主宰 TCP AIMD 的中心极限定理
我们的社会,城市,甚至自然界生态系统均是与 TCP/IP 互联网一样的随机的复杂自适应系统,这类系统的特点是去中心化,资源共享,分布式哑控制,没有任何措施规范个体的行为,全凭个体自主探测和适应,尽力而为,我们惊奇地发现,这类系统几乎运行得都非常和谐良好,其中的动力学正如 AIMD。,他用排队论首先证明了统计复用是可行的,奠定了互联网的统计学理论基础,在他之前,虽然人们设想了很多不同拓扑的组网方式,
能几句话说清楚的,绝不长篇大论万字长文故作高深。
继续 无懈可击的 TCP AIMD,本文说点根本的。
保持 VJ 管道最高效的方法是提供 BDP 大小的 buffer,此时执行完 MD 后,inflight 刚好填满 BDP。由此推之,考虑 n 条异步流共存时该如何,以证明 AIMD 是 TCP/IP 拥塞控制最优解。
大道至简,最深刻的道理往往只需要最苍白的语言,论证 AIMD 是互联网最优解只需最简单的中心极限定理。
TCP/IP 网络流对网络的统计复用过程本质上就是 “大量随机变量采样求和” 的过程,等价于下面的问题:
- n 个取值区间 [ BDP n , 2 ⋅ BDP n ] [\dfrac{\text{BDP}}{n},\dfrac{2\cdot\text{BDP}}{n}] [nBDP,n2⋅BDP] 的均匀分布随机变量,BDP 为常数,对其求和 S,求 S 的均值和标准差。
这题很容易,由中心极限定理,当 n 较大时, S ∼ N ( 3 ⋅ BDP 2 , BDP 2 12 n ) S\sim N(\dfrac{3\cdot\text{BDP}}{2}, \dfrac{\text{BDP}^2}{12n}) S∼N(23⋅BDP,12nBDP2),即均值为 3 ⋅ BDP 2 \dfrac{3\cdot\text{BDP}}{2} 23⋅BDP,标准差为 BDP 2 ⋅ 3 n \dfrac{\text{BDP}}{2\cdot\sqrt{3}\sqrt{n}} 2⋅3nBDP 的正态分布。
既然 inflight 之和可列为正态分布,那么所需 buffer 就可由该正态分布直接度量,buffer 最大值由 inflight 之和最大值规定,buffer 最小值由 inflight 之和恰好填满 BDP 规定。
于是,可将 buffer 用途分为两部分,μ - r·δ 部分不至于低于 BDP 造成链路欠载,保持带宽利用率,μ + r·δ 部分避免大量丢包,由于 3 倍标准差可覆盖 99.73% 情况,故 r 取 3,如下图:
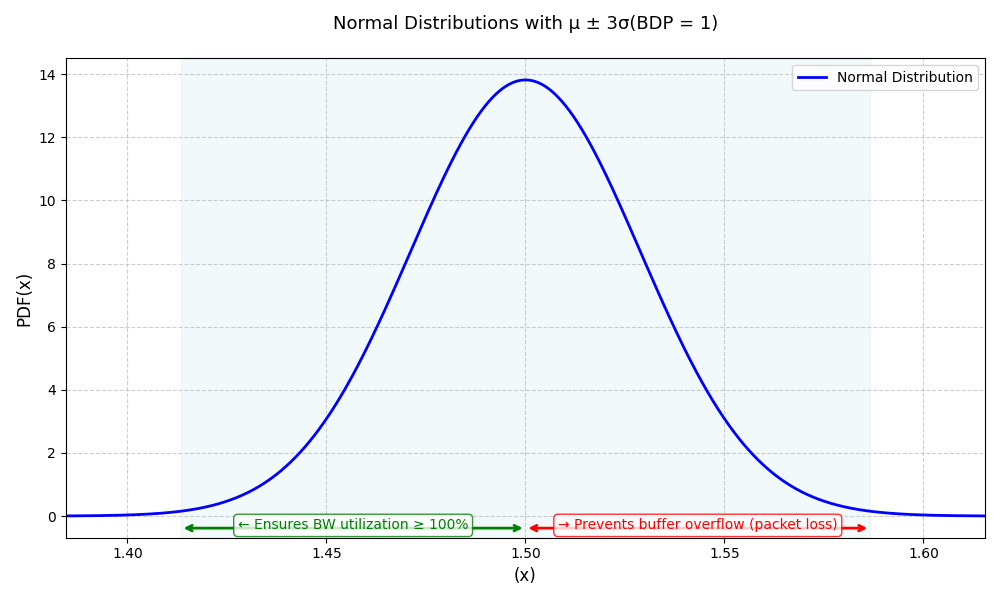
中心极限定理说明的是,当大量独立随机变量叠加时,复杂性会自我简化,最终呈现出优雅的正态分布,而不论多么复杂的事,简化后的正态分布统统是易于计算的。
给出不同的 n,可观测到中心极限定理的自然结论,随着 n 的增大,标准差以 n \sqrt{n} n 的比例缩减,所需 buffer 减少,如下图: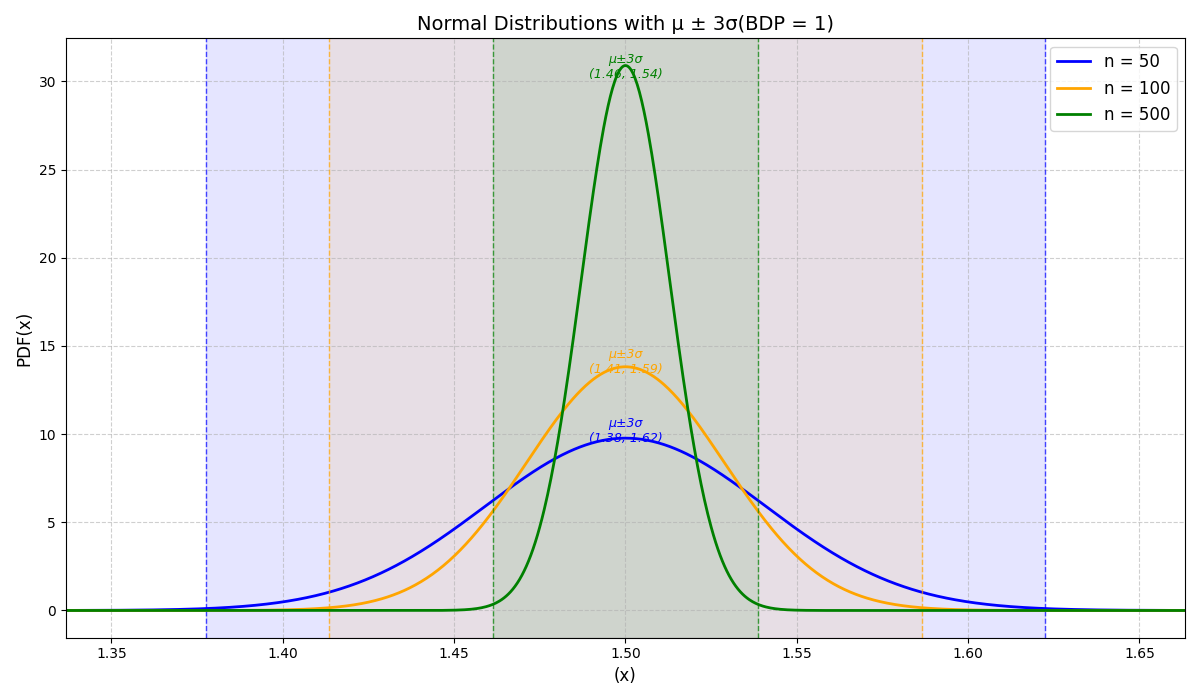
这意味着可以在不影响总带宽利用率的前提下,将 3 ⋅ BDP 2 \dfrac{3\cdot\text{BDP}}{2} 23⋅BDP 均值向左平移,即所有流放弃一部分理想 VJ 管道的 inflight。下图展示平移后结果,三个颜色范围标识 n = 50,100,500 时 buffer 需求,与上图相比,看横坐标,buffer 需求量大大减少(即使 n = 50 时也是):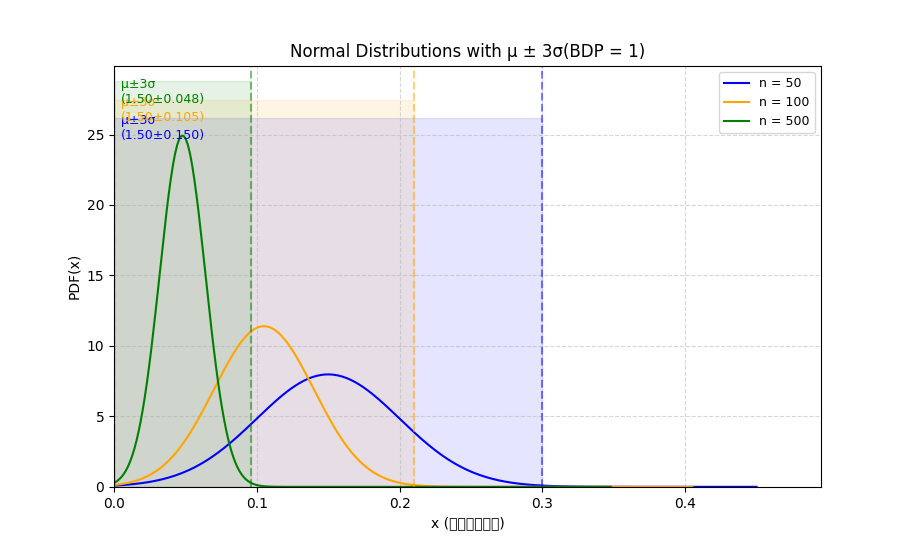
至于公平性推演,之前已说过太多,AI(Additive Increase) 行为逐步弥补初始差异,MD 行为属于相似缩放到原始规模,这是公平收敛的根本,就像和面一样,面多了加水,水多了加面,拧下一块继续和,如此反复。
以上推论了以下事实表示 AIMD 的收益:
- 异步流越多,n 越大,所需 buffer 越少,时延越低;
- 异步流越多,n 越大,带宽利用率越不易欠载过低;
- AIMD 天然公平性不随 n 增加而被弱化;
- 理想情况下,n 无穷大,buffer 需求为 0,所有流均分利用 100% 带宽;
在成本上,AIMD 仅依赖丢包,这证明了 AIMD 是 TCP/IP 拥塞控制最优解,而 BBR 做不到 1,3,4。
结论是神奇的,AIMD 的整体行为只与 BDP 强相关,与 MD 线性相关,自然收敛到无 buffer 最高效状态。这是冥冥中的吗?就好像一个统计复用系统无需任何外力就自然撑满,不多也不少,这就是世界的本质吧,做小作用量,做得越多,无用功越多,效能越低。so,大道至简,顺其自然。
下面是形而上时间。
虽然网络效率需从全局考虑,而非个体,但这原则别指望在一个随机的复杂自适应系统被遵守,只需博弈论。随着 n 增加,个体作恶对整体影响微乎其微,自己边际收益微不足道,只要有权衡能力,这就是被动均衡点。
把网络想象成盲盒,宁可盲猜不要启发,如此收益最大,就像猜硬币正反面,没有任何信息,随机 50% 盲选就是最优,涉及到算法的具体,丢包判定要适可而止,不要进一步区分于乱序,否则虽有收益,但代价更大,性价比肯定降低,这是信息论决定的,不是我说的。
我们的社会,城市,甚至自然界生态系统均是与 TCP/IP 互联网一样的随机的复杂自适应系统,这类系统的特点是去中心化,资源共享,分布式哑控制,没有任何措施规范个体的行为,全凭个体自主探测和适应,尽力而为,我们惊奇地发现,这类系统几乎运行得都非常和谐良好,其中的动力学正如 AIMD。
不妨稍微展开。
连续 3 天晚上 7 点遭遇拥堵,你会在第 4 天避开那个时间到达拥堵地,当觉得开车成本太高,你会选择公共交通,当足够多的人都受够了,道路会畅通,如此反复,这一切都是自适应的,但凡引入任何措施,个人便会对措施做反应,这反而破坏了自适应,比如限号会导致多买一辆车,限外牌会拉高本地车牌价格。规范化措施的引入让系统变得不再最优,这些措施的收益仅是个别个体的效率,比如拥有本地车牌的人,但对全局的综合效率肯定拉低,因为人们的反应成本太高,况且措施还有执行成本。
这解释了我一贯的观点,绝对的高效率一定要专用系统,随机的复杂自适应系统兼顾效率和公平的最优解一定是哑控制。
“你永远不能仅凭 BBR 的吞吐更高就说 BBR 比 CUBIC 更好”,给出一系列 iperf 测试结论的文章甚至顶会论文看腻了,TCP/IP 广域网不需要任何优化。
互联网的统计学建模来自 Leonard Kleinrock,他用排队论首先证明了统计复用是可行的,奠定了互联网的统计学理论基础,在他之前,虽然人们设想了很多不同拓扑的组网方式,但大家始终无法摆脱可用性的魔鬼,人们怀疑,如此不受任何约束的,混乱的所谓分组交换网,真的行得通?真的不会毫无征兆地崩溃?
浙江温州皮鞋湿,下雨进水不会胖。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)