基于vLLM本地部署企业级DeepSeek大模型
本文介绍了基于vLLM本地部署企业级DeepSeek大模型的方法。vLLM是一款专为大型语言模型设计的高效推理工具库,具有高性能推理能力、灵活兼容性和便捷开发体验。其技术架构包括调度器、模型执行器、内存管理器等核心组件,支持多种并行计算策略和先进的内存管理机制。文章详细说明了vLLM的安装步骤,包括系统要求、虚拟环境创建、CUDA配置等,并提供了验证安装成功的方法。通过vLLM部署DeepSeek
注:此文章内容均节选自充电了么创始人,CEO兼CTO陈敬雷老师的新书《GPT多模态大模型与AI Agent智能体》(跟我一起学人工智能)【陈敬雷编著】【清华大学出版社】
清华《GPT多模态大模型与AI Agent智能体》书籍配套视频课程【陈敬雷】
GPT多模态大模型与AI Agent智能体系列一百九十三
基于vLLM本地部署企业级DeepSeek大模型
9.1.2 基于vLLM本地部署企业级DeepSeek
在当今数字化和智能化快速发展的时代,企业对于人工智能技术的应用需求日益增长,尤其是在大型语言模型的推理和部署方面。而vLLM作为一款专门为大型语言模型设计的高效推理与部署工具库,以及DeepSeek-R1模型作为先进的大语言模型代表,它们的结合能够为企业带来强大的AI能力。然而,要充分发挥其优势,正确的安装、配置和部署至关重要。接下来将详细介绍基于vLLM本地部署企业级DeepSeek-R1模型的相关内容,包括vLLM的简介、技术架构、安装步骤,以及DeepSeek-R1模型的文件分析和部署方法,帮助企业顺利实现模型的落地应用,提升企业在数字化转型中的竞争力。
1.vLLM简介
vLLM是一款专为大型语言模型推理与部署打造的高效且易用的工具库,其核心特性与优势如下:
1)核心特性
vLLM通过突破性架构设计与多维度技术创新实现推理效能跃升,核心优势集中体现在:
(1)高性能推理能力:采用PagedAttention技术,实现注意力键值(KV)内存的高效管理,搭配CUDA/HIP图优化模型执行,达成业内领先的服务吞吐量。支持连续批处理传入请求,显著提升推理效率,轻松应对高并发场景。
(2)前沿优化技术集成:融合多样化量化方案(GPTQ、AWQ、INT4、INT8、FP8),结合优化的CUDA内核(集成FlashAttention、FlashInfer),更支持推测性解码、分块预填充等先进技术,从内存管理到计算加速全面优化推理性能。
2)灵活性与易用性
vLLM通过多维度架构设计实现灵活适配与高效开发,核心特性体现在:
(1)广泛兼容性:无缝集成HuggingFace生态的主流模型,支持张量并行、流水线并行的分布式推理模式,适配NVIDIA GPU、AMD CPU/GPU、Intel CPU/GPU、PowerPC CPU、TPU及AWS Neuron等多类型硬件,覆盖多样化部署环境。
(2)便捷开发部署体验:提供高吞吐量服务框架,支持并行采样、束搜索等多种解码算法,满足不同场景需求;支持流式输出与前缀缓存,优化交互体验;配备OpenAI兼容的API服务器,降低开发门槛,同时支持多LoRA,灵活适配模型微调与个性化部署需求。
2.vLLM技术架构
在当今人工智能领域,大型语言模型的推理和部署面临着诸多挑战,尤其是在高效利用资源和提升推理速度方面。vLLM作为一款专门为大型语言模型设计的推理和部署库,其架构设计以高效推理和资源优化为核心,充分借助现代硬件设施和并行计算技术的优势,为大规模语言模型在分布式环境下的高效推理提供了有力支持。它的核心架构由多个模块构成,主要围绕内存管理、动态批处理和并行推理展开,接下来详细介绍。
1)核心组件
vLLM核心模块通过协同工作机制实现高效推理,核心组件包括以下几个:
(1)调度器:调度器(Scheduler)是vLLM架构的中枢神经,它承担着管理推理任务调度的重任。它就像一位精明的资源管理者,能够实时、动态地根据系统资源的状态,如内存使用情况、GPU负载等,对推理请求进行智能调度。通过这种方式,它可以显著提高系统的吞吐量,同时减少推理延迟。此外,调度器还具备根据请求的优先级、大小以及系统资源状况,灵活调整批处理大小的能力,确保每一份系统资源都能得到最优分配。
(2)模型执行器:模型执行器(Model Executor)负责具体执行推理任务。它就像一个桥梁,在不同的硬件资源(如GPU、CPU)之间搭建起沟通的渠道,合理分配模型的计算任务。在vLLM中,模型执行器通过优化并行性和批处理操作,大幅减少推理的时间开销。同时,它还能够将任务分布到多个GPU上,进一步加速执行过程,充分发挥硬件的计算能力。
(3)内存管理器:内存管理器(Memory Manager)是vLLM的核心组件之一,其主要职责是动态分配和回收内存,确保在推理过程中尽可能降低显存的占用。它采用了一种名为“块级内存管理”(Block - level Memory Management)的先进技术,能够对内存使用进行细粒度的管理。根据实际需求进行内存的分配和释放,避免了不必要的显存浪费,使得系统资源得到更高效的利用。
(4)批处理管理器:批处理管理器(Batch Manager)的主要任务是将多个推理请求打包在一起。通过对不同请求进行动态批处理,它能够在保持推理速度的同时,灵活应对不同批次的输入,最大化硬件资源的利用率,从而提升整个系统的吞吐量。
2)模型并行性支持
为了加速大规模语言模型的推理,vLLM设计了多种模型并行性策略,主要包括以下几种:
(1)数据并行:数据并行是一种常见且有效的并行计算策略。vLLM能够将相同模型的不同输入数据分发到多个GPU上进行推理,通过均衡各个GPU的负载,确保每个GPU都能充分利用其计算资源,从而显著提升整体处理速度。
(2)张量并行:对于非常庞大的模型,单个GPU的显存可能无法容纳完整的模型权重。在这种情况下,vLLM支持张量并行,它会将模型的张量分割成更小的部分,并将这些部分分布到多个GPU上进行计算。这种策略有助于在多GPU环境下高效地推理大模型,突破了单个GPU显存的限制。
(3)流水线并行:流水线并行通过将模型的各个层分布到不同的GPU上,形成一个流水线式的推理过程。每个GPU负责处理模型的部分层次,并将处理结果传递给下一个GPU,直到最终完成推理任务。这种并行方式有效地减少了推理过程中的瓶颈,提高了推理效率。
3)内存管理机制
内存管理是vLLM的重要优化领域,它运用了多种技术来确保推理过程中内存使用的高效性。
(1)块级内存管理:vLLM的内存管理器采用块级内存分配策略,根据推理过程中模型的实际需求,将内存划分为不同的块。这样可以确保只在真正需要的时候分配内存,并在不再使用时立即释放,极大地减少了内存浪费,特别适合处理那些需要高显存的任务。
(2)惰性张量分配:vLLM采用了惰性张量分配技术,只有在张量实际需要使用时才进行内存分配。这种机制有效避免了不必要的内存占用,使得GPU显存可以用于处理更多的推理任务,提高了显存的使用效率。
(3)内存碎片管理:由于推理任务的不确定性,内存碎片问题在大型模型推理中较为常见。vLLM通过内存碎片整理技术,定期合并空闲内存块,防止内存碎片影响推理性能,确保系统始终保持高效运行。
(4)渐进式内存释放:当推理任务完成后,vLLM不会立即释放所有的内存,而是采用渐进式内存释放机制。它允许部分内存保留,以便能够快速响应接下来的任务。这种机制特别适用于高频请求的推理场景,能够减少内存分配和回收的时间开销。
通过上述先进的内存管理机制,vLLM在处理大规模模型推理时,不仅能够最大化利用硬件资源,还能有效控制内存使用,从而全面提升系统的整体性能。
3.vLLM安装
下面介绍vLLM安装与配置过程,涵盖系统要求、安装步骤以及依赖项的配置方法。
1)系统要求
在安装vLLM之前,务必确保你的硬件和软件环境满足以下要求:
(1)操作系统:Linux推荐使用Ubuntu 110.04或更高版本,Linux系统凭借其出色的稳定性和兼容性,能够为vLLM提供良好的运行环境。Windows系统上安装 vLLM 需要进行额外配置,相对来说会复杂一些。macOS适用于小规模的开发和测试工作,不过在性能方面可能会受到一定限制。
(2)GPU要求:vLLM设计支持GPU加速,为了充分发挥其性能,建议使用NVIDIA GPU并安装CUDA驱动。推荐选择NVIDIA Tesla或RTX系列显卡,它们拥有强大的计算能力,能够显著提升推理速度。同时,需要确保CUDA版本为11.0或更高版本,cuDNN版本为8或更高版本。
(3)Python版本:Python 3.7及以上版本是运行vLLM的必要条件,确保你的Python环境符合要求。
(4)深度学习框架支持:vLLM支持PyTorch 1.10或更高版本。
(5)依赖包管理工具:pip建议使用20.0或更高版本。conda作为可选工具,可用于管理虚拟环境,帮助你隔离不同项目的依赖。
2)安装步骤
vLLM安装主要通过pip进行,为了确保依赖项的独立性,建议在虚拟环境中进行安装。以下是详细的安装步骤:
(1)创建虚拟环境:可以使用conda或virtualenv来创建Python虚拟环境,命令如下:
使用virtualenv
pip install virtualenv
virtualenv vllm-env
source vllm-env/bin/activate
或者使用conda
conda create --name vllm-env python=3.8
conda activate vllm-env
(2)安装CUDA和cuDNN:若需要GPU加速,首先要确保已安装正确版本的CUDA和cuDNN库。可以通过NVIDIA官网获取详细的安装指导,安装完成后通过nvcc --version命令查看版本号。
(3)安装vLLM库:在安装vLLM之前,先确保pip为最新版本,用pip install --upgrade pip命令升级。然后,使用pip install vllm命令安装vLLM。
(4)验证安装
安装完成后,可以通过python -c “import vllm; print(vllm.version)”
命令验证vLLM是否安装成功,如果能够正确输出vLLM版本号,则表示安装成功。
3)配置依赖项
vLLM需要的依赖项通常包括深度学习框架、CUDA 和一些辅助工具。以下是常用依赖项的配置方法:
(1)安装PyTorch:vLLM支持PyTorch,确保安装正确的PyTorch版本。以CUDA 11.3为例命令如下:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu113
(2)安装CUDA和cuDNN
如果使用GPU,请根据GPU型号和操作系统安装相应的CUDA Toolkit和cuDNN库。可以从以下链接下载:
CUDA:NVIDIA CUDA 下载页面
cuDNN:NVIDIA cuDNN 下载页面
安装完成后,确保环境变量正确配置:
export PATH=/usr/local/cuda/bin: P A T H e x p o r t L D L I B R A R Y P A T H = / u s r / l o c a l / c u d a / l i b 64 : PATH export LD_LIBRARY_PATH=/usr/local/cuda/lib64: PATHexportLDLIBRARYPATH=/usr/local/cuda/lib64:LD_LIBRARY_PATH
(3)安装其他Python依赖项:vLLM还依赖于一些Python库,安装时pip会自动处理大多数依赖项。如果需要手动安装依赖,可以使用以下命令:
pip install numpy scipy tqdm
(4)配置日志和调试工具(可选)
为了更好地调试 vLLM,可以配置日志记录工具,如 loguru 或 logging命令如下:
pip install loguru
按照以上步骤,就可以顺利完成vLLM的安装与配置。
5.DeepSeek部署
为了在中国国内更顺畅地使用vLLM部署DeepSeek-R1模型,可以使用魔搭社区下载deepseek-ai/DeepSeek-R1模型,此模型是671B满血版的DeepSeek-R1,在魔搭社区官网的访问地址为https://modelscope.cn/models/deepseek-ai/DeepSeek-R1,界面如图7-9所示。
图7-9 魔搭社区DeepSeek-R1
点击模型文件页签切换到如下界面,如图7-10所示。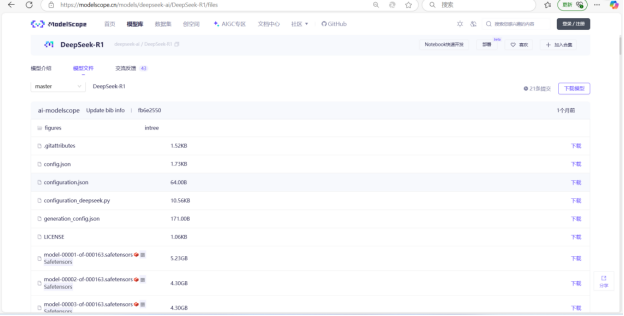
图7-10 DeepSeek-R1模型文件
接下来详细介绍DeepSeek-R1模型文件及部署过程。
1)DeepSeek-R1模型文件分析
以下是对DeepSeek-R1模型文件的详细分析总结:
(1)模型分片文件(核心参数):DeepSeek-R1模型的分片文件采用Safetensors格式存储,共包含163个分片文件,总大小约700GB,平均每个分片约5.31GB。其中约90%的分片(147个)为标准的5.30GB文件,构成模型的主体参数。首尾分片尺寸略大(6.23GB),最后一个分片达到7.58GB,推测可能包含额外的结构信息。此外,存在少量小尺寸分片:第12分片为1.32GB,第34/57/78/100/123/142分片为1.75GB,第142分片为3.14GB,这些可能对应模型参数分布不均的部分。所有分片文件以FP16格式存储,包含完整的Transformer参数及Embedding层,是模型推理的核心数据基础。
(2)核心配置文件:DeepSeek-R1的核心配置文件体系包含config.json、model.safetensors.index.json、generation_config.json、modeling_deepseek.py、configuration.json、configuration_deepseek.py等关键组件,其中config.json定义了模型架构的核心参数,如网络层数、注意力头数和维度等超参数,是模型构建的基础;model.safetensors.index.json作为分片索引文件,精确记录每个参数张量在163个分片中的存储位置;generation_config.json存储生成控制参数,如温度系数和核采样阈值等默认值;modeling_deepseek.py实现了模型结构的自定义逻辑,包含独特的注意力机制和前馈神经网络层。此外,configuration.json作为HuggingFace格式的配置文件,确保模型与Transformers库的兼容性;configuration_deepseek.py则提供了DeepSeek自定义的配置逻辑,可对模型行为进行深度优化。这些文件共同构建了从基础架构定义到框架适配、从生成策略到代码实现的完整配置体系,既保持了对主流生态的兼容性,又支持深度定制化需求。
(3)分词器组件:DeepSeek-R1的分词器组件由两个核心文件构成:tokenizer.json作为分词器的核心文件,存储了词表、合并规则以及特殊Token(如分隔符、填充符)的定义,负责将输入文本转化为模型可处理的Token序列;tokenizer_config.json则包含分词器的配置参数,如填充策略(Padding)、截断策略(Truncation)等,直接影响文本预处理的行为逻辑。这两个文件协同工作,确保输入文本的标准化处理,为模型推理提供基础支持。
2)DeepSeek-R1模型部署
首先通过命令pip3 install modelscope安装魔搭社区Python包。然后通过export VLLMUSEMODELSCOPE=True命令设置环境变量,然后运行vllm服务,命令如下:
vllm serve “deepseek-ai/DeepSeek-R1”
或者通过Python代码运行,命令如下:
python -m vllm.entrypoints.openai.apiserver --model=“deepseek-ai/DeepSeek-R1” --trust-remote-code --port 8000
如果本地服务器已经下载好了deepseek-ai/DeepSeek-R1模型,可以直接通过如下命令安装,指定模型的本地路径即可。
vllm serve “/root/model/deepseek-ai/DeepSeek-R1”
通过这些步骤,你可以在中国国内更方便地使用vLLM部署和运行DeepSeek-R1模型,而不会受到网络限制的影响。
更多技术内容
更多技术内容可参见
清华《GPT多模态大模型与AI Agent智能体》书籍配套视频【陈敬雷】。
更多的技术交流和探讨也欢迎加我个人微信chenjinglei66。
总结
此文章有对应的配套新书教材和视频:
【配套新书教材】
《GPT多模态大模型与AI Agent智能体》(跟我一起学人工智能)【陈敬雷编著】【清华大学出版社】
新书特色:《GPT多模态大模型与AI Agent智能体》(跟我一起学人工智能)是一本2025年清华大学出版社出版的图书,作者是陈敬雷,本书深入探讨了GPT多模态大模型与AI Agent智能体的技术原理及其在企业中的应用落地。
全书共8章,从大模型技术原理切入,逐步深入大模型训练及微调,还介绍了众多国内外主流大模型。LangChain技术、RAG检索增强生成、多模态大模型等均有深入讲解。对AI Agent智能体,从定义、原理到主流框架也都进行了深入讲解。在企业应用落地方面,本书提供了丰富的案例分析,如基于大模型的对话式推荐系统、多模态搜索、NL2SQL数据即席查询、智能客服对话机器人、多模态数字人,以及多模态具身智能等。这些案例不仅展示了大模型技术的实际应用,也为读者提供了宝贵的实践经验。
本书适合对大模型、多模态技术及AI Agent感兴趣的读者阅读,也特别适合作为高等院校本科生和研究生的教材或参考书。书中内容丰富、系统,既有理论知识的深入讲解,也有大量的实践案例和代码示例,能够帮助学生在掌握理论知识的同时,培养实际操作能力和解决问题的能力。通过阅读本书,读者将能够更好地理解大模型技术的前沿发展,并将其应用于实际工作中,推动人工智能技术的进步和创新。
【配套视频】
清华《GPT多模态大模型与AI Agent智能体》书籍配套视频【陈敬雷】
视频特色: 前沿技术深度解析,把握行业脉搏
实战驱动,掌握大模型开发全流程
智能涌现与 AGI 前瞻,抢占技术高地
上一篇:《GPT多模态大模型与AI Agent智能体》系列一》大模型技术原理 - 大模型技术的起源、思想
下一篇:DeepSeek大模型技术系列五》DeepSeek大模型基础设施全解析:支撑万亿参数模型的幕后英雄

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 9
9 0
0- 0



 已为社区贡献101条内容
已为社区贡献101条内容

所有评论(0)