强化学习训练后,大模型推理能力边界如何变化?程序员必读
本研究系统评估了带可验证奖励的强化学习(RLVR)对大语言模型推理能力的影响。通过pass@k指标分析发现,尽管RLVR能提升模型在低k值下的采样效率,但随着k值增大,基础模型的性能反超RLVR模型,且RLVR生成的推理路径已存在于基础模型中。研究表明当前RLVR方法未能让模型获得超越基础模型的新推理能力,在充分挖掘基础模型潜力方面远未达到最优水平,亟需改进强化学习范式以释放其潜力。
简介
本研究系统评估了带可验证奖励的强化学习(RLVR)对大语言模型推理能力的影响。通过pass@k指标分析发现,尽管RLVR能提升模型在低k值下的采样效率,但随着k值增大,基础模型的性能反超RLVR模型,且RLVR生成的推理路径已存在于基础模型中。研究表明当前RLVR方法未能让模型获得超越基础模型的新推理能力,在充分挖掘基础模型潜力方面远未达到最优水平,亟需改进强化学习范式以释放其潜力。
今天来看一篇文章来探究RL是否能让LLM获取超越基础模型的推理能力:《Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?》
带可验证奖励的强化学习(RLVR)
近年来,带可验证奖励的强化学习(Reinforcement Learning with Verifiable Rewards, RLVR)在提升大语言模型(Large Language Models, LLMs)的推理性能方面展现出显著成效,尤其在数学和编程任务中表现突出。人们普遍认为,与传统强化学习(RL)帮助智能体探索并学习新策略的机制类似,RLVR 能让大语言模型实现持续的自我改进,进而获得超越其基础模型能力范围的全新推理能力。
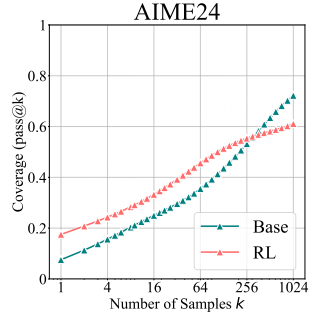
在本研究中,我们以大 k 值下的 pass@k 指标为评估标准,通过在不同模型系列、强化学习算法,以及数学 / 编程 / 视觉推理基准测试集上,系统性地探究经 RLVR 训练的大语言模型的推理能力边界,对 RLVR 的研究现状进行了批判性分析。研究发现,尽管 RLVR 能提高模型向正确路径采样的效率,但当前的训练方法并未催生出本质上全新的推理模式。具体而言,在 k 值较小时(如 k=1),经 RLVR 训练的模型性能优于其基础模型;但当 k 值增大时,基础模型的 pass@k 得分反而更高。此外,我们还观察到,随着 RLVR 训练的推进,大语言模型的推理能力边界往往会收窄。
进一步的覆盖率与困惑度分析表明,RLVR 模型生成的推理路径已包含在基础模型的采样分布中,这意味着 RLVR 模型的推理能力源于基础模型,且受限于基础模型的能力范围。从这一角度出发,若将基础模型视为能力上限,我们的定量分析显示:六种主流 RLVR 算法的性能表现相近,且在充分挖掘基础模型潜力方面远未达到最优水平。与之形成对比的是,我们发现知识蒸馏(distillation)能够从教师模型中引入新的推理模式,真正拓展模型的推理能力。
综合以上发现,当前的 RLVR 方法尚未充分发挥强化学习的潜力,未能让大语言模型获得真正新颖的推理能力。这凸显出我们亟需改进强化学习范式 —— 例如通过持续扩展规模、实现智能体与环境的多轮交互等方式 —— 以释放强化学习在提升大语言模型推理能力方面的潜力。
项目主页:https://limit-of-RLVR.github.io
- 引言
以推理为核心的大语言模型(如 OpenAI-o1(Jaech 等人,2024)、DeepSeek-R1(Guo 等人,2025)和 Kimi-1.5(Team 等人,2025))的发展,极大地拓展了大语言模型的能力边界,尤其在解决涉及数学和编程的复杂逻辑任务方面成效显著。
传统的指令微调方法依赖人工整理的标注数据(Achiam 等人,2023;Grattafiori 等人,2024),而推动大语言模型能力实现这一飞跃的关键驱动力,是大规模的带可验证奖励的强化学习(RLVR)(Lambert 等人,2024;Guo 等人,2025)。
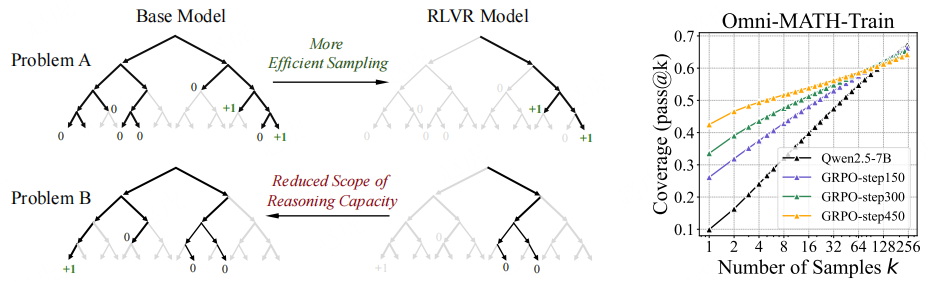
图 1:(左)当前 RLVR 对大语言模型(LLM)推理能力的影响。针对某一问题,通过对基础模型和经 RLVR 训练的模型进行重复采样,生成搜索树。灰色表示模型大概率不会采样的路径,黑色表示模型大概率会采样的路径,绿色表示正确路径(可获得正奖励)。我们的核心发现是:RLVR 模型中的所有推理路径均已存在于基础模型中。对于 “问题 A” 这类特定问题,RLVR 训练会使模型的采样分布向有奖励的路径倾斜,从而提升采样效率;但这一优势的代价是推理能力范围的缩小 —— 对于 “问题 B” 这类其他问题,基础模型包含正确路径,而 RLVR 模型却不包含。(右)随着 RLVR 训练的推进,模型的平均性能(即 pass@1 指标)有所提升,但可解决问题的覆盖率(即 pass@256 指标)却在下降,这表明大语言模型的推理边界在缩小。
RLVR 以预训练基础模型或经 “思维链(Chain of Thought, CoT)” 数据微调后的模型为起点,基于简单且可自动计算的奖励,通过强化学习对模型进行优化。这些奖励的判定依据是:在数学任务中,模型输出是否与真实解匹配;在代码任务中,模型输出是否能通过单元测试。这种奖励机制无需人工标注,因此具备良好的可扩展性。该框架因其简洁性和实际有效性,已获得广泛关注。
在游戏(如雅达利游戏、围棋)等传统强化学习场景中,智能体通常能通过自我改进自主探索新策略,甚至超越人类水平(Mnih 等人,2015;Silver 等人,2017)。受此启发,人们普遍认为,RLVR 同样能让大语言模型自主形成全新的推理模式(包括枚举、自我反思、迭代优化等),进而超越其基础模型的能力(Guo 等人,2025)。因此,RLVR 被视为实现大语言模型持续自我进化的潜在路径,有望帮助我们更接近更强大的智能体(Guo 等人,2025)。
然而,尽管 RLVR 在实证中取得了成功,其背后的实际效用仍未得到充分研究。这引发了一个核心问题:当前的 RLVR 是否真能让大语言模型获得全新的推理能力(如同传统强化学习通过探索发现新策略那样),还是仅仅在利用基础模型中已有的推理模式?
要严谨回答这一问题,我们首先需评估基础模型与经 RLVR 训练的模型各自的推理能力边界。传统评估指标依赖贪心解码或核采样(nucleus sampling)的平均得分(Holtzman 等人,2020),这类指标仅能反映模型的 “平均表现”。但它们存在低估模型真实潜力的风险 —— 例如,某些模型在有限尝试中可能无法解决难题,但通过更多次采样却能成功解决。
为克服这一局限,我们采用 pass@k 指标(Brown 等人,2024):若从模型采样的 k 个输出中存在至少一个正确答案,则认为该问题已被解决。通过允许模型进行多次尝试,pass@k 指标能揭示模型是否具备解决某一问题的潜力。在数据集上的平均 pass@k 得分,可反映模型在 k 次尝试内有望解决的问题比例,从而更可靠地展现其推理边界。这一指标为 “RLVR 训练是否能让模型获得突破性能力(即解决基础模型无法解决的问题)” 提供了严谨的检验标准。
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

我们以 pass@k 为评估指标,在多个基准测试集上开展了大量实验,涵盖不同系列的大语言模型、不同模型规模及不同 RLVR 算法,对比基础模型与其经 RLVR 训练后的版本。研究发现了若干出人意料的结论,这些结论不仅能更全面地评估当前 RLVR 训练的有效性,还揭示了现有 RLVR 方法与 “发现真正全新推理策略” 这一强化学习理想目标之间的差距:
-
当前 RLVR 模型的推理覆盖范围窄于基础模型
:在 pass@k 曲线中,尽管 RLVR 模型在 k 值较小时表现优于基础模型,但令人意外的是,随着 k 值增大,在所有基准测试集和所有系列的大语言模型中,基础模型的性能均持续超过 RLVR 模型。这表明当前的 RLVR 训练并未扩大、甚至缩小了模型可解决问题的推理范围。对模型响应的人工检查显示,对于大多数问题,基础模型至少能生成一条正确的思维链(CoT)—— 这意味着,对于此前被认为只有 RLVR 模型能解决的问题,基础模型其实早已能生成正确的推理路径。
-
当前 RLVR 模型生成的推理路径已存在于其基础模型中
:为进一步探究上述现象,我们对准确率分布进行了分析。结果显示,RLVR 虽能通过 “在基础模型已能解决的问题上更高效地采样” 提升平均性能(即 pass@1 指标),但无法让模型解决新的问题。进一步的困惑度分析表明,RLVR 模型生成的推理路径,已包含在基础模型的输出分布中。这些发现表明,RLVR 并未赋予模型全新的推理能力,当前 RLVR 模型的推理能力仍受限于其基础模型。RLVR 的这一影响可参考图 1(左)。
-
当前 RLVR 算法性能相近且远未达最优
:我们将基础模型视为能力上限,定义了 “采样效率差距(∆SE)”(见图 8(上))—— 即 RL 模型的 pass@1 得分与基础模型的 pass@k 得分(以 k=256 作为上限性能的代理指标)之间的差值。该指标可量化 RL 算法与最优边界的接近程度。结果显示,在所有算法(如 PPO、GRPO、Reinforce++)中,∆SE 的差异极小,但数值始终较大。这表明当前的 RLVR 方法虽能提升采样效率,但仍远未达到最优水平。
-
RLVR 与知识蒸馏存在本质差异
:RLVR 通过更高效地采样高奖励输出来提升推理得分,但无法激发模型的新推理能力,且始终受限于基础模型的能力范围。与之相反,知识蒸馏能将更强的教师模型的新推理模式迁移到学生模型中,因此,经蒸馏的模型往往能展现出超越基础模型的推理范围。
综上,我们的研究结果表明:当前的 RLVR 方法虽能提升采样效率,却无法让模型获得超越基础模型能力范围的全新推理能力。这一发现凸显了现有 RLVR 方法与强化学习目标之间的差距,也强调了我们亟需改进强化学习范式 —— 例如通过持续扩展规模、优化探索机制、实现智能体多轮交互等方式 —— 以释放其潜力。
- 预备知识
=======
本节首先概述 RLVR 的基本原理,随后介绍用于评估推理边界的 pass@k 指标,并解释为何选择该指标而非 “最优 N 选 1(best-of-N)” 等其他指标。
2.1 带可验证奖励的强化学习(RLVR)
可验证奖励(Verifiable Rewards)
设 πₜ为参数为 θ 的大语言模型,该模型以自然语言提示 x 为条件,生成 token 序列 y=(y₁, …, y_T)。确定性验证器 V 会返回一个二元奖励:r = V (x, y) ∈ {0, 1},其中 r=1 当且仅当模型的最终答案完全正确。此外,还可添加 “格式奖励”,以鼓励模型将推理过程与最终答案明确区分开。强化学习的目标是学习一个策略,以最大化期望奖励:J (θ) = 𝔼ₓ∼D [𝔼ᵧ∼πₜ(・|x)[r]],其中 D 为提示的分布。
RLVR 算法
近端策略优化(PPO)(Schulman 等人,2017)提出使用以下裁剪代理函数来最大化目标函数:
L_CLIP = 𝔼[min(rₜ(θ)Aₜ, clip(rₜ(θ), 1−ε, 1+ε)Aₜ)] (1)
其中,rₜ(θ) = πₜ(yₜ|x, y<ₜ)/πₜₒₗ𝚍(yₜ|x, y<ₜ),Aₜ为价值网络 V_φ 所估计的优势函数。此外,还可选择性地加入 KL 散度项,以限制模型与原始策略的偏差过大。
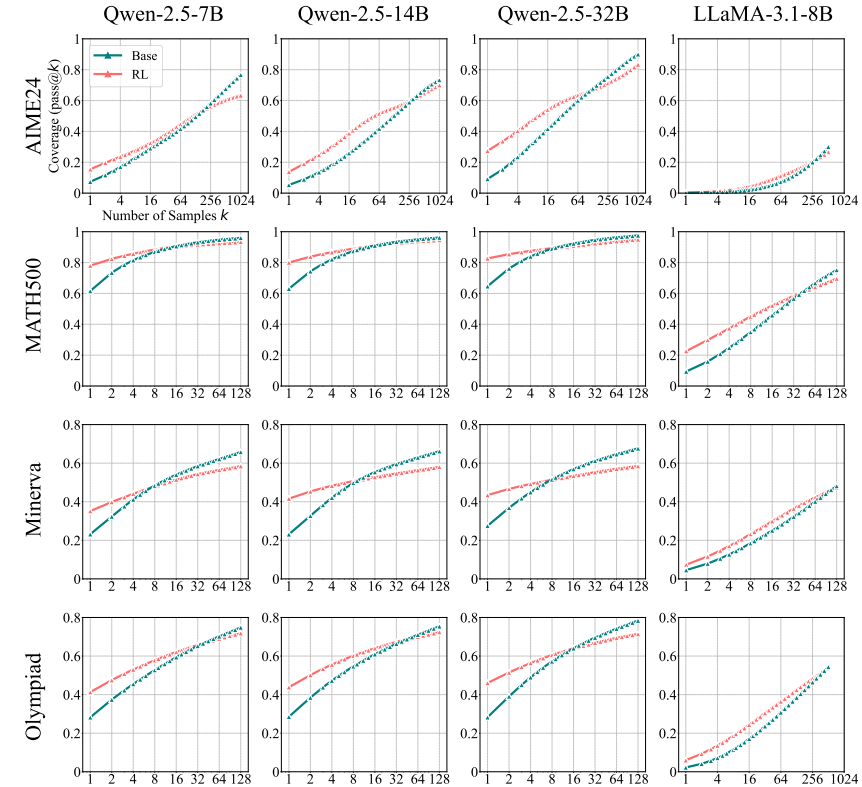
图 2:基础模型与其经 RLVR 训练的模型在多个数学基准测试集上的 pass@k 曲线。当 k 值较小时,经 RL 训练的模型性能优于其基础模型版本;但当 k 值增大到几十或几百时,基础模型会持续追赶并超越经 RL 训练的模型。关于 GSM8K 和 AMC23 数据集的更多结果可参见图 9。
(注:“policy” 为前文 “原始策略(original policy)” 的延续表述,此处完整语义为 “(KL 散度项可)限制模型与原始策略的偏差过大”,相关算法细节详见附录 D.4。)
策略梯度(Policy Gradient)
近端策略优化(PPO)及其变体均属于强化学习中的策略梯度类方法(Williams, 1992;Sutton 等人,1998)。这类方法仅通过 “在策略样本(on-policy samples)” 学习 —— 即样本均由当前大语言模型生成。在可验证奖励的场景下,训练目标通常是 “最大化正确答案样本的对数似然”,同时 “最小化错误答案样本的似然”。
零强化学习训练(Zero RL Training)
零强化学习训练指 “无需任何监督微调(SFT),直接对基础模型应用强化学习”(Guo 等人,2025)。为清晰探究 RLVR 的效果,我们在所有数学任务中均采用该零强化学习设置,以预训练模型作为初始模型。但在代码生成和视觉推理任务中,开源研究通常以 “经指令微调的模型” 作为起点 —— 主要原因是 “纯零强化学习设置” 存在训练不稳定、效果有限的问题。遵循这一惯例,我们将 “经指令微调的模型” 与其 “经 RLVR 训练的版本” 进行对比,以单独聚焦 RLVR 的作用。
2.2 大语言模型推理能力边界的评估指标
pass@k 指标(Pass@k Metrics)
准确衡量基础模型与 RL 模型的推理能力边界具有挑战性 —— 贪心解码、核采样平均值(Holtzman 等人,2020)等方法仅能反映模型的 “平均表现”。为精准衡量推理能力边界,我们将代码生成领域常用的 pass@k 指标(Chen 等人,2021)扩展到所有 “带可验证奖励的任务” 中。
针对某一问题,从模型中采样 k 个输出:若 k 个样本中至少有 1 个通过验证,则该问题的 pass@k 值为 1;否则为 0。在数据集上的平均 pass@k 值,可反映模型在 k 次尝试内有望解决的问题比例,为大语言模型的推理能力覆盖范围提供严谨评估。我们采用 “无偏、低方差估计器” 计算 pass@k,具体细节详见附录 A.2。
与 “最优 N 选 1(Best-of-N)” 和 “多数投票(Majority Voting)” 的对比
“最优 N 选 1”(Cobbe 等人,2021)和 “多数投票” 是选择正确答案的实用方法,但它们可能会忽略模型的完整推理潜力。与之不同,我们使用 pass@k 的目的并非评估 “实际实用性”,而是探究 “推理能力边界”:若模型在 k 次采样中能生成任意一个正确解,就认为该问题在其潜力范围内。因此,若强化学习真能提升推理能力,经 RL 训练的模型应能在 “更多此类问题” 上取得成功。而 “最优 N 选 1” 或 “多数投票” 若未通过验证器筛选或投票选中正确答案,就可能遗漏这些成功案例。
随机猜测问题(Random Guessing Issue)
在代码任务中,验证器为编译器和预设单元测试用例,此时 pass@k 值可准确反映模型是否能解决问题。但在数学任务中,随着 k 值增大,“猜测” 问题会愈发明显 —— 模型可能生成错误的思维链(CoT),却仍能偶然得到正确答案。
为解决这一问题,我们会手动检查部分模型输出的思维链正确性,具体细节详见 3.1 节。通过结合 “数学任务手动检查结果” 与 “代码任务结果”,我们能严谨评估大语言模型的推理能力范围。
另一个需要注意的点是:若 k 值极大(达到天文数字),即便对 token 词典进行均匀采样,也可能偶然得到正确推理路径 —— 但这在当前的时间与计算资源预算下完全不可行。关键发现是:基础模型在 “实际可行的 k 值(128 或 1024)” 下已能生成正确输出,而这类 k 值完全在实用资源范围内。
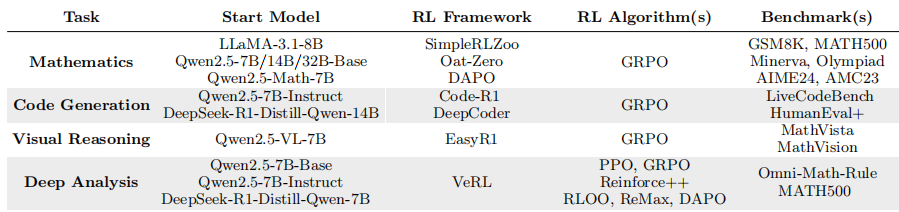
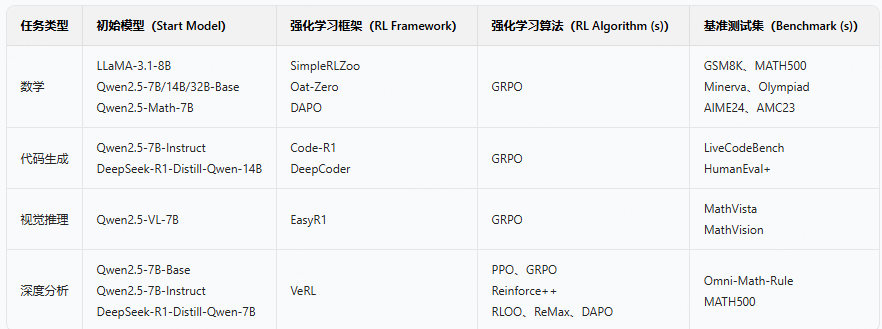
表 1:评估 RLVR 对大语言模型推理边界影响的实验设置
- RLVR 对推理能力边界的影响
==================
在确定推理边界的评估指标后,我们通过大量实验对基础模型与 RLVR 模型进行了全面评估。分析按任务类型划分,涵盖三个典型领域:数学、代码生成与视觉推理。整体实验设置汇总于表 1。
评估流程(Evaluation Protocol)
在对基础模型与 RLVR 模型进行采样时,我们将温度(temperature)设为 0.6,top-p 值设为 0.95,最大生成 token 数为 16384。不同温度设置的影响详见图 16。
评估基础模型时,常见做法是在提示词中加入 “少样本示例(few-shot examples)” 以引导输出(Grattafiori 等人,2024;Yang 等人,2024;Liu 等人,2024)。但为确保对比公平无偏,我们特意不为基础模型使用少样本提示词,以排除 “上下文示例可能对推理产生的干扰影响”。
评估基础模型与 RLVR 模型时,我们均使用 “与 RLVR 训练一致的零样本提示词” 或 “基准测试集提供的默认提示词”,确保两种模型的评估设置一致。有趣的是,尽管基础模型在 “无少样本引导” 时常生成格式混乱或无意义的响应,但我们观察到:只要采样次数足够,基础模型仍能生成格式正确的输出,并成功解决复杂问题。训练与评估所用的提示词模板详见附录 E。
3.1 RLVR 在数学推理中的作用
模型与基准测试集(Models and Benchmarks)
在数学问题中,模型需同时生成推理过程(即思维链 CoT)与最终答案。为确保结论的稳健性,我们采用多个系列的大语言模型开展实验,主要为 Qwen2.5(7B/14B/32B 基础版本)(Yang 等人,2024),此外还包括 LLaMA-3.1-8B(Grattafiori 等人,2024)。
我们采用 SimpleRLZoo(Zeng 等人,2025)发布的 RLVR 模型 —— 这类模型以零强化学习方式,在 GSM8K 和 MATH 训练集上通过 GRPO 算法训练,仅以 “答案正确性” 作为奖励,不包含任何 “格式奖励”。我们在不同难度的基准测试集上对比基础模型与零强化学习模型的 pass@k 曲线,包括 GSM8K(Cobbe 等人,2021)、MATH500(Hendrycks 等人,2021)、Minerva(Lewkowycz 等人,2022)、Olympiad(He 等人,2024)、AIME24 与 AMC23。
此外,我们还纳入了 RLVR 模型 Oat-Zero-7B 和 DAPO-32B(Liu 等人,2025b;Yu 等人,2025)—— 这两种模型在高难度的 AIME24 基准测试集上表现突出。
RLVR 的影响:正确样本概率提升,可解决问题覆盖范围缩小
如图 2 所示,我们在所有实验中均观察到 “k 值大小与模型性能” 的反向趋势:当 k 值较小时(如 k=1,相当于 “平均准确率”),经 RL 训练的模型性能优于基础模型 —— 这与 “强化学习提升性能” 的普遍认知一致,表明 RLVR 能显著提高模型采样到正确响应的概率;但随着 k 值增大,基础模型的性能曲线斜率更陡,在所有基准测试集上均会持续追赶并最终超越经 RL 训练的模型,这意味着基础模型可解决的问题覆盖范围更广。
例如,在 Minerva 基准测试集上,32B 规模的基础模型在 k=128 时,性能比经 RL 训练的同规模模型高出约 9%,这表明基础模型能解决验证集中约 9% 更多的问题。
我们进一步分析了经 Oat-Zero 和 DAPO 训练的 RL 模型。如图 10 所示,尽管 RL 模型初期表现强劲(性能比基础模型高近 30%),但最终仍会被基础模型超越。基于这些结果,我们得出结论:RLVR 能提高 “低 k 值下采样正确响应的概率”,但会缩小模型的整体推理覆盖范围。这一现象的根本原因将在 4.1 节中进一步分析。
思维链案例分析(CoT Case Analysis)
图 19 和图 20 展示了从基础模型中采样到的正确思维链 —— 这些样本均从 “AIME24 中最难问题的 2048 次采样” 中手动筛选得出。基础模型生成的响应往往是 “长思维链”,且表现出 “自我反思行为”,这凸显了基础模型本身就具备强大的推理能力。
思维链的有效性(Validity of Chain-of-Thought)
数学问题的常见评估方式仅关注 “最终答案正确性”,存在 “蒙对答案” 的风险。若要通过 pass@k 准确反映推理能力边界,需评估 “已解决的问题中,有多少是源于‘真正正确的思维链’,而非‘幸运猜测’”。
参考(Brown 等人,2024)的方法,我们手动检查了 “GSM8K 数据集中最难解决问题” 的所有正确思维链 —— 这些问题的平均准确率在 0% 至 5% 之间。结果显示:基础模型解决了 25 个此类问题,其中 24 个包含至少一条正确思维链;经 RL 训练的模型同样解决了 25 个此类问题,其中 23 个包含至少一条正确思维链。
我们还手动检查了 “AIME24 基准测试集中平均准确率低于 5% 的问题” 的思维链,具体细节详见附录 D.2:基础模型解决了 7 个此类问题,在可判断的 6 个问题中,有 5 个包含至少一条正确思维链(排除 1 个因 “跳过推理步骤” 导致正确性模糊的案例);经 RL 训练的模型解决了 6 个此类问题,其中 4 个包含至少一条正确思维链。这些结果表明,基础模型本身就能采样到解决问题的有效推理路径。
下面总结下要点:
这篇文档核心是探究一个关键问题:带可验证奖励的强化学习(RLVR),到底能不能让大语言模型(LLMs)学会比基础模型更厉害的推理能力? 结论挺出人意料的 —— 目前的 RLVR 还做不到,它只是让模型 “更会选答案”,没让模型 “学会新推理”。
先搞懂背景:什么是 RLVR?
之前大家觉得,RLVR 是让大模型变强的好办法 —— 比如让模型解数学题、写代码,对了给奖励,错了不给,像训练机器人玩游戏那样,让模型自己越练越厉害,甚至能学会基础模型不会的推理方法。但这篇研究就是要较真:这事儿真的成立吗?
研究怎么验证的?用了个关键指标 “pass@k”
平时评估模型,一般看 “一次就能做对”(pass@1),但这篇研究用了 “pass@k”—— 简单说就是 “让模型试 k 次,只要有一次做对就算成功”。这个指标的好处是能看出模型 “到底有没有潜力做对”,而不只是 “平均水平怎么样”。比如有的模型一次正确率不高,但多试几次能做对,说明它其实有解决能力;反之,要是试很多次都做不对,说明它是真不会。
最意外的发现:RLVR 模型 “小 k 厉害,大 k 拉胯”
研究用了好几种模型(比如 Qwen2.5、LLaMA-3.1)、好几个任务(数学题、写代码、看图推理),发现一个统一规律:
- 当 k 很小的时候(比如 k=1,就试 1 次),经过 RLVR 训练的模型确实比基础模型厉害 —— 这和之前大家看到的一致,RLVR 让模型 “更会选对的答案”;
- 但当 k 变大的时候(比如 k=128、256,多试几十上百次),反过来了!基础模型的正确率超过了 RLVR 模型。
这说明什么?RLVR 没让模型学会新推理,只是让模型更会从自己已有的能力里 “挑对的用” —— 比如基础模型其实能生成正确的推理路径,但平时藏在众多错误答案里;RLVR 只是把这些正确路径的优先级提高了,让模型一次就选到,但代价是 “把其他可能的推理路径给丢了”,导致多试几次时,反而不如基础模型能覆盖更多问题。
更深入的证明:RLVR 的推理路径,基础模型早就有
研究还做了两个关键分析,进一步实锤:
-
困惑度分析
:困惑度越低,说明模型越容易生成某个答案。结果发现,RLVR 模型生成的正确推理路径,在基础模型里的困惑度也很低 —— 也就是说,这些推理路径基础模型本来就能生成,RLVR 只是 “偏爱” 它们而已;
-
能解决的问题范围
:对比基础模型和 RLVR 模型能解决的问题,发现 RLVR 能解决的问题,基础模型基本都能解决(只是基础模型可能要多试几次);反而有些基础模型能解决的问题,RLVR 模型却解决不了 ——RLVR 缩小了模型的 “推理范围”。
对比蒸馏:真正能让模型 “学新东西” 的是它
研究还拿 RLVR 和 “蒸馏”(把厉害老师模型的能力传给普通学生模型)做了对比,发现两者完全不一样:
- 蒸馏后的模型,不管 k 是大是小,正确率都比基础模型高 —— 说明蒸馏真的让模型学会了老师的新推理方法,扩展了推理能力;
- 而 RLVR 模型始终跳不出基础模型的 “能力圈”,只是优化了 “选答案的效率”。
为什么 RLVR 做不到?可能有两个原因
-
大模型的 “动作空间” 太大了
:机器人玩游戏,动作就那么几种(比如上下左右),但语言模型生成文本的可能太多了,RLVR 很难探索到 “基础模型没见过的新推理路径”;
-
基础模型的 “先验知识” 是把双刃剑
:RLVR 是在基础模型上训练的,基础模型会引导它生成 “自己熟悉的内容”—— 要是偏离基础模型的知识,生成的内容大概率是错的(拿不到奖励),所以模型不敢 “尝试新推理”,只能在基础模型的框架里优化。
总结一下
目前的 RLVR,更像给模型装了个 “精准筛选器”—— 让它在已有能力里更快找到对的答案,但没给模型装 “新的推理发动机”。要是想让模型真的学会更厉害的推理,还得搞新的强化学习方法,比如让模型能和环境多轮互动、能更自由地探索新推理路径。
D. 详细实验结果
D.1 数学与代码生成任务的更多结果
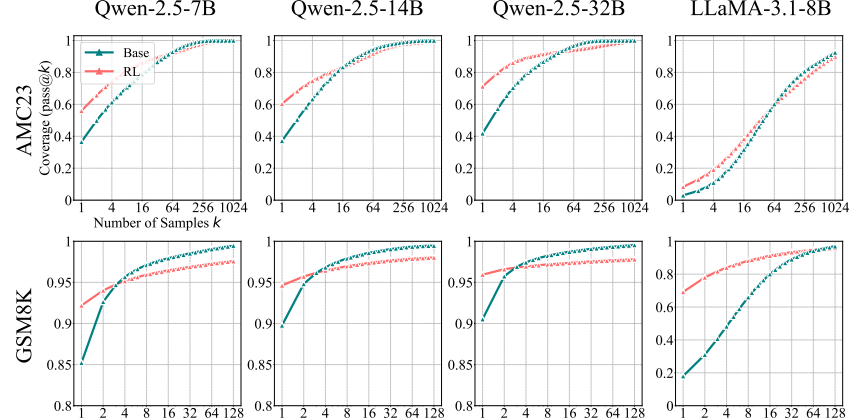
图 9:SimpleRLZoo 在 GSM8K 与 AMC23 基准测试集上的更多结果
(图表结构说明:该图包含 6 个子图,分别对应 4 种模型(Qwen-2.5-7B、Qwen-2.5-14B、Qwen-2.5-32B、LLaMA-3.1-8B)在 2 个数学基准测试集(GSM8K、AMC23)上的 pass@k 曲线。横轴为采样次数 k(取值为 1、4、16、64、256、1024 或 1、2、4、8、16、32、64、128),纵轴为覆盖率(Coverage,即 pass@k 值,范围 0-1 或 0.8-1);曲线 “Base” 代表基础模型,“RL” 代表经 RLVR 训练的模型。)
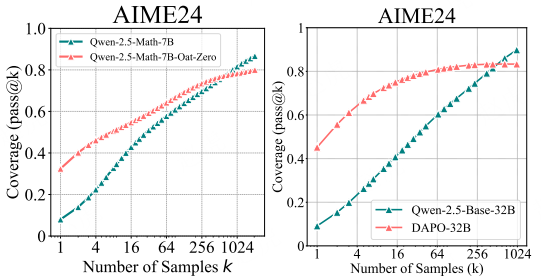
图 10:Oat-Zero-7B 与 DAPO-32B 在 AIME24 基准测试集上的评估结果(与各自基础模型对比)
(图表结构说明:该图包含 2 个子图,左侧子图展示 Qwen-2.5-Math-7B(基础模型)与 Qwen-2.5-Math-7B-Oat-Zero(经 Oat-Zero 训练的 RL 模型)在 AIME24 上的 pass@k 曲线;右侧子图展示 Qwen-2.5-Base-32B(基础模型)与 DAPO-32B(经 DAPO 训练的 RL 模型)在 AIME24 上的 pass@k 曲线。横轴为采样次数 k(取值为 1、4、16、64、256、1024),纵轴为覆盖率(Coverage,即 pass@k 值,范围 0-1 或 0-1.0)。)
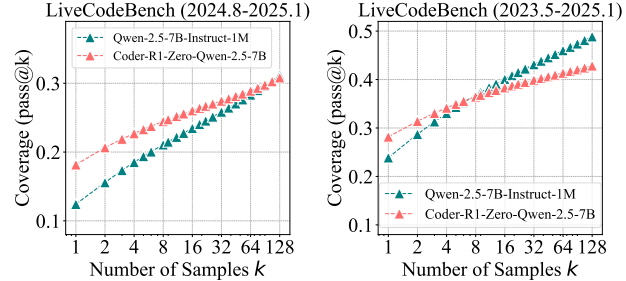
图 11:Coder-R1 在 LiveCodeBench 基准测试集上的结果
(图表结构说明:该图包含 2 个子图,均展示 Qwen-2.5-7B-Instruct-1M(基础模型)与 Coder-R1-Zero-Qwen-2.5-1M(经 Coder-R1 训练的 RL 模型)在 LiveCodeBench 上的 pass@k 曲线;左侧子图对应 2024 年 8 月 - 2025 年 1 月的 LiveCodeBench 数据集,右侧子图对应 2023 年 5 月 - 2025 年 1 月的 LiveCodeBench 数据集。横轴为采样次数 k(取值为 1、2、4、8、16、32、64、128),纵轴为覆盖率(Coverage,即 pass@k 值,范围 0.1-0.3 或 0.1-0.5)。)
D.2 AIME24 基准测试集中思维链(Chain-of-Thought)的有效性验证
我们手动检查了高难度 AIME24 基准测试集中所有(模型生成的)思维链(CoT)。首先,我们引入了一套过滤机制,用于排除 “易被猜测答案” 的问题。具体而言,我们向 Qwen2.5-7B 基础模型(Qwen2.5-7B-Base)输入提示,要求其不使用思维链推理、直接回答问题,并对答案进行多次采样。若某一问题被正确回答的概率较低但非零(例如,低于 5%),我们则认为该问题的答案可通过猜测获得,并将其从评估集中移除;若某一问题能以较高概率被直接正确回答,我们则保留该问题 —— 这类问题通常难度较低,且可通过有效的思维链推理解决。
(注:1. “Chain-of-Thought” 为 AI 领域固定术语,译为 “思维链”,简称 “CoT”,指模型通过逐步推理生成答案的过程;2. “AIME24” 为数学竞赛类基准测试集名称,全称为 “American Invitational Mathematics Examination 2024”,此处保留原名以符合学术文本规范;3. “Qwen2.5-7B-Base” 为模型名称,保留原名并补充 “基础模型” 字样,明确其 “未经过 RLVR 训练” 的属性;4. “guessable” 译为 “可通过猜测获得(答案)的”,精准体现 “无需推理、仅凭概率猜测即可答对” 的核心含义,区别于 “可推理解决的(solvable via reasoning)”。)
经筛选的 AIME24 基准测试集上基础模型与强化学习(RL)模型的 pass@k 曲线
经筛选的 AIME24 基准测试集上,基础模型与强化学习(RL)模型的 pass@k 曲线可参见图 12,其趋势与此前结果一致。尽管该筛选方法属于启发式方法,但事实证明它是有效的:将其应用于包含 30 道题的 AIME24 基准测试集后,得到了一个包含 18 道题的子集。随后,我们向模型输入提示,要求其使用思维链(CoT)推理来回答这些筛选后的问题。接着,我们手动检查了 “最难问题(平均准确率低于 5%)” 的所有思维链 —— 这些思维链均导向了正确答案。结果显示:基础模型答对了 7 道此类难题,在可明确判断的 6 道题中(排除 1 道因推理步骤缺失导致正确性存疑的题目),有 5 道题的思维链中至少包含 1 条正确推理路径;与之类似,经强化学习训练的模型答对了 6 道此类难题,其中 4 道题的思维链中至少包含 1 条正确推理路径。这些结果表明,即便是在高难度的 AIME24 基准测试集的最难题目中,基础模型也能采样到解决问题的有效推理路径。
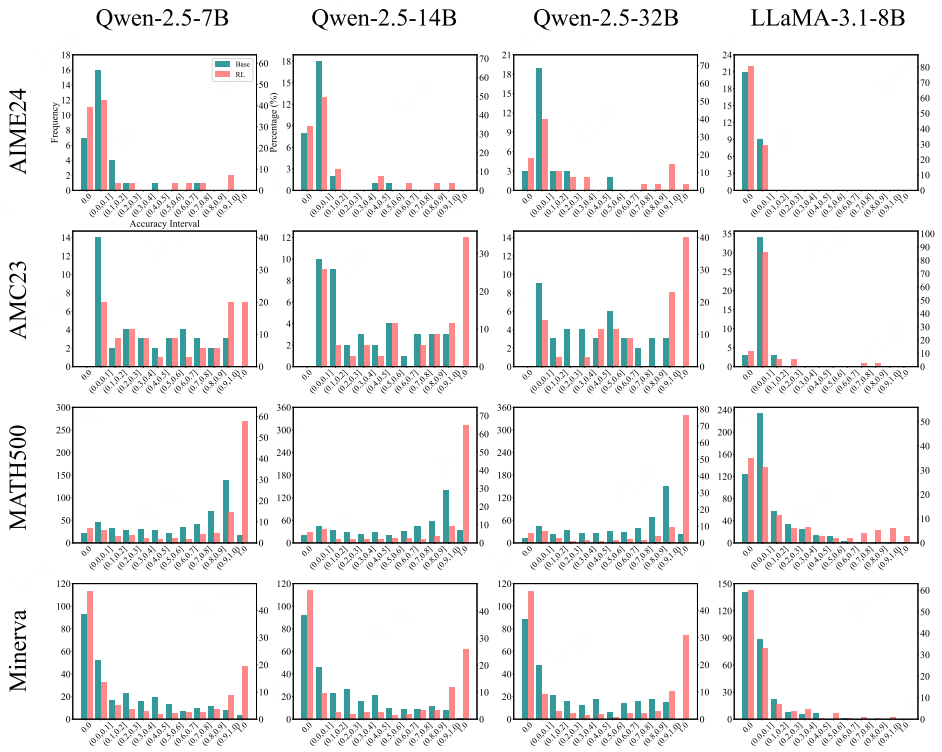
D.3 准确率分布可视化
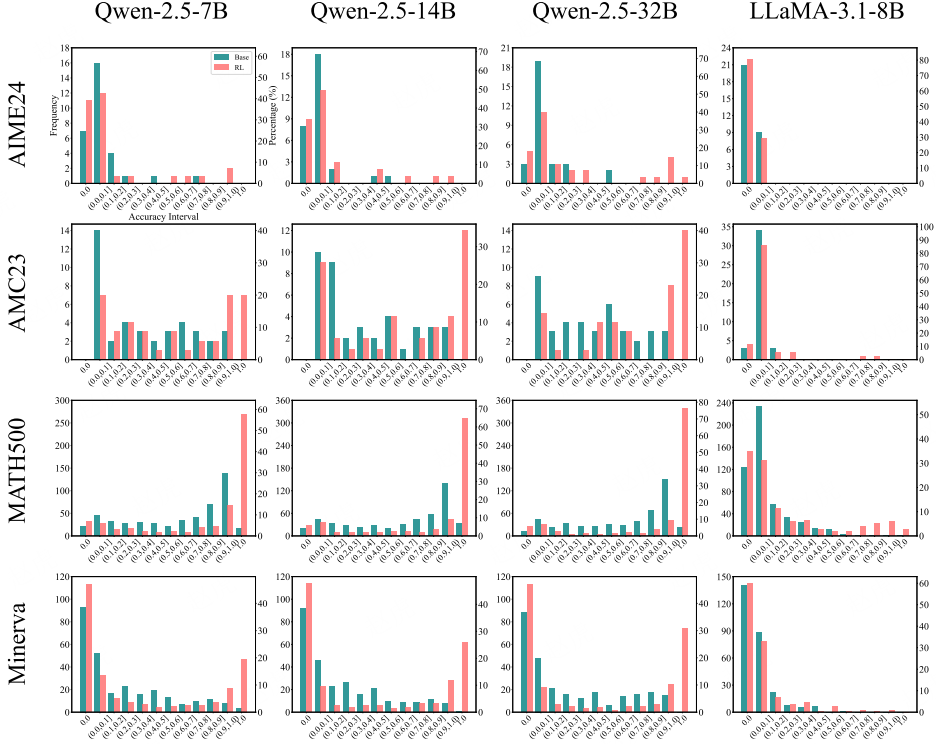
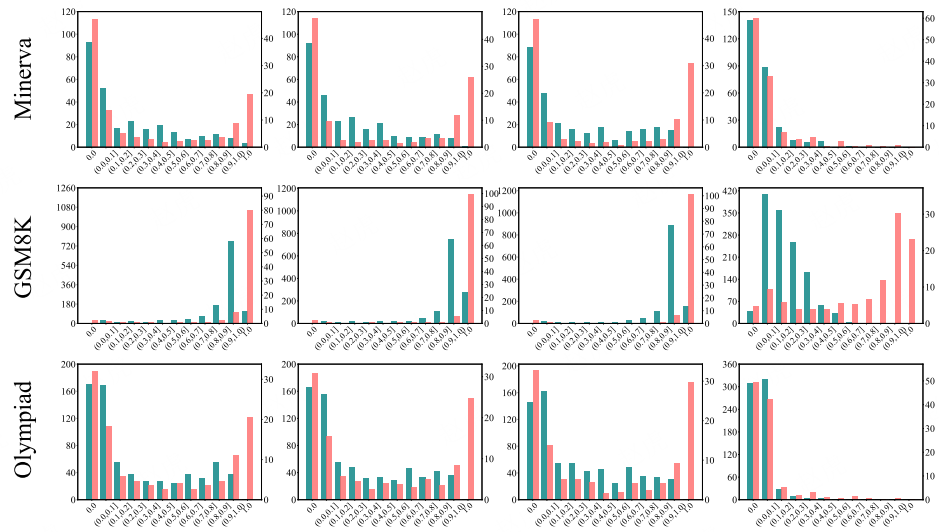
图 13:使用 SimpleRLZoo 模型进行 RLVR 训练前后的准确率直方图
D.4 不同的 RLVR 算法
我们在图 8 中报告了关于不同 RLVR 算法的额外观察结果,具体如下:
-
DAPO 算法
:在所有三个数据集上,DAPO 的 pass@1 得分均略高;但相比其他算法,其动态采样策略在训练期间每批次需要约 3~6 倍更多的样本,且在 k=256 时性能显著下降。
-
RLOO 与 Reinforce++ 算法
:在整个 k 值范围(1 至 256)内,这两种算法的性能始终表现良好,同时保持了高效的训练成本,在效果与效率之间实现了良好平衡。
-
ReMax 算法
:该算法在 pass@1 和 pass@256 上的性能均较低。我们推测,这是因为它将 “贪心响应奖励” 用作优势基线(advantage baseline)—— 而在 RLVR 场景中,该奖励为二元值(0 或 1)且波动性极大,这可能导致训练过程中梯度更新不稳定。
(注:1. 算法名称(DAPO、RLOO、Reinforce++、ReMax)均保留原名,为强化学习领域专用算法标识;2. “pass@1”“pass@256” 为评估指标,指 “采样 1 次 / 256 次时至少有 1 次正确的概率”,保留原名并补充中文释义;3. “dynamic sampling strategy” 译为 “动态采样策略”,“advantage baseline” 译为 “优势基线”,均为强化学习领域标准术语;4. “binary (0 or 1)” 译为 “二元值(0 或 1)”,明确奖励仅存在 “正确(1)” 与 “错误(0)” 两种状态;5. “gradient updates” 译为 “梯度更新”,为深度学习训练核心过程的标准表述。)
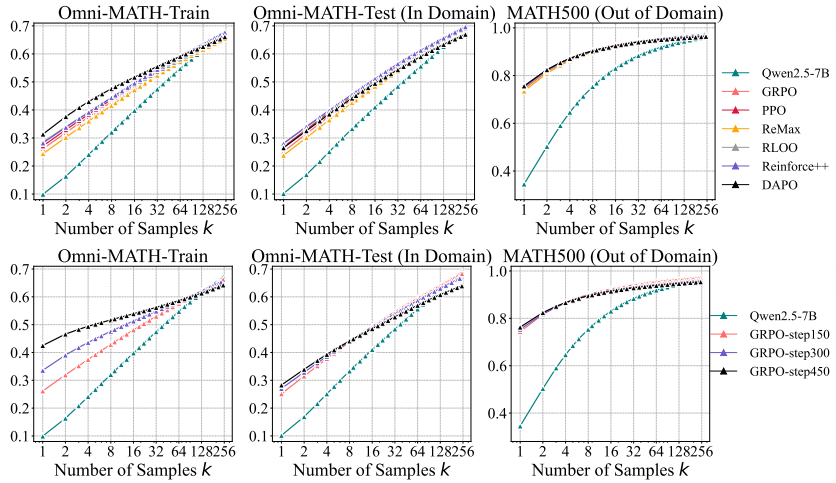
图 14:图 8 的 y 轴展开版本
表 2:图 8 中不同强化学习(RL)算法在 pass@1 和 pass@256 指标上各数据点的详细数值
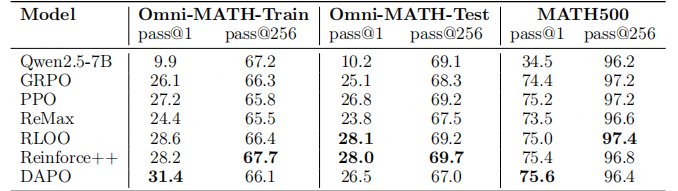
表 3:图 1(右)中不同强化学习(RL)训练步数下,pass@1 和 pass@256 指标的详细数值

D.5 KL 散度与滚动步数的影响
(说明:1. “KL” 全称为 “Kullback-Leibler Divergence”,是机器学习中衡量两个概率分布差异的核心指标,标准译为 “KL 散度”,保留缩写 “KL” 符合学术文本习惯;2. “Rollout Number” 为强化学习领域专用术语,指 “智能体在一次策略评估中生成的轨迹样本数量”,译为 “滚动步数”,准确体现 “多步采样生成轨迹” 的核心含义)
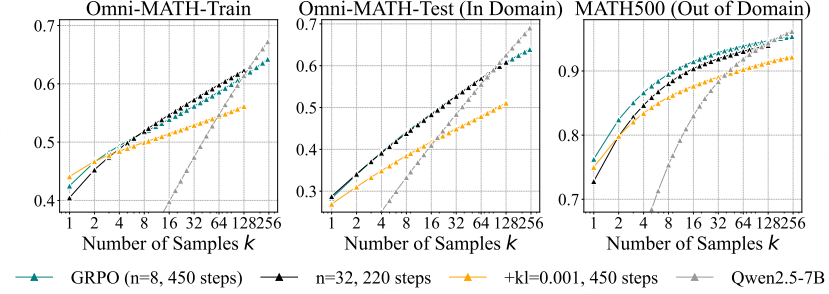
图 15:KL 损失与滚动步数 n 的消融实验
当将 n(滚动步数)从 8 增加到 32 时,我们保持提示词批次大小不变,这导致每个训练步骤的计算量增加。由于资源限制,在此设置下我们仅训练了 220 步 —— 模型尚未收敛,因此 pass@1 指标得分较低。尽管如此,n=32 的模型仍实现了更高的 pass@128 得分,这凸显了 “更大的滚动步数” 在 “提升高 k 值下 pass@k 指标” 方面的积极作用。(说明:1. “Ablation Study” 为机器学习领域固定术语,译为 “消融实验”,指通过移除或调整模型 / 算法的某一组件,验证该组件对性能的影响;2. “KL Loss” 译为 “KL 损失”,“KL” 为 “Kullback-Leibler Divergence”(KL 散度)的缩写,“KL 损失” 用于衡量模型训练前后策略分布的差异,避免策略偏移过大;3. “Rollout Number” 译为 “滚动步数”,指强化学习中模型单次生成的轨迹样本数量;4. “prompt batch size” 译为 “提示词批次大小”,“training step” 译为 “训练步骤”,均为模型训练的基础术语;5. “converged” 译为 “收敛”,指模型训练过程中损失稳定、性能不再显著变化的状态;6. “pass@1”“pass@128” 为评估指标,保留原名,分别指 “采样 1 次 / 128 次时至少 1 次正确的概率”。)
D.6 可解决问题覆盖范围分析
(说明:“Solvable Problem Coverage Analysis” 译为 “可解决问题覆盖范围分析”,“覆盖范围” 指模型能够成功解决的问题在整个数据集所占的比例,该分析用于验证模型推理能力的适用边界。)
表 4:AIME24 基准测试集中可解决问题的编号(编号从 0 开始)

可观察到近似的子集关系:强化学习(RL)模型能解决的大部分问题,基础模型也能解决。(说明:1. “Indices of solvable problems” 译为 “可解决问题的编号”,“indices” 此处指问题在数据集中的序号;2. “AIME24” 为数学竞赛类基准测试集(American Invitational Mathematics Examination 2024),保留原名以确保辨识度;3. “subset relationship” 译为 “子集关系”,指 RL 模型可解决的问题集合,大致是基础模型可解决问题集合的子集;4. “RL model” 译为 “强化学习(RL)模型”,“base model” 译为 “基础模型”,明确两类模型的定义差异 —— 前者经 RLVR 训练,后者为未训练的原始模型。)
D.7 温度(Temperature)与熵(Entropy)分析
(图表说明:该图包含 6 个子图,分别对应 2 个基准测试集(AIME24、MATH500)在 3 种温度设置(T=0.6、T=1.0、T=1.2)下的 pass@k 曲线。横轴为采样次数 k(取值为 1、4、16、64、256、1024 或 1、2、4、8、16、32、64、128),纵轴为覆盖率(Coverage,即 pass@k 值,范围 0-0.8 或 0.2-1);曲线 “Base” 代表基础模型,“RL” 代表经 RLVR 训练的模型。)
图 16:温度对模型性能的影响
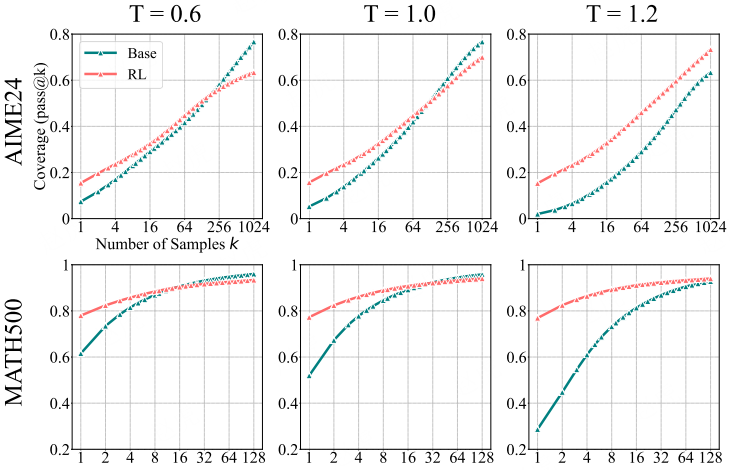
我们发现,当温度(Temperature)超过 1.0 时,基础模型的性能会下降 —— 因为此时模型倾向于生成更多随机且连贯性较差的词元(token)。与之相反,在不同温度设置下,强化学习(RL)模型的性能始终保持相对稳定。因此,我们在主要实验中采用 T=0.6 的温度设置,这一参数能让两种模型(基础模型与 RL 模型)均展现出最佳的推理性能。(说明:1. “Temperature” 为大语言模型采样核心参数,固定译为 “温度”,其值越高代表模型生成内容的随机性越强,值越低则输出越确定;2. “token” 为 NLP 领域基础术语,译为 “词元”,指模型处理文本时拆分的最小语义单位;3. “RL model” 结合上下文译为 “强化学习(RL)模型”,补充缩写全称便于理解,同时保留 “RL” 符合学术文本表述习惯;4. “T = 0.6” 中 “T” 为 “Temperature” 的缩写,保留原符号并补充中文释义,确保参数指代清晰。)
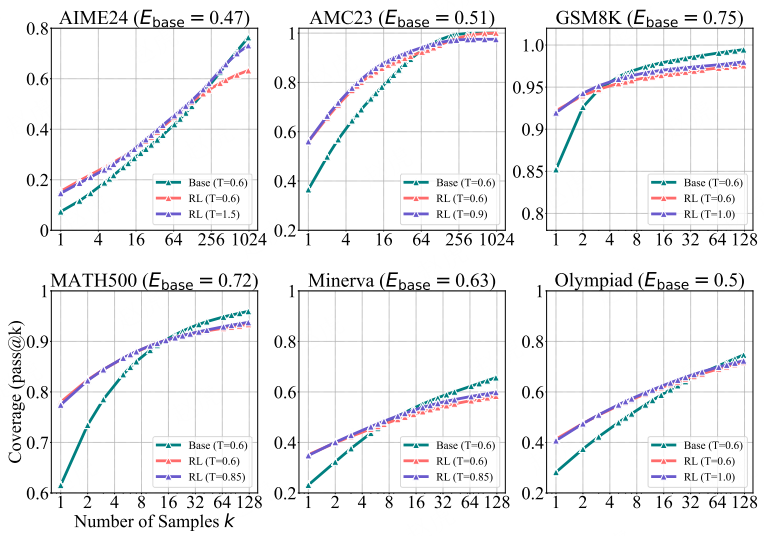
图 17:输出熵匹配条件下基础模型与 RLVR 模型的对比
我们在每个数据集上以温度 T=0.6 评估基础模型(Qwen2.5-7B),并在每个子图的标题中标注其输出熵 Ebase(基础模型输出熵)。为实现公平对比,我们逐步提高 RLVR 模型(SimpleRLZoo)的温度,直至其输出熵与 Ebase 大致匹配。例如,在 AMC23 数据集上,我们将温度设为 T=0.9,使 RL 模型的输出熵 ERL(强化学习模型输出熵)达到 0.47。此外,我们还纳入了 RLVR 模型在 T=0.6 时的结果作为额外基准 —— 该温度下模型的输出熵更低,例如在 AMC23 数据集上为 0.22,在 MATH500 数据集上为 0.33。
D.8 训练动态
(说明:1. “Training Dynamics” 译为 “训练动态”,指模型在训练过程中关键指标(如奖励、损失、性能)随训练步数变化的过程与趋势,是分析模型训练稳定性与收敛性的核心维度;

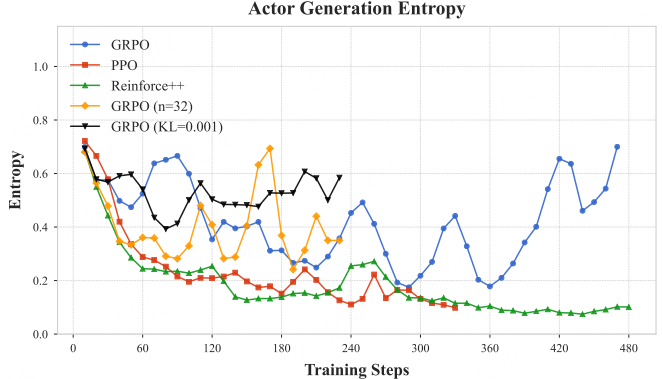
图 18:训练过程中训练奖励、响应长度与生成熵的变化曲线
D.9 思维链(CoT)案例分析




E. 提示词模板
我们提供了实验中用于训练和评估的提示词模板。SimpleRL 训练与评估所用的提示词如图 21 所示,Oat-Zero 训练与评估所用的提示词如图 22 所示。Code-R1 训练采用图 23 中的提示词;Code-R1 评估则遵循原始代码库,采用基准测试集提供的默认模板,包括 LiveCodeBench 提示词(图 24)、HumanEval + 提示词以及 MBPP + 提示词(图 25)。EasyR1 训练与评估所用的提示词如图 26 所示。对于经 VeRL 训练的强化学习(RL)模型,如第 4.3 节和第 4.4 节所述,其训练与评估提示词如图 27 所示。为确保对比公平,基础模型在评估阶段使用的提示词,与其对应的经强化学习训练的模型完全一致。(说明:1. “Prompt Templates” 译为 “提示词模板”,“Prompt” 为大语言模型交互中的核心输入文本,译为 “提示词” 符合中文 AI 领域表述习惯;2. “SimpleRL”“Oat-Zero”“Code-R1”“EasyR1”“VeRL” 均为模型训练框架或算法名称,保留原名以确保辨识度;3. “LiveCodeBench”“HumanEval+”“MBPP+” 为代码生成领域基准测试集名称,保留原名符合学术文本规范;4. “base models” 译为 “基础模型”,“RL-trained counterparts” 译为 “经强化学习训练的模型”,明确两类模型的定义差异,避免歧义;5. 保留 “Figure 21-27” 的图表编号格式,与原文引用逻辑一致。)



AI大模型学习路线
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 2
2 0
0- 0



 已为社区贡献238条内容
已为社区贡献238条内容

所有评论(0)