AI Infra-为什么AI需要专属的基础设施?
近几年,人工智能尤其是大模型的爆发式发展,让算力、存储、网络等基础资源的需求呈现指数级增长。传统的IT基础设施虽然支撑了互联网时代的业务运行,但面对AI训练和推理的超高计算密度、海量数据吞吐和低延迟需求时,显得力不从心。为了让AI技术真正落地,我们需要针对AI特性量身定制的AI基础设施(AI Infrastructure)。
近几年,人工智能尤其是大模型的爆发式发展,让算力、存储、网络等基础资源的需求呈现指数级增长。传统的IT基础设施虽然支撑了互联网时代的业务运行,但面对AI训练和推理的超高计算密度、海量数据吞吐和低延迟需求时,显得力不从心。为了让AI技术真正落地,我们需要针对AI特性量身定制的AI基础设施(AI Infrastructure)。
本文将介绍它的定义、重要性,以及它与传统IT基础设施的关键区别。
所有相关源码示例、流程图、模型配置与知识库构建技巧,我也将持续更新在Github:LLMHub,欢迎关注收藏!
希望大家带着下面的问题来学习,我会在文末给出答案。
- 什么是AI基础设施?
- 为什么AI需要专属的基础设施?
- AI基础设施与传统IT基础设施有什么不同?
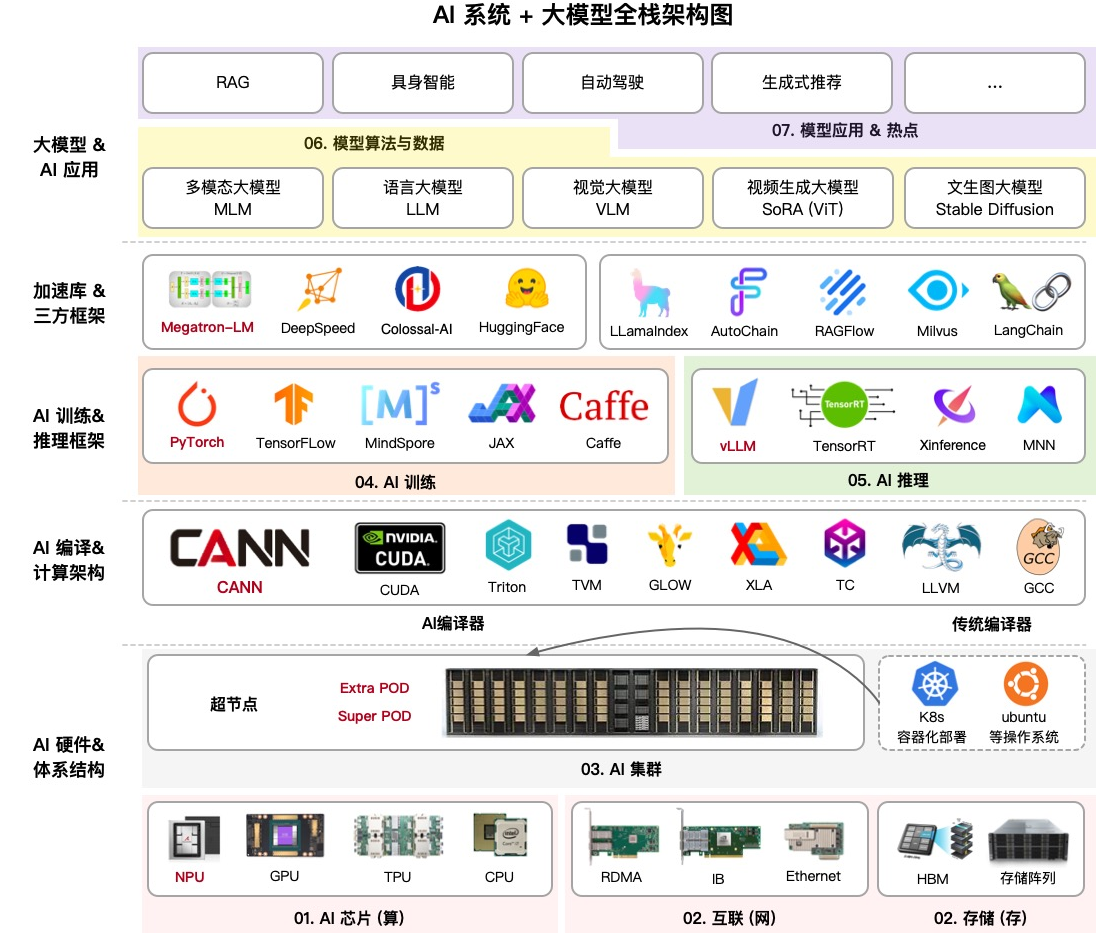
1. 什么是AI基础设施?
AI基础设施(AI Infra) 指的是支撑人工智能(特别是深度学习和大模型)开发、训练、部署和推理所需的全栈资源与服务。它不仅包括硬件层(如GPU、AI加速芯片、高带宽网络、超高速存储),还包括软件层(如分布式训练框架、数据处理平台、模型管理工具),以及运维层(如资源调度、监控、弹性扩展、容灾备份等)。
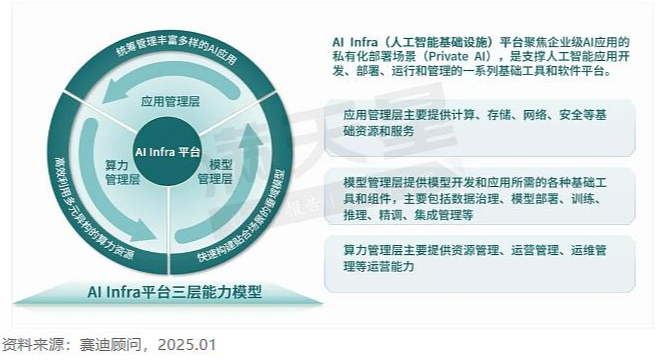
一个完整的AI基础设施通常包含:
- 算力层:GPU、TPU、AI ASIC、推理芯片等;
- 存储层:高性能分布式存储、对象存储、NVMe SSD;
- 网络层:高带宽低延迟互连(InfiniBand、NVLink、RoCE);
- 软件与中间件层:分布式训练框架(PyTorch DDP、DeepSpeed、Horovod)、MLOps工具链(Kubeflow、MLflow);
- 运维与管理层:Kubernetes集群调度、资源监控、自动扩缩容。
2. 为什么AI需要专属基础设施?
AI任务,尤其是大模型训练,与传统IT任务在资源消耗模式上有质的不同:
(1)计算密集型 & 高并发
AI训练需要海量浮点计算(FLOPs),例如GPT-3训练规模可达数百PetaFLOPs天。高并发GPU协同工作,需要高带宽低延迟通信,而不是传统CPU服务器的IO型任务模式。
(2)数据吞吐量巨大
模型训练需要加载TB甚至PB级的数据集。要求存储系统具备高IOPS和高顺序吞吐,支持高速数据预取。
(3)资源调度与弹性扩展复杂
AI训练通常是长任务(几天到几周),一旦中断代价巨大。分布式训练对GPU、网络拓扑和节点位置敏感,需要专门的调度策略。
(4)异构计算与优化需求
AI硬件不再是单一架构(GPU、TPU、FPGA、ASIC并存)。软件栈需要适配不同硬件的特性,最大化性能利用率。
简而言之,AI不是简单的“跑在服务器上的软件”,而是一个计算、数据、网络三者协同的高密度系统工程。
3.AI基础设施和传统IT基础设施有什么区别?
可以用一个表格来描述AI基础设施和传统IT基础设施的主要区别:
| 维度 | 传统IT基础设施 | AI基础设施 |
|---|---|---|
| 计算单元 | CPU为主 | GPU/TPU/AI ASIC为主,支持CPU协同 |
| 计算模式 | 多任务并发、IO密集 | 浮点运算密集、长时间批量计算 |
| 网络需求 | 千兆以太网足够 | 高速互连(InfiniBand、NVLink)低延迟通信 |
| 存储模式 | 磁盘阵列、低频访问 | 高IOPS、高吞吐分布式存储 |
| 调度策略 | 通用任务调度 | 大规模分布式训练优化调度 |
| 容错与恢复 | 短任务容错容易 | 长任务断点恢复关键 |
| 软件栈 | 通用应用和数据库 | 深度学习框架、分布式训练工具链、MLOps平台 |
所以AI基础设施对提升训练速度,降低成本,提升模型性能和支撑AI落地至关重要。
最后,我们回答文章开头提出的问题。
- 什么是AI基础设施?
支撑AI开发、训练、部署、推理的全栈硬件、软件和运维体系,包括算力、存储、网络、分布式训练框架及MLOps工具链。
- 为什么AI需要专属基础设施?
因为AI任务计算密集、数据吞吐巨大、调度复杂且依赖异构硬件,传统IT基础设施无法满足性能和稳定性要求。
- AI基础设施与传统IT基础设施有什么不同?
AI基础设施以GPU/TPU等高性能计算单元为核心,要求高带宽低延迟网络、高吞吐存储、分布式训练优化调度,而传统IT侧重通用计算与IO任务。
关于深度学习和大模型相关的知识和前沿技术更新,请关注公众号coting!
以上内容部分参考了云计算厂商技术白皮书和AI系统论文,非常感谢,如有侵权请联系删除!
参考链接
https://github.com/Infrasys-AI/AIInfra
AI Infra简介 AI Infra,定位于算力与应用之间的“桥梁”角色的基础软件设施层,主要利用AI/GPU芯片的算力中心和算力云等的推理… - 雪球

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 32
32 0
0- 0



 已为社区贡献43条内容
已为社区贡献43条内容

所有评论(0)