MySQL性能优化全攻略:从SQL编写、索引调优到配置详解,吃透这一篇就够了(上篇)
本文系统介绍了MySQL性能优化的金字塔模型,从架构优化到数据库设计、SQL优化、索引优化四个层面提供解决方案。重点包括:1)架构层面采用缓存、读写分离、分库分表;2)数据库设计强调合理选择数据类型和存储引擎;3)SQL优化着重使用EXPLAIN分析执行计划,避免全表扫描;4)索引优化需遵循最左前缀原则,注意区分度与性能平衡。文章还推荐了实用的MySQL备份工具,帮助提高工作效率。
这是一份全面且结构清晰的 MySQL 性能优化指南。我将从宏观到微观,从原则到实践,为您系统地介绍优化思路和方法。
一、核心思想:性能优化金字塔
优化工作应该像金字塔一样,从底层基础开始,越底层的优化效果越显著。
1. 架构优化(效果最显著):包括引入缓存、读写分离、分库分表等。这是解决性能问题的根本。
2. 数据库设计与SQL优化:良好的表结构设计和高效的SQL语句是性能的基石。
3. 数据库实例配置优化:调整MySQL的配置参数(如`innodb_buffer_pool_size`)以适应硬件和业务需求。
4. 硬件与系统优化:升级硬件(CPU、内存、SSD硬盘)和优化操作系统配置。
记住: 越靠近塔顶(硬件)成本越高,效果却越有限。应优先考虑塔底(架构和设计)的优化。
二、架构优化
这是优化的第一步,也是最重要的一步。
1. 引入缓存:
场景:读多写少,数据变化不频繁。
方案:使用 Redis、Memcached 等缓存热点数据,减少数据库的直接访问量。
2. 读写分离:
场景:读远大于写。
方案:搭建主从复制(Master-Slave)架构,写操作主库,读操作多个从库,分散压力。
3. 分库分表:
场景:单表数据量超千万,并发量极高。
方案:进行水平或垂直拆分,解决单库单表的性能和容量瓶颈。(详见上一篇文章)
三、数据库设计与SQL优化
这是开发人员最能发挥作用的环节。
1. 数据库设计优化
合适的数据类型:选择最精简、最高效的数据类型。
用 `INT` 而不是 `VARCHAR` 存储数字。
用 `DATETIME` 而不是 `VARCHAR` 存储时间。
避免使用 `TEXT`/`BLOB` 类型,如果必须使用,将其独立成表。
范式与反范式的平衡:
范式化(减少冗余)的好处是写操作快,但查询可能需要关联。
反范式化(适当冗余)的好处是读操作快,避免了关联查询,但需要维护数据一致性。
建议:根据核心查询场景,允许适当的冗余(如将用户名冗余到订单表中)。
为查询需求选择正确的存储引擎:
InnoDB:默认选择。支持事务、行级锁、外键。适用于绝大多数场景,尤其是高并发写入和事务性操作。
MyISAM:不支持事务和行级锁(表锁),读性能在特定场景下很好。不推荐在新项目中使用。
2. SQL语句优化(重中之重)
核心:使用 EXPLAIN 分析执行计划
这是SQL优化的必备工具。执行 `EXPLAIN SELECT ...`,重点关注以下字段:
type:访问类型。从好到坏:`system` > `const` > `eq_ref` > `ref` > `range` > `index` > `ALL`。至少要达到 `range` 级别,最好能达到 `ref`。
key:实际使用的索引。如果为 `NULL`,则未使用索引。
rows:预估需要扫描的行数。值越小越好。
Extra:额外信息。如果出现 `Using filesort`(文件排序)或 `Using temporary`(使用临时表),则需要警惕。
常见SQL优化策略:
1. 避免使用 `SELECT *`:只取需要的字段,减少网络传输和内存消耗。
2. 确保索引有效:
避免在索引列上使用函数或计算(如 `WHERE YEAR(create_time) = 2023`)。
避免索引列发生隐式类型转换(如字符串字段用数字查询)。
使用 `LIKE` 查询时,前缀匹配才能用索引(`'keyword%'`),`'%keyword%'` 会导致全表扫描。
3. 优化关联查询(JOIN):
确保 `ON` 和 `WHERE` 子句中的列上有索引。
被驱动表(小表)的连接字段必须有索引。
多表关联时,结果集小的表作为驱动表。
4. 优化 ORDER BY 和 GROUP BY:
为排序和分组的字段建立索引,以避免 `Using filesort` 和 `Using temporary`。
5. 优化大分页查询(LIMIT):
糟糕的写法:`SELECT * FROM table LIMIT 1000000, 20;` (会读取1000020条数据,然后丢弃前100万条)
优化写法:`SELECT * FROM table WHERE id > 1000000 LIMIT 20;` (利用主键索引进行位置定位,效率极高)
6. 避免使用 `OR` 来连接多个条件:
多数情况下会导致全表扫描。可用 `UNION` 或 `UNION ALL` 替代。
7. 使用批量操作:
插入多条数据时,使用 `INSERT INTO table VALUES (a), (b), (c)...` 而非循环单条插入。
四、索引优化
索引是提高查询速度最关键的数据结构。
索引创建原则:
出现在 WHERE 子句、ORDER BY 子句、GROUP BY 子句和 JOIN 子句中的列,是创建索引的首选候选列。
区分度高的列适合建索引(如手机号、用户名),区分度低的列(如性别、状态)效果不佳。
不要过度索引。索引会降低写操作(INSERT/UPDATE/DELETE)的速度,并占用额外空间。
考虑创建复合索引(多列索引),并遵守最左前缀原则。
索引 `(a, b, c)` 可以用于查询 `WHERE a = ?`、`WHERE a = ? AND b = ?`、`WHERE a = ? AND b = ? AND c = ?`,但不能用于 `WHERE b = ?` 或 `WHERE c = ?`。
另外搭配便捷的MYSQL备份工具,可定时备份、异地备份,MYSQL导出导入。可本地连接LINUX里的MYSQL,简单便捷。可以大大地提高工作效率喔。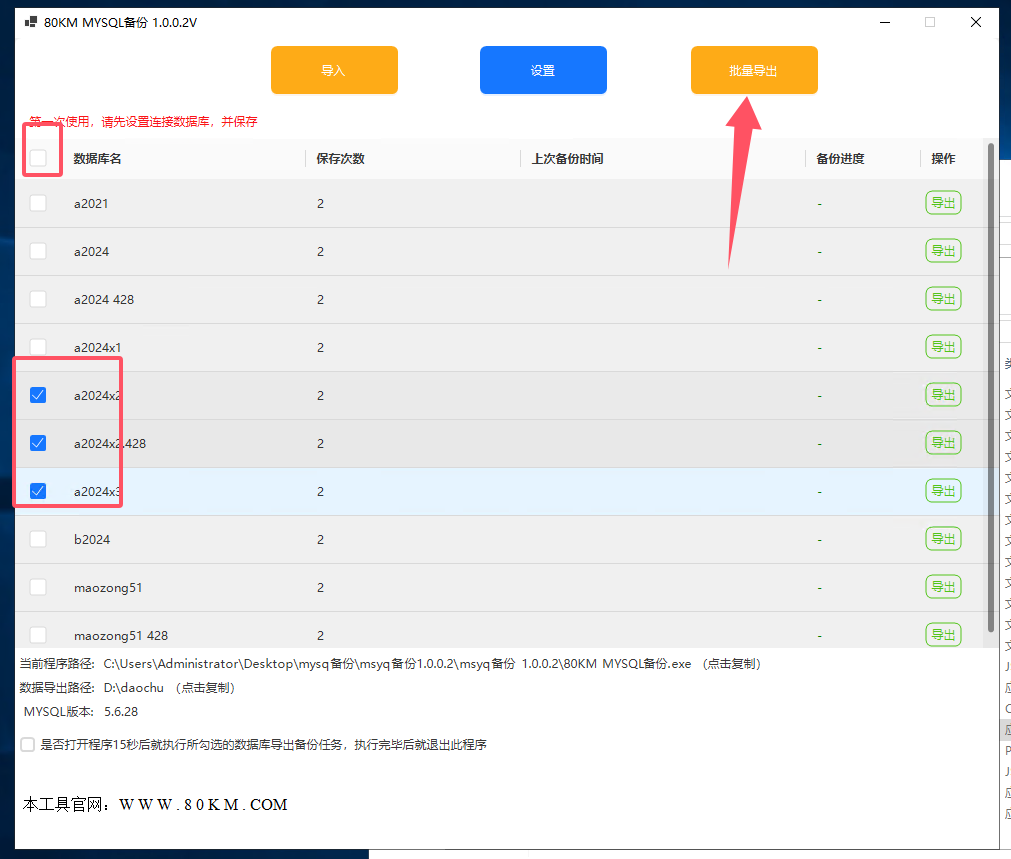

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)