一文看懂NVIDIA H100 :架构解析+性能对比
在AI军备竞赛的当下,高性能显卡成了兵家必争之地。但是,搭建算力集群造价不菲,对于正在成长中的企业而言,是一笔不小的资金压力。GPU云服务成为解决这一问题的关键。企业无需投入巨资自建数据中心,即可通过按需付费的方式,灵活地获取和使用全球最顶级的AI算力。PPIO GPU容器实例提供免运维 GPU 算力,用户可以开箱即用,无需复杂配置。单卡H100租用仅为12.9元/小时,计费透明,让更多中小企业及
NVIDIA H100 Tensor Core GPU 是英伟达于 2022 年上半年推出的高性能显卡,自发布以来,广泛应用于AI模型训练、科学计算等领域。
从技术层面看,H100集成了800亿个晶体管,采用先进的TSMC 4N定制工艺,并首次引入了为 Transformer模型量身打造的Transformer Engine和支持FP8精度的第四代Tensor Core。
这些创新使其在AI训练速度上比前代A100提升高达9倍,在AI推理方面更是实现了 30倍的惊人飞跃。本文将全面解析NVIDIA H100显卡的技术创新要点,为AI应用开发者及行业从业者提供参考。
Hopper架构:为万亿参数AI模型而生
NVIDIA H100的强大性能源于其全新的Hopper架构。
Hopper架构的设计理念是围绕“为大规模AI和HPC提供数量级的性能飞跃”这一核心目标,通过对计算单元、内存体系、互连技术和制程工艺的全方位革新,实现GPU计算能力的代际跨越。其主要革新点如下:
一群“数学天才”: 第四代 Tensor Core
第四代Tensor Core是H100计算能力的核心。相比A100,它在每个SM中的数量虽然不变,但其峰值计算能力实现了翻倍。
更重要的是,它引入了对FP8数据格式的原生支持。FP8相比FP16/BF16,可以将内存占用减半,计算吞吐量翻倍。
这就像一位数学家,不仅能用复杂的公式解题,还能用更简洁的符号,更快地得到答案。这对于动辄占用数十GB内存的大型语言模型至关重要。

一个“自动变速箱”: Transformer 引擎
Transformer Engine是Hopper架构的“点睛之笔”。
它是一种软硬件协同的技术,能够智能地分析Transformer模型中每一层的计算特点,并动态地在FP8和16位精度之间进行切换和转换。
例如,在矩阵乘法(GEMM)这类对精度不敏感的计算中,它会采用FP8以获得极致速度;而在需要保留更多信息的累加计算中,则切换回16位精度。整个过程对开发者完全透明,无需修改代码即可获得巨大的性能提升。
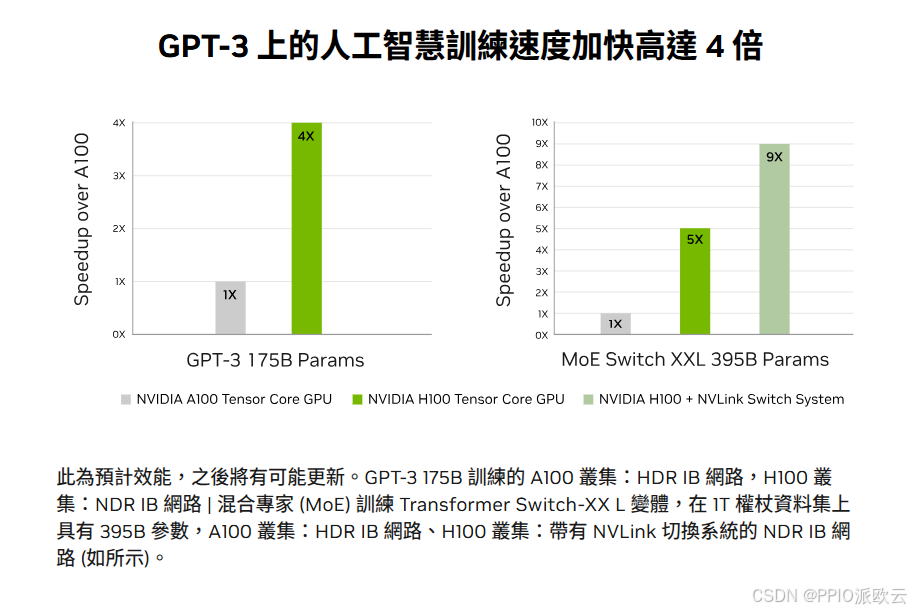
正是得益于 Transformer Engine,H100在训练大型语言模型时,结合NVLink Switch System,相比A100能够实现高达9倍的性能飞跃
一条“数据大动脉”:HBM3 内存
为喂饱强大的计算核心,H100在业界首次搭载了HBM3内存系统。
H100 SXM5版本的内存带宽高达3.35TB/s,相比A100的1.55TB/s (HBM2e)提升了超过一倍。如此高的带宽,确保了GPU在处理超大规模模型和数据集时,数据能够被迅速加载到计算单元,最大程度地减少了“等待数据”的时间。
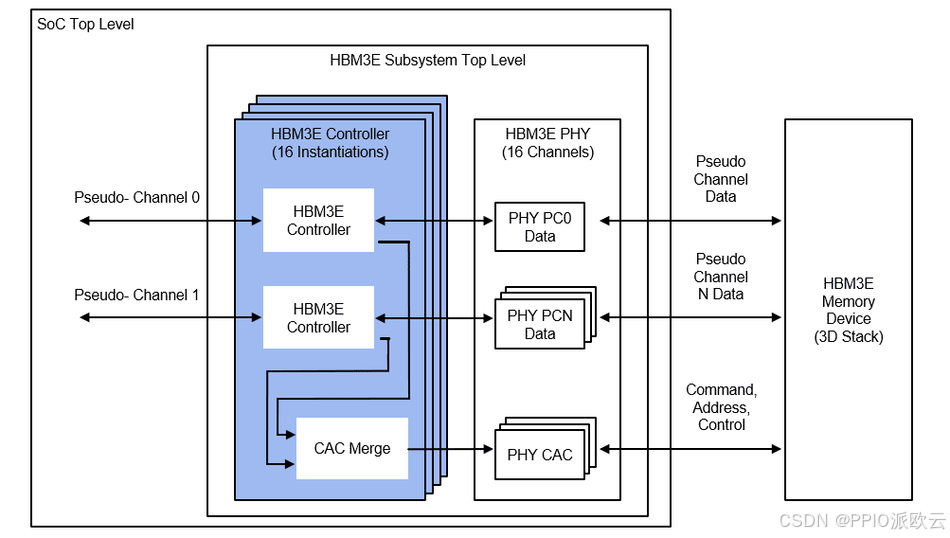
并且,H100配备了高达80GB的HBM3内存和50MB的L2缓存(A100为 40MB)。更大的缓存可以直接命中更多的数据,减少了对主内存的访问次数,进一 步降低延迟,提升整体性能。
一套“神经网络”:第四代 NVLink
在数据中心中,单一GPU的性能固然重要,但构建大规模计算集群的能力更为关键。
H100在这方面也进行了全面升级。第四代NVLink可以提供高达900GB/s的GPU间双向通信带宽,是A100的1.5倍,更是 PCIe 5.0的7倍。
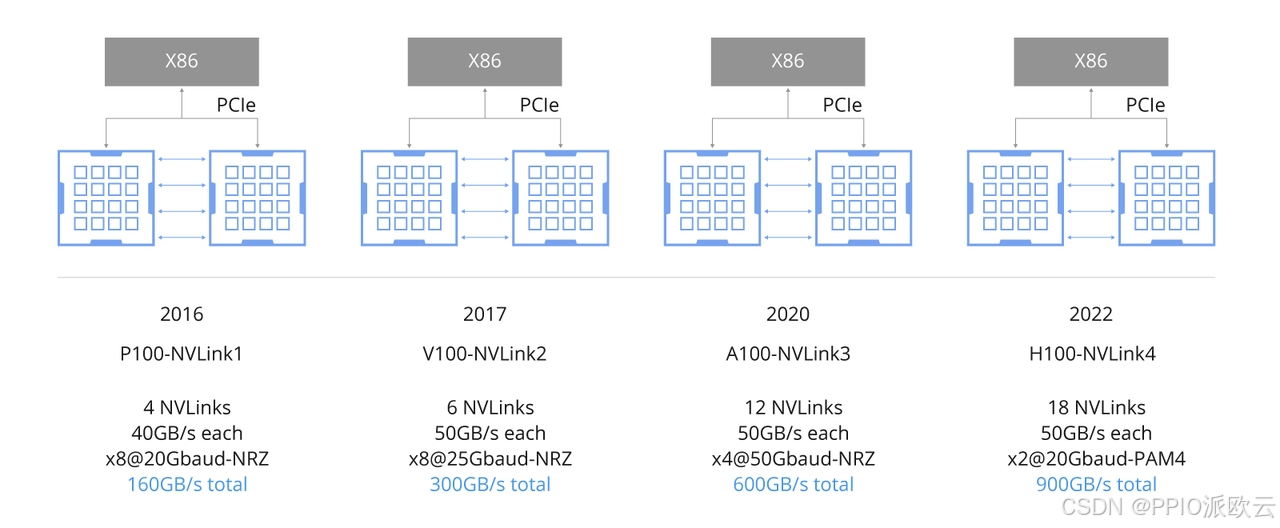
配合第三代NVSwitch,H100可以构建多达256个GPU互连的超级计算节点,节点内所有GPU之间都能以900GB/s的速度进行全对全通信,这对于需要频繁进行梯度同步的分布式训练至关重要。
H100也是首款支持PCIe 5.0的GPU,提供128GB/s的双向带宽,相比PCIe 4.0实现翻倍。这使得H100与CPU以及其他外设(如高速网卡)之间的数据交换速度更快,进一步提升了整个服务器系统的I/O性能。
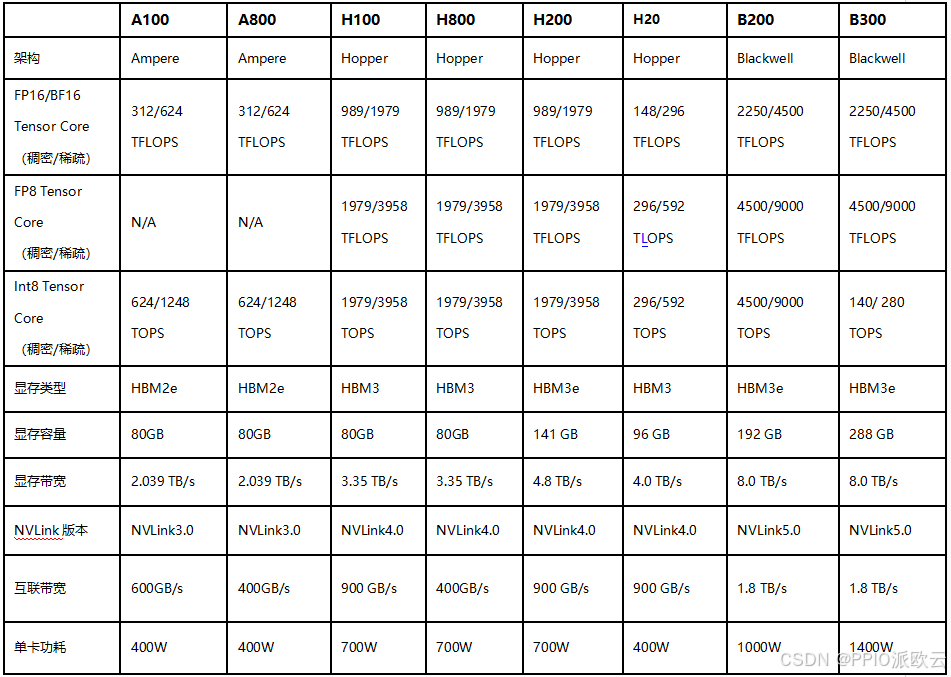
制程工艺与架构演进对比
H100的强大性能也得益于其采用了与台积电(TSMC)合作开发的4N定制工艺。
这一先进工艺使得NVIDIA可以在仅814mm²的芯片面积上,集成高达800亿个晶体管,相比A100 的542亿个晶体管增加了近50%,具体参数对比如下:
如果说训练决定了AI模型的能力上限,那么推理性能则直接关系到AI应用的部署成本和用户体验。H100在推理方面的提升甚至比训练更为惊人,相比A100实现了高达30倍的性能飞跃。
更令人期待的是,NVIDIA已经发布了H100的继任者——基于Blackwell架构的B100/ B200/GB200系列产品。据NVIDIA消息,Blackwell架构将带来又一次性能的巨大飞跃,包括采用更先进的制程工艺、第二Transformer Engine、第五代NVLink以及更高的内存带宽和容量。
Blackwell将在LLM推理等关键任务上,相比H100提供数倍的性能提升,并将能效比提升至新的高度。
结语
在AI军备竞赛的当下,高性能显卡成了兵家必争之地。但是,搭建算力集群造价不菲,对于正在成长中的企业而言,是一笔不小的资金压力。
GPU云服务成为解决这一问题的关键。企业无需投入巨资自建数据中心,即可通过按需付费的方式,灵活地获取和使用全球最顶级的AI算力。
PPIO GPU容器实例提供免运维 GPU 算力,用户可以开箱即用,无需复杂配置。单卡H100租用仅为12.9元/小时,计费透明,让更多中小企业及开发者可以使用性价比更高的GPU算力。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 6
6 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)