大模型原理
大模型技术综述:本文系统介绍了多模态大模型的技术架构与应用场景,包括GPT-4、Claude3等主流模型分类。重点解析了Transformer架构的预训练机制和语言统计规律学习原理,详细阐述了知识蒸馏和量化两大核心技术。同时深入探讨了vLLM推理引擎的优化策略,包括PagedAttention和KVCache等关键技术创新,为提升大模型推理效率提供了解决方案。文章涵盖从模型训练到部署落地的全流程技
一、模型分类
- 多模态大模型:GPT-4、Claude 3、Gemini、Qwen-VL
- 任务专用模型:Whisper(仅语音转文本)、Stable Diffusion(仅图像生成)
按技术架构分:
- Transformer 架构大模型
- 混合专家模型(MoE)
- 传统神经网络模型
按用途分:
- 生成模型:找特征分布,如 大语言模型
- 判别模型:找差异,基于神经网络
大模型选型依据:
- 中文适配:针对中文语料优化,中文问答、多轮对话能力更优。
- 成本:开源,部署成本低,量化后对显存要求低,适合企业内部部署。
- 上下文窗口:支持 32k Token 长上下文,适合客服多轮对话 / 长文本查询(如订单详情)
二、本质
大模型并非 “理解” 语言 或 “拥有” 知识,而是基于海量数据的“模式学习”与“概率预测”。通过Transformer 架构捕捉语言的统计规律(词与词的关联、上下文逻辑和顺序),通过大规模预训练将海量文本中的模式(语法、语义、常识) “固化” 到模型参数中,再通过自回归生成,在给定上下文的前提下,预测下一个最可能出现的token,对新输入做出 “符合模式的响应”。数据越多、参数越大、训练越充分,模型的语言理解和生成能力越强。
三、工作流程
用户输入(Prompt)→ token化 → 转换为词向量 → Transformer理解输入(编码、特征提取) → 逐词自回归生成结果(解码、概率分布、向量转文字)
- 模型无法直接处理文字,需要先将输入文本拆成 “Token”(模型的基本处理单位);
- token转换为词向量;使用词嵌入算法(Embedding)将每个词转换为一个词向量;词向量的维度(512、1024、2048维)
- 词向量会传入 Transformer 编码器、解码器,通过 “自注意力 + 前馈神经网络” 处理;编码器会接收一个向量作为输入。编码器首先将这些向量传递到 Self-Attention 层,然后传递到前馈网络,最后将输出传递到下一个编码器。
- 模型的输出是 “逐词生成” 的,核心逻辑是 “用已生成的内容预测下一个词”;
为了让生成结果更贴合需求(如避免重复、符合逻辑),会引入采样策略(如 Top-K 采样、Top-P 采样)或调整 “温度(Temperature)” 调整token选择的随机性 —— 温度越低,生成结果越稳定保守(重复率可能高);温度越高,生成结果越随机(更有创意)。
详细步骤:
1、分词
将Prompt拆分为最小单位“token”。例如,中文句子“我喜欢人工智能”会被拆分为“我”“喜欢”“人工”“智能”4个token;英文句子“I love AI”会被拆分为“I”“love”“AI”3个token。不同模型的分词规则不同,比如GPT-4会将“人工智能”拆分为“人工”“智能”,而Claude可能直接拆分为“人工智能”。
2、Embedding(嵌入)
为每个token生成“数值向量”。这个向量会包含token的语义信息,例如“苹果”(水果)和 “苹果”(公司)会对应不同的向量,“医生”和“护士”的向量会更接近(语义相关),而“医生”和“汽车”的向量会更远(语义无关)。
最终,Prompt转化为一组包含“任务指令、功能需求、格式要求”的向量序列,输入到编码模块。
3、编码
核心是Transformer架构的“编码器”(Encoder),其作用是“深度理解梳理输入文本中每个词向量的上下文关系”。通过多层自注意力机制,编码器会计算每个token与其他所有token的关联权重,每个token的向量不仅包含自身语义,还融入了与其他token的关联信息,生成包含上下文信息的“编码向量”。
4、特征提取
由Transformer的“前馈神经网络”(Feed-Forward Network, FFN)生成,“从编码向量中挖掘上下文深层语义与逻辑,提取深层特征”,包括语义逻辑、情感倾向、任务意图等。
例如,面对Prompt“帮我写一封道歉信,因为我昨天迟到了”:编码模块会理解“道歉信”“昨天”“迟到”的关联;特征提取模块则会捕捉到“任务类型是写道歉信”“核心原因是迟到”“情感基调是愧疚”等深层信息。
FFN通过多层非线性变换,将编码向量转化为“高维特征向量”,为后续的“输出预测”提供精准依据。
5、解码
对应Transformer架构的“解码器”(Decoder),用于“预测下一个token”生成输出。它基于“编码后的特征向量”和“已生成的token序列”,逐一生成下一个最可能的token。 解码器生成每个token的向量后,通过“softmax函数”将其转化为“概率分布”,确定每个token的概率,选择概率最高(或按采样策略选择)的token向量。
解码过程遵循“自回归”逻辑:
第一步:基于输入的Prompt(如“写一段关于春天的话”),生成第一个token(如“春”);
第二步:将“春”加入“已生成序列”,结合原始Prompt的特征向量,生成第二个token(如“天”);
第三步:将“春天”加入“已生成序列”,继续生成第三个token(如“来”);
重复上述过程,直到生成“结束符”()或达到预设长度,最终形成完整输出(如“春天来了,花儿开了,鸟儿在枝头唱歌”)。
6、向量转文字
输出处理模块是输入处理模块的“逆过程”,通过“Embedding逆映射”,将解码器生成的“token向量”转化为人类可读懂的文字。把所有还原后的文字按顺序拼接,形成最终输出文本。
四、训练过程
1、预训练
让模型学习通用能力,学习语言的通用规律(语法、语义、常识),不针对具体任务。
海量无标注文本 通过 “自监督学习” 让模型学习预测规律,最常用的是因果语言建模—— 即 “给定前文,预测下一个词”。让模型逐渐掌握 “什么样的上下文 该接什么样的词”,进而学会 语法、语义、常识。
2、微调
让模式适配具体“专业型”任务。
用小规模有标注的数据(如 “问题 - 答案” 对、“原文 - 译文” 对),“修正” 预训练模型的参数,让模型学会 “根据任务要求输出结果”。
- 全参数微调
- 参数高效微调(PEFT):仅调整模型的部分参数(如 LoRA、Prefix Tuning),在保证效果的同时降低成本。提供Trainer类简化自定义数据集上的模型训练。
大模型一般参数量都比较大(几十亿、几百亿)、计算资源要求高、内存占用大,因此在资源有限的服务器上难以部署,为解决这一矛盾,知识蒸馏(KD) 和量化(Quantization) 成为大模型高效化的核心技术。
五、知识蒸馏
(一)核心思想
利用一个性能优异的大模型(教师模型) ,将其蕴含的 “知识” 迁移到一个结构更精简的小模型(学生模型) 中,使小模型在参数规模和计算量大幅降低的同时,性能接近教师模型。
“知识”:不仅仅是教师模型最终的预测结果(硬标签),更重要的是其输出的概率分布(软标签)。软标签包含了丰富的“暗知识”,例如不同类别之间的相似性关系。
(二)核心原理:“温度软化” 与 “双损失训练”
1、教师模型预训练:先训练一个高性能的教师模型(如 BERT-Base)。
2、学生模型初始化:设计一个结构更小的学生模型(如层数减半、隐藏层维度降低的 BERT-Tiny)。
3、软化输出与蒸馏训练:
- 引入温度参数(Temperature) ,对教师模型的 softmax 输出进行 “软化”
- 学生模型同时学习两个目标:
- 软损失(Soft Loss):学生模型的软化输出与教师模型的软化输出的 KL 散度,学习教师的 “深层知识”。
- 硬损失(Hard Loss):学生模型的原始输出与真实标签的交叉熵,保证基础任务性能。
- 总损失为两者的加权和。
(三)常用蒸馏的方法
| 方法类型 | 代表方法 | 核心思路 |
|---|---|---|
| 输出层蒸馏 | Hinton 经典 KD | 仅利用教师软化后的输出分布,适用于简单分类任务。 |
| 中间层蒸馏 | FitNets | 让学生模型的中间层特征映射 “模仿” 教师模型,通过 L2 损失对齐特征。 |
| 注意力蒸馏 | Attention Distillation | 对齐教师与学生的注意力权重(如 BERT 的自注意力矩阵),保留语义关联能力。 |
| 对比蒸馏 | Contrastive KD | 将教师模型的特征作为 “正样本”,其他样本作为 “负样本”,增强学生的特征区分度。 |
| 任务适配蒸馏 | TinyBERT | 针对 NLP 任务(如问答、文本分类),分 “预训练蒸馏” 和 “任务蒸馏” 两阶段优化。 |
缺点:依赖教师模型;训练复杂;主要减少参数数量,对单参数存储开销优化弱,压缩有限。
六、量化
(一)核心思想
将模型中高精度的数值(如 FP32、FP16)转换为低精度数值(如 INT8、INT4),通过减少每个参数的比特数,损失少量精度 降低模型存储占用和计算开销。确定一个缩放因子(scale) 和零点(zero point),将FP32的数值范围线性映射到INT8等低精度的数值范围。
高精度量化(FP16、TF32),低精度量化(INT8),极低精度量化(INT4、INT2)
(二)量化方法
训练后量化(PTQ):
- 流程:在FP32模型训练完成后,只需少量校准数据(无需标签)来观察各层激活值的分布范围,从而确定最佳的S和Z参数,然后直接再对权重和激活值进行量化,无需重新训练。
- 关键步骤:校准(Calibration)—— 用少量验证集数据统计权重 / 激活值的分布(如 Min-Max、KL 散度),确定量化范围,减少精度损失。
量化感知训练(QAT):
在模型训练(或微调)的前向传播中模拟量化误差(加入“伪量化”节点),但在反向传播中仍然使用高精度权重更新。让模型“提前适应”量化会带来的误差。
(三)如何减少量化误差?
量化的核心挑战是精度损失,需通过以下策略缓解:
- 范围校准:用 Min-Max(适合权重)或 KL 散度(适合激活值)确定量化范围,避免数值溢出或欠拟合。
- 分层量化:不同层对量化的敏感度不同(如 Transformer 的 FFN 层比注意力层更耐量化),对敏感层用更高位宽(如 INT8),非敏感层用低位宽(如 INT4)。
- 混合精度量化:权重用 INT8,激活值用 FP16,平衡精度与效率(如 MobileNetV2 的量化方案)。
- 零点偏移(Zero Point):通过非对称量化引入零点偏移,更好适配激活值的非对称分布(如 ReLU 输出的非负分布)。
(四)缺点
-
精度损失:低精度表示会引入舍入误差,可能导致模型性能下降。
-
溢出风险:如果激活值分布中有极端 outlier,低精度范围可能无法表示,导致严重误差。
七、模型推理
(一)vLLM
专注于大模型推理加速的开源引擎,通过先进的调度算法和 CUDA 优化,大幅提升 LLM 的吞吐量。优化了大模型内存碎片化、吞吐量受限阻塞 的问题。
核心优势:
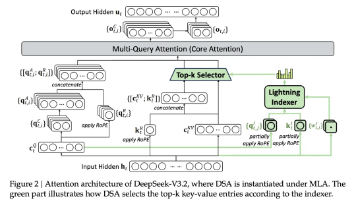
1、PagedAttention (分页注意力)机制:将每个序列的 KV Cache 分割成固定大小的 “块”(Block),每个块包含固定数量的 token;用 “页表” 记录块与序列的映射关系,页表可快速定位每个序列的完整 KV 数据,实现灵活的内存管理,让内存分配更紧凑。解决 KV 缓存(Key-Value Cache)的碎片化问题,内存利用率提升 2-4 倍,支持更长文本生成。
2、支持 连续批处理:不再等待整个批次完成后再处理新请求,而是动态插入新请求到空闲 “slot” 中,大幅减少请求等待时间(尤其对短序列)。并行处理不同长度的请求,吞吐量比 Hugging Face 原生实现高 10-20 倍。
3、支持 Prefix Caching:缓存对话历史的 KV 数据,避免重复计算。
from vllm import LLM, SamplingParams
# 多卡并行,通过 `tensor_parallel_size` 参数分配多张 GPU
llm = LLM(model="deepseek-moe-16b-chat", tensor_parallel_size=2)
# 批量问题
prompts = ["Hello, my name is", "What is the meaning of life?"]
# 设置采样参数
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
# 批量推理
outputs = llm.generate(prompts, sampling_params)(二)KV Cache
是优化LLM推理速度的关键技术,核心是 缓存已计算的Key 和 Value,避免重复计算。
- 在自回归生成中,生成第 t 个token时,需要计算它与前 t-1 个token的注意力,
- 若不缓存,每次生成新 token,都需要重新计算 所有历史token的 K 和 V ,复杂度O(t平方);
- 而 KV Cache 会存储前 t-1 个token的 K 和 V,生成第 t 个token时,仅需计算 第 t 个token的Q,再与缓存的K/V计算注意力,复杂度降至O(t);
代价是内存占用增加(存历史KV),长序列下 需要权衡缓存大小和性能。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)