AI训练与推理的硬件需求有什么区别?
在人工智能项目的全生命周期中,训练(Training) 和 推理(Inference) 是两个至关重要的阶段。虽然它们都需要算力支持,但在计算资源、内存容量、存储系统和通信带宽等方面的需求差异很大。
📚AI Infra系列文章
在人工智能项目的全生命周期中,训练(Training) 和 推理(Inference) 是两个至关重要的阶段。虽然它们都需要算力支持,但在计算资源、内存容量、存储系统和通信带宽等方面的需求差异很大。

所有相关源码示例、流程图、模型配置与知识库构建技巧,我也将持续更新在Github:LLMHub,欢迎关注收藏!
希望大家带着下面的问题来学习,我会在文末给出答案。
- AI训练和推理在计算资源上的主要差别是什么?
- 为什么训练阶段的显存需求往往高于推理?
- 在不同部署场景下,存储和网络的瓶颈会如何变化?
1. 计算资源需求对比
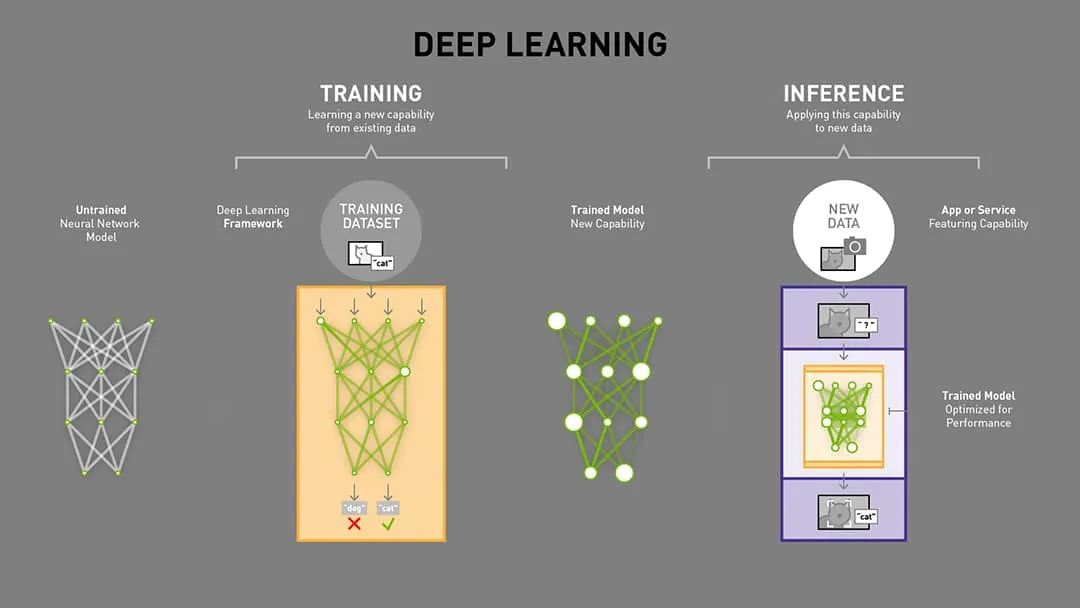
训练是一个计算密集型的工作,需要反向传播(Backward Pass)和梯度计算,计算量约为推理的 2~3 倍,同时训练并行化需求高,常采用数据并行、模型并行、混合并行以加速训练,并且训练高吞吐优先,更关注每秒可处理的样本数量(Throughput)。
推理(Inference)则是一个延迟敏感型的工作,尤其在实时推理场景中,比如在线搜索、对话机器人等,推理的计算量较低,只执行前向传播(Forward Pass),没有梯度计算,并且常用量化、剪枝等技术减少运算量。
2. 内存(显存)需求对比
训练显存消耗大,需存储模型参数、梯度、优化器状态、激活值。有一个显存的计算公式是显存需求 = 模型大小 × 3~4 + Batch Size × 激活缓存。大型模型训练通常需要40GB 显存以上的显卡,所以很多研究生的实验室研究不起大模型。
推理显存占用则比较小,只需存储模型参数与少量中间激活值。推理的时候可以批处理或流式处理,显存压力取决于批大小(Batch Size),当边缘部署的时候可在 4GB~16GB 显存的GPU或加速卡上运行。
3. 存储需求对比
训练是高容量、高吞吐、SSD优先的任务,需存储大规模训练数据集,TB、PB级别的数据在大模型训练中是很常见的,同时训练过程中需快速读取批量数据,也就是高吞吐,为了避免HDD的I/O瓶颈,特别是随机读取场景,所以SSD优先。
推理则以模型权重加载为主,通常只需读取一次模型权重到显存。进行边缘推理时可直接将模型固化到本地闪存;云端推理则依赖网络存储(如S3)。
4. 网络与通信需求
训练绝大部分采用分布式训练,因为没有一个单一的GPU能够完成这么庞大的计算,分布式计算我后面会出一个系列专门介绍,多GPU/多节点训练需高带宽低延迟互联,比如NVLink、InfiniBand。因为训练的时候数据并行需要频繁的梯度通信,带宽不足会显著拖慢速度。
在线推理时低延迟网络连接至关重要,尤其是API服务。批量推理就可以离线执行,对网络带宽依赖较低。
最后,我们回答文章开头提出的问题。
- AI训练和推理在计算资源上的主要差别是什么?
训练计算量更大、并行化需求高;推理则追求低延迟和低功耗。
- 为什么训练阶段的显存需求往往高于推理?
因为训练需要同时保存参数、梯度和激活值,而推理只需存储参数和少量中间结果。
- 在不同部署场景下,存储和网络的瓶颈会如何变化?
大规模分布式训练受限于网络带宽与存储I/O,而推理在实时场景中受限于网络延迟,在离线批处理场景中存储需求更小。
关于深度学习和大模型相关的知识和前沿技术更新,请关注公众号coting!
以上内容部分参考了NVIDIA官方文档与Google Cloud AI架构指南,非常感谢,如有侵权请联系删除!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 22
22 0
0- 0



 已为社区贡献43条内容
已为社区贡献43条内容

所有评论(0)