OpenMMLab AI实战九——MMSegmentation
OpenMMlLab 图像分割算法库 MMSegmentation相关算法库详细 信息详见MMSegmentation官方文档任务:将图像按照物体的类别分割成不同的区域(对每个像素进行分类)图示应用领域:无人驾驶汽车、人像分割、智能遥感、医疗影响分析图像分割包括三种:语义分割、实例分割、全景分割仅考虑像素的类别不分割同一类的不同实体分割不同的实体仅考虑前景物体背景仅考虑类别前景需要区分实体图1
OpenMMLab 图像分割算法库 MMSegmentation
相关算法库详细 信息详见MMSegmentation官方文档
语义分割
任务:将图像按照物体的类别分割成不同的区域(对每个像素进行分类)
图示

应用领域:无人驾驶汽车、人像分割、智能遥感、医疗影响分析
图像分割包括三种:语义分割、实例分割、全景分割
| 语义分割(图1) | 实例分割(图2) | 全景分割(图3) |
|
仅考虑像素的类别 不分割同一类的不同实体 |
分割不同的实体 仅考虑前景物体 |
背景仅考虑类别 前景需要区分实体 |
 图1 图2 图3
图1 图2 图3
语义分割基本思路
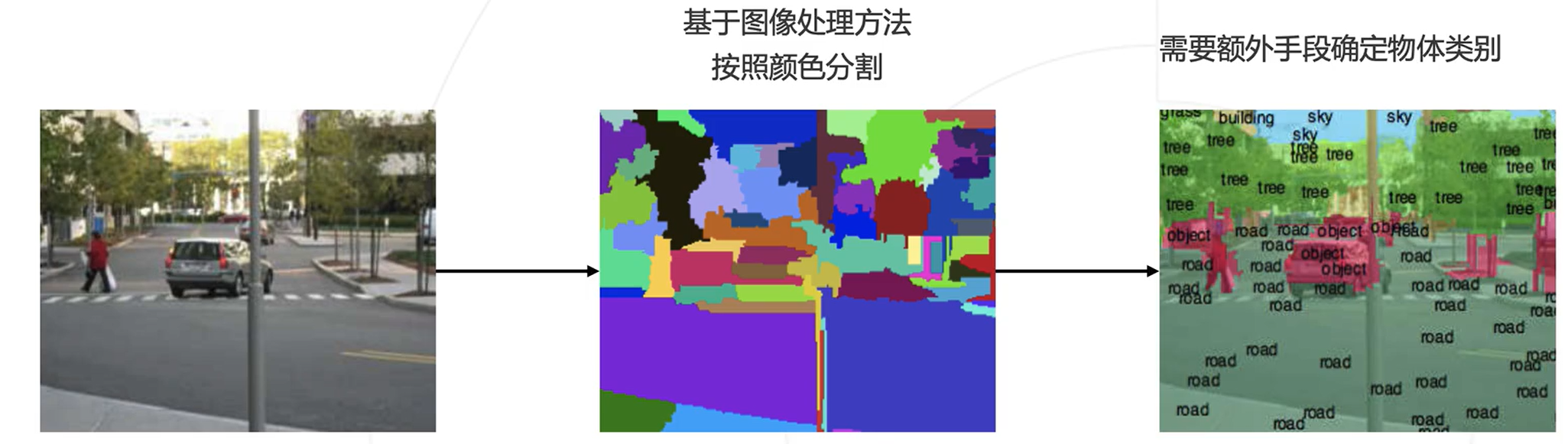
基本思路:按颜色分割
相关论文:Learning Hierarchical Features for Scene Labeling(2013)
先验知识:物体内部颜色相近,物体交界颜色变化(聚类的方法进行分割)
缺点:
-
先验知识不完全准确
-
不同物体颜色可能相近,物体内也会包含多种颜色
-
分割出的物体缺乏语义信息
图示
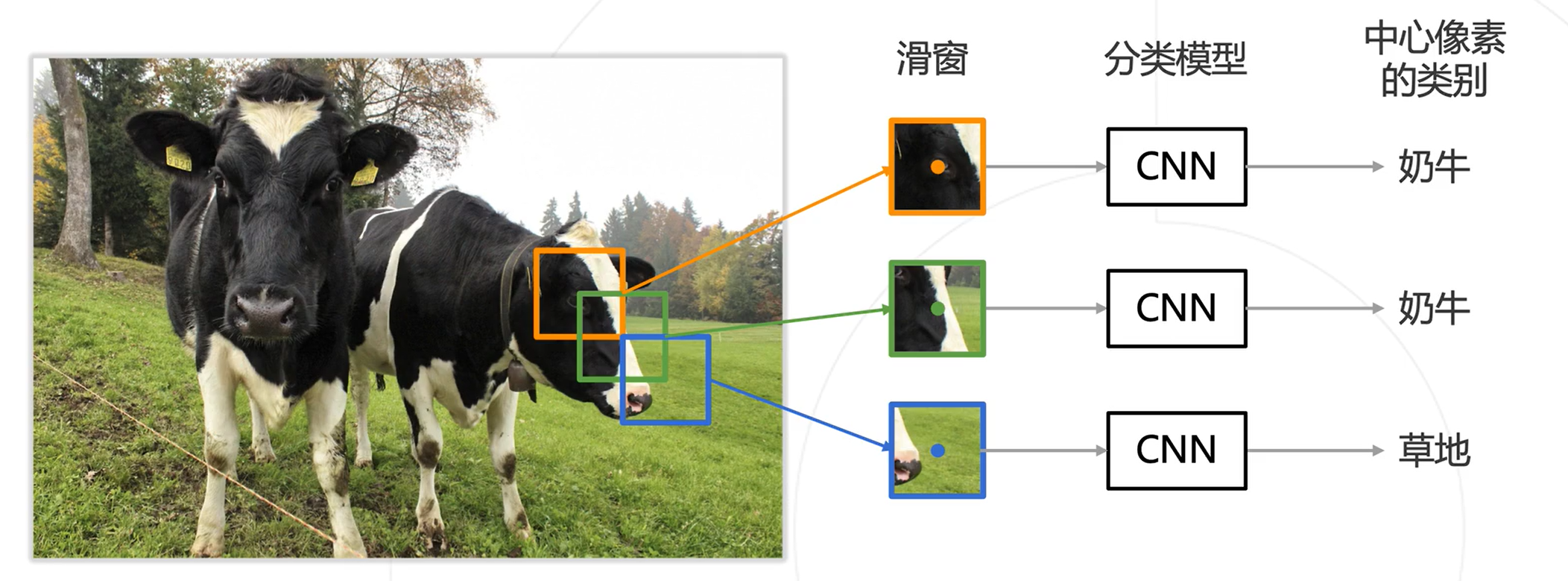
基本思路:逐像素分类
利用卷积神经网络的滑窗,将滑窗内的图片送入CNN中获得类别信息,将这种类别信息作为滑窗中心像素点的类别信息
优点:可以充分利用已有的图像分类模型
缺点:效率低下,重叠区域重复计算卷积
图示
改进思路:先在图片上做卷积,获得特征图后,再在特征图上进行滑窗
问题:在卷积神经网络中,利用全连接层进行图像分类,致使输入图片的大小必须固定,而语义分割中不一定固定
全连接层的卷积化(VGG)
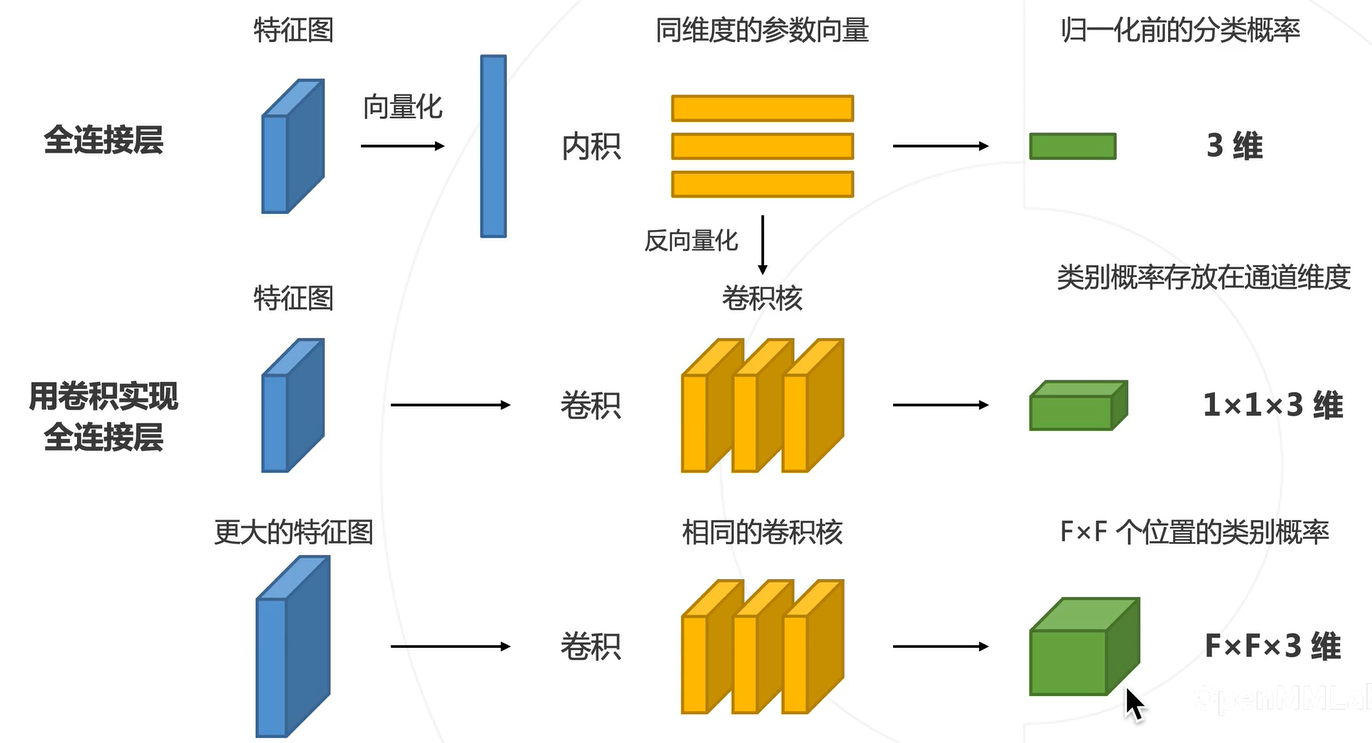
上下文信息
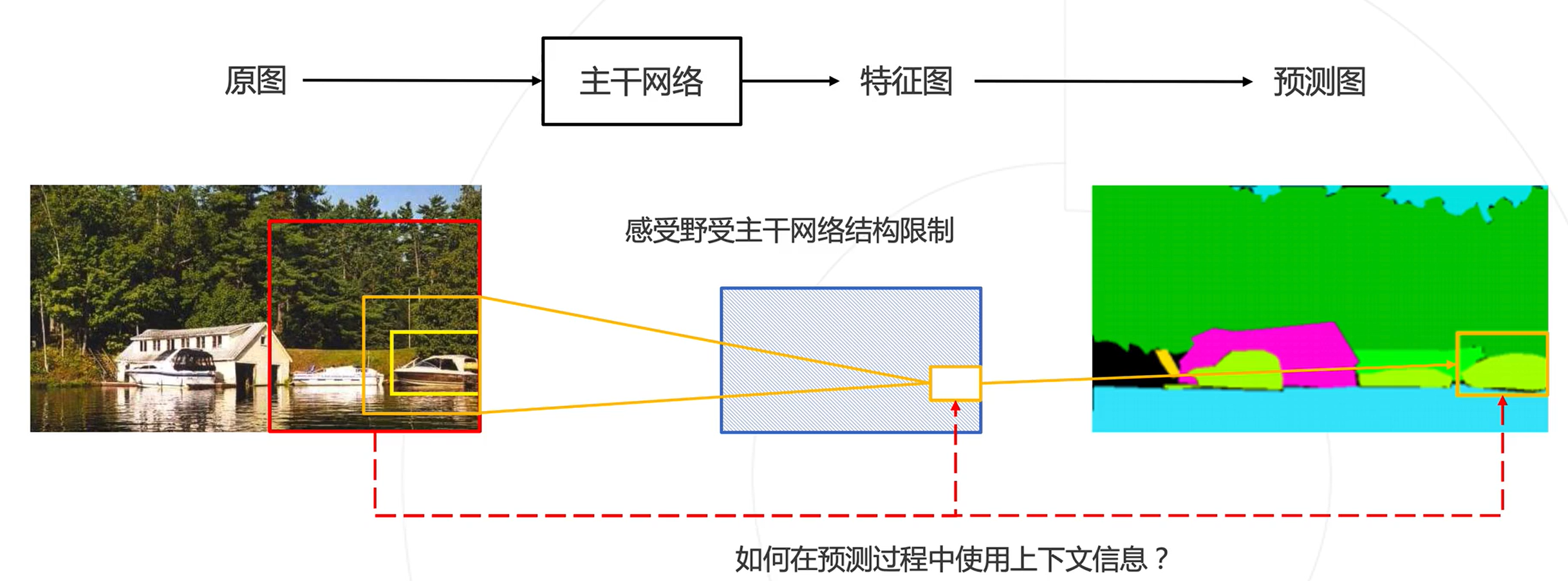
图像周围的内容(也称上下文)可以帮助我们做出更准确的判断。
如何在预测过程中使用上下文信息?
方案: 增加感受野更大的网络分支,将上下文信息导入局部预测中
图示
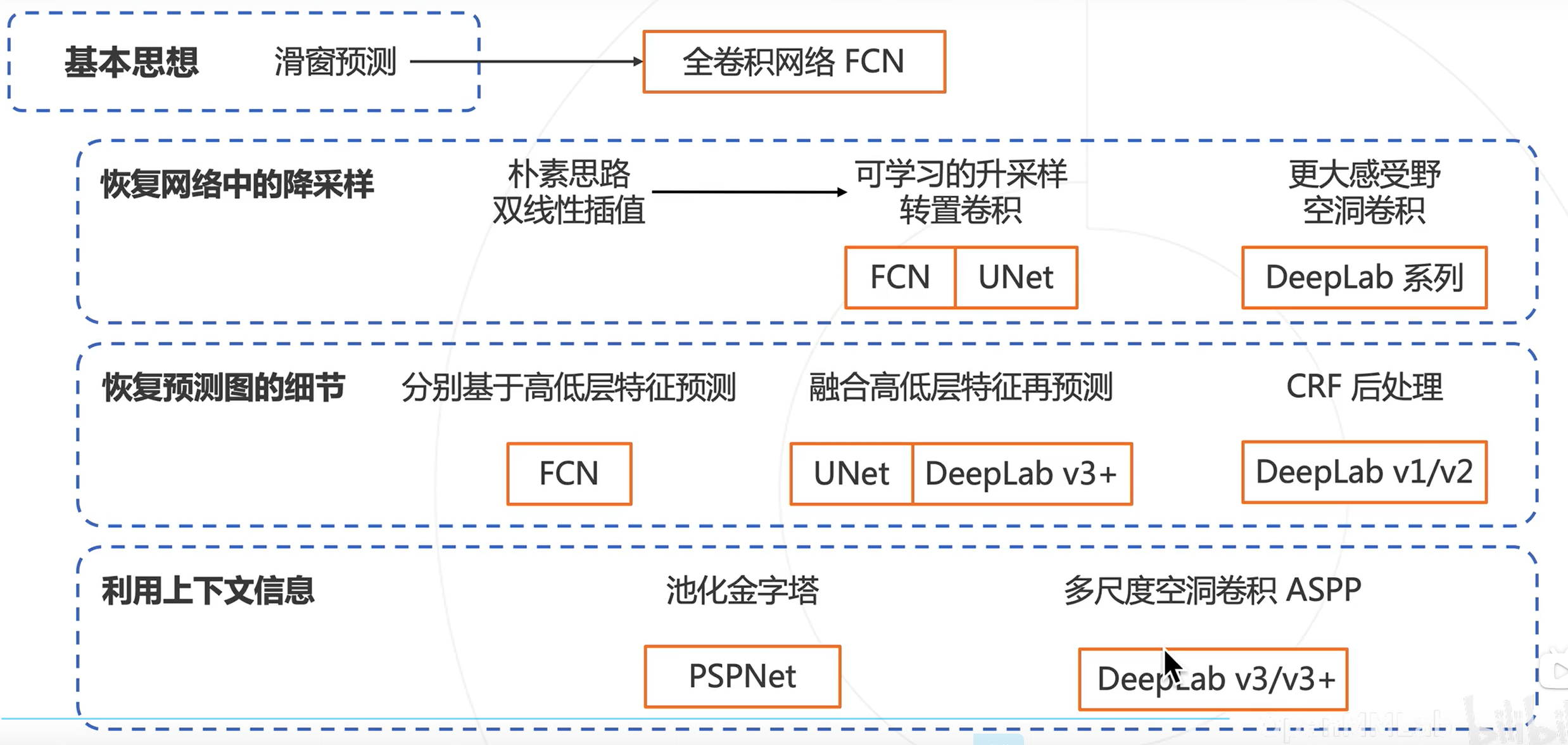
深度学习下的语义分割模型
全卷积网络
相关论文:Fully Convolutional Networks for Semantic Segmentation(2015)
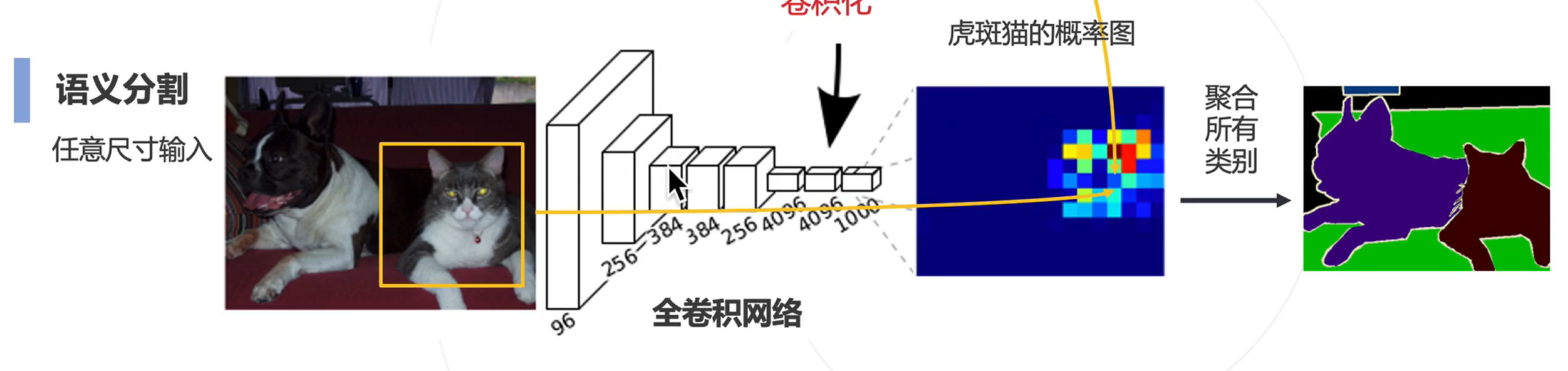
问题:图像分类模型使用降采样层(步长卷积或池化)获得高层次特征,导致全卷积网络输出尺寸小于原图,而分割要求同尺寸输出
解决方法:对预测的分割图上采样,恢复原图分辨率,上采样方案
-
双线性插值
-
转置卷积:可学习的上采样层
全卷积网络的预测与训练
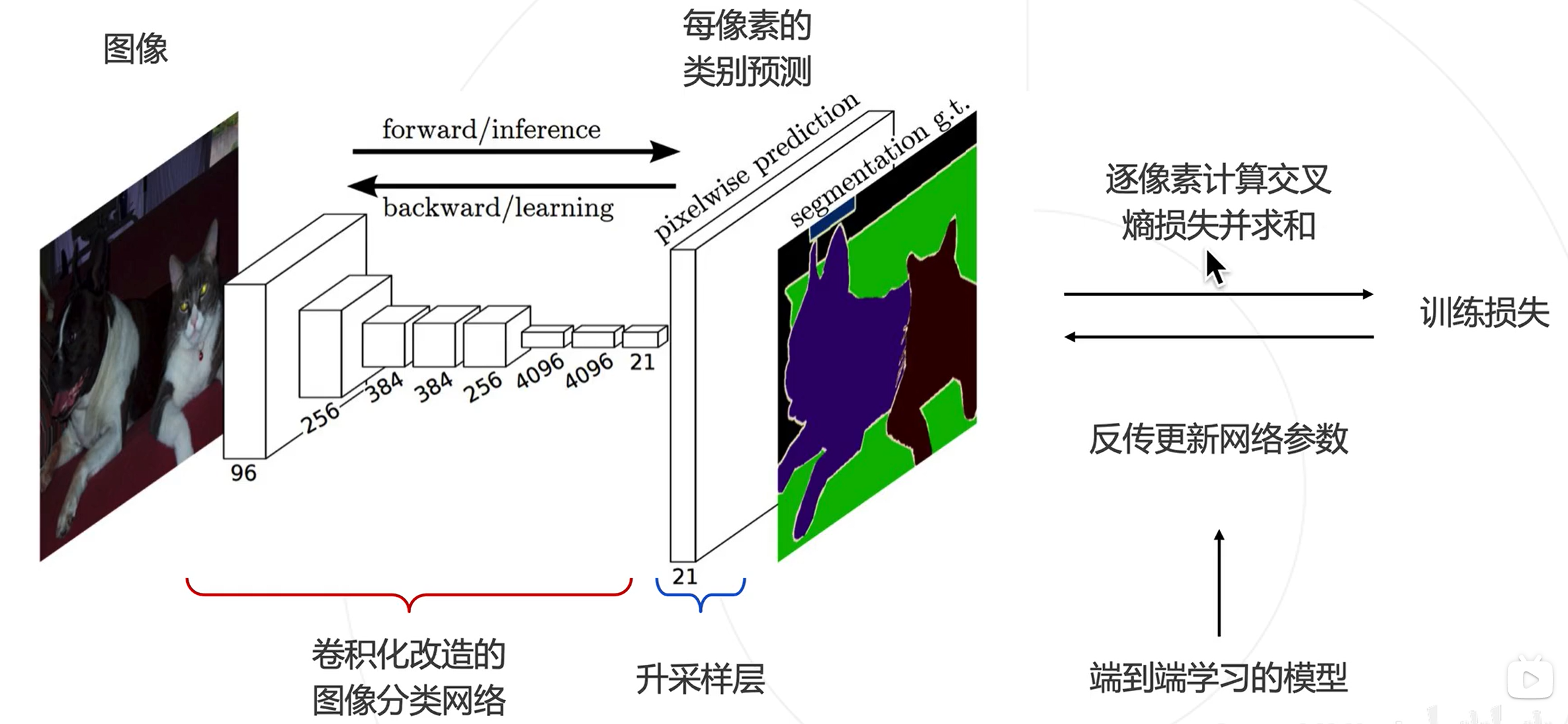
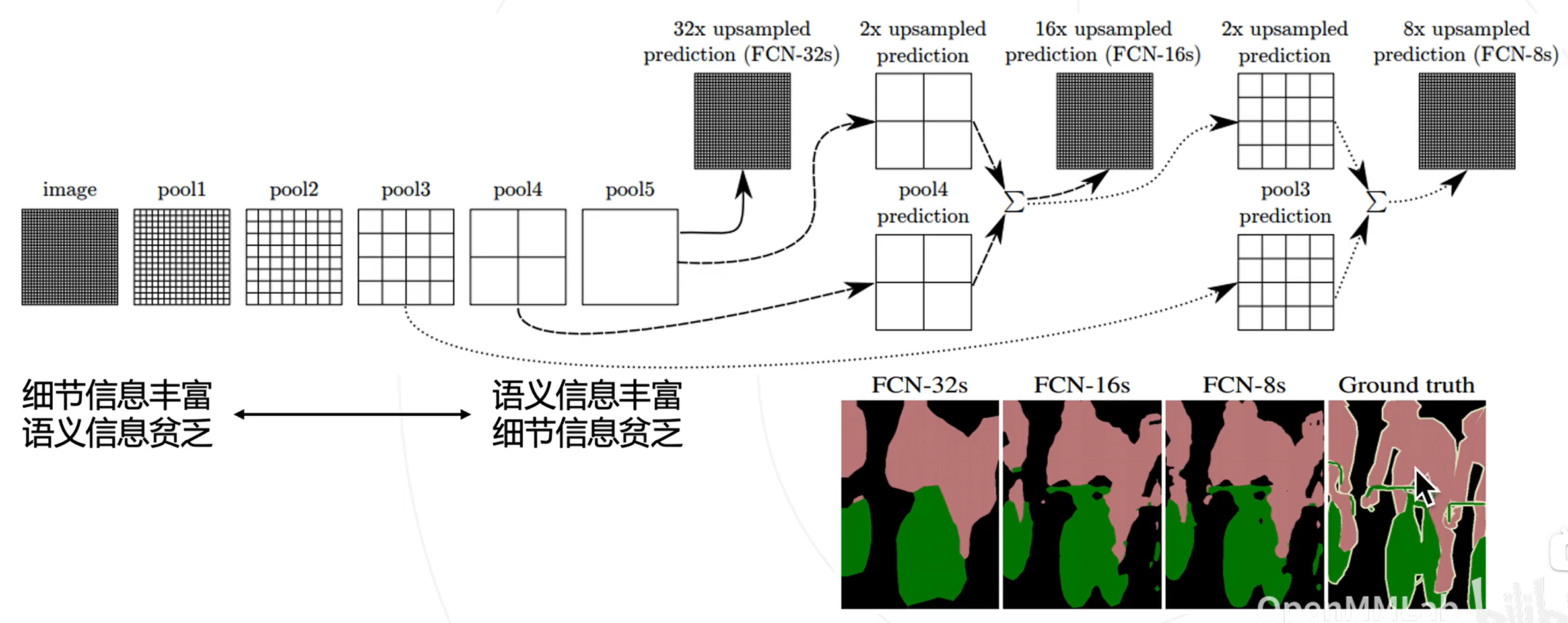
基于多层级特征的上采样
问题:基于顶层特征预测,再升采样32倍得到的预测图较为粗糙。
分析:高层特征经过多次降采样,细节丢失严重。
解决思路:结合低层次和高层次特征图。
解决方案FCN:基于低层次和高层次特征图分别产生类别预测,上采样到原图大小,再平均得到最终结果
图示
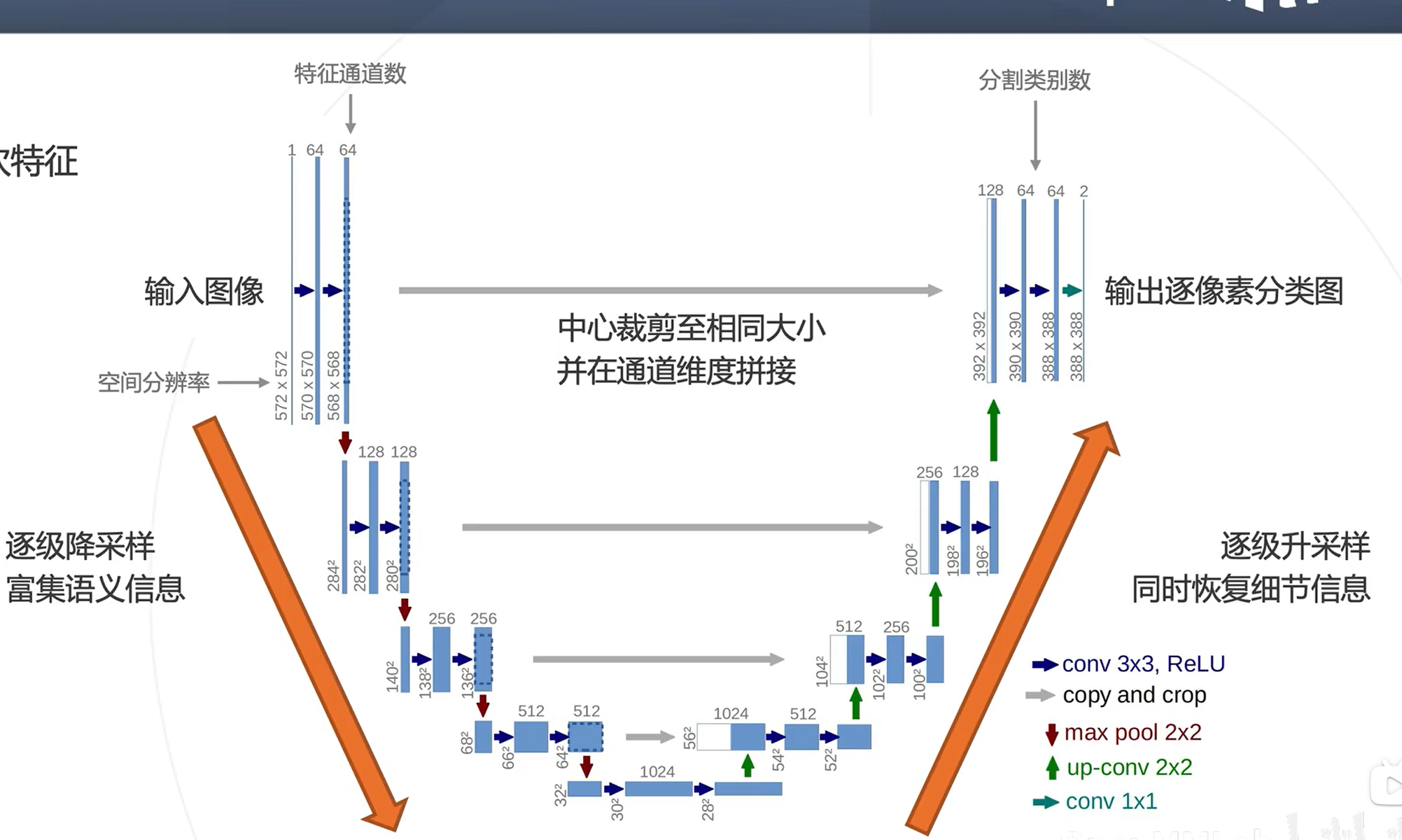
UNet
相关论文:U-Net: Convolutional Networks for Biomedical Image Segmentation(2015)
方法:逐级融合高低层次特征
PSPNet
相关论文:Pyramid Scene Parsing Network(2016)
图示
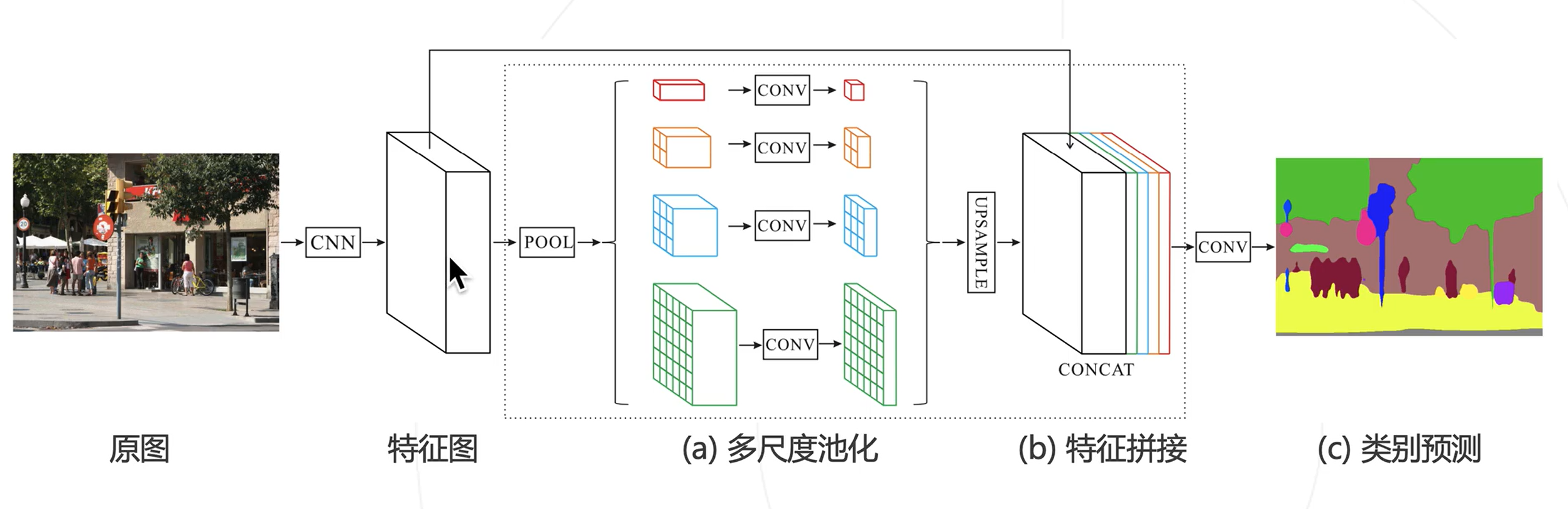
-
利用池化,特征有更大的感受野(小特征图对应大感受野;大特征图对应小感受野)
-
对特征图进行池化,得到不同尺度的上下文特征
-
上下文特征经过通道压缩和空间上采样之后拼接回原特征图→同时包含局部和上下文特征
-
基于融合的特征产生预测图
空洞卷积与DeepLab系列算法
相关论文:
-
Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs(DeepLabv1)(2014)
-
Rethinking Atrous Convolution for Semantic Image Segmentation(DeepLabv3)(2017)
-
Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation(DeepLabv3+)(2018)
主要贡献:
-
使用空洞卷积解决网络中的下采样问题
-
使用条件随机场CRF作为后处理手段,精细化分割图
-
使用多尺度的空洞卷积(ASPP模块)捕捉上下文信息
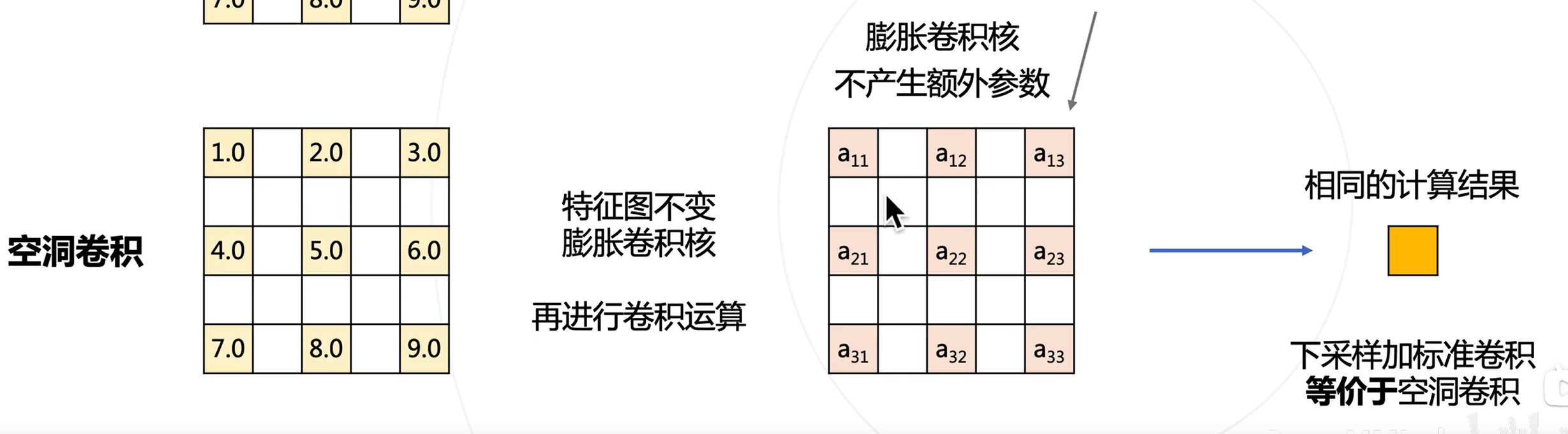
空洞卷积
主要用于解决下采样的问题
如果将池化层和卷积中的步长去掉:
-
可以减少下采样的次数
-
特征图就会变大,需要对应增大卷积核,以维持相同的感受野,但会增加大量参数
-
使用空洞卷积(Dilated Convolution/Atrous Convolution),在不增加参数的情况下增大感受野
图示
DeepLab模型
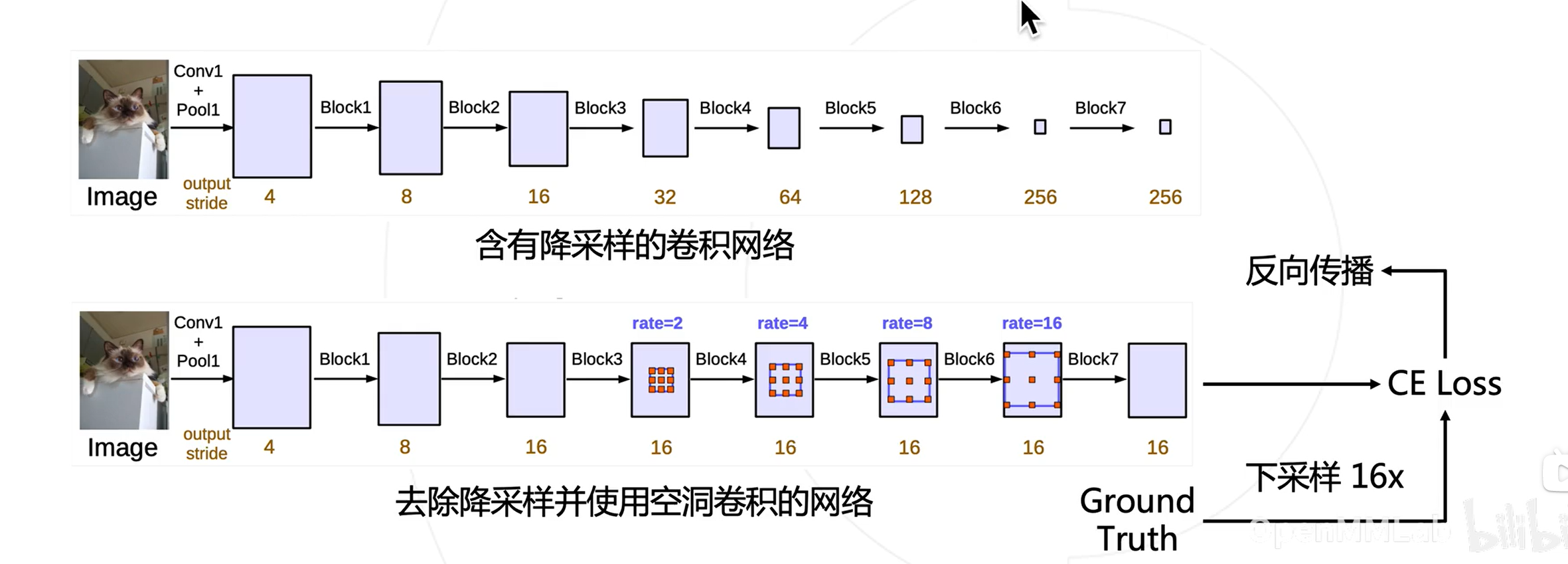
-
去除分类模型中的后半部分的下采样层
-
后续的卷积层改为膨胀卷积,并且逐步增加rate来维持原网络的感受野
CRF
CNN用于语义分割时存在一个明显的问题:空间不敏感
-
池化与卷积的缺点:CNN通过池化和卷积步长来增大感受野,整合上下文信息。但会降低特征图的空间分辨率,导致位置信息的丢失。
-
粗预测:即使通过上采样(Upsampling)或反卷积(Deconvolution)将特征图恢复到原图大小,得到的预测结果也往往是“模糊”和“粗糙”的。物体的边缘不清晰,小物体容易被预测错或漏掉。
简单来说,CNN善于判断“是什么”(物体的类别),但不善于精确定义“在哪里”(物体的精确边界)。
CRF是一种概率图模型,用于建模序列或空间上的数据。
-
核心思想:一个像素的类别标签,不仅取决于它自身的特征(如颜色),还取决于它周围像素的标签。
-
目标:为每个像素分配一个标签,使得整个图像的标签序列在概率上是最优的(即全局能量最低)。
-
相似的像素(颜色、纹理相近)被赋予相同的标签,而不相似的像素则被赋予不同的标签,从而使得分割边界与图像边缘更加吻合。
-
缺点:计算开销大、非端到端训练(先训练CNN,然后固定参数后再训练CRF)
-
优化方案:更大的空洞卷积与ASPP模块
ASPP
更大膨胀率的空洞卷积 -> 更大的感受野 -> 更多的上下文特征
总结
语义分割算法前沿
相关论文:
-
SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers(2021)
-
Per-Pixel Classification is Not All You Need for Semantic Segmentation(2021)
-
Masked-attention Mask Transformer for Universal Image Segmentation(2021)
分割模型的评估方法
真实图与预测图

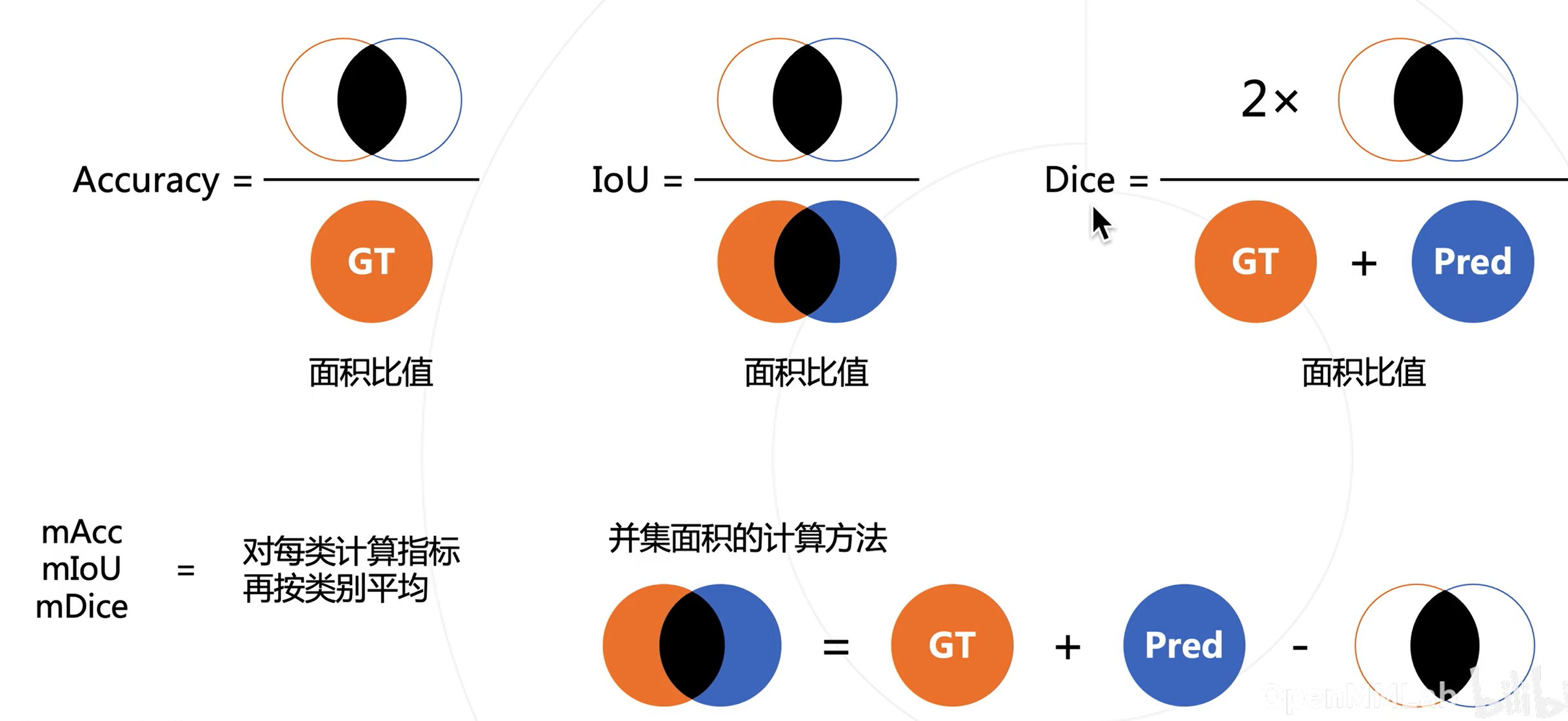
Dice可看作为某种调和平均数

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 13
13 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)