大模型Prompt优化全攻略:程序员必学的收藏级技术指南
本文详细介绍了大模型提示词(prompt)的工程化实践,包括prompt的组成结构、使用Velocity和Jinja2模板引擎进行组装的方法、调优经验及Context工程解决方案。文章通过具体示例展示了如何构建有效的prompt,处理模型幻觉问题,以及针对不同场景优化上下文管理,为开发者提供了一套系统化的大模型应用开发方法论。
一、prompt 组成及示例
prompt 一般由预设角色、技能(复杂的任务需给出处理步骤)、限制(如严格遵守的规则等)、输出要求、示例、历史会话和用户输入等部分组成,示例如下:
你现在是任务规划专家,你需要根据最新的输入内容(用户输入、上一步执行结果等),严格按照以下思考步骤,更新执行计划(EP)当前节点的内容。
***** 严格遵守规则 *******【严格遵守】绝对不允许调整执行计划的结构,只能变更当前节点的属性**【严格遵守】绝对不允许修改节点的status属性** ...(省略)
***** 风控领域基础知识 *****...(省略)
***** 可用的工具定义、描述、参数列表 *****=== 工具组:tableQuery =====工具编码: submitTableQuery* 工具描述: 查询表基础信息* 参数列表: tableName: 表名称,必填* 输出结果说明: 表的基础信息,其中 tableName 表示表名称, columns 表示列列表信息。...(省略)
***** 输出说明 *****最终需要输出两部分指定格式的内容:**第一部分是EP的更新说明,格式要求如下:使用\"@epupdatelog@\"作为起始符和结束符包裹更新信息,采用markdown格式,严格遵守以下格式:@epupdatelog@{更新内容说明}@epupdatelog@第二部分是最终更新后的EP内容,其中结构说明、EP节点属性说明、更新说明格式要求参考下面的描述,使用\"@EP@\"作为特殊符号包裹更新信息,严格遵守以下格式:@EP@*id=1*graph=digraph G { 1 [label ="标题1" shape=record type="function"]; 2[label =“标题2" shape=ellipse type="confirmtoolCode="”status="待用户输入中”toolInput=""toolOutput=""*,question=""];status="待初始化”]; 1->2;@EP@**EP结构说明**...(省略) ***** 参考示例 *****${caseList}
***** 当前执行计划详情 *****${curEP}
***** 用户对话历史 *****${history}
>>> 现在,让我们开始...>>> 当前的用户输入:${input}
二、prompt 组装
2.1 velocity 语法
prompt 模板在工程实践上可采用 velocity 语法进行配置,以使用 org.apache.velocity 包代码示例:
publicclassVelocityUtil {
privatestaticfinalVelocityEngineve=newVelocityEngine();
//...
publicstaticStringmerge(Stringtemplate, Map<String, Object>params) {
StringWritersw=newStringWriter();
ve.evaluate(newVelocityContext(params), sw, "", template);
returnsw.toString();
}
}
// prompt 拼接过程
Map<String, Object>params=newHashMap();
params.put("caseList", queryCaseList());
//......
Stringprompt=VelocityUtil.merge(prompteTemplate, params);
注意:#### 是 velocity 的注释符号,模板中不能使用。
2.2 Jinja2 模板
Jinja2 是一个基于 Python 的现代且功能丰富的模板引擎,广泛用于生成动态 HTML、XML 或其他标记语言内容。与Velocity的核心区别如下:
- Jinja2 更适合需要高灵活性、复杂逻辑的 Python 项目(如 Flask 应用),功能丰富且安全性强。
- Velocity 适合强调逻辑简单性、严格遵循 MVC 分离的 Java 项目,语法简洁但功能相对受限。
即 Python 优先选 Jinja2,Java 生态选 Velocity;复杂模板选 Jinja2,轻量需求选 Velocity。示例如下:
{# 基础提示词模板 #}{% block system_role %}你是一个{{ role }}。{% endblock %}
{% block user_query %}用户问题:{{ question }}{% if context %}附加上下文:{{ context }}{% endif %}{% endblock %}
{% block requirements %}生成要求:- 语言:{{ language }}- 长度限制:{{ max_length }}字{% endblock %}
三、prompt 调优经验
- 利用好 COT,遇到 badcase 需要排查大模型 COT,是否存在反复思考(或确认)的点,若存在,则 prompt 中可能存在矛盾点或描述不清的点。
- 排查 prompt 中示例和规则部分是否存在不合理的逻辑。
- prompt 优化到极致需要考虑是否由模型能力不足引起,在不更换模型的情况下可考虑增加 few-shot。若 few-shot 不起作用,可尝试单点 LLM 优化或者深度 workflow 模式。
- 开启深度思考模式,比如 Qwen 系列可通过标签 \think。
- 遇到大模型始终不遵守的规则,可采用 cot 方式在 prompt 中讲清楚思考规则。
- 通过示例对齐标准和强化推理,多次强调加强约束。
- 数字计算类的最好通过工具来解决。
- prompt 的指令的输出若包含推理依据和结论时,先给出推理依据,再给出结论(顺序不要搞反)。
- 学会控制大模型,比如输出工具和参数时,只需要让大模型给出参数 key 对应的 value 就行(一般参数名称 key 是确定的),来减小大模型的不确定性。
- 输出要求放到 prompt 的最后可能会起到意想不到的效果。
- 有的 prompt 包含模块较多,实战时“用户历史会话”部分放到 prompt 的最后,因会话信息格式杂乱,经常会影响大模型的输出,尝试将“输出格式”放到 prompt 最后,把“用户历史会话”上移,效果好了很多。
- 有时 prompt 中描述的太复杂,解释的越清晰,会起反作用。另外精准的描述会减小大模型的思考时间。如工具参数的复杂计算逻辑,大模型经常会出现幻觉。
- 大模型出现幻觉的常用解决方案:代码后处理进行工程兜底、few shot 中增加 COT。
四、Context 工程
随着 Agent 接入的业务场景日益增多,Prompt 逐渐变得零散且复杂。例如,在信贷风控场景中,规则需根据不同的客群进行区分,因此在优化 Prompt 时,必须为不同客群配置相应的知识上下文。然而,诸如风控基础知识、工具调用等部分又是多个场景共用的,如何有效组织和复用成为挑战。与此同时,会话历史中往往包含模型输出、用户对话以及工具执行记录等大量信息,过长的上下文不仅增加 token 数量,还容易导致大模型产生幻觉。随着业务知识不断沉淀,Prompt 的复杂度将持续攀升。在此背景下,上下文工程(Context Engineering)为解决这一系列问题提供了系统性的优化思路。context 工程并非要取代 prompt 工程,而是一个更高阶、更侧重于系统设计的必要学科。文章《Context Engineering》针对“丰富”的上下文可能出现的问题提出了几种解决方案,如下图:
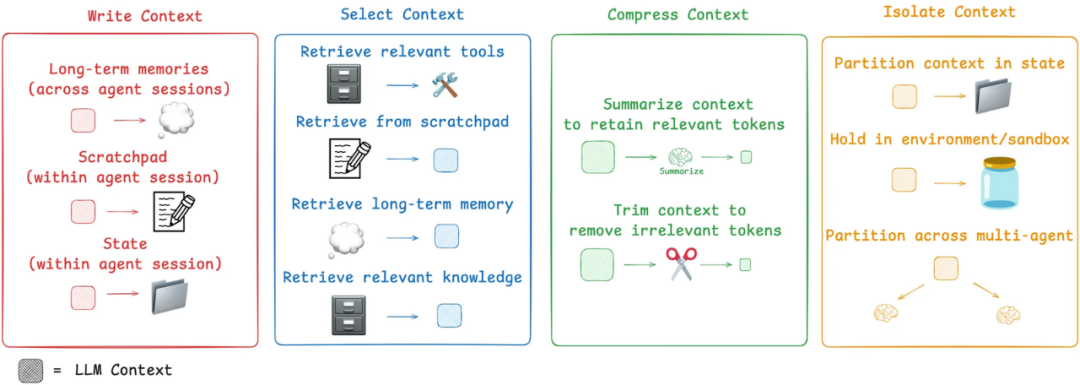
针对大模型经常出现幻觉上下文优化思路:
- 采用“Select Context”思路针对不同客群加载不同的知识和指令、预圈选可使用工具(只为特定任务获取最相关的工具)等。
- 采用“Compress Context”思路对工具执行结果进行摘要,同时过滤掉无用、错误的对话信息。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 19
19 0
0- 0



 已为社区贡献260条内容
已为社区贡献260条内容

所有评论(0)