大模型-Tokenizer
本文系统介绍了自然语言处理中的分词粒度分类,重点解析了Subword级别的四种主流分词方法:BPE(字节对编码)、BBPE(字节级BPE)、WordPiece和Unigram。详细对比了各方法的原理、优缺点及应用场景,如WordPiece在BERT模型中的应用优势。同时介绍了谷歌开源工具包SentencePiece的功能特性,包括多语言支持、可逆分词等,并指出其对中文处理的局限性。文章提供了Sen
本文介绍分词粒度分类,详细介绍Subword的4种分词方法:BPE、BBPE、Unigram、WordPiece,并介绍SentencePiece工具包。
分词粒度
分为三类:
1、Word-Level
2、Character-Level:将句子拆分为单个字符进行分词。这种方法适合处理未知词汇(OOV)问题,但粒度较细,语义表达能力有限。
3、Subword
Subword
BPE
BPE:字节对编码。是一种基于频率的子词分词方法。它从字符级别开始,逐步合并频率最高的相邻子词,直到达到目标词表大小。
优点:可以有效平衡词表大小和分词效率,但可能会导致分词歧义。
BBPE
全称为Byte-Level BPE,是字节级别的BPE。
优点:用基于UTF-8的BBPE,词表可以相比于BPE减少到1/8(来自原论文的摘要,划重点),且可以解决OOV(out-of-vocabulary)问题。
WordPiece
算法概述
是一种子词粒度的分词算法(subword tokenization algorithm),广泛应用于Transformer模型(如BERT、DistilBERT、Electra)。
- 核心思想:通过最大化训练数据的似然值来指导子词合并,优化分词效果。
- 优点:相比BPE,更灵活地处理未登录词(OOV),适用于复杂语言和长尾词汇。
- 应用场景:主流预训练模型(如BERT系列)的标准分词工具。
合并原则
BPE直接合并最高频的字符组合,WordPiece每次合并两个字符串A和B时,选择使如下概率值最大的组合:
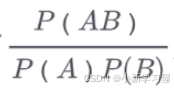
Unigram
算法概述
与BPE或WordPiece不同,Unigram的算法思想是从一个巨大的词汇表出发,再逐渐删除(trim down)其中的词汇,保留高频子词,直到大小满足预定义。
初始词汇表构建
初始的词汇表可以采用所有预分词器分出来的词,再加上所有高频的子串。
删除原则与损失函数
每次从词汇表中删除词汇的原则是使预定义的损失最小。训练时,计算loss的公式为:
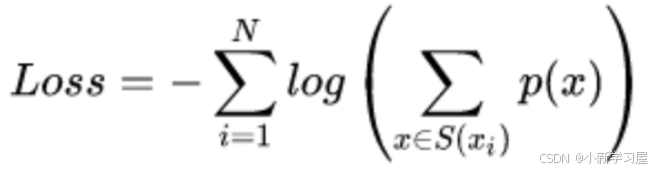
假设训练文档中的所有词分别为 x1,x2,…,xn,而每个词tokenize的方法是一个集合 S(xi)。当一个词汇表确定时,每个词tokenize的方法集合 S(xi)就是确定的,而每种方法对应着一个概率 P(x)。
如果从词汇表中删除部分词,则某些词的tokenize的种类集合就会变少,log(∗) 中的求和项就会减少,从而增加整体loss。
Unigram算法每次会从词汇表中挑出使得loss增长最小的10%~20%的词汇来删除。
Unigram与SentencePiece
一般Unigram算法会与SentencePiece连用。
SentencePiece
是谷歌推出的子词开源工具包。官方地址:https://github.com/google/sentencepiece。使用请参考:https://zhuanlan.zhihu.com/p/630696264。
支持多种分词方法,主要包括BPE和Unigram,同时支持Word-Level、Character-Level分词。
多语言支持:通过将所有输入转化为 Unicode 编码,SentencePiece 能够处理多种语言,解决了不同语言编码方式的差异问题。
可逆性:显式将空格作为基本标记,用特殊符号“▁”表示空格,从而实现分词和解码的可逆性。
无需预分词:SentencePiece 可以直接从原始文本进行训练,无需额外的预处理步骤。
轻量化:工具简单高效,适合大规模文本处理。
对于中文来说它并不是特别友好,主要体现为:sentencepiece会把某些全角符号强制转化为半角符号,这在某些情况下是难以接受的,而且还可能影响任务的评测结果。参考:https://spaces.ac.cn/archives/8209/comment-page-4
使用示例:
import sentencepiece as spm
# 训练 SentencePiece 模型
spm.SentencePieceTrainer.train('--input=train.txt
--model_prefix=m
--vocab_size=1000
--character_coverage=0.9995
--model_type=bpe')
# 加载模型
sp = spm.SentencePieceProcessor()
sp.load('m.model')
# 文本分词
text = "Hello, world!"
tokens = sp.encode_as_pieces(text)
print(tokens)结尾
亲爱的读者朋友:感谢您在繁忙中驻足阅读本期内容!您的到来是对我们最大的支持❤️
正如古语所言:"当局者迷,旁观者清"。您独到的见解与客观评价,恰似一盏明灯💡,能帮助我们照亮内容盲区,让未来的创作更加贴近您的需求。
若此文给您带来启发或收获,不妨通过以下方式为彼此搭建一座桥梁: ✨ 点击右上角【点赞】图标,让好内容被更多人看见 ✨ 滑动屏幕【收藏】本篇,便于随时查阅回味 ✨ 在评论区留下您的真知灼见,让我们共同碰撞思维的火花
我始终秉持匠心精神,以键盘为犁铧深耕知识沃土💻,用每一次敲击传递专业价值,不断优化内容呈现形式,力求为您打造沉浸式的阅读盛宴📚。
有任何疑问或建议?评论区就是我们的连心桥!您的每一条留言我都将认真研读,并在24小时内回复解答📝。
愿我们携手同行,在知识的雨林中茁壮成长🌳,共享思想绽放的甘甜果实。下期相遇时,期待看到您智慧的评论与闪亮的点赞身影✨!
万分感谢🙏🙏您的点赞👍👍、收藏⭐🌟、评论💬🗯️、关注❤️💚~
自我介绍:一线互联网大厂资深算法研发(工作6年+),4年以上招聘面试官经验(一二面面试官,面试候选人400+),深谙岗位专业知识、技能雷达图,已累计辅导15+求职者顺利入职大中型互联网公司。熟练掌握大模型、NLP、搜索、推荐、数据挖掘算法和优化,提供面试辅导、专业知识入门到进阶辅导等定制化需求等服务,助力您顺利完成学习和求职之旅(有需要者可私信联系)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)