身份证信息提取系统
🖥️ 用户输入 → 🤖 AI 解析 → ✏️ 人工编辑 → 💾 数据库存储 → 🎉 成功反馈本系统通过 Streamlit 前端 + FastAPI 后端 + LLM AI 解析 + MySQL 存储,实现了身份证信息从“非结构化文本”到“结构化数据库记录”的完整自动化处理流程,具备高可用性、易扩展性和良好用户体验。
🖥️ 用户输入 → 🤖 AI 解析 → ✏️ 人工编辑 → 💾 数据库存储 → 🎉 成功反馈
本系统通过 Streamlit 前端 + FastAPI 后端 + LLM AI 解析 + MySQL 存储,实现了身份证信息从“非结构化文本”到“结构化数据库记录”的完整自动化处理流程,具备高可用性、易扩展性和良好用户体验。
1. 背景
-
了解前端页面、后端、AI服务、mysql存储之间的交互过程
-
前端页面按钮跳转,对应后端是如何操作的
-
前端页面预览编辑是如何实现的,当编辑确认后的数据是如何存储在mysql数据库的、
2. 技术栈
|
前端界面 |
Streamlit |
快速构建交互式 UI,适合原型和轻量级应用 |
|
后端服务 |
FastAPI |
高性能、自动生成文档、支持异步、类型安全 |
|
数据库 |
MySQL |
成熟稳定,支持事务,适合结构化数据存储 |
|
AI 服务 |
DeepSeek LLM API |
利用大模型做非结构化文本信息抽取 |
|
HTTP 客户端 |
|
简单易用,调用外部 API |
|
日志管理 |
|
统一记录运行状态,便于调试 |
|
状态管理 |
|
Streamlit 多页面状态保持 |
3. 系统交互架构图
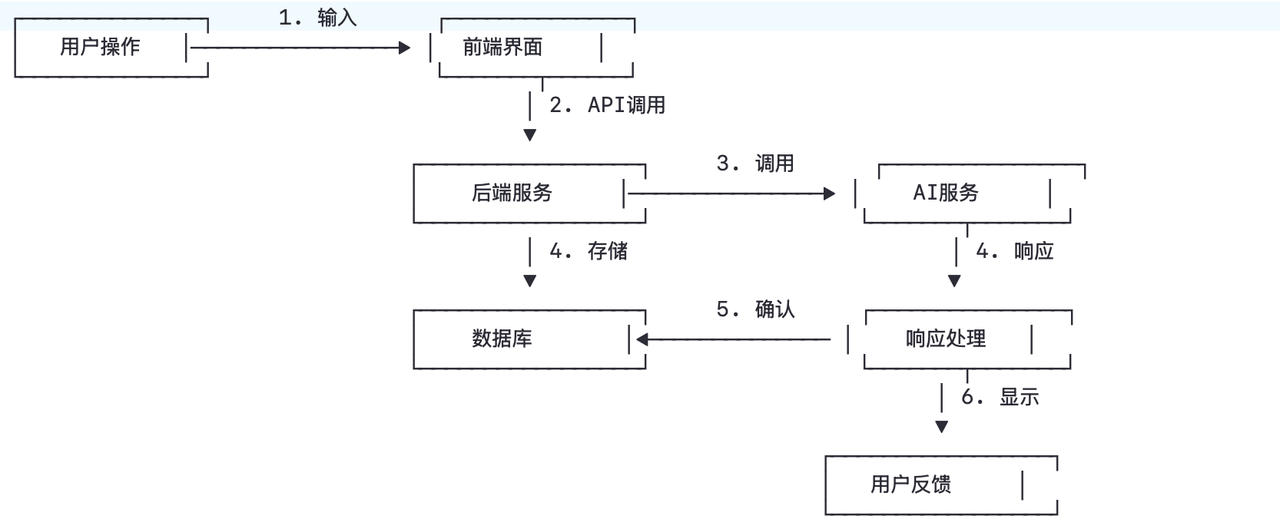
4. 数据流
-
用户输入:在前端输入身份证文本
-
前端处理:点击"开始解析" → 调用
/parseAPI -
后端处理:接收请求 → 调用AI服务 → 返回结果
-
AI服务:调用DeepSeek API → 解析文本 → 返回JSON
-
前端显示:接收JSON → 渲染表格 → 显示结果
-
用户编辑:修改数据 → 点击"保存" → 调用
/saveAPI -
后端存储:接收数据 → 写入MySQL → 返回确认
-
完成显示:显示成功消息 → 展示闭环流程
5. 前端页面衔接过程
Streamlit应用是无状态的 - 每次用户交互都会重新运行整个脚本。为了解决这个问题,Streamlit提供了
st.session_state
四个页面通过 session_state.页面 + safe_rerun 刷新,
动态效果通过 spinner、balloons、CSS 实现
-----------------------------------
Streamlit没有传统意义上的"页面跳转",而是通过状态驱动实现 - # 设置要显示的页面 st.session_state.page = "parsed" - # 重新运行脚本 safe_rerun()
-----------
状态情况:
st.session_state.retry_connection # 后端服务连接重试
st.session_state.parse_result # 解析结果
st.session_state.input_text # 用户输入文本
st.session_state.save_result # 保存结果
st.session_state.final_data # 最后的数据
1. 用户在 [主页] 输入身份证文本
↓
2. 点击“开始解析” → 调用后端 /parse → AI 提取结构化数据
↓
3. 跳转到 [解析页] → 展示结果,标记缺失字段
↓
4. 点击“编辑信息” → 进入 [编辑页] → 用户修改字段
↓
5. 点击“保存” → 调用后端 /save → 存入 MySQL
↓
6. 跳转到 [完成页] → 显示成功动画 + 数据库ID
↓
7. 点击“开始新处理” → 清空状态 → 回到 [主页]6. 启动服务
6.1 启动后端:
uvicorn backend:app --reload --port 8011-
访问
http://localhost:8011/docs查看API文档
6.2 启动前端:
streamlit run frontend.py7. 核心交互流程
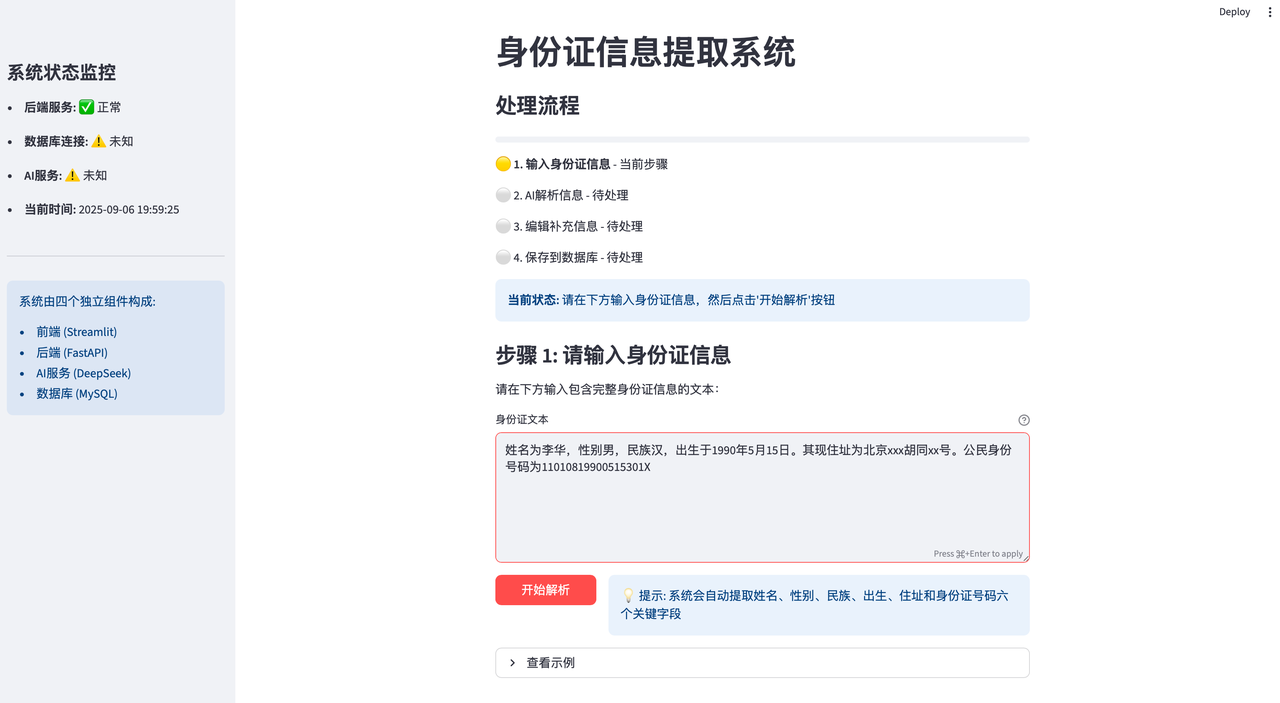
7.1 在前端页面输入身份证文本,点击"开始解析"
前端代码frontend.py中的main_page()【页面】函数
前端通过
requests.post调用后端API使用
st.session_state保存状态(类似浏览器的session)通过修改
st.session_state.page(4个页面)控制页面跳转
|
主页(main) |
输入原始身份证文本 |
|
|
解析页(parsed) |
展示 AI 提取结果,可查看缺失字段 |
|
|
编辑页(edit) |
允许用户编辑/补全字段,表单提交 |
|
|
完成页(complete) |
显示保存成功、数据库 ID、闭环流程 |
|
7.2 后端操作:处理/parse请求
前端调用后端:
backend.py中的parse_id_info_endpoint()函数AI服务调用:
ai_service.py中的parse_id_info()函数
BACKEND_URL = "http://localhost:8011" # 后端服务地址
# 调用后端API
response = requests.post(
f"{BACKEND_URL}/parse",
json={"text": input_text},
timeout=15
)
# 后端解析函数
@app.post("/parse",
summary="解析身份证信息",
description="调用AI服务,解析身份证文本,提取结构化信息")
async def parse_id_info_endpoint(input: TextInput):
"""
前端->后端->AI服务的关键交互点
处理流程:
1. 接收前端传来的身份证文本
2. 调用AI服务模块进行信息提取
3. 返回提取结果给前端
这是系统的核心交互接口之一
"""
logger.info("收到解析身份证信息请求")
try:
# 调用AI服务
result = parse_id_info(input.text)
if not result["success"]:
logger.error(f"AI解析失败: {result['error']}")
raise HTTPException(status_code=500, detail=result["error"])
logger.info("成功返回解析结果")
return result
except Exception as e:
logger.error(f"解析身份证信息失败: {str(e)}", exc_info=True)
raise HTTPException(status_code=500, detail=str(e))
# AI服务接口
def parse_id_info(text):
"""
AI服务:解析身份证信息
处理流程:
1. 接收身份证文本
2. 调用DeepSeek LLM API进行信息提取
3. 处理LLM响应,确保返回结构化数据
4. 返回提取结果
这是AI服务的核心功能实现
"""
logger.info("开始调用AI服务解析身份证信息...")
try:
# 构造LLM请求 - 关键:设计精确的prompt让模型返回结构化数据
payload = json.dumps({
"model": "deepseek-chat",
"messages": [
{
"role": "system",
"content": "你是一个信息提取助手,请从用户提供的文本中提取以下字段:姓名、性别、民族、出生、住址、公民身份号码。请以JSON格式输出,字段名为name, gender, ethnicity, birth, address, id_number。如果某个字段未找到,出生必须按照身份证的信息情况进行转换(例如一九九九年,要转换为1999年),请留空字符串。只输出JSON内容,不要包含其他说明。"
},
{
"role": "user",
"content": text
}
],
"stream": False
})
headers = {
'Authorization': f'Bearer {LLM_API_KEY}',
'Content-Type': 'application/json'
}
# 调用LLM API
logger.debug("向LLM API发送请求...")
response = requests.request("POST", LLM_API_URL, headers=headers, data=payload, timeout=10)
response.raise_for_status() # raise_for_status() 会检查 response.status_code 请求失败,会抛后面的except异常
# 解析响应
llm_response = response.json() # 解析为python字典
llm_content = llm_response["choices"][0]["message"]["content"]
logger.debug(f"LLM原始响应: {llm_content}")
# 处理可能的Markdown代码块包裹(LLM有时会这样返回)
if llm_content.startswith("```json"):
llm_content = llm_content[7:-3].strip()
logger.info("检测到JSON代码块包裹,已清理")
elif llm_content.startswith("```"):
llm_content = llm_content[3:-3].strip()
logger.info("检测到代码块包裹,已清理")
# 尝试解析JSON
try:
parsed_data = json.loads(llm_content)
logger.info("成功解析LLM返回的JSON数据")
except json.JSONDecodeError:
# 如果解析失败,尝试提取JSON部分
json_match = re.search(r'\{[\s\S]*\}', llm_content)
# [\s\S]* 匹配任意字符,如果模型返回了多余文字(如 “好的,这是你要的JSON:{...}”),这段代码能提取出 {...} 部分。
if json_match:
try:
parsed_data = json.loads(json_match.group())
logger.warning("LLM响应不是纯JSON,已从文本中提取JSON部分")
except json.JSONDecodeError:
raise ValueError("无法从LLM响应中提取有效的JSON数据")
else:
raise ValueError("无法从LLM响应中提取有效的JSON数据")
# 确保所有字段都存在,缺失的设为空字符串
required_fields = ["name", "gender", "ethnicity", "birth", "address", "id_number"]
for field in required_fields:
if field not in parsed_data: # 修复:parsed_ -> parsed_data
parsed_data[field] = ""
logger.warning(f"字段 '{field}' 在LLM响应中缺失,已设为空字符串")
logger.info("AI解析完成,返回结构化数据")
return {
"success": True,
"data": parsed_data,
"llm_response": llm_content,
"input_text": text
}
except requests.exceptions.RequestException as e:
logger.error(f"网络请求失败: {str(e)}", exc_info=True)
return {
"success": False,
"error": f"网络请求失败: {str(e)}"
}
except Exception as e:
logger.error(f"解析身份证信息失败: {str(e)}", exc_info=True)
return {
"success": False,
"error": str(e)
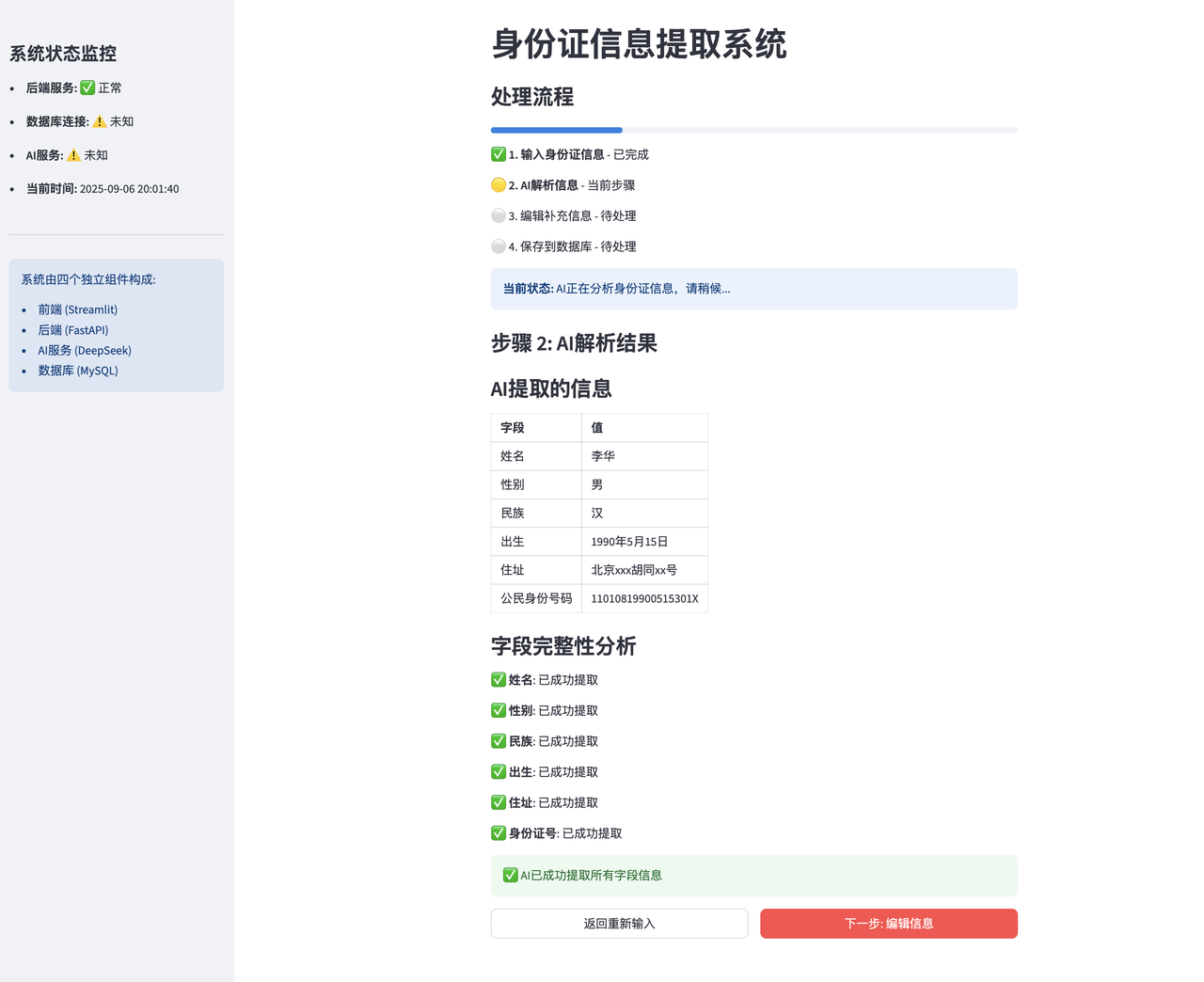
}7.3 用户看到:解析结果表格,显示AI提取的6个字段
前端解析页面:
frontend.py中的parsed_page()函数(前端展示)
从
st.session_state.parse_result获取之前保存的结果前端:
display_id_info()函数将数据渲染为表格展示
# 前端展示设置
def parsed_page():
# 1. 从session获取结果
result = st.session_state.parse_result
# 2. 显示解析结果
st.subheader("AI提取的信息")
display_id_info(result["data"])
# 3. 检查是否有缺失字段
missing_fields = [k for k, v in result["data"].items() if not v]
# 4. 提供下一步操作
if st.button("下一步: 编辑信息", type="primary", use_container_width=True):
st.session_state.page = "edit"
safe_rerun()
# 解析数据表格渲染展示
def display_id_info(data):
"""以表格形式显示身份证信息 - 前端展示的关键实现"""
# 创建Markdown表格
table_md = "| 字段 | 值 |\n|------|-----|\n"
table_md += f"| 姓名 | {data.get('name', '')} |\n"
table_md += f"| 性别 | {data.get('gender', '')} |\n"
table_md += f"| 民族 | {data.get('ethnicity', '')} |\n"
table_md += f"| 出生 | {data.get('birth', '')} |\n"
table_md += f"| 住址 | {data.get('address', '')} |\n"
table_md += f"| 公民身份号码 | {data.get('id_number', '')} |\n"
st.markdown(table_md)
# 添加字段状态指示器
st.subheader("字段完整性分析")
fields = [
("姓名", data.get('name', '')),
("性别", data.get('gender', '')),
("民族", data.get('ethnicity', '')),
("出生", data.get('birth', '')),
("住址", data.get('address', '')),
("身份证号", data.get('id_number', ''))
]
for field, value in fields:
if value:
st.markdown(f"✅ **{field}**: 已成功提取")
else:
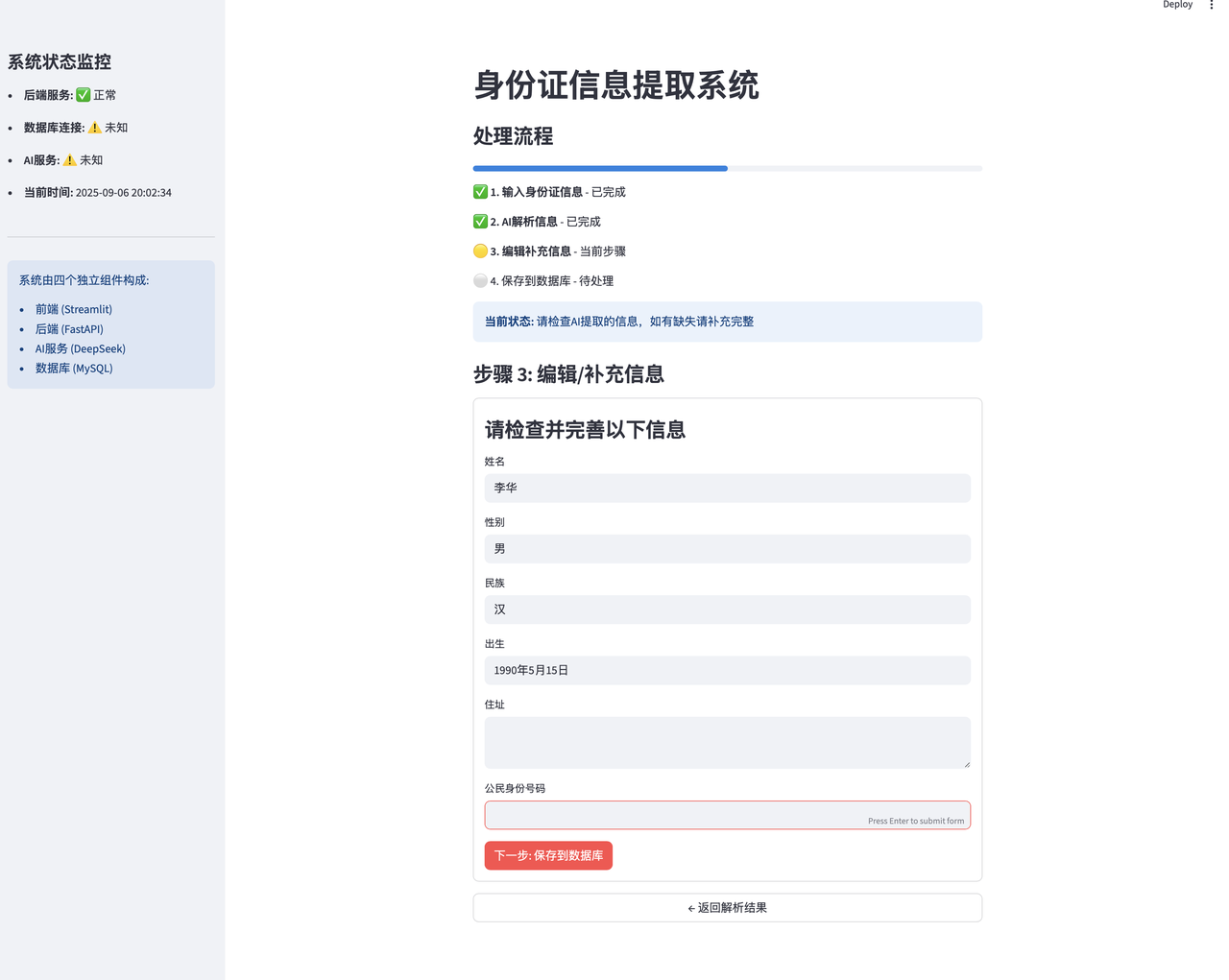
st.markdown(f"❌ **{field}**: 未提取到,需要补充") 7.4 用户操作:在编辑页面完善信息,点击"保存到数据库"
前端编辑页面:
frontend.py中的edit_page()函数关键点:
表单自动填充AI已提取的数据
添加了身份证号码格式验证
将8个字段数据(6个提取字段+原始文本+LLM响应)发送给后端
# 边界页面
def edit_page():
"""编辑页面:允许用户编辑/补充解析结果"""
st.title("身份证信息提取系统")
# 显示流程
show_process_flow(2)
st.subheader("步骤 3: 编辑/补充信息")
# 获取之前的解析结果
result = st.session_state.parse_result
# 创建编辑表单
## st.form 创建展示表单
with st.form("edit_form"):
st.subheader("请检查并完善以下信息")
# 各字段编辑
name = st.text_input("姓名", value=result["data"].get("name", ""))
gender = st.text_input("性别", value=result["data"].get("gender", ""))
ethnicity = st.text_input("民族", value=result["data"].get("ethnicity", ""))
birth = st.text_input("出生", value=result["data"].get("birth", ""))
address = st.text_area("住址", value=result["data"].get("address", ""), height=100)
id_number = st.text_input("公民身份号码", value=result["data"].get("id_number", ""))
# 提交按钮
## 表单容器 + 提交按钮 避免每次输入都刷新,适合多字段编辑
submitted = st.form_submit_button("下一步: 保存到数据库", type="primary")
if submitted:
with st.spinner("正在保存信息到数据库..."):
try:
# 准备数据
save_data = {
"name": name,
"gender": gender,
"ethnicity": ethnicity,
"birth": birth,
"address": address,
"id_number": id_number,
"input_text": result["input_text"],
"llm_response": result["llm_response"]
}
# 调用后端保存API
response = requests.post(
f"{BACKEND_URL}/save",
json=save_data,
timeout=10
)
if response.status_code == 200:
st.session_state.save_result = response.json()
st.session_state.final_data = save_data
# 跳转到完成页面
st.session_state.page = "complete"
safe_rerun()
else:
st.error(f"保存失败 (状态码 {response.status_code}): {response.text}")
except requests.exceptions.RequestException as e:
st.error(f"网络请求超时或失败: {str(e)}")
st.info("请检查后端服务是否正常运行")
except Exception as e:
st.error(f"请求处理失败: {str(e)}")
7.5 后端操作:处理/save请求
后端保存标记好确认的数据:
backend.py中的save_id_info()函数
使用参数化查询防止SQL注入
事务处理确保数据一致性
返回新记录ID用于前端展示
@app.post("/save")
async def save_id_info(id_info: IdInfo):
try:
connection = get_db_connection()
with connection.cursor() as cursor:
# 插入数据
sql = """INSERT INTO id_info
(input_text, llm_response, name, gender, ethnicity, birth, address, id_number)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s)"""
cursor.execute(sql, (
id_info.input_text,
id_info.llm_response,
id_info.name,
# ...其他字段
))
insert_id = cursor.lastrowid # 获取新记录ID
connection.commit()
return {"success": True, "id": insert_id, "message": "数据已成功保存"}
except Exception as e:
# 错误处理
raise HTTPException(status_code=500, detail=str(e))
finally:
if 'connection' in locals() and connection.open:
connection.close()7.6 用户看到:成功消息,最终保存的数据,系统闭环信息
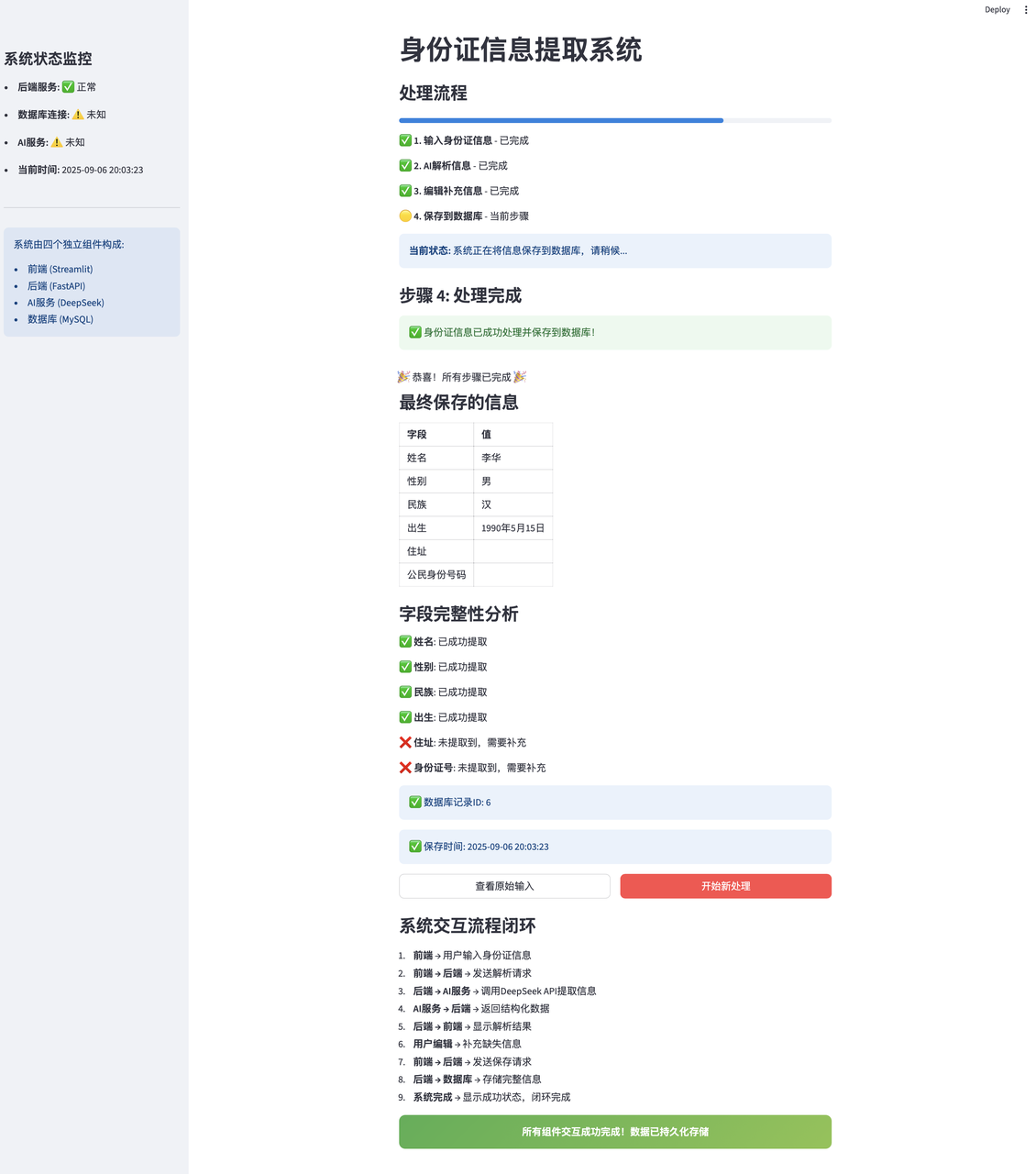
前端保存页面:
frontend.py中的complete_page()函数
8. Streamlit 的st.命令
|
命令 |
页面效果 |
用途说明 |
示例代码 |
是否推荐复用 |
|
|
大号加粗标题(H1) |
页面主标题,吸引注意力 |
|
✅ 是 |
|
|
中号标题(H3) |
分区标题,如步骤标题 |
|
✅ 是 |
|
|
普通等宽文本 |
显示不可编辑的纯文本内容 |
|
✅ 是 |
|
|
支持 Markdown 语法 |
可加粗、列表、表格、颜色、HTML(需 |
|
✅ 是 |
|
|
蓝色信息框 |
用于提示、说明、引导用户 |
|
✅ 是 |
|
|
黄色警告框 |
提醒缺失、注意、建议操作 |
|
✅ 是 |
|
|
红色错误框 |
显示错误、失败、异常信息 |
|
✅ 是 |
|
|
绿色成功框 |
显示操作成功、完成状态 |
|
✅ 是 |
|
|
进度条(0~1) |
显示流程进度、加载百分比 |
|
✅ 是 |
|
|
旋转加载图标 + 文本 |
包裹耗时操作,提升体验 |
|
✅ 是 |
|
|
屏幕放彩色气球动画 |
庆祝完成、增强正向反馈 |
|
✅ 是 |
|
|
按钮 |
触发事件,如跳转、提交、重试 |
|
✅ 是 |
|
|
多行文本输入框 |
输入长文本(如身份证原文) |
|
✅ 是 |
|
|
单行文本输入框 |
编辑姓名、身份证号等字段 |
|
✅ 是 |
|
|
表单容器 + 提交按钮 |
避免每次输入都刷新,适合多字段编辑 |
|
✅ 是 |
|
|
分栏布局 |
创建多列(如按钮左右排布) |
|
✅ 是 |
|
|
可折叠区域 |
点击展开/收起内容(如“查看示例”) |
|
✅ 是 |
|
|
会话状态字典 |
跨页面/组件保存数据(如解析结果、当前页) |
|
✅ 是 |
|
|
重新运行整个脚本 |
页面跳转、状态更新后刷新界面 |
|
✅ 是(推荐封装为 |
|
|
代码块样式 |
显示示例代码、JSON、SQL 等 |
|
✅ 是 |
|
|
格式化 JSON 显示 |
调试用,显示结构化数据 |
|
✅ 是 |
|
|
侧边栏组件 |
所有上述组件均可加 |
|
✅ 是 |
|
|
占位符 |
动态更新内容区域(如倒计时、实时日志) |
|
⚠️ 中高级,按需使用 |
|
|
下拉框 / 单选按钮 |
选择选项(本项目未用,但常用) |
|
✅ 是(扩展用) |
9. 系统架构设计
1. 需求分析 → 2. 架构设计 → 3. 数据库设计 → 4. 后端开发 → 5. AI服务集成 → 6. 前端开发 → 7. 测试调试
### 1. 需求分析(文档阶段,无代码)
"""
功能需求:
- 用户输入身份证文本
- AI 自动提取姓名、性别、民族、出生、住址、身份证号
- 支持人工编辑校对
- 保存到数据库
- 显示处理进度与系统状态
技术栈:
- 前端:Streamlit
- 后端:FastAPI
- 数据库:MySQL
- AI 服务:DeepSeek API
"""
### 2. 架构设计(模块划分)
"""
文件结构:
.
├── frontend.py # 前端界面(Streamlit)
├── backend.py # 后端服务(FastAPI)
├── ai_service.py # AI 服务封装(LLM 调用)
├── db_init.py # 数据库初始化
└── config.py # 配置管理(可选)
"""
### 3. 数据库设计
# db_init.py
import pymysql
def init_database():
"""创建数据库和所有必要表"""
pass # TODO: 连接 MySQL,创建 project_text 数据库
# TODO: 创建 id_info 表(字段:id, input_text, llm_response, name, gender, ...)
def get_db_connection():
"""获取数据库连接"""
pass # TODO: 使用 DB_CONFIG 创建并返回 pymysql 连接
# ========================================
# 4. 后端开发
# ========================================
# backend.py
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
import logging
app = FastAPI(title="身份证信息提取API")
# ------------------------
# 数据模型定义
# ------------------------
class TextInput(BaseModel):
text: str
class IdInfo(BaseModel):
name: str
gender: str
ethnicity: str
birth: str
address: str
id_number: str
input_text: str
llm_response: str
# ------------------------
# 中间件
# ------------------------
@app.middleware("http")
async def log_requests(request, call_next):
pass # TODO: 记录请求方法、URL、响应状态码
# 添加 CORS 支持
app.add_middleware(...)
# ------------------------
# API 端点
# ------------------------
@app.post("/parse", summary="解析身份证信息")
async def parse_id_info_endpoint(input: TextInput):
"""调用AI服务解析身份证文本"""
pass # TODO: 调用 ai_service.parse_id_info(input.text)
# TODO: 成功返回结果,失败抛 HTTPException
@app.post("/save", summary="保存身份证信息")
async def save_id_info(id_info: IdInfo):
"""将结构化信息保存到数据库"""
pass # TODO: 使用 get_db_connection() 插入数据
# TODO: 返回插入 ID 和成功状态
@app.get("/health", summary="健康检查")
async def health_check():
"""检查服务是否运行"""
pass # TODO: 返回 {"status": "ok"}
@app.get("/api-status", summary="全面状态检查")
async def api_status():
"""检查后端、数据库、AI服务状态"""
pass # TODO: 分别测试数据库连接、调用AI测试请求
# TODO: 返回各组件状态
# ========================================
# 5. AI服务集成
# ========================================
# ai_service.py
import requests
import json
import logging
LLM_API_URL = "https://api.deepseek.com/chat/completions"
LLM_API_KEY = "sk-..." # 建议从环境变量读取
def parse_id_info(text: str) -> dict:
"""
调用LLM API解析身份证信息
返回: {"success": bool, "data": {...}, "error": "...", "llm_response": "..."}
"""
pass # TODO: 构造 system prompt(要求返回JSON)
# TODO: 发送 POST 请求到 LLM API
# TODO: 处理响应:清理 ```json、提取 JSON、补全字段
# TODO: 捕获网络异常、JSON解析异常
# TODO: 返回标准化结果
# ========================================
# 6. 前端开发
# ========================================
# frontend.py
import streamlit as st
import requests
# 配置
BACKEND_URL = "http://localhost:8011"
def check_backend():
"""检查后端是否可用"""
pass # TODO: GET /health
def show_process_flow(current_step):
"""显示处理流程进度条"""
pass # TODO: st.progress + st.markdown 步骤状态
def show_system_status():
"""显示侧边栏系统状态"""
pass # TODO: st.sidebar 显示后端、数据库、AI状态
def main_page():
"""主页面:输入身份证文本"""
pass # TODO: st.text_area + "开始解析"按钮
# TODO: 调用 /parse,保存结果到 st.session_state
def parsed_page():
"""解析结果页面"""
pass # TODO: 显示AI提取结果,标记缺失字段
# TODO: 提供“编辑”按钮
def edit_page():
"""编辑页面:用户修改字段"""
pass # TODO: st.form 表单,预填AI结果
# TODO: 身份证号格式校验
# TODO: 提交时调用 /save
def complete_page():
"""完成页面:显示成功"""
pass # TODO: st.balloons() + 成功动画 + 数据库ID
# TODO: “开始新处理”按钮清空状态
def safe_rerun():
"""兼容版本的页面刷新"""
pass # TODO: try st.rerun() except AttributeError: st.experimental_rerun()
# ------------------------
# 页面路由主逻辑
# ------------------------
if "page" not in st.session_state:
st.session_state.page = "main"
show_system_status()
# 根据当前页面显示对应内容
if st.session_state.page == "main":
main_page()
elif st.session_state.page == "parsed":
parsed_page()
elif st.session_state.page == "edit":
edit_page()
elif st.session_state.page == "complete":
complete_page()
# ========================================
# 7. 测试调试
# ========================================
# test_unit.py - 单元测试
"""
def test_ai_service():
result = parse_id_info("张三 男 汉 1990年 ...")
assert result["success"] == True
assert "name" in result["data"]
def test_db_connection():
conn = get_db_connection()
assert conn.open == True
"""
# test_integration.py - 跨模块测试
"""
def test_parse_and_save():
# 模拟前端调用
response = requests.post(f"{BACKEND_URL}/parse", json={"text": "..."})
assert response.status_code == 200
data = response.json()
save_response = requests.post(f"{BACKEND_URL}/save", json={...})
assert save_response.json()["success"] == True
"""
# test_e2e.py - 端到端测试(可选)
"""
使用 Selenium 或 Playwright 模拟用户操作 Streamlit 页面
"""
# 用户测试计划
"""
邀请 3-5 名非技术人员试用,记录:
- 是否能顺利完成全流程
- 哪些提示不清楚
- 哪些功能缺失
"""10. 代码
# db_init.py
import pymysql
import logging
# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger("DB_INIT")
DB_CONFIG = {
"host": "localhost",
"port": 3306,
"user": "root",
"password": "", # 替换成自己的本地root密码
"database": "project_text",
"charset": "utf8mb4",
}
def init_database():
"""初始化数据库:创建数据库和表(如果不存在)"""
logger.info("开始数据库初始化...")
try:
# 先尝试连接,不指定数据库
conn = pymysql.connect(
host=DB_CONFIG["host"],
port=DB_CONFIG["port"],
user=DB_CONFIG["user"],
password=DB_CONFIG["password"],
charset=DB_CONFIG["charset"]
)
cursor = conn.cursor()
# 创建数据库(如果不存在)
cursor.execute(f"CREATE DATABASE IF NOT EXISTS {DB_CONFIG['database']} CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci")
logger.info(f"数据库 '{DB_CONFIG['database']}' 已创建或已存在")
# 切换到目标数据库
conn.select_db(DB_CONFIG['database'])
# 创建表
create_table_sql = """
CREATE TABLE IF NOT EXISTS id_info (
id INT AUTO_INCREMENT PRIMARY KEY,
input_text TEXT NOT NULL,
llm_response TEXT NOT NULL,
name VARCHAR(100),
gender VARCHAR(20),
ethnicity VARCHAR(50),
birth VARCHAR(50),
address TEXT,
id_number VARCHAR(50),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
"""
cursor.execute(create_table_sql)
logger.info("表 'id_info' 已创建或已存在")
conn.commit()
cursor.close()
conn.close()
logger.info("数据库初始化完成")
return True
except Exception as e:
logger.error(f"数据库初始化失败: {str(e)}")
raise
if __name__ == "__main__":
init_database()
"""
conn = pymysql.connect(...) # 1. 建立连接,连接数据库
cursor = conn.cursor() # 2. 创建游标,执行SQL语句
cursor.execute(sql1) # 3. 用游标执行SQL语句
cursor.execute(sql2)
conn.commit() # 4. 提交事务(对写操作很重要!)管理事务(commit / rollback)。
cursor.close() # 5. 关闭游标
conn.close() # 6. 关闭连接
"""# ai_service.py
import requests
import json
import logging
import re # 添加re模块导入
# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger("AI_SERVICE") # 创建名为 "AI_SERVICE" 的日志记录器,便于后续过滤或输出到不同文件。
# ========== LLM API 配置 ==========
LLM_API_URL = "https://api.deepseek.com/chat/completions"
LLM_API_KEY = "" # 实际使用中建议通过环境变量管理
def parse_id_info(text):
"""
AI服务:解析身份证信息
处理流程:
1. 接收身份证文本
2. 调用DeepSeek LLM API进行信息提取
3. 处理LLM响应,确保返回结构化数据
4. 返回提取结果
这是AI服务的核心功能实现
"""
logger.info("开始调用AI服务解析身份证信息...")
try:
# 构造LLM请求 - 关键:设计精确的prompt让模型返回结构化数据
payload = json.dumps({
"model": "deepseek-chat",
"messages": [
{
"role": "system",
"content": "你是一个信息提取助手,请从用户提供的文本中提取以下字段:姓名、性别、民族、出生、住址、公民身份号码。请以JSON格式输出,字段名为name, gender, ethnicity, birth, address, id_number。如果某个字段未找到,出生必须按照身份证的信息情况进行转换(例如一九九九年,要转换为1999年),请留空字符串。只输出JSON内容,不要包含其他说明。"
},
{
"role": "user",
"content": text
}
],
"stream": False
})
headers = {
'Authorization': f'Bearer {LLM_API_KEY}',
'Content-Type': 'application/json'
}
# 调用LLM API
logger.debug("向LLM API发送请求...")
response = requests.request("POST", LLM_API_URL, headers=headers, data=payload, timeout=10)
response.raise_for_status() # raise_for_status() 会检查 response.status_code 请求失败,会抛后面的except异常
# 解析响应
llm_response = response.json() # 解析为python字典
llm_content = llm_response["choices"][0]["message"]["content"]
logger.debug(f"LLM原始响应: {llm_content}")
# 处理可能的Markdown代码块包裹(LLM有时会这样返回)
if llm_content.startswith("```json"):
llm_content = llm_content[7:-3].strip()
logger.info("检测到JSON代码块包裹,已清理")
elif llm_content.startswith("```"):
llm_content = llm_content[3:-3].strip()
logger.info("检测到代码块包裹,已清理")
# 尝试解析JSON
try:
parsed_data = json.loads(llm_content)
logger.info("成功解析LLM返回的JSON数据")
except json.JSONDecodeError:
# 如果解析失败,尝试提取JSON部分
json_match = re.search(r'\{[\s\S]*\}', llm_content)
# [\s\S]* 匹配任意字符,如果模型返回了多余文字(如 “好的,这是你要的JSON:{...}”),这段代码能提取出 {...} 部分。
if json_match:
try:
parsed_data = json.loads(json_match.group())
logger.warning("LLM响应不是纯JSON,已从文本中提取JSON部分")
except json.JSONDecodeError:
raise ValueError("无法从LLM响应中提取有效的JSON数据")
else:
raise ValueError("无法从LLM响应中提取有效的JSON数据")
# 确保所有字段都存在,缺失的设为空字符串
required_fields = ["name", "gender", "ethnicity", "birth", "address", "id_number"]
for field in required_fields:
if field not in parsed_data: # 修复:parsed_ -> parsed_data
parsed_data[field] = ""
logger.warning(f"字段 '{field}' 在LLM响应中缺失,已设为空字符串")
logger.info("AI解析完成,返回结构化数据")
return {
"success": True,
"data": parsed_data,
"llm_response": llm_content,
"input_text": text
}
except requests.exceptions.RequestException as e:
logger.error(f"网络请求失败: {str(e)}", exc_info=True)
return {
"success": False,
"error": f"网络请求失败: {str(e)}"
}
except Exception as e:
logger.error(f"解析身份证信息失败: {str(e)}", exc_info=True)
return {
"success": False,
"error": str(e)
}# backend.py
from fastapi import FastAPI, HTTPException, Request
from fastapi.middleware.cors import CORSMiddleware
from pydantic import BaseModel
import logging
from db_init import init_database
from ai_service import parse_id_info
# 初始化数据库
init_database()
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger("BACKEND")
logger.info("正在启动后端服务...")
app = FastAPI(
title="身份证信息提取API",
description="提供身份证信息解析和存储服务",
version="1.0.0"
)
# 添加CORS中间件 - 修复前端通过浏览器跨域访问后端问题 中间件起的功能是什么?
app.add_middleware(
CORSMiddleware,
allow_origins=["*"], # 允许所有域名访问(开发用,生产应限制)
allow_credentials=True, # 允许携带 Cookie
allow_methods=["*"], # 允许所有 HTTP 方法
allow_headers=["*"], # 允许所有请求头
)
"""
中间件(Middleware) 是在“请求到达路由处理函数之前”和“响应返回给客户端之前”执行的代码。
"""
# ========== 数据库配置 ==========
DB_CONFIG = {
"host": "localhost",
"port": 3306,
"user": "root",
"password": "yk123123",
"database": "project_text",
"charset": "utf8mb4",
"autocommit": True,
}
import pymysql
def get_db_connection():
"""创建并返回数据库连接"""
try:
connection = pymysql.connect(**DB_CONFIG)
return connection
except Exception as e:
logger.error(f"数据库连接失败: {str(e)}", exc_info=True)
raise
class TextInput(BaseModel):
text: str
class IdInfo(BaseModel):
name: str
gender: str
ethnicity: str
birth: str
address: str
id_number: str
input_text: str
llm_response: str
@app.middleware("http")
async def log_requests(request: Request, call_next): # call_next什么意思?call_next 是一个函数,它代表“继续执行后续的中间件或路由处理函数”。
"""请求日志中间件"""
logger.info(f"收到请求: {request.method} {request.url}")
response = await call_next(request)
logger.info(f"响应状态: {response.status_code}")
return response
@app.post("/parse",
summary="解析身份证信息",
description="调用AI服务,解析身份证文本,提取结构化信息")
async def parse_id_info_endpoint(input: TextInput):
"""
前端->后端->AI服务的关键交互点
处理流程:
1. 接收前端传来的身份证文本
2. 调用AI服务模块进行信息提取
3. 返回提取结果给前端
这是系统的核心交互接口之一
"""
logger.info("收到解析身份证信息请求")
try:
# 调用AI服务
result = parse_id_info(input.text)
if not result["success"]:
logger.error(f"AI解析失败: {result['error']}")
raise HTTPException(status_code=500, detail=result["error"])
logger.info("成功返回解析结果")
return result
except Exception as e:
logger.error(f"解析身份证信息失败: {str(e)}", exc_info=True)
raise HTTPException(status_code=500, detail=str(e))
@app.post("/save",
summary="保存身份证信息",
description="将完整身份证信息保存到数据库")
async def save_id_info(id_info: IdInfo):
"""
前端编辑确认后->后端->数据库的关键交互点
处理流程:
1. 接收前端传来的完整身份证信息
2. 将信息保存到MySQL数据库
3. 返回保存状态
这是系统的核心交互接口之一
"""
logger.info("收到保存身份证信息请求")
try:
connection = get_db_connection()
with connection.cursor() as cursor:
# 插入数据
sql = """INSERT INTO id_info
(input_text, llm_response, name, gender, ethnicity, birth, address, id_number)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s)"""
cursor.execute(sql, (
id_info.input_text,
id_info.llm_response,
id_info.name,
id_info.gender,
id_info.ethnicity,
id_info.birth,
id_info.address,
id_info.id_number
))
# 获取插入的ID
insert_id = cursor.lastrowid
connection.commit()
logger.info(f"成功保存ID信息,记录ID: {insert_id}")
return {"success": True, "id": insert_id, "message": "数据已成功保存到数据库"}
except Exception as e:
logger.error(f"保存ID信息失败: {str(e)}", exc_info=True)
raise HTTPException(status_code=500, detail=str(e))
finally:
if 'connection' in locals() and connection.open:
connection.close()
@app.get("/health",
summary="健康检查",
description="检查服务健康状态")
async def health_check():
"""健康检查端点,用于确认服务正常运行"""
return {"status": "ok", "service": "id-info-parser"}
@app.get("/api-status",
summary="API状态检查",
description="检查API各组件状态")
async def api_status():
"""全面检查API状态"""
try:
# 检查数据库连接
connection = get_db_connection()
with connection.cursor() as cursor:
cursor.execute("SELECT 1")
db_status = "connected"
connection.close()
except Exception as e:
db_status = f"error: {str(e)}"
# 检查AI服务
try:
test_result = parse_id_info("测试")
ai_status = "available" if test_result["success"] else f"error: {test_result['error']}"
except Exception as e:
ai_status = f"error: {str(e)}"
return {
"api": "running",
"database": db_status,
"ai_service": ai_status,
"timestamp": datetime.now().isoformat()
}
if __name__ == "__main__":
import uvicorn
from datetime import datetime
logger.info("启动FastAPI服务...")
uvicorn.run(app, host="0.0.0.0", port=8011, log_level="info")# frontend.py
import streamlit as st
import requests
import json
import time
from datetime import datetime
import re
import sys
# uvicorn backend:app --reload --port 8011
# streamlit run frontend.py
# Local URL: http://localhost:8501
# Network URL: http://192.168.35.78:8501
# 配置
BACKEND_URL = "http://localhost:8011" # 后端服务地址
CHECK_INTERVAL = 1 # 检查后端服务状态的间隔(秒)
MAX_RETRIES = 3 # 最大重试次数
def check_backend():
"""检查后端服务是否可用"""
try:
response = requests.get(f"{BACKEND_URL}/health", timeout=3)
return response.status_code == 200
except requests.exceptions.RequestException:
return False
def get_api_status():
"""获取API全面状态信息"""
try:
response = requests.get(f"{BACKEND_URL}/api-status", timeout=5)
if response.status_code == 200:
return response.json()
return None
except:
return None
def show_process_flow(current_step, total_steps=4):
"""显示流程进度条和状态"""
steps = [
"1. 输入身份证信息",
"2. AI解析信息",
"3. 编辑补充信息",
"4. 保存到数据库"
]
st.subheader("处理流程")
# 创建进度条
progress = min(1.0, current_step / total_steps)
st.progress(progress)
# 显示步骤状态
for i, step in enumerate(steps):
if i < current_step:
st.markdown(f"✅ **{step}** - 已完成")
elif i == current_step:
st.markdown(f"🟡 **{step}** - 当前步骤")
else:
st.markdown(f"⚪ {step} - 待处理")
# 显示当前状态信息
status_messages = {
0: "请在下方输入身份证信息,然后点击'开始解析'按钮",
1: "AI正在分析身份证信息,请稍候...",
2: "请检查AI提取的信息,如有缺失请补充完整",
3: "系统正在将信息保存到数据库,请稍候..."
}
if current_step < total_steps:
st.info(f"**当前状态:** {status_messages.get(current_step, '处理中...')}")
def show_system_status():
"""显示系统各组件状态"""
# sidebar 侧边栏
st.sidebar.title("系统状态监控")
# 检查后端状态
backend_status = "✅ 正常" if check_backend() else "❌ 不可用"
st.sidebar.markdown(f"- **后端服务:** {backend_status}")
# 检查API详细状态
api_status = get_api_status()
if api_status:
db_status = "✅ 正常" if "connected" in api_status["database"] else f"❌ 问题: {api_status['database']}"
ai_status = "✅ 正常" if "available" in api_status["ai_service"] else f"❌ 问题: {api_status['ai_service']}"
else:
db_status = "⚠️ 未知"
ai_status = "⚠️ 未知"
st.sidebar.markdown(f"- **数据库连接:** {db_status}")
st.sidebar.markdown(f"- **AI服务:** {ai_status}")
# 显示当前时间
st.sidebar.markdown(f"- **当前时间:** {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}")
st.sidebar.markdown("---")
# info 蓝色信息框 提示、说明
st.sidebar.info("系统由四个独立组件构成:\n- 前端 (Streamlit)\n- 后端 (FastAPI)\n- AI服务 (DeepSeek)\n- 数据库 (MySQL)")
# 修复:不再在函数内部调用st.experimental_rerun()
# 而是设置一个标志,让主流程处理
# button 触发事件,如跳转、提交、重试
if not check_backend():
if st.sidebar.button("🔄 重试连接后端", use_container_width=True):
st.session_state.retry_connection = True
def main_page():
"""主页面:输入身份证信息并显示解析结果"""
st.title("身份证信息提取系统")
# 显示流程
show_process_flow(0)
st.subheader("步骤 1: 请输入身份证信息")
# 输入区域
st.markdown("请在下方输入包含完整身份证信息的文本:")
## text_area 多行文本输入框
input_text = st.text_area(
"身份证文本",
height=200,
help="请输入包含姓名、性别、民族、出生、住址、公民身份号码的身份证信息文本",
value="""兹有中华人民共和国公民,姓名为张伟,性别男,民族汉,出生于1990年5月15日。其现住址为北京市海淀区颐和园路5号北京大学畅春园宿舍楼3单元101室。公民身份号码为11010819900515301X"""
)
## columns 列布局
col1, col2 = st.columns([1, 4])
with col1:
if st.button("开始解析", type="primary", use_container_width=True):
if not input_text.strip():
st.error("请输入身份证信息")
return
with st.spinner("正在验证后端服务状态..."):
if not check_backend():
st.error("后端服务不可用,请确保已启动FastAPI服务")
return
## spinner 加载动画 转圈圈
with st.spinner("正在调用AI服务解析信息..."):
try:
# 调用后端解析API - 前端->后端的关键交互
response = requests.post(
f"{BACKEND_URL}/parse",
json={"text": input_text},
timeout=15
)
if response.status_code == 200:
result = response.json()
# 保存结果到session state,用于后续页面
st.session_state.parse_result = result
st.session_state.input_text = input_text
# 显示解析结果
st.success("AI解析完成!")
# 屏幕放彩色气球动画
st.balloons()
# 等待用户看到成功消息
time.sleep(1)
# 跳转到解析结果页面
st.session_state.page = "parsed"
safe_rerun()
else:
st.error(f"解析失败 (状态码 {response.status_code}): {response.text}")
except requests.exceptions.RequestException as e:
st.error(f"网络请求超时或失败: {str(e)}")
st.info("请检查:\n1. 后端服务是否正常运行\n2. 网络连接是否正常\n3. API密钥是否有效")
except Exception as e:
st.error(f"请求处理失败: {str(e)}")
with col2:
st.info("💡 提示: 系统会自动提取姓名、性别、民族、出生、住址和身份证号码六个关键字段")
# 显示使用示例
## expander 折叠面板
with st.expander("查看示例"):
st.code("""
兹有中华人民共和国公民,姓名为张伟,性别男,民族汉,出生于1990年5月15日。其现住址为北京市海淀区颐和园路5号北京大学畅春园宿舍楼3单元101室。公民身份号码为11010819900515301X
""")
def parsed_page():
"""解析结果页面"""
st.title("身份证信息提取系统")
# 显示流程
show_process_flow(1)
st.subheader("步骤 2: AI解析结果")
# 获取之前解析的结果
if "parse_result" not in st.session_state:
st.error("没有解析结果,请先返回主页面解析信息")
if st.button("返回主页面"):
st.session_state.page = "main"
safe_rerun()
return
result = st.session_state.parse_result
# 显示解析结果
st.subheader("AI提取的信息")
display_id_info(result["data"])
# 检查是否有缺失字段
missing_fields = [k for k, v in result["data"].items() if not v]
if missing_fields:
st.warning(f"⚠️ 检测到 {len(missing_fields)} 个字段未提取到: {', '.join(missing_fields)}")
st.info("建议点击下方按钮进行编辑补充")
else:
st.success("✅ AI已成功提取所有字段信息")
# 添加动画效果
with st.spinner("系统正在准备下一步操作..."):
time.sleep(0.5)
col1, col2 = st.columns(2)
with col1:
if st.button("返回重新输入", type="secondary", use_container_width=True):
st.session_state.page = "main"
safe_rerun()
with col2:
if st.button("下一步: 编辑信息", type="primary", use_container_width=True):
st.session_state.page = "edit"
safe_rerun()
def edit_page():
"""编辑页面:允许用户编辑/补充解析结果"""
st.title("身份证信息提取系统")
# 显示流程
show_process_flow(2)
st.subheader("步骤 3: 编辑/补充信息")
# 获取之前解析的结果
if "parse_result" not in st.session_state:
st.error("没有可编辑的数据,请先返回主页面解析信息")
if st.button("返回主页面"):
st.session_state.page = "main"
safe_rerun()
return
result = st.session_state.parse_result
# 创建编辑表单
## st.form 创建展示表单
with st.form("edit_form"):
st.subheader("请检查并完善以下信息")
# 各字段编辑
name = st.text_input("姓名", value=result["data"].get("name", ""))
gender = st.text_input("性别", value=result["data"].get("gender", ""))
ethnicity = st.text_input("民族", value=result["data"].get("ethnicity", ""))
birth = st.text_input("出生", value=result["data"].get("birth", ""))
address = st.text_area("住址", value=result["data"].get("address", ""), height=100)
id_number = st.text_input("公民身份号码", value=result["data"].get("id_number", ""))
# 提交按钮
## 表单容器 + 提交按钮 避免每次输入都刷新,适合多字段编辑
submitted = st.form_submit_button("下一步: 保存到数据库", type="primary")
if submitted:
## spinner 避免每次输入都刷新,适合多字段编辑
with st.spinner("正在验证输入信息..."):
# 简单验证身份证号码格式
if id_number and not re.match(r'^[1-9]\d{5}(18|19|20)\d{2}(0[1-9]|1[0-2])(0[1-9]|[12]\d|3[01])\d{3}[\dXx]$', id_number):
st.error("身份证号码格式不正确,请检查")
return
with st.spinner("正在保存信息到数据库..."):
try:
# 准备数据
save_data = {
"name": name,
"gender": gender,
"ethnicity": ethnicity,
"birth": birth,
"address": address,
"id_number": id_number,
"input_text": result["input_text"],
"llm_response": result["llm_response"]
}
# 调用后端保存API
response = requests.post(
f"{BACKEND_URL}/save",
json=save_data,
timeout=10
)
if response.status_code == 200:
st.session_state.save_result = response.json()
st.session_state.final_data = save_data
# 跳转到完成页面
st.session_state.page = "complete"
safe_rerun()
else:
st.error(f"保存失败 (状态码 {response.status_code}): {response.text}")
except requests.exceptions.RequestException as e:
st.error(f"网络请求超时或失败: {str(e)}")
st.info("请检查后端服务是否正常运行")
except Exception as e:
st.error(f"请求处理失败: {str(e)}")
# 返回按钮
if st.button("← 返回解析结果", type="secondary", use_container_width=True):
st.session_state.page = "parsed"
safe_rerun()
def complete_page():
"""完成页面:显示最终结果"""
st.title("身份证信息提取系统")
# 显示流程 最前面设定的
show_process_flow(3)
st.subheader("步骤 4: 处理完成")
st.success("✅ 身份证信息已成功处理并保存到数据库!")
st.balloons()
# 添加完成动画
st.markdown("""
<style>
.congrats {
animation: pulse 2s infinite;
}
@keyframes pulse {
0% { transform: scale(1); }
50% { transform: scale(1.05); }
100% { transform: scale(1); }
}
</style>
""", unsafe_allow_html=True)
## 动态晃动动画
st.markdown('<div class="congrats">🎉 恭喜!所有步骤已完成 🎉</div>', unsafe_allow_html=True)
# 显示最终结果
st.subheader("最终保存的信息")
# 添加安全检查
if "final_data" in st.session_state:
## 处理过的前端表格页面显示
display_id_info(st.session_state.final_data)
else:
st.warning("无法显示最终数据,请重新处理")
st.json({"error": "final_data not found in session state"})
# 显示数据库ID
if "save_result" in st.session_state and "id" in st.session_state.save_result:
st.info(f"✅ 数据库记录ID: {st.session_state.save_result['id']}")
st.info(f"✅ 保存时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}")
else:
st.warning("⚠️ 无法获取数据库记录ID")
# 提供返回选项
col1, col2 = st.columns(2)
with col1:
if st.button("查看原始输入", type="secondary", use_container_width=True):
with st.expander("原始输入内容"):
if "input_text" in st.session_state:
st.text(st.session_state.input_text)
else:
st.warning("原始输入数据不可用")
with col2:
if st.button("开始新处理", type="primary", use_container_width=True):
# 重置所有状态
for key in list(st.session_state.keys()):
del st.session_state[key]
st.session_state.page = "main"
safe_rerun()
# 显示系统闭环信息
st.markdown("### 系统交互流程闭环")
st.markdown("""
1. **前端** → 用户输入身份证信息
2. **前端 → 后端** → 发送解析请求
3. **后端 → AI服务** → 调用DeepSeek API提取信息
4. **AI服务 → 后端** → 返回结构化数据
5. **后端 → 前端** → 显示解析结果
6. **用户编辑** → 补充缺失信息
7. **前端 → 后端** → 发送保存请求
8. **后端 → 数据库** → 存储完整信息
9. **系统完成** → 显示成功状态,闭环完成
""")
# 添加成功动画
st.markdown("""
<style>
.success-animation {
background: linear-gradient(135deg, #4CAF50, #8BC34A);
color: white;
padding: 15px;
border-radius: 10px;
text-align: center;
font-weight: bold;
animation: fadeIn 1s;
}
@keyframes fadeIn {
from { opacity: 0; }
to { opacity: 1; }
}
</style>
<div class="success-animation">所有组件交互成功完成!数据已持久化存储</div>
""", unsafe_allow_html=True)
def display_id_info(data):
"""以表格形式显示身份证信息 - 前端展示的关键实现"""
# 创建Markdown表格
table_md = "| 字段 | 值 |\n|------|-----|\n"
table_md += f"| 姓名 | {data.get('name', '')} |\n"
table_md += f"| 性别 | {data.get('gender', '')} |\n"
table_md += f"| 民族 | {data.get('ethnicity', '')} |\n"
table_md += f"| 出生 | {data.get('birth', '')} |\n"
table_md += f"| 住址 | {data.get('address', '')} |\n"
table_md += f"| 公民身份号码 | {data.get('id_number', '')} |\n"
st.markdown(table_md)
# 添加字段状态指示器
st.subheader("字段完整性分析")
fields = [
("姓名", data.get('name', '')),
("性别", data.get('gender', '')),
("民族", data.get('ethnicity', '')),
("出生", data.get('birth', '')),
("住址", data.get('address', '')),
("身份证号", data.get('id_number', ''))
]
for field, value in fields:
if value:
st.markdown(f"✅ **{field}**: 已成功提取")
else:
st.markdown(f"❌ **{field}**: 未提取到,需要补充")
# =============== 专业修复:解决Streamlit API兼容性问题 ===============
def safe_rerun():
"""安全地重新运行Streamlit应用,兼容不同版本的Streamlit"""
try:
# 尝试使用Streamlit 1.27.0+的稳定API
st.rerun()
except AttributeError:
# 回退到旧版Streamlit的experimental API
st.experimental_rerun()
# 页面路由
if "page" not in st.session_state:
st.session_state.page = "main"
# 修复:将重试连接的处理移到主流程
if "retry_connection" in st.session_state and st.session_state.retry_connection:
st.session_state.retry_connection = False
safe_rerun()
# 显示系统状态
show_system_status()
# 检查后端服务
if st.session_state.page != "main" and not check_backend():
st.warning("⚠️ 后端服务不可用,请确保已启动FastAPI服务")
if st.button("重试连接"):
st.session_state.retry_connection = True
safe_rerun()
# 显示当前页面
if st.session_state.page == "main":
main_page()
elif st.session_state.page == "parsed":
parsed_page()
elif st.session_state.page == "edit":
edit_page()
elif st.session_state.page == "complete":
complete_page()11. 图片/视频

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)