EXPERT: An Explainable Image Captioning Evaluation Metric with Structured Explanations(ACL 2025)
本文提出EXPERT,一种基于视觉语言模型的无参考图像字幕评估指标。通过构建包含42,000+结构化解释的数据集(Polaris-exp和Nebula-exp),从流畅性、相关性和描述性三个维度规范解释生成。设计两阶段评估模板:先评分后解释,并采用LLaVA-1.5模型进行监督训练。方法解决了现有指标解释不一致和质量未验证的问题,通过人工评估验证了解释质量,最终实现兼具数字评分和结构化文本解释的可
研究方向:Image Captioning
1.论文介绍
本文提出了EXPERT,一种基于视觉语言模型(VLM)的无参考评估指标,用于图像字幕的可解释性评估。
1)构建了包含超过42,000个结构化解释的大规模数据集。每个解释根据三个基本标准进行结构化:流畅性、相关性和描述性。
2)设计了一个两阶段评估模板,以有效监督通用VLM,并结合人类偏好和高质量的结构化解释。第一阶段为评分阶段,查询模型并分配分数;第二阶段为解释阶段,查询模型并提供基于流畅性、相关性和描述性的简要解释。

可解释指标提供数字评分和文本解释,增强了评估的可解释性和透明度。
可解释指标的研究存在两个局限性:
首先,现有指标提供的解释并非基于标准化标准或指南生成,可能导致内容和结构的不一致。
其次,以往研究缺乏对生成解释质量的彻底评估,使得整体质量未经证实。
2.方法介绍

2.1 数据集构建
1)生成解释
通过扩展Polaris数据集和Nebula数据集,分别构建了Polaris-exp和Nebula-exp数据集。为每个图像-字幕对添加一个“解释”。每个解释根据三个维度进行结构化:
(1)流畅性评估字幕是否流畅、自然且语法正确;
(2)相关性评估句子是否正确地描述了视觉内容,并且与图像密切相关;
(3)描述性评估句子是否是精确、提供信息的字幕,描述了图像的重要细节。
这些维度是最近人类判断数据集开发中用于人类注释的通用标准。我们通过提示GPT-4o来生成解释,并附上相应的图像。因此,Polaris-exp 和 Nebula-exp 分别包含了 16,014 个和 26,152 个针对独特图像-标题对的解释。
2)为评估生成解释的质量,对来自 Polaris-exp 和 Nebula-exp 组合集的 100 个抽样实例进行了人工评估。从三个评分区间均匀抽样——[0, 0.33)、[0.33, 0.66) 和 [0.66, 1]——每个区间内随机选择。招募四位以英语为母语的评价员来评估解释的质量,基于三个标准:
(1)一致性衡量解释与给定评分的逻辑一致性;
(2)事实性衡量解释在描述给定的图像-标题对时的事实准确性;
(3)信息性衡量解释提供的相关细节和有意义信息量,以支持和证明给定的评分。
2.2 两阶段评估模板
设计了一个两阶段评估模板,遵循评分-解释顺序,以有效监督具有人类偏好和高质量结构化解释的通用视觉语言模型(VLM)。
第一个评分阶段用于给定的图像-标题对分配分数,即来自构建数据集的人类评分。将区间0.0-1.0的分数分为10份。
第二个解释阶段基于三个标准(流畅性、相关性和描述性)供分数的简要解释,以及每个标准的描述和预定义的输出格式。
2.3 训练
使用LLaVA-1.5(13B)作为基础模型,用带解释的数据集对 VLM 做监督训练。包含具有不同注释者评分的重复图像-标题对,通过平均人类评分将这些组合成单个实例。此外,共享重叠的图像-标题对,通过平均人类评分将这些跨数据集的重复项合并成单个实例。
训练目标
-
输入:图像 + Caption
-
输出:符合 Two-stage Template 的结果
-
分数(0.0–1.0)(按 bin size=0.10 离散化)
-
三维度解释(简短句子)
-
2.4 推理
给定一个图像-标题对,依次用两阶段评估模板的查询提示训练好的模型。使用贪婪解码来确保结果确定且可复现,并在评分阶段应用分数平滑以获得更详细的分数。分数平滑涉及计算每个数字i(0≤i≤9)在第j个小数位(j=1,2)生成的概率p(i,j),然后使用它来产生最终分数s。
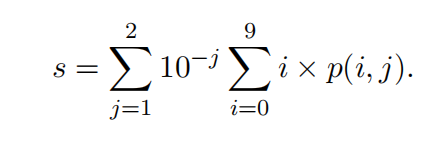

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)