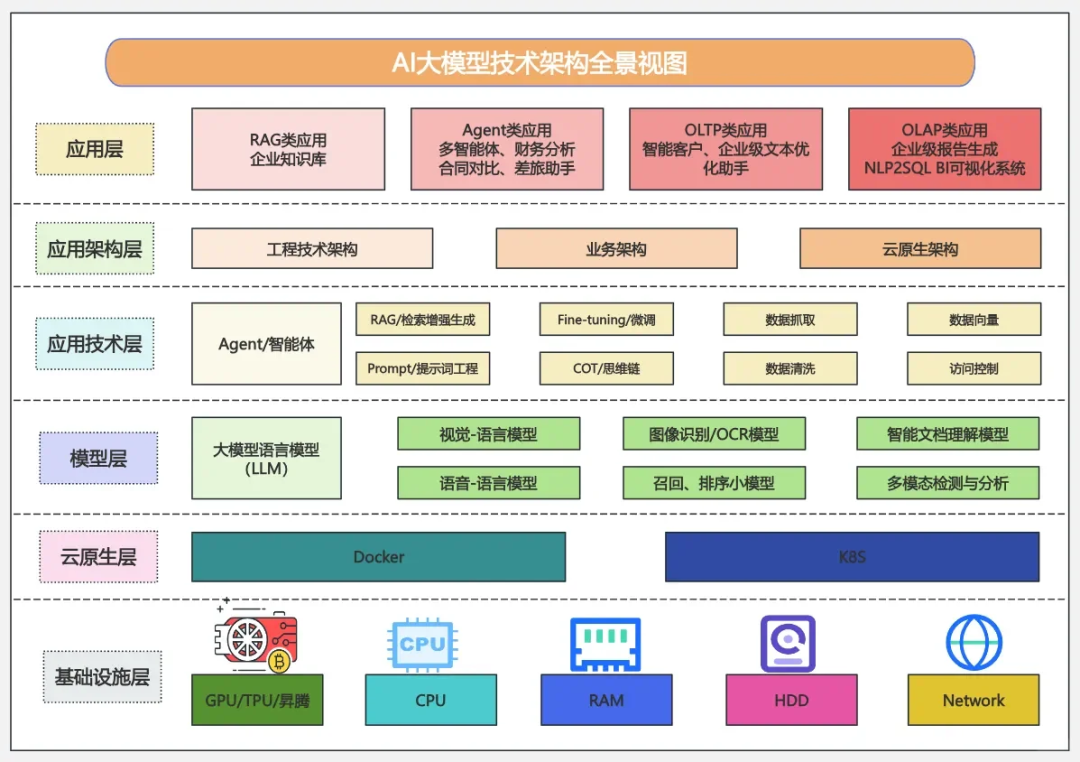
有没有觉得最近所有信息都在疯狂呐喊大模型正在重塑人类文明?好像要是现在不搞懂Transformer架构,明天就会被时代列车甩在站台上?
这种焦虑我太懂了——某个加班的深夜,盯着满屏的参数量、注意力机制,我咬着咖啡决定必须搞清这波技术浪潮的本质。于是熬出这篇硬核解析:
能区分BERT和GPT的差异,就超越了80%的跟风者;如果还能解释反向传播的数学推导,恭喜晋级野生专家行列。下次酒局聊到AI的时候,至少能从容接住技术流的梗。
读技术文档确实不如刷短视频爽快,但请相信:你此刻啃下的每一行代码,都在为未来的认知壁垒添砖加瓦。接下来我们就一起拆开这个黑匣子。
最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,其中算法、工程应用类人才需求最为紧迫!
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
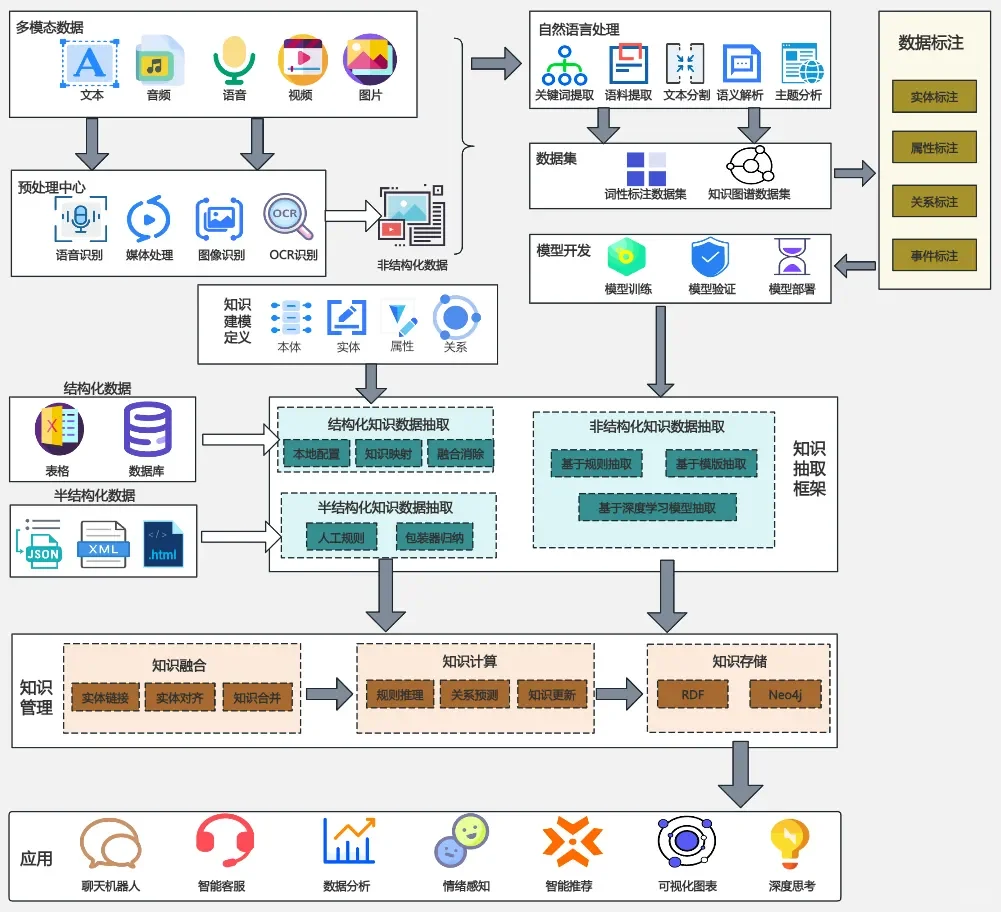
深度学习
【人工智能】的英文术语为artificialintelligence,简称A。其核心关联领域包含两个专业概念:深度学习与机器学习。
【深度学习】对应英文deep learning;【机器学习】的英文表述为machine learning。
作为机器学习与人工智能的关键研究方向,深度学习专注于神经网络技术的探索与应用。
通过深度学习技术的进步,大语言模型得以依托大规模文本数据进行训练,相较于传统方法更能挖掘深层语义特征和语言细微差异。
这一突破使大语言模型在机器翻译、情感识别、智能问答等自然语言处理任务中展现出卓越的性能优势。
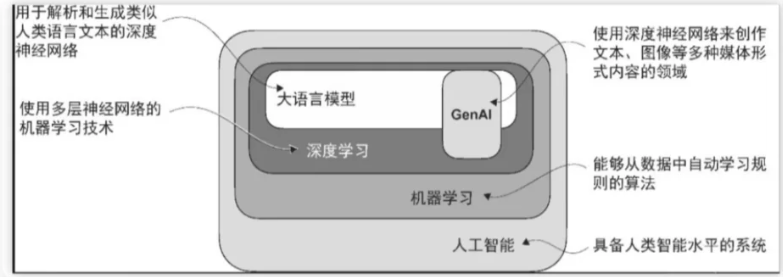
大语言模型的成功,一方面源于其底层采用的Transformer架构,另一方面归功于训练过程中使用的庞大数据集。
这种组合使其能够识别语言中的复杂特征、语境关联和统计规律,而这些特性通过传统编程手段难以精确复现。
LLM
大语言模型(large language model,LLM,简称大模型)是基于神经网络构建的人工智能系统,专为处理、生成类人语言文本而设计。
这类模型属于深度神经网络(deep neural network)架构,其训练数据规模庞大,可能覆盖互联网上绝大多数公开文本资源。
尽管大语言模型在语言处理与生成方面表现卓越,但需明确其"理解"本质是通过统计模式实现的文本连贯性,而非人类意义上的认知能力。
"大语言模型"中的"大"字具有双重含义:既指代训练数据的海量规模,也体现模型参数量的惊人数量级(通常达数百亿至数千亿个参数)。
这些参数作为神经网络的动态权重,通过持续优化来完成下一词预测(next-word prediction)任务——该训练方法巧妙利用了语言序列特性,使模型得以掌握上下文关联与语义结构。
因其文本生成能力,大语言模型被纳入生成式人工智能(generative artificial intelligence,简称generativeAI或GenAI)范畴。
当前主流大语言模型多采用PyTorch框架开发,与ChatGPT等通用模型相比,面向特定领域(如金融、医疗)的定制化模型往往具备更优性能。
定制化方案在数据隐私方面优势显著:企业可避免将敏感数据交由第三方处理,且轻量化模型可直接部署至终端设备(如笔记本电脑、智能手机),这成为大模型商业应用的重要探索方向。
本地化部署既能降低延迟,又可减少服务器依赖成本。
【预训练】与【微调】
此外,开发者通过定制大语言模型可获得完整控制权,能够依据需求自主调整模型的迭代与优化流程。
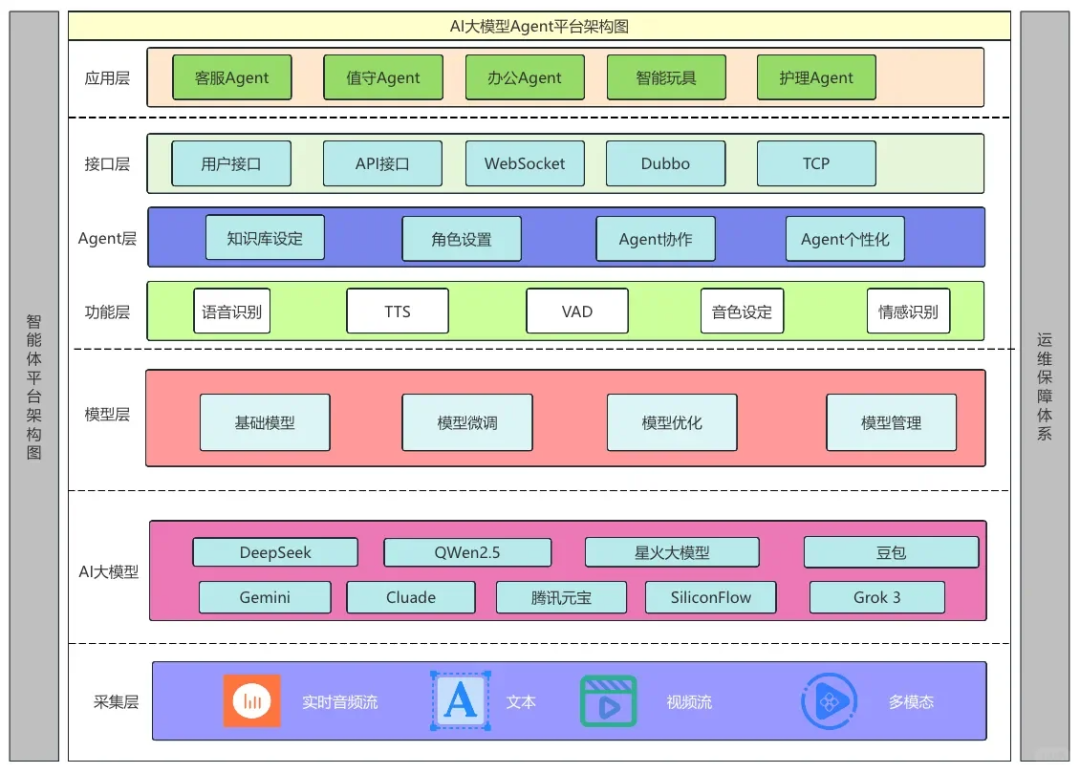
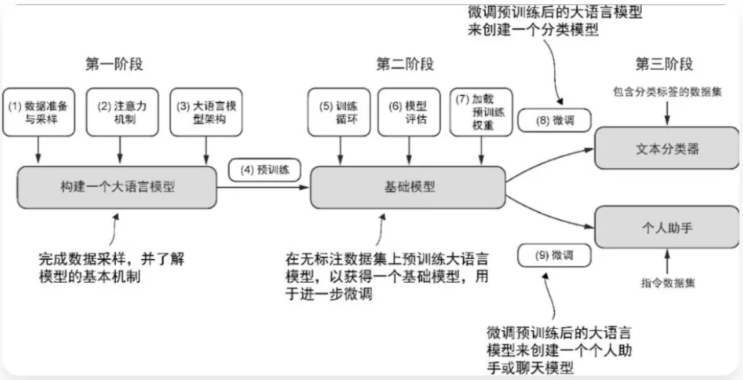
大语言模型的开发流程主要涵盖预训练(pre-training)与微调(fine-tuning)两大关键环节。
预训练定义:预训练是通过海量通用数据对模型实施基础训练,使其掌握数据中的普适性特征与模式,为后续专业化任务学习建立底层能力框架。
"预训练"中的"预"强调其作为训练起点的属性,此阶段模型将在广泛且多元的数据集上进行训练,从而构建基础的语言理解体系。
基于预训练模型,微调阶段会采用特定领域或任务的有限数据集,对模型实施定向优化以强化其专项性能。
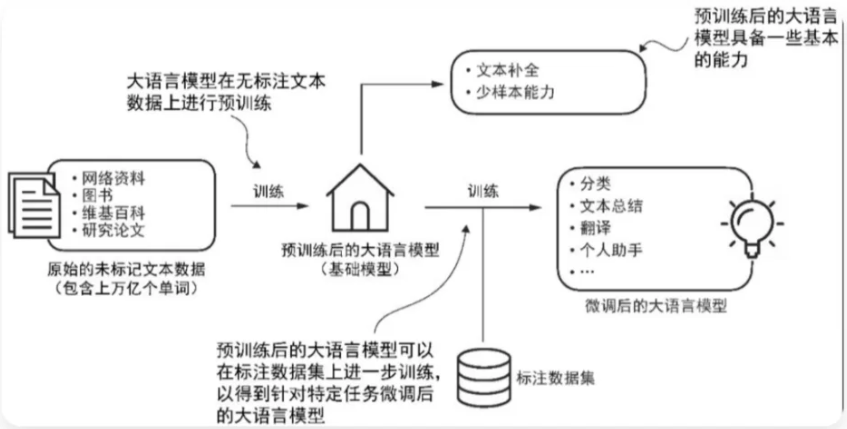
预训练作为大语言模型初始训练阶段,其产出模型普遍被称为基础模型(foundation model)。
以ChatGPT的雏形——GPT-3为例,该模型具备文本续写能力,可根据用户输入的前半部分自动补全句子,同时展现出少量示例即可学习新任务的少样本学习特性。
【微调】指在预训练模型基础上,利用特定领域的小规模数据对模型参数进行定向优化,以提升任务适配性。
当前主流微调方法包括【指令微调】与【分类任务微调】两类。
指令微调(instruction fine-tuning)采用"指令-答案"配对数据(如翻译任务中的"原文-译文"对)。
而分类任务微调(classification fine-tuning)则使用文本与类别标签的组合数据(如已标注"垃圾邮件/正常邮件"的邮件样本)。
Transformer 架构
该架构是在谷歌于2017年发表的论文“Attention Is All You Need”中首次提出的。Transformer最初是为机器翻译任务(比如将英文翻译成德语和法语)开发的。
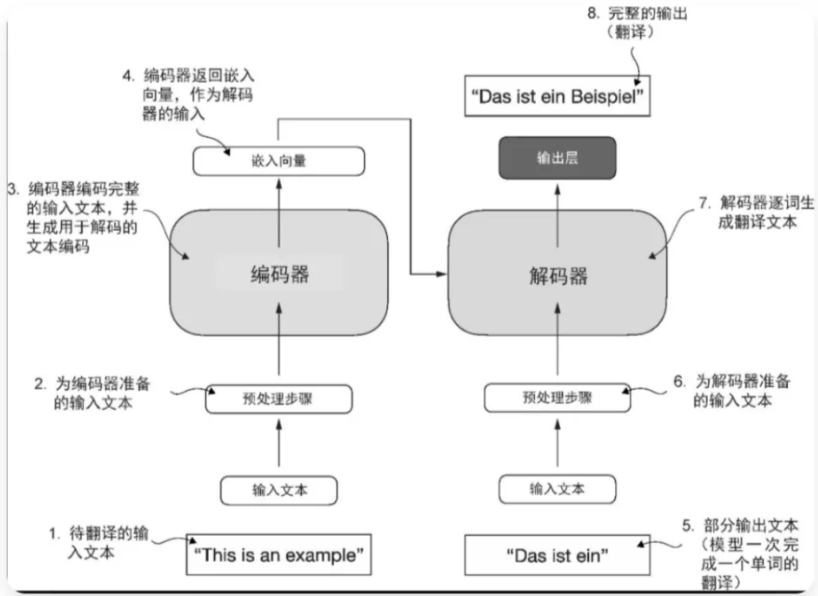
Transformer架构包含两个核心组件:编码器与解码器。编码器(encoder)的功能是对输入文本进行编码处理,将其转化为数值向量序列,从而提取文本的上下文特征。
解码器(decoder)则基于这些编码向量生成目标文本。
在机器翻译场景中,编码器首先将源语言文本转换为向量表示,解码器随后将这些向量解码为目标语言文本。
编码器和解码器均采用多层结构设计,各层之间通过自注意力机制实现交互。
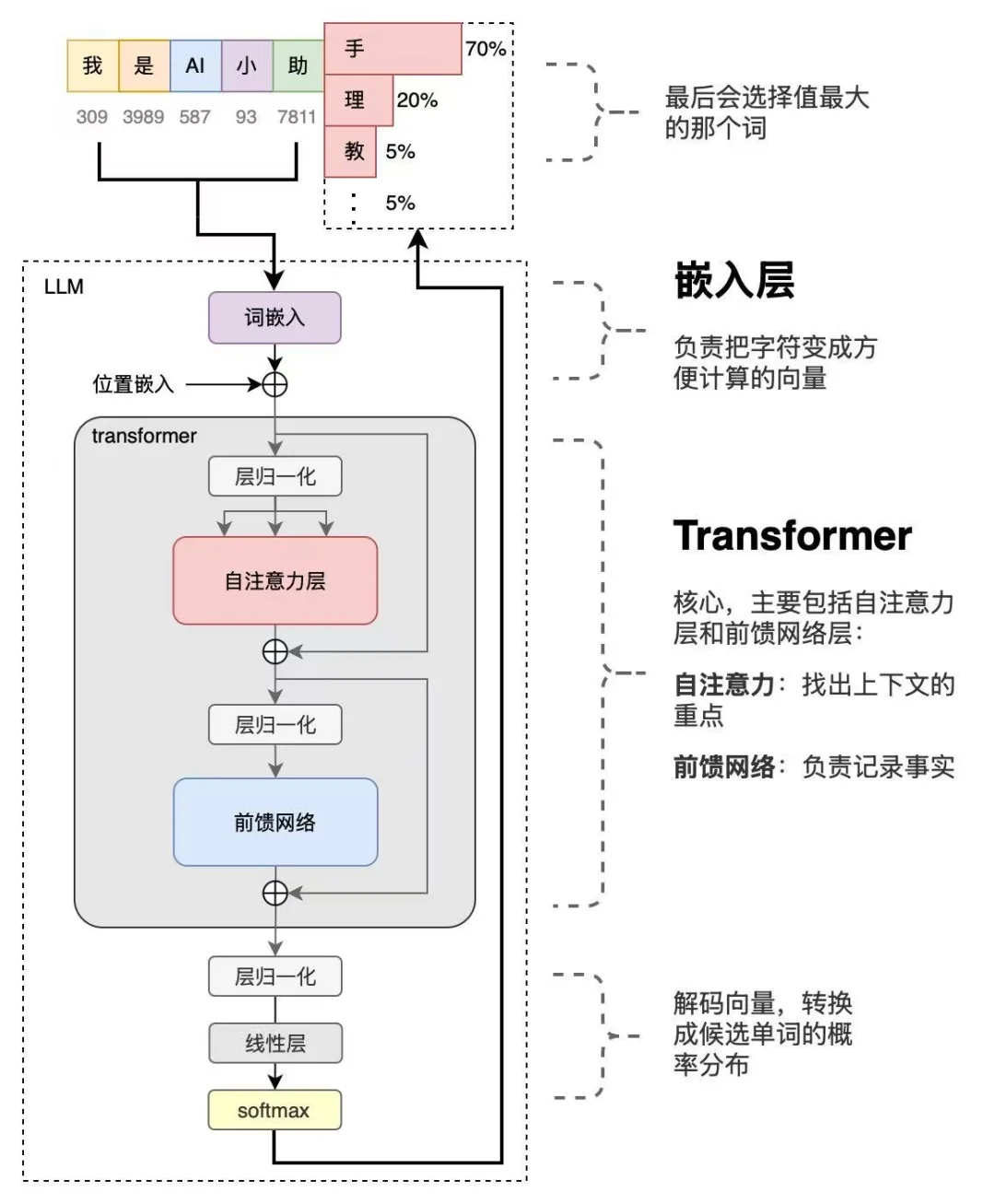
自注意力机制(self-attentionmechanism)作为Transformer与大语言模型的核心技术,能够动态计算序列中不同词元的重要性权重。
该机制有效解决了长距离依赖问题,使模型输出的文本更具上下文一致性。
Transformer的应用不限于大语言模型领域,其同样适用于计算机视觉任务。
此外,部分大语言模型采用循环神经网络或卷积架构,而非Transformer结构。
GPT 与 Bert
与原始 Transformer架构相比,GPT的通用架构更为简洁。
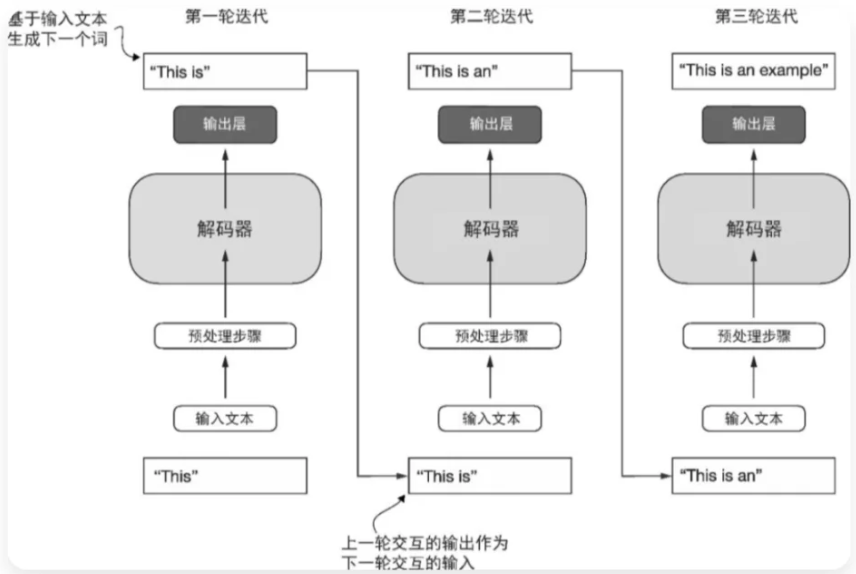
该架构仅保留解码器组件,未集成编码器模块。以GPT为代表的解码器模型基于逐词预测机制生成文本,此类模型被定义为自回归模型(autoregressive model)。
其核心特征是将已生成序列作为后续预测的输入条件。例如GPT-3模型包含96个堆叠层。
关于Transformer架构与1750亿参数规模:原始Transformer(含编码器-解码器双模块)虽专为机器翻译设计,但GPT系列采用更庞大的纯解码器结构,通过下一词预测实现翻译等任务。
这种未经专门训练即可执行新任务的现象称为涌现(emergence),源于模型对海量多语言数据及多样化语境的自主学习能力。
GPT系列聚焦于Transformer解码器部分,核心应用于文本生成领域,涵盖机器翻译、摘要创作、文学创作、代码生成等场景。
零样本学习(zero-shot learning)指无示例直接泛化新任务的能力,少样本学习(few-shot learning)则通过少量示例快速适应新任务。
BERT模型则基于Transformer编码器构建,采用掩码词预测(masked word prediction)训练范式,与GPT的生成式目标形成鲜明对比。
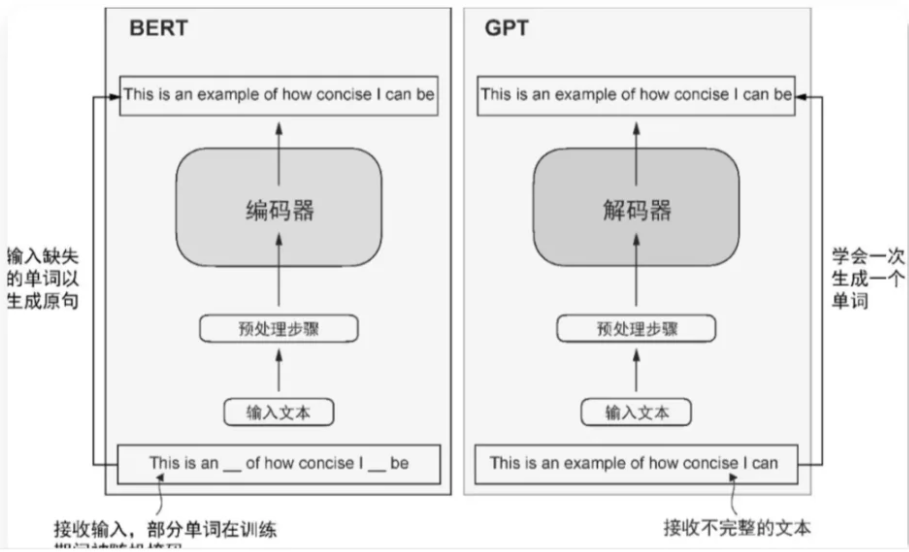
总而言之: GPT 是 Transformer的解码器部分,Bert 是 Transformer 的编码器部分。
Token
词元(token)是模型读取文本的基本单位。数据集中的词元数量大致等同于文本中的单词和标点符号的数量。
分词,即将文本转换为词元的过程。
训练GPT-3模型所需的云计算成本预估达到460万美元,其训练数据规模为3000亿个词元。
当前多数预训练大语言模型已开源,可作为通用工具应用于写作、摘要及编辑等任务,即使这些文本未出现在原始训练数据中。
此外,大语言模型可通过少量数据针对特定任务进行微调,既能降低计算资源消耗,又能优化任务表现。
其核心的下一单词预测任务基于自监督学习(self-supervised learning)机制,即利用数据内在结构实现自动标注。
具体而言,模型通过预测句子或文档中的后续词作为标签,无需人工标注。这种动态生成标签的方式使得海量无标注文本得以用于模型训练。
关键点总结
1.LLM(大语言模型): 采用深度学习技术构建的巨型语言模型,具备自然语言理解与生成能力,可完成多样化复杂任务。
2.Transformer: 以自注意力机制为核心的深度学习架构,现已成为GPT、BERT等主流大模型的标准框架。
3.GPT(生成式预训练Transformer): 依托Transformer架构的预训练生成模型,在文本创作、对话交互等自然语言生成场景表现突出。
4.BERT(双向编码器表示来自Transformer): 基于Transformer的双向预训练模型,专注于自然语言理解任务,广泛应用于文本分类、实体识别等领域。
5.预训练: 利用海量无标注数据训练模型,使其掌握通用语言特征,为后续特定任务奠定基础。
6.微调(FineTuning): 在预训练模型基础上,通过任务专用标注数据进行二次训练,实现模型对具体应用场景的优化适配。
7.深度学习: 借助多层神经网络自动提取数据特征的机器学习分支,构成现代大模型技术的核心基础。
8.Token: 作为NLP处理的基本单元,可以是词语、子词或字符,用于将文本转化为模型可处理的数字化序列。
最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,其中算法、工程应用类人才需求最为紧迫!
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 2
2 0
0- 0



 已为社区贡献45条内容
已为社区贡献45条内容

所有评论(0)