Dify插件开发:基于火山引擎大模型上下文缓存方案的集成与优化
文章摘要:针对电话外呼场景中离线质检存在的重复推理、token消耗大等问题,提出采用火山引擎的上下文缓存策略优化流程。通过规则整合、批量处理和智能缓存机制,可减少同一对话文本的重复处理。测试数据显示,在催收场景中应用自适应缓存方案后,能有效节省70%的token消耗,显著降低质检成本。该方案支持多种缓存模式,包括Session缓存和前缀缓存,适用于不同长度的提示词和文本场景,为大规模通话质检提供了
背景:在催收、电销、客服等电话外呼场景中,离线质检是确保服务质量、合规性和业务效果的关键,但因质检规则繁多复杂,现有流程逐条分析对话文本,导致重复推理、token消耗大、效率低。亟需优化流程,减少重复推理,降低成本,提升质检效率。
推理定价(Doubao-1.5-pro-32k):
输入:8 元/千万 tokens
输出:20 元/千万tokens
缓存定价(Doubao-1.5-pro-32k):
存储 0.17 元/千万 tokens/小时
命中 1.6 元/千万 tokens
预计效果:使用缓存后可规避一通对话反复咀嚼的情况,按照当前的质检规则,预计可节省50%-80%的 token费用消耗。(按照当前20个模型,存储6小时内命中计算
1 - (0.17*6 + 1.6*20) / (8*20) = 80.40 %
一、背景
在当前的催收、电销、客服等电话外呼场景中,离线质检是确保服务质量、合规性以及业务效果的重要环节。质检过程通常需要对大量的对话文本进行分析,以检查是否符合预设的业务规则、合规要求或服务标准。
然而,由于质检规则数量庞大且复杂,涉及多方面的检查点(如语气、措辞、合规性、关键词使用等),现有的质检流程通常采用逐条规则对对话文本进行单独分析的方式。这种方式导致同一段对话文本需要被重复输入到模型中进行多次推理处理,每次推理都会消耗大量的计算资源(以token为单位计费或计量)。这种重复处理不仅显著增加了计算成本,还延长了质检的整体耗时,降低了系统效率,特别是在处理大规模通话记录时,问题尤为突出。因此,亟需优化质检流程,减少对话文本的重复推理,降低token消耗,提升质检效率和成本效益。
二、当前的问题
1.问题
在催收、电销、客服等电话外呼场景的离线质检中,由于质检规则繁多(涵盖语气、措辞、合规性、关键词等多种检查点),当前流程采用逐条规则单独对对话文本进行模型推理。这种方式导致同一段对话文本被反复处理,多次调用模型进行推理,显著增加了token消耗,造成计算资源浪费。同时,重复推理延长了质检处理时间,降低了系统效率,尤其在处理大规模通话记录时,成本高昂且耗时严重。
2. 当前流程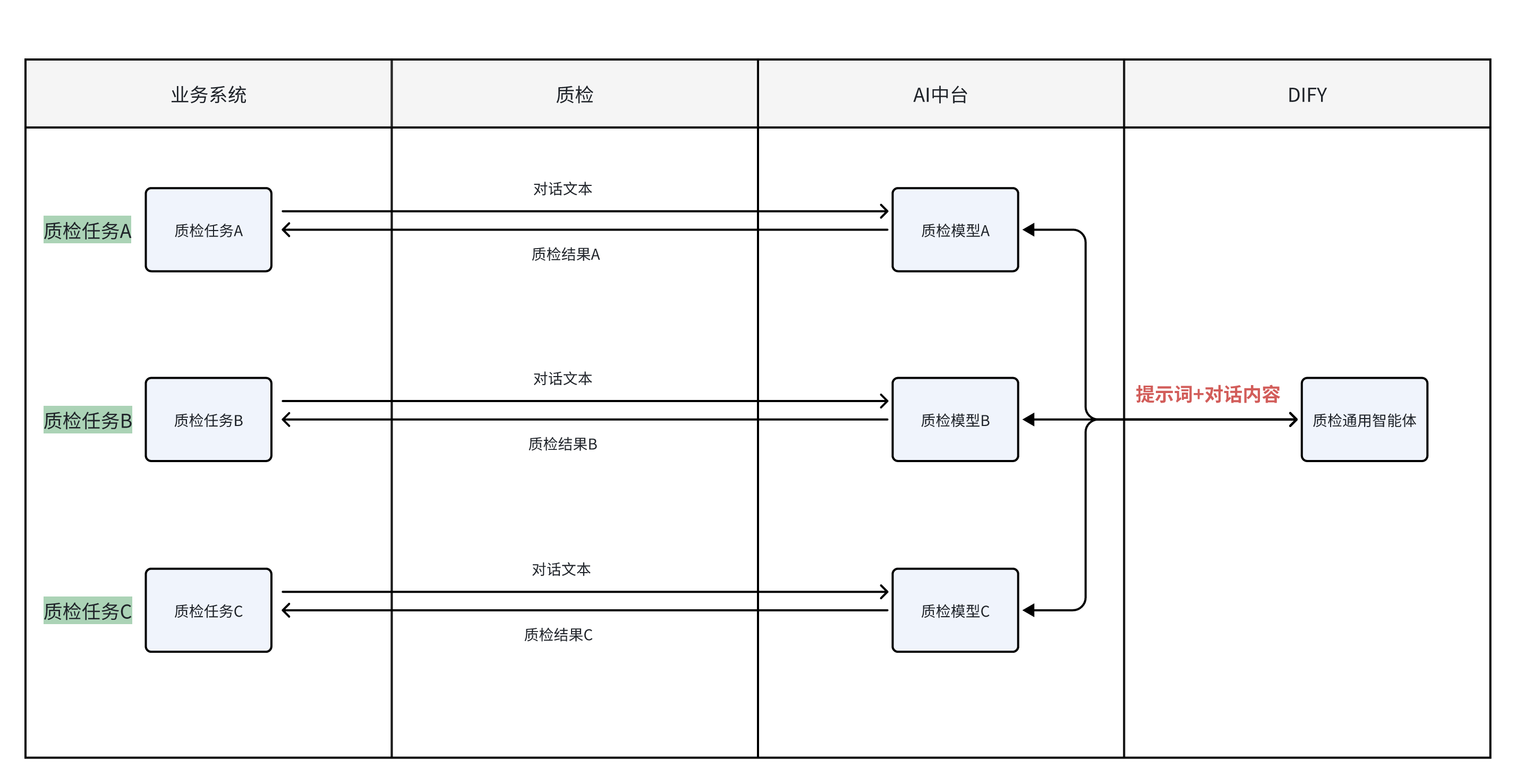
三、火山缓存策略
1.上下文缓存概述
上下文缓存(简称缓存)是方舟提供的一个高效的缓存机制,旨在为您优化调用模型服务体验。通过缓存常用上下文数据,减少每次请求时重复处理加载开销,达到降低成本(命中缓存的输入有折扣优惠)目标。适合多轮对话、工具调用、角色扮演等需多次传入相同内容的场景。
1.1 支持模型
| 模型名称 | 版本 | 调用方式 | 模式 | 计费 |
| doubao-seed-1.6 | 250615 | Response API | 前缀缓存 Session 缓存 |
深度思考模型 |
| doubao-seed-1.6-flash | 250715 | Response API | 前缀缓存 Session 缓存 |
深度思考模型 |
| 250615 | Response API | 前缀缓存 Session 缓存 |
深度思考模型 | |
| doubao-seed-1.6-thinking | 250715 | Response API | 前缀缓存 Session 缓存 |
深度思考模型 |
| 250615 | Response API | 前缀缓存 Session 缓存 |
深度思考模型 | |
| doubao-1.5-pro-32k | character-250715 | Context API | Context API:前缀缓存Session 缓存的rolling_tokens 模式 | 在线推理 |
| character-250228 | Context API | Session 缓存rolling_tokens 模式 | 在线推理 | |
| 250115 | Context API | 前缀缓存 Session 缓存rolling_tokens 模式 |
在线推理 | |
| doubao-1.5-lite | 32k-250115 | Context API | 前缀缓存 Session 缓存rolling_tokens 模式 |
在线推理 |
| doubao-pro-32k | 241215 | Context API | 前缀缓存 Session 缓存rolling_tokens 模式 |
在线推理 |
| character-241215 | Context API | Session 缓存last_history_tokens 模式 | 在线推理 | |
| deepseek-r1 | 250528 | Context API | 前缀缓存 | 在线推理 |
| 250120 | Context API | 前缀缓存 | 在线推理 | |
| distill-qwen-32b-250120 | Context API | 前缀缓存 | 在线推理 | |
| deepseek-v3 | 250324 | Context API | 前缀缓存 Session 缓存rolling_tokens 模式 |
在线推理 |
| 241226 | Context API | 前缀缓存 |
1.2 工作原理
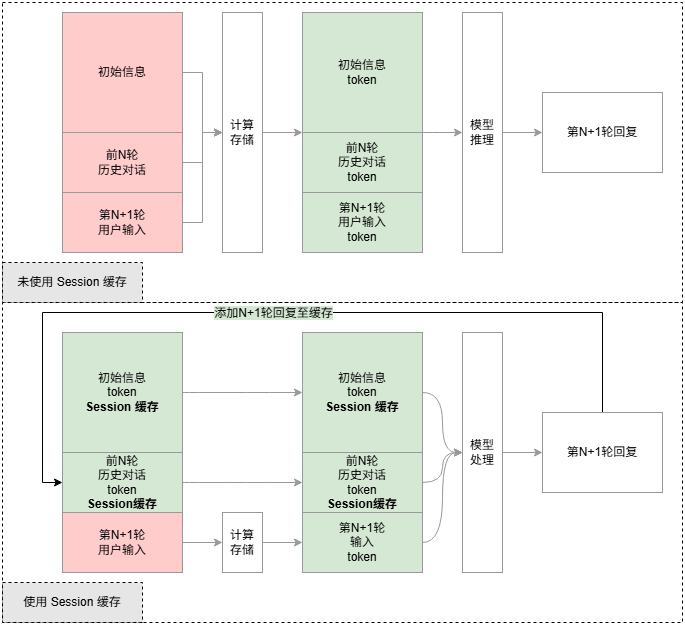
如下图所示,使用缓存处理请求,会在新输入信息(问题)处理完成后,将缓存中已处理好的信息(信息 token)拼接在新输入信息(问题 token)前。相比未使用缓存的请求,可以减少信息的开销,有效降低成本。
-
用户创建缓存时,方舟将信息作为(Value)存到缓存中,并生成对应的缓存 ID 作为 Key。
-
方舟收到对话请求时,会根据请求的缓存 ID 匹配缓存中的初始化信息。
-
方舟只需处理新输入的信息,再结合缓存中已处理的上下文信息,交由模型推理。
-
模型输出回复信息,无需更新缓存中的信息。
1.2 缓存类型
1.2.1 Session 缓存
存储初始信息,同时将每一轮对话动态更新至缓存,在请求时,将缓存的信息与输入信息一起输入给模型进行处理。适合在多轮次对话场景使用,如陪聊、多工具调用等等。 可见 Session 缓存的内容随着请求调用会不断更新,不适用于并发请求场景。
工作原理
1.2.2 前缀缓存
存储初始信息,在每次对话时无需更新,适合标准化对话开场白、特定任务的指令、规则化模板、超长文本深度分析等静态 Prompt 模板的反复使用场景。
工作原理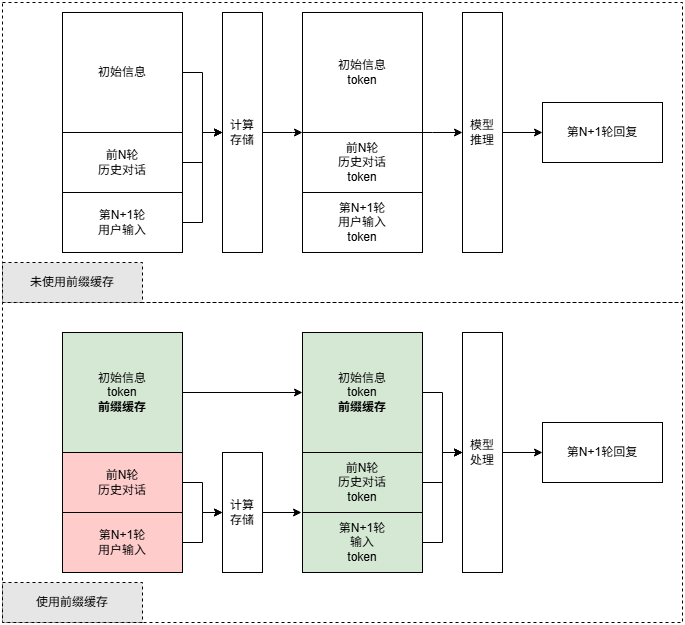
1.2.3 调用方式
方舟提供了两套 API 来使用上下文缓存功能,具体到单个模型,最多支持一套 API 调用缓存方式,即选定模型后,缓存调用的 API 也已确定。下面是两套 API 调用方式的简要说明,供您快速了解调用方式以及两套缓存API的几个核心的区别。可以跳转至对应 API 教程中,查阅具体的调用教程。
| API | Responses API | Context API |
| API 文档 | 创建&使用缓存 API删除缓存 API | 创建缓存 API使用缓存 API |
| 使用流程 | 缓存信息:在对话时配置 "caching": {"type": "enabled" },存储当前对话内容到缓存中。在返回信息中获取 ID 值。使用缓存:在对话时配置 "previous_response_id":"<ID>",本轮对话使用缓存信息。Session 缓存:每次使用缓存同时配置"caching": {"type": "enabled" },将本轮信息也更新到缓存中,并生成新 ID。下一轮调用获取本轮调用返回的 ID。前缀缓存:无需配置"caching": {"type": "enabled" },previous_response_id仅配置为固定缓存 ID 即可。 | 缓存信息:使用创建缓存接口创建缓存信息,并指定创建的缓存类型(Session 缓存、前缀缓存)。在返回信息中获取缓存 ID 值。使用缓存:通过使用缓存接口配置 "context_id":"<ID>",本轮对话使用缓存信息。Session 缓存:每次使用缓存时,更新本轮信息至缓存中。不生成新 ID。下一轮您继续使用原缓存 ID 即可。前缀缓存:每次使用固定的缓存信息。 |
| 保留初始信息 | 是 可灵活控制,即您可删除任意一轮传入的缓存信息,来控制初始信息内容。 初始信息为第一轮输入的信息+第一轮模型的回答。 |
是 不可控制,一旦写入,不可更改。 初始信息为第一轮输入的信息,即调用创建缓存接口,模型不会回答。 |
| 缓存收费项 | 存储缓存费用以及输入命中缓存费用(折扣) | 存储缓存费用以及输入命中缓存费用(折扣) |
| 可缓存的类型 | 支持对多模态输入进行缓存,支持对 Functioncall 内容进行缓存。 | 仅支持文本缓存。 |
| 变更缓存内容 | Session 缓存:支持更新缓存信息,缓存 ID 会新生成一个缓存 ID。 前缀缓存:无需更新。 |
Session 缓存:支持更新缓存信息,缓存 ID 保持不变。 前缀缓存:不支持,且无需更新。 |
| 调用往期缓存信息 | 支持 使用往期缓存 ID |
Session 缓存:不支持,创建缓存后 ID 不变,往期的缓存不可调用。 前缀缓存:不涉及,内容不可变。 |
| 手动删除缓存信息 | 支持 可以删除任意ID的缓存信息 |
不支持 过期自动删除 |
| 手动配置缓存保留时间 | 支持 创建时 72 小时(3天) |
支持 创建缓存时可配置 TTL (7天) |
| 过期机制 | 创建缓存 3 天后自动删除或手动删除 | 创建缓存后,在 TTL 周期内未使用过。使用后激活缓存,重新计时。 |
| 最大缓存长度 | 有 最大上下文窗口 |
有 最大上下文窗口-最大输出长度 |
| 触发最大缓存长度 | 创建时超出最大缓存长度,会报错。 其中 Session 缓存在更新时超出长度限制会报错。 |
创建时超出最大缓存长度,会报错。 其中Session 缓存在更新时超出长度限制,会自动删除历史消息。 |
综上 Responses API 对缓存操控非常灵活,可进行 ID 粒度的使用、变更,前缀缓存/ Session 缓存更多是使用上的区别,而非功能上的隔离,如您可在任意一轮对话中,切换至前缀缓存使用方式,只需请求不再更新缓存 "caching": {"type": "disalbed" },而使用固定的缓存ID。
-
细节说明
缓存上限说明
随着对话轮数增加,内容会达到 Session 缓存的上限。按照处理方式的不同,可以分为 2 种模式。
last_history_tokens 模式
触发上限则滚动信息窗口,遵循先进先出的策略。触发缓存上限时,先删除最早的缓存对话记录(初始消息不会删除,即在创建 session 缓存时写入缓存的信息不会删除),再存入新的对话信息。这个模式下,滚动数据不会产生额外的计算成本。
rolling_tokens 模式
触发上限则定量删除信息并重新计算,使用固定长度 A 来限制 Session 缓存上限,固定长度 B 来控制删除上下文的长度。当 Session 缓存达到上限时,即达到 A 长度时,会进行下面两个动作:
清除 Session 缓存 B 长度的陈旧消息(初始消息不会删除,即在创建 session 缓存时写入的信息不会删除),为后续新的消息腾挪存储空间。
重新计算缓存中历史信息,以确保模型回复与历史交互的连贯性。
具体计算逻辑供您了解:以Doubao-pro-32k模型为例,Session 缓存的 token 量达到 32k(最大上下文长度)-4k(最大输出长度)时,会删除 4k 陈旧的历史信息(除了初始消息),然后重新计算和存储保留的缓存内容。
触发 Session 缓存上限引起重新计算的轮次,会将保留的历史信息和新消息一样进行计算和存储。表现为此轮 Session 缓存的 token 比例降低为 0,该轮无缓存输入 token,后续又会趋于正常。
过期时间
Session 缓存未被使用时会开始计时,达到 TTL(Time To Live),会被删除;如果中途被使用,那么此缓存 TTL 会被重置,并继续保留。
四、解决方案
-
解决方案
为解决上述问题,提出以下优化方案:
通过以上方案,可显著减少token消耗,提升质检效率,降低成本,同时保证质检的准确性和全面性。
-
规则整合与批量处理:将多个质检规则进行整合,设计一个统一的规则框架,通过单次模型推理同时检查多种规则,减少对话文本的重复输入和推理次数。
-
上下文缓存机制:引入缓存机制,存储对话文本的中间推理结果,供后续规则复用,避免重复计算。
-
模型优化:采用轻量化模型或对大型模型进行蒸馏,针对质检场景定制化优化,降低单次推理的token消耗。
-
并行处理:利用分布式计算或并行处理技术,将多段对话文本分配到不同节点同时进行质检,提高吞吐量。
-
智能规则筛选:根据对话内容预先筛选适用的质检规则,避免无关规则的冗余推理,进一步节省资源。
-
-
定制化插件
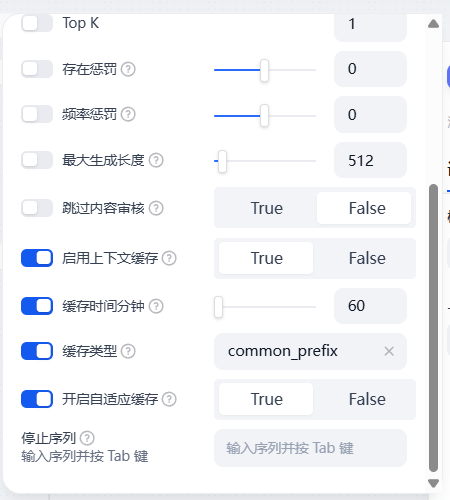
定义解释:
启用上下文缓存:启用上下文缓存功能,可以减少重复计算减少token消耗
缓存时间分钟:缓存时间分钟,按照火山规则,最小60分钟,最大7天
缓存类型:指定缓存类型,session为session缓存,适用于对话型智能体,common_prefix为前缀缓存,适用于任务型智能体
开启自适应缓存:auto为自适应缓存,适用于前缀缓存场景,能够自动选择缓存system提示词还是缓存user文本,非自适应前缀缓存需以 缓存上下文$ 开头
-
优化后流程
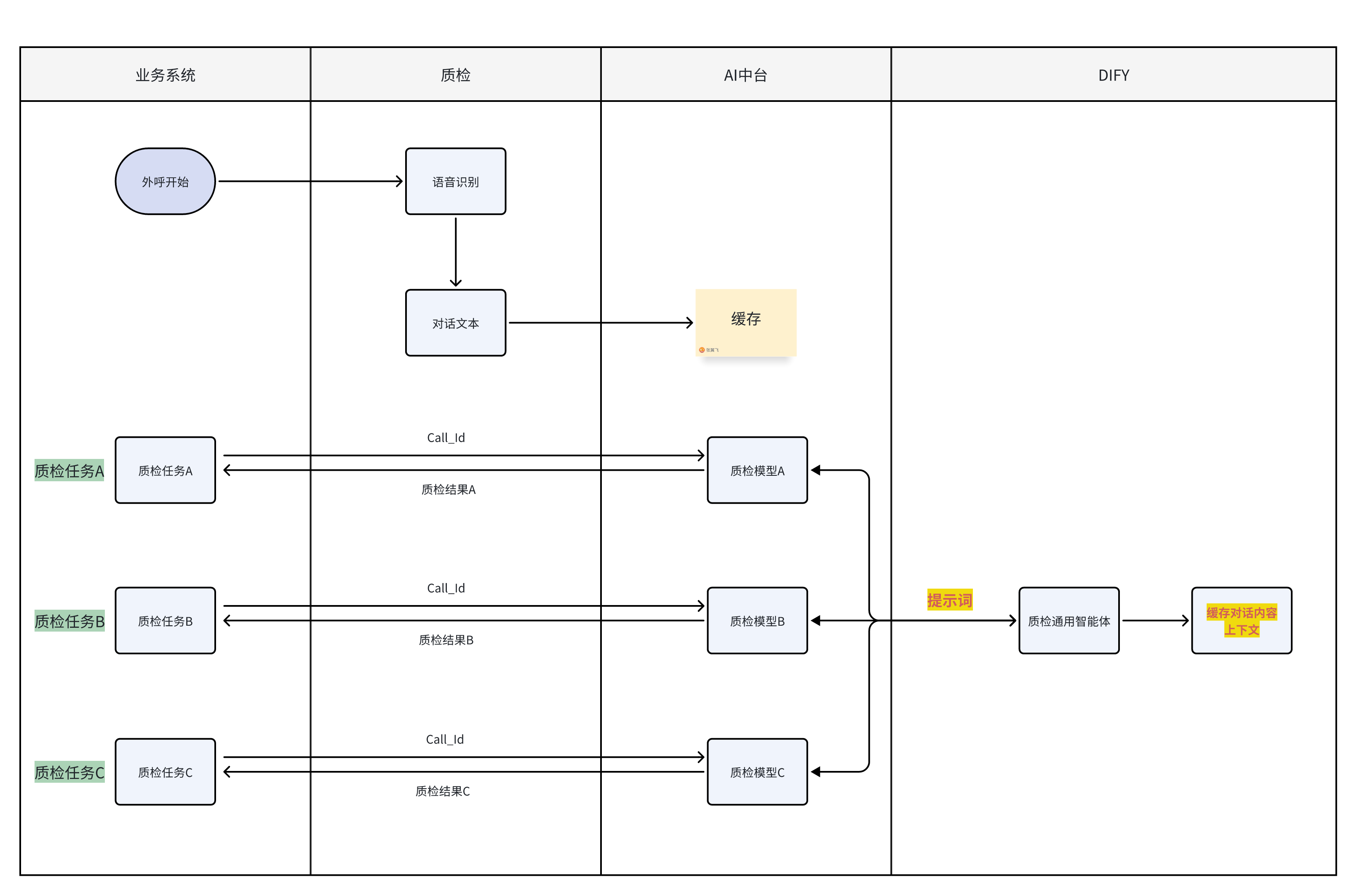
五、效果对比
-
测试数据:
数据集名称:催记验证测试集(截止2025年1月).xlsx
数据集说明:催收场景催记打标数据集
数据集数量:937
-
智能体:
智能体名称:催收催记下码
智能体说明:催收场景挂机下码,标识客户状态和意愿
大模型节点数量:14
-
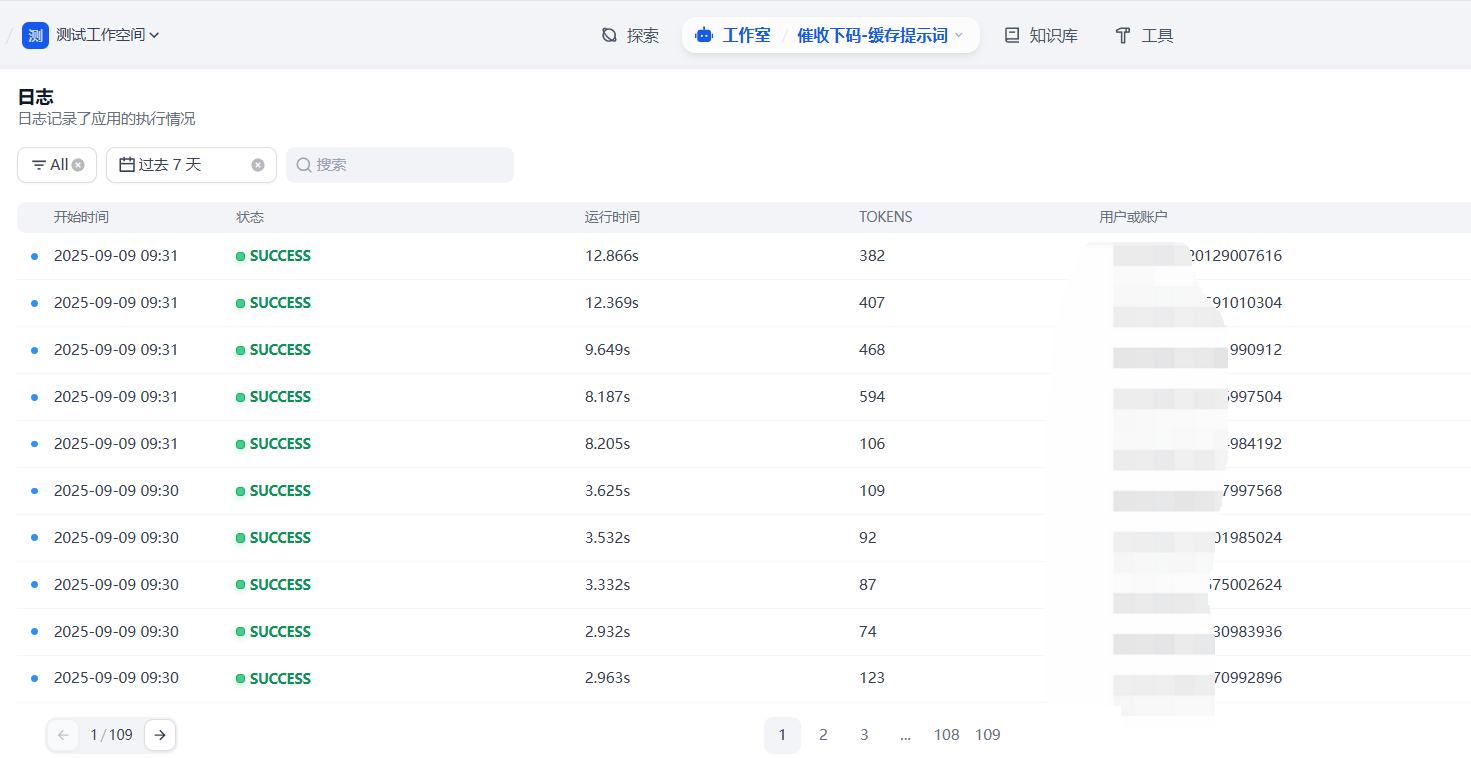
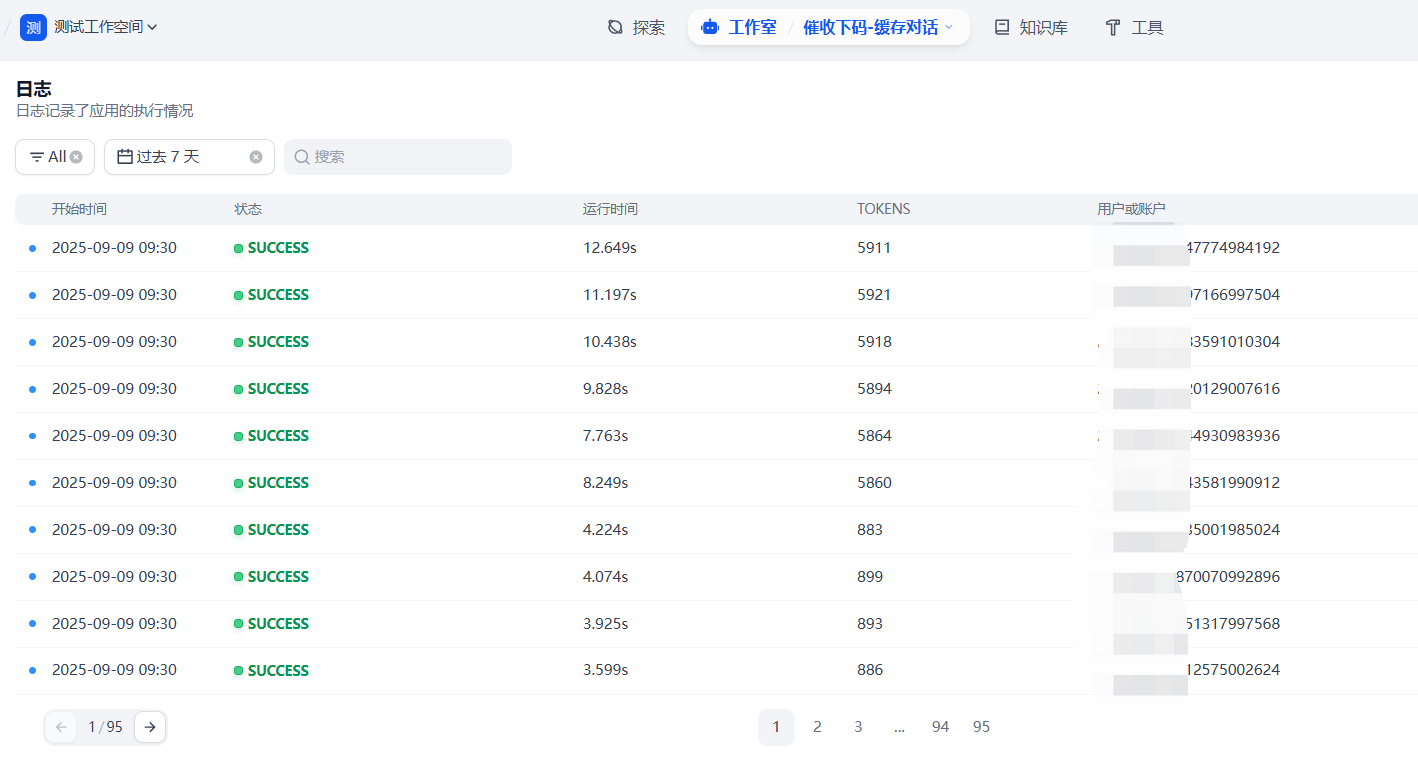
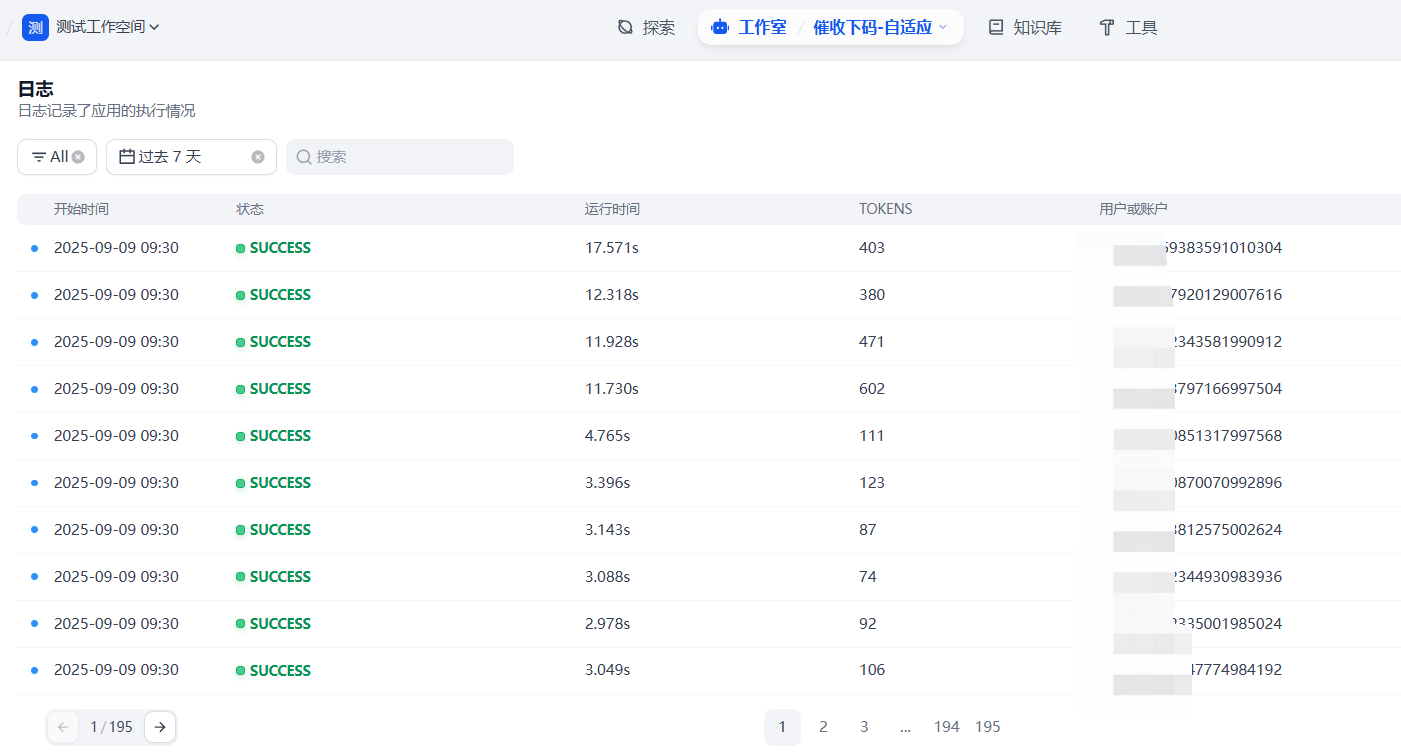
测试效果
实测在一段文本需要多次质检的情况下,如果提示词比较长,缓存提示词效果较好,如果文本较长,缓存文本效果较好,在本场景中,使用自适应缓存方案,可有效节省token消耗 70%。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 15
15 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)